



12月1日〜12月5日にラスベガスでAWS re:Invent 2025が開催され、ZOZOのエンジニアが5名参加しました。この記事の前半では熱気に溢れる会場の様子を、後半では面白かったセッションについてご紹介します!
- AWS re:inventとは
- 現地の様子
- セッションレポート
- Build observable AI agents with Strands, AgentCore, and Datadog (AIM233)
- SEC320-R: The AWS Security Incident Response Challenge: Defend the Cake!
- Accelerate platform engineering on Amazon EKS (CNS301-R1)
- Using Amazon Q to Cost Optimize Your Containerized Workloads (CMP348)
- Infrastructure Innovations (KEY004)
- Advanced AWS Network Security : Building Scalable Production Defenses [REPEAT] (SEC303-R1)
- The Kiro coding challenge (DVT317)
- Ditch your old SRE playbook: AI SRE for root cause in minutes (sponsored by Resolve AI) (AIM260-S)
- [NEW LAUNCH] Resolve and prevent future operational issues with AWS DevOps Agent [REPEAT] (DVT337-R1)
- おわりに
AWS re:inventとは
re:InventはAmazon Web Services(AWS)が主催するAWS最大のカンファレンスです。このイベントでは、AWSが提供する様々なクラウドサービスに関する新サービスやアップデートが発表されます。
2025年は世界中から約60,000人以上が、日本から昨年と同程度がラスベガスに集まりました。今年のre:Inventでは、「AIアシスタントからAIエージェントへ」という転換点を象徴するイベントでした。
現地の様子
メイン会場
The Venetian Resort Las Vegasがメインの会場となっており、KeynoteやEXPO、Swag(ノベルティ)など様々なコンテンツがここに集合しています。そんな会場で出会った様々なコンテンツをご紹介いたします!
メイン会場では、AWS re:Invent会場への入口案内があり、この時点ですでに私たちはテンションがとても上がっていました。周りの参加者からも笑い声や笑顔で写真を撮る人も多くとてもよい空間となっていました。

メイン会場に入ると、大きな黒板がありチョークで好きなように描けました。たくさんの参加者がここで社名を書き記念撮影を行なっていました。イベントが行われる5日間このブースもとても盛り上がっていました。


メイン会場で特に盛り上がっていたブースはKiroのお化け屋敷でした。筆者もお化け屋敷に入りました! コーディングによるバグやエラーなどがホラー演出として現れ、それをKiroが救ってくれるといった内容だったと思います。このお化け屋敷を抜けた後に、記念写真をとってもらい、さらにKiroのSwagもいただきました!

メイン会場にはAWSの公式グッズが売っているショップもありました! シャツやパーカー、リュック、タンブラーなど様々な商品が売っておりどれも魅力的でした! 来年参加される方はぜひ立ち寄ってみてください!

メイン会場には2日目から世界的な企業がブースを構えているEXPOエリアがオープンします!

各企業のブースに行って、議論を交わしたりサービスの説明を受けたりしました。
アンケートに答えたりゲームをクリアしたりするとSwagがもらえます。現地参加したメンバーもSwag集めを楽しんでいました!
特にResolve.aiさんのブースでは、オリジナルのパーカーに目の前で自分の名前を印字してくださる企画が開催されており、長蛇の列ができていました!

どの企業もブースやSwagに力を入れており、持って帰るのがかなり大変でしたが、様々な企業の話も聞けて楽しかったです!

朝食や昼食
re:Inventの会期中は、朝食や昼食が各会場で提供されていて、参加者なら無料で食べられます! ビュッフェ形式なので好きなものを食べられました!

さらに、セッション会場の通路で定期的に軽食も提供されます。Workshopなど長めのセッションに参加する時は、軽食やコーヒーを持ち込んで栄養補給しながら臨みました!

Sports Forum
AWSがスポーツ領域でどのようにクラウドやAIを活用しているか、展示・セッション・体験ブースを通じて体感できるSports ForumというイベントゾーンがCaesars Forum会場で開催されていました!

F1からNBAまで様々なスポーツでの技術活用例が展示されており、セッションの合間のリフレッシュにもなり、とても楽しい空間でした。eSportsのRiot Games社も展示しており、ゲームを体験できるスペースも用意されていました。


無料のStarbucks Coffee
re:Invent参加者には、会場であるVenetian内のスターバックスでドリンクとフード、合わせて4点までが無料で提供されます! 朝8:30くらいに行った際は30分ほど並んだので、時間に余裕のある方はぜひお立ち寄りください!

AWS主催のパーティ


初日(12/1)は、「APJ Kick Off Party」に行ってきました。本イベントはアジア太平洋地域と日本からre:Inventに参加する方向けのAWS公式のネットワーキングイベントです。ラスベガスのナイトクラブで行われます。今年の出演はマーク・ロンソンさんでした。ブルーノ・マーズさんとの「Uptown Funk」など、大ヒット曲を生み出しています。
また、最終日前日、12/4には「re:Play」というパーティーが行われました。これはre:Inventのフィナーレのようなもので、大きな広場を使い行われました。日付が変わるまでパーティーでした。最後を締め括ったのはDJのKASKADEさんで、会場は大盛り上がりでした!
セッションレポート
ここからはre:Inventの参加メンバーが気になったセッションを紹介します。
Build observable AI agents with Strands, AgentCore, and Datadog (AIM233)
SRE部 カート決済SREブロックの小松です。ZOZOTOWNのカート決済機能のリプレイス・運用・保守に携わっています。また、全社のAWS管理者としての役割も担っています。
今回は興味を持っていたサービスの1つであるStrands AgentsとAmazon Bedrock AgentCoreについて、AIエージェントの本番運用に向けたObservability(可観測性)の観点から紹介されたセッションに参加しました。
DatadogのSr. Technical AdvocateであるKunal Batra氏と、AWSのSr. Developer AdvocateであるDu'An Lightfoot氏による共同セッションで、その内容について簡単ではありますがご紹介します。

AIエージェント運用の課題
セッション冒頭では、AIエージェントをスケールで運用する際の課題が紹介されました。

- Hallucinations & Quality: LLMが不正確な情報を生成する可能性があり、継続的な評価と修正が必要
- Complexity: エージェントは複合システムであり、内部の動作が見えないとトラブルシューティングが困難
- LLM Costs: 本番ワークロードではコストが容易に膨らむ
- Security & Safety: プロンプトインジェクションやデータ漏洩のリスク
特に印象的だったのは、エージェントが「非決定的(non-deterministic)」であるという点です。同じ入力でも異なる出力を返す可能性があり、従来のソフトウェアとは異なるアプローチでの監視が必要になります。

Strands AgentsとAgentCore
続いて、AWSが提供する、エージェント構築・運用ツールが紹介されました。Strands Agentsは、わずか数行のコードでエージェントを構築できるオープンソースのPython SDKです。モデルに依存せず、MCPやA2Aプロトコルもサポートしています。

Amazon Bedrock AgentCoreは、エージェントを本番環境にデプロイするための包括的なプラットフォームです。
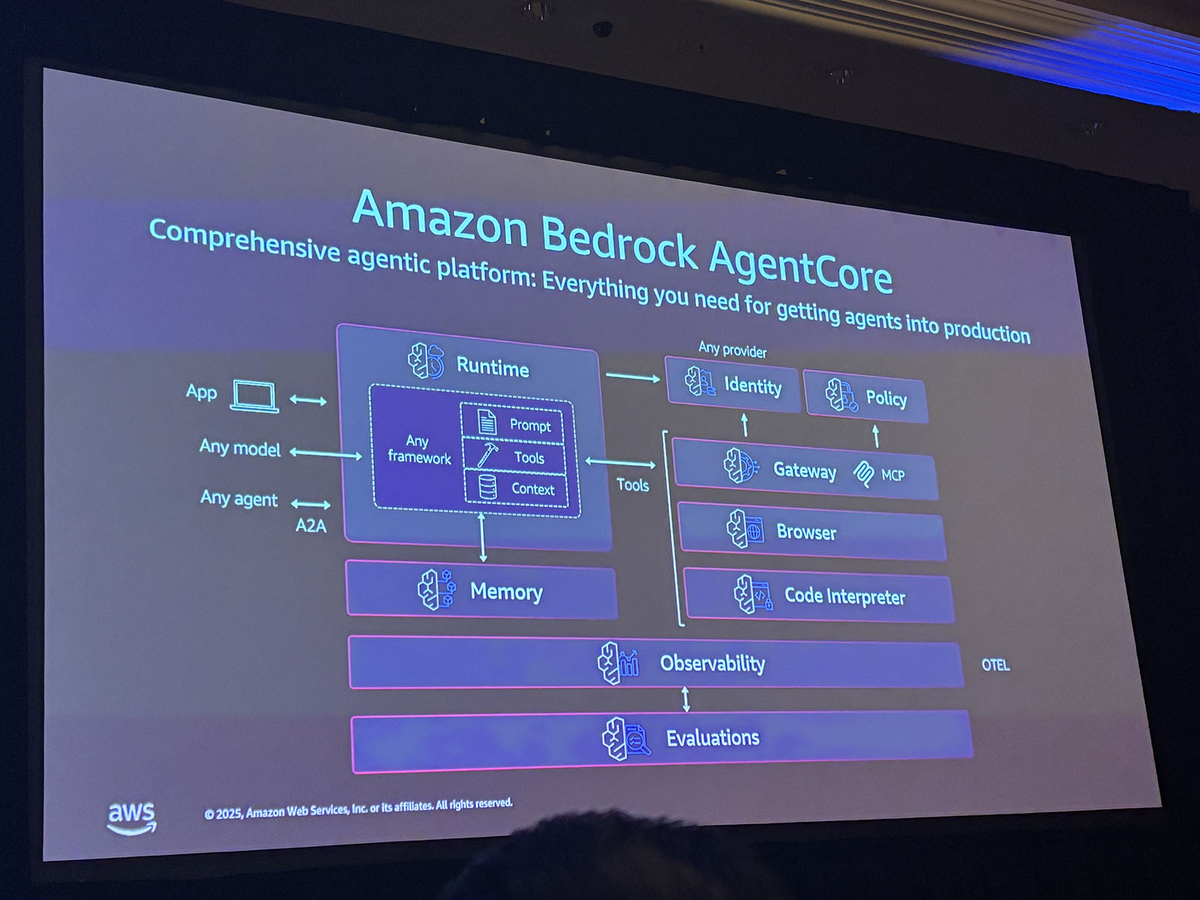
AgentCoreは以下のコンポーネントを提供します。
- Runtime: エージェントのホスティング環境。DockerfileまたはCode-zipでデプロイ可能
- Memory: 短期記憶(チャット履歴、セッション状態)と長期記憶(セマンティック、ユーザー設定、エピソディック)
- Observability: OpenTelemetry(OTEL)ベースのテレメトリ収集
- Identity/Policy/Gateway: セキュリティとアクセス制御
デモ:AWS Newsletter Agent
セッションではAWS Newsletter Agentを使ったデモが行われました。このエージェントはAWSの最新ニュースを取得し、AIに関連するアップデートをフィルタリングしてニュースレターとして配信します。
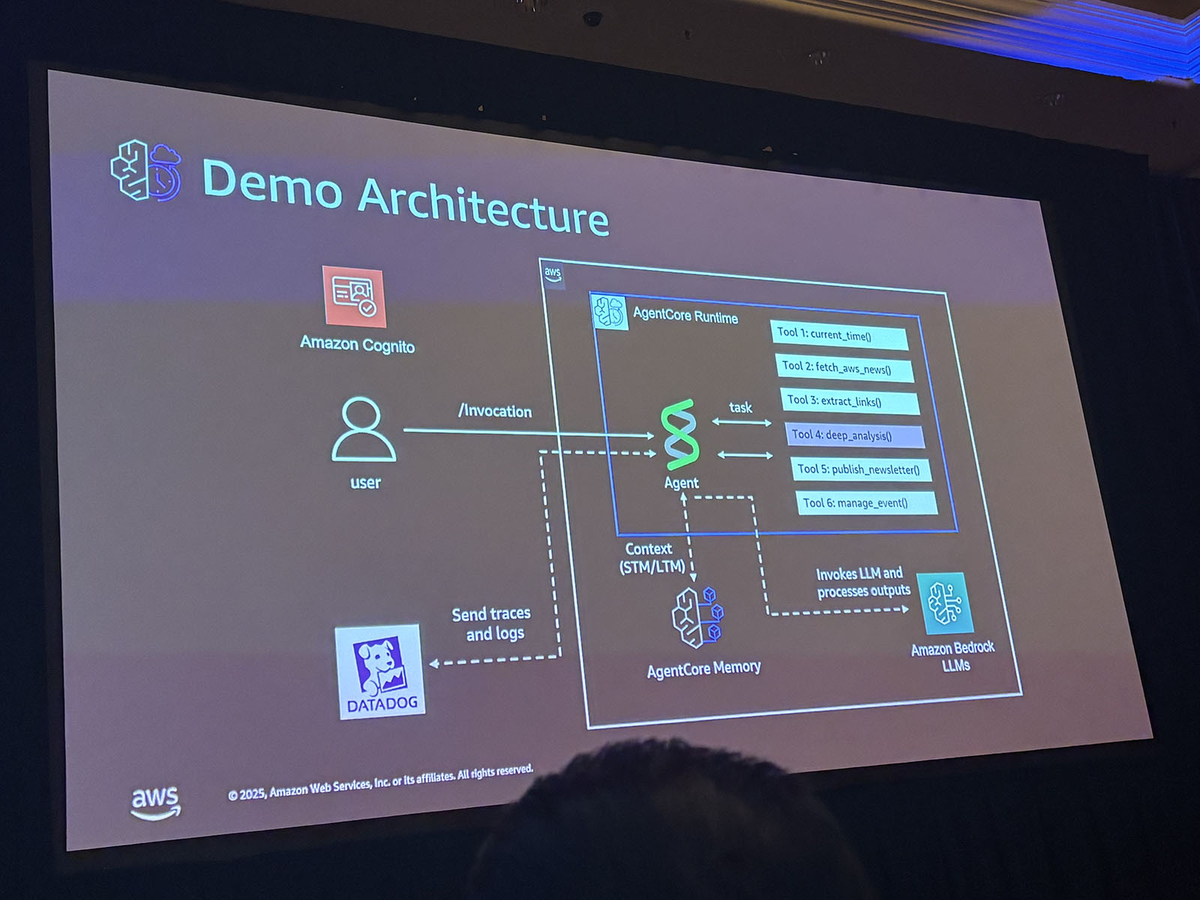
デモでは、以下のような流れが紹介されました。
- ユーザーが「What's new in AWS today?」と質問
- エージェントが
current_timeとfetch_aws_newsツールを実行 - AI/MLに関連するニュースを抽出してサマリーを生成
- ニュースレターをメールで送信
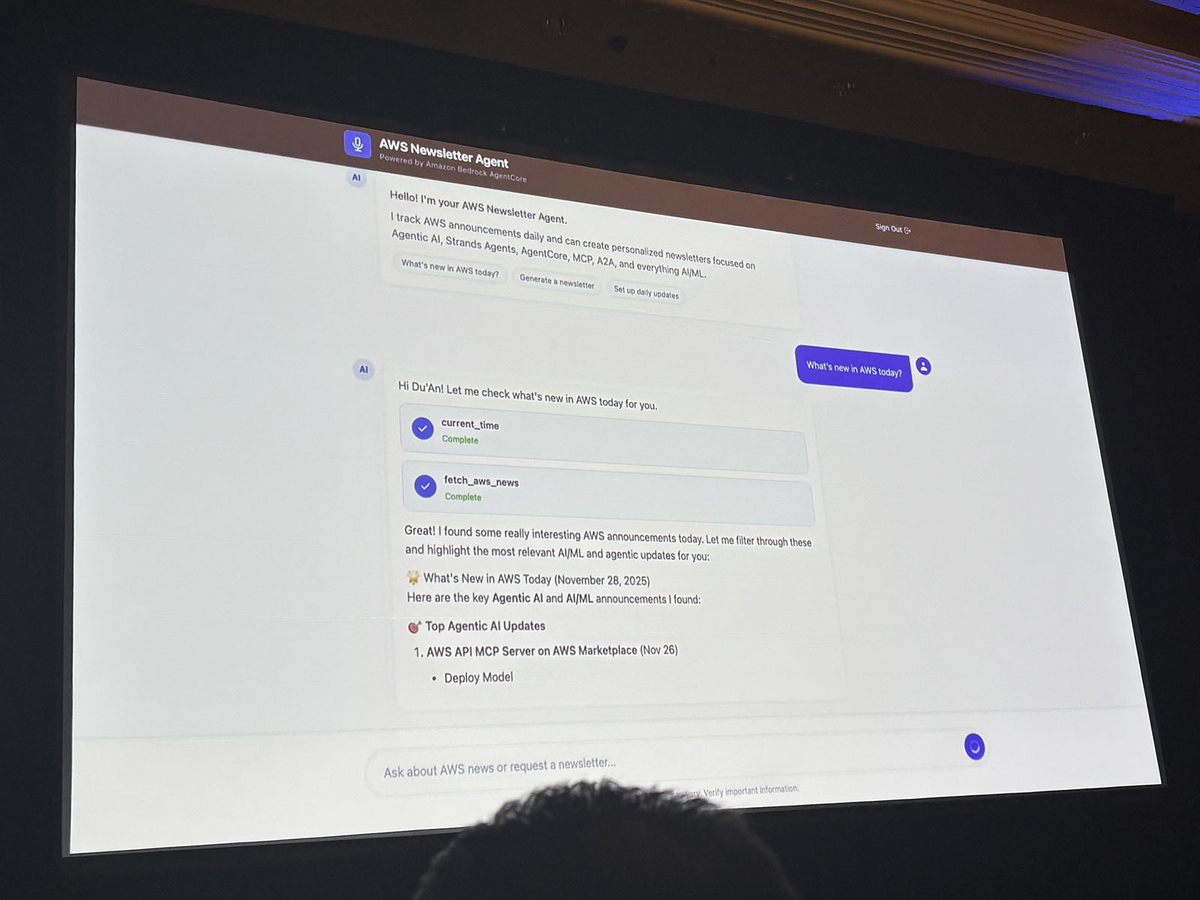
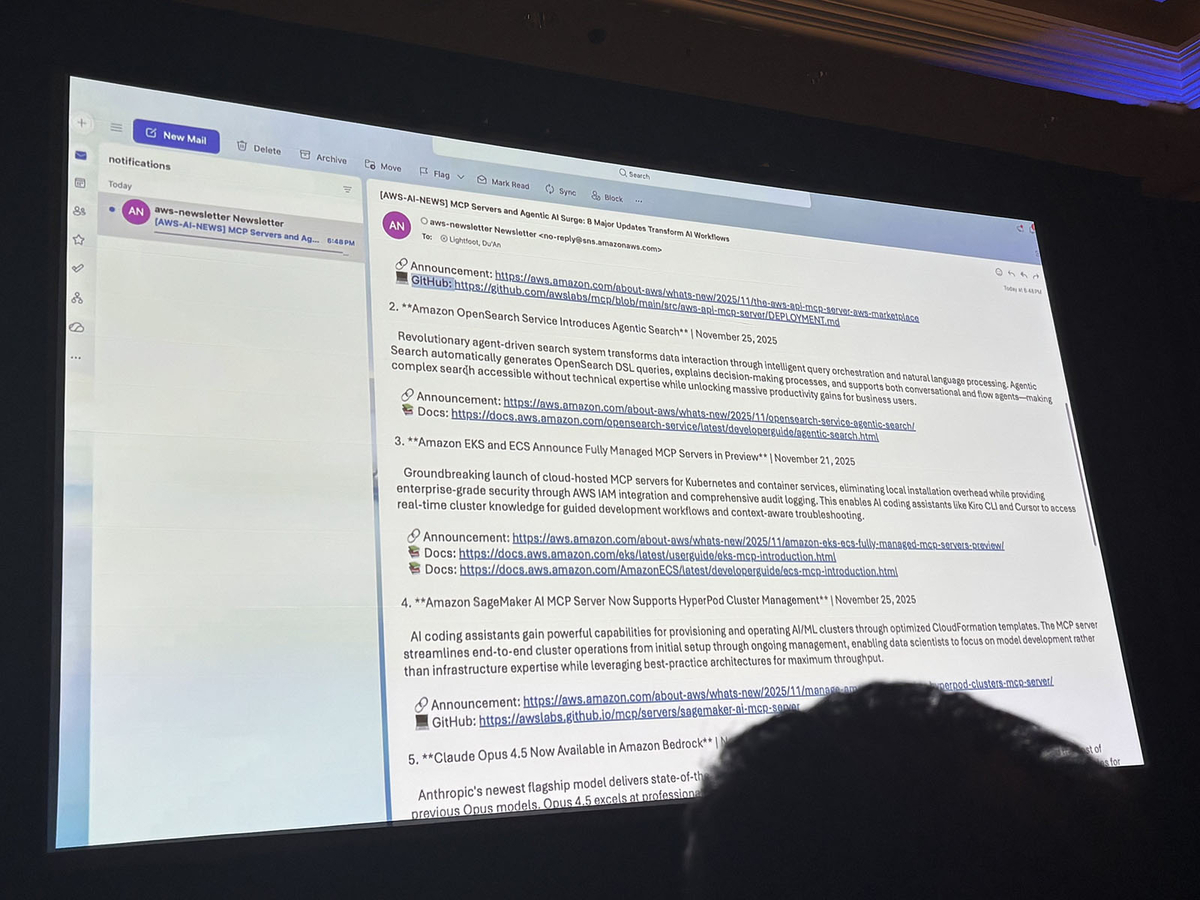
さらに、エージェントが自然言語の指示だけでEventBridgeのスケジュールを作成し、毎日自動でニュースレターを配信する設定まで行っていました。
AWS Well-Architected Framework - Generative AI Lens
セッションでは、AWS Well-Architected FrameworkにGenerative AI Lensが2025年に追加されたことも紹介されました。
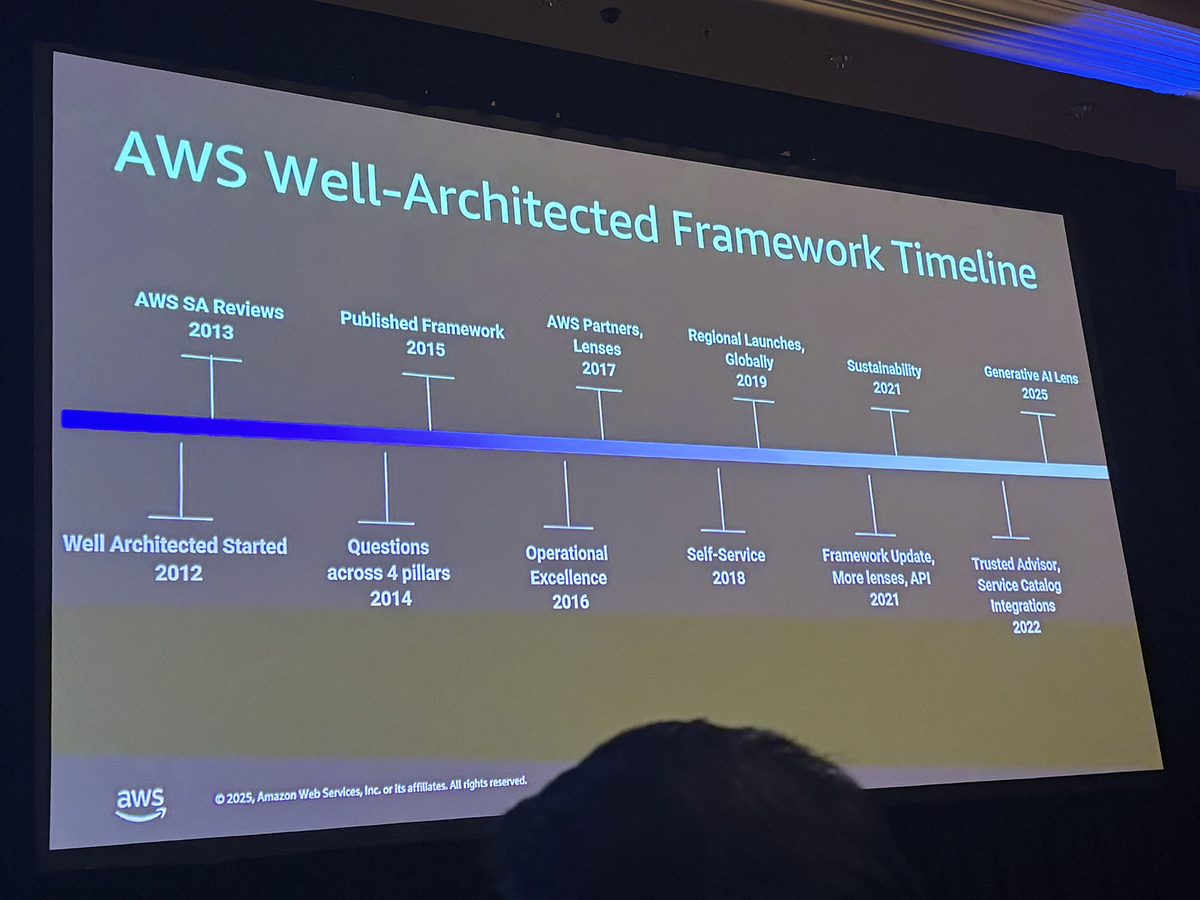
6つの柱それぞれにAIエージェント向けのベストプラクティスが定義されています。
- Operational Excellence: 包括的なObservabilityの実装
- Security: 安全で責任あるアウトプットのためのGuardrails
- Cost Optimization: 長時間実行ワークフローにおける停止条件の設定
DatadogによるLLM Observability
セッション後半では、Datadogを使ったAIエージェントの監視デモが行われました。
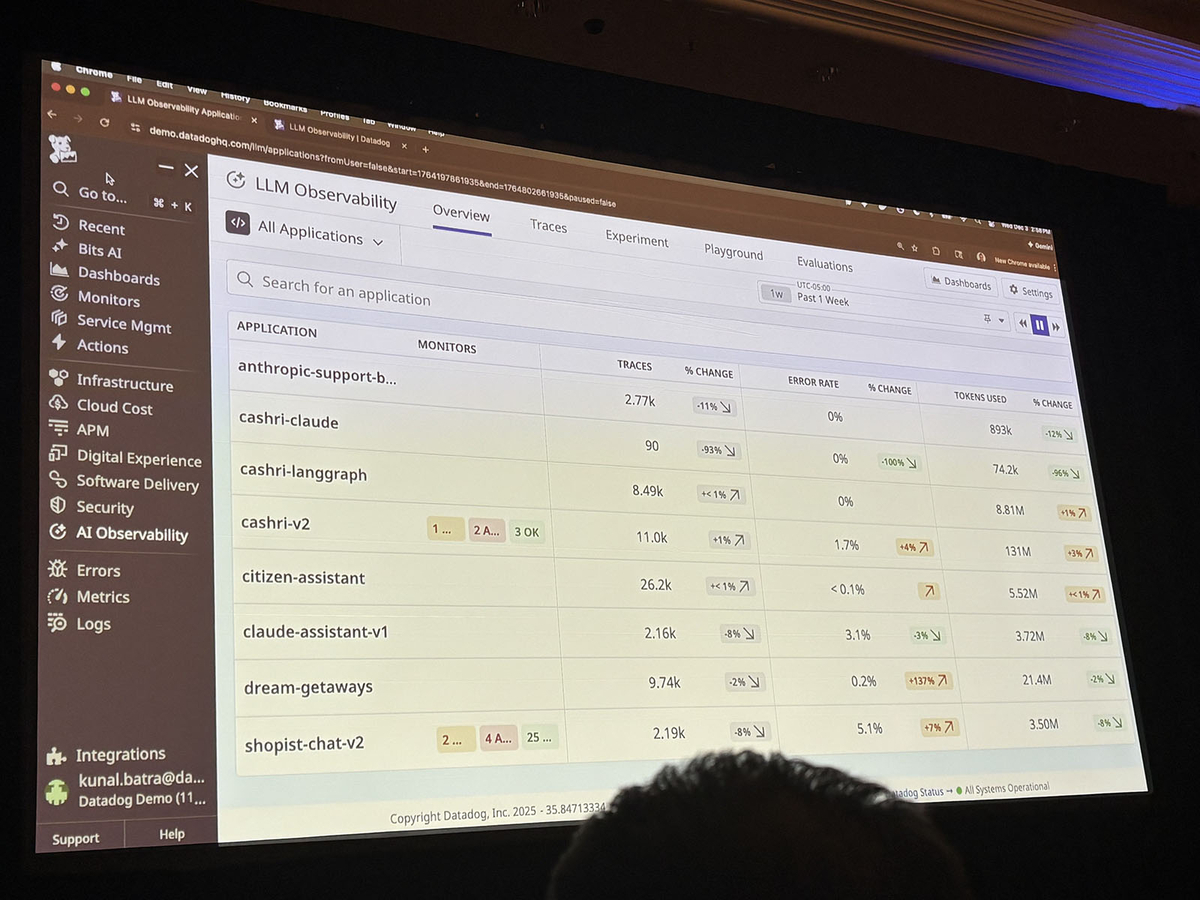
DatadogのLLM Observabilityでは、以下のような情報を一元的に確認できます。
- Summary: エラーレート、LLM呼び出し回数、トークン使用量の概要。
- Evaluations: エージェントの応答品質を評価。「Failure to Answer」の割合や、カスタム評価(Financial Advisory Compliance Checkなど)の結果を確認できる。
Cost: トークン使用量とコストの推移。最もコストがかかっているモデル呼び出しを特定できる。
Traces: エージェントの処理フローを詳細に追跡。特に印象的だったのは、マルチエージェント構成(Budget Guru → Triage Agent → Prompt Injection Agent → PII Detection Agent)の各ステップが可視化されている点。
Security & Safety: プロンプトインジェクション、出力の有害性(Toxicity)、PII(個人情報)の検出状況を監視できる。
- Experiments: 異なるモデルやプロンプトを比較して、品質・コスト・レイテンシのトレードオフを分析できる。Claude Haiku 4.5など複数モデルが比較されていた。
まとめ
AIエージェントを本番運用する上で、従来のアプリケーション監視とは異なる観点が必要だと実感しました。特に以下の点が印象に残っています。
- 非決定性への対応: 同じ入力でも出力が変わるため、品質評価の自動化が重要
- コスト可視化: トークン単位でのコスト追跡により、予期せぬコスト増加を早期に検知
- セキュリティ監視: プロンプトインジェクションやPII漏洩のリアルタイム検出
- マルチエージェントのトレース: 複数エージェントが連携する場合、処理フローの可視化が不可欠
弊社でもAIエージェントの活用を進めていますが、本番運用に向けてはObservabilityの整備が重要な課題になりそうです。StrandsとAgentCore、そしてDatadogの組み合わせは、その解決策の1つとして検討していきたいと思います。
SEC320-R: The AWS Security Incident Response Challenge: Defend the Cake!
このWorkshopは、架空の企業「Unicorn Cake Company」のセキュリティチームとして、攻撃者(Grumpy Cats)から秘密のレシピを守るという、ゲーム形式で楽しみながらセキュリティインシデント対応を学べる内容でした。

このWorkshopでは、Blue Teamとして、AWS Lambdaで実装されたRed Teamの攻撃を防御するシナリオをシミュレートします。30分の準備期間の後、攻撃が開始され、リアルタイムで対応していく形式です。

画像引用元: Workshop参加者向けに用意されたページの画面をスクリーンショット
ストーリー設定:Unicorn Cake Companyを守れ!
参加者は「Unicorn Cake Company」という架空のケーキ製造会社のクラウドセキュリティチームとして参加します。この会社はユニコーン向けの魔法のケーキを製造しており、その秘密のレシピ「UnicornCakesSecretRecipe.txt」が攻撃者に狙われています。
攻撃者は「Grumpy Cats(気難しい猫たち)」と呼ばれる集団で、レシピを盗むか、盗めなければ破壊しようとしています。
インシデント対応のアプローチ(NIST SP 800-61 Rev.3)
Workshopでは、NIST SP 800-61 Rev.3に基づいたインシデント対応のフレームワークが紹介されました。
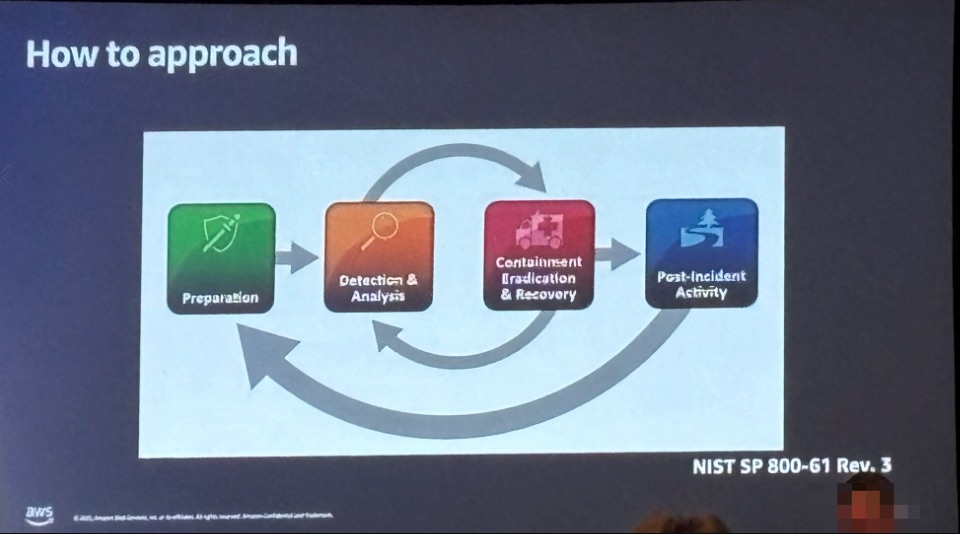
- Preparation(準備): インシデント対応能力の確立、ツールの準備、スタッフの訓練
- Detection & Analysis(検出と分析): 脅威の検出と影響範囲の分析
- Containment, Eradication & Recovery(封じ込め、根絶、復旧): 被害の拡大防止と復旧
- Post-Incident Activity(事後活動): 振り返りと改善

特に印象的だったのは「Incident Response is a TEAM SPORT!」というメッセージです。セキュリティインシデント対応は一人で行うものではなく、チーム全体で取り組むべきものだという点が強調されていました。

環境のアーキテクチャ
Workshopの環境は単一リージョン(us-east-1)で構成されており、以下のコンポーネントで構成されています。
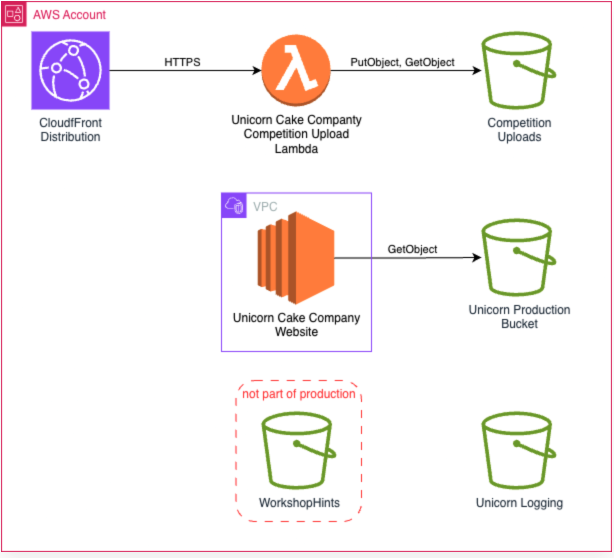
画像引用元: Workshop参加者向けに用意されたページの画面をスクリーンショット
主要コンポーネント
- CloudFront Distribution → Lambda (Competition Upload) → S3 (Competition Uploads)
- VPC内 Unicorn Cake Company Website → S3 (Unicorn Production Bucket)
- WorkshopHints(本番環境外、ヒント用)
- Unicorn Logging(ログ保存用)
組織構造
- 25人のユーザーが5つのチームに分かれている
- 営業、HR、開発、食品工学、レストラン経営者
- 全員がアクセスキーと管理者権限を持っている(これがセキュリティ的にヤバい設定)

画像引用元: Workshop参加者向けに用意されたページの画面をスクリーンショット
CISOからの指示
Workshopでは、CISO(Rainbow Sparkles氏)からの緊急ブリーフィングという形で、取り組むべき課題が提示されます。
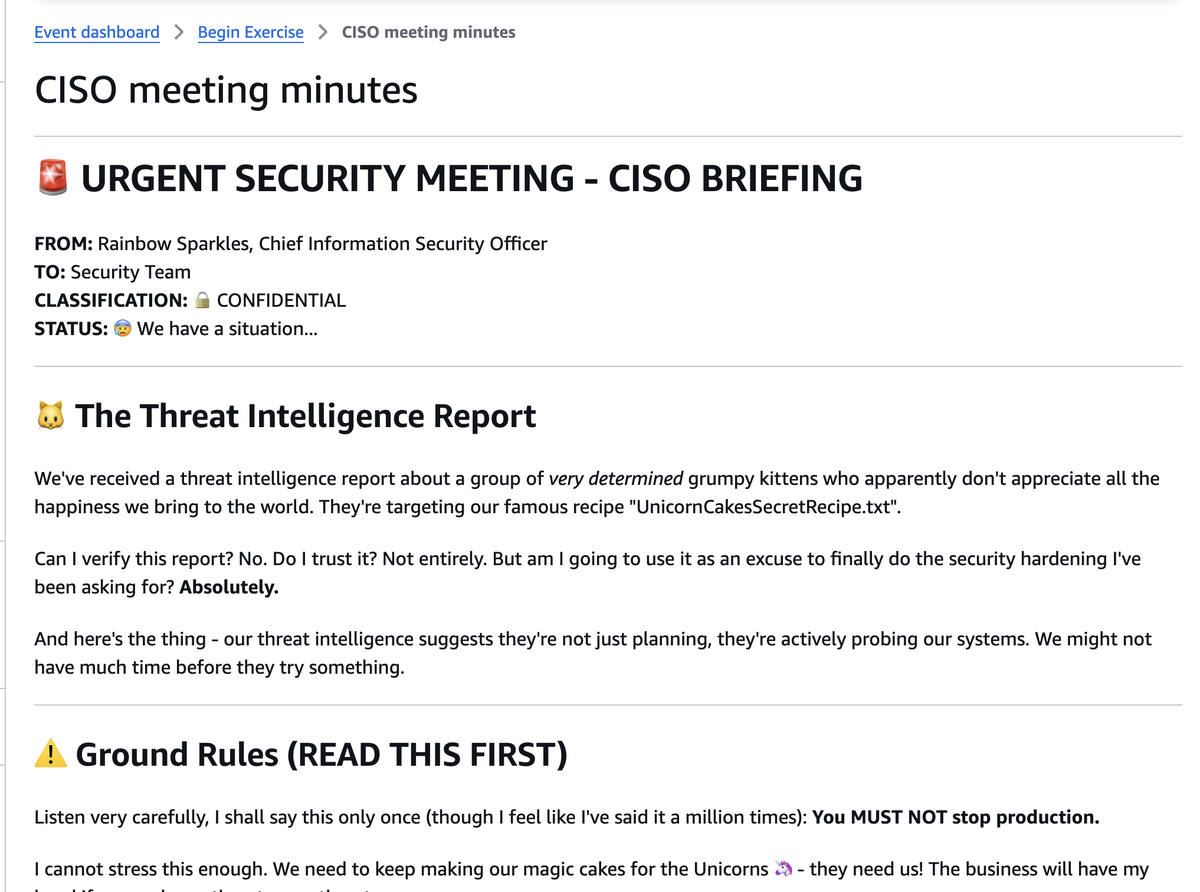
画像引用元: Workshop参加者向けに用意されたページの画面をスクリーンショット
最重要ルール:「生産を停止してはいけません」
ユニコーンたちのために魔法のケーキを作り続けなければならないという制約の中で、セキュリティを強化する必要があります。これは実際の本番環境でも同様で、セキュリティ対策のために事業を止めることはできないという現実的な制約を体験できます。
取り組んだセキュリティ課題
CISOから提示された課題は大きく4つのカテゴリに分かれていました。
1. アクセス制御の強化
- MFAの有効化: 全ユーザーにMFAを設定(まずは「Unicorn_Cakes_Sales_1」で実演)
- IAM認証情報レポートのダウンロード: 現状の把握
2. クラウンジュエル(秘密のレシピ)の保護
- 削除・ダウンロードの追跡: 誰がレシピにアクセスしたかを特定できるようにする
- 改ざん検知: レシピが変更されていないことを確認する方法
- 不変ストレージ: S3 Object Lockを使用して、管理者でも削除できないようにする
- 多層防御: S3バケットポリシーでAWSアカウント内からのみアクセス可能にする
3. 検出と警告の設定
- Amazon GuardDutyの有効化: 24時間365日の脅威検知
- 即時アラートの設定: EventBridgeを使用してレシピへのアクセスをリアルタイムで通知
- CloudTrailの設定確認: ログが正しく収集されているかの確認
4. ウェブサイトの保護
- 可用性の維持: ウェブサイトが継続して動作することを確保
- 復旧手順の確立: 万が一破損した場合の復旧方法
攻撃者の手口:知っておくべき統計
Workshopでは、実際の攻撃者がどのような方法で初期アクセスを獲得するかという統計も紹介されました。

- 66%: 有効なIAM認証情報を使用(うち約1/3がroot認証情報)
- 13%: 公開されたEC2インスタンス経由
この統計からも、IAM認証情報の管理がいかに重要かがわかります。
IAM設定の問題点
Workshopの環境には、意図的にセキュリティ上の問題が含まれていました。
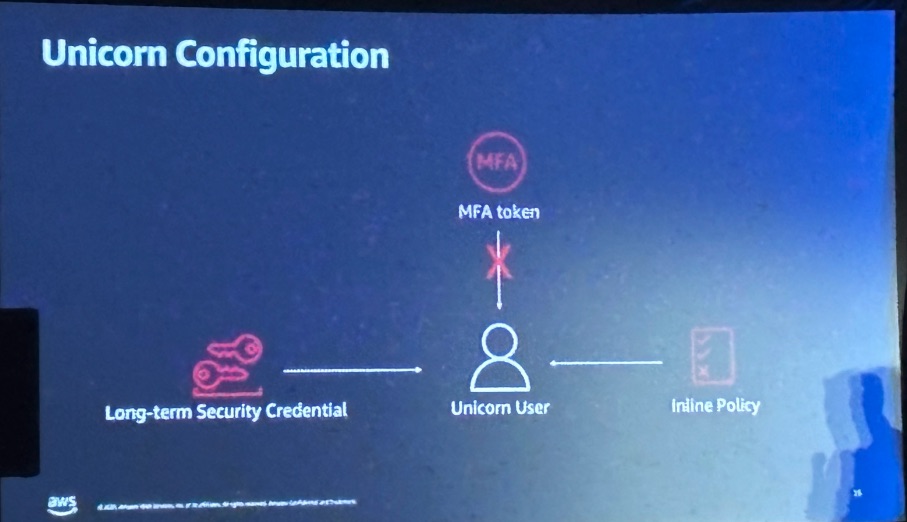
- Long-term Security Credentials: 長期間有効なアクセスキーの使用
- MFA未設定: MFAトークンが設定されていない(×マーク)
- 過剰な権限: 全ユーザーがInline Policyで管理者権限を持っている
また、「Overprivileged website」として、EC2インスタンスがIMDSv1を使用して過剰な権限を持つIAMロールがアタッチされているという、典型的な攻撃対象となる構成も紹介されました。
Shift Left:開発段階からのセキュリティ
Workshopの最後には、「Shift security left in your development flow」というメッセージとともに、Kiroが紹介されました。

開発段階からApplication Security Testingを導入することで、本番環境に脆弱性を持ち込まないようにするアプローチです。
AWS CIRT リソース
セッションの最後には、AWS CIRT(Customer Incident Response Team)が提供する、有用なリンク集がQRコードで共有されました。インシデント対応についてさらに学びたい方は、こちらのリソースも参考になります。
Workshopの様子
会場では多くの参加者がチームごとに分かれて、リアルタイムで攻撃に対応していました。スコアボードには各チームのポイントが表示され、競争形式で楽しみながら学べる環境でした。
まとめ
このWorkshopを通じて、以下の点が特に印象に残りました。
- セキュリティと事業継続のバランス:「生産を停止してはいけない」という制約の中でセキュリティを強化する経験は、実際の本番環境でも直面する課題そのものでした。
- 多層防御の重要性: IAMポリシー、S3バケットポリシー、MFA、GuardDuty、CloudTrailなど、複数のレイヤーで防御することの重要性を実感しました。
検知と対応の速度: 攻撃はいつ来るかわかりません。GuardDutyやEventBridgeを使ったリアルタイム検知の仕組みが、早期対応には不可欠。
チームワーク: 「Incident Response is a TEAM SPORT!」というメッセージ通り、一人ではなくチームで対応することの重要性を学びました。
弊社でもAWS環境のセキュリティ強化を進めていますが、このWorkshopで学んだ実践的な知識を活かして、より堅牢なセキュリティ体制を構築していきたいと思います。
Accelerate platform engineering on Amazon EKS (CNS301-R1)
SRE部 プラットフォームSREブロックのさかべっちです! 普段はZOZOTOWNのマイクロサービス基盤をEKSで構築・運用しています。
最先端のプラットフォームエンジニアリングを学ぶため参加してきました! 多くの人が帰国する最終日に開催されたセッションにもかかわらず、予約していない人はほとんど入れていなかったとても人気のセッションでした。
Workshopの概要
BackstageやArgo CDなどの最先端ツールやKiroを駆使して、ハンズオン形式で開発プラットフォームを構築するものでした。Workshopで使用したプラットフォームは、EKS Auto Mode上に構築されており、非常に豪華な構成でした。
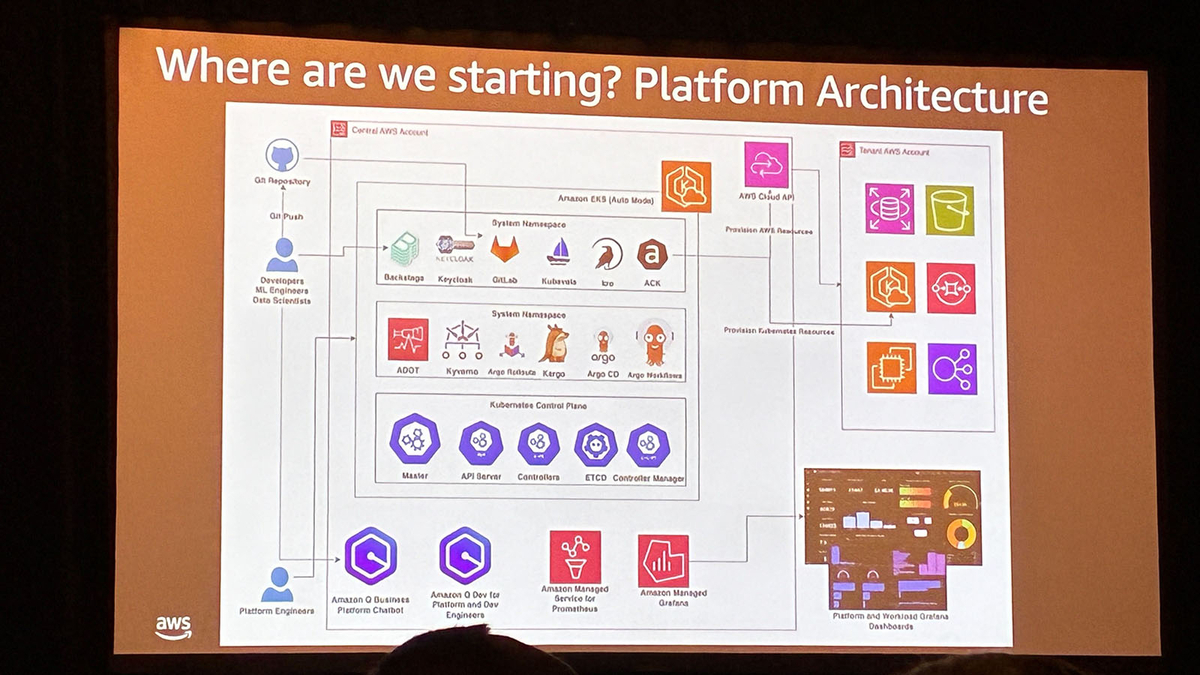
主なコンポーネントは以下の通りです。
- Backstage:開発者ポータル
- Argo CD:GitOpsエンジン
- Argo Workflows:CI/CDワークフロー
- Argo Rollouts:Progressive Delivery
- KubeVela:OAM(Open Application Model)ベースのアプリケーション管理
- kro:Kubernetes Resource Orchestrator
- Kargo:環境間のプロモーション管理
- Amazon Q:生成AIアシスタント
今年発表されたEKS Capabilitiesについてもここで紹介されました。
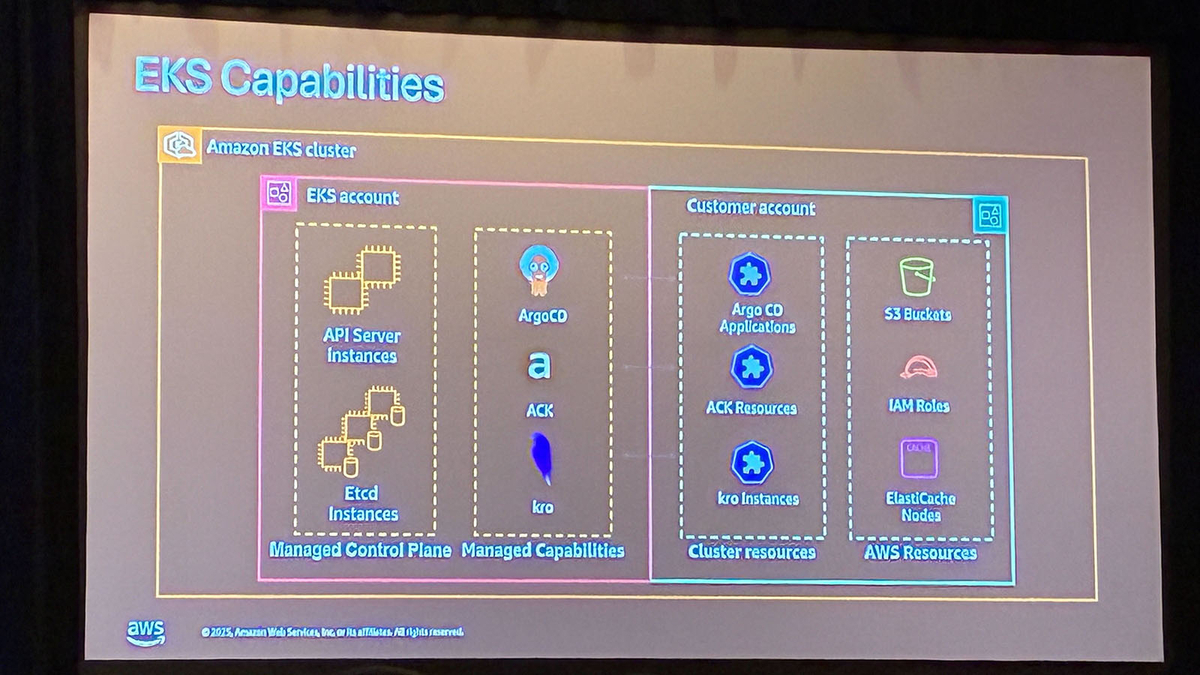
Argo CD、ACK(AWS Controllers for Kubernetes)、kroがマネージドで提供されるようになり、運用負荷が大幅に下がりそうです。VPC CNIやFluent BitなどのEKS addonとは別物で、詳しくは下記のbreakout sessionで紹介されているのでご覧ください。
プラットフォーム基盤構築
Workshopの前半は、Backstageを使ってプラットフォーム基盤を構築していく内容でした。Backstageを使うと、サービスカタログ、API一覧、ドキュメント、CI/CDパイプラインの状態などを一元管理できます。特に感動したのは、テンプレートからCI/CDパイプラインを数クリックで構築できる点です。Application Name、AWS Region、EKS Cluster Nameなどを入力して「CREATE」を押すだけで、GitLabリポジトリの作成からArgo CDの設定まで自動で行ってくれます。

たった数分でGitOpsワークフローの構築が完了しました。GitOpsとは、インフラやアプリケーションの状態をGitで宣言的に管理する手法です。Gitにマニフェストをpushすると、Argo CDが差分を検知して自動でEKSクラスターに反映してくれます。
生成AIを活用したプラットフォームエンジニアリング
Kiroをプラットフォームエンジニアリングに活用する方法も紹介されました。Kiroを活用して先ほどのプラットフォーム基盤にアプリケーションをデプロイします。
KiroにRustアプリケーションのDynamoDBテーブルとデプロイマニフェストを作成してもらいました。
Please use the Kubevela OAM component definition ...(中略) as a template and create a new Kubevela OAM component definition with the name of ddb-table using this dynamodb table CRD yaml Create an OAM manifest ...(中略) using Kubevela templates Include in strict order of dependency using dependsOn between components: - DynamoDB table with component-policy trait for permissions - Service account - Rust app (deploy last) - Path based ingress with /rust-app routing
KubeVelaを用いたアプリケーションマニフェストが生成されます。KubeVelaを使うと、OAM(Open Application Model)に基づいてマイクロサービスを1つのファイルで定義できます。通常であればDeployment、Service、Ingressなどを個別に書く必要がありますが、KubeVelaのOAMを使えばこれだけでOKです。
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: rust-application
spec:
components:
- name: rust-webservice
type: appmod-service
properties:
image: <image>
image_name: java-app
port: 8080
targetPort: 8080
replicas: 2
appPath: "/app"
env:
- name: APP_ENV
value: "DEV"
readinessProbe:
httpGet:
path: /app/
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 5
resources:
requests:
cpu: "500m"
memory: "256Mi"
limits:
memory: "512Mi"
functionalGate:
pause: "20s"
image: "httpd:alpine"
extraArgs: "red"
performanceGate:
pause: "10s"
image: "httpd:alpine"
extraArgs: "160"
traits:
- type: path-based-ingress
properties:
domain: "*.elb.us-west-2.amazonaws.com"
rewritePath: true
http:
/app: 8080
また、kro(Kubernetes Resource Orchestrator)を使うと、cicdpipelinesやeksclusterといった新しいカスタムAPIを作成でき、KubernetesとAWSリソースのデプロイをさらにシンプルにできます。上記のコードをGitにpushすると自動でビルド・テスト・デプロイが実行されます。
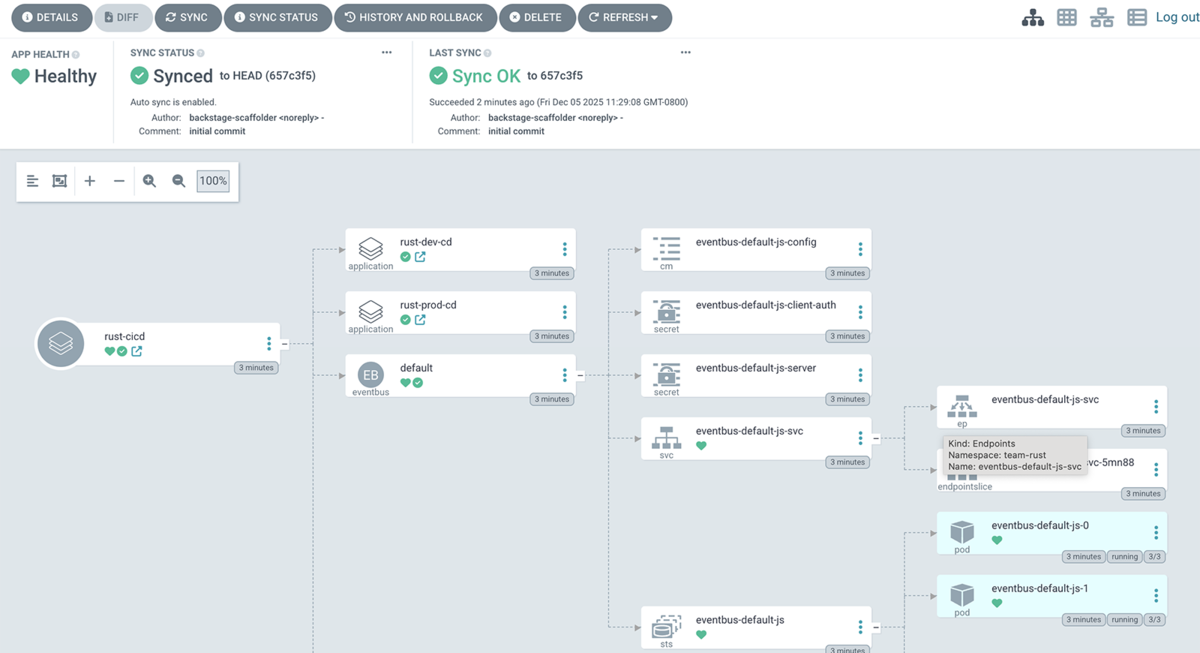
Progressive Deliveryの実践
Workshopの後半では、Argo Rolloutsを使ったProgressive Deliveryを体験しました。Argo Rolloutsの詳細な設定はプラットフォームエンジニアが担当し、開発者はKubeVelaのコンポーネントを使ってgit pushするだけで段階的デプロイを実現できるようにします。
CI/CDパイプラインと組み合わせると、Progressive Deliveryは以下のようなフローになります。
- 開発者がGitリポジトリにコードをプッシュ
- Argo Workflowsがコードをコンパイル、イメージをビルド、ECRにプッシュし、マニフェストのイメージタグを更新
- Argo CDがマニフェストの変更を検知し、DEV環境へのデプロイをトリガー
- Rolloutが新バージョンを20%に展開し、機能テストを実行
- 40%、60%、80%と段階的に展開し、パフォーマンステストを実行
- テスト失敗時は自動で最後の安定バージョンにロールバック
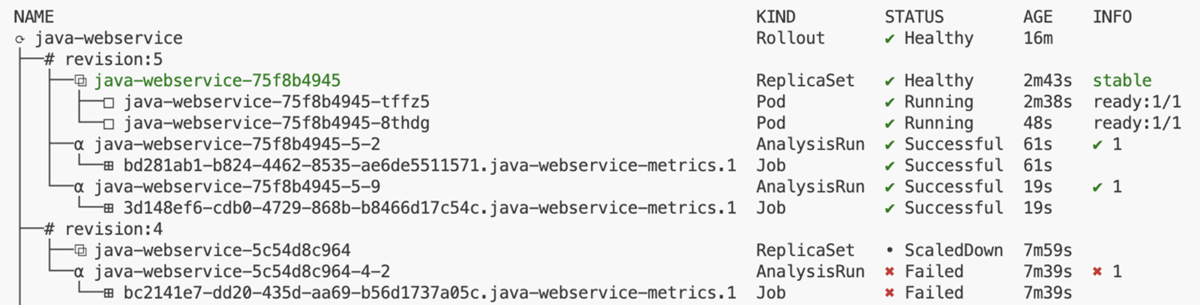
実際にわざとエラーになる変更を入れてテストしてみました。

revision:4のAnalysisRunが「Failed」となり、自動でロールバックされています。修正を加えて再度git pushすると、無事Successfulになりました。
DEV環境へのデプロイが成功した後はPROD環境へのデプロイです。DEVからPRODへの昇格管理にはKargoを使いました。Kargo UIで「Promote」をクリックすると、先ほどDEVでデプロイが成功したイメージを使用して、自動でK8sマニフェストを更新してくれます。

DEVで成功したイメージをそのままPRODに適用できるので、環境間の差異による問題を防げます。
さらに、DevOps Research and Assessment (DORA) メトリクスも自動で計測・可視化されます。これにより、チームや組織のソフトウェアデリバリのスピードと品質の改善点を特定できます。
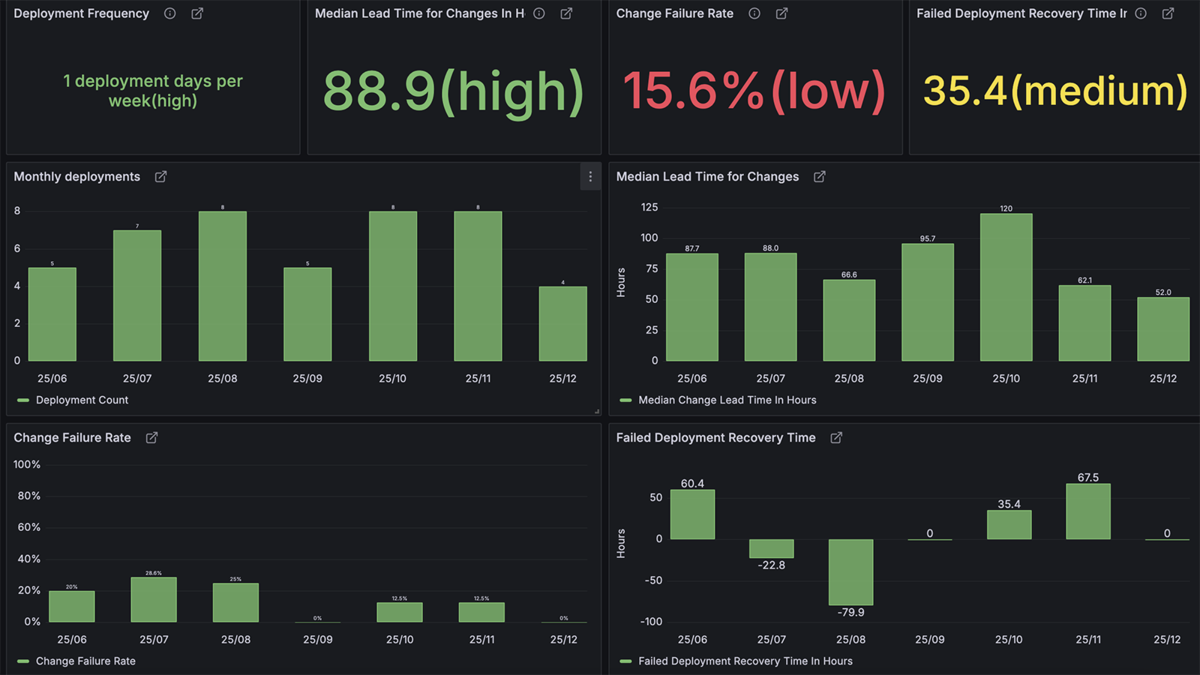
最終的に構築したDevOpsアーキテクチャの全体像は下記の通りです。
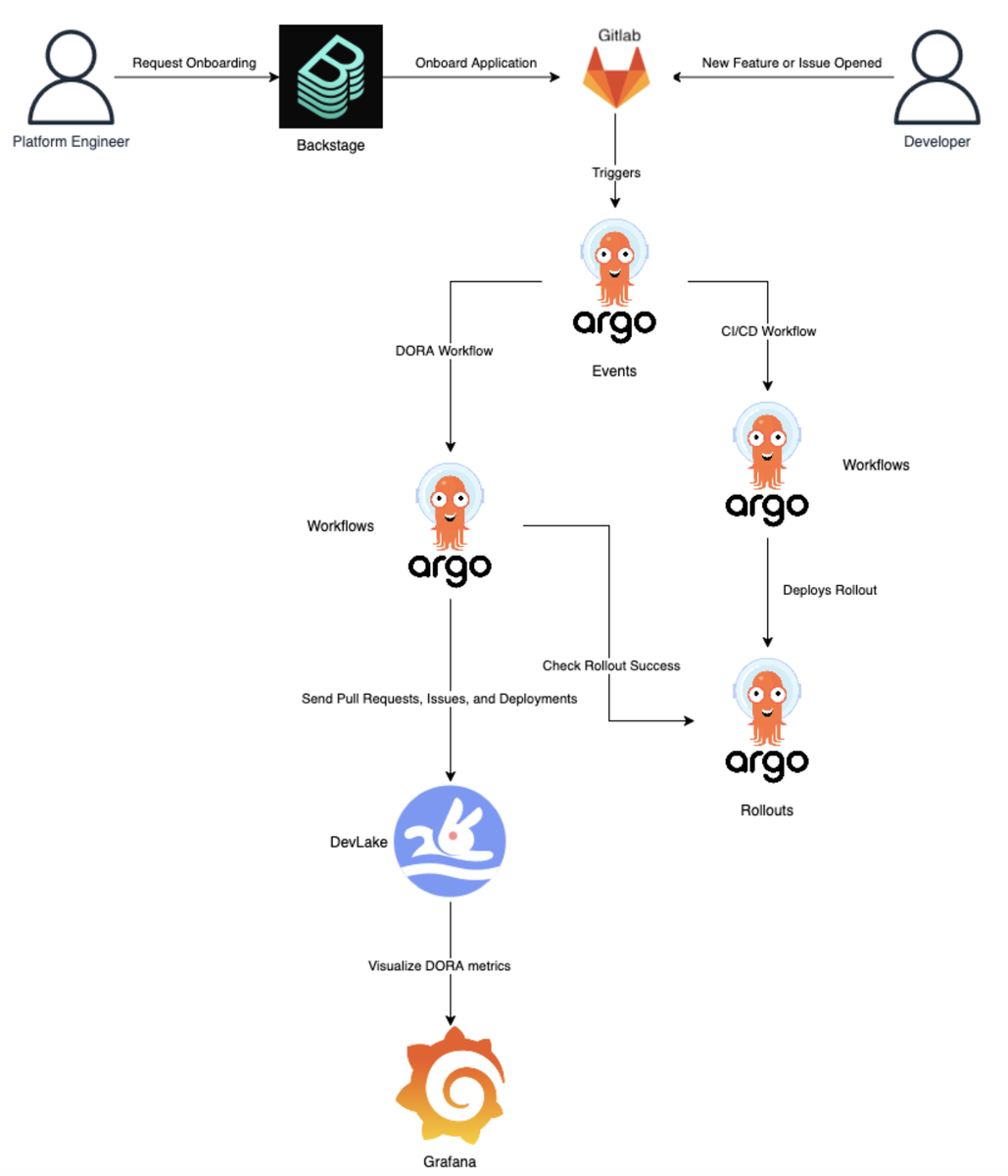
感想
Backstageの導入を検討していたのですが、実際に触ってみてCI/CDパイプラインをテンプレート化して開発者に提供できる点が便利であることを実感しました。また、EKS Capabilitiesで今後Argo CDなどがマネージドで提供されるようになると、プラットフォームの構築・運用コストが大幅に下がりそうです。
ただ、弊チームでは現在FluxCDを使ってGitOpsを運用していますが、今回のre:Inventの発表を見る限りArgo CDがかなり推されている印象だったので、中長期的にはArgo CD移行も視野に入れて検討していく必要がありそうです。今後様々なEKSエコシステムのEKS Capabilitiesも使えるようになると嬉しいです!
WorkshopのソースコードはGitHubで公開されているので、興味のある方はぜひ試してみてください!
Using Amazon Q to Cost Optimize Your Containerized Workloads (CMP348)
引き続きさかべっちが参加したWorkshopをご紹介します! こちらはAmazon Qを活用してEKSワークロードをGravitonに移行し、コスト最適化を行うWorkshopです! 私が入社前のアルバイトをしていた頃に、チーム内でGravitonの移行について話題が上がっていたので、今後移行の予定ができたときのためにキャッチアップしておこうと考えて参加しました! AWS GravitonはAWSが独自開発したARMベースのプロセッサです。x86インスタンスと比較して最大40%優れたコストパフォーマンスを実現し、さらに最大60%少ないエネルギー消費という特徴があります。
Graviton移行の流れは以下の5ステップです。
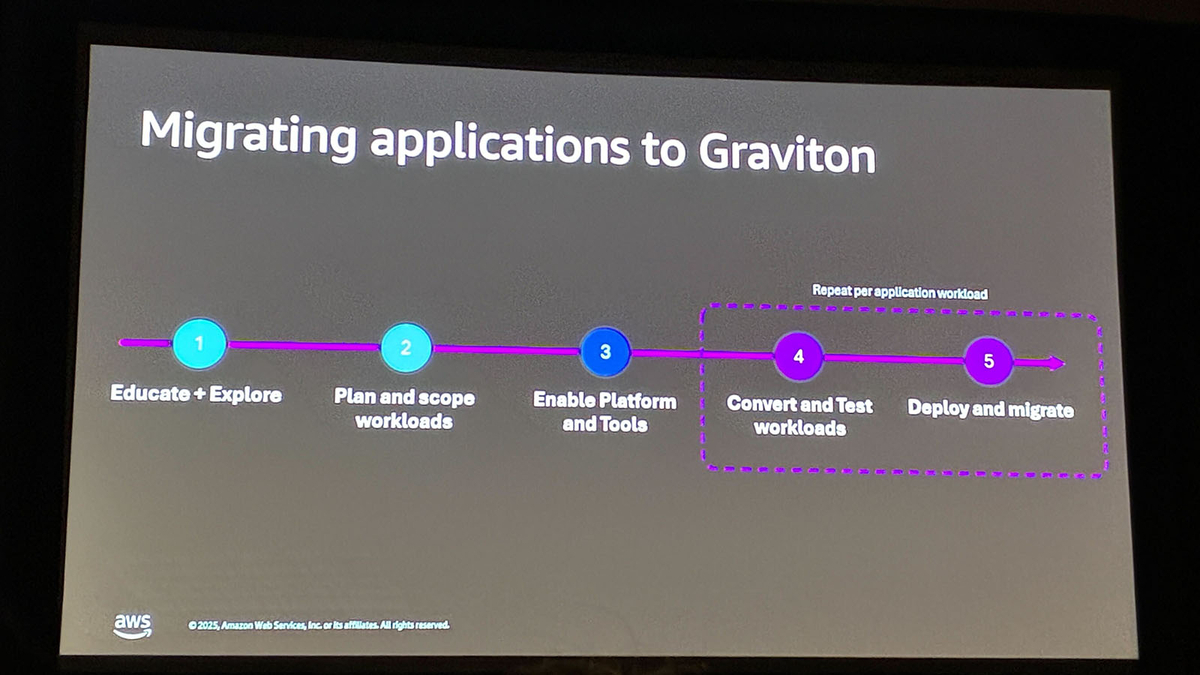
Workshopの概要
サンプルのチャットボットアプリケーション(Java、Python、Go、.NET Coreから選択)をx86からGravitonへ移行する流れを体験しました(自分はGoを選択して進めました)。Amazon QにGraviton移行の専用agentがすでに組み込まれており、Amazon Qに質問しながら移行の分析や実装を進めていくスタイルでした。
Amazon Qによる移行分析
まず、Amazon Qに現状のEKSインフラがGraviton移行可能かを分析してもらいました。
Q. Analyze the EKS infrastructure for Graviton readiness
すると、Karpenter NodePoolの設定やアプリケーションマニフェストの問題点、コンテナビルドの準備状況などを詳細に分析してくれます。さらに言語ごとの移行複雑度をスコアリングしてくれるので、どのアプリから移行すべきかの判断材料になりました。
コスト分析もAmazon Qにやってもらいます。
Q. Perform EKS Graviton migration cost analysis for my go app
現在のx86コストとGraviton移行後の予測コストを比較したレポートを作成してくれました。月額約14%の削減、年間では約$600の削減が見込まれるという結果でした。
負荷試験でGravitonへの移行の効果測定
Workshopでは事前に用意されていた負荷試験ツールを実行して、Graviton移行前後のパフォーマンスを比較しました。
Graviton移行前(x86)
#[Mean = 2192.524, StdDeviation = 47.983] Requests/sec: 0.45
Amazon Qから言われた通りにGraviton移行で必要な下記の変更を加えてから負荷試験を実施します。
- nodepool:
kubernetes.io/archにarm64を追加 - instance-familyを
c7gに変更
Graviton移行後
#[Mean = 1593.935, StdDeviation = 57.964] Requests/sec: 0.63
レイテンシが約27%改善、スループットは約40%向上という結果になりました! Gravitonはコスト最適化のイメージでしたが、パフォーマンスもかなり向上していることを知りました。
段階的な移行アーキテクチャ
本番環境での移行時は、いきなり全てをGravitonに切り替えるのではなく、段階的に進めることが推奨されていました。これにより、問題が発生した場合でも影響範囲を限定できます。
Amazon Qに段階的な移行方法を教えてもらいます。
Q. Can you help me create a migration runbook based on the progressive Graviton migration?
3フェーズ(Dev → Staging → Production)の段階的移行計画、バリデーション基準、ロールバック手順まで含んだ手順を生成してくれます。
また、マイクロサービスごとの移行は下記の手順で実行します。
Phase 1: 移行用のGraviton NodePoolを用意し、pilot環境での移行検証

Phase 2: capacity-spreadの導入
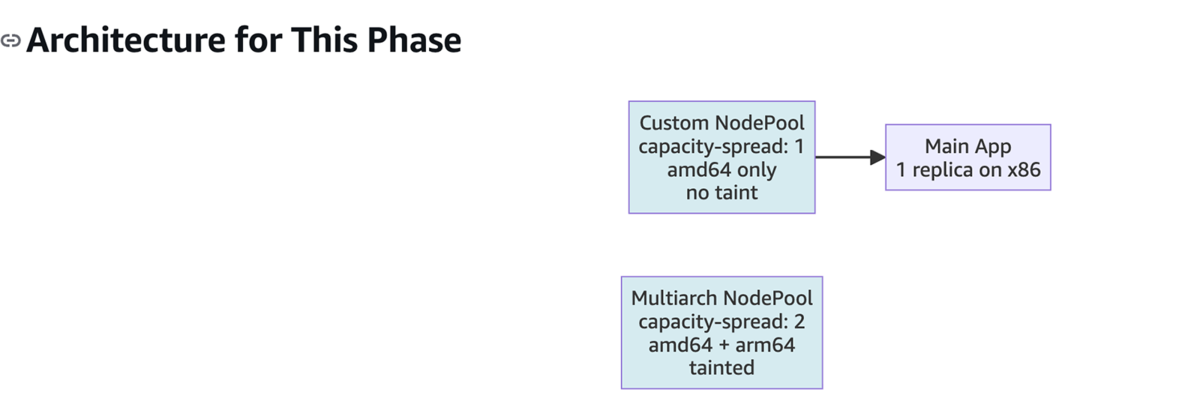
Phase 3: トラフィック分散

具体的にはtopologySpreadConstraintsを使って、x86とGravitonの両方にPodを分散させながら徐々に移行していく方法です。
topologySpreadConstraints:
- labelSelector:
matchLabels:
app.kubernetes.io/name: goapp
maxSkew: 1
topologyKey: capacity-spread
whenUnsatisfiable: DoNotSchedule
感想
Graviton移行用のagentを使うと、インフラの分析からコスト試算、実装の提案、段階的な移行まで一貫してサポートしてくれます。Graviton移行の取り掛かりとしてはハードルがかなり下がった印象です。
特に印象的だったのは、負荷テストでパフォーマンスが大幅に向上した点です。Gravitonは「コスト削減」のイメージが強かったのですが、実際にはレイテンシ27%改善・スループット40%向上と、パフォーマンス面でも大きなメリットがあることを体感できました。
弊チームではZOZOTOWNのマイクロサービス基盤をEKSで運用していますが、マイクロサービスごとに使っている言語が異なるため、今回学んだ段階的な移行アプローチは非常に参考になりました。
具体的には、環境ごと(Dev → Stg → Prd)、NodePoolごと(x86とGravitonを併用)に段階リリースしていく方法は、弊チームでも必須になると思います。移行の予定が決まった際はAmazon Qに現状のインフラを分析してもらい、移行の優先度を決めるところから始めてみたいと思います。
Infrastructure Innovations (KEY004)
SRE部 基幹プラットフォームSREブロックの若原です。普段はZOZOの倉庫システムやブランド様向けの管理ページなどのサービスのオンプレミスとクラウドの構築・運用に携わっています。
現地時間12/4の朝に行われた、AWS SVPのPeter DeSantis氏とVice President of Compute and Machine Learning ServicesであるDave Brown氏によるKeynoteを聴講してきましたので、この基調講演の概要と印象に残ったポイントをお伝えします。
講演のはじめに
講演では、AIがクラウドと開発者コミュニティに何をもたらすのかという問いから始まりました。Peter氏はAIトランスフォーメーションがもたらす未来を語る前に、まず変わらない大切な価値に目を向けるべきだと強調しました。
どれだけ世の中が変化しようとも、AWSが創業以来一貫して大切にしてきたSecurity(セキュリティ)、Availability(可用性)、Elasticity(弾力性)、Cost(コスト)、Agility(俊敏性)の5つのAttributes(特性)は、クラウド基盤の核心であり、AI時代においてさらに重要になると述べていたのが印象的でした。
主なアップデート #1 Graviton5
AWSが自社開発する次世代CPU「Graviton5」が発表されました。高いコア数やキャッシュ性能を備えながら省電力・高性能を両立している点が特徴で、複雑なデータ処理やAIワークロードにも適した設計になっています。

主なアップデート #2 Lambda Managed Instances
Lambda関数をEC2インスタンス上で実行可能にする新機能として紹介され、サーバーレスの簡易さを保ちながらEC2の柔軟なインスタンスタイプ選択と割引価格モデルを活用し、柔軟なトラフィックワークロードのコスト最適化と性能制御を可能にすると説明されました。

主なアップデート #3 Vectors
Amazon S3 Vectorsがネイティブなベクトルデータの保存・検索をサポートするクラウドストレージとして紹介され、生成AIや意味検索(RAG)など大規模AIワークロードのコストを最大90%削減しつつ効率的に処理できる基盤として発表されました。

ゲストセッション
新機能のアップデート以外にも、AppleのPayam Mirrashidi氏が登壇し、AWS Gravitonを活用してSwiftベースのバックエンドでパフォーマンスとコスト効率を大幅に向上させた事例を紹介しました。また、TwelveLabs社のJae Lee CEOはS3 Vectorsを使って大規模な動画データを効率的にインデックス化・検索するAIシステムの事例を共有し、さらにDecart社のDean Leitersdorf CEOはTrainium3を用いたライブ・ビジュアル・インテリジェンスの実演を披露するなど、大変興味深い内容となりました。

講演を通じて感じたこと
AWSはAI時代の最前線で先進的なサービス・機能を展開しつつも、クラウドの原点となる価値を創業以来常に大切にしているというメッセージが強く伝わってきました。
今回発表されたGraviton5、Lambda Managed Instances、S3 Vectorsなどは、単に追加された新機能ではなく、基本となる要素であるAgilityやCostといった基本価値をさらに強化するものに感じられました。今後のAWSとクラウドの進化がますます楽しみです。

おまけ
講演の冒頭で、Peter氏は学部時代に愛読していた「CSの教科書」の第7版が最近刊行され、その中にNitroシステムとGravitonプロセッサに関する新しい章が追加されたことを紹介していました。
これを記念して、会場に投影されたQRコードを読み取った先着1000名に、その最新版の教科書を講演後にExpoホールでプレゼントするというサプライズ企画があり、私も運よく受け取れました。ひとつ想定外だったのは、喜んで受け取ったのは良いものの、この本がほぼ2kgある大著で思いのほか重く、帰りの預け荷物の重量制限が頭をよぎり少しハラハラしてしまいました。無事に持ち帰れたので、これから大切に読ませていただこうと思います。

Advanced AWS Network Security : Building Scalable Production Defenses [REPEAT] (SEC303-R1)
AWS環境におけるネットワークセキュリティ強化方法を実践的に学ぶ2時間のWorkshopに参加しました。
最初に講師の方から約30分ほどの座学があり、AWS Network FirewallやDNS Firewallの基礎、今回のLabのアーキテクチャについて解説がありました。その後は用意された環境を使い、参加者が自分の手で設定を進めながら学ぶハンズオン形式で進んでいきます。

主な内容
冒頭の座学では、オンプレミス環境のように単一のファイアウォールで全通信を集約するモデルではなく、AWSではユースケースごとに適切な境界を組み合わせて防御する、という設計思想が強調されていました。
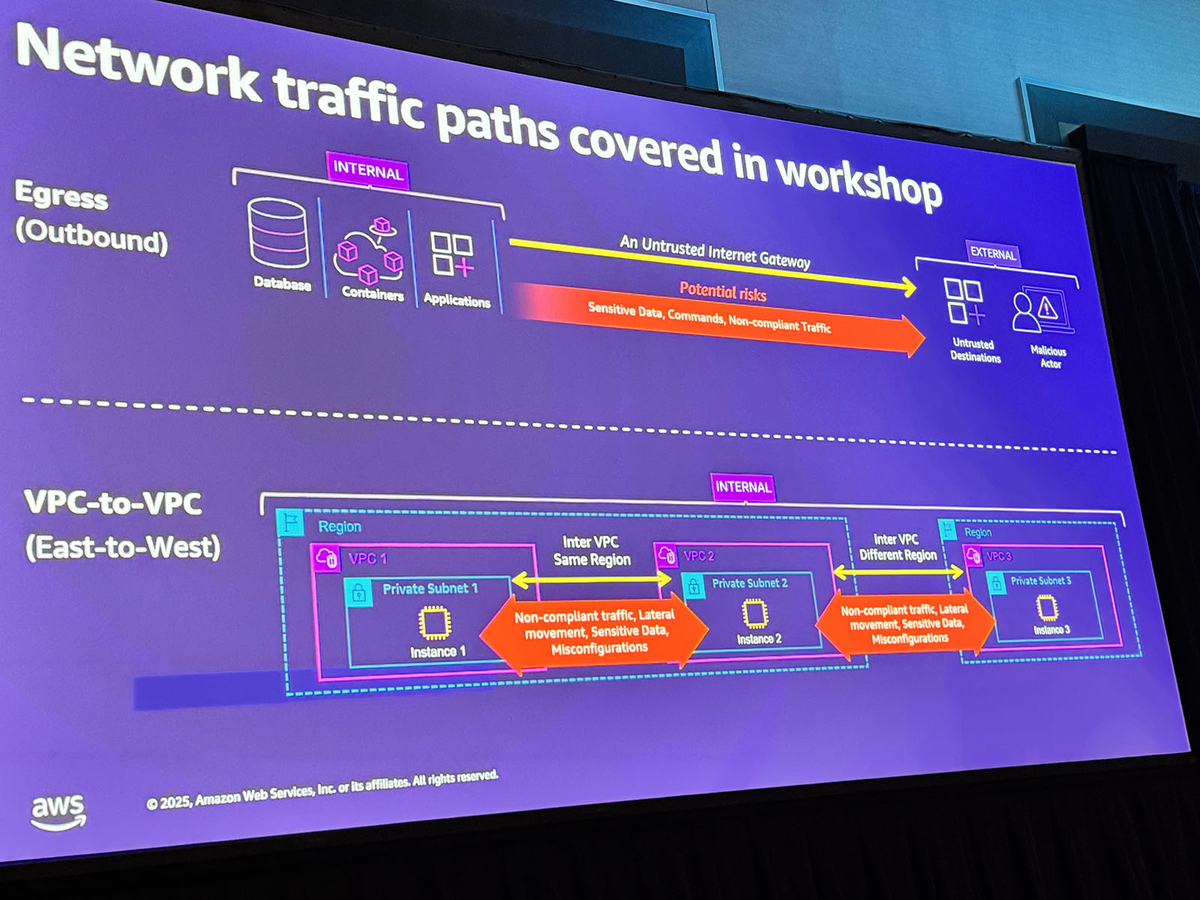
本WorkshopではEgress(外向き通信)とEast-West(VPC間通信)に焦点が当てられ、それぞれの通信に対して多層的に検査・制御するセキュリティを構築するという内容でした。
Ingress(内向き通信)ではWAFによるアプリケーションレイヤー保護が主役となる一方、本Workshopで取り扱ったEgressやVPC 間通信ではAWS Network FirewallとRoute 53 Resolver DNS Firewallの2つのサービスが中心的な役割を果たし、それぞれどのように組み合わせて環境を保護すべきかについて学びました。
AWS Network Firewallとは
AWS上のネットワークトラフィックを保護するためのマネージド型ファイアウォールサービスで、AWS環境のネットワークを総合的に守るためのセキュリティ基盤として利用できるサービスです。侵入防止(IPS)、ステートフル/ステートレスルール、ドメインフィルタリングといった機能を備えており、既存のセキュリティ運用に合わせた詳細なトラフィックの検査が可能です。Suricataというルール形式に対応している点も特徴で、既存のセキュリティ運用で利用している独自ルールやコミュニティルールをそのまま適用できます。
Route 53 Resolver DNS Firewallとは
AWS環境内のDNSクエリを保護するためのマネージド型ファイアウォールサービスで、悪性ドメインへのアクセスやDNSを悪用した攻撃をDNSレイヤーで防止するための基盤として利用できます。AWSが提供する脅威ドメインリストや独自のカスタムリストを使ってドメイン単位で通信を制御でき、DNSトンネリングや不正なクエリを早期に検知・遮断できます。VPCのRoute 53 Resolverと統合されており、アプリケーションを変更することなくDNSトラフィックを一元的に監査・制御できるのが特徴です。
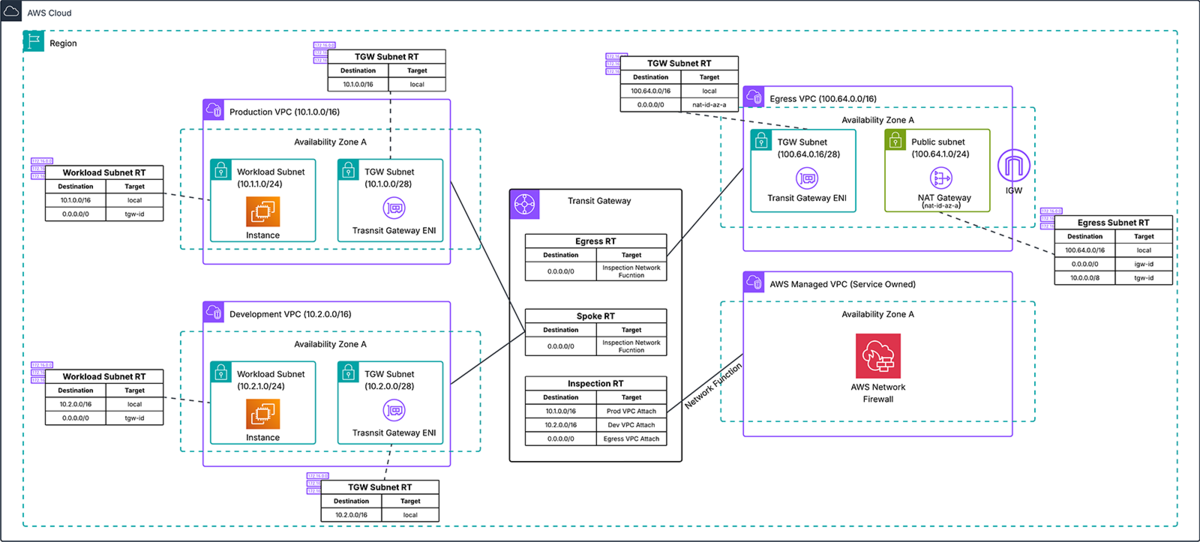
Workshop参加者には複数のVPCがTransit Gatewayで接続された環境を渡され、その上でネットワークセキュリティ構築を段階的に体験できる内容となっていました。
Labのアーキテクチャ図
VPCの内部から外向きの通信状態を確認するテストスクリプトが用意されており、Labの開始時点では、画像のようにあらゆる通信が通ってしまう状態になっています。

ここからAWS Network FirewallとDNS Firewallを使って、攻撃に悪用されるポイントを1つずつ対策しながらセキュリティを強化していきます。
AWS Network Firewallでの通信制御
ここでは例としてAWS Network FirewallのGeoIP機能を使って、特定の国や米国・カナダ以外への通信をブロックするルールを追加し、地域ベースでの通信制御を実践します。
コンソール上のVPCサービスから、Lab用に用意されているFirewallを選択します。Firewall policy settings→StatefulRuleGroupへ移動し、RulesセクションからEditします。
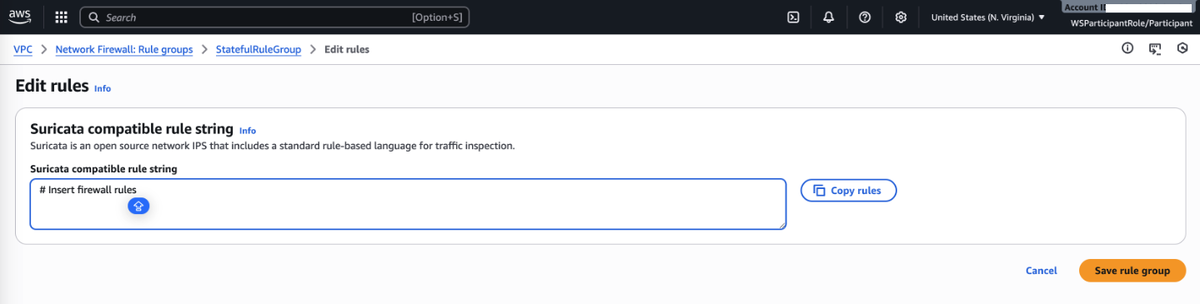
USとカナダ以外への通信をブロックするSuricataルール表記を追記してSaveします。
# Block Traffic To/From Any Country Besides the US or Canada drop ip any any -> any any (geoip:any,!US,!CA; msg:"Drop traffic to countries other than US and Canada"; sid:10000009;)
1分ほど待つとRuleが適用され、先ほどまで通っていたcurlコマンドが無事Blockされるようになりました。

DNS Firewallでの通信制御
次に、DNS Firewallを用いて、独自のドメインブロックリストを作成し、攻撃者に悪用されやすいTLDをまとめてブロックする設定例を紹介します。
VPCの画面からDNS Firewallを選択、Rule groupsへ移動し、新規でRule groupを作成します。作成したRule groupに対してAdd ruleでブロックしたいドメインのリストを記載します。
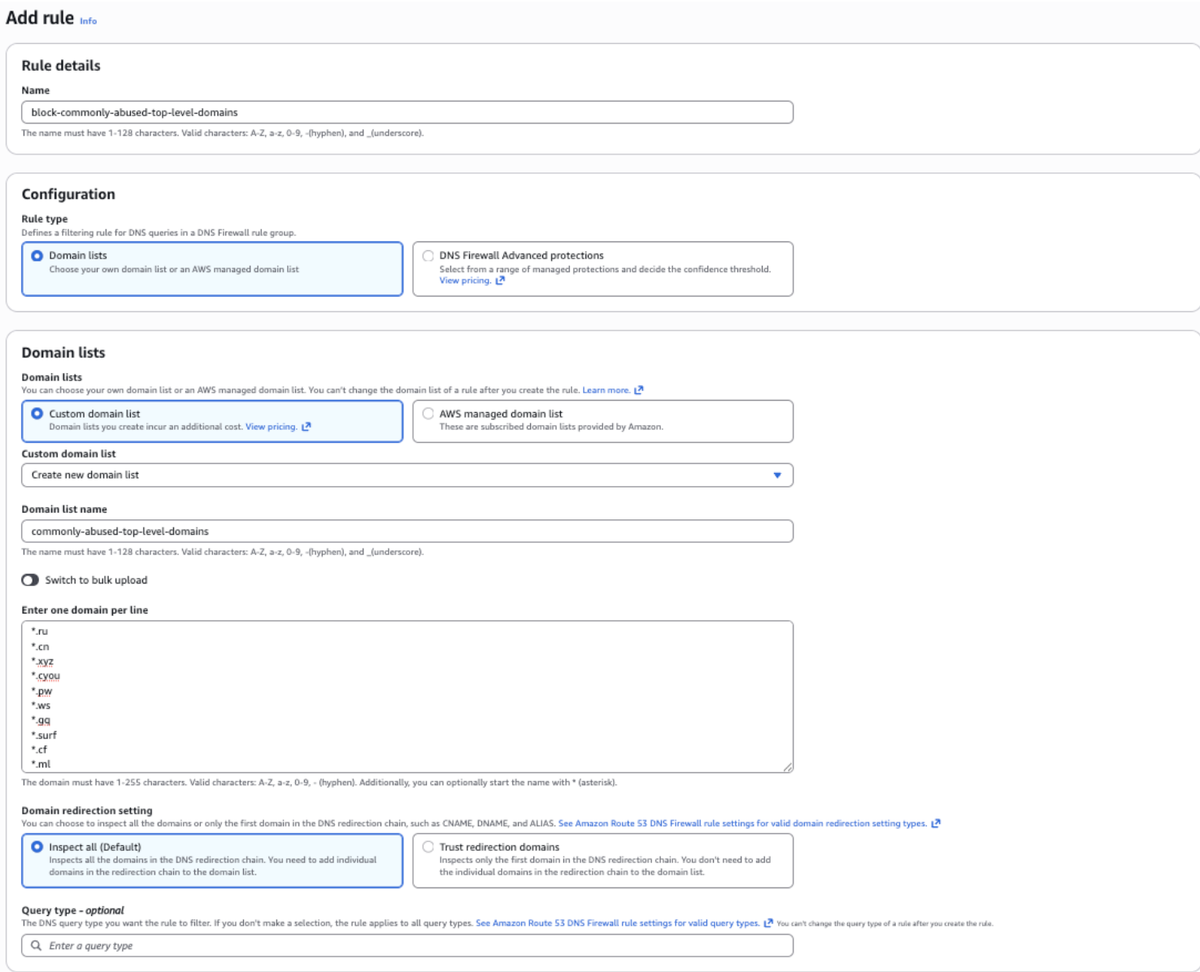
設定例は以下の通りです。
- Rule name: <Rule名は自由に設定>
- Domain list: Custom domain list and Create new domain list
- Domain list name:
- Domains: 以下を記載
*.ru *.cn *.xyz *.cyou *.pw *.ws *.gq *.surf *.cf *.ml
- Domain redirection setting: Select Inspect all (Default)
- Action: Block
- Block response: OVERRIDE
- Record type: CNAME
- Record value: dns-firewall-block
- TTL (seconds): Enter 0
適用後、該当ドメインへのリクエストがBlockされることを確認できました。

Workshopまとめ
今回紹介した内容以外にも、プロトコルとポートのミスマッチを利用した攻撃を検出するPort/Protocol Enforcementや、AWS Managed Domain Listsを利用したDNS Firewallの設定などもありました。
また、上記で設定した検知のログをCloudWatch Logsで確認したり、VPC間通信のトラフィック制御を試したりするなど、他にもいくつかのシナリオを想定したLabもありました。内容が盛りだくさんで時間内に到底収まらないほどのボリュームでした。
普段意識しづらい外向き通信のネットワークセキュリティについて、実際に手を動かして学ぶ、とても良い機会となりました。
The Kiro coding challenge (DVT317)
ZOZOMO部 SREブロックの中村です。ZOZOMOなどのマイクロサービスのSREを担当しています。ZOZOMO部ではAI Agentを活用した業務の効率化や本番運用にAIへの積極的活用に力を入れており、re:Inventでは多数のAgentサービスの新発表や既存サービスのアップデートが行われ、それに関するセッションも多く行われました。
Kiroを用いた仕様書駆動開発のWorkshopに参加したのでそのセッション内容をご紹介します。また、「Ditch your old SRE playbook: AI SRE for root cause in minutes」のセッションも合わせて紹介します。
Workshopの概要
このWorkshopは、KiroというエージェントネイティブIDEを使った実践的なコーディングチャレンジです。難易度が徐々に上がる10個のコーディングチャレンジをKiroの支援を受けながら課題を解決していきます。参加者は約70〜80人ほどで、他のWorkshopと比較してもとても人気のセッションとなっていました。


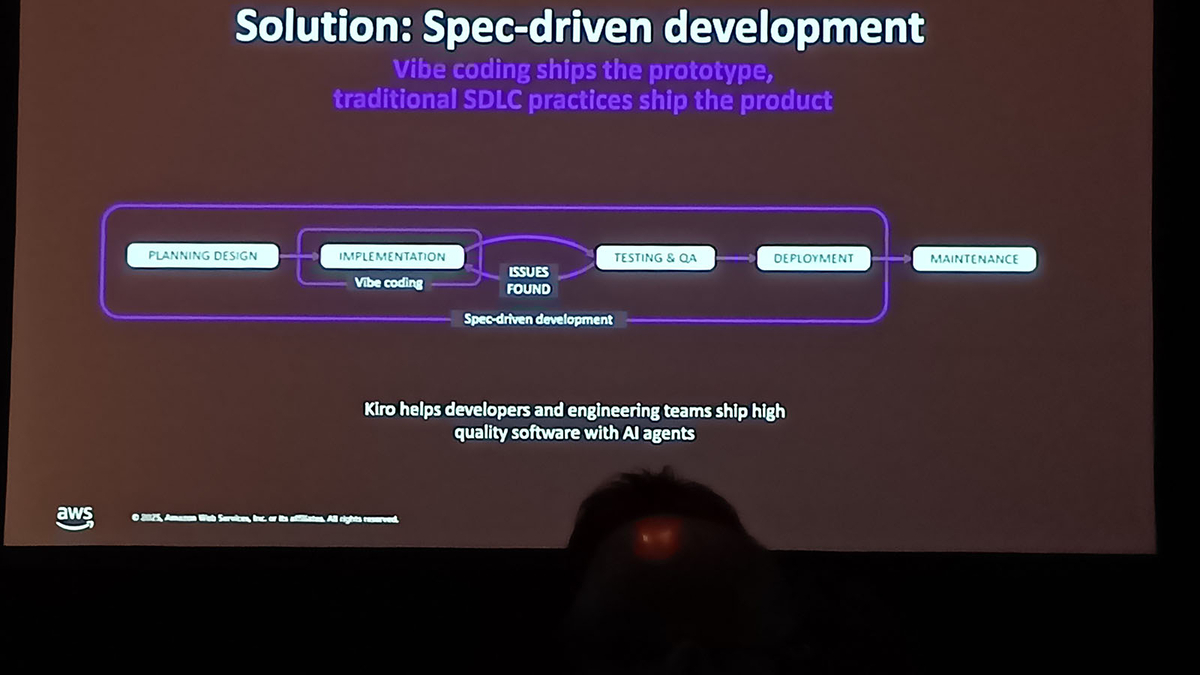
Workshopの冒頭ではKiroや仕様書駆動開発についての簡単な説明が行われました。仕様書駆動開発では、PLANNING DESIGN → IMPLEMENTATION → TESTING & QA まで一貫してカバーし、仕様を先に定義してから開発するので、手戻りが少なく高品質な製品を出荷できるような説明が図とともに行われました。
実践
Kiroの説明と、Workshopの説明が終わった後、AWSが用意してくれたWorkshopの環境に接続し、今回のWorkshopの概要等を確認できます。必要に応じてセットアップなど行なっていきます。
今回のWorkshopでは1から10のタスクが用意されており、それらをKiroを使って解決していきます。
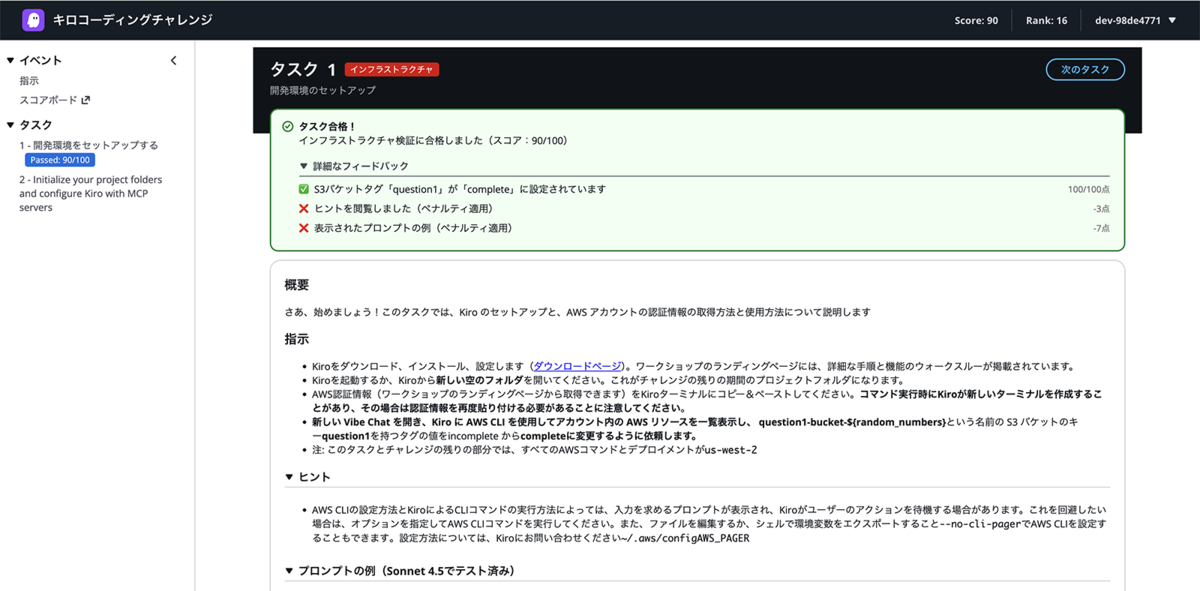
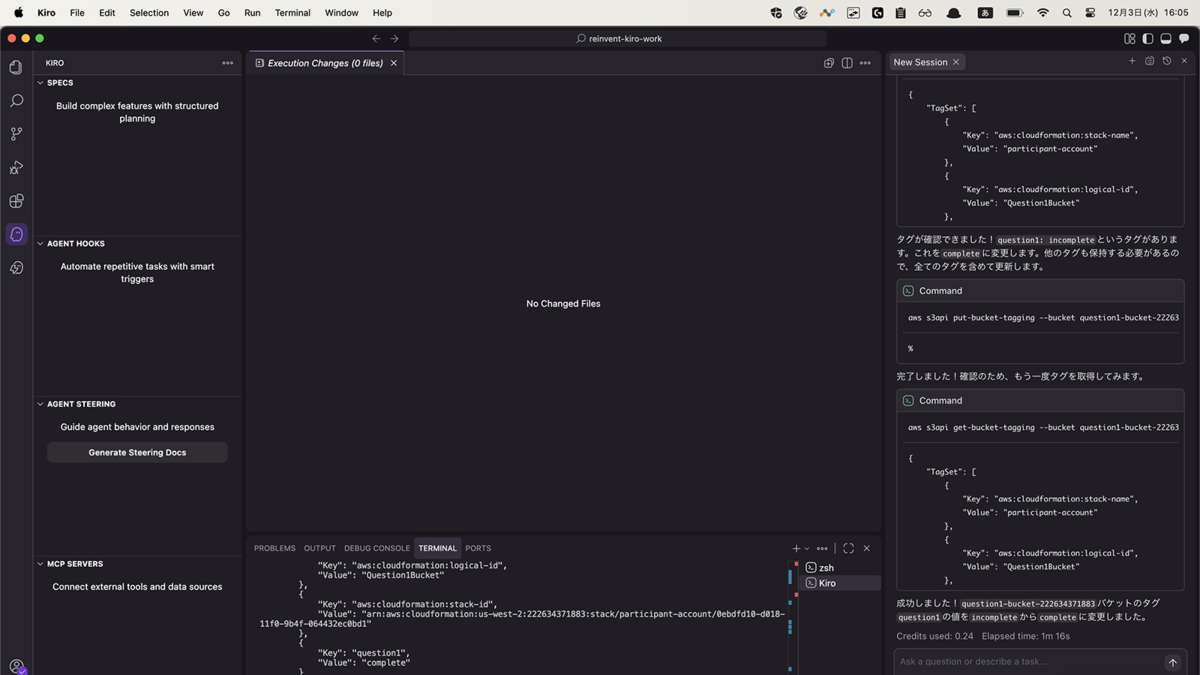
タスクを解決するプロンプトをKiroで叩き、解決していってもらいます。序盤はプロジェクトのセットアップをメインに行うタスクが多く存在しました。
タスク6では、ついに仕様書駆動開発を使用するタスクがでてきました。Kiroに対し、仕様を伝えそれを仕様書として作成するように依頼することで、Kiroの管理下に仕様書が作成されます。仕様書を作成したのち、Kiroは仕様書を元に実装を行なっていきます。
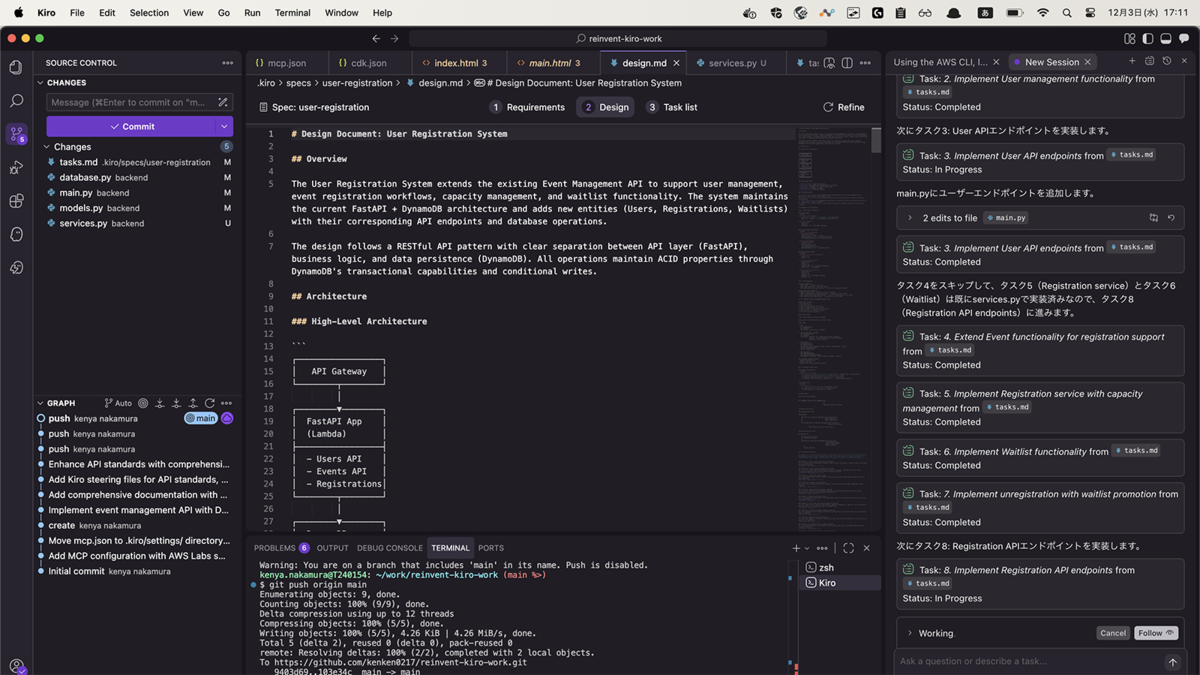
タスク8では、AgentHooksを利用しコードの変更をトリガーに、対応のドキュメントを併せて更新するような指示を追加できました。AgentHooksを利用するとドキュメント更新以外のアクションも実行できるので色々と夢が広がる機能ですね!
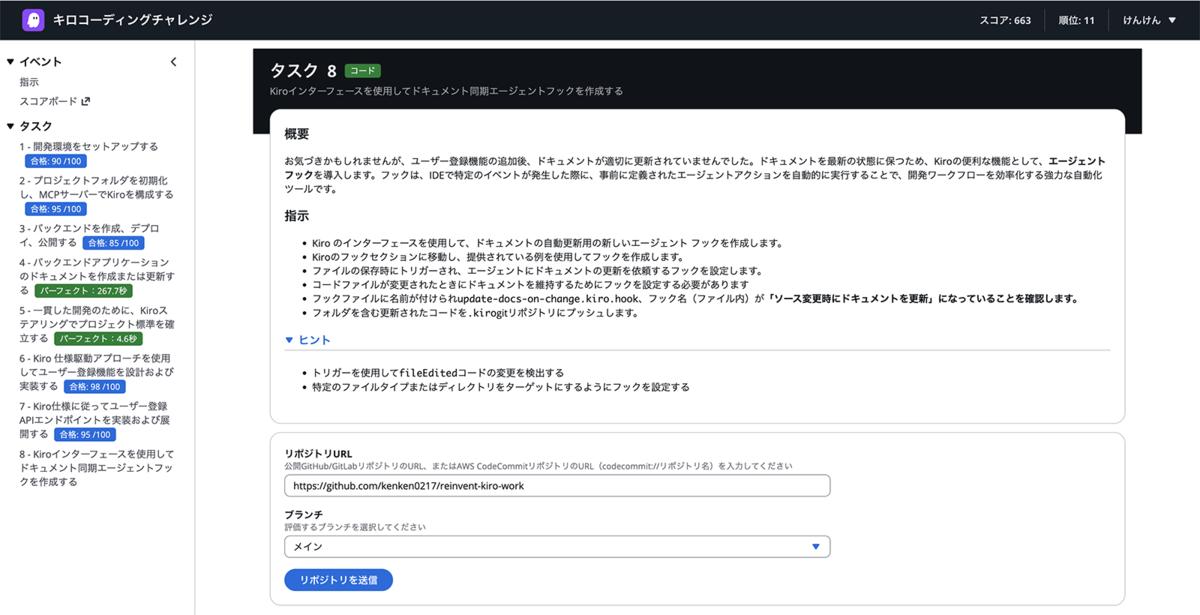
また、このWorkshop中は常にTOP10の順位が前のスクリーンに投影されていて、エンジニア全員で競い合い会場が熱気に包まれていました。
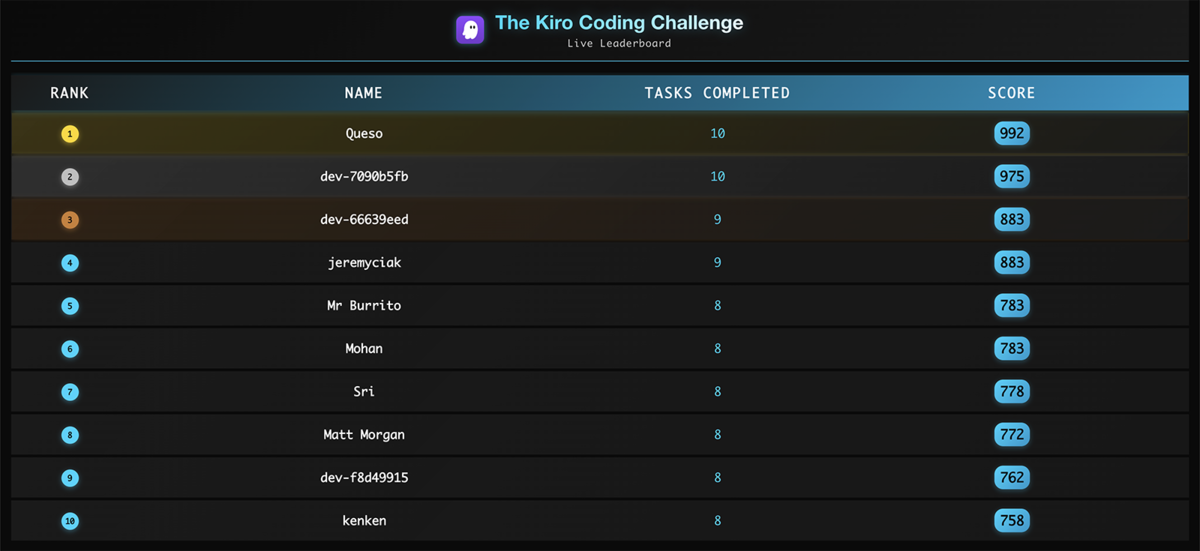
まとめ
本セッションを通じて、仕様書駆動開発がどのように行われていくのか、またKiroを利用した仕様書駆動開発をどのように行なっていくのかを学べました! 実際にWorkshopで利用したリポジトリはこちらです。どのような仕様書が作られたか気になった際はぜひ確認してみてください!
Ditch your old SRE playbook: AI SRE for root cause in minutes (sponsored by Resolve AI) (AIM260-S)
概要
このセッションでは、Resolve AI社により、SRE領域におけるAIエージェントの活用についてBreakout session形式で実施されました。本番環境の運用やインシデントの根本的な原因の分析を数分で実行するなど、開発でなく運用面にフォーカスをおいていました。SREという文字が含まれるセッションは少なく、こちらもとても人気でした。

内容
ソフトウェアエンジニアリングの進化
セッション冒頭では、数年ほど前からAIがソフトウェアエンジニアリングに与えている大きな影響、進化を3段階に分けて説明されました。
1段階目ではAIがコードを書くのでなく、人間が書いたものを自動補完するようなところから始まり当初は人間がオペレーターとなって作業を行なっていました。
2段階目ではAgentが登場した頃で、AIがオペレーターとなり作業し、それを人間が管理、監視するという、現段階で多くのエンジニアが行なっていることなのだと思います。今はこの段階の進化レベルにあると考えられています。
3段階目はすでに移行の過程である、またはこれからAIの進化が到達すると考えられており、AIが開発だけなく、今までエンジニアが扱ってきた様々な監視ツールや本番でのインフラ構成など運用に必要なあらゆるツールを人間同様に使いこなせるという話がされました。
AI for prod
Resolve AI社が提供するAI Agentを用いて実際にインシデント対応するデモが実施されました。このAgentは事前にアプリのコードはもちろん、インフラの構成等全てを知識として把握しています。GrafanaからSlackのアラートチャンネルにエラーが通知された時にそれをトリガーにAgentが起動しエラーを調査します。
Slackでは何が原因でどうすれば解決できるかを提案してくれます。しかしなぜその結論になったのかを知りたい場合は、Resolve AIのWeb UIを確認しAgentがどのような調査を行なったか詳細な情報を確認できます。
デモでの調査内容は次の通りです。
- ログクエリの生成
- 履歴の確認
- トレースの調査
- インフラストラクチャイベントの確認
- チャート・ダッシュボードの分析
- コードのチェック
Resolve AIの3つの重要な特徴
セッションではResolve AIの構築にあたり、3つの重要な特徴について説明されました。特にマルチエージェントを生かして本番環境での実用性を説明しているように感じられました。
- 理解(Understand)
- Knowledge graphを用いてシステム全体を理解する
- 優秀なプリンシパルエンジニアが持つような知識を再現
- システムの歴史
- 障害パターン
- 過去のポストモーテム
- 学習(Learn)
- ツール使用履歴からの学習
- ダッシュボードの使用頻度など、ツールの使われ方から学習
- アラートの優先度ラベル(P1など)を評価基準として活用
- インシデントチャンネルでの議論から原因究明・修復プロセスを学習
- チーム・組織レベルでカスタムコンテキストを追加可能
- ツール使用履歴からの学習
- 推論(Reason)
- マルチエージェントアーキテクチャ
- プランナーが「何をすべきか」を判断
- 専門化されたサブエージェントがエビデンスを収集
- レート制限やペイロードの処理を理解
- 人間のフィードバックループを組み込み、継続的に改善
- マルチエージェントアーキテクチャ
AIエージェント構築のアプローチ比較
このセクションでは、インシデント対応を自動化するAIエージェントの構築には、大きく4つのアプローチがあると説明をされました。セッションを聞いた内容を簡単に要約してみました。
- LLMs
エラーをそのままLLMに投げる最もシンプルな方法。時には正解するが、複雑なシステムではコンテキスト不足で機能しない。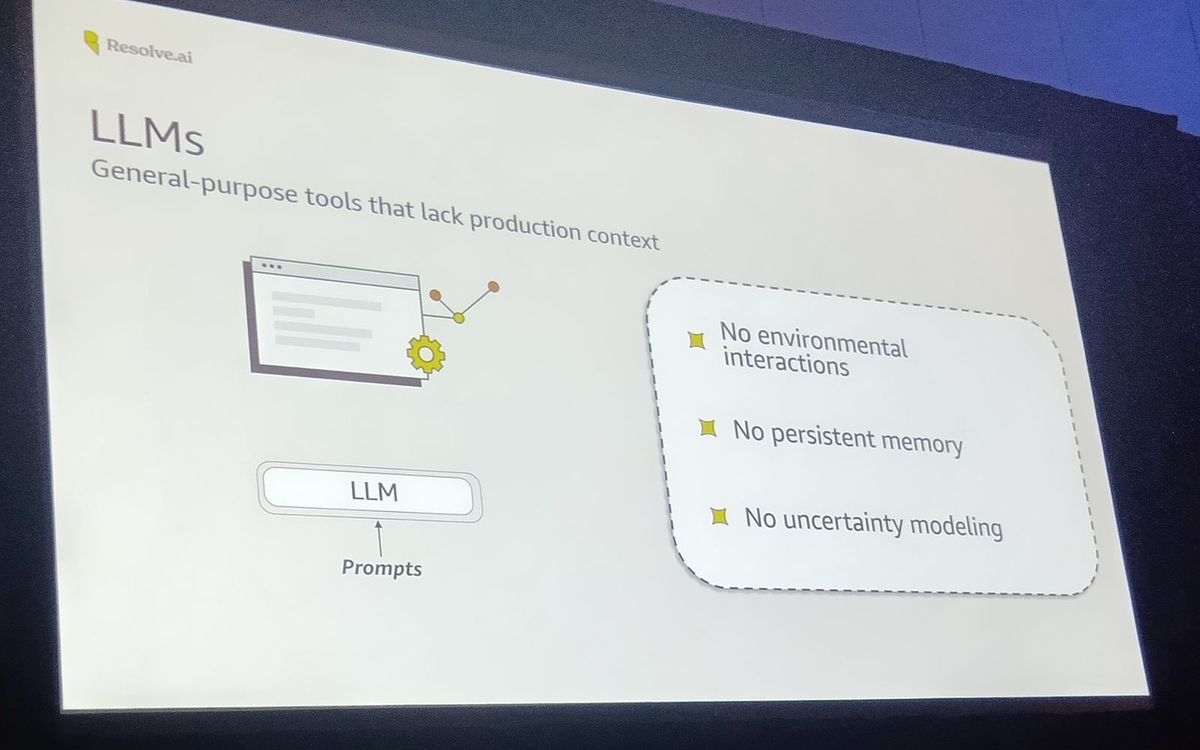
セッションの様子 - LLMS + tools(MCP)
MCPサーバー経由でObservabilityツールにアクセス。データは取れるが、状態管理がなく「1時間分見るべきか、1週間か」の判断ができない。 - Single Agent
ランブックやコンテキストを詰め込んだ単一エージェント。肥大化して遅くなり、未知のインシデントに対応できなくなる。 - Multi-Agent Systems 専門化されたエージェント群の協調動作。最も柔軟だが、オーケストレーションの複雑さがマイクロサービス同様の課題になる。
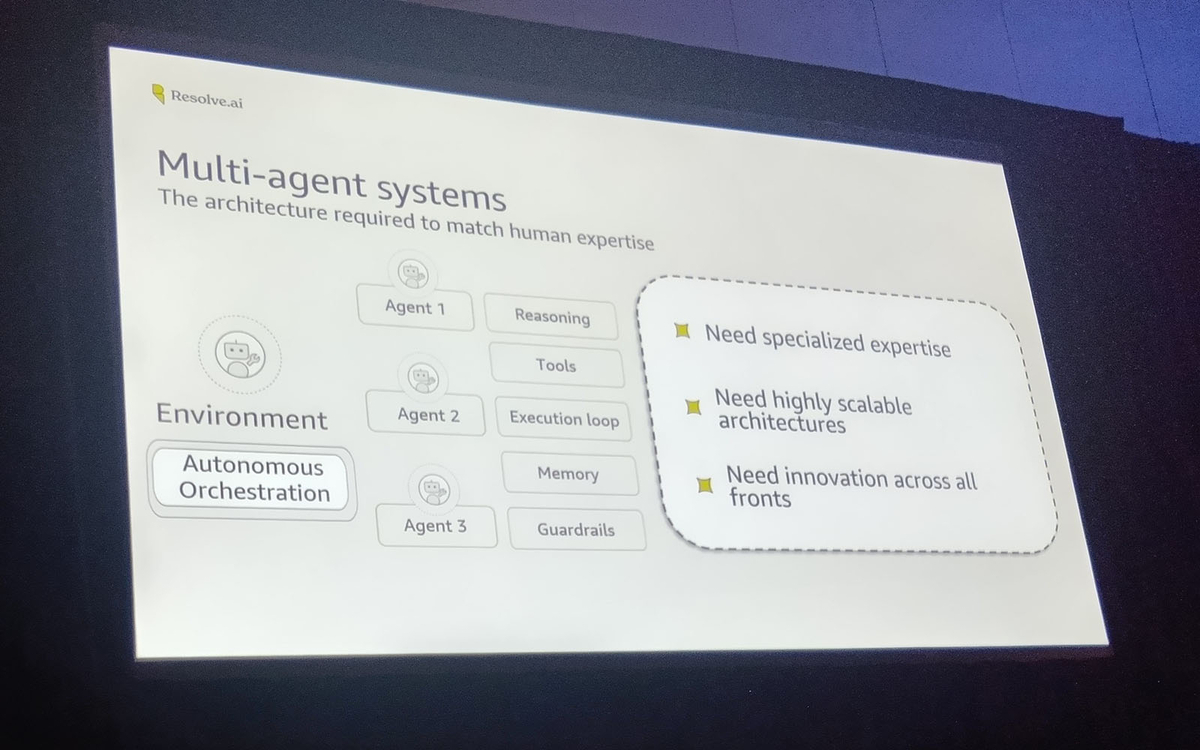
感想
今回のセッションでSREにフォーカスを当てたAIエージェントのサービスを初めて知りました。確かにインシデントの調査や一部対応は既存のAIエージェントでもできますが、既存の情報のみでしか判断等できずに自律的な成長などをエージェントにさせようとすると、とても難しいことだと改めて感じました。
セッションの内容はAWS公式のYouTubeチャンネルに公開されているので、さらに細かい内容を知りたい方はぜひそちらの動画をご覧ください!
[NEW LAUNCH] Resolve and prevent future operational issues with AWS DevOps Agent [REPEAT] (DVT337-R1)
計測システム部 バックエンドブロックの髙橋です。普段はZOZOMETRY、ZOZOGLASS、ZOZOMATなどの計測プロダクトのバックエンドの開発・運用を担当しています。
今回、Keynoteで新たに発表された「AWS DevOps Agent」について、Keynoteをリアルで聞きながら興味を持ちました。発表後にハンズオンを受けてきましたので、ハンズオンの内容とAWS DevOps Agentの使いどころについてご紹介します。
まず、AWS DevOps Agent(以下、DevOps Agent)とは、今回のre:Inventで発表されたFrontier Agentsの一角を成すAIエージェントです。主に運用上発生する障害などのインシデントに対し迅速に原因を調査し、それに対する解決策を提案してくれます(2025年12月の記事公開時ではPublic Preview)。その上で、今回のハンズオンでは用意されたシナリオを通じ、DevOps Agentの実際の使い所について学んできました。
AWS DevOps Agentができること - AWS上のリソースの可視化
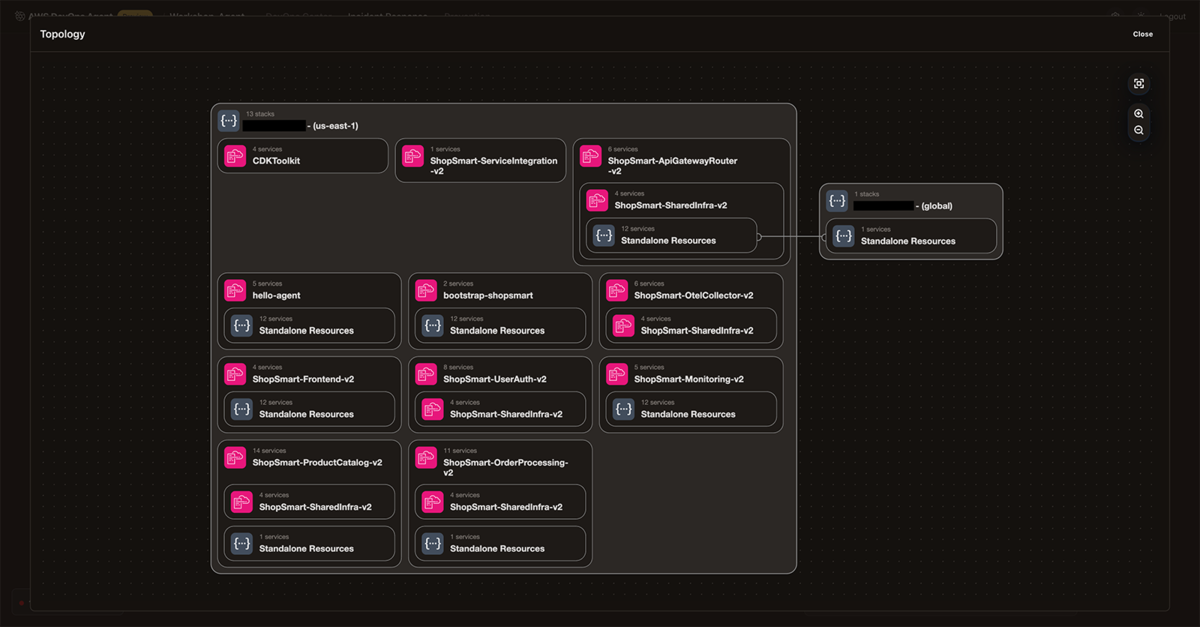
DevOps Agentでは、最初のステップとしてAgent Spaceというスペースを作成します。作成し、用意されたWebポータルにアクセスすると、現在ログイン中のアカウントのAWSリソースのトポロジが表示されます。
AWS DevOps Agentができること - 障害調査
今回のWorkshopでは、DynamoDBの書き込みキャパシティを意図的に大幅に絞り、システムに障害を発生させました。すると、予めセットされていたCloudWatch Alarmが発報します。
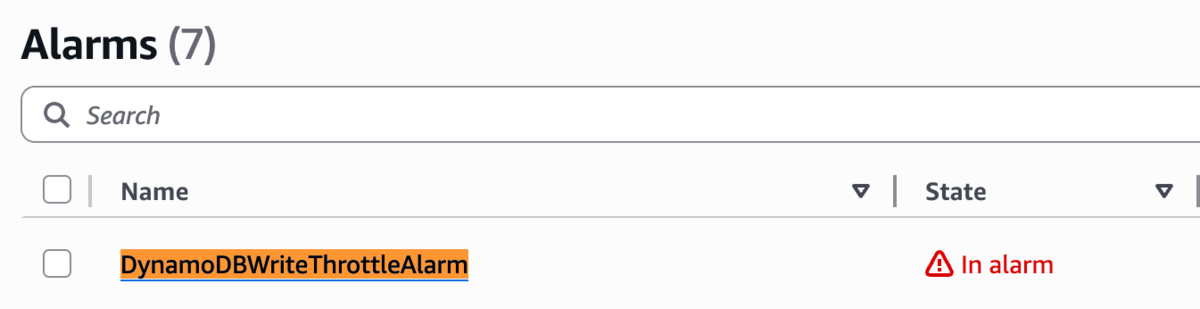
発報された後、DevOps Agentの「Start an investigation」ページで、「Investigate the DynamoDBWriteThrottleAlarm(CloudWatchで発報されたアラーム名)alarm」と入力し、調査してもらいます。
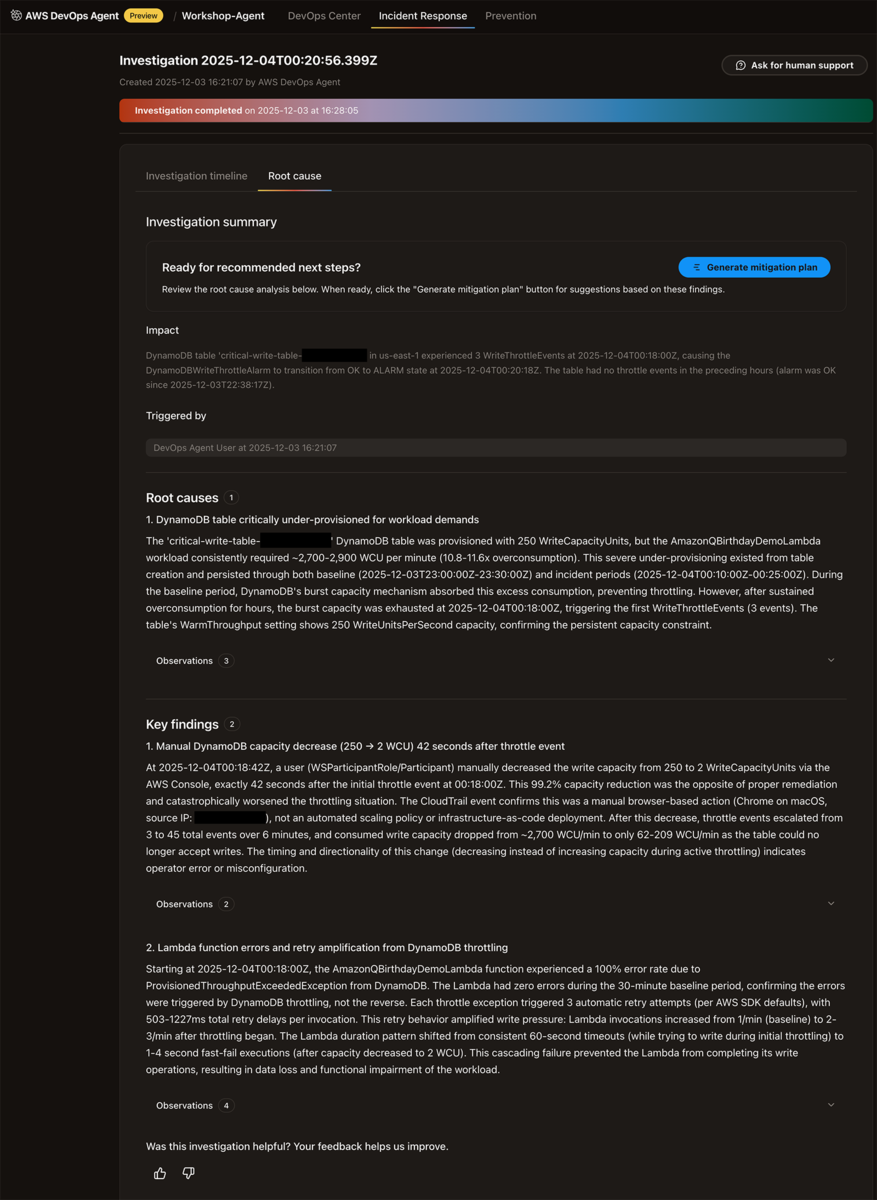
調査が進むと、「Root cause」という部分でDynamoDBの書き込みキャパシティの小ささが根本原因として書かれていることがわかります。
さらに、「Mitigation Plan」で実際の復旧に必要な作業の計画を立ててくれます。
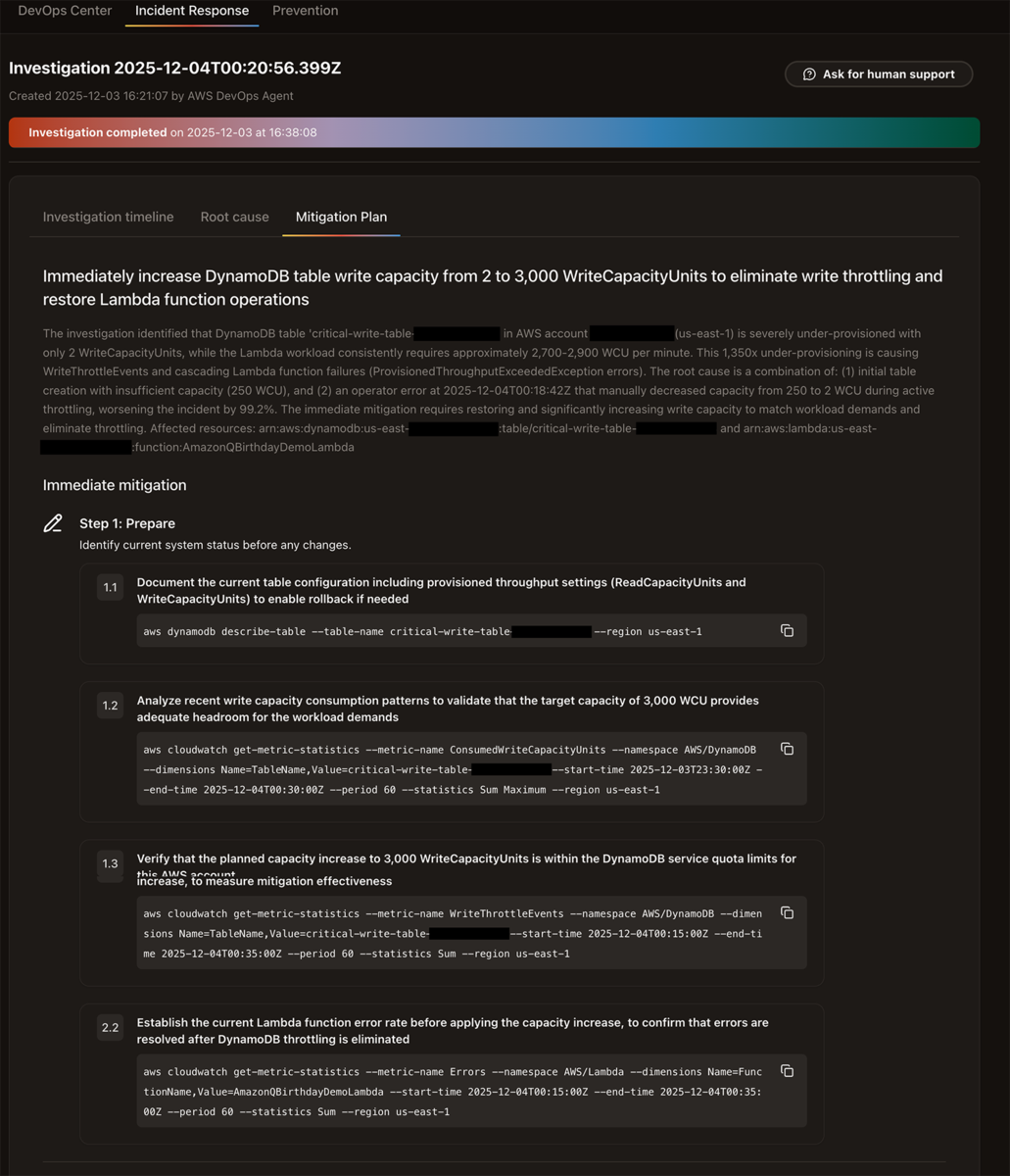
このように、今までは人間がやっていた障害内容の調査→原因究明→復旧のための計画までをDevOps Agentにアウトソースできます。
実際の使い所
DevOps Agentでは人間が先ほどの画像のように指示して調査させるだけではなく、Datadogなどのツールから異常検知されたことをトリガーとして自動的に調査を開始できます。
実際の運用現場では、アラートが鳴り、人間が気付いてからの初動対応は数秒レベルの即時とはいかない場合が多いですし、その時のメンバーによってシステムに対する習熟度や調査時に見る観点も違うでしょう。そのような場合にDevOps Agentが先回りして即時に自動で調査を開始し、人間に対して原因と復旧計画を提供することによってより高品質かつ、迅速な障害対応を行えると考えています。
現在DevOps Agentは現在Public Preview期間であるため、いきなり本番環境に組み込まずともチームのカオスエンジニアリング・障害訓練等からまず使ってみることもおすすめです。チームでのカオスエンジニアリングの記事は以下をご覧ください。
おわりに
セッションや展示ブースで多くのことを学べるのはもちろん、AWSのエキスパートや他社のエンジニアの方々と交流し、多くの刺激を受けられるのが現地参加の醍醐味です。今回得た知見を社内外に共有しながら、これからもAWSを活用してプロダクトとビジネスの成長に貢献していきます。
ZOZOではAWSが大好きなエンジニアを募集しています。奮ってご応募ください!