



はじめに
こんにちは。ブランドソリューション開発本部 WEAR部 SREの笹沢(@sasamuku)です。
FAANSはショップスタッフの効率的な販売をサポートするスタッフ専用ツールです。FAANSの一部機能は既にリリースされており全国の店舗で利用いただいております。正式リリースに向け、WEARと連携したコーディネート投稿機能やその成果をチェックできる機能などを開発中です。
FAANSのコンテナ基盤にはCloud Runを採用しており、昨年にSREとしての取り組みをテックブログでご紹介しました。しかし、運用していく中で機能需要や技術戦略の変遷があり、Cloud RunからGKE Autopilotへリプレイスすることを決めました。本記事ではリプレイスの背景と、複数サービスが稼働している状況下でのリプレイス方法についてご紹介します。
目次
リプレイスの背景
なぜCloud Runだったのか
そもそもなぜCloud Runを採用していたのか簡単に振り返ります。詳細は昨年の記事をご覧ください。
コンテナ化されたアプリケーションを利用する前提で、開発・運用両面の要件を満たせるサービスには、Cloud RunとGKEがありました。ここでの要件とは、「Goのバージョン1.16をサポートしていること」と「サーバレスなコンテナ基盤であること」の2つです。Cloud Run採用の決め手は構築・運用コストの低さです。リリース当初、Kubernetesを運用できるほど人員が潤沢ではなく、時間的な制約もありました。実際、Cloud Runは非常にシンプルで、素早く利用開始でき、GCPサービスとの連携も容易にできます。おかげでリリースまでに構築を終えられましたし、追加要件にもスピーディーに対応できました。
なぜGKEに移行したいのか
GKEに移行する理由は2つあります。
- Cloud Runはサイドカーコンテナ非対応である
- コンテナ運用におけるチーム標準をKubernetesにする
まず、「1.」について説明します。Cloud Runはserviceと呼ばれる単位で管理されます。1 serviceにデプロイできるのは1コンテナのみとなっており、サイドカーコンテナは利用できません1。弊社では主な監視ツールにDatadogを利用しています。サイドカーコンテナとしてDatadog Agentを構成できないことはトレース取得の観点で痛手でした2。Datadog Agentを直接アプリケーションコンテナにインストールする方法も考えられますが、イレギュラーな対応3を要するため見送りました。
次に、「2.」についてです。私達のチームは、FAANSの他に2つのプロダクトを運用しています。これらはECSを採用していましたが、デプロイやスケールのさらなる柔軟さを求め、EKSへの移行が検討されていました4。FAANSも足並みを揃えてGKEに移行することにより、チームが利用するコンテナ基盤をKubernetesに統一できます。こうすることで、プロダクト毎の技術差異が抑えられ、運用負荷の軽減、ノウハウ横展開による効率化を実現できると考えました5。
なぜGKE Autopilotなのか
GKEにはStandardとAutopilotの2つの運用モードがありますが後者を採用しました。その主な理由は、運用負荷が軽減されるためです。
Standardは、マスターノードはマネージドであるものの、ワーカーノードの管理はユーザに委ねられます。一方のAutopilotは、ワーカーを含む全てのノード管理がマネージドです6。そのため、マシンタイプ選定やオートスケーラー構成といったノードに関する対応は必要ありません。Pod仕様に応じて自動的に必要サイズのノードが必要数プロビジョニングされます7。
ただ、大規模トラフィックや急峻なスパイクが見込まれるケースではStandardの利用が推奨されています8。FAANSはtoBアプリケーションであり、そうした傾向は現在のところありませんでした。そのため、Autopilotの恩恵をありがたく享受することにしました。
Autopilotの制限事項により利用できるHelm Chartに制限が生じることもありましたが、現在のところクリティカルな影響は生じていません。これについては後述します。
リプレイスの全体像
制約条件
リプレイスを進める上で、まず始めに制約条件として下記を掲げました。
- サービスをメンテナンスモードにしない
- アプリケーションのリリースを停止させない
- アプリケーションコードの改修は最小限にする
FAANSはリリース済みのサービスであり、メンテナンスモードにするには各所へ調整が要ります。そのため無停止で完了させる方針としました。また、機能開発が盛んな状況だったため、コードフリーズは行わず開発の足かせとなる改修も極力避ける方針としました。
アーキテクチャ
それでは、新旧アーキテクチャを説明します。
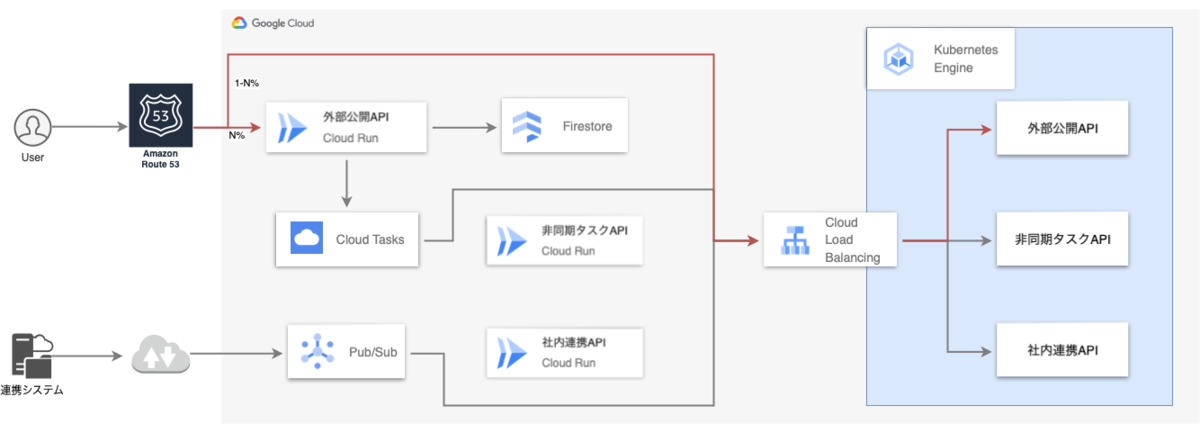
Cloud Runを活用した既存のアーキテクチャがこちらです。
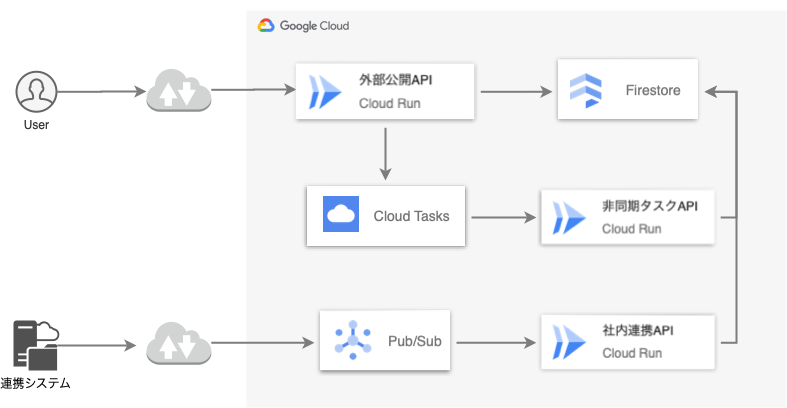
稼働しているCloud Run serviceは3つあります。
- 「外部公開API」: 一般ユーザからリクエストを受け付ける
- 「非同期タスクAPI」: Cloud Tasksからタスクを受け付ける
- 「社内連携API」: 連携システムからPub/Sub経由でメッセージを受け付ける
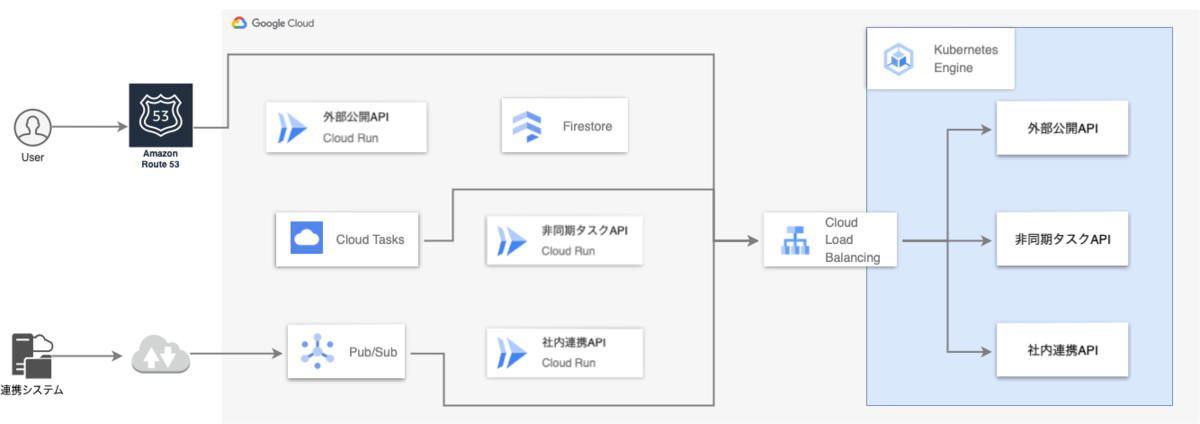
そして、リプレイス後のアーキテクチャがこちらになります。
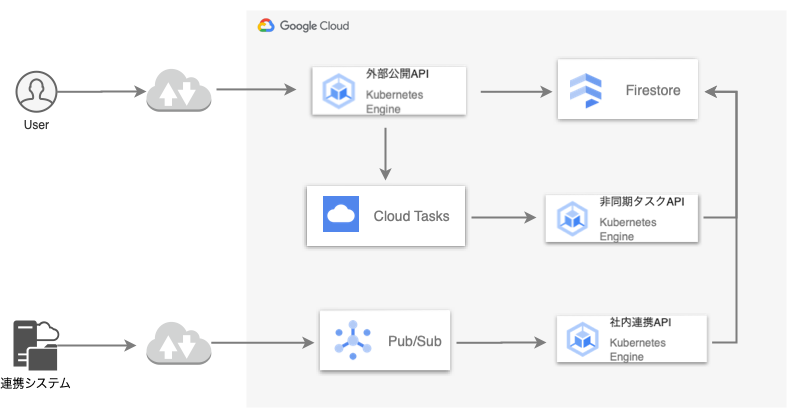
アプリケーションの改修を避けるためアーキテクチャはほとんど変更しません。Cloud TasksやPub/Subといったサービスは継続利用し、各APIのエンドポイントをCloud RunからGKEに置き換えます。リクエストはIngressのhostベースルーティングで各APIに振り分けます。
段階的リプレイス
問題発生時の影響を最小限にするため段階的にリプレイスを進めます。具体的には、影響度の小さい順にCloud Run serviceをGKEへ置き換えます。検討の結果、社内連携API、非同期タスクAPI、外部公開APIの順でリプレイスする方針にしました。
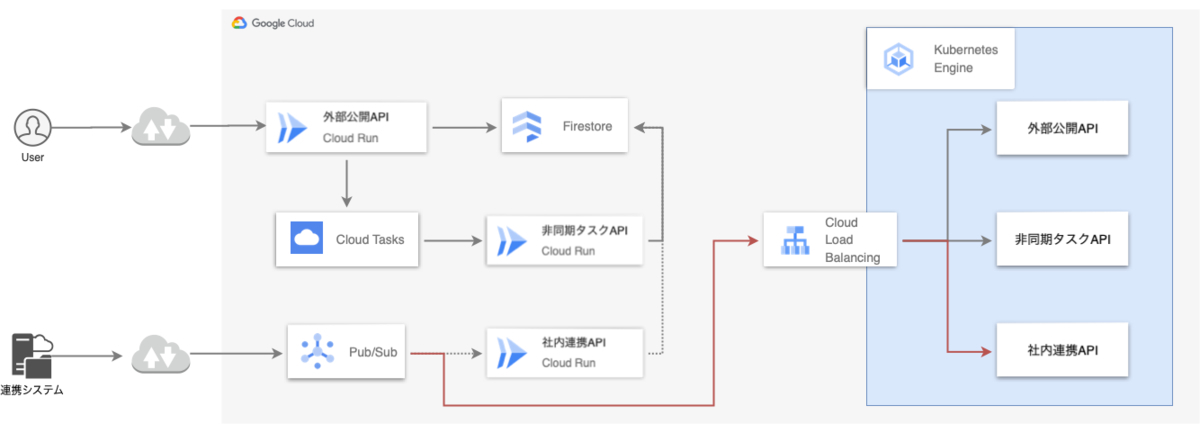
Phase1: 社内連携API
社内連携APIは、Pub/SubからPush型でリクエストを受け取るため、サブスクリプションに設定しているPushエンドポイントをCloud RunからGKEに変更します。なお、無停止で移行させるため、移行先のGKEには最新バージョンのコンテナがデプロイされている状態になっています。
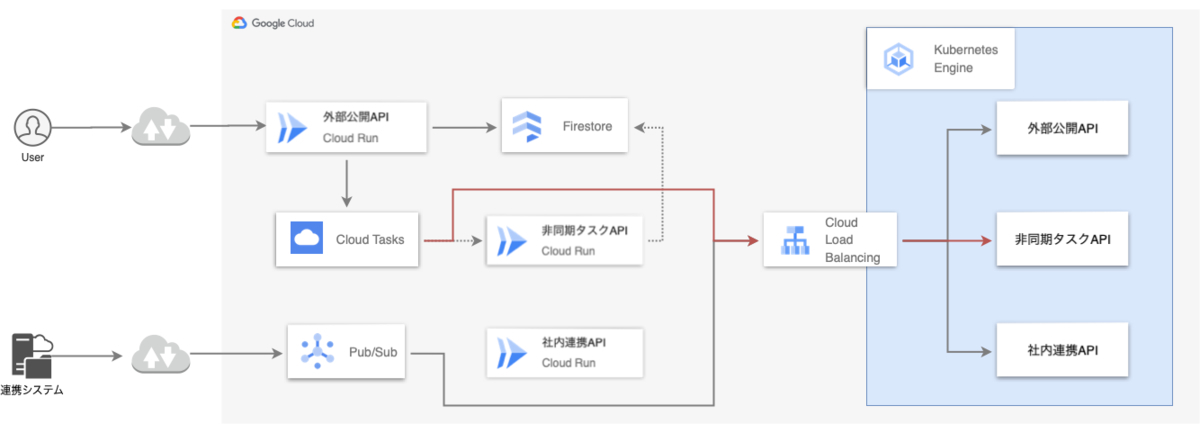
Phase2: 非同期タスクAPI
外部公開APIは処理時間の長いデータベース更新といった一部の処理を非同期タスクAPIに任せます。このとき、Cloud Tasksを挟むことで疎結合に連携しています。Cloud Tasksがタスクを送るエンドポイントは、外部公開APIが送るタスクデータに埋め込まれます。そのため、アプリケーションの設定ファイルを書き換えることでエンドポイントを移行します。
Phase3: 外部公開API
最後に外部公開APIです。こちらはユーザにダイレクトに影響が出るためカナリアリリースします。DNSにはRoute53を利用しているため、加重ルーティングを利用します。Cloud Runのドメイン(CNAMEレコード)とGKE IngressのIPアドレス(Aレコード)の加重を徐々に変えていきます。初回は10%程度とし、最終的にGKE Ingressに100%のトラフィックを振ります。
最後にはCloud Runへの導線が0の状態になります。
リプレイスにあたって苦労したこと
GKE Autopilotへのリプレイスで苦労した点もいくつかありました。
認証方法の違いによる追加構成
Cloud Runは機能として認証・認可を具備しています。一方のGKEには存在しなかったため代替手段としてIdentity-Aware Proxy (IAP) と呼ばれるサービスを活用しました。
Cloud Run serviceでは、社内連携APIと非同期タスクAPIの2つでサービスアカウントによる認証を実施していました。これらのAPIは外部公開APIとは異なり、不特定多数のユーザからのアクセスを想定していません。そのため、Cloud TasksやPub/Subに紐づけているサービスアカウントからのみリクエストを許可する設定をしていました。
Pub/Subの場合、次のようなTerraformのコードでCloud Runへのアクセスを制限します。
resource "google_cloud_run_service_iam_member" "example_api" { location = google_cloud_run_service.example_api.location project = google_cloud_run_service.example_api.project service = google_cloud_run_service.example_api.name # 認証を挟みたい Cloud Run サービス role = "roles/run.invoker" # Cloud Run の呼び出しに必要なロール member = "serviceAccount:${google_service_account.example_sa.email}" # 認証に使うサービスアカウント } resource "google_pubsub_subscription" "example_subscription" { ... push_config { push_endpoint = "https://cloudrun-api.com/push" # メッセージの送信先エンドポイント (Cloud Run) oidc_token { service_account_email = google_service_account.example_sa.email # 認証に使うサービスアカウント } } ... }
GKEにはこのような組み込みの認証がないため、冒頭に記述のIAPを利用しています。IAPはCompute EngineやCloud Load Balancingといったサービスに認証・認可のフローを提供できます。GKEのエンドポイントは、GKE Ingress Controllerが作成したCloud Load Balancingで公開されるため、IAPを活用した構成が利用できました。
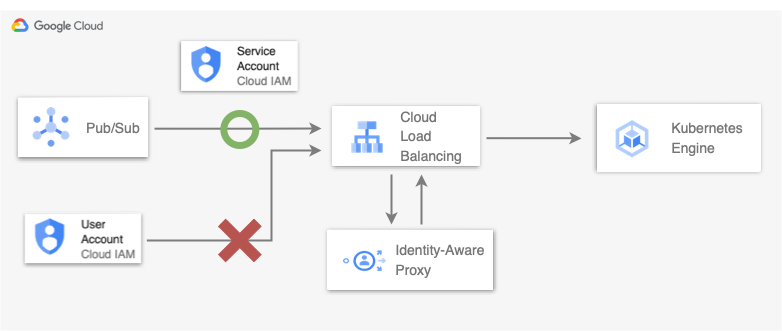
これにより、Cloud Runを利用していたときと同様に、意図しないアクセスをブロックできます9。
GKE Autopilotの制限事項への対応
公式ドキュメントから抜粋すると、GKE AutopilotにはStandardと比較して次のような制限が存在します。
- hostPathボリュームが使用できない(
/var/log/配下のみ可) - hostPortとhostNetworkが使用できない
- ワークロード内のコンテナに対するPrivileged modeが使用できない
したがって、これらの使用を前提としているHelm Chartは利用できません。
例えば、Secret ManagerのシークレットをPodで取得可能にするsecrets-store-csi-driverは利用できません。hostPathやPrivileged modeの制限に引っ掛かるためです10。幸い、同様の機能を提供するExternal Secrets Operatorは利用可能となっています。
また、Datadog AgentのHelm Chartにおいて一部機能が制限されます。具体的には、ワークロードからのトレース送信にhostPortの使用を想定していますが11、これはAutopilotによって制限されています。公式のサポートではありませんが、こちらのIssueで案内されている対応で回避できました。
各ChartにおいてもAutopilotの制約は認知されているため近い将来には改善している可能性もあります。
おわりに
FAANSにおけるコンテナ基盤リプレイスの背景と事例を紹介しました。コンテナ基盤がKubernetesに統一されることはプロダクト横断のSREチームにとって大きなメリットとなります。複雑なマニフェストやHelmの管理が大変であることも事実ですが、反面、様々な要件に応えられる柔軟さと捉えることもできます。今後運用を重ねながらさらなる拡張・改善に取り組んでいきたいと思います。
最後に、ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。
- 公式ブログではサイドカーを必要としないケースでのCloud Run利用を薦めています。↩
- 最新のサポート状況は公式ドキュメントをご確認ください。↩
- 1コンテナで複数プロセスを起動する方法は公式ドキュメントに記載されています。wrapper scriptまたはsupervisordのどちらの場合もいわゆるPID1問題への考慮が必要となります。↩
- 組織内でもEKSを利用しているチームが多数あったため人員流動性や採用の観点からもEKSが有利でした。↩
- External SecretやArgoCDなど、利用するHelmを統一することでプロダクト間のスイッチングコストが抑えられます。↩
- 2つの運用モードの詳細については公式ドキュメントおよび公式ブログをご覧ください。↩
- AutopilotではCluster autoscalerとNode auto-provisioningがデフォルトで有効化されています。↩
- https://cloudonair.withgoogle.com/events/google-cloud-day-digital-21?talk=d1-appdev-01↩
- 拙稿にてCloud RunとGKEの認証について簡単にまとめております。↩
- https://github.com/kubernetes-sigs/secrets-store-csi-driver/issues/672↩
-
Helm Chartでデプロイされるdatadog agent(Pod)はhostPortでNodeの8126ポートにマッピングされます。アプリケーションは
status.hostIPでNodeのIPアドレス宛にデータを送るように案内されています。↩