




こんにちは。ZOZOテクノロジーズZOZOTOWN部 検索チーム 兼 ECプラットフォーム部 検索基盤チームの有村(@paki0o)です。
ZOZOTOWNではこれまで度々紹介してきた通り、検索エンジンとしてElasticsearchを利用しています。リクエスト元のサーバーサイドのアプリケーションはJava(Spring Boot)で書かれており、クライアントにはHigh Level Rest Client(以下、HLRC)を使用しています。
HLRCを実際にプロダクション環境で運用していく中で、サービスのSLAを満たすために安定稼働させるための設定や、効率的に通信するための設定などを細かく指定しました。現在の設定にたどり着くまで、ドキュメント上で表現されていなかったり機能が用意されていなかったり等様々な苦労があったので、まだ道半ばですが現時点で辿り着いた設定内容についてご紹介いたします。同じくHLRCを利用されている方の参考になれば幸いです。
タイムアウト値の設定
公式ドキュメントにも記載のある通り、HLRCでは3種のタイムアウト値が設定可能です。なお、この値はHLRC固有のものではなく、内部で使用しているApache HttpClient共通の設定項目です。(ref : RequestConfig)
| 設定項目 | 説明 | デフォルト値 |
|---|---|---|
| connection request timeout | コネクション取得時のタイムアウト | -1(undefined) |
| connect timeout | コネクション確立時のタイムアウト | 1000ms |
| socket timeout | ソケット通信の監視用タイムアウト値 | 30000ms |
HLRCにてこの設定を上書きするためには、setRequestConfigCallbackにてRequestConfigを上書きします。
RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost(host, port, "https")) .setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder .setSocketTimeout(socketTimeout) .setConnectTimeout(connectTimeout) .setConnectionRequestTimeout(connectionRequestTimeout)));
公式のドキュメントには一部タイムアウト値の設定方法に関する記述はありましたが、connection request timeoutに関する記述は無く、またデフォルト値の設定もありませんでした。そのため、実際の運用ではconnection request timeoutにも独自の適切な値を入れ運用しています。
コネクション数の設定
コネクション数も同様に、クライアント生成時にオプションとして設定可能です。こちらもHLRC固有のものではなく、内部で使用しているApache HttpClient共通の設定項目です。(ref : ドキュメント)
| 設定項目 | 説明 | デフォルト値 |
|---|---|---|
| max conn per route | IP、 ポート単位の最大接続数 | 10 |
| max conn total | 最大接続数 | 30 |
RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost(host, port, "https")) .setHttpClientConfigCallback(httpAsyncClientBuilder -> httpAsyncClientBuilder .setMaxConnPerRoute(maxConnPerRoute) .setMaxConnTotal(maxConnTotal)));
リリース後しばらくはデフォルトの設定で運用していました。しかし実運用中、クラウド障害に起因したElasticsearchのレスポンス速度低下が発生した際、受け付けたリクエストがコネクション取得待ちで詰まる現象が発生しました。そのため現在はコネクション数に任意の値を追加し、合わせてクエリタイムアウト設定値も見直して運用しており、設定後同様の挙動は見られていません。
なお、ここまでで紹介したタイムアウト・コネクション数のHLRCにおけるデフォルト値は、org.elasticsearch.client.RestClientBuilderに記載されています。
通信のgzip圧縮対応
弊社が検索を全面的にElaticsearchへ移行した2020年4月時点(Elasticsearch v7.6.2)では、HLRCがgzip圧縮に対応していませんでした。もう少し具体的な説明をすると、リクエストの圧縮には対応しておらず、レスポンスの圧縮はRequestOptionsを用いヘッダへAccept-Encoding: gzipを付与する必要がありました。しかし、Low Level Rest Clientが圧縮されたレスポンスの解凍に対応していなかったため、エラーが発生しており利用を断念していました。
そこからしばらくIssueをウォッチしていたところ、8月リリースのv7.9.0でレスポンスの解凍が、12月リリースのv7.10.1でリクエストの圧縮がサポートされていました。またv7.10.1では、クライアント生成時のオプションに指定することで、必要最低限の設定でリクエスト・レスポンスの圧縮が可能となりました。
弊社ではインデキシングバッチと検索APIがそれぞれ独立したシステムで動いており、その両方がHLRCを利用していますが、それぞれリクエストの特徴が異なります。
| インデキシングバッチ | 検索API | |
|---|---|---|
| リクエスト量 | < 5req/sec | > 100req/sec |
| リクエストサイズ | > 10MB/req | < 5KB/req |
そのため、今回はそれぞれの特徴に合った検証となるよう、インデキシングバッチではトラフィック検証を、検索では受け側であるElasticsearchのCPU負荷検証を行いました。
なお、本検証は一般的なgzip圧縮による効果の検証であり、Elasticsearchに限られたものではない点にご注意ください。
インデキシングバッチでのトラフィック検証
インデキシングバッチ側では、上述の通りトラフィックがどの程度減少するのかを確認しました。
gzip圧縮適用のためHLRC生成時に指定する設定は以下の通りです。
RestHighLevelClient client = return new RestHighLevelClient( RestClient.builder(new HttpHost(host, port, Constants.HTTP_SCHEME)) .setCompressionEnabled(true)
上記の設定により以下2点が有効化されます。
- Request Bodyの圧縮
- Request Headerへの
Accept-Encoding: gzipの付与
検証結果
以下、圧縮前後の比較検証です。なお、インデキシングのリクエストはbulkで行っており、1リクエスト辺りのサイズは圧縮前で約1MBです。
| 平均 | 最大 | 改善率 |
|---|---|---|
| 1.5MiB/sec | 3MiB/sec | - |
| 100KiB/sec | 210KiB/sec | 93% |
適用前
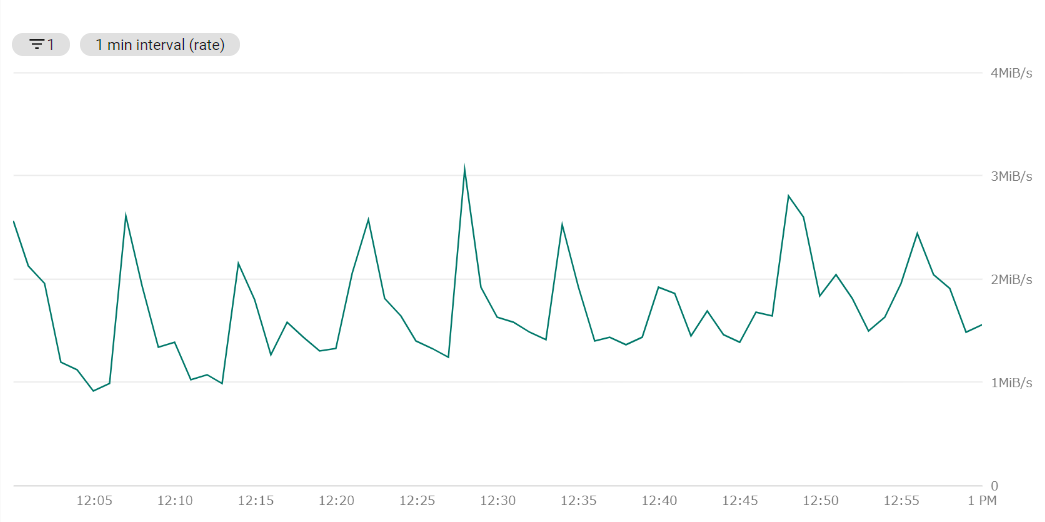
適用後
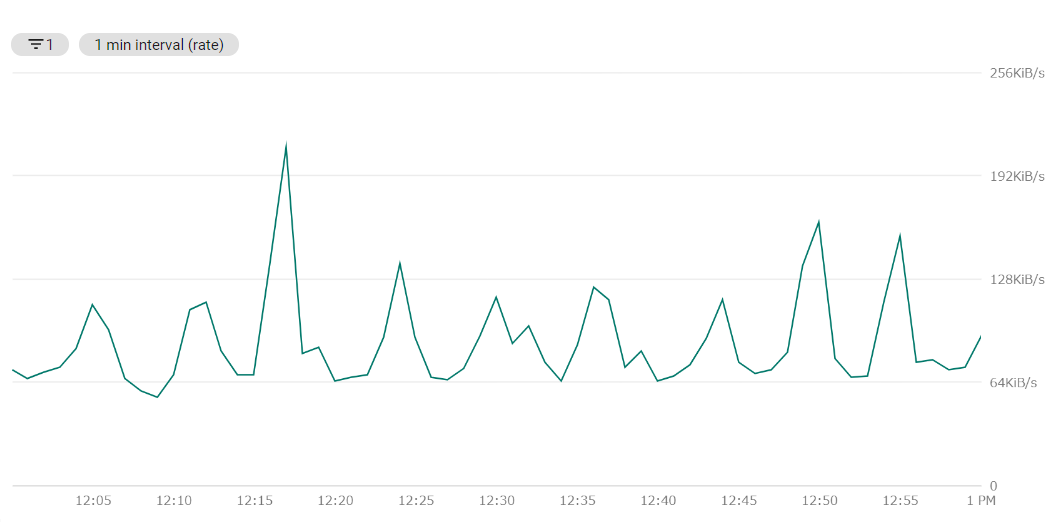
インデキシングバッチはApp Engine上で稼働しており、トラフィックに基づいた課金が発生しています。この改善によって送信量が格段に下がり、バッチの運用にかかる費用を1カ月当たり2~3万円ほど下げられました。
検索リクエストでのCPU負荷検証
一般的に、圧縮されたリクエストで通信するケースでは、圧縮側・解凍側それぞれ追加のCPUコストが発生します。これはElasticsearchでも当てはまることで、無圧縮状態の通信より必要となるリソースの増加が考えられます。
そのため、実際の検索リクエストをサンプリングしたものを用いて、CPU負荷がどの程度上昇するか検証しました。
検証はElastic Cloud上に構築した専用クラスタで行い、Coordinating Nodeを1台、Data/Master Eligible Nodeを3台用意しました。
検証結果
以下が実際にリクエスト数を増やした際のCoordinating NodeのCPU負荷遷移です。
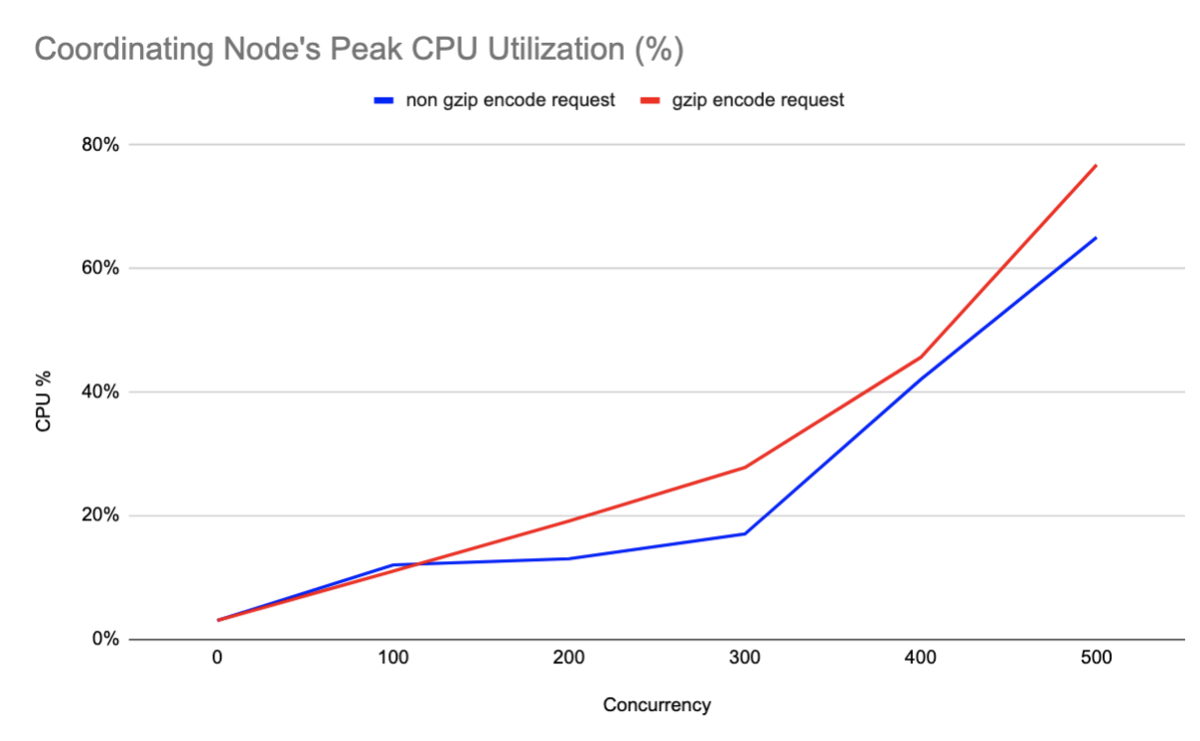
上図の通り、gzip圧縮ありのケースの方が、無しのケースに比べてCPU負荷が5%~10%増しでした。この上昇幅を致命的とみるかどうかはケースバイケースですが、あくまでも1ノードに対して負荷をかけた場合の値であり、本番同等のスケールでは致命的なレベルでないと判断しました。
HLRCのシングルトンインスタンスのエラーハンドリング・再作成
Spring BootでHLRCを利用する際、DIコンテナに登録しシングルトンなオブジェクトとして使うことは一般的な利用方法かと思いますが、そのエラーハンドリング周りに一癖あり苦労させられました。
具体的にはHLRC固有の問題ではなく、さらにそのバックエンドで用いられているLow Level Rest Clientが抱えている問題であり、Issueとしても挙げられています。内部で利用しているHttpClientのステータスが使用不可(I/O reactor status:STOPPED)な状態になった際、そこからのリカバリ策が現状用意されていません。
ここで解決策として以下の2つの手段が挙げられていましたが、直感的にも確実にリカバリが可能なことから弊チームでは後者を採用することとしました。
- HttpClientに対して独自のコールバックを定義し、I/O reactorを再作成する
- インスタンス自体を一旦破棄し、再作成する
実装
手元で事象を再現したところ、利用不可な状態になるケースではその直前にConnectionClosedExceptionの発生が確認できたため、この例外を捕捉した場合だけ再作成することとしました。
@Repository public class ElasticsearchAdapter { @Autowired private EsConfig esConfig; private RestHighLevelClient esClient; @Autowired public void setEsClient(RestHighLevelClient esClient) { this.esClient = esClient; } public SearchResponse search(SearchRequest searchRequest) { SearchResponse searchResponse = null; try { searchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT); } catch (Exception exception) { reCreateClientOnError(exception, esClient); } return searchResponse; } private void reCreateClientOnError(Exception e, RestHighLevelClient client) { if (e instanceof ConnectionClosedException) { try { client.close(); this.setEsClient(esConfig.esClientReCreate()); } catch (Exception ex) { throw new Exception(); } } } }
@Component @Configuration public class EsConfig { @Value("${spring.elasticsearch.es-username}") private String esUsername; @Value("${spring.elasticsearch.es-password}") private String esPassword; @Value("${spring.elasticsearch.es-host}") private String esHost; @Value("${spring.elasticsearch.es-port}") private Integer esPort; private final Integer socketTimeout = xxxx; private final Integer connectTimeout = xxxx; private final Integer connectionRequestTimeout = xxxx; private final Integer maxConnPerRoute = xxxx; private final Integer maxConnTotal = xxxx; @Bean(name = "esClient", destroyMethod = "close") RestHighLevelClient esClient() { return getEsClient(); } public RestHighLevelClient esClientReCreate() { return getEsClient(); } private RestHighLevelClient getEsClient() { final CredentialsProvider credentialsProvider = new BasicCredentialsProvider(); credentialsProvider.setCredentials( AuthScope.ANY, new UsernamePasswordCredentials(esUsername, esPassword)); RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost(esHost, esPort, "https")) .setHttpClientConfigCallback(httpAsyncClientBuilder -> httpAsyncClientBuilder .setDefaultCredentialsProvider(credentialsProvider) .setMaxConnPerRoute(maxConnPerRoute) .setMaxConnTotal(maxConnTotal)) .setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder .setSocketTimeout(socketTimeout) .setConnectTimeout(connectTimeout) .setConnectionRequestTimeout(connectionRequestTimeout)) .setCompressionEnabled(true) ); return client; } }
ElasticsearchAdapterリポジトリに登録されたesClientオブジェクトを再作成することで、利用不可なクライアントを破棄・上書きしています。
この設定を適用して以降、利用不可なクライアントが生き残りエラーとなるケースに遭遇することは無くなりました。ただ、実装の素直さで言うと前者の実装方法の方が綺麗であることは間違いないため、機会があればそちらも検証予定です。
まとめ
本記事では、High Level Rest Clientのプロダクション環境での運用で得たノウハウについてまとめました。設定項目が多いだけに安定稼働までは苦労がありましたが、各種リクエストが全てラップされており、多くの恩恵を受けているので今後も利用を続けていきたいです。
余談ですが、クライアントの名称がドキュメント上ではHigh Level Rest Client、パッケージ上ではRestHighLevelClientと語順に揺らぎがあり記事にする上で辛かったです。
最後に
ZOZOテクノロジーズでは、このようなちょっとした改善・チューニングが好きなエンジニアはもちろん、これからの検索を更に改善していきたいエンジニアを募集しています。全国フルリモートでの採用もあるので、ご興味のある方は以下のリンクからぜひご応募ください!