



はじめに
こんにちは、ML・データ部MLOpsブロックの松岡です。
本記事ではCloud Composerのワークフローにおいて、GPUを使うタスクで発生したGoogle CloudのGPU枯渇問題と、その解決のために行った対策を紹介します。
ZOZOが運営するZOZOTOWN・WEARでは、特定の商品やコーディネート画像に含まれるアイテムの類似商品を検索する類似アイテム検索機能があります。本記事ではこの機能を画像検索と呼びます。
画像検索では類似商品の検索を高速に行うため、画像特徴量の近傍探索Indexを事前に作成しています。近傍探索Indexはワークフローを日次実行して作成しています。
このワークフローでは大きく次のように処理を行っています。
当日追加された商品の情報を取得し、商品情報をもとに商品画像を取得する。
物体検出器で商品画像から商品が存在する座標とカテゴリーを検出する。
検出した座標で、商品画像を切り抜き、画像の特徴量を抽出する。
特徴量からカテゴリーごとに、Spotifyが開発したPython製の近傍探索ライブラリであるAnnoyを使って近似最近傍探索Indexを作成する。
我々はこのワークフローをCloud Composer上に構築しています。Cloud ComposerとはGoogle CloudにおけるApache Airflowのマネージドサービスです。Cloud Composerには大きくCloud Composer 1とCloud Composer 2があり、画像検索のワークフローはより新しいCloud Composer 2に移行済みです。
Apache Airflowでは個別の処理をタスクとして記載し、タスク同士の依存関係を有向非巡回グラフ(Directed Acyclic Graph: DAG)として記載することでワークフローを定義します。本記事の中でもワークフローのことはDAGと記載します。
画像検索の近傍探索Indexを作成するDAGのなかで、物体検出と特徴量抽出のタスクはMLモデルを利用しており高速化のためにGPUを使用しています。
Annoyにつきましては、弊社テックブログの近傍探索ライブラリ「Annoy」のコード詳解もご参照ください。
今回はこのDAGを運用する中で発生した、Google Cloud内部のGPUリソース枯渇による課題と、その解決のために行った対策について説明します。
目次
GPUを使用する構成
まずDAGのタスクでGPUを使用する際のCloud Composer 2の環境構成について説明します。
Cloud Composer 2の環境はGoogle Kubernetes Engine(GKE)のAutopilotモードのVPCネイティブクラスタを利用して構築されます。
Airflowはタスクのスケジュールを行うスケジューラ、管理画面を提供するウェブサーバー、各タスクを実行するワーカーのコンポーネントにより構成されます。
各コンポーネントはCloud Composerが動作するクラスタ内のPodでコンテナとして実行されます。ワークロードの構成でCPU、メモリ、ストレージ、スケーリング台数を指定可能ですが、GPUの指定はできません。このように2023年9月現在Cloud Composer 2はGPUの利用をサポートしていません。
Cloud Composer 2環境の詳細については次の公式ドキュメントを参照してください。
そのためCloud Composer 2でGPUを使ったタスクを実行するには、ワーカーとは別にGPUが利用可能なインスタンスを用意する必要があります。画像検索では別途構築したクラスタにGPUが利用可能なNode poolを用意して、GPUが必要な処理をオフロードしています。
Cloud Composer 2のGKEStartPodOperatorを使用することで、Cloud Composer 2からGKEクラスタのPodを起動できます。ワーカーはPodを起動、監視しGPUが必要な処理はワーカーが起動したPodにて行います。
Podを起動する先として、Composerが動作するGKEクラスタとは異なるGKEクラスタも指定可能です。画像検索においても、Cloud Composer2が動作するGKEクラスタとは異なるGKEクラスタを指定しています。
GPUを割り当てたNodeが起動しないことによるタスクの失敗
ここからは画像検索のDAGを運用する中で発生した具体的な問題について述べます。
プロダクション環境のDAGにおいて、物体検出のタスクが失敗し、DAGが正常に終了しない問題が発生しました。物体検出は上述したGPUを使用するタスクの1つです。本節ではこのタスクの失敗について、実際に行った原因調査と暫定対応についてご説明します。
タスクが失敗した原因の調査
まず失敗の原因が環境起因か切り分けるために、プロダクション環境以外でも同様の問題が発生していないか調査しました。画像検索ではプロダクション環境の他に開発環境とステージング環境が存在します。ステージング環境ではプロダクション環境と同じDAGを日次実行しています。ステージング環境を調べると同様の問題がプロダクションと近い時刻に発生していることがわかりました。また並列化した全カテゴリーで同様にタスクが失敗していることがわかりました。
AirflowのWeb UI上から失敗を起こした物体検出のタスクが出力したログを確認すると次のエラーログが確認できました。
{pod_manager.py:310} WARNING - Pod not yet started: detect-object-pants-v3-830zvw9r
{pod_manager.py:310} WARNING - Pod not yet started: detect-object-pants-v3-830zvw9r
{pod_manager.py:310} WARNING - Pod not yet started: detect-object-pants-v3-830zvw9r
{pod.py:716} INFO - Deleting pod: detect-object-pants-v3-830zvw9r
{taskinstance.py:1770} ERROR - Task failed with exception
Traceback (most recent call last):
File "/opt/python3.8/lib/python3.8/site-packages/airflow/providers/cncf/kubernetes/operators/pod.py", line 548, in execute_sync
self.await_pod_start(pod=self.pod)
File "/opt/python3.8/lib/python3.8/site-packages/airflow/providers/cncf/kubernetes/operators/pod.py", line 510, in await_pod_start
self.pod_manager.await_pod_start(pod=pod, startup_timeout=self.startup_timeout_seconds)
File "/opt/python3.8/lib/python3.8/site-packages/airflow/providers/cncf/kubernetes/utils/pod_manager.py", line 317, in await_pod_start
raise PodLaunchFailedException(msg)
airflow.providers.cncf.kubernetes.utils.pod_manager.PodLaunchFailedException: Pod took longer than 1200 seconds to start. Check the pod events in kubernetes to determine why.
Pod took longer than 1200 seconds to start.のログからPodが起動時にタイムアウトしたことにより、タスクが失敗となった事がわかります。
PodのタイムアウトについてはCloud Composer 2の公式ドキュメントでKubernetesPodOperatorのトラブルシューティングガイドに記載があります。GKEStartPodOperatorのPodが起動するデフォルトタイムアウト時間は120秒ですが、物体検出タスクではモデルのロードに時間がかかるため次のように1200秒を設定しています。
GKEStartPodOperator(
startup_timeout_seconds=1200,
...
)
Podが起動しなかった原因について、再現性があるものなのか確認するためタスクをリトライしました。
通常であればPodが起動するのに十分な時間が経過しても、{pod_manager.py:310} WARNING - Pod not yet started:のログが出力され続けていました。
物体検出の処理を行うオフロード先のGKEクラスタに対してKubectl get podsを実行してPodのステータスを確認したところ、次の結果が出力されました。
NAME READY STATUS RESTARTS AGE detect-tops 0/1 Pending 0 60m detect-pants 0/1 Pending 0 60m ...
NodeのNodeAffinity、Toleration、コンテナに割り当てるResourceなどPendingの原因になりそうな項目は確認しましたが、問題ありませんでした。
Podのステータスについての詳細はKubernetes公式ドキュメントのPod Lifecycleをご参照ください。
上記でステータスがPendingとなっているPodの1つに対してkubectl describe podコマンドを実行し、Podの詳細な情報を確認しました。実行中のPodのデバッグについては実行中のPodのデバッグをご参照ください。
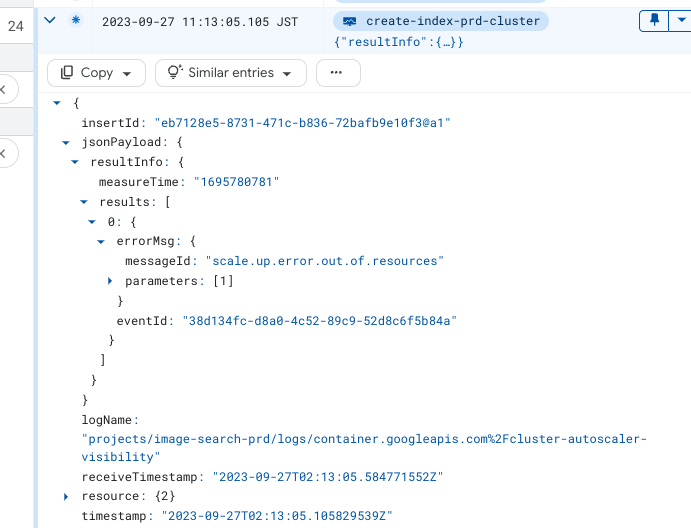
kubectl describe podsの出力結果のうちEventsフィールドに次のEventが確認できました。EventsフィールドにはPodの直近のEventが表示されています。KubernetesのEventはスケジューラによって行われた決定や、PodがNodeからEvictされた原因など、クラスタ内部で起こっている情報を提供します。
Node scale up in zones asia-east1-a associated with this pod failed: GCE out of resources. Pod is at risk of not being scheduled. Node scale up in zones asia-east1-a associated with this pod failed: GCE out of resources, GCE quota exceeded. Pod is at risk of not being scheduled. 0/2 nodes are available: 2 node(s) didn't match Pod's node affinity/selector.
GCE out of resources.との出力から、Google Compute Engine(GCE)のリソースを超えているとわかります。続くPod is at risk of not being scheduled.の出力から、Podはスケジュールされていない可能性があるとわかります。
続くログにGCE quota exceededと出力されています。メッセージからはGCEのQuota(割り当て)を超過していると受け取れます。
さらに2 node(s) didn't match Pod's node affinity/selector.が出力されています。このため、Podで設定したaffinity/selectorと一致するNodeのうち割り当て可能なものがなかったとわかります。
GCEでは割り当てによりGoogle Cloudプロジェクト単位で割り当てるリソースの上限が設定されています。割り当ての上限を超えるとGoogle Cloudプロジェクトへそれ以上のリソースが割り当てられなくなります。プロジェクトに割り当てられた割り当ての上限と、現在の使用量はナビゲーションメニューからIAMと管理を選び割り当てから確認可能です。
上述のログから割り当ての上限に達したことを想定していましたが、割り当ての状態を確認するとリソースの使用量は上限値まで余裕がある状態でした。またPodがデプロイされるNode poolのマシンタイプ等を変更したわけでもないため、Podはこれまで正常に動いていたスペックと同じスペックのNodeで実行されるはずです。
続いてGoogle CluodのWebコンソールからGKEのプロダクトページを開き、対象のPodが動作するクラスタの詳細を確認すると次の表示が出ていました。

表示の詳細を開くと表示の詳細を開くと次のメッセージを確認できました。

また詳細からログのリンク先に移動すると、Cloud LoggingのLogs Explorerから次のエラーメッセージを確認できました。
これらの調査から今回の問題の原因は、DAGの実装や構築したインフラの設定など開発者側の問題ではない可能性が高いと判断し、Cloudカスタマーケアにてサポートケースを作成しました。
サポートチームの回答と提案された暫定対応
Google Cloudのサポートチームからの回答により、事象が発生していた時間帯において、オフロード先のGKEクラスタが存在するasia-east1-aゾーン全体でnvidia-tesla-t4インスタンスのリソースが一時的に枯渇していたことがわかりました。
対応方法として別の時間帯でタスクをリトライし、正常に動作するか確認することを提案されました。
提案に従ってリトライを繰り返すと、問題の発生から4時間ほど経って一部のカテゴリーでnvidia-tesla-t4インスタンスを割り当てたNodeが起動しました。その後PodがスケジュールされステータスもRunningとなりました。
一方で引き続きPodがスケジュールされずPendingのままになっているカテゴリーもありました。このことから、nvidia-tesla-t4インスタンスのリソースはまだ完全に充実していないことが推測できます。
そこで同時に使用するGPUのリソース量を少しでも減らすため、先にRunningとなったタスクが完了してPodが終了するのを待ってから、Pendingとなっているタスクをリトライしました。するとPodがスケジュールされ、Runningになりました。
タスクの状態をAirflowのWeb UIで監視し続け、タスクが完了するたびに失敗となっているカテゴリーのタスクをリトライすることで、全カテゴリーの物体検出を完了させることができました。
ところがGPUの枯渇はその後も頻発しました。上記の方法により、GPUが枯渇するたびに人力でタスクの状態を監視してリトライを行うのは運用コストが大きすぎます。また人力での対応では復旧までの時間もかかってしまいます。そこで割り当て可能なGPUが枯渇し物体検出タスクを実行できない問題について、恒久的な対応を実施しました。
次章では実施した恒久対応について説明します。
Google Cloud内部のGPUリソース枯渇への対策
GKEPodOperatorはGPUが必要なタスクを実行するときに動的にNodeのリソースを確保します。タスクが終わるとNodeも終了するため確保されたリソースが開放されます。
一方でCompute Engine ゾーンリソースの予約を利用することでリソースを確保し続けることもできます。
しかしながら日次で実行されるDAGにおいて物体検出は30分から2時間程度で完了します。また、商品カテゴリー単位で物体検出のタスクを並列に実行しているため、同時に多くのGPUを必要とします。画像検索では現在対応カテゴリーが13カテゴリーあり、各カテゴリーごとに4GPUを割り当てており計52GPUを使用しています。
もし、52GPUを一日中確保し続けると、タスクが実行されていないほとんどの時間帯ではGPUが使用されないため、無駄なコストが発生してしまいます。そこでリソースの予約は行わずGPUリソース枯渇問題に対応する必要がありました。
対応1 GKEクラスタのロケーションタイプをゾーンからリージョンに変更する
GKEクラスタが動いているCompute Engineのリソースは世界中のロケーションごとにリージョンという単位で配置されています。リージョンにはゾーンというリソースの論理グループが3つから4つ用意されています、リージョン内のそれぞれのゾーンは広帯域のネットワークで接続されています。ゾーンごとに冷却インフラなどをグループ化することで、各ゾーンの障害が異なるゾーンに影響しづらくなるよう設計されています。
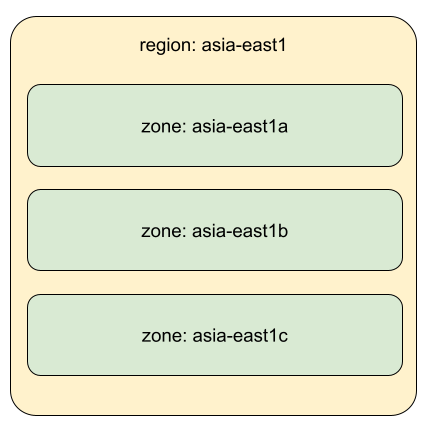
GKEクラスタのロケーションタイプには、リージョンタイプとゾーンタイプの2タイプがあります。ロケーションタイプにリージョンを指定することでクラスタは特定のゾーンに制限されなくなります。これによりCompute Engineはリージョン内の複数ゾーン間でリソースを適切に割り当てることができるようになります。
以前のバージョンであるCloud Composer 1のGKEPodOperatorではロケーションにゾーンしか指定できませんでした。Cloud Composer 2になり、ロケーションにリージョンも指定できるようになりました。画像検索は構築時にCloud Composer 1を使用していたため、これまでオフロード先にゾーンタイプのGKEクラスタを使用していました。画像検索は昨年Cloud Composer 2へのバージョンアップを行ったことで、リージョンタイプのGKEクラスタも使用可能となっています。そこで、オフロード先のGKEクラスタをリージョンタイプに切り替えます。
GKEクラスタのロケーションは一度構築すると変更できません。そのためリージョンタイプのロケーションを持つGKEクラスタを用意するにはGKEクラスタの再作成が必要です。
GKEクラスタを作成時にリージョンを指定することで、ロケーションタイプがリージョンのGKEクラスタを作成できます。
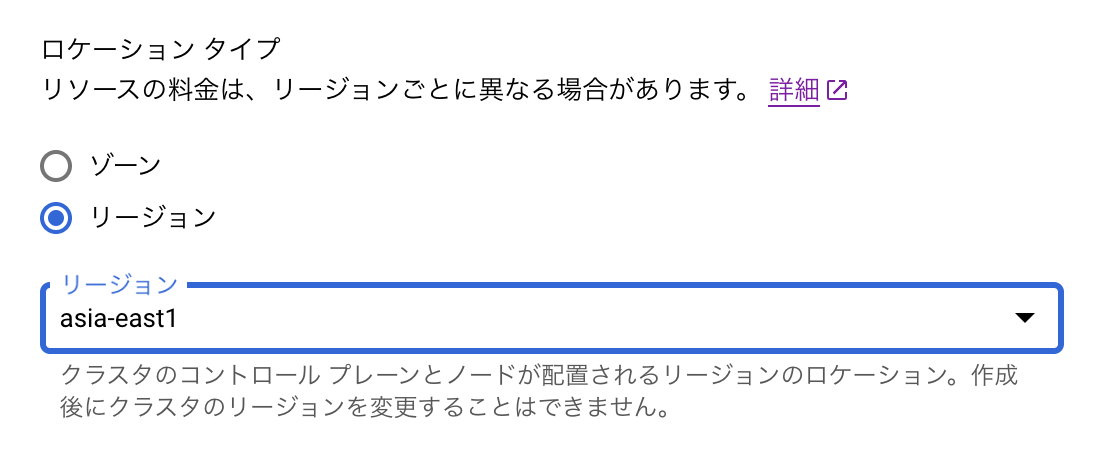
GPUに関しては全ゾーンにすべてのGPUプラットフォームのリソースが存在するわけではなく利用できるゾーンが限定されているため注意が必要です。今回はNVIDIA Tesla T4を使用するためデフォルトのノードのロケーションにasia-east1-aとasia-east1-cを指定します。

これによりオフロード先のGKEクラスタをリージョンタイプで再作成できました。
Cloud Composer 2からリージョンタイプのGKEクラスタへオフロードするにはGKEStartPodOperatorのlocationパラメータへゾーン名に変わってリージョン名を指定します。
GKEStartPodOperator(
location="asia-east1",
...
)
この対応により複数ゾーンのGPUを利用できるようになり、asia-east1-aのGPUインスタンスリソースが枯渇しているときでもasia-east1-cのリソースを使用可能になりました。
対応2 Composerタスクのリトライ間隔を最適化する
Airflowはタスクが失敗すると、一定期間をおいて自動でタスクをリトライさせます。今回の物体検出タスクが失敗した際にも、Airflowは自動的にタスクをリトライしていました。
しかしGPUの枯渇が長時間に及んだことで、リトライ回数の上限を超えてしまいタスクが失敗していました。失敗とマークされたタスクは、それ以降は自動的にリトライされなくなります。その場合手作業でタスクをリトライしなければなりません。
GPUの枯渇と回復は前触れなく発生するため、手作業での対応は手間と時間がかかり望ましくありません。タスクが失敗していることに気が付かなければリトライされない危険もあります。GPUの枯渇は週末に発生することが多く、タスクの失敗に気が付きにくいため問題はより深刻でした。
そこで、リソースが回復されるまでより幅広い時間に渡ってリトライするよう設定の見直しを行いました。それにはリトライ回数を増やすか、リトライ間隔を広げる方法が有効です。ただしこれらの対応にはそれぞれ弊害もあります。
リトライ回数を増やすと問題発生時、余計なコストを発生させる場合があります。一般的にタスクの失敗はリトライのみで解決するとは限りません。今回の原因以外にも入力データの不備により失敗することもあります。この場合データを整備して原因を解消してからリトライしなければ、タスクは失敗とリトライを繰り返してしまいGPUリソースを長時間使用し続けることになります。
リトライ間隔を広げるとタスクが失敗した時の復旧に時間がかかるようになります。一時的な問題が原因でタスクが失敗した場合など、直後にリトライすることで解決する問題も多くあります。長すぎるリトライ間隔はこのような場合に復旧が遅れる原因となってしまいます。
そのためまずは短い間隔でリトライし、リトライ時にもタスクが失敗した場合はリトライ間隔を広げていくExponential backoffを行います。
タスクのリトライでExponential backoffを有効にするには、Airflowのretry_exponential_backoffを設定します。
retry_exponential_backoffにTrueを設定すると、リトライ回数に応じてリトライ間隔が指数関数的に増加します。例えばリトライ間隔に60秒を設定した場合、最初のリトライは60秒、2回目は120秒、3回目は240秒となります。これにより、直後にリトライすれば解決する偶発的な問題では最初に短い間隔でリトライが行われます。最初のリトライで解決しなかった場合はリトライ間隔が広がることで、リトライ回数を増やすことなく、長期間に渡ってリトライが行われます。
retry_exponential_backoffの指定はDAGを定義するスクリプトに記述します。retry_delayを60秒とし、retry_exponential_backoffをTrueに設定するには次のように記述します。
dag = models.DAG(
"YOUR_DAG_NAME",
default_args={
"retry_delay": 60,
"retry_exponential_backoff": True,
...
)
注意すべき点としてリトライ間隔が指数関数的に増加するため、リトライ回数が増えると間隔が必要以上に広がりすぎてしまうことがあります。例えばリトライ間隔を60秒に設定している場合、10回目のリトライではリトライ間隔が8時間以上まで広がってしまいます。これではリソースが空いてもすぐにリトライが行われず、再度割り当て可能なリソースがなくなってしまう恐れもあります。
このような事態を避けるために、retry_exponential_backoff に合わせてmax_retry_delayを設定します。これによりリトライ間隔に上限を設定できます。
dag = models.DAG(
"YOUR_DAG_NAME",
default_args={
"retry_delay": datetime.timedelta(minutes=1),
"max_retry_delay": datetime.timedelta(minutes=30),
"retry_exponential_backoff": True,
...
)
今回はmax_retry_delayに30分を設定したことで6回目のリトライ以降はリトライ間隔が広がらず30分ごとにリトライされます。
これによりリトライ回数を大きく増やすことなく、リトライを幅広い時間帯で行えるようになり、GPUのリソースが枯渇した場合にもリトライで復旧できる可能性が高まります。
対応3 各タスクが使用するGPU数を最適な値に調整する
タスク自体を見直し、同時に必要なGPU数を減らすことでGPUの枯渇が発生した場合の影響を低減します。
前述のとおり画像検索では13カテゴリーそれぞれで4GPUを使用し物体検出のタスクを行っており、一度に52GPUをリクエストしていました。このように大量のGPUを使用していたのは、インスタンスの使用コストがリソースのGPU数だけでなく使用時間にも比例するためです。1GPUで52時間かけて処理を行うのも、52GPUで1時間かけて処理を行うのも、どちらも利用するGPUのリソース量は52時間となります。一方で処理時間は52時間から1時間に短縮できます。このためリソースが充分に使用できる場合においては一度に大量のGPUを使用するのは妥当な方法と言えます。
しかしNodeに割り当て可能なGPUが枯渇した状態では、大量のGPUをリクエストするとタスク自体が動作しません。そのため上記の方法を見直し、同時に使用するGPU数を削減しました。
単純にGPUの数を減らすと、処理時間が犠牲になってしまいます。処理時間を犠牲にしないためカテゴリーごとの商品数に着目しました。ZOZOTOWNで取り扱う商品数はカテゴリーごとに差があり、必要な処理時間も異なります。商品数が少ないカテゴリーは物体検出が早く終わり、商品数が多いカテゴリーの物体検出が終わるまで待ち状態となっていました。
そこで商品数が少ないカテゴリーの物体検出で使用するGPU数を減らします。
直近の商品数を調べるとトップスカテゴリーの商品数が1番多く、続くパンツはその半分より少なく、それ以外の各カテゴリーはパンツのさらに半分以下でした。
そのためトップスにはこれまで通り4GPUを割り当て、パンツはその半分の2GPU、それ以外のカテゴリーは1GPUを割り当てることにします。カテゴリーによってはこれまでの4倍の時間がかかりますが、元々商品数が多いカテゴリーの物体検出が終わるまでは待ち状態となっていたため、トータルの処理時間は変わりません。
これにより全体の処理時間に影響なく、同時に割り当てるリソースを最大52GPUから17GPUにまで減少させることができました。
対応4 同時に実行するタスク数を制御し必要なGPU数を更に下げる
GPU枯渇後の復旧時には全カテゴリーのタスクを同時に実行できず、一部カテゴリーのPodはPendingとなっていました。このため先に実行されているタスクの終了を待機し、終了したらPodがPendingとなっているタスクをリトライする必要がありました。この方法はGPU枯渇の対策に効果的でしたが、人力の作業であったため運用面での問題となっていました。
この問題を解決するため全カテゴリーのGPU使用量に応じて、自動的にタスクを実行する仕組みを構築します。対策3により使用するGPU数はカテゴリーごとで異なっているため、それも考慮して同時に実行するタスクを制限します。
タスクの並列数を自動的に監視し、制御するために、AirflowのPoolを利用します。PoolはAirflowのスケジューラがタスクの実行を管理するために使用する仮想的なリソースです。
Airflow全体で使用できるPoolとPoolが持つSlot数を設定し、タスクには使用するPoolと消費するSlot数を指定します。タスクが開始されると、指定されたPoolのSlotが消費されます。タスクが終了するとPoolのSlotが復活します。
スケジューラはタスクの消費するSlotがPoolに残っていない場合にはタスクの開始を待機します。その場合でもタスクは失敗となりません、そのためリトライ間隔が広がったり、リトライ回数を超えることはありません。他のタスクが終了し待機していたタスクの消費するSlotがPoolに確保されるとタスクは開始されます。
これにより17GPU未満しか割り当たらない場合でも、他タスクのGPU使用量を考慮してタスクをスケジュールできます。
今回はgpu_poolというPoolを設定し、同時に割り当て可能なGPU数をPoolのSlot数として設定します。
AirflowのWeb UIからメニューのAdminを選びプルダウンのPoolsを選ぶと、Poolsの設定画面が表示されます。
Composer 2の標準ではdefault_poolというPoolが設定されており、Slotsに100000が設定されています。+ボタンをクリックすると新しいPoolを追加できます。
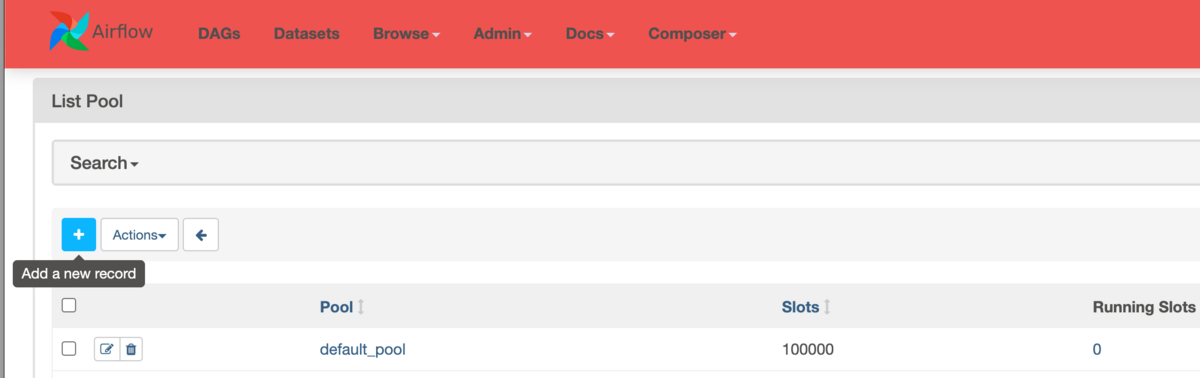
PoolにPool名、Slotsに使用可能なSlot数を指定します。今回はgpu_poolというPoolを追加し、割り当て可能なGPU数をSlot数として指定します。
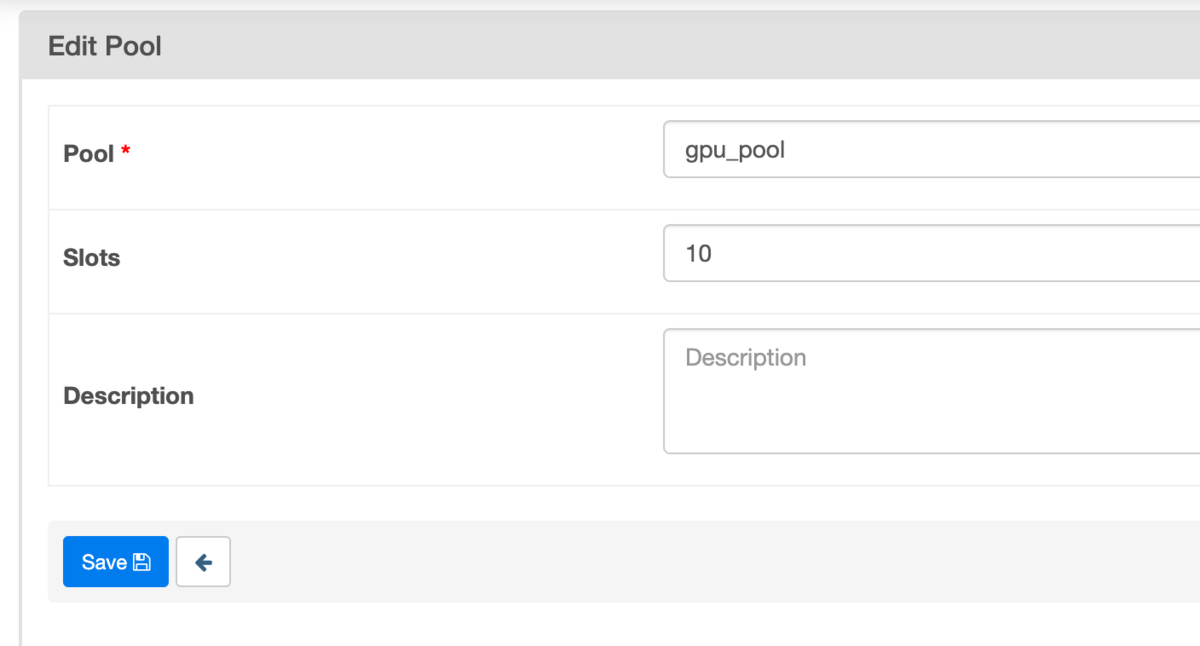
次にGKEStartPodOperatorのパラメータpoolに使用するPool名を指定し、pool_slotsに使用するGPU数(トップスは4、パンツは2、それ以外は1)を指定します。
GKEStartPodOperator(
...
pool="gpu_pool",
pool_slots=1
)
カテゴリーごとに使用するGPUの数に合わせて消費するSlot数を指定することで、タスクで使用するGPU数に応じて同時実行数が調整されます。
例えばSlotに4が指定されているときは、トップスの物体検出中は他カテゴリの処理は開始されません。トップスの処理が終わると、パンツとその他カテゴリが2カテゴリー同時に実行されます。
これにより人力による監視を必要とせず、使用可能なGPUを有効に使えるようタスクを順番にスケジュールし、全タスクを完了できるようになりました。
対応5 前日のDAGが完了するまで翌日のDAG実行を遅延する
GPUがNodeへ割り当てられるのに時間がかかるようになったことで、DAGの総実行時間が1日を超える日が出てきました。
画像検索では前日のDAGが作成した結果のデータを利用して、翌日のDAGでは新たに追加された商品のみを差分で計算することで、処理量を減らす差分実行の仕組みを導入しています。そのため前日のDAGがデータを作成する前に翌日のDAGが実行されると、翌日のDAGは前日のDAGが作成したデータを利用できなくなってしまいます。この問題を防ぐために、前日のDAGが完走するまで、翌日のDAGが実行されないようにします。
これを実現するためにAirflowのmax_active_runs_per_dagを使用します。max_active_runs_per_dagは同一のDAGが同時に実行できる数を制限します。これに1を指定すると、同一のDAGが複数起動しなくなるため、前日のDAGが完了するまで翌日のDAGは開始されなくなります。
max_active_runs_per_dagを設定するにはコンソールのナビゲーションメニューからComposerを開き、名前を選択してAirflow構成のオーバーライドタブで編集ボタンを押下します。
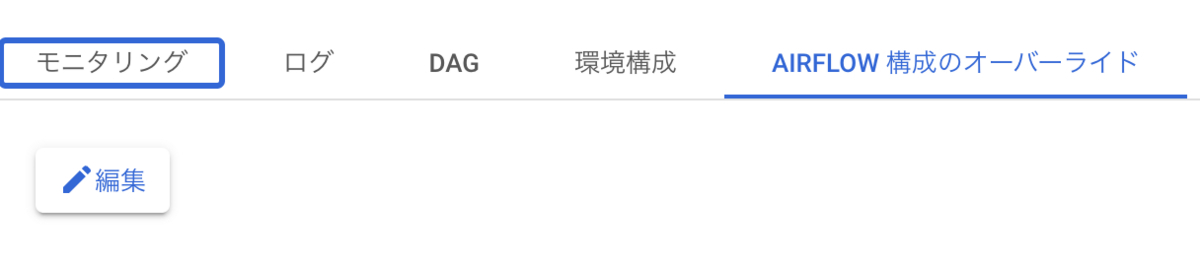
AIRFLOW構成のオーバーライドを追加を押下し、セクションでCore、キーにはmax_active_runs_per_dagを選んで値を1に設定します。
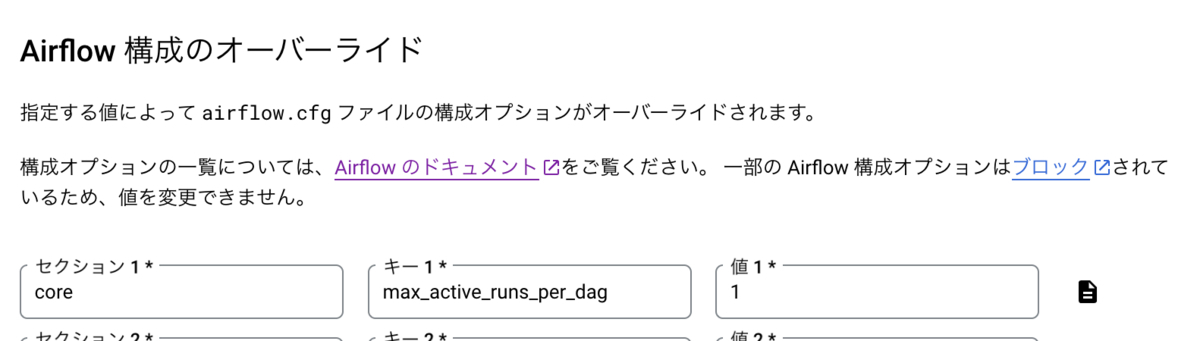
これにより前日のDAGが完了する前に、翌日のDAGが実行されてしまう問題を防止できるようになりました。
対応6 前日のDAGが正常に完了していることを確認する
max_active_runs_per_dagは同時に実行するDAGの数を制限するだけで、DAGの成否について考慮しないことに注意が必要です。もし前日のタスクが失敗し、DAGがFailedで終了しても、他に実行しているDAGがなければ翌日のDAGは実行されてしまいます。
これでは前日のデータが存在しない状態で翌日のDAGが動いてしまう問題を完全には防止できません。そこでDAGの冒頭で前日のDAGがSuccessで完了していることを確認するタスクを追加します。
DagRun.find()を使用することで他のDAGの状態を取得できます。自身のDAG_IDと一致するDAGの状態を取得し、実行日の降順でソート、今回の実行日より前に開始された最初のDAGを調べることで、前回実行されたDAGのステータスを取得できます。前回実行されたDAGのステータスがSuccessでない場合にはタスクを失敗としDAGの処理がそれ以上実行されないようにします。
def check_yesterday_state(**context): ds = datetime.datetime.strptime((context["ds"]), "%Y-%m-%d").astimezone(datetime.timezone.utc) dagruns = DagRun.find(dag_id=<DAG_ID>) dagruns.sort(key=lambda x: x.execution_date, reverse=True) for dagrun in dagruns: if dagrun.execution_date < ds: if dagrun.state == State.SUCCESS: return else: raise Exception("Previously ( Usually yesterday ) started DAG has not completed yet.")
これにより前日のDAGが失敗したときに翌日のDAGが実行されるのを防ぐことができました。
まとめ
本記事ではCloud Composer 2でGPUを使うタスクで発生したGPU枯渇問題とその対策について紹介しました。
リージョンタイプのGKEクラスタへの移行と、各タスクが使用するGPU数を最適な値に調整したことにより、GPU枯渇を大きく減らすことができました。
本番環境において発生したGPU枯渇は、対策前の30日間で24回発生していたのに対し、対策後の直近30日では6回に抑えられています。またその6回いずれの場合においても自動的にリトライが行われ手作業を必要とせずDAGを正常終了できています。
ステージング環境でDAGが正しく動作しなかった際には、翌日のDAGが実行前に停止しており、差分データを取得できない問題も未然に防ぐことができました。
今後も、さらなる改善により低コストで安定したシステムを構築していきたいと考えています。
終わりに
最後までお読みいただきありがとうございました。
ZOZOでは一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、次のリンクからぜひご応募ください。