



はじめに
こんにちは。SRE部MLOpsチームの田島(@tap1ma)です。
現在、ZOZOTOWNの「おすすめアイテム」に使われていたアイテム推薦ロジックを刷新するプロジェクトを進めています。既に一部のユーザに向けて新しいアイテム推薦ロジックを使った「おすすめアイテム」の配信を開始しています。その刷新に伴い推薦システムのインフラ基盤から新しく構築したので、本記事ではその基盤について解説したいと思います。
目次
- はじめに
- 目次
- 「おすすめアイテム」とは
- 新しい推薦ロジック
- 新しい推薦システム
- まとめ
- 最後に
「おすすめアイテム」とは
この記事で扱う「おすすめアイテム」とは、ZOZOTOWNで取り扱っている各アイテムの詳細ページ内にある「おすすめアイテム」枠のことです。アイテム詳細ページのアイテムやそのページを閲覧しているユーザに合わせて、おすすめのアイテムを複数表示しています。
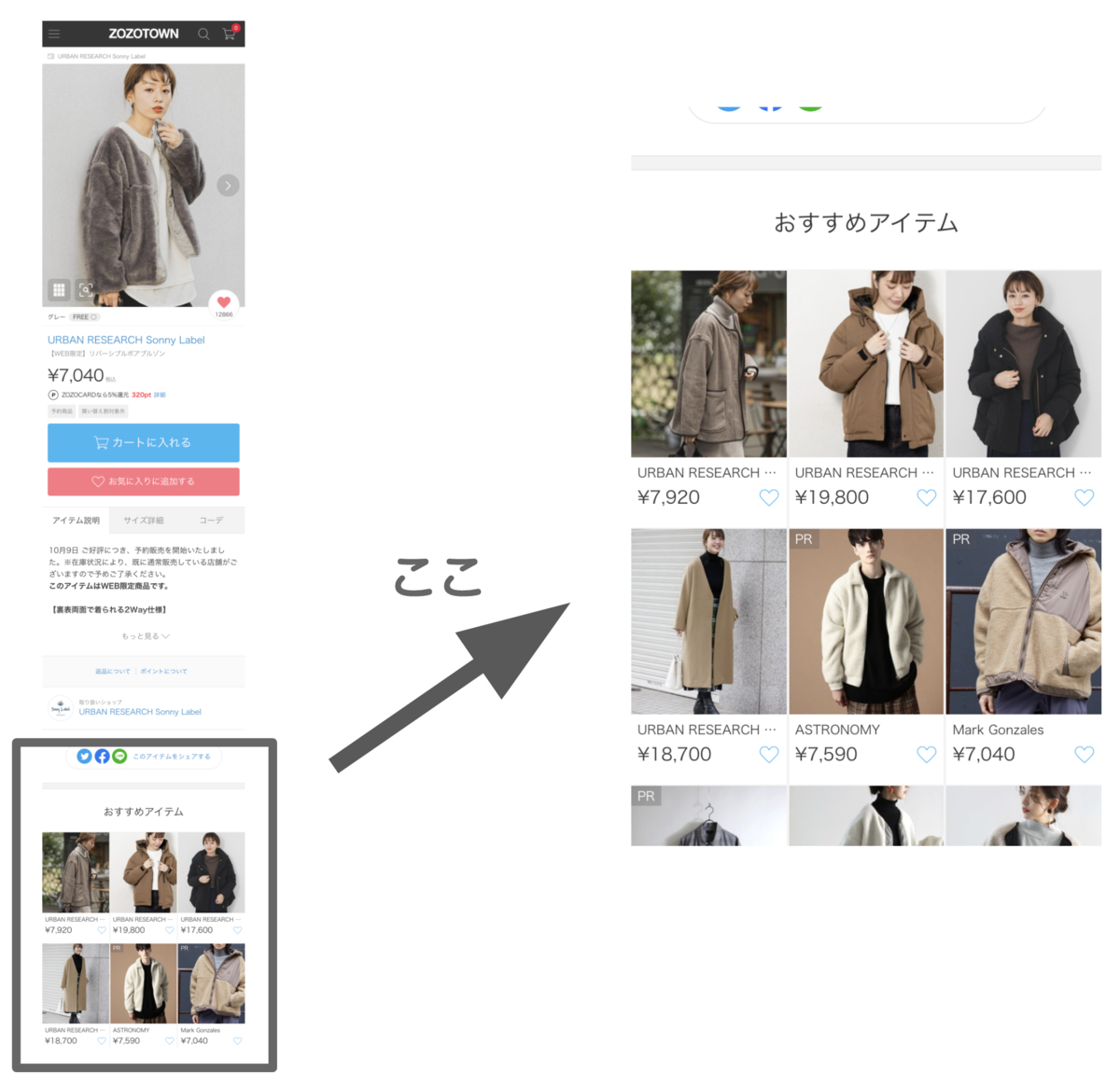
アイテムの詳細ページは、アイテムの詳細な説明やサイズ毎の在庫状況、商品画像といった情報を含み、ユーザがアイテム購入時に必ず通る重要なページです。そして、アイテム詳細ページ内に設置された「おすすめアイテム」枠もまたZOZOTOWNの重要な要素の1つです。
しかし、これまで使われていた推薦ロジックは10年以上前に開発されたもので、ストアドプロシージャとしてオンプレミスのSQL Serverに保存されているなど非常にレガシー化したシステムの上で動いていました。そのため、大きな技術的負債となっていました。
この度、より高性能な推薦ロジックの導入とそのためのシステムをインフラ基盤から新しく構築することで、推薦ロジックの性能向上と推薦システムの技術的負債の回収を同時に実現できました。
新しい推薦ロジック
推薦ロジックの刷新に際し、以下の2種類の推薦ロジックを開発しました。
- Recommendations AIを用いた推薦ロジック
- ZOZO研究所によって独自で開発された推薦ロジック
2種類の推薦ロジックの開発を並行で行い、互いに性能を競わせながら、より高性能な推薦ロジックの実現を目指して日々開発に取り組んでいます。
Recommendations AIを用いた推薦ロジック
Recommdendations AIはECサイトに特化し、ユーザにパーソナライズされた商品の推薦システムを機械学習の高度な知識を必要とせずに簡単に構築できるGCPのフルマネージドサービス(本稿執筆時点でベータ版)です。
推薦ロジックのモデル構築に必要なデータを入力することで推薦ロジックの機械学習モデルの構築から、そのモデルを使って商品の推薦結果を返す推論用のWeb APIのサービングまで自動で行ってくれます。
また、データの入力に対してリアルタイムでモデルを更新できること、推論用のWeb APIがスケーラブルであることといった特徴を持ちます。
詳しくはこちらの資料をご覧ください。
ZOZO研究所によって独自で開発された推薦ロジック
弊社が有する研究機関「ZOZO研究所」によって独自で開発された推薦ロジックです。
現在は、ランダムウォークのアルゴリズムをベースとし、高速な推論速度、アイテムのカテゴリ分布の調整が可能(=推薦アイテムの多様性を制御できる)、などの特徴を持つ推薦ロジックとなっています。
手法の詳細は本記事では割愛しますが、現在もより高性能な推薦ロジックの実現を目指して様々な手法を用いた開発が進められています。
新しい推薦システム
本章では、ユーザがアイテムの詳細ページへアクセスした際に詳細ページの「おすすめアイテム」枠に最適なアイテムを選出する新しい推薦システムについて詳しく解説します。
推薦システムの処理の流れ
新しい推薦ロジックを使った推薦システムはGCP上でVPCから新規で構築しました。
以下が新しい推薦システムのシステム構成の概略図です。
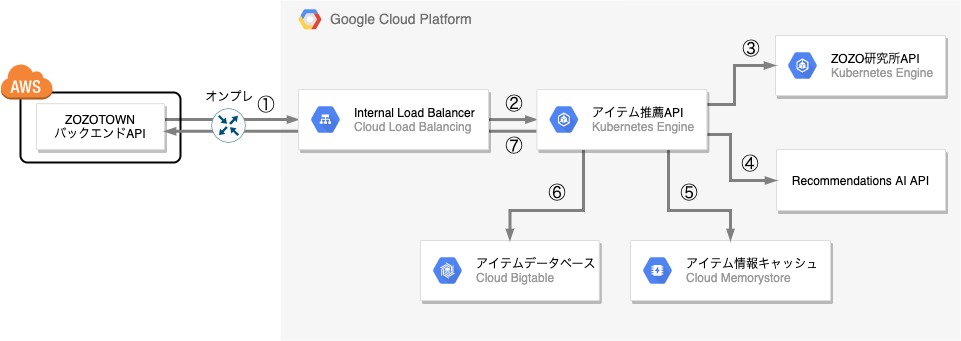
推薦システムはAWS上に存在するZOZOTOWNのバックエンドAPIからアクセスされ、推薦結果のアイテム情報をリストで返します。AWS→GCPのプライベート接続には、AWSではDirect Connect、GCPではDedicated Interconnectという専用線サービスを使用しオンプレ経由での専用線接続を行うことで高可用・低レイテンシーな通信を実現しています。
ZOZOTOWNバックエンドAPIからきたリクエストを推薦システムが処理して推薦結果となるアイテムのリストを返すまでの流れを、図の番号に沿って説明します。なお、登場するコンポーネントの説明は後述します。
- ユーザがアイテムの詳細ページを開いた時に非同期でZOZOTOWNバックエンドAPIはアイテム推薦API宛にGETリクエストを投げます。
- Internal Load BalancerはZOZOTOWNバックエンドAPIからのリクエストをアイテム推薦APIに振り分けます。
- アイテム推薦APIはまずRecommendations AI APIまたはZOZO研究所APIに対してリクエストを投げて、「おすすめアイテム」枠に表示すべきアイテムIDのリストを取得します。
- アイテム推薦APIは3.で取得したアイテムIDのリストに対してRedisにアクセスし、キャッシュヒットした場合は、取得したアイテムの詳細情報を推薦結果のアイテムIDのリストに付加します。
- Redisアクセス時にキャッシュヒットしなかった場合は、Bigtableへアクセスし取得したアイテムの詳細情報を推薦結果のアイテムIDのリストに付加します。
- Bigtableから取得したアイテムの詳細情報をRedisにキャッシュさせた後、推薦結果のアイテムIDのリストに付加します。
- 推薦結果のアイテム情報のリストをZOZOTOWNバックエンドAPIへ返します。
システム構成
以下、図の各コンポーネントを解説します。
Internal Load Balancer
ZOZOTOWNのバックエンドAPIからのアクセスを捌くL7ロードバランサーです。今回GKE(Google Kubernetes Engine)クラスタを新規で構築し、後述する「アイテム推薦API」及び「ZOZO研究所API」のサーバーをGKEクラスタのPod上で稼働させています。このGKEクラスタはプライベートネットワーク内に閉じているため、GKEクラスタの受け口にL7内部負荷分散を立てる必要がありました。GKEのバージョン1.16.5-gke.10からGCPのL7内部負荷分散に対応したIngress for Internal HTTP(S) Load Balancingが使用できるようになったので、今回初めて採用しました。
アイテム推薦API
アイテム推薦APIはZOZOTOWNバックエンドAPIからInternal Load Balancer経由で届いたリクエストに対して、最終的な推薦結果となるアイテムをリストで返すAPIサーバーです。ZOZOTOWNバックエンドAPIから届くリクエストのパラメータには閲覧しているアイテムの情報とユーザの情報、推薦結果として取得したいアイテムの件数が含まれています。Java製フレームワークSpring Bootを用いて作られており、GKEのPod上で稼働しています。
ZOZO研究所API
ZOZO研究所が開発した推薦ロジックを用いた推論用のAPIサーバです。アイテム推薦APIからきたリクエストに対してそのアイテムの詳細ページの「おすすめアイテム」枠に最適なアイテムを推論し、アイテムIDのリストを返します。Python製フレームワークのFlaskを用いて作られており、GKEのPod上で稼働しています。
Recommendations AI API
GCPのRecommendations AI上で構築したアイテム推薦の推薦ロジックの機械学習モデルによる推論を行うWeb APIです。ZOZO研究所API同様、アイテム推薦APIからきたリクエストに対して推論したアイテムIDのリストを返します。
アイテムデータベース
ZOZOTOWNの最新のアイテム情報のデータが格納されているデータベースで、GCPのフルマネージドな大規模分散データベースであるCloud Bigtableを使用しています。Cloud Pub/Sub経由で送られてくるアイテムのデータの更新情報がリアルタイムで反映されるので、常に最新のアイテムデータが格納されています。
アイテム情報キャッシュ
GCPのフルマネージドなRedisサービスを利用しています。Bigtableへの負荷軽減のためにアイテム推薦APIがBigtableから取得したアイテムの情報は一定期間Redisにキャッシュさせています。
新しい推薦システムで工夫したポイント
以下、工夫した点についていくつか紹介します。
Bigtableのパフォーマンス改善
ZOZOTOWNの最新のアイテムの情報を格納しておくデータベースとして以下の要件から高スループットかつ低レイテンシーなGCPのCloud Bigtableを採用しました。
- 大量の書き込みに耐えられる
- 高速な応答性能を持つ推薦システムを実現できる
しかし、実際にアイテム推薦APIからBigtableへアクセスしてみると期待通りの応答性能が出なかったため、パフォーマンスチューニングを行い応答性能を改善しました。ここでは、実際に行ったチューニング方法について説明します。
前提として、アイテム推薦APIは以下のような実装となっていました。
- アイテム推薦APIではJava製のBigtableクライアントライブラリbigtable-hbase-2.xのバージョン1.12.0を使用しています。
- アイテム推薦APIからBigtableへのアクセスは全て
Multi-Getという参照系の操作です。
調査したところ、上記のBigtableクライアントライブラリによるBigtableへのアクセスエラー発生時のリトライ処理は以下のような挙動をしていることが分かりました。
- BIGTABLE_RPC_TIMEOUT_MS_KEYで設定されたタイムアウト時間(ミリ秒)を迎えるまでリトライ処理を繰り返す。
- 参照系処理の場合はタイムアウト後にMAX_SCAN_TIMEOUT_RETRIESの回数だけ更にリトライ処理が走る。なお、ドキュメントに記載は見当たりませんが、実装を確認するとscanだけではなくgetの処理においてもMAX_SCAN_TIMEOUT_RETRIESの回数分リトライ処理が走ることが分かっています。
今回、アイテム推薦システムのタイムアウト時間の要件は5秒であったため、元々の設定であった設定値Aとタイムアウト時間を減らしてその分タイムアウト後のリトライ回数を増やした設定値B、2つの設定値でアイテム推薦APIに負荷をかけてBigtableへのアクセス時の応答性能を測定しました。

実験の結果、設定値Bの応答速度は設定値Aに比べて99パーセンタイル値の比較で平均約29%速いことが分かりました。つまり、応答が想定時間で返ってこない場合はそのまま待つよりも再度リクエストを投げた方がより速く応答を返しやすいようです。
以上の結果を踏まえてBの設定値となるように更新し、パフォーマンスを改善できました。
アイテム推薦APIのPodの安全停止
アイテム推薦APIのデプロイ時にPodがローリングアップデートされた際、Ingress for Internal HTTP(S) Load Balancing(以下、Ingress)でステータスコード503のエラーが出る事象が発生しました。調査したところ、原因はGKEのIngressのコネクションドレインのタイムアウト時間がデフォルトの0秒であったためコネクションドレインが機能せずリクエスト処理の途中でコネクションが切られてしまっていたからでした。そこで、適切なコネクションドレインのタイムアウト時間を設定したのですが、ここではその設定の際に考えたことについて説明します。
PodがIngressから登録解除されて停止する際にPodではpreStopフックの実行処理が、Ingressではコネクションドレインの処理が同時に非同期で実行されます。そして、PodではpreStopフックの実行終了後にコンテナのルートプロセスに対してSIGTERMが送られ、サーバーがGraceful Shutdownされます。実際に計測してみるとアイテム推薦APIのpreStopフックの処理が始まって10〜15秒後にコネクションドレインの処理が始まっていることが分かりました。そのため、まずはpreStopフックでは15秒のsleep処理を走らすことで、PodがIngressから登録解除されてコネクションドレイン処理開始する前にサーバーのGraceful Shutdownが始まらないように調整しました。また、サーバーのGraceful Shutdownに要する時間は約20秒だったので、この場合のコネクションドレインのタイムアウト時間はPodのpreStopフックの開始から正常にGraceful Shutdownされるまでの時間である(15秒+20秒=)35秒以上に設定すべきであることが分かります。実際には少し余裕を持ってコネクションドレインのタイムアウト時間として45秒を設定しました。
ZOZO研究所APIのキャッシュ戦略
ZOZO研究所APIに対して負荷試験を行ったところ、クエリとなるアイテムIDによって応答速度に大きなばらつきがあり、CPUスパイクも頻繁に起こしていました。
調査したところ、以下のことが判明しました。
- 推薦ロジックのアルゴリズムの性質上、アイテム詳細ページのアクセス数が多いアイテムほど推論の計算コストが高くなるため、推論速度が遅い。
- アイテム詳細ページのアクセス数はアイテム毎に大きな偏りがある。
上記の特性を踏まえて、アクセス数上位のアイテムに関しては推論結果をキャッシュするようにしました。ZOZO研究所APIのPod起動時に推論を行い、サーバーのメモリ上に推論結果を展開しています。キャッシュしたアイテムの数は総アイテム数のわずか0.2%ですが、システムパフォーマンスが大幅に向上し、観測されていたCPUスパイクも起きなくなり安定化できました。
推薦ロジックのモデル更新時のワークフロー
ZOZO研究所製の推薦ロジックに使用するモデルの更新は毎日1回行われています。
ここでは、そのモデル更新時のワークフローを解説したいと思います。以下が、そのワークフローの概略図です。

Cloud ComposerとBigQueryで日次集計された最新のアイテムデータを読み込み、Pythonスクリプトによって推薦ロジックのモデルファイルを生成します。この日次集計処理は今回のプロジェクト以前から運用されていて、かつ、異なるGCPプロジェクトで存在していました。そのため集計完了の通知をCloud Pub/Subで受け取るようにし、本プロジェクトのモデルファイル生成Jobを実行するトリガーとしています。Cloud RunはCloud Pub/Subからメッセージを受け取りGKEのJobを実行するトリガーとしてのみ利用しています。なお、Cloud Run・GKEのJobの選定に関しては後述します。
モデル更新時の流れを図の番号に対応する手順で説明します。
- Cloud Composerの日次集計で最新のアイテムデータをBigQueryに保存後、集計完了を意味するメッセージをCloud Pub/Subにパブリッシュします。
- Cloud Pub/SubはCloud Composerから飛んできたメッセージをトリガーにCloud Runのエンドポイントを叩きます。
- Cloud Runのエンドポイントが叩かれるとCloud Runではモデル作成用のPythonスクリプトを実行するGKEのJobをアイテム推薦APIと同じGKEクラスタ上で作成します。Cloud RunではGoで書かれたAPIサーバが動いており、そのAPIサーバのエンドポイントが叩かれるとモデル作成用のPythonスクリプトを実行するJobをアイテム推薦APIと同じGKEクラスタ上に作成します。Goの選定理由はKubernetes APIアクセス時に使用するGo言語用のKubernetesクライアントライブラリclient-goが他の言語用のクライアントライブラリに比べて開発が活発で継続的にメンテナンスされることが期待できるためです。
- GKEのJobではモデル構築用のPythonスクリプトを実行してBigQueryから最新のアイテムデータを読み込んでモデルファイルを作成し、Cloud Storageにアップロードします。
- GKEのJobはCloud Storageにモデルファイルをアップロード後、最後にZOZO研究所APIのPodを
kubectl rollout restartコマンドによって再起動させて処理が終了します。 - ZOZO研究所APIのPodは再起動時に新しいモデルファイルをCloud Storageからダウンロードし、推論時にそのモデルを使用するようになります。
推薦ロジックのモデル更新時のワークフローで工夫したポイント
以下、推薦ロジックのモデル更新時のワークフローで工夫した点についていくつか紹介します。
Cloud Runの選定
前述の通り、既存のCloud Composerとは別のGCPプロジェクトでモデル更新のジョブを実行する必要がありました。そこで、Cloud Composerの日次集計のワークフローの最後にCloud Pub/Subへ通知を送り、その通知をトリガーに別のGCPプロジェクトでモデル更新のジョブを実行する設計としました。
1日1回Cloud Pub/SubからくるPOSTリクエストをトリガーにワークロードを実行する用途として、リクエストが実際に処理されている時間のみ課金が発生する以下の3つのサーバレスソリューションを検討しました。
ただし、現在弊チームではAnthos環境を運用していないので、Cloud Runの場合はCloud Run for Anthos on Google Cloudではなくフルマネージド版のCloud Runのみに限ります。
また、これらのメモリの上限値は以下の通りです。
| App Engine(スタンダード環境) | Cloud Functions | Cloud Run(フルマネージド) | |
|---|---|---|---|
| メモリ上限 | 2Gi | 2Gi | 4Gi |
モデル更新ジョブのメモリ消費量は上記のどのソリューションにおいてもそのメモリ上限値を超えてしまうので、モデル更新処理をそれだけで完結することはできません。そこで、モデル更新ジョブをアイテム推薦APIのPodなどが稼働しているGKEクラスタ内のハイメモリなインスタンス上でKubernetes Jobとして実行することにし、そのJobの作成処理を上記のサーバレスソリューションのいずれかで実行することにしました。理想を言うと、Cloud Pub/Subへの通知をトリガーとして直接GKEのJobを作成できるようなソリューションがあったら嬉しいですね。
検討の末、他の2つに比べてワークロードのランタイムに縛りがなく、Dockerfileで管理できる開発のしやすさの点で優れたCloud Runをチームで今回初めて採用しました。また、Cloud Runでは、Cloud Pub/Subからきたリクエストのトークン認証処理を組み込みでサポートしているので、簡単な設定でCloud Pub/SubとCloud Run間を安全に通信することができます。GCPの公式ドキュメントには記載が見当たりませんでしたが、Cloud RunとCloud Pub/Subが異なるGCPプロジェクトに存在しているケースでもトークン認証処理を利用することができます。便利。
Cloud Pub/Subのat-least-once配信の考慮
Cloud Pub/Subはat-least-once配信方式を採用しているため、同一のメッセージが複数回配信される可能性があります。そのため、たとえCloud ComposerからCloud Pub/Subへのメッセージのパブリッシュは1日1件であっても、そのメッセージが複数回配信されてCloud Runのエンドポイントが1日に複数回叩かれてしまう場合を考慮しないといけません。
まず、Cloud Runで日に複数回GKEのJobの作成処理が実行される可能性があるため、GKEのJobの処理が冪等である必要があります。今回GKEのJobで実行するモデル作成処理は冪等であるため、この要件は満たしていました。
また、Cloud RunによるGKEのリソースへの操作が並列で行われる可能性も考慮する必要があります。Cloud Runの処理ではGKEのJobを作成するためにKubernetes APIを使ってGKEのリソースを操作します。実際の処理ではJobの作成処理だけでなく、昨日分のJobの設定をクリーンアップしたりJob作成時に立ち上がったPodの情報を取得したりと、Cloud Runのエンドポイントへのリクエスト毎に複数回Kubernetes APIへのアクセスが発生します。もしCloud Pub/Subからほぼ同時に複数のリクエストがきた場合、これらのKubernetes APIへの操作が並列で実行されるため、Jobの作成処理が同時に2度実行されてしまい片方の処理がエラーになるといった問題に繋がる可能性があります。一方で、Kubernetes APIを使った操作は非同期なこともあり、このようなエッジケースにも対応した並行性制御を実装するのはなかなか大変です。そこで、複数リクエストが同時にきてもCloud Runではリクエストを並列では処理しないようにすることでGKEのリソースへの一連の操作を排他制御するようにしました。具体的には、Cloud Runではコンテナあたりの最大同時リクエスト数とスケールアウト時の最大コンテナインスタンス数を簡単に設定できるので、どちらも最大値を1とすることで複数リクエストを並列で処理しないようにしました。
Cloud Monitoringを使用したGKE Jobの監視設定
GKEのJobの監視を導入時にいくつか躓いた点があるので、それらの点も踏まえてどのような設定をしたのかをここでは説明したいと思います。
以下の2種類の監視が現在設定されています。
- JobのPodステータスがFailedになった時のアラート設定
- 長時間経ってもJobのPodステータスがSucceededにならない時のアラート設定
JobのPodステータスがFailedになった時のアラート設定
当初はJobが異常終了した時、すなわち、Jobが作成したPodのステータスがFailedとなった時にアラートが鳴るようにCloud Monitoringで監視を導入しようと試みました。しかし、Cloud MonitoringではPodのFailedステータスを直接カウントしアラートのトリガーとするような設定方法はサポートされておりませんでした。そこで、代わりにPod内のコンテナの再起動回数であるrestart countをトリガーに使用できることを利用し、Pod内のコンテナの異常終了後の再起動処理が発生(restart count > 0)したらアラートが鳴るように設定しました。ただし、このやり方は以下の点において理想的な監視とは言えない妥協策です。
- JobのrestartPolicyがOnFailureに設定されている場合においてのみ使える方法である
- Podの失敗ステータスを直接監視できておらず、間接的な監視となってしまっている
もっと適切な方法ご存知の方いましたら教えてください!
長時間経過してもJobのPodステータスがSucceededにならない時のアラート設定
Jobが失敗した時の監視だけでは以下のような異常時のケースを拾うことができません。
- そもそもJobが実行されていない場合
- Jobの処理途中になんらかの理由でスタックしている場合
上記のケースが発生した際にアラートが飛ぶように、日次で実行されるJobがその日のうちに正常終了していない時にアラートがなるような監視も導入しました。しかし、Cloud MonitoringではPodのFailedステータスと同様Succeededステータスを直接カウントしアラートのトリガーとするような設定方法もサポートされておりませんでした。また、Cloud Monitoringでは24時間周期の監視もサポートされていませんでした。そこで、妥協策として以下の手順で監視を設定しました。
- Jobの処理の最後にJobの成功を意味するログをコンテナログとして出力するようにする。
- GKEのCronJobで毎日定時に直近24時間でCloud Loggingへ出力されたJobのコンテナログからJobの成功を意味するログを検索する。もし成功ログが見つからなかった場合は、エラーログをCronJobのコンテナログに吐くようにする。
- Cloud MonitoringでCronJobが吐いたエラーログをトリガーとしてアラートを鳴らすように設定する。
このやり方もPodの成功ステータスを直接監視できていない複雑な設計となってしまっています。もっと適切な方法ご存知の方いましたら教えてください!(2回目)
まとめ
本記事ではZOZOTOWNの「おすすめアイテム」枠に使われている新しい推薦システム基盤のアーキテクチャについて解説しました。私が今年入社して最初に取り組んだプロジェクトでしたが、ネットワーク設計から任せてもらい、個人的に思い入れの深いプロジェクトです。ユーザの皆さんが気に入るアイテムをより簡単に見つけやすくできるように引き続き改善に取り組んでいきます。
最後に
SRE部MLOpsチームでは、データや機械学習を用いてサービスを成長させたいエンジニアを募集しています。ご興味のある方は、以下のリンクからぜひご応募ください!