



はじめに
こんにちは、SRE部 検索基盤SREブロックの花房です。2025年12月11日に東京の虎ノ門で開催された「OpenSearchCon Japan 2025」にZOZOのエンジニア5人が参加しました。本記事では、会場の様子と印象に残ったセッションについて紹介します。
- はじめに
- OpenSearchCon Japanとは
- 会場の様子
- セッションレポート
- Maximize Resource Efficiency with Separated Index and Search Workloads
- Intelligent Japanese Search With OpenSearch
- Lessons From Migrating To OpenSearch: Shard Design, Log Ingestion, and UI Decisions
- OpenSearch Agentic Memory: Intelligent Context
- Mastering Search Performance: Advanced Query Insights for Production OpenSearch
- From Chaos To Control: GitOps Disaster Recovery With the OpenSearch Operator
- おわりに
OpenSearchCon Japanとは
オープンソースの分散型検索・分析エンジンであるOpenSearchに特化した国際カンファレンスです。OpenSearchの開発者やユーザが、主なユースケースである検索・オブザーバビリティ・セキュリティアプリケーションに関する技術的な最新情報や知見を共有します。
主催はLinux Foundation・OpenSearch Software Foundation・AWSです。毎年、世界各地で開催されており、今年は日本以外にヨーロッパ・インド・北アメリカ・韓国で開催されました。日本での開催は今年が初めてでした。

過去のセッションの録画や資料は以下のリンク先から確認できます。本記事の執筆時点ではまだ公開されていませんが、OpenSearchCon Japanの録画も公開されると思います。
会場の様子
今回の会場はビジョンセンター東京虎ノ門でした。5階の3部屋の内、1部屋を受付・ロビーとして、2部屋を発表会場として利用していました。
ロビーでは飲み物や軽食が提供されており、配置されていた丸いテーブルは他の参加者と話しやすい環境を作り出していたと感じました。


セッションレポート
特に印象に残ったセッションを紹介します。
Maximize Resource Efficiency with Separated Index and Search Workloads
SRE部 検索基盤SREブロックの富田です。普段はZOZOTOWNの検索基盤の運用・改善を担当しています。私はIndexingとSearchのワークロード分離に関するセッションについて紹介します。
課題
OpenSearchでは、検索(search)とインデキシング(indexing)が同じDataノードで動くのが基本でした。しかし、この仕組みは以下のような課題がありました。
- searchとindexingが同じリソース(CPU、メモリ、I/O)を奪い合うため、片方の負荷がもう片方に悪影響を与える
- 大量のindex更新が走ると、検索レイテンシが顕著に悪化する
- リソースを追加したくても「検索だけ増やしたい」「書き込みだけ減らしたい」といったワークロード別のスケールが出来ない
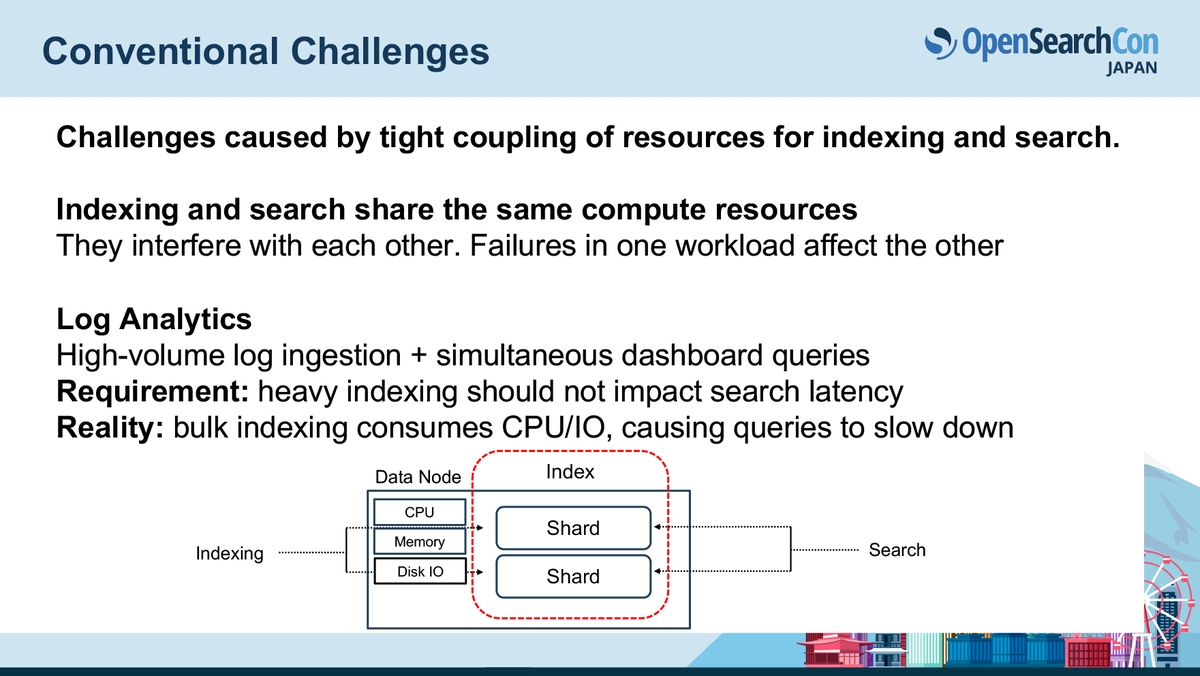
解決策: ワークロードの物理的分離(Reader-Writer Separation)
OpenSearch v3.0で導入されたReader-writer Separationは、search用ノードとindexing用ノードを物理的に分離します。
- 検索処理:Searchノード(Reader)
- インデックス作成:Dataノード(Writer)
これによりSearchノードは検索だけに集中し、indexing負荷の影響を一切受けなくなるというメリットがあります。
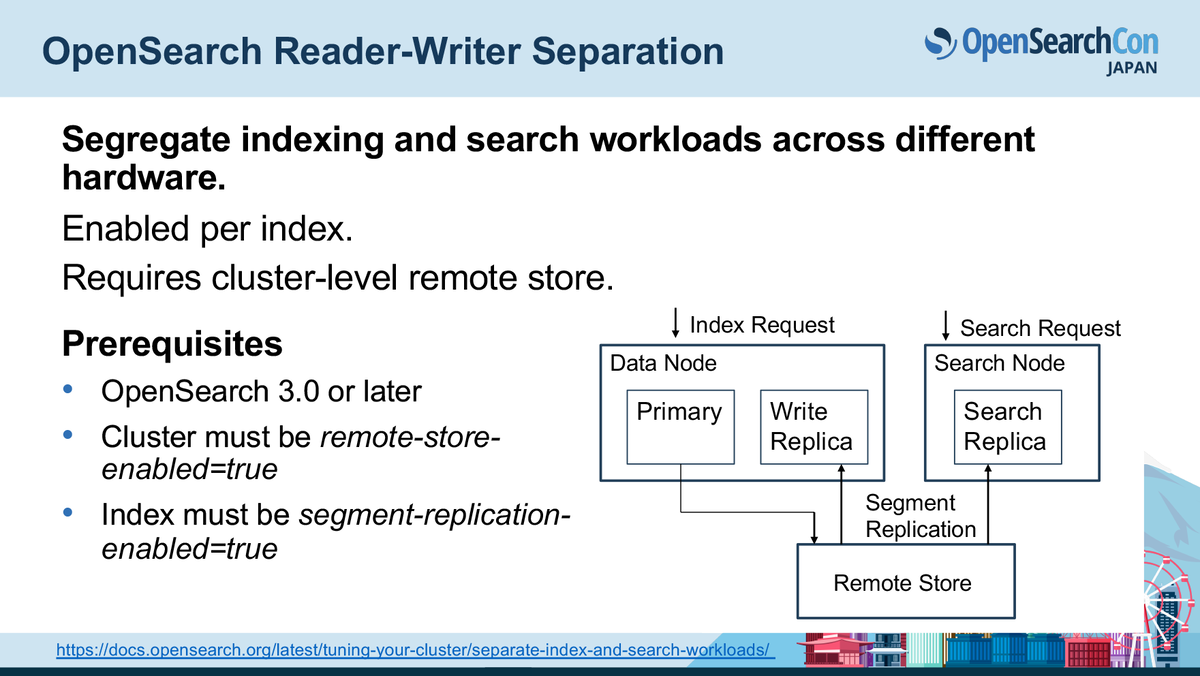
Remote Store(S3など)でデータの共有を実現
Searchノードがインデックスを持たなくても検索できる仕組みとして、Remote Store(リモートストレージ)が前提になります。
- Primary shardがセグメントをアップロード
- Search ReplicaがRemote StoreからPullする
この仕組みによってsearchとindexingの完全分離が実現されています。
感想
ZOZOTOWNの検索基盤でも、商品インデックスにindexingによる更新が走ると検索レイテンシに悪影響を与えるという課題に何度も直面していました。
今回のセッションで紹介されたReader-Writer Separationは、まさにこの問題を根本から解決できる仕組みなので非常に期待が大きい機能だと感じました。ただしこの機能はOSS OpenSearchのみ利用可能で、AWSのAmazon OpenSearch Serviceではまだサポートされていません。非常に良い機能だと思いますし、AWSのサービス側でもサポートされる予定と聞いたので期待しています。
(2026/01/07修正)現時点ではAWSサービスでのサポート予定はまだありません。
Intelligent Japanese Search With OpenSearch
検索基盤部 検索技術ブロックの今井です。普段は、検索システムの開発や検索精度の改善に取り組んでいます。
私からは、Amazon Web Service Japanの後藤氏によるOpenSearchを活用したインテリジェントな日本語検索のセッションを紹介します。
検索システムは主にドキュメントを格納するindexingとクエリから結果を取得するretrievalの2つで構成されているのですが、セッションでは検索精度の観点で主にretrievalを取り上げています。日本語検索の精度を改善したい方、困っている方は内容を把握しておくと良いと思います。
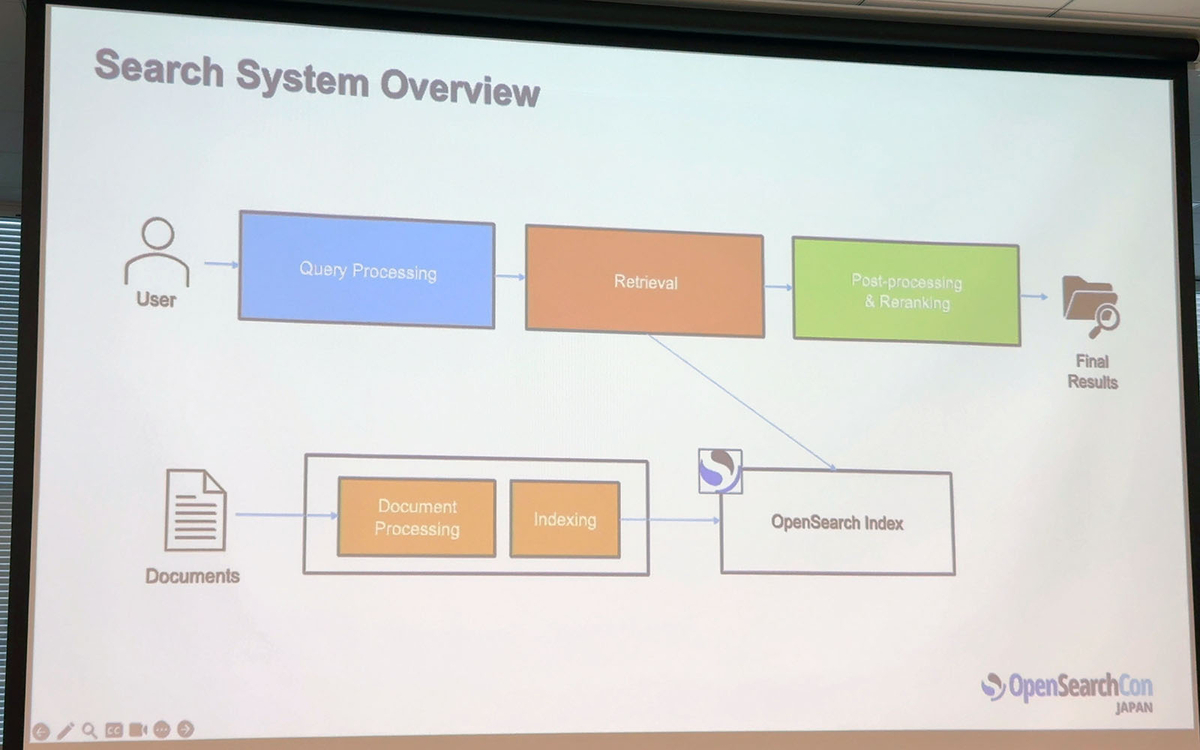
OpenSearchで利用可能な4つのretrieval手法について紹介がありました。ここでは各手法の特徴やメリット・デメリットの話がありました。
- 語彙検索(Lexical Search)
- BM25アルゴリズムによるキーワードマッチで高速かつ透明性は高いが、同義語に対応できず文脈も理解できない
- 密ベクトル検索(Dense Vector Search)
- BERTなどで意味をベクトル化し、「犬」と「ペット」のような意味的に近い言葉もマッチできるが、計算コストが高くなぜマッチしたのかの説明が困難
- 疎ベクトル検索(Sparse Vector Search)
- SPLADEなどでキーワードに重みを付け、メモリ効率が良いが日本語対応モデルが少ない
- 初回はラフに検索して2回目に最終結果を出すために検索するTwo-Phase Searchや効率的にスパース検索するNeural Sparse ANN Search, SEISMICの新機能も簡単に紹介もあった
- ハイブリッド検索
- 上記手法を組み合わせ、スコアベースまたはランクベースでスコアを統合
ハイブリッド検索のベクトル用インデックスとして、ドキュメント全体のベクトルを持つのか、Nested k-NN機能で1ドキュメントにネストで複数ベクトルを持つのかなどベクトル検索のためのインデックス設計の重要性についても解説がありました。

検索精度の向上には以下の要素も重要です。
- リランキングによる結果の再評価
- クエリ拡張によるシノニム展開や意図理解
- LLMを活用したAgentic Search
リランキングでは、OpenSearchの新機能としてベクトル検索のMMRリランキング が導入されたようです。これは関連性と多様性の両方を考慮したリランキングをMMRというランキングのバランスを取るアルゴリズムで実現する機能です。
これらの技術を組み合わせることで、ユーザーの意図を深く理解し、高精度な日本語検索を実現できると紹介されました。
感想
日本語検索に関する現在の取り組みが広く分かるセッションでした。ベクトル検索のインデックス設計の話で、Nested k-NN機能で1ドキュメントにネストで複数ベクトルを持つ手法は、ドキュメントに重要要素が複数あるユースケースではこの手法を使うと効果的だと感じました。
また、Neural Search Pipelineについての解説の中では、クエリをSearch Pipelineの中でベクトル化する機能が備わっている話があり、モデルを配置しセットアップすることで容易に利用可能になる点で印象に残りました。
公式ドキュメントの「Semantic search using a model in Amazon SageMaker」には、SageMakerを利用したベクトル検索の導入方法が記載されており使い方のイメージができました。
Lessons From Migrating To OpenSearch: Shard Design, Log Ingestion, and UI Decisions
検索基盤部 検索基盤ブロックの岡田です。普段はZOZOTOWNの検索機能に関する機能追加や保守運用を行っています。私からは、Sansan株式会社 藤原氏のログ基盤をセルフホストのElasticsearchからAmazon OpenSearch Serviceへ移行するプロジェクトに関するセッションを紹介します。
1日約150GBという大規模なログ流入がある環境で、移行時に実際に直面したトラブルについて具体的な原因と対応を知ることができた大変興味深いセッションでした。以下の3つの具体的な課題とその際の対応が紹介されました。
- 可用性の確保(Yellowステータス対策)
コスト重視のシングルノード構成ではレプリカを配置できず、ステータスがYellowになる課題がありました。これに対し、インスタンスサイズを下げて台数を増やす(複数台構成・マルチAZ)ことで、コストを維持したまま、許容リスクとのバランスを取った現実的な可用性を確保していました。 - 高負荷への対応(CPU高騰・バッファ溢れ)
構成上の問題でシャード数が3,000を超え、特定ノードでのインデックス作成負荷によりCPU使用率が高騰してしまいました。対策として、データ量に基づき「5日でローテーション」するISM Policyを適用してシャード数を約300まで削減しました。そうして更新間隔(refresh_interval)を120秒へ緩和することで解決を図りました。 - 運用リスクの顕在化(Redステータスとログ欠損)
さらなる負荷軽減のためにレプリカを「0」にした結果、ノード障害時にシャードが消失し、クラスターがRedステータス(機能不全)に陥りました。これにより自動復旧せず手動対応が必要となり、ログ欠損も発生してしまったとのことです。最終的には、インデックス負荷を根本から低減するために、マッピングの見直しやRemote Backed Storageの検討といったアプローチが紹介されました。
感想
本セッションを通じて痛感したのは、安定運用は継続的なチューニングによって初めて実現するという点です。ベストプラクティスは万能ではなく、実際のワークロードを観察しながら構成を磨き続ける姿勢こそが成功の鍵であることを強く認識しました。
特に、OpenSearchをアプリケーションの検索エンジンとして利用する場合、この姿勢は一層重要になります。アプリケーションのトラフィック特性やデータ構成の仕様要件に踏み込んだ丁寧な設計と、それを支える継続的なモニタリングが不可欠であることを改めて学ぶことができました。
OpenSearch Agentic Memory: Intelligent Context
検索基盤部 検索基盤ブロックの佐藤です。AIエージェントに「長期記憶」を持たせるための基盤として提案された OpenSearch Agentic Memory に関するセッションについて紹介します。本セッションでは、従来のLLMが抱える「金魚の記憶問題」を解決し、ユーザーとの対話を継続的に深めていくための実装アーキテクチャやデモが数多く取り上げられていました。
発表内容については以下のブログで取り上げられています。詳しくはこちらをご参照ください。
OpenSearchを「記憶装置」として活用し、短期記憶と長期記憶を分離する設計は非常に興味深く、AIエージェントの実用性を大きく引き上げる手法だと感じました。また、REST APIベースのフレームワーク非依存な構成により、LangChainをはじめとする既存エコシステムと柔軟に統合できる点も魅力的でした。
本セッションが焦点を当てていたのは、AIエージェントが抱える本質的な課題──「コンテキストを保持できない」という問題でした。コンテキストウィンドウの制約により長い対話履歴を保持できなかったり、セッションを跨ぐと過去情報を完全に忘れてしまったりする限界が、これまでのユーザー体験を大きく阻害していました。
これに対し、発表者らが提示した解決策はOpenSearchを用いた永続的なエージェント用メモリ「Agentic Memory」です。
アーキテクチャは大きく以下の4つのコンポーネントで構成されています。
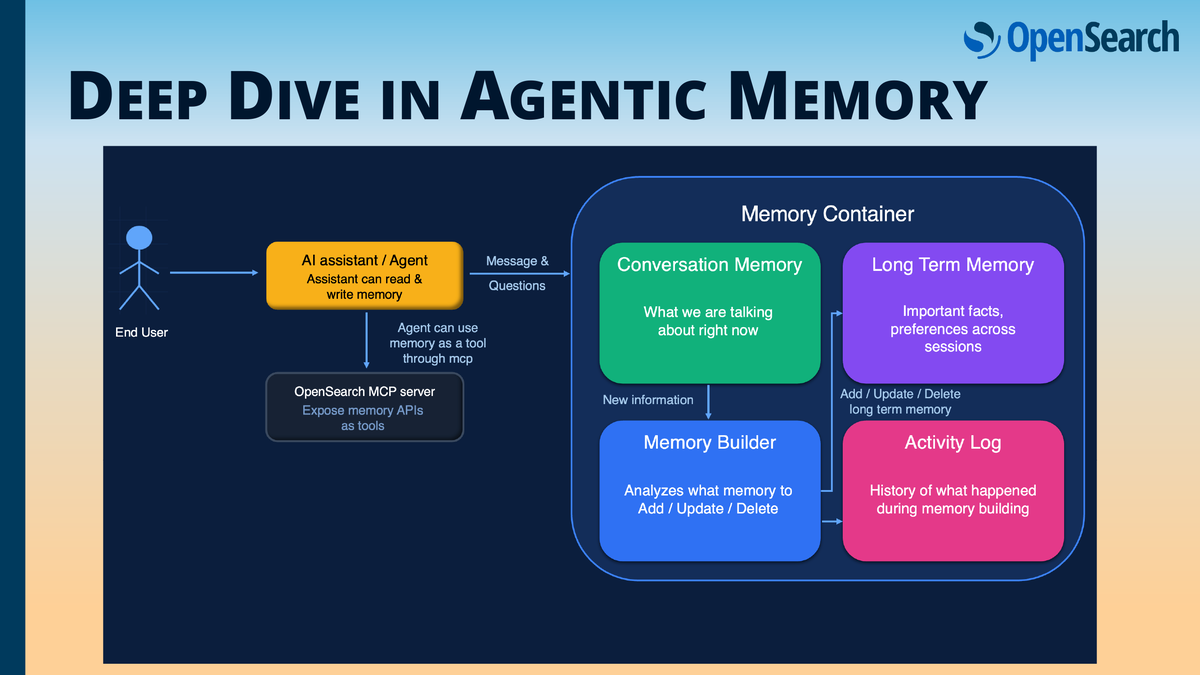
- Conversation Memory(短期記憶):現在のセッションに必要な会話履歴を保持
- Memory Builder(情報抽出):LLMを用いて「記憶として残すべき情報」を抽出・構造化
- Long term Memory(長期記憶):永続的な知識としてOpenSearchに保存
- Activity Log(監査ログ):記憶の読み書きを追跡し、透明性を担保
この二層構造により、AIエージェントは必要なときにだけ長期記憶からベクトル検索で関連情報を取り出し、過去のやりとりを踏まえた文脈的に豊かな応答が可能になります。
具体的な実装ノウハウとしては、以下の3つの記憶戦略が紹介されました。
- Semantic Strategy:会話の中から重要な事実や知識を抽出
- User Preference Strategy:ユーザーの嗜好(好み、履歴、選択基準)を蓄積
- Summary Strategy:セッション全体を要約して長期的な理解を保存
また、ユーザー別・エージェント別に独立した記憶領域である「Namespaces(名前空間)」を作れるため、マルチテナント環境への展開にもそのまま対応できる設計となっています。
デモでは、LangChainを用いたショッピングエージェントや旅行計画エージェントが紹介され、過去の嗜好や計画を思い出しながらユーザーに提案する様子が説明されました。特定のフレームワークに依存しないREST API構成のため、既存のエージェント基盤との統合性が高い点も強調されていました。
感想
AIエージェントの賢さはモデルの性能だけでなく、「何をどのように覚え続けるか」で決まる、というメッセージが非常に腹落ちしました。短期記憶と長期記憶をOpenSearch上で分離し、LLMはあくまで「記憶を整形する役」として使う設計は、運用とスケーラビリティの観点でも現実的だと感じました。
また、既存のLLMは膨大なコンテキストを一度に入力すると精度が低下する傾向があります。しかし、この二層構造により必要な情報だけを効率よく取り出せる点も魅力的でした。特に、ユーザー嗜好や行動履歴を扱える仕組みは検索のパーソナライズ機能との相性が良く、プロダクト体験の向上にも大きく寄与すると感じました。
Mastering Search Performance: Advanced Query Insights for Production OpenSearch
SRE部 検索基盤SREブロックの花房です。このセッションでは、「Query Insights」というクエリパフォーマンス調査用プラグインについて紹介されました。
検索クエリのパフォーマンス調査や最適化が必要になる場面は多々あります。標準機能によりスローログは出力可能ですが、出力されたログをUI上で確認したり、詳細に分析したりするのは難しいという課題があります。
Query Insightsはクエリパフォーマンス分析のための機能と専用ダッシュボードを提供してくれるプラグインです。プラグインをインストールすると、OpenSearch Dashboardsに「Query Insights Dashboards」というメニューが追加され、GUIベースで詳細な分析が可能になります。プラグインに関連するリポジトリを以下に記載しておきます。
- プラグイン:https://github.com/opensearch-project/query-insights
- ダッシュボード:https://github.com/opensearch-project/query-insights-dashboards
Query Insightsでは現在、以下の3つの機能が利用可能です。
- Top N queries:レイテンシ・CPU・メモリに基づいて、リソースを大量に消費しているクエリを特定できる。さらに、Pattern Grouping機能により類似したクエリはグループ化して表示も可能。
- Live queries:実行中のクエリに関する各種メトリクスをリアルタイムで確認できる。
- Configuration:Top N queriesの抽出閾値や集計間隔、Query Insights自体のデータの出力先を設定できる。
感想
クエリパフォーマンスの分析データを取得・保存する場合、やはりクラスタ全体への負荷影響が気になります。しかし、このプラグインでは優先度キューや非同期処理などを活用したアーキテクチャにより影響を最小限に抑えていました。ユーザのことを考慮し、導入しやすい工夫がされていると感じました。
Query Insights DashboardsのUIは使いやすい雰囲気を感じました。今後はProfile API Visualizerへの対応も進められるようなので、さらなる利便性の向上に期待を寄せたいと思います。
From Chaos To Control: GitOps Disaster Recovery With the OpenSearch Operator
花房です。このセッションは、OpenSearch OperatorとGitOpsを活用した障害復旧の自動化手法についての発表でした。
OpenSearch Operatorは、OpenSearchの運用管理を自動化するKubernetes Operatorです。クラスタやダッシュボードをはじめとする基本的なリソースに加え、インデックスやスナップショットなどのライフサイクル設定もKubernetesのCustom Resource (CR) として宣言的に定義できます。発表の中では、Node pools, Roles, Plugins, Security, Dashboardsの5つが設定項目の例として挙げられていました。
GitOpsは、Gitリポジトリを唯一信頼できるソースとして管理し、専用ツールによってリポジトリと実環境を同期させることでデプロイや運用を自動化する手法です。発表の中では、ツールとしてArgo CDを利用していました。
OpenSearch OperatorとArgo CDを組み合わせることで、インフラ構築から詳細設定までを一貫してコードで管理し、障害発生時には自動復旧する高度な仕組みを実現していました。仮にクラスタが完全に消失しても、以下のプロセスを経て自動的に再構築・復旧が完了します。
- Argo CDがGitリポジトリに基づいてKubernetesにクラスタをデプロイ
- OpenSearch Operatorがクラスタをプロビジョニング
感想
セルフホストでの運用や障害対応はどうしても負荷が高くなってしまうものですが、この方法ならマネージド並とはいかないまでも、運用負荷をかなり抑えつつシステムの安定性も保つことができると感じました。
注意点として、スナップショットの復元におけるデータの一部損失の可能性が挙げられていました。そのようなパターンも想定し、クラスタが再構築された後はインデキシングのバッチをフックし、インデックスを作り直すところまで完全に自動化できると理想的だと考えました。
おわりに
本記事では、OpenSearchCon Japan 2025の参加レポートをお届けしました。イベントへの参加を通して得られた主な収穫・知見は以下の通りです。
- ZOZOTOWNの商品検索にとって有用と考えられる新機能について、日本の開発コミュニティの方から直接説明を聞き、理解を深められた
- 検索・オブザーバビリティ・セキュリティアプリケーションの各領域における日本国内でのユースケースやプラクティスを知れた
- Query InsightsやMCPサーバなど、ユーザの利用体験を向上する拡張機能について、デモを通じて効果と可能性を実感できた
1日だけの開催でしたが、その期間の短さを感じないほどOpenSearchに関する多くの学びを得られた充実したカンファレンスでした。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからご応募ください。