



はじめに
こんにちは。ECプラットフォーム部のAPI基盤チームに所属している籏野 @gold_kou と申します。普段は、GoでAPI GatewayやID基盤(認証マイクロサービス)の開発をしています。
先日、【ZOZOTOWNマイクロサービス化】API Gatewayを自社開発したノウハウ大公開! を公開したところ、多くの方からご好評いただきました。ありがとうございます。まだ読まれていない方はぜひご覧ください。 techblog.zozo.com
今回はその記事の続きです。API Gatewayは単にリバースプロキシの役割を担うだけでなく、ZOZOTOWN全体の可用性を高める仕組みを用意しています。本記事では、それらの中でカナリアリリース機能・リトライ機能・タイムアウト機能に関して実装レベルの紹介をします。
マイクロサービスに興味ある方や、API Gatewayを自社開発する方の参考になれば幸いです。
なお、本記事における可用性の定義はこちらを参考にしており、 成功したリクエスト数 /(成功したリクエスト数 + 失敗したリクエスト数) で計算できるものとします。
カナリアリリース機能
ここでは前回の記事では触れなかったカナリアリリース機能の実装面について主に紹介します。
カナリアリリースとは、一部のリクエストのみ新系サービスにアクセスさせて、新系サービスに問題がなければ段階的に新系サービスへの比重を高めるデプロイ方法です。
例えば、まずは新系と旧系を1:9の比重でリクエスト分散します。仮にこの段階で、新系の変更部分が起因で問題が発生した場合は、被害は一部(ここでは1割のリクエスト)で済みます。もし新系に問題なければ比重を徐々にあげていき、最終的には新系と旧系を10:0にします。旧系はこの時点で削除します。
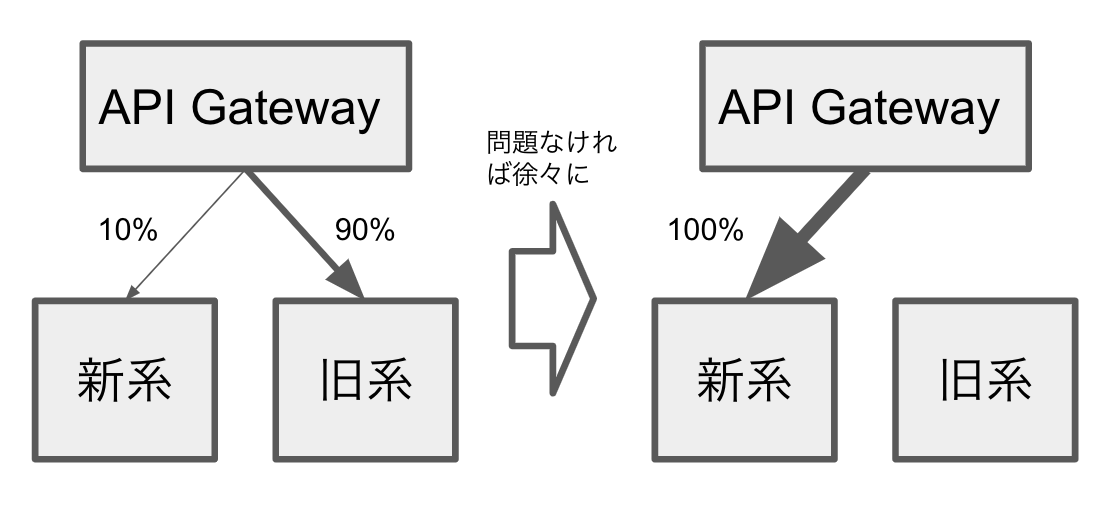
新系サービスにバグがあっても新系への加重率を低くしていれば失敗リクエスト数は減るため、可用性の低下を抑えられます。インフラコストは増えるものの、エンドユーザへの影響を最小限に抑えつつ、エンジニアのリリース時の心理的なハードルを下げられます。
前回記事のおさらい
前提知識として必要なものを簡単に説明します。
ターゲットとターゲットグループ
API Gatewayにはターゲットとターゲットグループという概念があります。ターゲットは転送先の接続情報(ホストとポート)です。ターゲットグループは、転送先であるターゲットをまとめた単位です。
ターゲットとターゲットグループの設定には、 target_groups.yml という名前のYAMLファイルを用意します。以下は設定の具体例です。TargetGroupAというターゲットグループの中に、2つのターゲットを設定しています。
TargetGroupA: targets: - host: target1.example.com port: 8080 - host: target2.example.com port: 8081
ルーティング
ルーティングの設定には、 routes.yml という名前のYAMLファイルを用意します。
以下は設定の具体例です。ルーティングする転送元と転送先の情報を定義します。HTTPリクエストのパスが正規表現で ^/sample/(.+)$ に一致した場合、転送先のパスをGoの regexp.ReplaceAllString を使って、 /$1 に置き換えます。正規表現マッチした部分がURLのリライトの対象となるため、例えば /sample/hoge というパスでリクエストがきた場合は、 /hoge に置き換えられます。
- from: path: ^/sample/(.+)$ to: destinations: - target_group: TargetGroupA path: /$1
加重ルーティング
加重ルーティングの設定には、 target_groups.yml および routes.yml の重みを指定します。
target_groups.yml で指定する重みはターゲットに対する重みで、 routes.yml で指定する重みはターゲットグループに対する重みです。ターゲットとターゲットグループで2段階の重み付けができます。転送先の比重をコントロールすることで、加重ルーティングおよびカナリアリリースを実現できます。
下記は target_groups.yml でTargetGroupA内のtarget1.example.comとtarget2.example.comに4:1の比重で振り分ける例です。
TargetGroupA: targets: - host: target1.example.com port: 8080 weight: 4 - host: target2.example.com port: 8081 weight: 1
下記は routes.yml でTargetGroupAとTargetGroupBに2:1の比重で振り分ける例です。
- from: path: ^/sample/(.+)$ to: destinations: - target_group: TargetGroupA path: /$1 weight: 2 - target_group: TargetGroupB path: /$1 weight: 1
スケジューラの基本
転送先を決定するスケジューラの基本について説明します。
重み付きランダムサンプリングでなく重み付きラウンドロビンを採用
ランダムサンプリングとは、複数の候補から無作為に対象を選択する方法です。一様ランダムサンプリングとも呼びます。重み付きランダムサンプリングとは、各対象が何かしらの選ばれやすさに関するパラメータを持っている場合のランダムサンプリングです。
スケジューラとして重み付きランダムサンプリングを採用する手段もありました。しかしながら、あるマイクロサービスの特殊な要件により、例えば重みの割合が9:1の場合では10回に1回は確実に片方へアクセスすることを保証する必要があったため、重み付きラウンドロビンを採用しています。
SchedulerインタフェースとFetchメソッド
ターゲットおよびターゲットグループのどちらも同一の Scheduler インタフェースで処理が共通化されています。 Scheduler インタフェースは Fetch メソッドを持ちます。実装するラウンドロビンの種類によって Fetch メソッドの動作は異なりますが、いずれの種類においてもターゲットを決めるためのインデックスをint型の値で返します。
type Scheduler interface { Fetch() int }
初期化
NewScheduler 関数でスケジューラの初期化をします。一般的なラウンドロビンスケジューラ roundRobinScheduler あるいは重み付きラウンドロビンスケジューラ weightedRoundRobinScheduler を返します。どちらのスケジューラも Fetch メソッドを実装しているため Scheduler インタフェースを満たしています。
func NewScheduler(weights []int) (Scheduler, error) { e := validateWeights(weights) if e != nil { return nil, e } one := weights[0] for _, w := range weights[1:] { if one != w { return newWeightedRoundRobinScheduler(weights), nil } } return newRoundRobinScheduler(len(weights)), nil }
どちらのスケジューラになるか
どちらのスケジューラになるかは、設定ファイル(target_groups.yml あるいは routes.yml)の weight の設定次第です。均等に weight の値が設定されているか weight が設定されていなければ一般的なラウンドロビンです。それ以外は重み付きラウンドロビンです。
下記は target_groups.yml の一般的なラウンドロビンの例です。 weight が設定されていません。
TargetGroupA: targets: - host: target1.example.com port: 8080 - host: target2.example.com port: 8081
下記は target_groups.yml の重み付きラウンドロビンの例です。異なる weight の値が設定されています。
TargetGroupA: targets: - host: target1.example.com port: 8080 weight: 2 - host: target2.example.com port: 8081 weight: 1
重みのバリデーション
重みに負の値が設定されていないか、一部の対象にしか重みが設定されていないかをバリデーションします。
func validateWeights(weights []int) error { nonweightedCount := 0 for _, weight := range weights { if weight < 0 { return errors.New("invalid weight") } if weight == 0 { nonweightedCount++ } } if nonweightedCount != 0 && nonweightedCount != len(weights) { return errors.New("mixed weighted and nonweighted targets") } return nil }
下記は target_groups.yml で weight に負の値が設定されているNG例です。
TargetGroupA: targets: - host: target1.example.com port: 8080 weight: -10 - host: target2.example.com port: 8081 weight: -1
下記は routes.yml で weight プロパティが設定されているものと、されていないものが混在しているNG例です。
- from: path: ^/sample/(.+)$ to: destinations: - target_group: TargetGroupA path: /$1 weight: 2 - target_group: TargetGroupB path: /$1
一般的なラウンドロビンのスケジューラ
一般的なラウンドロビンのスケジューラ実装について説明します。
構造体
roundRobinScheduler 構造体は以下の変数を持ちます。
- mutex
- 複数のリクエストを排他制御する
- current
- 現在のインデックス
- 初期値は0(つまりリストの先頭)
- count
- ラウンドロビン対象の総数
newRoundRobinScheduler関数の引数で渡される
type roundRobinScheduler struct { mutex *sync.Mutex current int count int }
newRoundRobinScheduler 関数は NewScheduler 関数から呼び出されます。初期化して roundRobinScheduler のポインタ型の変数を返します。
func newRoundRobinScheduler(count int) *roundRobinScheduler { return &roundRobinScheduler{mutex: &sync.Mutex{}, current: 0, count: count} }
Fetchメソッド
roundRobinScheduler 構造体の Fetch メソッドの処理内容は以下の通りです。
- 排他制御ロックをかける
- 次の呼び出しに備えてインデックス
currentをインクリメントしておく- リスト上に記載された次の対象を返すようにする
- もしリスト上で最後の場合は、最初のターゲットを返す
- 現在のインデックスを返す
func (s *roundRobinScheduler) Fetch() int { s.mutex.Lock() defer s.mutex.Unlock() i := s.current s.current = (i + 1) % s.count return i }
例えば、下記の target_groups.yml があった場合に3回 Fetch メソッドを実行するときの挙動を見てみます。
TargetGroupA: targets: - host: target1.example.com port: 8080 - host: target2.example.com port: 8081
まず、 roundRobinScheduler 構造体の以下のフィールドは値が決定します。
count: 2
各実行回数とその時の最終的な値は以下の通りです。次回は前回の変数の値を引き継ぎます。
1回目 Fetch()の戻り値: 0(target1.example.comが選択される) current: 1 2回目 Fetch()の戻り値: 1(target2.example.comが選択される) current: 0 3回目 Fetch()の戻り値: 0(target1.example.comが選択される) current: 1
重み付きラウンドロビンのスケジューラ
重み付きラウンドロビンのスケジューラ実装について説明します。
構造体
weightedRoundRobinScheduler 構造体は以下の変数を持ちます。
- mutex
- 複数のリクエストを排他制御する
- weights
- 対象全ての重み
newWeightedRoundRobinScheduler関数の引数で渡される
- maxWeight
weightsの中で最大の重みnewWeightedRoundRobinScheduler関数で決定される
- currentIndex
- 現在のインデックス
Fetchメソッドで返される値- 初期値は
-1
- currentWeight
- インデックスを返す際の基準となる重み
currentWeightよりも重いweightを持つcurrentIndexをFetchメソッドで返す- 初期値は0
type weightedRoundRobinScheduler struct { mutex *sync.Mutex weights []int maxWeight int currentIndex int currentWeight int }
newWeightedRoundRobinScheduler 関数は NewScheduler 関数から呼び出されます。 normalizeWeights 関数を実行して weightedRoundRobinScheduler のポインタ型の変数を返します。処理中に、引数で渡された重み weights を normalizeWeights 関数で約分します。
func newWeightedRoundRobinScheduler(weights []int) *weightedRoundRobinScheduler { normalizedWeights := normalizeWeights(weights) max := 0 for _, w := range normalizedWeights { if w > max { max = w } } return &weightedRoundRobinScheduler{weights: normalizedWeights, maxWeight: max, currentIndex: -1, currentWeight: 0, mutex: &sync.Mutex{}} }
重みの約分
normalizeWeights 関数は gcd 関数により求めた最大公約数で weights の要素を全て約分した結果を返します。約分する理由は、 Fetch メソッド内で無駄なforループを無くすためです。
func normalizeWeights(weights []int) []int { g := weights[0] for _, w := range weights[1:] { g = gcd(g, w) } normalizedWeights := []int{} for _, w := range weights { normalizedWeights = append(normalizedWeights, w/g) } return normalizedWeights }
gcd 関数は標準パッケージのmath/bigのGCDを利用してユークリッドの互除法により、最大公約数(greatest common divisor)を返します。
func gcd(m, n int) int { x := new(big.Int) y := new(big.Int) z := new(big.Int) a := new(big.Int).SetUint64(uint64(m)) b := new(big.Int).SetUint64(uint64(n)) result := z.GCD(x, y, a, b) return int(result.Int64()) }
Fetchメソッド
はじめに、イメージを掴んでいただくために Fetch メソッドによる走査処理の概要から説明します。
例えば、 target1に3、target2に5、target3に1 といった重み付けがされたケースを考えます。この場合、以下の割り当て順にはなりません。
target1 →target1 →target1 →target2 →target2 →target2 →target2 →target3
下のような2次元配列のようにして上から順に、左から走査する形で割り当てます。
weight 5: target2 weight 4: target2 weight 3: target1 target2 weight 2: target1 target2 weight 1: target1 target2 target3
つまり、割り当て順は以下になります。
target2 →target2 →target1 →target2 →target1 →target2 →target1 →target2 →target3
それでは、実装を見ていきます。 weightedRoundRobinScheduler 構造体の Fetch メソッドの処理内容は以下の通りです。
- 排他制御ロックをかける
currentIndexをインクリメントし、リストの最後の場合は先頭に戻るcurrentIndexがリストの先頭の場合は、currentWeightをデクリメントする- デクリメントした
currentWeightが負の値であればcurrentWeightにmaxWeightを代入する
- デクリメントした
currentIndexにおけるweightsの値がcurrentWeight以上であればそのcurrentIndexを返し、未満であれば2-4のステップを繰り返す
func (s *weightedRoundRobinScheduler) Fetch() int { s.mutex.Lock() defer s.mutex.Unlock() for { s.currentIndex = (s.currentIndex + 1) % len(s.weights) if s.currentIndex == 0 { s.currentWeight = s.currentWeight - 1 if s.currentWeight <= 0 { s.currentWeight = s.maxWeight } } if s.weights[s.currentIndex] >= s.currentWeight { return s.currentIndex } } }
例えば、下記の target_groups.yml があった場合に3回 Fetch メソッドを実行するときの挙動を見てみます。
TargetGroupA: targets: - host: target1.example.com port: 8080 weight: 1 - host: target2.example.com port: 8081 weight: 2
まず、 weightedRoundRobinScheduler 構造体の以下のフィールドは値が決定します。
maxWeight: 2 weights: [1, 2]
各実行回数とその時の最終的な値は以下の通りです。次回は前回の変数の値を引き継ぎます。
1回目 Fetch()の戻り値: 1(target2.example.comが選択される) currentIndex: 1 currentWeight: 2 2回目 Fetch()の戻り値: 0(target1.example.comが選択される) currentIndex: 0 currentWeight: 1 3回目 Fetch()の戻り値: 1(target2.example.comが選択される) currentIndex: 1 currentWeight: 1
Fetchメソッドの呼び出し
上記で説明した Fetch メソッドの呼び出し側について説明します。ターゲットとターゲットグループのいずれのスケジューリングにも使用できます。
ターゲットのスケジューリング
下記のように target_groups.yml の targets 配下には複数のターゲットを指定可能です。
TargetGroupA: targets: - host: target1.example.com port: 8080 weight: 1 - host: target2.example.com port: 8081 weight: 2
TargetGroup 構造体は Scheduler インタフェース型の変数 scheduler をフィールドとして持っています。したがって、 TargetGroup 構造体のポインタ型をレシーバに持つ ScheduledTargets メソッド内で Fetch メソッドを呼び出せます。ScheduledTargets メソッドは、複数の中から1つのターゲットを決定するために Fetch メソッドを呼び出します。 Fetch メソッドにより取得したインデックスで最初のターゲットを決定します。
type Target struct { Host string Port int Timeout timeout } type TargetGroup struct { // ... scheduler scheduler.Scheduler targets []*Target } func (targetGroup *TargetGroup) ScheduledTargets(length int) []Target { targetIndex := targetGroup.scheduler.Fetch() roundRobinTargets := []Target{} target := targetGroup.targets[targetIndex] // ... return roundRobinTargets }
ターゲットグループのスケジューリング
下記のように routes.yml の destinations 配下には複数のターゲットグループを指定可能です。
- from: path: ^/sample/(.+)$ to: destinations: - target_group: TargetGroupA path: /$1 - target_group: TargetGroupB path: /$1
routeTo 構造体は Scheduler インタフェース型の変数 scheduler をフィールドとして持っています。したがって、 routeTo 構造体のポインタ型をレシーバに持つ scheduledDestination メソッド内で Fetch メソッドを呼び出せます。複数の中から1つのターゲットグループを決定するために Fetch メソッドを使用します。 Fetch メソッドにより取得したインデックスでターゲットグループを選定します。
type routeTo struct { destinations []destination scheduler scheduler.Scheduler } type destination struct { targetGroup *targetgroup.TargetGroup path string } func (routeTo *routeTo) scheduledDestination() destination { destinationIndex := routeTo.scheduler.Fetch() return routeTo.destinations[destinationIndex] }
リトライ機能
ここでは前回の記事では触れなかったリトライ機能の一部仕様を紹介します。
前回記事のおさらい
前提知識として必要なものを簡単に説明します。
リトライ機能は、リクエスト失敗時にAPI Gatewayとマイクロサービス間でリトライする機能です。どのようなシステムであっても、なんらかの原因でリクエストが失敗する可能性はあります。
例えば、転送先マイクロサービスの一時的なエラー、通信問題、タイムアウトなどです。その失敗をAPIクライアントへそのまま返さずに、API Gatewayとマイクロサービス間でリトライします。リトライによりリクエストが成功すれば、エンドユーザへエラーを返さずにすむため成功リクエスト数が増えることになり、可用性を高められます。
以下のように、リトライ回数やリトライ条件、リトライ先ターゲット、リトライ前のスリープを target_groups.yml から設定可能です。
TargetGroupAB: targets: - host: target-a-1.example.com port: 8080 retry_to: target-b-2.example.com - host: target-a-2.example.com port: 8080 retry_to: target-b-1.example.com - host: target-b-1.example.com port: 8080 retry_to: target-a-2.example.com - host: target-b-2.example.com port: 8080 retry_to: target-a-1.example.com max_try_count: 3 retry_cases: ["server_error", "timeout"] retry_non_idempotent: true retry_base_interval: 50 retry_max_interval: 500
ターゲットグループを跨いだリトライ
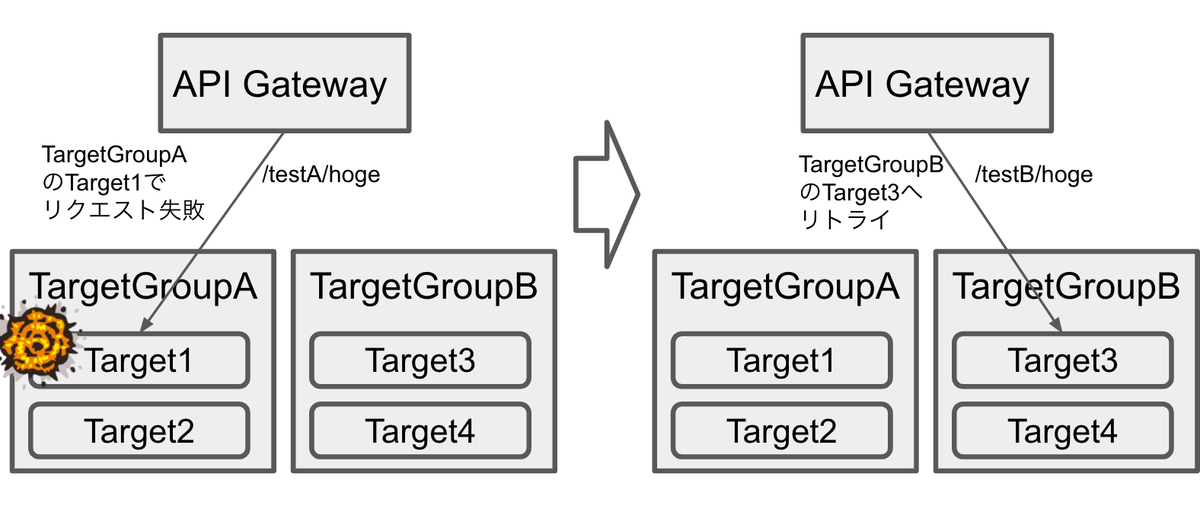
デフォルトでは、リトライ先のターゲットは同一ターゲットグループに属するもので限定されるため、ターゲットグループを跨ぎません。しかしながら、ターゲットグループを跨いだリトライでメリットが生まれるケースもあります。
例えば、TargetGroupAを新系、TargetGroupBを旧系のターゲットグループとします。TargetGroupAのTarget1で変更部分のバグによりリクエストが失敗した場合に、同じターゲットグループのTarget2へリトライしても同じ失敗になります。しかしながら、そのバグを含まないTargetGroupBのTarget3へリトライすればエンドユーザへの影響を最小限に抑えられます。エンドユーザへの若干のレスポンス速度の低下は発生しますが、エラーが返らずに済みます。また、マイクロサービスがターゲットグループ間で異なる場合は、下図のようにパスも異なる可能性があります。
設定方法
target_groups.yml の retry_to_target_group_id プロパティにターゲットグループIDを指定します。リトライ時は指定したターゲットグループのターゲットへのリトライになります。
下記は TargetGroupA の retry_to_target_group_id で TargetGroupB を指定している例です。
TargetGroupA: targets: - host: target1.example.com port: 8080 retry_to_target_group_id: TargetGroupB TargetGroupB: targets: - host: target2.example.com port: 8081
リバースプロキシとリクエスト情報の準備
HTTPリクエストをマイクロサービスへ転送する上で、リトライ情報を含めたリクエスト準備が必要です。ここでは、リクエスト情報を準備する上でどのように転送先のターゲット情報やリトライ情報を作成しているかの実装面を紹介します。
ServeHTTP メソッドは Route メソッドと transferRequest メソッドを実行します。http.Handler のインタフェースのメソッドでもあります。
func (reverseProxy ReverseProxy) ServeHTTP(w http.ResponseWriter, r *http.Request) { // ... func() { // ... fetchedTargetGroup, routedPathMap, e := reverseProxy.router.Route(client, ip, r) // ... response, body, tryURLs, e = reverseProxy.transferRequest(r, fetchedTargetGroup, routedPathMap, traceID, client) // ... } }
Route メソッドは fetchedTargetGroup と routedPathMap を返します。 fetchedTargetGroup は、内部の Fetch メソッドにより取得した最初の転送先ターゲットグループです。 routedPathMap はマッチしたルーティングに含まれる全てのターゲットグループとAPIパスの組み合わせを持つマップです。
func (router Router) Route(c client.Client, ip net.IP, req *http.Request) (fetchedTargetGroup *targetgroup.TargetGroup, routedPathMap map[*targetgroup.TargetGroup]string, e error) { routedPathMap = map[*targetgroup.TargetGroup]string{} for _, route := range router.routes { // ... fetchedTargetGroup = route.to.scheduledDestination().targetGroup for _, d := range route.to.destinations { routedPathMap[d.targetGroup] = route.from.path.ReplaceAllString(req.URL.Path, d.path) } return } // ... return } func (routeTo *routeTo) scheduledDestination() destination { destinationIndex := routeTo.scheduler.Fetch() return routeTo.destinations[destinationIndex] }
transferRequest メソッドはHTTPリクエストの転送処理をします。 Route メソッドの戻り値の fetchedTargetGroup と routedPathMap を引数に渡します。
func (reverseProxy ReverseProxy) transferRequest(r *http.Request, fetchedTargetGroup *targetgroup.TargetGroup, routedPathMap map[*targetgroup.TargetGroup]string, traceID string, client client.Client) (response *http.Response, body []byte, tryURLs []string, e error) { // ... }
transferRequest メソッド内では target_groups.yml に retry_to_target_group_id が指定されているかどうかで異なるリクエスト情報を作成します。
最大の試行回数 maxTryCount だけ、 targets 変数に以下のケースに基づいたターゲット情報を格納します。
retry_to_target_group_idが指定されていない場合fetchedTargetGroupのScheduledTargetsの戻り値
retry_to_target_group_idが指定されている場合- 最初のターゲットは
fetchedTargetGroupのScheduledTargetsの戻り値の1つ目の要素 - それ以降のターゲットはリトライ先のターゲットグループの
ScheduledTargetsの戻り値(要素数は1つ減らす)
- 最初のターゲットは
maxTryCount := fetchedTargetGroup.MaxTryCount() if !fetchedTargetGroup.RetryNonIdempotent() && (r.Method == http.MethodPost || r.Method == http.MethodPatch) { maxTryCount = 1 } var targets []targetgroup.Target if fetchedTargetGroup.RetryToTargetGroup() == nil { targets = fetchedTargetGroup.ScheduledTargets(maxTryCount) } else { firstTarget := fetchedTargetGroup.ScheduledTargets(1)[0] targets = append(targets, firstTarget) scheduledTargets := fetchedTargetGroup.RetryToTargetGroup().ScheduledTargets(maxTryCount - 1) targets = append(targets, scheduledTargets...) }
ScheduledTargets メソッドのリトライ対象の決定に関する処理を補足します。 Fetch メソッドで先頭のターゲットIDを決定した後に、for文内では決定したターゲット情報をkeyに retryTargetMap フィールドからリトライ先情報を取得します。 retryTargetMap は、keyがターゲットIDでvalueにそのターゲットIDへのリクエストが失敗した場合の次の転送先のターゲットIDを持ちます。リトライ先のターゲットはラウンドロビンでなく target_groups.yml の retry_to に設定されたターゲットあるいは次のインデックスのターゲットを使用します。このようにして、引数のリトライ上限回数 length の数だけfor文でターゲット情報の集合 roundRobinTargets を生成して返します。
type TargetGroup struct { // ... retryTargetMap map[*Target]*Target } func (targetGroup *TargetGroup) ScheduledTargets(length int) []Target { targetIndex := targetGroup.scheduler.Fetch() roundRobinTargets := []Target{} target := targetGroup.targets[targetIndex] for len(roundRobinTargets) < length { roundRobinTargets = append(roundRobinTargets, *target) target = targetGroup.retryTargetMap[target] } return roundRobinTargets }
作成した targets の数、つまり最大の試行回数だけ以下の情報を作成します。
url.Path 変数に以下のケースに基づいたパス情報を格納します。
retry_to_target_group_idが指定されていない場合fetchedTargetGroupをkeyにroutedPathMapから取得したもの
retry_to_target_group_idが指定されている場合- リトライ先のターゲットグループをkeyに
routedPathMapから取得したもの
- リトライ先のターゲットグループをkeyに
retryInfo 変数に以下のケースに基づいたリトライ情報を格納します。
retry_to_target_group_idが指定されていない場合fetchedTargetGroupのリトライ情報
retry_to_target_group_idが指定されている場合- リトライ先のターゲットグループのリトライ情報
targetURLs := []string{} // ... type retryInfo struct { cases []targetgroup.RetryCase baseInterval int maxInterval int } retryInfos := []retryInfo{} for i, target := range targets { url := *r.URL url.Scheme = "http" url.Host = fmt.Sprintf("%v:%v", target.Host, target.Port) var r retryInfo retryToTargetGroup := fetchedTargetGroup.RetryToTargetGroup() if i == 0 || retryToTargetGroup == nil { url.Path = routedPathMap[fetchedTargetGroup] r = retryInfo{ cases: fetchedTargetGroup.RetryCases(), baseInterval: fetchedTargetGroup.RetryBaseInterval(), maxInterval: fetchedTargetGroup.RetryMaxInterval(), } } else { url.Path = routedPathMap[retryToTargetGroup] r = retryInfo{ cases: retryToTargetGroup.RetryCases(), baseInterval: retryToTargetGroup.RetryBaseInterval(), maxInterval: retryToTargetGroup.RetryMaxInterval(), } } targetURLs = append(targetURLs, url.String()) // ... retryInfos = append(retryInfos, r) }
マイクロサービスへのリクエスト
上述の通り、リトライ情報含めたリクエストに必要な情報を準備しました。後続の処理では transferRequestToHTTP 関数でマイクロサービスにHTTPリクエストします。こちらの関数内処理の詳細は本リトライの話から逸れますので割愛します。
for i, targetURL := range targetURLs { response, body, e = transferRequestToHTTP(r, requestBody, targetURL, httpClients[i], traceID, client) // ... }
タイムアウト機能
ここでは前回の記事では触れなかったタイムアウト機能の一部仕様を紹介します。
前回記事のおさらい
前提知識として必要なものを簡単に説明します。
タイムアウトとは、その名の通り、一定の期間が経過したリクエストを打ち切ることです。実行が長引いているリクエストをタイムアウトさせて、後ろに詰まっているリクエストを正常に処理することで全体としてリクエスト成功数が増え、可用性を高められます。
API GatewayにはリバースプロキシするHTTPリクエストのタイムアウト設定が可能です。
設定項目は以下の通りです。
connect_timeout- 1リクエストあたりのTCPコネクション確立までの間のタイムアウト値(ミリ秒単位)
read_timeout- 1リクエストあたりのリクエスト開始からレスポンスボディを読み込み終わるまでの間のタイムアウト値(ミリ秒単位)
ターゲットとターゲットグループのタイムアウト
ターゲットとターゲットグループの両方にタイムアウト設定が可能です。
例えば、マイクロサービス化した新しいターゲットはレスポンスが速いのでそちらだけタイムアウトを小さくしたいといったケースです。該当のターゲットにタイムアウト設定しつつ他のターゲットにはターゲットグループのタイムアウト設定をデフォルトとして適用させることが可能です。
設定
以下の target_groups.yml の通り、両方で connect_timeout と read_timeout の設定が可能です。
TargetGroupA: targets: - host: target1.example.com port: 8080 connect_timeout: 10 read_timeout: 5000 connect_timeout: 50 read_timeout: 3000
実装
TargetGroupConfig は target_groups.yml に対応する構造体です。タイムアウト関連のフィールドも持ちます。
type TargetGroupConfig struct { Targets []struct { // ... ConnectTimeout int `yaml:"connect_timeout"` ReadTimeout int `yaml:"read_timeout"` // ... } `yaml:"targets"` ConnectTimeout int `yaml:"connect_timeout"` ReadTimeout int `yaml:"read_timeout"` // ... }
newTargetGroup 関数は TargetGroup 型の変数を返します。その処理過程でターゲットグループとターゲットのタイムアウト設定を読み込みます。ターゲットのタイムアウト設定に関しては、 ターゲットの設定>ターゲットグループの設定>ハードコーディングによるデフォルト設定 の順で優先付けされています。
const defaultConnectTimeout = 1000 const defaultReadTimeout = 10000 const defaultRetryBaseInterval = 50 // ... func newTargetGroup(targetGroupConfig TargetGroupConfig) (TargetGroup, error) { targets := []*Target{} // ターゲットグループにタイムアウト設定があればそれを使う。なければハードコーディングのデフォルト値とする。 if targetGroupConfig.Timeout < 0 || targetGroupConfig.ReadTimeout < 0 || targetGroupConfig.ConnectTimeout < 0 { return TargetGroup{}, errors.New("invalid timeout") } targetGroupConnectTimeout := defaultConnectTimeout if targetGroupConfig.ConnectTimeout != 0 { targetGroupConnectTimeout = targetGroupConfig.ConnectTimeout } targetGroupReadTimeout := defaultReadTimeout if targetGroupConfig.ReadTimeout != 0 { targetGroupReadTimeout = targetGroupConfig.ReadTimeout } else if targetGroupConfig.Timeout != 0 { targetGroupReadTimeout = targetGroupConfig.Timeout } // ... // ターゲットのタイムアウト設定があればそれを使う。なければターゲットグループの値とする。 for i, t := range targetGroupConfig.Targets { targetConnectTimeout := targetGroupConnectTimeout targetReadTimeout := targetGroupReadTimeout if t.ConnectTimeout != 0 { targetConnectTimeout = t.ConnectTimeout } if t.ReadTimeout != 0 { targetReadTimeout = t.ReadTimeout } target := Target{ // ... Timeout: timeout{ Connect: targetConnectTimeout, Read: targetReadTimeout, }, } // ... } // ... }
Target 構造体のタイムアウト値は、 http.Client の Timeout に Connect の値、 net.Dialer の Timeout に Read の値を使用します。
http.Client{
Transport: &http.Transport{
DialContext: (&net.Dialer{
Timeout: time.Duration(connectTimeout) * time.Millisecond,
// ...
}).DialContext,
// ...
},
// ...
Timeout: time.Duration(readTimeout) * time.Millisecond,
}
機能追加の展望
今後、さらに可用性を高める以下の機能追加を考えています。
- スロットリング
- クライアントタイプごとにレートリミットで制限するような機能を想定
- 一部のクライアントタイプによる大量リクエストでシステム全体が停止するのを避け、可用性を高める
- サーキットブレーカー
- ある閾値以上の失敗が続いたら、そのマイクロサービスにはリクエストを送らずにAPI Gatewayが503エラーを返すような機能を想定
- カスケード障害を防ぎ、可用性を高める
We are hiring
ZOZOTOWNのマイクロサービス化はまだ始まったばかりです。今後は、API GatewayやID基盤の追加開発に加えて、新たなマイクロサービスの開発も目白押しです。そのためのエンジニアが足りていない状況です。
ご興味のある方は、以下のリンクからぜひご応募ください。お待ちしております。