




はじめに
こんにちは、計測プラットフォーム開発本部SREブロックの山本です。普段はZOZOMATやZOZOGLASSなどの計測技術に関わるシステムの開発、運用に携わっています。
我々のチームは、複数サービスを運用する中で障害対応の経験不足や知見共有の難しさといった課題に直面していました。そこで、半年ほど前にカオスエンジニアリングの導入を開始しました。
本記事では、カオスエンジニアリングを一過性のものではなくチームの文化として根付かせ、継続的な改善サイクルを生み出すための導入から運用まで、我々のチームでの実践から得られた具体的な方法をお伝えします。
これからカオスエンジニアリングを始めようとしている方はもちろん、すでに導入しているものの効果的な運用に悩んでいる方の参考になれば幸いです。
目次
背景・課題
我々のチームでは、オンコール担当をローテーションで回しながらシステムの安定運用に努めています。しかし、以下のような課題に直面していました。
障害対応の経験不足
- システムの安定性が向上し、実際の障害の発生頻度が低下したことで、チームメンバーが障害対応の経験を積む機会が減少した
役割の固定化
- 障害発生時、特定のメンバーが特定の役割を担当する傾向があった
- それにより障害が発生したタイミングで、メンバーの負荷状況に応じて柔軟に対応することが難しくなっていた
知見の偏り
- システム障害時の勘所や、調査時の必須知識(コマンドや監視ツールのどこを見るべきか、などといった知見)がチーム全体に浸透していなかった
これらの課題を解決し、チーム全体の障害対応の能力を向上させるため、カオスエンジニアリングの導入を決定しました。
カオスエンジニアリング導入の流れ
我々のチームではカオスエンジニアリングの導入を以下のステップで行いました。
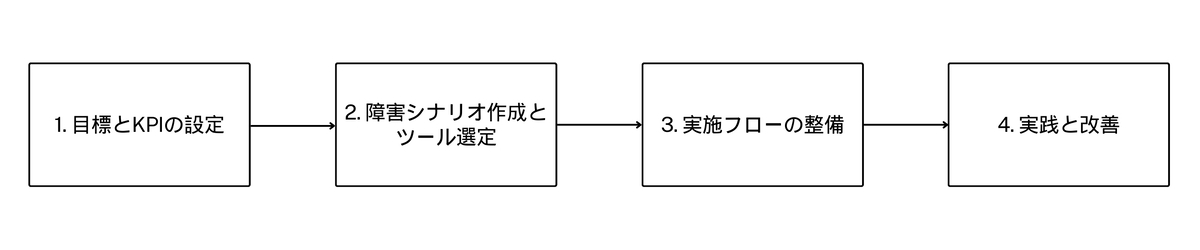
- 目標とKPIの設定
- 障害シナリオの作成とツール選定
- 実施フローの整備
- 実践と改善
それぞれのステップについて説明します。
1. 目標とKPIの設定
カオスエンジニアリングを効果的に実施するため、まずチーム目標に基づいた具体的な目標とKPIを設定しました。これは非常に重要なステップで、これをやらないとカオスエンジニアリングの効果が半減すると言っても過言ではないと思います。
1.1 目標設定
前述した課題の解消を目指し、目標を以下のように設定しました。
- チームメンバーの障害対応の能力を向上させ、障害対応フローを効率化する
- システムの障害リスクを特定しチーム全体で把握する
- システムの耐障害性と安定性を向上させる
目標を設定することで、チーム内外でのカオスエンジニアリングに対する認識を揃え、今後何をやって何をやらないか判断できるようになります。
1.2 KPIの設定
各目標に対し、以下のようにKPIを定めました。
- チームメンバーの障害対応の能力を向上させ、障害対応フローを効率化する
- 各メンバーのカオスエンジニアリング実施回数:1回/月以上
- インシデント対応にあたったメンバーの自己評価スコア:80点以上
システムの障害リスクを特定しチーム全体で把握する
- カオスエンジニアリング実施時の挙動予測スコア:80点以上
- 障害発生から検出までの時間:3分以内
システムの耐障害性と安定性を向上させる
- 障害発生から復旧までの時間(MTTR):10分以内
- カオスエンジニアリング実施時のエラーバジェット消費率:エラーバジェット枯渇までの期間がSLO目標の全期間の25%以上をキープ
- 例えば、SLO目標の全期間が30日の場合に7.5日でエラーバジェットが枯渇するような消費率を超えるとアウト、ということ
これらの目標とKPIは、カオスエンジニアリングの実施ごとに見直し、改善を重ねています。
1.3 KPIの測定方法
各KPIの測定方法について、いくつか例を挙げます。
- カオスエンジニアリング実施回数
- 実施ごとにドキュメントを残し、実施の都度確認する
- 自己評価スコア
- 評価項目を事前に用意し、実施後に自己採点する
- 障害検出までの時間
- カオスエンジニアリング開始時からアラート通知までの時間を計測する
- 検知されない場合はKPI未達とする
- エラーバジェット消費
- DatadogのSLOバーンレートアラートを使用し、アラートが発火された時点でKPIは未達となる
これらのKPIは、カオスエンジニアリング実施の都度確認し、目標の達成度を測ります。なお、実際の自己評価の項目は後述の『実施フローの整備』の部分で詳細に紹介しています。
1.4 KPI設定時の考慮点
KPIを設定する際は、以下の点を考慮しました。
- 目標とKPIの整合性
- KPIの達成が目標の達成に繋がること
- 現実的な計測可能性と改善可能性
- 計測が出来る指標であることと、改善が現れる指標であること
- KPIとしての有用性
- 数値が正常化されることで改善に繋がるKPIであること
- 逆に数値が正常化されたからといって改善に繋がっているとは限らないKPIはNG
このように目標とKPIを設定することで、カオスエンジニアリングの効果を具体的に測定し、継続的な改善サイクルを確立することが出来ました。また、これにより取り組みの成果を可視化し、チーム全体で改善に向けた意識を高めることが出来ています。
カオスエンジニアリングの導入を検討されている方々は、チームの状況に合わせて適切な目標とKPIを設定することをお勧めします。
2. 障害シナリオの作成とツール選定
カオスエンジニアリングを効果的に実施する上では、起こりうる障害シナリオとその影響を事前に予測しまとめておくことが重要です。
これは以下の記事でも紹介されているので、ぜひご覧ください。
このステップにより、システムの障害リスクに気づくきっかけとなるだけでなく、実際のカオスエンジニアリング実施時に予期せぬ影響が見つかった際により大きな学びが得られます。
2.1 シナリオ作成のプロセスとシナリオ例
前提として、カオスエンジニアリングの対象とするサービスは1つに絞った上で、以下のステップでシナリオを作成しました。
- 過去の障害ログの分析
- 過去に発生した実際の障害事例を確認
- システム構成図からの検討
- 利用しているプラットフォーム(Datadog, Kubernetes, AWS)ごとに起こりうる障害の洗い出し
- 重要度と実現可能性による絞り込み
- 影響の大きさと、カオスエンジニアリングツールでの再現可能性を考慮
これらのステップを通して、以下のシナリオを扱うことに決定しました。
- Availability Zoneネットワーク障害
- Dynamo DBネットワーク障害
- ElastiCacheインスタンス障害
- S3ネットワーク障害
- Pod CPU圧迫
- Pod Memory圧迫
なお、シナリオの実現可能性を考慮し、ツールとしてはAWS Fault Injection Service(以降、FISと記載)を使用することにしました。FISはAWSリソースへの障害注入に特化しているだけでなく、EKS上のPodへの障害注入も可能で、カオスエンジニアリングの対象とするサービスのインフラ構成に最適であったためです。
ツールの比較・検討をする中で、Litmus ChaosはGitOps対応やFIS経由の障害注入など魅力的な特徴がありましたが、現時点ではFISのみで十分と判断しました。
2.2 シナリオによる影響予測
次に、決定されたシナリオの実行時にシステムが受ける影響を予測します。各シナリオで以下の項目を考慮して進めました。
- 障害の影響範囲
- システムへの影響予測
- 影響を受けるメトリクスとSLI/SLO
- アラート・モニタリングでの検知可能性
- 障害検知と復旧までの予想時間
なお、ここでは1つを深掘りし過ぎないようにし「予測→実践→改善」のサイクルを回してブラッシュアップしていくことを優先する意識をしていました。
以下は、これらを踏まえて『S3ネットワーク障害』での影響を予測した例になります。

3. カオスエンジニアリングの実施フローの整備
シナリオまで考えることが出来れば、あとは実施していくだけなのですが、長期的に見ると「いかにカオスエンジニアリングを形骸化させず継続的にチーム全員で運用していくか」が重要です。
そのため、以下のようにカオスエンジニアリングの実施フローを整備しました。
- カオスエンジニアリングの実行者と対応者を決める
- (実行者のみ)障害内容を決め、システムの挙動を予測する
- カオスエンジニアリング実施のアナウンスを行う
- カオスエンジニアリングを開始する
- 障害対応をする
- 振り返りを行う
実施フローの各項目について説明します。
3.1 カオスエンジニアリングの実行者と対応者を決める
我々のチームでは、障害を注入する実行者を一人決め、他のチームメンバーはそれに対応する対応者として役割を分けることにしました。
一般的にはチーム全体で障害シナリオとその影響を考えることが多いと思いますが、起こる障害が事前に分かっていないことで、対応者の障害対応スキル向上に繋がると考えてこのような形式にしています。これは「チームメンバーの障害対応の能力を向上させ、チームとしての対応フローを効率化する」という目標に沿っています。
なお、実行者と対応者はツールを使ってランダムに選出するようにしています。
3.2 (実行者のみ)障害内容を決め、システムの挙動を予測する
このステップでは実行者が実施する障害と障害を継続しておく時間を決め、システムの挙動を予測します。これは先ほどの『障害シナリオの作成』のセクションでやったことそのものです。
もちろん、アプリケーションにこっそりバグを混入させるなどしてFISを利用せずに障害を起こすのもありです。
なお、実施内容と挙動の予測はカオスエンジニアリングを実施する前にドキュメント化し、まとめておきます。
3.3 カオスエンジニアリング実施のアナウンスを行う
カオスエンジニアリングを行う環境を使っている他チームに影響を与えてしまう可能性があるので、前日までにその旨を伝えておきます。
3.4 カオスエンジニアリングを開始する
ついに障害を注入していきます。
理由は後述しますが、我々のチームではステージング環境でカオスエンジニアリングを実施することにしています。そのため、障害発生中にサービスにより近い状態を再現すべく、ローカルから負荷をかけながら障害を注入していきます。
具体的には、FISを使って障害注入をする場合、aws fis start-experiment コマンドを実行することで事前に用意したシナリオを発火します。
3.5 障害対応をする
我々のチームでは、障害対応時の役割として指揮者・コミュニケーション担当・記録者・オペレータを決めるルールにしているので、初めに対応者間で役割を確認します。
カオスエンジニアリングが開始されたら、対応者はアラートなどを元に原因を理解し、サービスを継続させるための対策をしていきます。なお、「ユーザーが問題なくサービスを受けられている」ことを「サービス継続」と定義しています。
ポストモーテムもカオスエンジニアリング用にドキュメントとして作成します。
また、実行者はこのタイミングで「カオスエンジニアリング実施中のタイムライン」をまとめておきます。
3.6 振り返りを行う
障害注入が終了し、障害対応が完了したら実行者と対応者で振り返りミーティングを行います。振り返りミーティングの内容は以下のような流れになっています。
| 概要 | 詳細 |
|---|---|
| 1. 実行者から障害内容について共有 | 事前準備で用意した障害シナリオとシステムへの影響予測、カオスエンジニアリング実施中のタイムラインを共有する。対応者からすると、ここで答え合わせが行われるイメージ。 |
| 2. 対応者から対応の流れの共有 | 障害対応時に用意したポストモーテムを元に対応の流れを振り返る。 |
| 3. KPIの達成度を記入 | 各KPIの達成度をメンバーごとに評価する。 |
| 4. 改善点のブレスト | KPIの達成度を元に、実行者・対応者のそれぞれの観点で改善点をブレストする。 |
| 5. ネクストアクションの整理 | ブレストで挙がった改善点のうち、必要なものをタスクに落とし込む。 |
なお、KPIの達成度は、以下のように各項目を数値化し得点や結果を残すようにしています。
| KPI | KPIの項目 | 数値化する方法 |
|---|---|---|
| 1. 各メンバーのカオスエンジニアリング実施回数が1回/月以上 | 今月の実施回数を数える | |
| 2. (対応者のみ)インシデント対応にあたったメンバーの自己評価スコアが80点以上(7項目合計) | 初動対応の適切さ | 障害発生時の最初の対応は適切かつ迅速だったかを振り返り、対応者全員が点数をつける(15点満点) |
| 障害対応時のチームワーク | 障害対応時に適切に各メンバーのロールを決めて動けたか・連携は適切だったかを振り返り、対応者全員が点数をつける(15点満点) | |
| コミュニケーションの適切さ | チーム内外への情報共有が明確かつタイムリーに行われたかを振り返り、対応者全員が点数をつける(15点満点) | |
| 障害記録の適切さ | 障害の詳細、原因などポストモーテムに適切に記録できたかを振り返り、対応者全員が点数をつける(15点満点) | |
| 障害の原因特定までの速さ | 障害の原因をいかに迅速に特定できたかを振り返り、対応者全員が点数をつける(15点満点) | |
| 障害の原因特定の正確さ | 障害の原因をいかに正確に特定できたかを振り返り、対応者全員が点数をつける(15点満点) | |
| ツール活用の度合い | 利用可能なツールやリソースを最大限活用して障害対応にあたることができたかを振り返り、対応者全員が点数をつける(10点満点) | |
| 3. (実行者のみ)カオスエンジニアリング実施時の挙動予測スコアが80点以上(5項目合計) | 事前準備における「システムに起こること」の正確さ | 事前に予測した障害が与えるシステムへの影響がいかに正確であったかを振り返り、実行者が点数をつける(20点満点) |
| 事前準備における「障害の影響が想定される範囲」の正確さ | 事前に予測した「障害の影響が想定される範囲」がいかに正確であったかを振り返り、実行者が点数をつける(20点満点) | |
| 事前準備における「障害により影響を受けるメトリクス・SLI/SLO」の正確さ | 事前に予測した「障害により影響を受けるメトリクス・SLI/SLO」がいかに正確であったかを振り返り、実行者が点数をつける(20点満点) | |
| 事前準備における「アラート・モニタリングで気づけるか」の正確さ | 事前に予測した「アラート・モニタリングで気づけるか」がいかに正確であったかを振り返り、実行者が点数をつける(20点満点) | |
| 事前準備における「気づくまでにかかる時間・復旧にかかる時間」の正確さ | 事前に予測した「気づくまでにかかる時間・復旧にかかる時間」がいかに正確であったかを振り返り、実行者が点数をつける(20点満点) | |
| 4. カオスエンジニアリング実施時の障害発生後から検出されるまでの時間が3分以内 | カオスエンジニアリング終了後に検出までの時間を計算する | |
| 5. カオスエンジニアリング実施時の障害発生から復旧までの時間(MTTR)が10分以内 | カオスエンジニアリング終了後に復旧までの時間を計算する | |
| 6. カオスエンジニアリング実施時において、エラーバジェット枯渇までの期間がSLO目標の全期間の25%以上をキープ | DatadogのSLOバーンレートで計測する |
フローをドキュメント化し、チームの合意を得たことで、属人化を防ぎ、全員でカオスエンジニアリングを継続的に運用しやすくなりました。
4. 実践と改善
フローの整備まで完了すれば、あとはフローに沿ってカオスエンジニアリングを実施していくだけです。
我々のチームでは、毎月GameDayとしてカオスエンジニアリングを実施し、その都度振り返りを行うことにしています。
また、我々は現在、ステージング環境でカオスエンジニアリングを実施しています。これは「本番環境での直接検証」を推奨するPrinciples of chaos engineeringの内容とは異なりますが、リスク軽減のため現段階では適切と判断しています。
本番環境での実施も検討していますが、ツール等の進化により、ステージング環境でも本番同様のトラフィックでの試験が可能になってきているため、安全かつ本番と同様の状況下での試験方法を探っています。
カオスエンジニアリング導入の効果
カオスエンジニアリングの導入により、以下のような効果が得られました。
- 月に1回GameDayを行う文化の醸成
- 障害対応フローの効率化
- システムへの理解度向上・障害リスクの把握
- アラート・モニタリング設定の最適化
それぞれ説明していきます。
効果1. 月に1回GameDayを行う文化の醸成
カオスエンジニアリングを導入して以来、月に1回必ずGameDayを実施するようになりました。
ここまでカオスエンジニアリングが浸透したのは「小さく始めて敷居を下げ、徐々に拡大していく」というアプローチが要因の1つだと考えています。
- 個人での「セルフカオスエンジニアリング」からスタート
- SRE内での実施へ拡大
- 開発チームを巻き込んだ全体での実施へ
この段階的なアプローチにより、チームメンバーの心理的ハードルを下げることが出来たのだと思います。また、既存のツール(FIS)を活用し、最もシンプルな構成のプロダクトから始めたことも、スムーズな導入に寄与しました。
さらに、明確な目標とKPIを設定し、毎回の振り返りで「次はこうしよう!」という前向きな議論が生まれたことも、継続的なカオスエンジニアリングの実施を後押ししています。
効果2. 障害対応フローの効率化
振り返りの際にKPIをベースに足りなかった点・改善点を話し合う中で、既存の障害対応フローで至らない点を改善するサイクルができました。
効率化のアイデアも挙がり、それを次回のGameDayで試してみようという流れも出来ています。
例えば、我々のチームでは障害時には専用のSlackスレッドを作り、その中でそれぞれが調査内容などを自由に投稿していくスタイルでした。しかし、これだと他の人が何を調査しているのかが見えず作業が被ってしまうケースがありました。そこで、Confluenceの同時編集の機能を活用し、それぞれが作業している内容とその調査結果をリアルタイムで見られるようなフローにするアイデアが出たこともありました。
さらに、GameDayの中で普段よくやる・やったことのある役割は出来るだけやらないようにすることで、役割の固定化も解消することが出来ています。
- 指揮者と調査担当者とのコミュニケーションの形はどうするとやりやすいか
- 原因特定か影響範囲の割り出しのどっちを優先すべきかを指揮者の立場から判断しかねたので、どうすべきだったか
など、役割ごとに「どのような動きが望ましいか」を振り返りでフィードバックし合うようにしたことも影響していると思います。
効果3. システムへの理解度向上・障害リスクの把握
GameDayを行う際には、障害を仕掛ける側は毎度システムにどのような作用があるか仮説を立て、それを振り返りで採点するフローになっているため、システムの理解度が上がりました。
また、システムへの作用について仮説を立て、実際にカオスエンジニアリングを実施する中で、予想外の障害リスクを発見できました。
例えば、GameDayでS3ネットワーク障害を発生させたところ、ECRからimageのpullが出来なくなり、デプロイが失敗するようになることがわかりました。これは、『2.2 シナリオによる影響予測』のセクションで例に挙げたS3ネットワーク障害の影響予測には記載されていなかった影響で、完全に予想外の障害リスクでした。
障害を仕掛ける役割をローテーションすることでこのような発見をするチャンスが全メンバーに与えられるだけでなく、振り返りで共有も行われるので知見の偏りを防ぐことができるようになりました。
効果4. アラート・モニタリング設定の最適化
カオスエンジニアリングによって、いくつかのアラートやモニタリング設定の穴に気づくことも出来ました。
例えば、GameDayで障害対応をする中で、ログが構造化されておらず検索効率の悪いアプリケーションがあることに気づき、改善につながることがありました。
また、ElastiCacheのfailoverを発生させた際には、本来発生するはずのアラートが発生しないケースもありました。そこで、なぜアラートが発生しなかったのかを分析したところ、必要な監視項目が不足していたことが判明しました。また、そもそもElastiCacheは構成上必要ないかもしれないという仮説も生まれました。
細かい点だと、我々のチームでは複数プロダクトを管理しているため、不慣れなプロダクトでアラート発生した際にどの情報を確認すべきかを素早く判断することが難しいと分かりました。そこで、即座に対応できるよう、アラートのDescriptionに「監視設計のリンク」や「確認すべき情報源」を明記するなど小さな改善も行われています。
カオスエンジニアリングの導入後に感じた課題と対策
ここまで、我々のチームにカオスエンジニアリングを導入した方法とその効果を紹介してきましたが、当然全てがいきなり上手くいったわけではありません。
カオスエンジニアリングを導入し実践していく中で感じた課題がいくつかあったので、ここではそれらの課題と対策について共有します。
課題1. 障害が発生していないのか負荷がかかっていないだけなのかわからない問題
問題の詳細
前述の通り、我々はステージング環境でカオスエンジニアリングを実施しているため、本番環境の負荷を再現するために負荷試験を流しながら障害を実行しないといけません。
その制約により、GameDayが始まったにもかかわらずアラートが発生しない場合に「異常を検知できていない」のか「実行者が負荷をかけておらずエラーになっていない」のか判別できないという問題がありました。
特に、特定のプロダクトに閉じない障害を実施した際に1つのプロダクトのみでアラートが発生している場合、障害対応のミスリードを誘ってしまうケースがありました。具体的には、S3ネットワーク障害時にZOZOGLASSにのみ負荷をかけた場合、ZOZOGLASSのみでアラートが発生し「障害はZOZOGLASSに限定されている」と誤解するケースです。
対策
そこで、対策として『SREで管理するプロダクト全てに対し負荷をかけながら障害を注入する』というルールを決めました。こうすることで、前述のミスリードが無くなるだけでなく、もし特定のプロダクトで異常が検知出来ていない場合に気付きやすくなりました。
また、このルールを実現するために全プロダクトで負荷試験の整備も行ったので、副次的に不備の改善にも繋がりました。
課題2. GameDayをスキップしがちになってしまう問題
問題の詳細
当初、GameDayは丸一日使って障害の実行・障害対応・振り返りまで全て行っていました。
しかし、振り返りは「障害の流れの共有→KPIの評価→改善点のブレスト→タスク化」とかなりやることが多く、継続的なシステムの改善のためには必須であるものの時間がかかります。ブレストの際にはファシリテーターが上手くまとめないと議論が発散し過ぎてしまうこともあります。
GameDayに参加する上で多くの時間が必要となると、優先度の高いタスクを抱えていて参加出来ないメンバーが出てきてしまうことも往々にしてあります。そういった理由から敷居が上がってしまい、GameDayをスキップすることが増えていました。それにより、メンバー全員に障害対応のノウハウが行き渡りにくく、改善が回りづらい状況でした。
対策
そこで『GameDayを丸一日ではなく、数時間に縮小する』ことで対策しました。具体的には、「障害対応は午前から午後にかけて1〜2時間程度、振り返りは夕方に1時間程度」といった具合に各作業を細かく分けました。
これにより、GameDayをする日でも他のタスクに集中できる時間を作れるため参加しやすくなり、スキップすることはかなり少なくなりました。
ただ、『丸一日カオスエンジニアリングにだけ集中する時間にする』という方法にも「障害対応にしっかり時間をかけることが出来る」・「それにより大規模な障害の訓練も可能になる」などメリットはあります。そのため、この対策は参考程度に留め、チームの状況に応じて適切な方法を選択していただくのがベターだと思います。
課題3. 改善タスクが作りっぱなしになってしまう問題
問題の詳細
GameDayを経て得られた改善点は、実際に改善に繋げなければ意味がありません。しかし、「カオスエンジニアリングから得られた改善タスクが放ったらかしになってしまう」・「他タスクで手が空かず次のGameDayを迎えてしまう」といったことがよくありました。
これは「チーム運営のフロー上、カオスエンジニアリングで挙がったタスクが拾いきれていなかったこと」・「カオスエンジニアリングから得られた改善タスクの優先度が明確に出来ていなかったこと」が原因でした。
対策
そこで『カオスエンジニアリングの振り返りの時点で、改善タスクをバックログに入れて優先度もつけておく』というフローにすることで対策しました。
我々のチームではスクラムを模したタスク管理方法をとっているのですが、この対策で、プランニング時に改善タスクを見落とすことが無くなり、次のGameDayまでに取り組むべき改善がより明確になりました。
弊チームのタスク管理方法については以下の記事をご覧ください。
「改善タスクの優先度を明確にすることで放ったらかしにしない」というのは今考えれば当たり前のことですが、実際にカオスエンジニアリングを運用して初めて気付いたポイントでした。同じ轍を踏まないよう、ぜひ参考にしていただければ幸いです。
終わりに
本記事では、計測プラットフォーム開発本部SREブロックにおけるカオスエンジニアリングの導入プロセスとその効果について紹介しました。
まだ半年程度の運用ですが、すでにカオスエンジニアリングの導入によって、チーム全体の障害対応の能力を向上させシステムの信頼性を高めることが出来たと言って良いほどの効果がありました。カオスエンジニアリングを始める前に目標とKPIを定め、それを元に振り返りを行なっていくことで、継続的に改善のサイクルを生み出せていることがポイントだと思います。
同様の課題を抱えているチームがいれば、ぜひ参考にしてみてください。
今後は、ステージング環境での本番環境の再現や、カオスエンジニアリングの自動化などを検討していきたいと考えています。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。