はじめに
こんにちは、SRE部 ECプラットフォーム基盤SREブロックの亀井です。
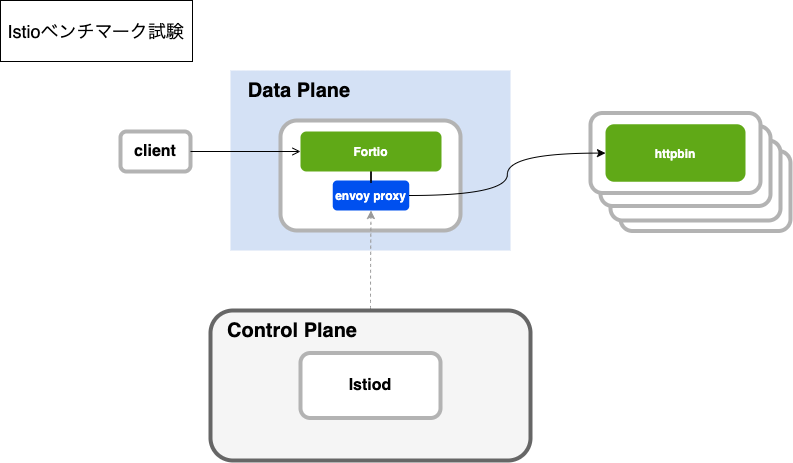
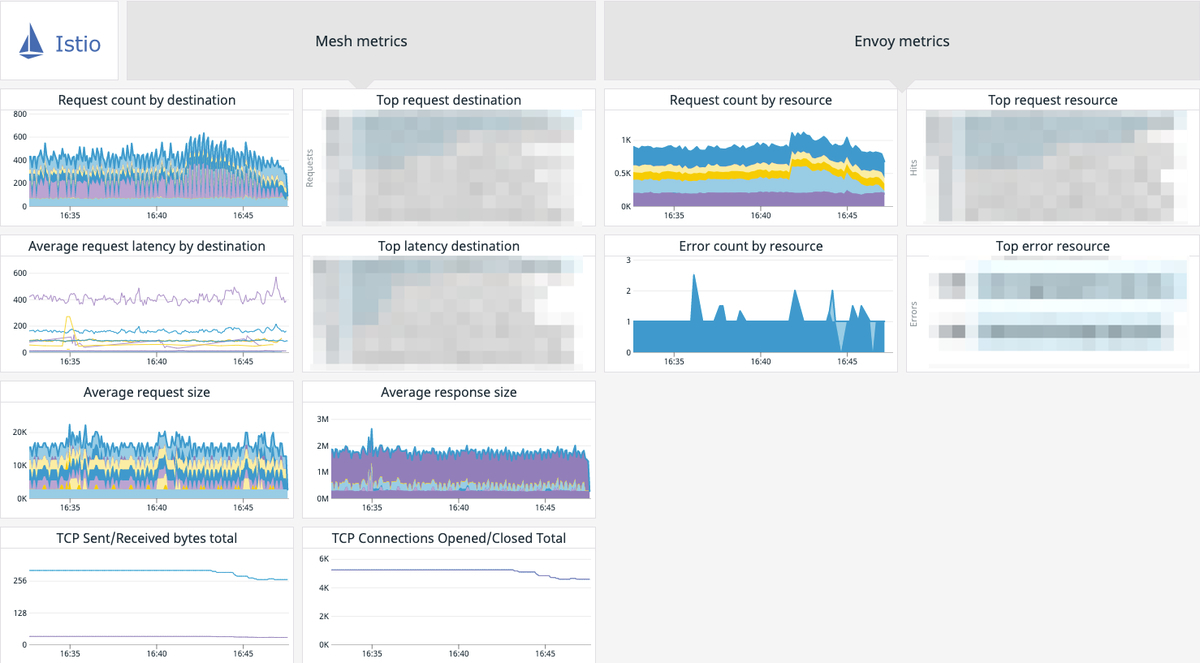
ZOZOTOWNのマイクロサービスプラットフォーム基盤(以下、プラットフォーム基盤)ではサービス間通信におけるトラフィック制御・カナリアリリース実装のため、Istioによるサービスメッシュを導入しました。現在は初期段階としてBFF機能を司るZOZO Aggregation APIとその通信先サービス間へ部分的に導入しています。
ZOZO Aggregation APIについては、以前に三神が紹介しているので、そちらの記事をご参照ください。
その後、Istioによる一貫したトラフィック制御・カナリアリリース実装を目的とし、プラットフォーム基盤全体へサービスメッシュを拡大しました。本記事ではその取り組みを紹介します。
なお、本記事はプロダクション運用中サービスのサービスメッシュ移行という運用目線の内容です。Istioの概要や選定理由などサービスメッシュ導入の背景にご興味がある方は、以前川崎が執筆した記事をご参照ください。
- はじめに
- サービスメッシュ導入後の課題
- プロダクション運用中サービスのサービスメッシュ化方針
- ZOZO API Gatewayサービスメッシュ化における考慮点
- ZOZOTOWNへの導入効果
- 今後の課題
- さいごに
サービスメッシュ導入後の課題
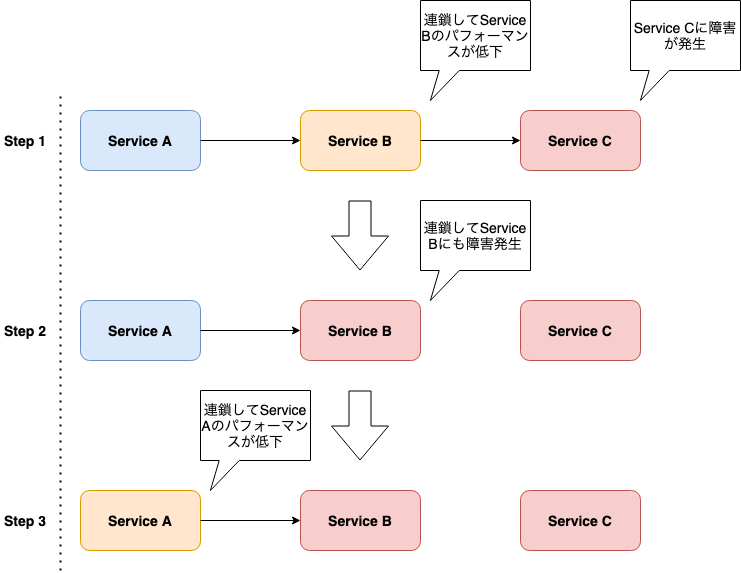
ZOZO Aggregation APIと通信先サービスが部分的にサービスメッシュ化された状態を下図に示します。
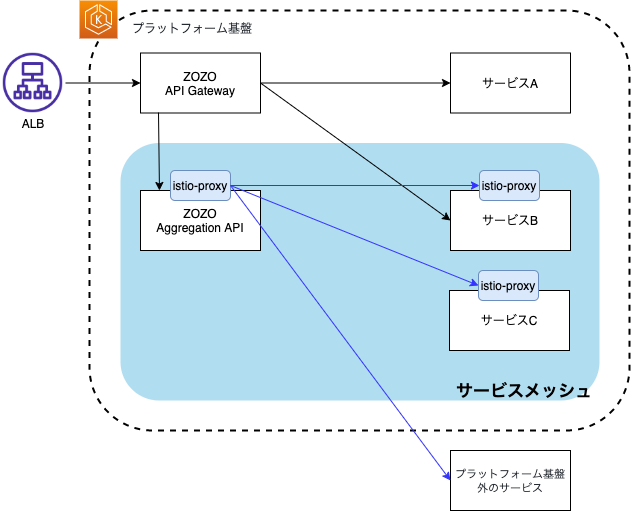
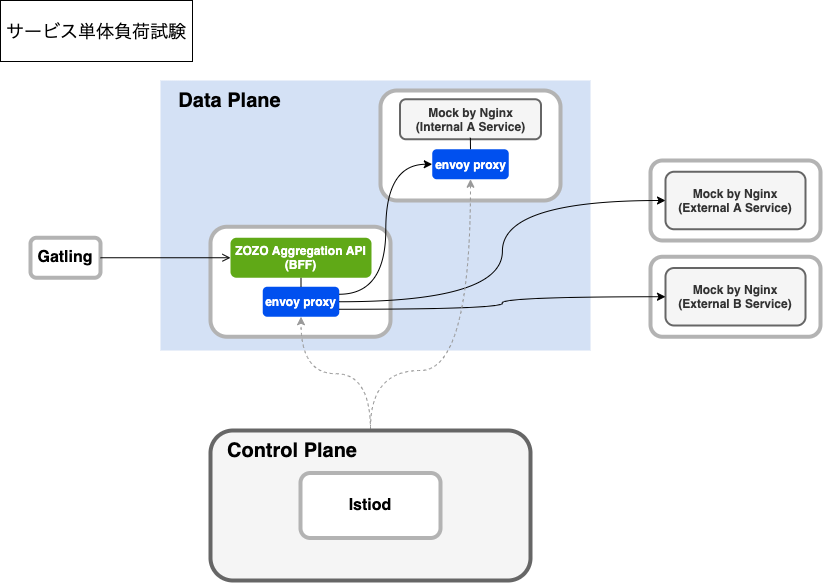
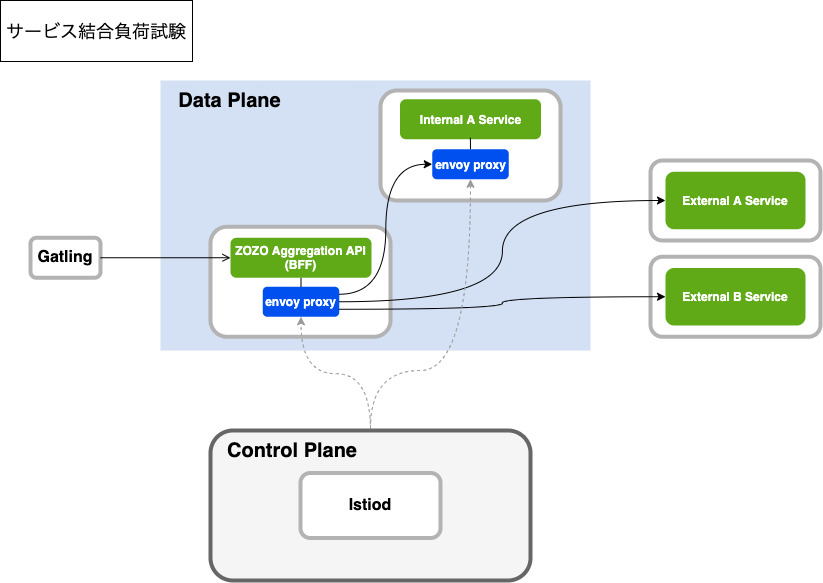
「ZOZO Aggregation API → サービス」間はサービスメッシュ化され、Istioによるトラフィック制御・カナリアリリースが実装されました。しかし、プラットフォーム基盤全体ではサービスメッシュの導入は部分的であり、下図の様にサービスによってトラフィック制御・カナリアリリース手法に差異が生まれていました。サービスによって「設定が異なる」または「複数の設定を持つ」状態となっており、運用負荷が高く、二重にリトライが行われるなどの設定不備によるミスが起きやすい状況にありました。
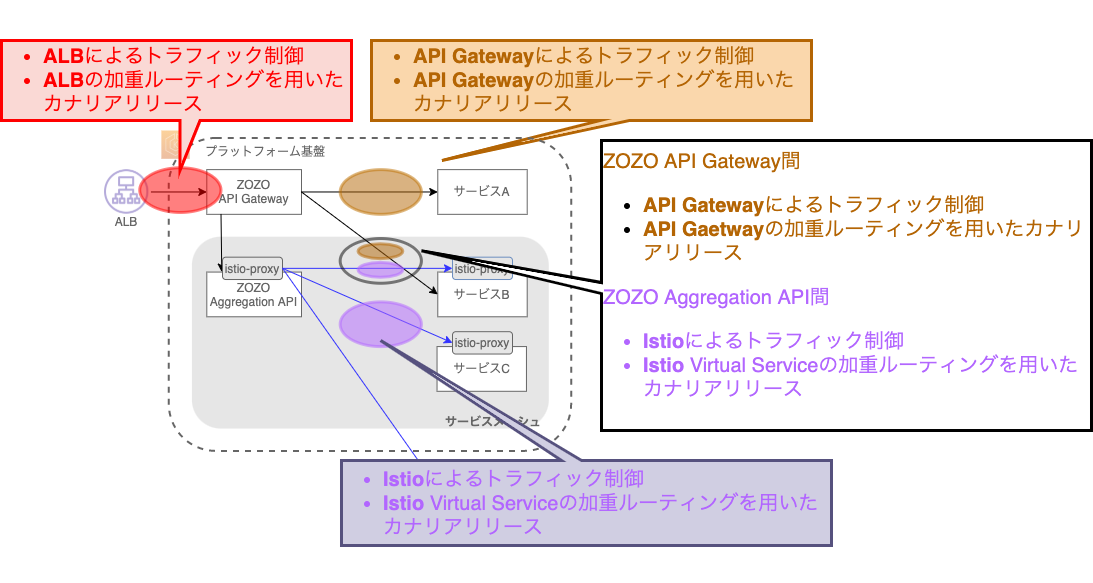
この状況の解消に向け、プラットフォーム基盤全体へサービスメッシュを拡大し、Istioによる一貫したトラフィック制御・カナリアリリース実装の展開を進めました。
プロダクション運用中サービスのサービスメッシュ化方針
プロダクション運用中サービスのサービスメッシュ化では、大きく以下の2点を実施しました。
- ZOZO API GatewayとIstioの責務整理と機能分担
- 段階的な移行
以降で、具体的な内容を順に説明していきます。
ZOZO API GatewayとIstioの責務整理と機能分担
ZOZOTOWNはストラングラーパターンでレガシシステムの段階的なリプレイスを行っています。ZOZO API Gatewayは、この中でストラングラーファサードという役割を担っており、ルーティングや認証、トラフィック制御などの機能を持つリバースプロキシとして動作しています。なお、ZOZO API Gatewayは、独自要件に対し柔軟に対応出来るよう独自実装しています。
詳細は、旗野の記事をご参照ください。
一方、Istioはトラフィック制御、セキュリティ、可観測性の機能を持ちます。つまり、ZOZO API GatewayとIstioでタイムアウト・リトライなどのトラフィック制御機能が重複しています。そこで、ZOZO API GatewayとIstioの責務を明確にし、重複する機能を分担する必要がありました。
まず、下図の様に責務を整理しました。
 (画像が小さい場合は拡大してご覧ください)
(画像が小さい場合は拡大してご覧ください)
そして、下図の様に機能を分担しました。
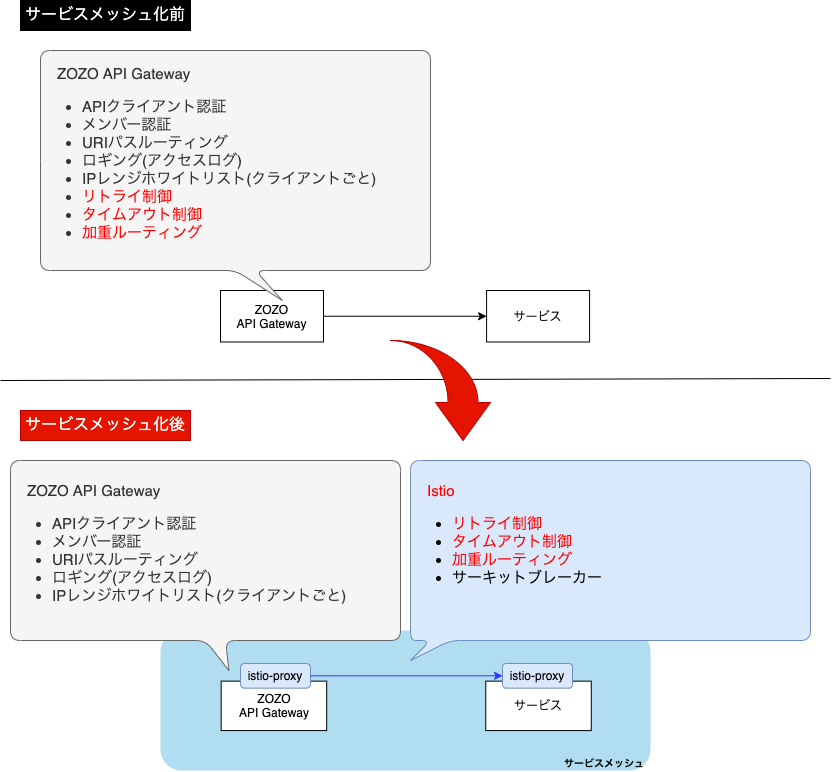
このような責務整理と機能分担の結果、プラットフォーム基盤全体に対し、サービスメッシュの拡大を滞りなく進める事が出来ました。
段階的な移行
ZOZOTOWNを停止させずにサービスメッシュへ移行するため、下記の様に段階的な移行方針を取りました。
- 優先度の高いサービスから段階的にサービスメッシュ化
- ZOZO API Gateway
- その他マイクロサービス
- 無停止を前提としたサービス単位でカナリアリリース
一斉にプラットフォーム基盤全体をサービスメッシュ化せず、優先度の高いサービスから下図の様に10%、100%とカナリアリリースし、無停止で移行しました。

ZOZO API Gatewayサービスメッシュ化における考慮点
ZOZO API Gatewayは責務整理と機能分担の他にも考慮した点があります。みなさまの参考になるであろう、大きな考慮点なので、その内容をご紹介します。
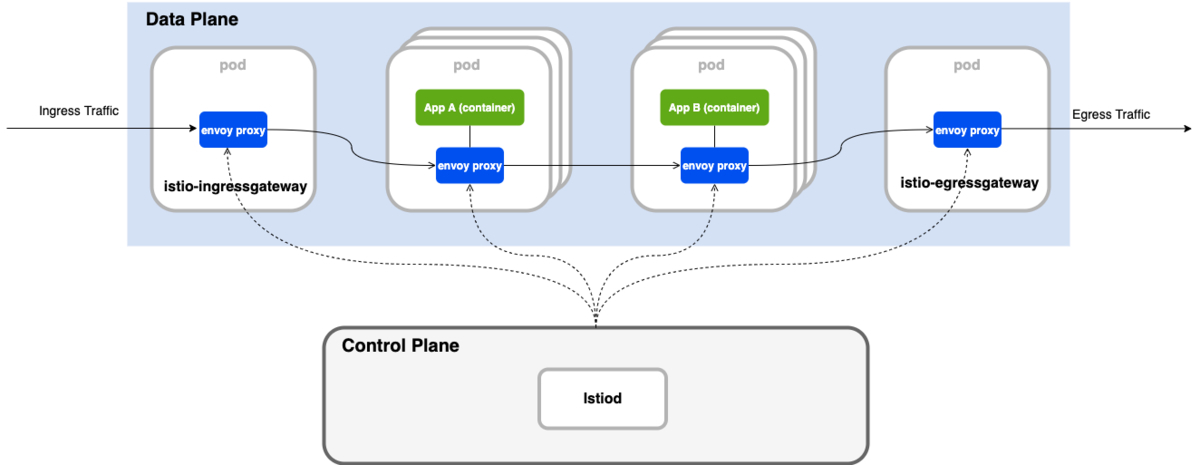
「ALB → ZOZO API Gateway」のトラフィックはサービスメッシュ外から中への通信(Ingress Traffic)です。Ingress Trafficにおいても、サービスメッシュ間のトラフィック同様にIstioによる一貫したトラフィック制御が求められていました。
そこで、IngressGatewayを使う事で上記の課題を解決しました。サービスメッシュの境界にIngressGateway(実態はistio-proxy)を追加する事で、Ingress TrafficもIstioによるトラフィック制御が可能となります。
なお、k8sマニフェストは下記の通りです。IstioOperatorにてIngressGatewayコンポーネントを作成し、ZOZO API Gateway用のIstioカスタムリソースを設定します。
apiVersion: install.istio.io/v1alpha1 kind: IstioOperator metadata: namespace: istio-system name: istio-control-plane spec: components: ingressGateways: # IngressGatewayコンポーネントを追加 - name: ingressgateway --- apiVersion: networking.istio.io/v1alpha3 kind: Gateway metadata: name: gateway spec: selector: istio: ingressgateway servers: - hosts: - zozo-api-gateway.example.com port: name: http number: 80 protocol: HTTP --- apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: virtualservice spec: gateways: - gateway hosts: - zozo-api-gateway.example.com http: - route: - destination: host: zozo-api-gateway.ns.svc.cluster.local subset: primary weight: 100 - destination: host: zozo-api-gateway.ns.svc.cluster.local subset: canary weight: 0 timeout: 10s --- apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: destinationrule spec: host: zozo-api-gateway.ns.svc.cluster.local subsets: - name: primary labels: version: primary - name: canary labels: version: canary
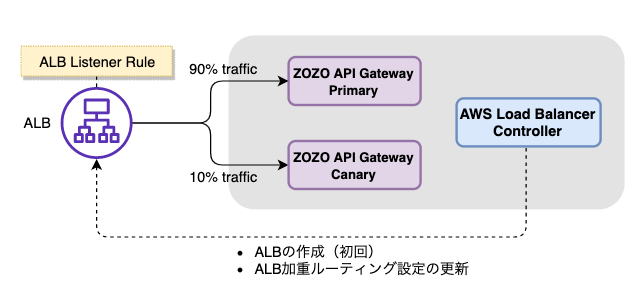
Amazon EKS上にIngressGatewayをデプロイすると、デフォルトではClassic Load Balancer(CLB)が作成され、サービスが外部に公開されます。しかし、ZOZOTOWNではセキュリティ要件により、AWS WAFのアタッチされたApplication Load Balancer(ALB)を使っています。そのため、サービスメッシュ化も同様のセキュリティレベルを保つため、下図の様にIngressGatewayはCLBで公開せず、既存のALB配下で公開する構成にしました。
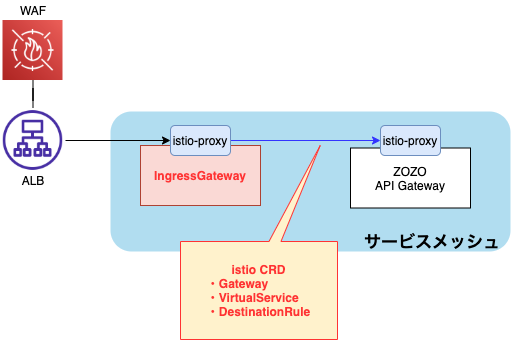
そして、CLBはセキュリティホールとなり得るため、削除しています。下記の様にIstioOperatorのIngressGatewayコンポーネントを設定する事でCLBを作成しない事が可能です。
apiVersion: install.istio.io/v1alpha1 kind: IstioOperator metadata: namespace: istio-system name: istio-control-plane spec: components: ingressGateways: - name: ingressgateway k8s: service: type: NodePort # CLBを作成しない
ZOZOTOWNへの導入効果
ZOZO API GatewayとIstioの責務整理と機能分担を行い、サービス単位での段階的な移行をしました。その結果、ZOZOTOWNを停止することなく、下図の様にプラットフォーム基盤全体をサービスメッシュ化することが出来ました。
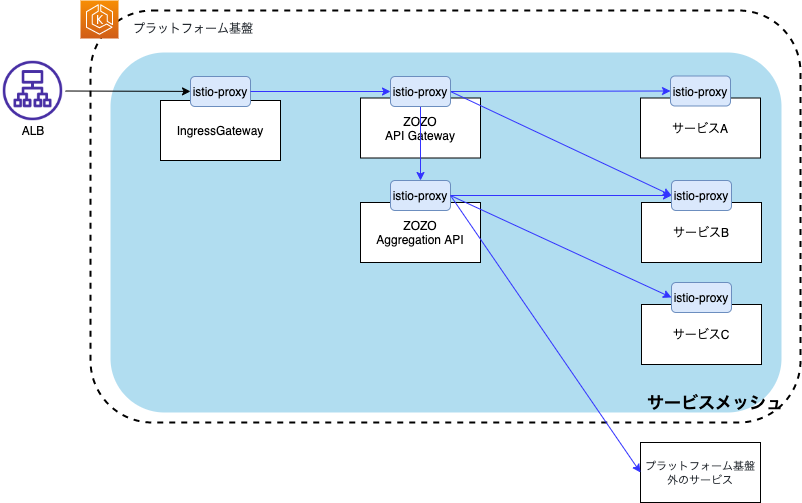
そして、プラットフォーム基盤全体がサービスメッシュ化された事で下記の様な事が可能となっています。
- 一貫したトラフィック制御
- カナリアリリース手法の統一
- 基盤全体でのIstio活用
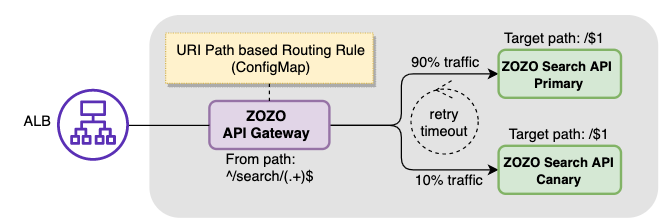
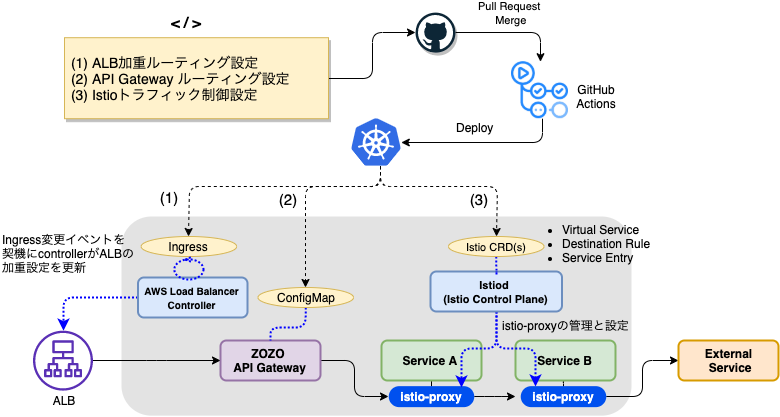
2つ目に挙げた「カナリアリリース手法の統一」は、ZOZO API Gatewayの場合、下図の様に変更されIstioによる加重ルーティングを用いてカナリアリリースが可能になりました。
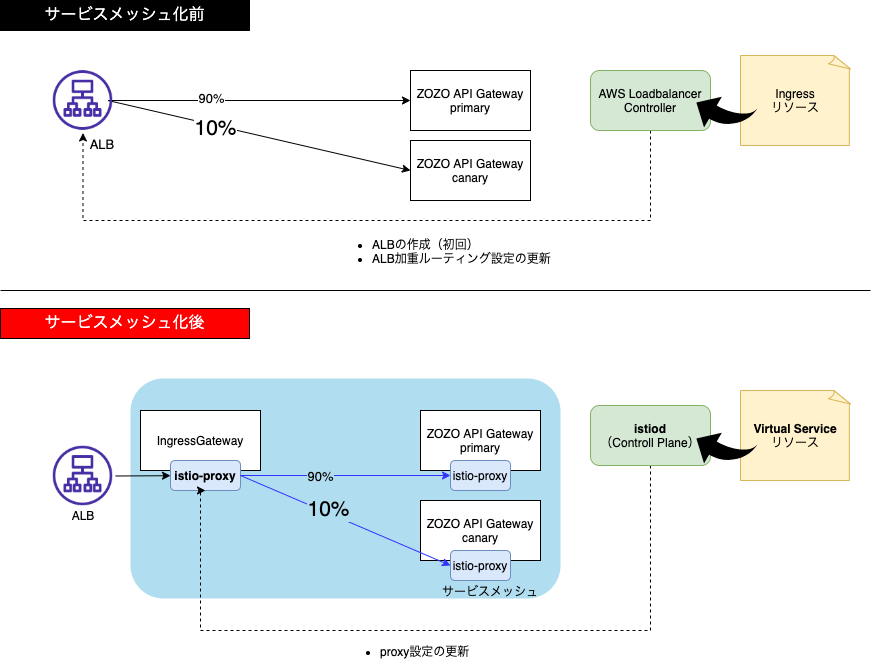
次に、Istio Virtual Service、Destination Ruleリソースのマニフェスト設定例を紹介します。
まず、Destination Ruleでsubsetにprimary、canaryを登録します。合わせて、Virtual Serviceのroute部分に先程のsubsetを指定し宛先を登録します。そして、weightを更新してクラスタに適応すると、istiodにより自動的にistio-proxyのconfigが更新され、ZOZO API Gatewayへのトラフィック加重率が変更されます。
apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: virtualservice spec: hosts: - zozo-api-gateway.example.com gateways: - ingressgateway http: - route: - destination: host: zozo-api-gateway.ns.svc.cluster.local subset: primary weight: 90 - destination: host: zozo-api-gateway.ns.svc.cluster.local subset: canary weight: 10 retries: attempts: 1 perTryTimeout: 3s retryOn: 5xx timeout: 6s --- apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: destinationrule spec: host: zozo-api-gateway.ns.svc.cluster.local subsets: - name: primary labels: version: zozo-api-gateway - name: canary labels: version: zozo-api-gateway-canary
以上の流れで、プラットフォーム基盤全体のカナリアリリース手法が上記に統一されました。
また、基盤全体でIstioの活用も行っており、直近ではサーキットブレーカーを導入しマイクロサービスの連鎖障害に備える取り組みを行いました。詳細は大澤の記事で解説しているので、併せてご参照ください。
今後の課題
さらなる改善のため、大きく下記2つの課題に取り組んでいく予定です。
- k8sクラスタを跨ぐIstioサービスメッシュの拡大
- カナリアリリースの自動化
k8sクラスタを跨ぐIstioサービスメッシュの拡大
ECプラットフォーム基盤SREブロックでは、認証サービス基盤というもう1つの基盤・k8sクラスタが存在します。個人情報などのセキュリティ要件の高い情報を取り扱うサービスが稼働する基盤です。プラットフォーム基盤から認証サービス基盤間の通信は現状サービスメッシュ化出来ておらず、下図の様にZOZO API Gatewayによるトラフィック制御が行われています。
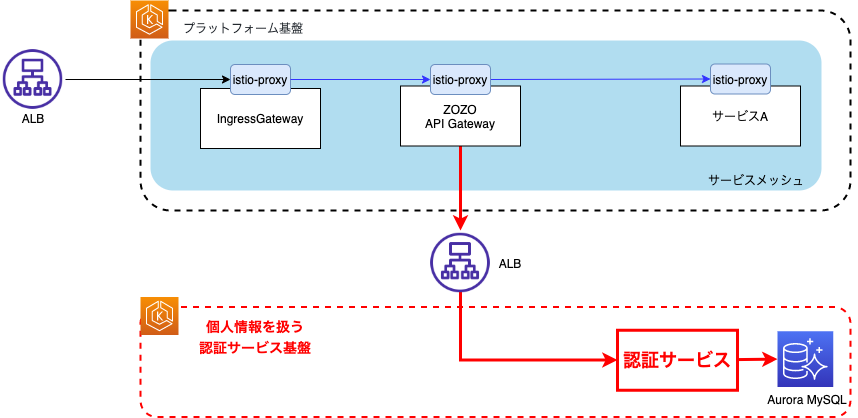
k8sクラスタを跨ぐサービスメッシュの構築を今後の課題としています。
カナリアリリースの自動化
プラットフォーム基盤全体のサービスメッシュ化により、障害を軽減し無停止で進行するカナリアリリース手法が統一されました。しかし、カナリアリリースの進行における判断コストや加重ルーティングを進行、もしくは切り戻す設定変更コストは依然高い状況にあります。一方、カナリアリリース手法が統一されたことで、判断の自動化・設定変更の自動化がしやすくなりました。そこで、Progressive Deliveryの導入など更なるリリーススピードの向上、運用負荷の削減も今後の課題としています。
さいごに
ZOZOでは、一緒にサービスを作り上げてくれるSREエンジニアを募集中です。ご興味のある方は以下のリンクからぜひご応募ください。