



はじめに
こんにちは、検索基盤部 検索基盤チームの可児(@KanixT)です。以前は通勤に片道2時間ほどかかっていましたが、フルリモートワークの環境になり空いた時間で生後4か月の娘の子育てに奮闘中です。
本記事では、検索基盤チームが取り組んだZOZOTOWN検索機能のマイクロサービス化の事例・工夫点を紹介します。これから検索機能のマイクロサービス化にチャレンジする方の参考になれば幸いです。
目次
背景と課題
ZOZOTOWNでは、ASPからJavaへのリプレイスプロジェクトが数年前より実施されており、これまで多くのAPIを改善・改修してきました。一方、そのリプレイスされた環境には、1つのマイクロサービスに非常に多数のAPIが存在している状態にもなっていました。検索基盤チームが管理する検索APIも、このマイクロサービス(以下、既存マイクロサービス)の中にありました。
既存マイクロサービスは別チームが主管のため、機能追加や改修の際は別チームにレビュー・リリース依頼をしていました。
そのため、改修した内容のマージや、リリースのタイミング等を検索基盤チームが自由にハンドリングできない状態でした。また、把握していないAPIや共通処理等も多数ある状況故に、開発難度が高くなってしまうという課題もありました。
既存マイクロサービスはSQL ServerとElasticsearchを参照しており、1つのマイクロサービスとしては責任が大きく、障害発生時は複数チームが原因特定に動く状態でした。そのため、「リクエスト数が非常に多い検索機能に特化したElasticsearchのみを参照するマイクロサービス」を構築したいという思いがありました。
検索機能に特化したマイクロサービスの構築
検索基盤チームが主管である検索APIのみのマイクロサービスを構築することで、別チームへの依頼事項は無くなり、精通したAPIの開発に集中できます。そのため、開発・改修・リリースに掛かるサイクルの短縮が見込まれます。また、チャレンジングな実装の場合でも、スムーズな意思決定が可能となると考えました。
そこで既存マイクロサービスから検索APIを切り出し、検索機能に特化したマイクロサービスを構築するに際し、下記の目的を定めました。
- 開発速度を向上させる
- 検索機能に特化したマイクロサービスを開発する
- バックエンドはElasticsearchのみとする
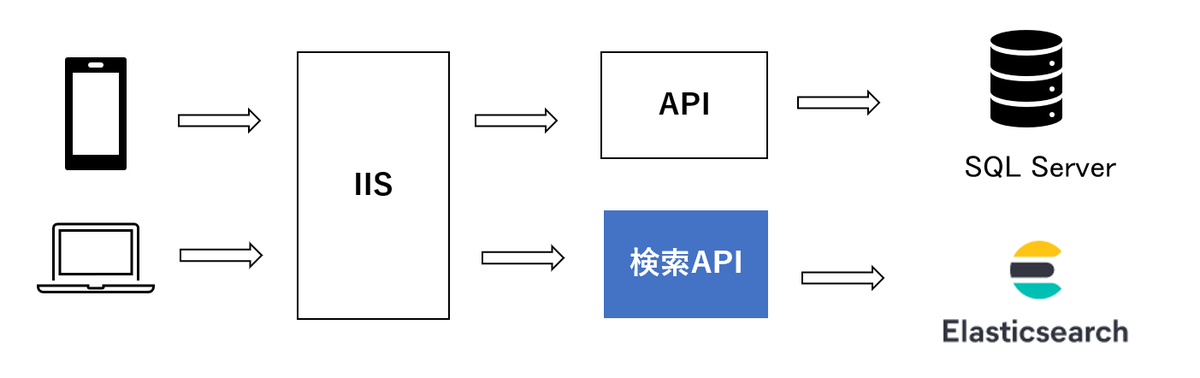
既存マイクロサービスから検索APIを切り出すイメージは下図の通りです。この図はZOZOTOWNのシステム概要図であり、青色の部分が今回構築した検索機能のマイクロサービスです。なお、詳細は一部省略しています。
既存マイクロサービス

検索機能のマイクロサービス実装後
検索APIで利用する技術スタックは以下の表の通りです。
| 技術スタック | |
|---|---|
| 言語 | Java |
| フレームワーク | Spring Boot |
| データベース | Elasticsearch |
どのように構築したか
分割する方針はいろいろと考えられますが、下記の2案で検討しました。
既存マイクロサービスのリポジトリをコピーする
既存のリポジトリを丸々コピーした別のマイクロサービスを構築し、検索機能のリクエストのみを受け付け、不要なAPIは後々消す方式。
- メリット
- リポジトリをコピーするため少ない作業量で短期間の本番リリースが可能
- デメリット
- 不要なAPIのコードが丸々残る
- SQL Serverの参照が残る
- 古くなっているライブラリ等もそのまま残る
- メリット
既存マイクロサービスから検索APIのみを切り出す
検索APIのコードのみをコピー・リファクタリングし、別のマイクロサービスを構築する方式。
- メリット
- 検索APIのみのマイクロサービスが構築できる
- Elasticsearchのみの参照にできる
- コードのコピー・リファクタリングのタイミングで各種のバージョンアップが可能
- デメリット
- 1のパターンより作業量が多い
- メリット
検討の結果、2. の方針を採用し、検索機能に特化したマイクロサービスを構築することにしました。
選定の主な理由は、2. は 1. より実装コストがかかりますが、このタイミングで不要なAPIを取り除いたマイクロサービスを構築することで負債を抱えずに今後の検索機能の開発に集中できると考えたためです。また、このタイミングで、各種バージョンアップや不要なライブラリを削除することでアプリケーション全体の整理整頓ができるメリットもありました。
構築時にやったこと
APIの実装
既存マイクロサービスを分割して切り出す対象となるAPIは全部で4本でした。
一からすべてのコードを書き直す余裕はなかったため、既存マイクロサービスの検索APIのコードを移植し、必要に応じて部分的に再実装しました。その際、ユニットテストが十分に書いてあったおかげで安心して移植と再実装ができました。ユニットテストを書くことは安定した品質につながり、コードを変更する作業が非常に容易になると再認識できる良い経験でした。
静的解析
コードの静的解析ツールとしてSonarCloudを利用し、コードの状態を可視化しています。チームの取り組みとして、ユニットテストガイドラインを作成し、テストカバレッジを毎週確認することで、コードの品質を保つようにしています。
また、GitHubリポジトリへのPull Request単位でユニットテストのカバレッジが確認できるため、レビュー依頼時には開発者自身でテスト不足がないかを確認してもらうようにしています。
なお、現在のカバレッジは86%です。
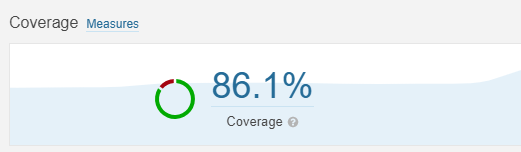
この程度のカバレッジになると、実装時にはユニットテストを書くことが当たり前になっているため、「テストを書くこと」が浸透していると実感できます。1
ヘルスチェックの実装
アプリケーションのヘルスチェックにSpring Boot ActuatorのElasticsearch用ヘルスチェックの利用を検討しました。Actuatorは単一のElasticsearchエンドポイントのみに対応しており、複数エンドポイントで運用している弊社には対応できないため独自のヘルスチェックを実装しました。
複数エンドポイントのヘルスチェック
ヘルスチェックの独自実装の方法は非常に単純で、各Elasticsearchエンドポイントに対してindexの存在有無を確認するAPIを実装しました。indexの確認方法は次の通りです。
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
ElasticsearchのIndex Exists APIより引用
単一エンドポイントのヘルスチェック
複数エンドポイントに比べ、単一のElasticsearchヘルスチェックを行う場合はさらに簡単で、実装は不要で設定のみで実現できます。
まず、pom.xmlに依存関係を追加します。なお、以下に示すXMLはビルドツールにMavenを利用している場合の例です。
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> </dependencies>
次に、Elasticsearchに対するヘルスチェックを有効にします。Spring Boot Actuatorの公式ドキュメントも併せてご覧ください。
management: health: elasticsearch: enabled: true
Java(Spring Boot)とElasticsearchを組み合わせたアプリケーションの運用ノウハウにご興味ある方は、こちらの記事も是非ご覧ください。 techblog.zozo.com
各種バージョンアップ
検索機能のマイクロサービス化の際に行った大きなバージョンアップ作業は、JavaとSwaggerのバージョンアップです。なおバージョンアップ後のバージョンは非公表とさせていただきます。
| 対象 | バージョンアップ前 |
|---|---|
| Java | 8 |
| Swagger | 2.x |
Java
バージョンアップに伴うコード修正はなく、スムーズにバージョンアップできました。しかし、GCをCMSからG1へ変更したため負荷テストとメモリサイズのチューニングを実施しました。
Swagger
Swagger 2.xは古くなっていたため、RESTful APIの標準規格と言われるOpen APIへ変更しました。また、今までは非常に大きな1つのyamlファイルに定義が集約されており、開発し辛い状況でした。そのため、yamlファイルを分割し開発をやり易くしました。
OSSのライセンスチェック
アプリケーション内では様々なライブラリを利用しているため、OSSライセンスのチェックを行いました。ここでは、そのチェック方法を紹介します。
具体的には、Spring Bootの依存関係からライセンスの一覧を作成し、各ライブラリのライセンスが社内のOSS利用ガイドラインを順守しているかを目視で確認していきました。なお、OSS利用ガイドラインに関する情報は以下の記事に書かれています。 techblog.zozo.com
ライセンス一覧は下記コマンドで出力できます。
$ mvn license:add-third-party -D license.excludedScopes=test $ cat ./target/generated-sources/license/THIRD-PARTY.txt | sort > license.txt
参考:License Maven Plugin license:add-third-party
依存関係も把握しておきたい場合、下記コマンドで出力できます。
$ mvn dependency:tree > dependency_tree.txt
外部サービス
運用・監視には下記の外部サービスを活用しています。どのサービスも運用・監視にはなくてはならないサービスです。個別の説明は省きますので、各社のWebページをご参照ください。
- Datadog
- マイクロサービスのモニタリングとアラート検知
- Sentry
- エラー通知
- SonarCloud
- コードの静的解析
- PagerDuty
- インシデントのオンコール通知
リリース
すでに本番稼働しているAPIなので、リクエスト先の切り替えは慎重に実施しました。当然のことですが、通常の開発案件も平行で動いているため、それらの開発案件のリリースの合間をみて検索機能のマイクロサービスをリリースしていきました。
リリース時にやったこと
- 既存マイクロサービスの検索APIと新APIでの比較テスト
- 同一のリクエストをそれぞれのAPIへリクエストし、同等の結果が得られることを確認する
- 既存マイクロサービスの開発案件の差分取込
- 毎週担当者を決めて差分をウォッチし、検索機能に関係する差分がある場合は内容を確認してコードの差分を取り込む
- カナリアリリース
- 検索APIは非常に大量のリクエストを受けるため、1度に全リクエストの切り替えず、カナリアリリースで段階的に切替える
カナリアリリースについてご興味ある方は、こちらの記事も是非ご覧ください。 techblog.zozo.com
得られた効果
検索機能に特化したマイクロサービスを構築することで、前述の下記の目的が達成できたかを検証してみます。
- 開発速度の向上
- 検索機能に特化したマイクロサービスの開発
開発速度の向上
定量的な測定ができていないため、定性的な評価になってしまいますが、自チームでハンドリングできるマイクロサービスは意思決定が早く、開発作業のスピードは確実に上がっていると感じています。
機能の開発だけでは無く、開発がやり易くなるような改善やリファクタリングもチームメンバーが自発的に実施しているため、チームの気持ちのこもったマイクロサービスへと着々と進化しています。
検索機能に特化したマイクロサービスの開発
本番リリース後はプログラム起因による障害は無く、ZOZOTOWNの検索機能のリクエストを日々安定して処理できています。データベースはSQL Serverを参照することは無く、Elasticsearchのみを参照しており、パフォーマンスとアーキテクチャの両面で想定通りのマイクロサービスが構築できました。
なお、既存マイクロサービスの一部APIでは、まだElasticsearchを参照しているため、完全に目的を達成したとは言えないところが残念ではあります。
まとめ
本記事では、ZOZOTOWNで本番稼働している肥大化したマイクロサービスから検索APIを切り出し、検索機能に特化したマイクロサービスを構築した事例を紹介しました。肥大化したマイクロサービスや役割が多いマイクロサービスをシンプルな形にすることで受けられる恩恵は十分にあると思いました。
ZOZOTOWNにおける検索機能は「ZOZOTOWN利用者が欲しい商品を見つける」ための重要な機能でかつ、リクエスト数も膨大です。今回ご紹介したようにシステムの改修を柔軟に対応できる形へ切り出せた事で、今では更なる検索速度や精度を改善に取り組む環境が整いました。このような検索基盤を開発する経験は個人的にも非常に良い経験でした。
おわりに
ZOZOテクノロジーズでは、検索機能を開発・改善していきたいエンジニアを全国から募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
- ユニットテストのガイドラインを作成いただいた木目沢さん、ありがとうございました!↩