



はじめに
こんにちは。SRE部 ECプラットフォームSREチームの大澤です。
先日、SREチームにてBFF機能を司る「ZOZO Aggregation API」の導入について紹介しました。
BFFは複数のバックエンドと通信するアーキテクチャであるため、通信先のバックエンド障害に大きな影響を受けてしまいます。そのため、ZOZO Aggregation APIでは、各バックエンド間の通信障害をIstioによるタイムアウトとリトライ制御で可用性を担保していました。
今回は、新たにIstioサーキットブレーカーを導入することで、さらなる安定性・回復性の向上を果たした取り組みを紹介します。
サーキットブレーカーとは
サーキットブレーカーとは、あるサービスの障害を検知した場合には通信を遮断、その後サービスの復旧を検知すると通信を復旧させる仕組みです。
複数のマイクロサービスが連動するサービスの場合、一部のマイクロサービスの障害が連鎖的な障害に繋がるカスケード障害を発生させる可能性があります。
以下はカスケード障害の例です。Service Cが応答不能となると、Servie BはService Cからのレスポンスを待ち続けるため、不安定な状態となります。この状況が続くとService Bが応答不能となり、連動するService Aへと障害が連鎖します。
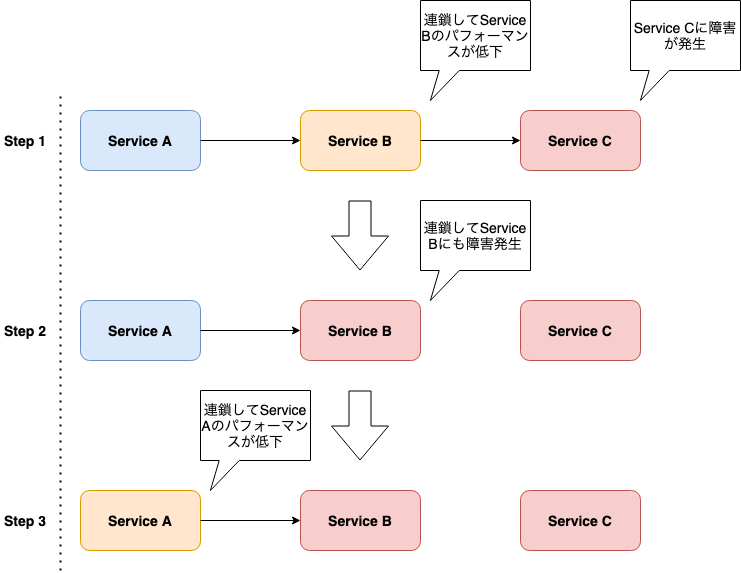
サーキットブレーカーは、このようなマイクロサービスアーキテクチャ特有の課題に対するデザインパターンの1つです。
以下の図は、先程の例にサーキットブレーカーを導入した場合の流れです。Service Cで発生した障害を検知するとServie Bはリクエストを遮断します。リクエストを遮断することでレスポンスを待ち続ける状況やスレッドプールの枯渇を防ぎ、Service Bと連動するService Aを保護します。

サーキットブレーカーパターンの詳細についてはこちらを参照ください。 docs.microsoft.com
ここで紹介した例は非常にシンプルなカスケード障害の場合ですが、ZOZOTOWNのプラットフォーム基盤はマイクロサービスアーキテクチャを採用しており、より複雑なサービス間連携が発生しています。そのため、連鎖による大規模な障害に発展しないよう、カスケード障害への対策の必要性が増していました。
既存のタイムアウト・リトライ制御の問題点
ZOZO Aggregation APIでは、Istioによるタイムアウト・リトライ制御設定を通信先のバックエンド毎に入れています。設定したタイムアウト・リトライ試行内でバックエンドからレスポンスが得られない場合には、それ以外のバックエンドから取得できたモジュールのみでレスポンスし、サービスを継続しています。

以下の図は、リトライでサービスを救える場合の処理の流れの例です。商品詳細API呼出処理は、リトライを含めて130msで完了しています。

この様に、すぐに復旧が見込まれる様な一時的なネットワークの瞬断などの不具合であれば、リトライ機能により適切にサービスを救うことができます。
しかし、バックエンドとの通信のエラー状況によってはタイムアウト・リトライ制御が必ずしも適切に働くわけではありません。通信先のバックエンドが不安定になって直ちにエラーが返ってこない場合、Istioによるタイムアウトまでバックエンドからのレスポンスを待つことになります。
以下の例は、Istioで10sのタイムアウト、かつ1回のリトライを設定していた場合です。最終的に商品詳細API呼出処理は20s待つことになります。ZOZO Aggregation APIとしては、該当のAPI以外のバックエンドから取得したモジュールで正常ステータスを返却できます。ただし商品詳細APIの回復までレイテンシーは増加し続けてしまいます。

この様なレイテンシーの増加を防ぐために、異常なバックエンドをサービスアウトし、ZOZO Aggregation APIからリクエストしない状態にするのが理想的です。
以下の例はサーキットブレーカーを導入した場合に期待される動作例です。商品詳細APIに障害が発生している場合、API呼出を行わずに処理を完了できます。

この様に障害を検知し、リクエストを遮断するサーキットブレーカーは有効な手段です。
サーキットブレーカーの導入方法
サーキットブレーカーを導入するには、大きく分けて以下の2つのアプローチが考えられます。
- 各マイクロサービスにサーキットブレーカーが実装されたライブラリを組み込むアプローチ
- Istioやnginxのサービスメッシュなど、ネットワーク機能として導入するアプローチ
弊社は後者のアプローチを採用しました。なぜIstioサービスメッシュによる導入を選択したのか、どのようにZOZO Aggregation APIにサーキットブレーカーを導入していったのかを本章で紹介します。
Istioサーキットブレーカーを導入した理由
サーキットブレーカーが実装されたライブラリを各マイクロサービスに組み込んでいく場合、以下の課題がありました。
- マイクロサービスへの組込やアップグレードの際に、アプリケーション開発者とSRE間でコミュニケーションが多く発生し、コミュニケーションコストが増加する
- マイクロサービス毎に異なるアーキテクチャー・言語を採用しているため、ライブラリ・組込方法も異なり一貫性の担保が困難になる
こういった点を考慮し、SREチームでは以下の理由でIstioサービスメッシュによるアプローチを選択しました。
- アプリケーションコードを変更する必要がなく、インフラコードの改修のみでサーキットブレーカーの機能追加が実現でき、かつサービスメッシュ全体で一貫した制御が可能
- 既にマイクロサービスプラットフォーム基盤にIstioサービスメッシュを活用していたので、サーキットブレーカー導入の敷居が低い
- Istioサーキットブレーカーは、外れ値検出(エラー検出)だけではなく、接続要求(接続数上限など)によるサーキットブレーカーも提供しており機能要件に適していた
Istioサーキットブレーカーの組込
Istioサーキットブレーカーの設定項目の理解は、サーキットブレーカー自体の振る舞いを把握しているとより容易になります。
そのため、まずはサーキットブレーカーパターンの動作原理を説明します。
サーキットブレーカーは動作原理として以下の状態を持ちます。
- Closed
- 遮断機がOFFの状態
- リモートのサービスにリクエストを要求可能となる
- リクエストが失敗した場合、エラー数をカウントし、エラー数が閾値に達するとOpen状態へと移行する
- Open
- 遮断機がONの状態
- リモートのサービスへのリクエストは直ちに失敗となる
- Open状態へ遷移した時間をカウントし、時間経過カウントが閾値に達するとHalf Open状態へ移行する
- Half Open
- 障害が解決したか確認する状態
- リモートのサービスに少数の限られたリクエストを要求可能となる
- リクエストが成功した場合にはエラーカウントをリセットしClosed状態へ、リクエストが失敗した場合にはOpen状態へと移行する

また、外れ値検出によるIstioサーキットブレーカーの組込は、カスタムリソースであるDestinationRuleへOutlierDetectionを設定することで実現できます。
以下のサンプルコードは、外れ値検出による基本的なサーキットブレーカーを組込む場合の例です。
apiVersion: networking.Istio.io/v1beta1 kind: DestinationRule metadata: name: test-api spec: host: test-api.test-api.svc.cluster.local trafficPolicy: outlierDetection: consecutive5xxErrors: 10 interval: 10s baseEjectionTime: 1m
OutlierDetectionの設定項目は以下の通りです。
| 設定項目 | 説明 |
|---|---|
| consecutive5xxErrors | Open状態に遷移する5xxエラー閾値 |
| interval | 5xxエラー検出の間隔 |
| baseEjectionTime | Open状態からHalf Open状態に移行する時間 |
Istioサーキットブレーカーには、上記以外にも様々な設定値が存在します。詳細はDestinationRuleの公式リファレンスをご参照ください。 istio.io
上記のサンプルの設定では「10秒間で10回の5xxエラーを検知すると、1分間Open状態とするサーキットブレーカー」として動作します。
よって、ZOZO Aggregation APIへのサーキットブレーカー組込は、既存のDestinationRuleにOutlierDetectionを設定するのみです。ただし、サーキットブレーカーを適切に稼働させるためにはバックエンドをOpen状態へ遷移させるための閾値を決定する必要があります。
閾値の決定
閾値を決めるには、以下の2つのアプローチがあります。

- クライアント側のサービス要件で閾値を決める
Service Aは1sに、1回のエラー発生でService Dへのリクエスト前に遮断したいService Bは1sに、2回のエラー発生でService Dへのリクエスト前に遮断したいService Cは1sに、3回のエラー発生でService Dへのリクエスト前に遮断したい
- リモート側のサービス要件で閾値を決める
Service Dは1sに、4回のエラー発生で受付けるリクエストを遮断したい
以下に示すのは、クライアント側の要件で閾値を設定する場合の例です。DestinationRuleのサンプル同様に、どのサービスからのリクエストであるのかを個別に定義する必要があります。
apiVersion: networking.Istio.io/v1beta1 kind: DestinationRule metadata: name: service-d-api spec: host: service-d-api.service-d-api.svc.cluster.local # Service AからService Dへの設定 - name: service-a-api-to-service-d-api trafficPolicy: outlierDetection: consecutive5xxErrors: 1 interval: 1s baseEjectionTime: 1m # Service BからService Dへの設定 - name: service-b-api-to-service-d-api trafficPolicy: outlierDetection: consecutive5xxErrors: 2 interval: 1s baseEjectionTime: 1m # Service CからService Dへの設定 - name: service-c-api-to-service-d-api trafficPolicy: outlierDetection: consecutive5xxErrors: 3 interval: 1s baseEjectionTime: 1m
SREチームではZOZOTOWNのセールなどのイベントに合わせて随時Pod数を調節しています。仮にService Dの管理者がPod数を2倍にした場合、Service A〜Cの管理者は個別にエラー閾値を調節しなければならず、運用が複雑になります。また、本記事では省略していますが、VirtualServiceにも同様に、どのサービスからのどのサービスへのルーティングであるか個別に定義する必要があり、複雑さがさらに増します。
そのため、SREチームではリモート側のサービス要件で閾値を決定する方法を採用しました。
サーキットブレーカー導入の効果
安定性・回復性向上のために導入したサーキットブレーカーですが、そのような機能が実際に使われることなく安定してサービスが運用されることが望ましいです。
幸いにもサーキットブレーカー導入後、実際の障害によってサーキットブレーカーが発動されたことはありません。そのため、今回は開発環境に用意したmockアプリで、擬似的に障害状態を再現した事例を紹介します。
以下の図は、サーキットブレーカー導入前のアプリケーショントレーシングの結果です。バックエンドサービスAPIのタイムアウトに影響を受け、ZOZO Aggregation APIのレイテンシーが増加していることが確認できます。

一方、以下の図は、サーキットブレーカー導入後のアプリケーショントレーシングの結果です。サーキットブレーカーによりバックエンドサービスAPIへのリクエストが直ちに遮断されていることが確認できます。また、サーキットブレーカー導入前にはバックエンドサービスAPIのパフォーマンス劣化の影響を受け、9.08sで返却していたレスポンスタイムが136msへ改善していることも確認できます。

サーキットブレーカー導入後の課題
サーキットブレーカーを導入したことにより回復性は高まりました。しかし、バックエンドが障害から復旧したと判断する時間設定によっては、サービス復旧までにタイムラグが生じてしまいます。ユーザ体験を損なわないためにも、「全てのモジュール情報が揃った正しいレスポンス」をタイムラグなく返却することが重要です。障害のパターンは様々なため、運用しながら最適値を見極めていく必要があります。
また、現状はサーキットブレーカーによって通信がOpen状態へ移行したことを検出しておらず、バックエンド自体のサービス稼働状況で通信状況が問題ないか判断しています。もし、通信がOpen状態に移行したことを検知できれば早期にサービス稼働状況が危険な状態であることを発見できるため、サーキットブレーカー検出も今後導入していく予定です。
まとめ
本記事では、Istioサーキットブレーカー導入の事例を紹介しました。本記事により、サーキットブレーカーの有効性、Istioサービスメッシュ環境下であれば簡単に導入可能であることをご理解いただけたら幸いです。また新たな知見が得られた際には、紹介したいと思います。
さいごに
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。