



ZOZOテクノロジーズ推薦基盤チームの寺崎(@f6wbl6)です。ZOZOでは現在、米Yale大学の経営大学院マーケティング学科准教授である上武康亮氏と「顧客コミュニケーションの最適化」をテーマに共同研究を進めています。
推薦基盤チームでは上武氏のチームで構築した最適化アルゴリズムを本番環境で運用していくための機械学習基盤(以下、ML基盤)の設計と実装を行っています。本記事ではML基盤の足掛かりとして用いたAI Platform Pipelines (Kubeflow Pipelines) の概要とAI Platform Pipelinesの本番導入に際して検討したことをご紹介し、これからKubeflow Pipelinesを導入しようと考えている方のお役に立てればと思います。記事の最後には、推薦基盤チームで目指すMLプロダクト管理基盤の全体像について簡単にご紹介します。
上武氏との共同研究のより詳しい内容については弊社のニュース記事を参照ください。
案件概要
Yale大学との共同研究に関して、推薦基盤チームで担当する業務の要件概要は以下の通りです。
- 毎日決まった時間にモデルによる予測を実行する(バッチ実行)
- モデルに入力する特徴量はBigQuery上の複数のテーブルから取得し、所定の前処理を加える
- モデルはpickle形式の学習済みモデルを提供していただき、当面の間はモデルの再学習を行わない
- 予測結果はBigQueryに出力する
具体的な入出力について詳細を書くことはできませんが、入力としてZOZOTOWNユーザーの属性や回遊情報を使い、出力としてユーザーごとに最適なコンテンツを得る最適化問題と考えるのが良いかと思います。一般的に予測モデルはデプロイして終わりではなく継続的に学習・検証とモデル更新を繰り返しますが、今回は共同研究における実験という側面があり、実験期間中は再学習を行わず運用することになりました。
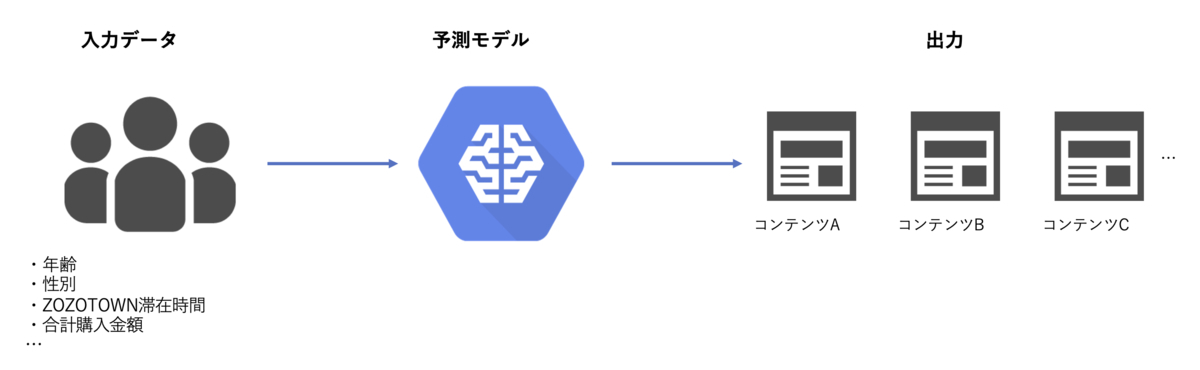
今回運用するモデルはオンライン予測しない + モデルの再学習も行わないため、機械学習モデルの運用としては比較的負荷の少ないケースと言えます。この機械学習モデルの運用方法を検討するにあたり、まず私たちのチームで抱えていた機械学習モデルの運用上の課題について見ていきます。
推薦基盤チームで抱えていた課題
推薦基盤チームではZOZOTOWNの推薦システム全般の構築・運用を担当しており、様々なアルゴリズムが本番環境で動いています。推薦アルゴリズムは弊チームで構築したものだけでなく分析本部やMA部で構築したものもあり、他チームから本番導入を依頼されるようなケースが少なくありません。案件ごとに様々な形でモデルの実装・運用を行っていく中で、以下のような要求に耐え得るML基盤が求められていました。
- 運用中の予測モデル(ワークフロー)を一元管理できること
- モデル構築の際に環境構築が容易であること
- 実験段階からプロダクションへの移行が容易であること
- 車輪の再発明をしないような仕組みであること(= 似たようなモデル開発をしない)
- モデルサービングが可能であること
機械学習モデルを本番環境で運用するにあたってこうした課題はよく直面するものと思います。特に私たちのチームでは様々なチームからモデルの実装・運用を依頼されるため、今後管理すべきモデルが増えていく状況の中で「運用中の予測モデルを一元管理できること」は最初に対処したい課題でした。仮にモデルごとに管理環境が異なっていた場合、モデル導入に関与した担当者でしかメンテナンスができないという状況にも繋がりモデル管理が属人的になってしまいます。
また推薦基盤チームでもモデルを作ることはあるため、推薦モデルを増やしていく上で「実験段階からプロダクションへの移行が容易であること」も重要な項目でした。
こうした課題を背景に、推薦基盤チームではMLOps全体に渡ってカバーしているKubeflowを導入することにしました。
Kubeflow

Kubeflowはモデルの作成・学習・検証、ワークフロー構築、モデルサービングといったMLOpsに関するワークロードをKubernetes上で実行するためのオープンソースツールキットです。要するに、MLプロジェクトで必要となるツールの全部盛りです。
元はGoogle社内で使われていたTensorflow ExtendedというML基盤があり、より汎用的に使えるML基盤を目指してオープンソース化した姿がKubeflowというプロジェクトになったようです。2020年11月現在v1.1が最新バージョンですが公式ドキュメントが追いついていない部分が多いため、実際に利用する際にはv1.0からキャッチアップしていくのが良いと思われます。
公式サイトによると、Kubeflowコミュニティの目指すゴールは以下であると述べられています。
Our goal is to make scaling machine learning (ML) models and deploying them to production as simple as possible, by letting Kubernetes do what it’s great at:
・Easy, repeatable, portable deployments on a diverse infrastructure (for example, experimenting on a laptop, then moving to an on-premises cluster or to the cloud)
・Deploying and managing loosely-coupled microservices
・Scaling based on demand
特に"Easy, repeatable, portable..."の項目に関してはドキュメントの中で頻繁に出てくることから、MLプロジェクトで陥りがちな「開発環境と本番環境の整合性を取るための雑務を取り除く」という思想が前面に出ているように思います。
こうした思想から、KubeflowにはMLプロジェクトで取り組むタスクをEnd to Endで行えるような要素が盛り込まれています。
| MLプロジェクトでのタスク | Kubeflowでの機能名 |
|---|---|
| モデル構築・実験 | Jupyter Notebooks |
| モデルの学習 | TensorFlow Training, PyTorch Training, ... |
| ハイパーパラメータ調整 | Katib |
| 特徴量管理 | Feast |
| ワークフロー構成 | Kubeflow Pipelines |
| モデルサービング | KFServing, Seldon Core Serving, ... |
Jupyter Notebooksによるモデル構築・実験からKFServingによるオンライン予測のエンドポイント作成まで、MLプロジェクトのタスクをEnd to Endで行うことができます。各タスクに最適化されたツールは既に様々な場所で運用されていますが、それらを1つのツールでまとめられるのがKubeflowの強みでしょう。
再三になりますが今回の要件としてモデルの構築・学習・オンライン予測は対象外であるため、Kubeflowの機能のうちKubeflow Pipelinesのみを利用することにしました。
Kubeflow Pipelines
Kubeflow Pipelinesは機械学習ワークフローを管理するためのツールで、類似ツールだとAirflowがあります。確かに今回の要件を満たすワークフローを作るだけであればAirflowで事足りるのですが、ここで推薦基盤チームにて抱えていた課題を振り返ります。
実験段階からプロダクションへの移行が容易であること 車輪の再発明をしないような仕組みであること
目の前のタスクを潰していくことを優先的に進めるとこうした課題の解決は後回しになっていき、やがて課題は大きく積み重なって後続のエンジニアの負債となります。モデル構築からパイプライン実装までを分離しない基盤であり、かつ一度作ったワークフローの構成要素を再利用する基盤を作ることの第一歩としてKubeflow Pipelinesを利用することにしました。
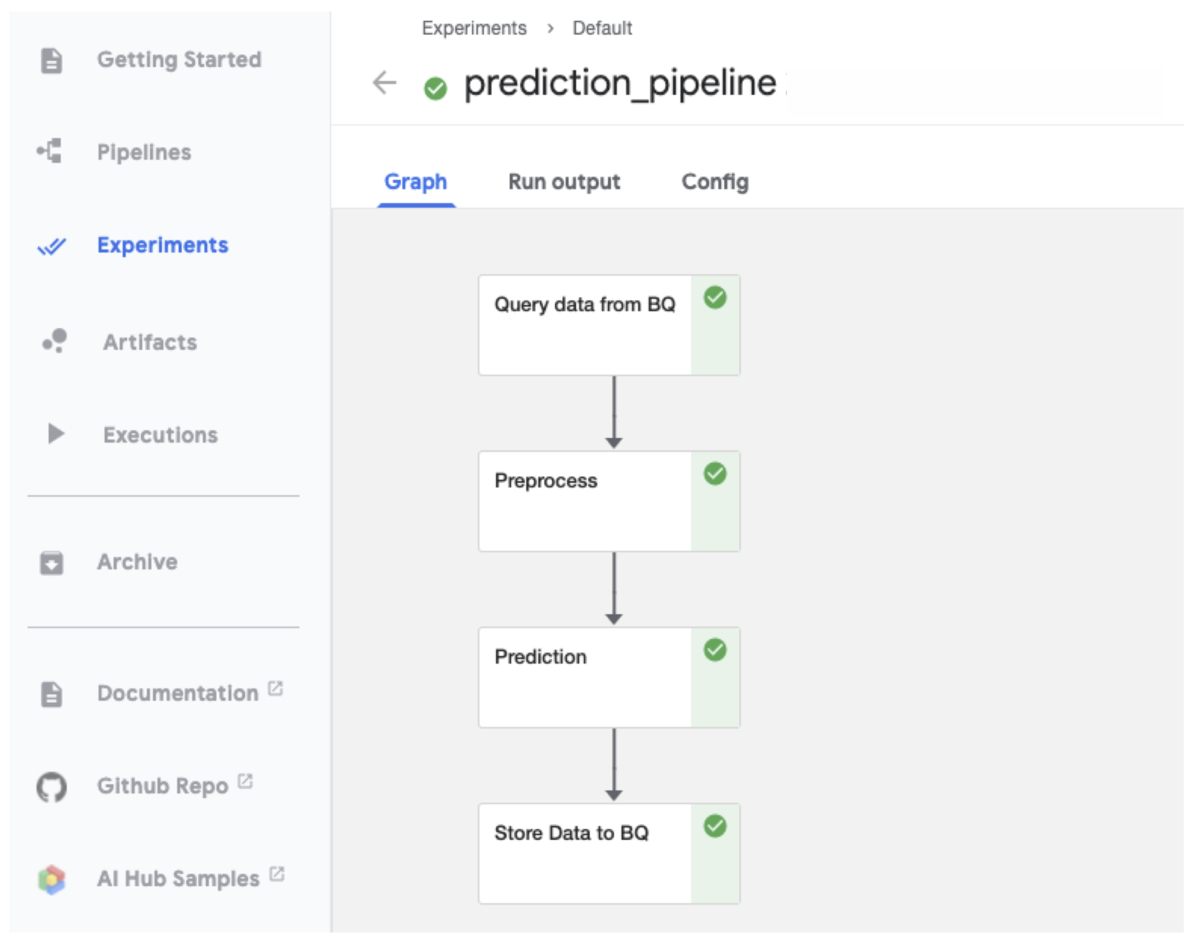
Kubeflow Pipelinesではコンテナ単位で機能を開発し、それを繋げて一連の処理を行うワークフロー(DAG)を構成します。ここで作ったコンテナはComponentと呼ばれ、それを繋げたものをPipelineと呼びます。
Componentはコンテナ化されているので、一度作ったComponentは様々な環境で使い回すことができます。汎用的なComponentはKubeflow PipelinesのGitHubリポジトリから利用できるため、どのようなComponentが提供されているかはそちらを参照ください。
例えば機械学習モデルで予測を行うワークフローは大まかには以下のステップに分解されます。
- データ収集
- 前処理
- 推論
- 予測結果を返却
このワークフローをKubeflow Pipelinesで構築すると以下のようなDAGになります。
Kubeflow Pipelinesの運用環境
Kubeflow PipelinesはKubeflowの機能の1つなので、Kubernetes環境があればKubeflowをインストールして利用できます。GCPでKubeflow Pipelinesを利用するには以下の2つの方法があります。
- GKEインスタンスを立てて自前でKubeflowをインストールする
- GCPのマネージドサービスであるAI Platform Pipelinesを使う
GKEインスタンスにKubeflowをインストールしてセルフマネージすることで常にKubeflowの最新版をキャッチアップし続けられるというメリットがあります。しかし今回は環境構築と管理の手間を考え、マネージドなAI Platform Pipelinesを利用することにしました。
AI Platform Pipelines
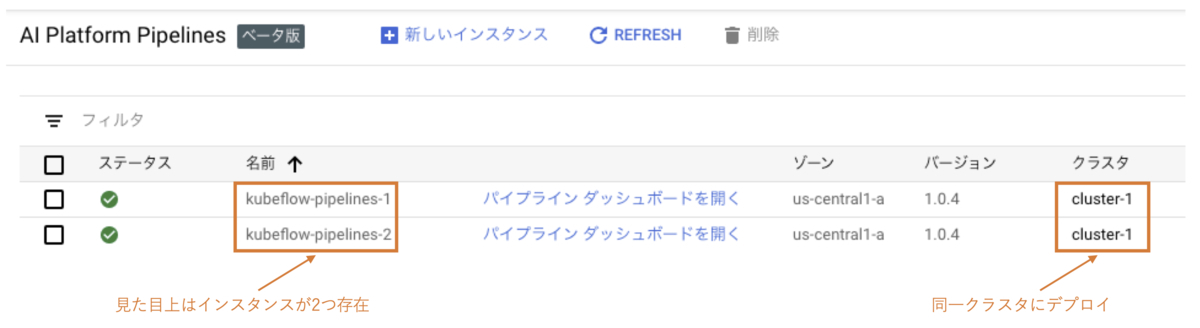
AI Platform PipelinesはGCPにおけるKubeflow Pipelinesのマネージドサービスであり、自分で一から環境構築することなくKubeflow Pipelinesを利用できます。GUIでの操作だけでGKEクラスタ作成からAI Platform Pipelinesインスタンスの立ち上げまでが自動的に行われます。なおGKEクラスタについては予め作成しておいたクラスタを指定することもできますが、同一クラスタに対して複数のインスタンスを立ててはいけないようです。
以下の図ではインスタンスが2つ存在していますが、実際にはkubeflow-pipelines-2のデプロイに失敗しています。
AI Platform Pipelinesは2020年3月よりベータ版がリリースされており、7月頃まではKubeflowのサポートバージョンがv0.5で止まっていましたが11月現在ではv1.0までサポートされています。v0.5まではKubeflow自体がツールとして成熟していなかったために挙動が不安定になることも多かったようですが、v1.0で運用している現状で変わった動きはあまり確認されていません。
Pipelineの設計・実装で意識したこと・ハマったこと
以下ではAI Platform Pipelines(+ Kubeflow Pipelines)を本番運用するにあたって意識したこと・ハマったことなどを紹介します。Kubeflow Pipelinesに関して「まずは使ってみた」という記事が多い中、実装や実運用面での知見は現状少ないので、これから本番導入を検討している方の一助になれば幸いです。
Pipeline内で日時情報を扱う
定期実行するバッチの場合、実行結果のログや成果物は日付や時間ごとでパーティションを切って保存することが一般的かと思います。例えばComponentの実行結果をあるGCSのバケットに保存する場合、以下のように日付を取得して全てのComponentに保存先を渡すことが考えられます。
# pipeline_1.py from datetime import datetime from kfp import dsl from kfp import components as comp from kfp.components import func_to_container_op @func_to_container_op def thanks(message: str, gcs_output_path: str): from myutils import upload_to_gcs # GCSにファイルをアップロードする関数 upload_to_gcs(message, gcs_output_path) @dsl.pipeline def pipeline(text:str): """ 毎日thanks.txtをGCSに出力する """ today = datetime.today().strftime('%Y%m%d') thanks_path = f'gs://my-gcp-project/my-bucket/{today}/thanks.txt' print(f'{thanks_path=}') thanks_task = thanks(message='byebye', gcs_output_path=thanks_path)
Pipelineにする必要性は全くないサンプルですがご了承ください。
一見正しく動きそうなプログラムですが、実際にはここで取得したtodayはこのpipeline_1.pyがコンパイルされた日付で固定されています。つまり今日(2020/11/13)にpipeline_1.pyをコンパイルして毎日実行した場合、print文の出力は以下のようになります。
# 2020/11/13に実行した結果 thanks_path='gs://my-gcp-project/my-bucket/20201113/thanks.txt' # 2020/11/14に実行した結果 thanks_path='gs://my-gcp-project/my-bucket/20201113/thanks.txt' # 2020/11/15に実行した結果 thanks_path='gs://my-gcp-project/my-bucket/20201113/thanks.txt' ...
todayがコンパイルされた日(2020/11/13)で固定されているため、thanks.txtは常にgs://my-gcp-project/my-bucket/20201113へ出力されることになります。ローカルでデバッグしながら開発していると常にPipelineをコンパイルしながら作業することになるため、この挙動に気付きにくいかもしれません(実際私はデブロイして定期実行の動作を確認している時に初めて気付きました)。
想定した挙動を得るためには以下のようにComponent内で時刻を取得する必要があります。Componentは実行の度にコンテナとして立ち上げられるため、コンテナが起動したタイミングの日付が得られるという算段です。
# pipeline_1_fix.py from kfp import dsl from kfp import components as comp from kfp.components import func_to_container_op from myutils import upload_to_gcs # GCSにファイルをアップロードする関数 @func_to_container_op def thanks(message: str, gcs_output_path: str): from myutils import upload_to_gcs # GCSにファイルをアップロードする関数 from datetime import datetime # 追加 today = datetime.today().strftime('%Y%m%d') # 追加 thanks_path = f'{gcs_output_path}/{today}/thanks.txt' # 追加 print(f'{thanks_path=}') # 追加 upload_to_gcs(message, thanks_path) @dsl.pipeline def pipeline(text:str): """ 毎日thanks.txtをGCSに出力する """ gcs_path = f'gs://my-gcp-project/my-bucket' thanks_task = thanks(message='byebye', gcs_output_path=gcs_path)
ただこの方法では「日付を取得して保存先として使う」という業務ロジックをComponentに含めるため、Component化することのメリットが失われることになります。またComponentの中を見ないとファイルの出力先がわからないという問題もあります。
ここで、Kubeflow Pipelinesのワークフロージョブエンジンとして使われているArgoではWorkflow VariablesというPipeline内の様々なメタデータを参照できる変数があります。
例えば現在の処理を実行しているGKEのPod名を以下のように取得できます。
print("Current pod name: {}".format({{ pod.name }}))
同様に、workflow.creationTimestampというvariableを使えば現在時刻をstringで取得できるため、この時刻から日付を抽出すれば解決!
# pipeline_2.py ... @func_to_container_op def thanks(message: str, gcs_output_path: str): from myutils import upload_to_gcs # GCSにファイルをアップロードする関数 upload_to_gcs(message, gcs_output_path) @dsl.pipeline def pipeline(text:str): """ 毎日thanks.txtをGCSに出力する """ today = '{{workflow.creationTimestamp}}' # '2020-11-14 01:51:55 +0000 UTC' ymd = today.split(' ')[0] # '2020-11-14' が得られる想定 thanks_path = f'gs://my-gcp-project/my-bucket/{ymd}/thanks.txt' print(f'{thanks_path=}') thanks_task = thanks(message='byebye', gcs_output_path=thanks_path)
と思いきや、このprint文の出力は以下のようになります。
thanks_path=gs://my-gcp-project/my-bucket/{{workflow.creationTimestamp}}/thanks.txt
これはArgoによるWorkflow Variablesの置換がComponentの内部に入るタイミングで実行されるためです。
上記の例ではComponent内でgs://my-gcp-project/my-bucket/2020-11-14 01:51:55 +0000 UTC/thanks.txtと置換され、想定した挙動にはなりません。正しくは以下のように、あらかじめ年月日だけの形にしておく必要があります。
# pipeline_2_fix.py ... @func_to_container_op def thanks(message: str, gcs_output_path: str): from myutils import upload_to_gcs # GCSにファイルをアップロードする関数 print(f'{gcs_output_path=}') # 追加 upload_to_gcs(message, gcs_output_path) @dsl.pipeline def pipeline(text:str): """ 毎日thanks.txtをGCSに出力する """ today = '{{workflow.creationTimestamp.Y}}{{workflow.creationTimestamp.m}}{{workflow.creationTimestamp.d}}' # 変更 thanks_path = f'gs://my-gcp-project/my-bucket/{today}/thanks.txt' print(f'{thanks_path=}') thanks_task = thanks(message='byebye', gcs_output_path=thanks_path)
ここで、各print文の出力は以下のようになります。
thanks_path='gs://my-gcp-project/my-bucket/{{workflow.creationTimestamp.Y}}{{workflow.creationTimestamp.m}}{{workflow.creationTimestamp.d}}/thanks.txt' gcs_output_path='gs://my-gcp-project/my-bucket/20201114/thanks.txt'
実際の運用ではComponentの出力先の初期化を行うためのComponentを作り、その内部で必要な日時を生成するようにしました。
# pipeline.py from typing import NamedTuple from kfp import dsl from kfp.components import func_to_container_op @func_to_container_op def initialize(timestamp: str) -> NamedTuple('Outputs', [('t_jst', str), ('t_ymd', str), ('t_hour', str)]): from datetime import datetime, timezone, timedelta shift_hours = 9 # Create and shift timestamp JST = timezone(timedelta(hours=shift_hours), 'JST') jst_dt = datetime.strptime(timestamp, '%Y-%m-%d %H:00:00').astimezone(JST) t_jst = jst_dt.strftime('%Y-%m-%d %H:00:00') t_ymd = f'{jst_dt.year:04}{jst_dt.month:02}{jst_dt.day:02}' t_h = f'{jst_dt.hour:02}' return (t_jst, t_ymd, t_h) @dsl.pipeline(name='Prediction Pipeline') def pipeline(GCS_OUTPUT_DIR): init_task = ( initialize( timestamp='{{workflow.creationTimestamp.Y}}-{{workflow.creationTimestamp.m}}-{{workflow.creationTimestamp.d}} {{workflow.creationTimestamp.H}}:00:00') .set_display_name('Initialize') ) # Define gcs path gcs_hourly_output_dir = f'{GCS_OUTPUT_DIR}/{init_task.outputs["t_ymd"]}/{init_task.outputs["t_hour"]}' ...
上記の例はタイムゾーンの変換をするためにinitializeというComponentを設けています。この例ではdatetimeライブラリを使うのと変わりありませんが、Argoの機能としてタイムゾーンの指定ができるようになればよりスマートにPipeline内で日時情報を扱うことができるでしょう。
https://argoproj.github.io/argo/variables/argoproj.github.io
Slack通知
定期実行しているPipelineが正常に稼働していることを監視するために、Kubeflow Pipelines SDK (kfp)のkfp.dsl.ExitHandlerクラス(以下ExitHandler)を利用しています。ExitHandlerはwithブロックから抜け出す際に実行するComponentを指定するものです。
https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.dsl.html#kfp.dsl.ExitHandlerkubeflow-pipelines.readthedocs.io
以下のようにSlack通知用のComponentを定義してExitHandlerの実行Componentに指定することで、Pipelineが異常終了した際にSlackで通知を飛ばします。ここではSlack通知のメッセージにRun名やKubeflow PipelinesのURLを記載するために、Workflow VariablesをComponentの引数として指定しています。
# pipeline.py @dsl.pipeline() def pipeline(): with dsl.ExitHandler(exit_op=slack_notification_op( slack_webhook_url="<<SLACK_URL>>", status="{{workflow.status}}", job_name="{{workflow.name}}", pipelines_url="<<KUBEFLOW_URL>>" + "/#/runs/details/" + "{{workflow.uid}}") ): init_task = ( initialize( timestamp='{{workflow.creationTimestamp.Y}}-{{workflow.creationTimestamp.m}}-{{workflow.creationTimestamp.d}} {{workflow.creationTimestamp.H}}:00:00') .set_display_name('Initialize') ) ...
ただしこの方法はPipelineの実行可否を通知するものであり、Component単位で通知ログを残すことはできません。こうしたログをSlackに通知するには、2020年11月現在ではComponent内部にSlack通知用の関数を埋め込むか、ログに何らかのタグを埋め込んでCloud LoggingとCloud Monitoringで拾うしか方法がないと思われます。
もし何か他にベストプラクティスをご存知の方がいらっしゃいましたら是非ご連絡をお願いします。
ノードプールによるリソースと権限の分離
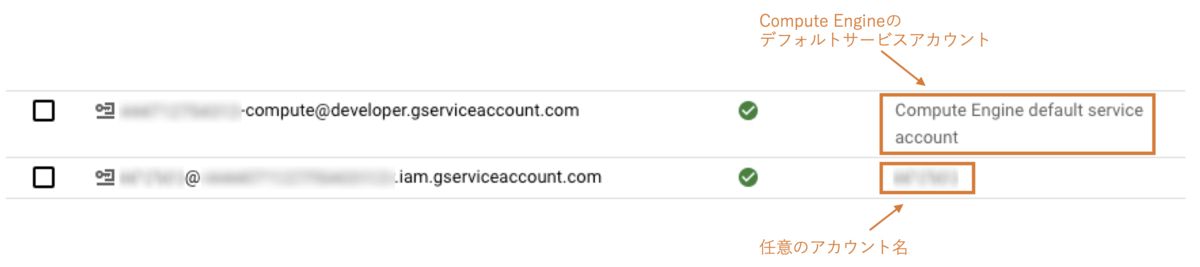
AI Platform Pipelinesではインスタンス作成時に自動的にGKEクラスタも作成されると前述しましたが、予め用意しておいたGKEクラスタを指定することもできます。自動的に作成されるGKEクラスタには123456789-compute@developer.gserviceaccount.comのようなCompute Engineのデフォルトサービスアカウント名が割り当てられ保守性に欠けるため、事前にサービスアカウントを作成しGKEクラスタに割り当てておくのが吉と言えます。
今回の案件で使用する特徴量にはユーザーの属性情報や回遊行動を用いるため、様々なBigQueryのテーブルを参照することになります。GKEクラスタと紐づけたサービスアカウントに必要な権限を全て付与しても良いのですが案件ごとに参照するテーブルやGCSのバケットは変わり得るため、権限は案件ごとに分けたいという思いがありました。
そこで今回は案件ごとに使用するノードプールを分けて、ノードプールに対してサービスアカウントを紐づける方法を取るようにしました。Kubeflow PipelinesではComponentごとに使用するノードを指定できるため、ハイメモリインスタンスを使う場合やGPUを使う時にも専用のノードプールに切り替えることができます。
init_task = (
initialize(
timestamp='{{workflow.creationTimestamp.Y}}-{{workflow.creationTimestamp.m}}-{{workflow.creationTimestamp.d}} {{workflow.creationTimestamp.H}}:00:00')
.set_display_name('Initialize')
.add_node_selector_constraint('cloud.google.com/gke-nodepool', 'high-memory-pool')
)
add_node_selector_constraintの第一引数にはノードラベルを指定し第二引数にはノード名を指定します。
cloud.google.com https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.dsl.html#kfp.dsl.ContainerOp.add_node_selector_constraintkubeflow-pipelines.readthedocs.io
Componentの実行に使うノードプールはノード数を0に指定してオートスケーリングするように設定することで、リソースを使わない時に余計なノードプールが残らないようにしました。
なお、以下のようにComponentが利用するノードプールのリソースサイズを指定して垂直スケールさせることもできます。権限管理を考えなければこちらの方がスマートにマシンリソースをスケールさせることができるでしょう。
# Using Large memory preprocess_task = preprocess_op(csv_files=csv_file_path).set_memory_request("60G")
https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.dsl.html#kfp.dsl.Sidecar.set_memory_requestkubeflow-pipelines.readthedocs.io
CI/CDの実装
Kubeflow Pipelinesを使った継続的な開発を進めるために検討しなければいけないのがCI/CDの実現方法です。
Google Cloudの公式ドキュメントにはKubeflow Pipelinesに対するCI/CDワークフローのユースケース例が提示されています。こちらのCI/CDワークフローではCloud Source RepositoriesやGitHubリポジトリに対してCloud Buildでビルドトリガーを設定し、ブランチにcommitやmergeが発生した時にCloud Buildで構築したワークフローを実行するというアーキテクチャになっています。
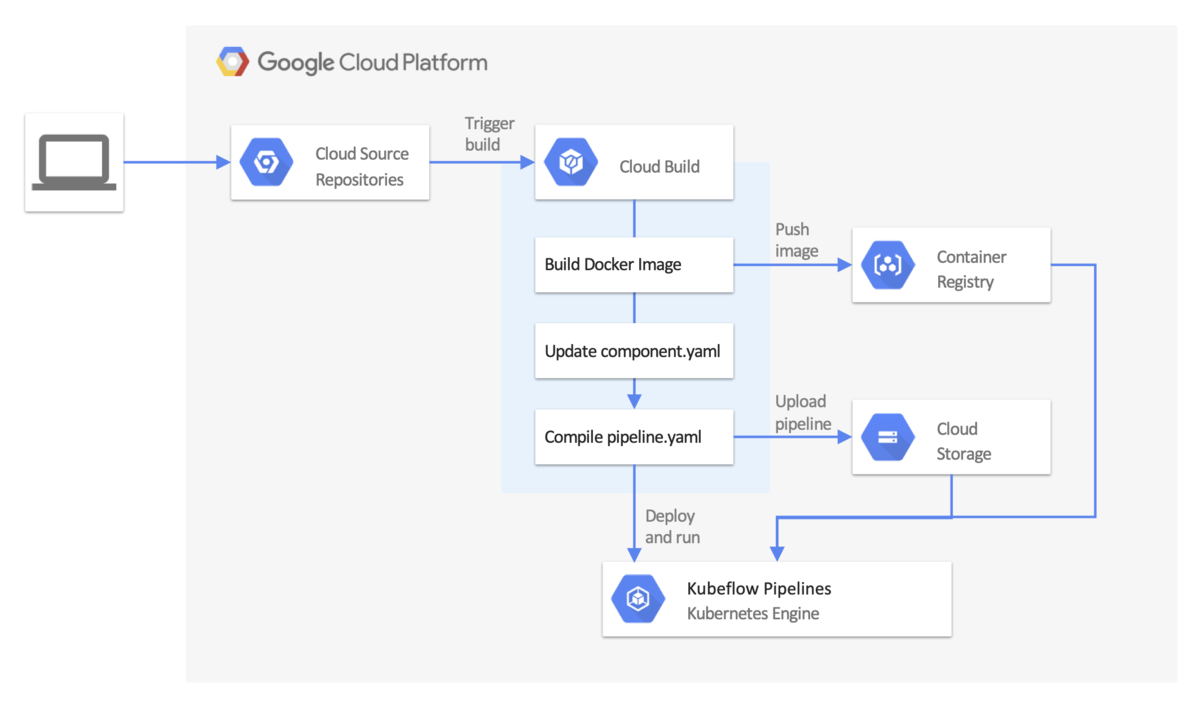
一方、推薦基盤チームでの製作物はGitHub ActionsでCI/CDを構築・管理する土壌ができていたため、今回もGitHub Actionsで完結させたいという思いがありました。
そこで調査を進めた結果、同様の課題を抱えた先人が上に示したワークフローをGitHub Actionsで作ってくれていました。
こちらのGitHub Actionsを使うことでコンパイルされたpipeline.yamlファイルをKubeflow Pipelinesにデプロイできます。しかし、今回の要件として定期実行する必要があり、このGitHub ActionsではKubeflow PipelinesのRecurring Run(cron実行機能)を利用することができませんでした。
追加機能としてPull Requestを出しても良かったのですがログを見る限りではあまりメンテナンスがされていないようだったので、必要な機能を参照しつつRecurring Run機能を追加実装することとしました。
実装内容としては単純で、以下のようにrecurring_flagというフラグを設けてフラグが立っている時にRecurring Runを登録するようにしました。
# github_actions.py def run_pipeline_func(client: kfp.Client, pipeline_name: str, pipeline_id: str, pipeline_paramters_path: dict, recurring_flag: bool = False, cron_exp: str = ''): ... if recurring_flag: client.create_recurring_run(experiment_id=experiment_id, job_name=job_name, params=pipeline_params, pipeline_id=pipeline_id, cron_expression=cron_exp) client.run_pipeline(experiment_id=experiment_id, job_name=job_name, params=pipeline_params, pipeline_id=pipeline_id) ...
このGitHub Actionsを用いて、最終的に以下のようなワークフローとなりました。
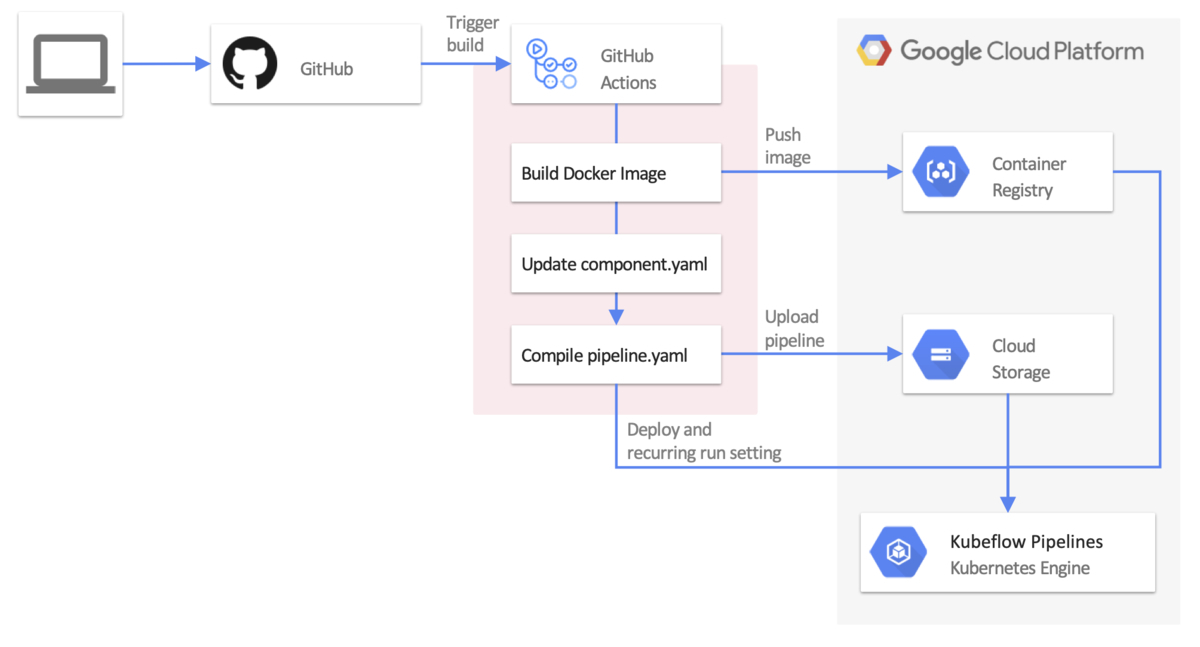
今回作成したGitHub ActionsをFork元にマージするか否かはまだ決めかねていますが、また別のテックブログ記事で使い方を含めて公開したいと思います!
今後の展望
今回はKubeflow導入の足掛かりとして、Kubeflow PipelinesのマネージドサービスであるAI Platform Pipelinesを用いたバッチ実行の予測パイプラインを構築しました。一方で、以下のように利用・検討しきれていないことも多々あります。
- モデルの再学習を伴うPipelineの運用:AI Platform Training + Vizier
- 学習済みモデルのオンラインサービング:AI Platform Prediction or GKEで自前ホスティング
- Feature Storeによる特徴量の管理:Feast
- AI Platform Pipelinesインスタンスの管理単位
特にAI Platform Pipelinesインスタンスの管理については悩ましいものがあります。今後様々なMLモデルが増えるにつれて、GKEクラスタとAI Platform Pipelinesインスタンスはどのように立てていくのが良いのかという問題が生じます。
AI Platform Pipelines1つにつきGKEクラスタ1つを紐づけるように公式ドキュメントには記載されているため、AI Platform Pipelinesインスタンスを立てるにつれてGKEクラスタも増え、コストの増加に繋がってしまいます。またGCPプロジェクトごとにインスタンスを立てるとなると、コストだけでなく管理面でも複雑になり得ます。
この問題の対応については現在SREチームと共に、GKEクラスタに対して自前でKubeflow環境を構築することも視野に入れながら模索中という段階です。
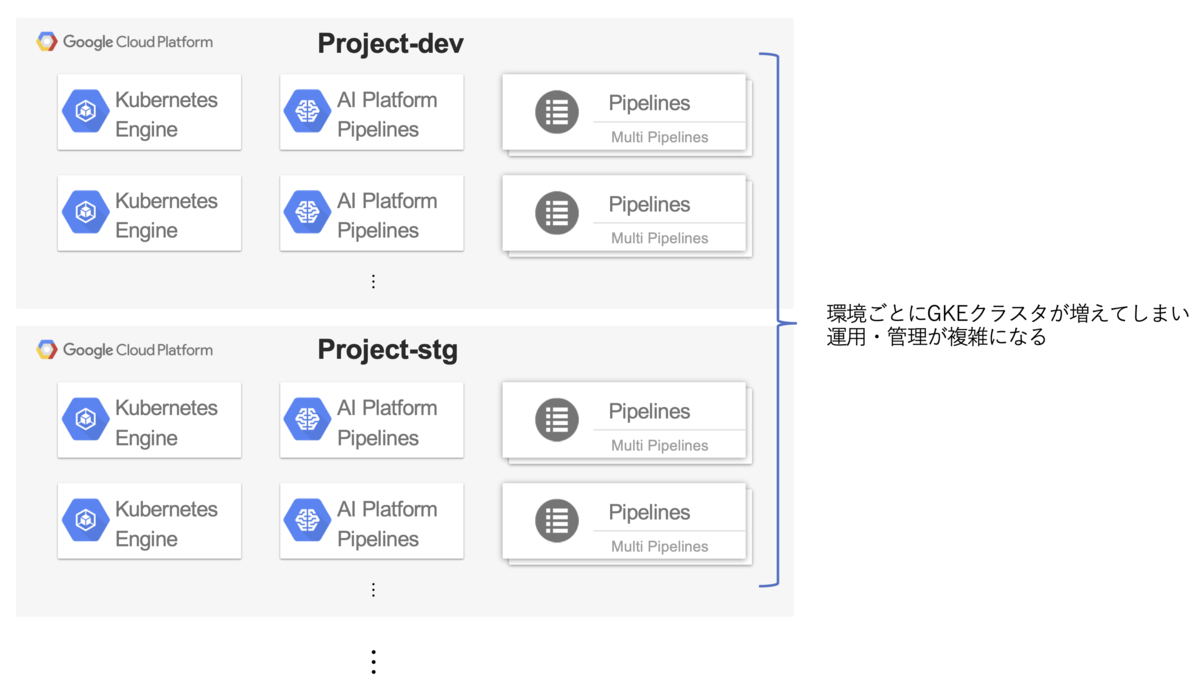
ML基盤として目指す姿
最後に、推薦基盤チームで目指すMLプロダクト管理基盤の全体像について簡単に述べておきます。まだ構想段階ではありますが、大まかには以下のようなアーキテクチャを考えています。
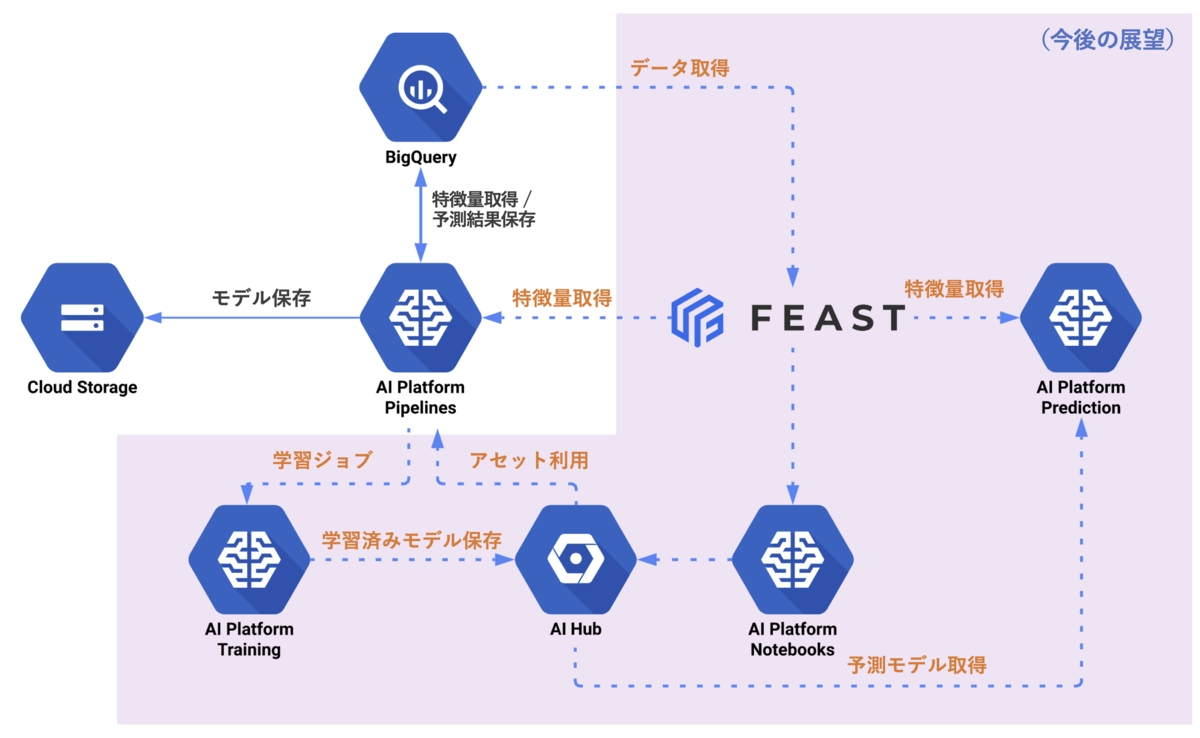
基本的にはGCPのマネージドサービスを積極的に取り入れていくことを考えています。
この中でも特にポイントとなるのは今回ご紹介したワークフロー実行基盤であるKubeflow Pipelinesに加え、特徴量の管理基盤であるFeast、そして成果物を一元管理するAI Hubでしょう。
FeastはKubeflowにてα版でサポートされているFeature Storeです。
Feature Storeはモデル構築・運用で使用している特徴量を管理するための基盤の総称で、2017年にUberで使われているMichelangeloというML基盤の紹介記事が初出のようです。
www.slideshare.net
モデルを作成する際に必要となる特徴量はFeature Storeから取得し、モデルサービング時にも同様にFeature Storeから同様の特徴量を使用することでモデル構築とサーブ時で使用する特徴量の齟齬を解消できます。AI Platformでも近いうちにFeature Store機能が追加されていくようなので、今後のML基盤の構成要素としてスタンダードなものになっていきそうです。
AI Hubはプロジェクトでの成果物(モデル、Pipeline、Componentなど)や分析結果(ノートブック、クエリなど)といったアセットを一元管理し再利用できるようにする大きな箱、というイメージです。AI Hubでは社内で利用するプライベートなPipelineや学習済みモデルの管理に加えて、パブリックなPipelineやNotebookを探すこともできます。また、登録するアセットの種類やカテゴリ、データ種別でラベル付けをすることで必要なアセットを容易に検索できます。
プロジェクトの成果物や分析結果、各種アルゴリズムの検証結果などをAI Hubで統合管理し組織のナレッジベース化することで、推薦基盤チームが抱えている課題の一つである「車輪の再発明をしないような仕組み」を実現できると考えています。
一方、現状AI Platformの各種サービスはベータ版での提供のものが多いため本番環境への導入を慎重に検討しつつ、ZOZOTOWNで利用されるMLモデルの管理・運用基盤の構築を進めていきます!
おわりに
本記事ではKubeflow PipelinesのマネージドサービスであるAI Platform Pipelinesの紹介と本番環境への導入に際して直面した問題について述べました。推薦基盤チームではZOZOTOWNで運用する推薦システムをより良くできるように、日々新しい技術のキャッチアップをして様々な可能性を模索していきたいと考えています。
ZOZOテクノロジーズではZOZOTOWNの推薦システム構築・運用に興味のある方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
https://tech.zozo.com/recruit/mid-career/tech.zozo.com
参考
- Cloud Composerで組む機械学習パイプライン
- MLSE 機械学習基盤 本番適用と運用の事例・知見共有会
- Kubeflow Pipelinesで日本語テキスト分類の実験管理
- Machine Learning Pipelines with Kubeflow
- How to carry out CI/CD in Machine Learning (“MLOps”) using Kubeflow ML pipelines (#3)
- ML Feature Stores: A Casual Tour
- Michelangelo Palette: A Feature Engineering Platform at Uber
- Feature Store: The Missing Data Layer in ML Pipelines? Feast: feature store for Machine Learning
- pachyderm/kfdata Prototype implementation of KFData Proposal
- Introducing AI Hub and Kubeflow Pipelines: Making AI simpler, faster, and more useful for businesses