
こんにちは。ZOZO研究所の山﨑です。
ZOZO研究所では、検索/推薦技術をメインテーマとした論文読み会を進めてきました。週に1回の頻度で発表担当者が読んできた論文の内容を共有し、その内容を参加者で議論します。
本記事では、その会で発表された論文のサマリーを紹介します。
続きを読む
こんにちは。SRE部MLOpsチームの中山(@civitaspo)です。みなさんはGWをどのように過ごされたでしょうか。私は実家に子どもたちを預けて夫婦でゆっくりする時間にしました。こんなに気軽に実家を頼りにできるのも全国在宅勤務制度のおかげで、実家がある福岡に住めているからです。「この会社に入って良かったなぁ」としみじみとした気持ちでGW明けの絶望と対峙しております。
現在、MLOpsチームでは増加するML案件への対応をスケールさせるため、Kubeflowを使ったMLOps基盤構築を進めています。本記事ではその基盤構築に至る背景とKubeflowの構築方法、および現在分かっている課題を共有します。
冒頭で「増加するML案件への対応をスケールさせるため」と述べましたが、まずはその背景を私たちのチームが直面している状況を踏まえて説明します。
MLOpsチームは2019年4月に発足しました。当初はZOZO研究所がML機能開発を担当していたものの、プロダクションにその機能をリリースできていない課題がありました。その課題を解決するために、プロトタイプからプロダクションレベルへの引き上げをミッションとして発足したのがMLOpsチームです。このミッションは2年経った現在も変わっていません1。
ミッションは変わっていませんが、周囲を取り巻く環境は変わりました。なぜなら、着実にML機能のリリースを重ね、社内からの信頼度が高まってきているためです。これについて、もう少し深掘りして説明します。
私たちはチームの中長期目標として3つのフェーズを定めていました。
Phase1ではML機能を1つのプロダクションに出すことが目標でした。これは、私たちがレベルの高いインフラ、つまり技術選定が妥当である、安定している、十分に高速であるインフラを構築可能であると示すことで、MLOpsチームに対する社内からの信頼を獲得するための目標でした。同時に技術的なプレゼンスを高め、社外に対して発信することも目標に含んでいました。その最初のML機能が画像検索でした。
Phase2ではML機能を複数のプロダクションに出すことが目標でした。ここでは、Phase1で実践したレベルの高いインフラ構築、およびそれを用いたML機能のプロダクションリリースの再現性を示すことが重要でした。全ての事例は載せられないので、検索パーソナライズと推薦の代表的な2例を紹介します。
techblog.zozo.com techblog.zozo.com
そして、現在はPhase3の目標である、ML機能の量産体制の整備に取り組んでいます。Phase2までの取り組みで社内からの信頼を確実なものとしました。そのため、ML機能をリリースする案件も以前より増加しています。社外に対する技術的なプレゼンス向上も、実際に優秀な人材の採用に繋げられています。
しかし、案件の増加スピードに対して人材の増加が追いつかなくなる未来も見え始めています。そのため、ML機能のリリースをスケールさせるような基盤構築を進めています。この基盤が本記事で「MLOps基盤」と呼んでいるものです。複数のML機能をリリースしたことで、ML機能をプロダクションへリリースするために必要な共通要素・デザインパターンが分かってきました。その経験を元にMLエンジニアと協力して要件整理・検証を進めています。
構築を進めているMLOps基盤の説明の前に、私たちの考えるMLOps基盤とは何かを説明します。
私たちの考えるMLOps基盤とは以下の要件を満たすものです。
以前にAI Platform Pipelinesを取り上げた記事でも言及した内容ですが、改めて本記事でも説明します。
まず、「運用中の予測モデル(ワークフロー)を一元管理できる」必要があります。少人数で多数のML機能をリリースするためにはプロジェクト間・環境間の差分を極力排除し、構築・運用が共通化されていなければなりません。
同様の理由で「モデル作成の際に環境構築が容易である」ことも重要です。プロジェクト・環境が異なっても同じ方法で実験を開始できれば、その分だけMLエンジニアはモデル開発に集中できます。
さらに「実験段階からプロダクションへの移行が容易である」ことも必須です。実験段階のコードとプロダクションのコードが大幅に異なる場合、実験時と同じ結果を得られる保証がありません。そのため、再度検証が必要となり、大きな工数が必要となります。
「車輪の再発明をしないような仕組みである」ことはエンジニアなら当然考えることですが、MLOpsの文脈では過去の実験を再現可能であることが重要です。過去の実験をカタログのように扱い、新たなML機能をリリースする際にも過去の実験を参考・流用できる状態にしておく必要があります。
最後の「モデルサービングが可能である」ことは、モデルを構築すればそのままサービングが可能であることを求めています。モデルを構築しても別途サービング用のコードを書く必要がある場合、実装工数が必要となる他、学習時にオフライン評価で使用した推論結果とサービング時の推論結果が一致していることを保証する必要もあります。そのため、モデルサービングをフレームワークレベルでサポートし、MLエンジニアはモデル作成に専念できる状態を目指しています。

KubeflowはMLに必要な全てのワークロードをKubernetes上で実現するツールキットです。Kubeflowそのものに関しては先ほど紹介したAI Platform Pipelinesを取り上げた記事で説明しているので割愛します。Kubeflowに関する知見は既に社内で溜まりつつあり、またMLOps基盤としての要件を十分に満たす機能を持っていたため採用を決めました。
特に[Kubeflow Pipelines](https://www.kubeflow.org/docs/components/pipelines/overview/pipelines-overview/)の非常に高い実験管理機能は魅力的でした。Kubeflow Pipelinesはワークフローエンジンとして内部で[Argo Workflows](https://argoproj.github.io/projects/argo)を利用しています。Argo Workflowsではワークフローのタスク1つ1つがPodとなっているため、元データと使用するイメージに変更が無ければ多くのケースで何度でも同じ挙動を再現できます。Kubeflow Pipelinesではワークフローの実行ごとに、実行時メタデータだけでなくワークフローの定義自体も含めて保存しているため、過去の実行を容易に再現できます。 また、Kubeflowは[マルチテナンシーをサポート](https://www.kubeflow.org/docs/components/multi-tenancy/)しており、単一のKubeflowで複数のプロジェクトを管理できます。Kubeflow内部で[Profile](https://www.kubeflow.org/docs/components/multi-tenancy/design/)という単位で権限を管理できる機能を持っており、プロジェクト間で厳密な権限管理を行いつつ、Kubeflowという基盤に実験を集約することが可能です。1つの基盤を運用すれば良いので運用工数も大幅に削減できます。 そのため、MLOps基盤を構築する最初の目標としてマルチテナンシーが有効化されたKubeflowを構築し、Kubeflow Pipelinesを利用できる状態を目指しました。前置きが長くなりましたが、本記事ではこの目標を達成するためにKubeflowを構築した際に得られた知見、課題を共有します。 # なぜAI Platform Pipelinesを使わないのか
Kubeflow構築の説明をする前に、なぜAI Platform Pipelinesを使わなかったか触れておきます。MLOpsチームはGoogle Cloud Platform(以下、GCP)を使っているため、Kubeflow Pipelinesの代わりにGCPのマネージドサービスであるAI Platform Pipelinesを利用することも検討しました。しかし、複数の観点から採用を見送りました。
まず、AI Platform Pipelinesは1つのプロジェクトを作成する毎に1つのGoogle Kubernetes Engine(以下、GKE)が構築されてしまう点です。AI Platform Pipelinesは1つのGKEクラスタに複数構築することができないので、プロジェクトを増やす毎にGKEを構築する必要があります。GKEが増えれば増えるほど、GKEのバージョンアップ、監査ログ取得ツールFalcoなどの共通コンポーネントのインストール、などのクラスタ管理コストが増えてしまうため、運用がスケールしないと判断しました。
また、AI Platform Pipelinesの内部で保持するワークフローのデータなどをGKEに依存せず永続化するためにはCloud SQLを利用することになります。しかし、これに関してもプロジェクト増加毎に1インスタンス必要となりコスト面で許容できませんでした。Cloud SQLを使用しない場合は、GKE上にStatefulSetとしてMySQLがデプロイされ、Persistent Volumeに依存する構成となります。つまり、Zoneに依存する構成となり耐障害性が低くなってしまいます。
そして、一番課題と感じた点は利用者側でGKEにApplyされたManifestを直接書き換えても強制的に巻き戻ってしまう点です。問題発生時にManifestを修正することで問題解決できず、サポートケースを上げて解決することになるため、問題解決までのリードタイムが長くなってしまいます。
これらの理由によりMLOps基盤としてAI Platform Pipelinesの採用を見送りました2。
さて、Kubeflowを構築する話に移っていきます。なお、今回構築したKubeflowはv1.2.0で、GKE 1.18.16-gke.502を使用しています。
最初にKubeflowの公式ドキュメントに沿ってKubeflow構築を進めました。このドキュメントに従うと、以下のように構成管理用GKEクラスタを使用して構築を進めることになります。

構成管理用GKEクラスタではConfig Connectorを有効化しています。Config ConnectorはKubernetesを介してGCPのリソース操作を可能にするGKEアドオンです。このアドオンをインストールするとKubernetesにGCPのリソースを定義するためのCustom Resource Definitionsが使用可能になります。例えば、以下のようなManifestをApplyするとsample-gcp-projectというGCP Projectにkubeflow-adminという名称のService Accountが定義されます。
apiVersion: iam.cnrm.cloud.google.com/v1beta1 kind: IAMServiceAccount metadata: name: kubeflow-admin namespace: sample-gcp-project labels: kf-name: kubeflow spec: displayName: kubeflow admin service account
Kubeflowの公式ドキュメントでは、以下の手順でKubeflowを構築します。
これらの手順がMakefileに記述されており、make applyで構築が完了するようになっています。
この手法は構成管理用GKEクラスタを構築する必要があるという点もさることながら、以下のような問題がありました。
これらの問題を解決しつつKubeflowを構築できるよう、次に示すような方法で構築しました。
私たちの環境に合わせた運用が可能になるよう、以下の方針でKubeflow構築を進めることにしました。
まず、Kubeflowの公式ドキュメントに沿ってManifest群を生成します。
$ kpt pkg get https://github.com/kubeflow/gcp-blueprints.git/kubeflow@v1.2.0 kubeflow $ cd kubeflow $ make get-pkg
上記コマンドでManifest群生成に必要なファイルを準備し、可能な限り私たちのインフラ要件に合うように一部のファイルを修正します。
$ vim Makefile 55c55 < kpt cfg set ./instance gke.private false --- > kpt cfg set ./instance gke.private true # VPCネイティブクラスタで構築するため 57c57 < kpt cfg set ./instance mgmt-ctxt <YOUR_MANAGEMENT_CTXT> --- > kpt cfg set ./instance mgmt-ctxt null # 構成管理用GKEクラスタは利用しないため 59,62c59,62 < kpt cfg set ./upstream/manifests/gcp name <YOUR_KF_NAME> < kpt cfg set ./upstream/manifests/gcp gcloud.core.project <PROJECT_TO_DEPLOY_IN> < kpt cfg set ./upstream/manifests/gcp gcloud.compute.zone <ZONE> < kpt cfg set ./upstream/manifests/gcp location <REGION OR ZONE> --- > kpt cfg set ./upstream/manifests/gcp name kubeflow > kpt cfg set ./upstream/manifests/gcp gcloud.core.project sample-gcp-project > kpt cfg set ./upstream/manifests/gcp gcloud.compute.zone asia-northeast1 > kpt cfg set ./upstream/manifests/gcp location asia-northeast1 65,66c65,66 < kpt cfg set ./upstream/manifests/stacks/gcp name <YOUR_KF_NAME> < kpt cfg set ./upstream/manifests/stacks/gcp gcloud.core.project <PROJECT_TO_DEPLOY_IN> --- > kpt cfg set ./upstream/manifests/stacks/gcp name kubeflow > kpt cfg set ./upstream/manifests/stacks/gcp gcloud.core.project sample-gcp-project 68,71c68,71 < kpt cfg set ./instance name <YOUR_KF_NAME> < kpt cfg set ./instance location <YOUR_REGION or ZONE> < kpt cfg set ./instance gcloud.core.project <YOUR PROJECT> < kpt cfg set ./instance email <YOUR_EMAIL_ADDRESS> --- > kpt cfg set ./instance name kubeflow > kpt cfg set ./instance location asia-northeast1 > kpt cfg set ./instance gcloud.core.project sample-gcp-project > kpt cfg set ./instance email takahiro.nakayama@example.com $ vim instance/gcp_config/kustomization.yaml 13a14,16 > - ../../upstream/manifests/gcp/v2/privateGKE/ > patchesStrategicMerge: > - ../../upstream/manifests/gcp/v2/privateGKE/cluster-private-patch.yaml
修正が完了したらManifest群を生成します。
$ make set-values $ make clean-build $ make hydrate
これにより .build ディレクトリ以下に大量のManifest群が生成されます。
$ find .build -type f | head -n10 .build/cert-manager-crds/apiextensions.k8s.io_v1beta1_customresourcedefinition_certificates.cert-manager.io.yaml .build/cert-manager-crds/apiextensions.k8s.io_v1beta1_customresourcedefinition_challenges.acme.cert-manager.io.yaml .build/cert-manager-crds/apiextensions.k8s.io_v1beta1_customresourcedefinition_orders.acme.cert-manager.io.yaml .build/cert-manager-crds/apiextensions.k8s.io_v1beta1_customresourcedefinition_issuers.cert-manager.io.yaml .build/cert-manager-crds/apiextensions.k8s.io_v1beta1_customresourcedefinition_certificaterequests.cert-manager.io.yaml .build/cert-manager-crds/apiextensions.k8s.io_v1beta1_customresourcedefinition_clusterissuers.cert-manager.io.yaml .build/iap-ingress/networking.gke.io_v1beta1_managedcertificate_gke-certificate.yaml .build/iap-ingress/v1_configmap_ingress-bootstrap-config.yaml .build/iap-ingress/rbac.istio.io_v1alpha1_clusterrbacconfig_default.yaml .build/iap-ingress/cloud.google.com_v1beta1_backendconfig_iap-backendconfig.yaml $ find .build -type f | wc -l 505
これら全てのファイルを気合で読み進め、Terraform化、Kustomize化を進めます。
ここまでの手順でConfig Connector向けのManifestも出力されるので、Terraform管理可能な定義に変換していきます。Config Connector向けのManifestは.build/gcp_config以下のファイル群です。
これらファイル群で定義されているGCPリソースは以下の通りです。
GKEを構築済みである場合、Virtual Private CloudやCloud NATなどは既に存在しているはずなので、リソース作成の要不要は定義を読んで判断する必要があります。私たちの場合はFirewall rulesとCloud IAM以外は不要でした。
生成したManifest群をKustomizeで参照するために、以下のようなディレクトリ構成をとることにしました。
. ├── generated │ └── kubeflow │ └── .build │ ├── application │ ├── cert-manager │ ├── cert-manager-crds │ ├── cert-manager-kube-system-resources │ ├── cloud-endpoints │ ├── gcp_config │ ├── iap-ingress │ ├── istio │ ├── knative │ ├── kubeflow-apps │ ├── kubeflow-issuer │ ├── metacontroller │ └── namespaces ├── base # generatedを参照する │ ├── application │ ├── cert-manager │ ├── cert-manager-leaderelection │ ├── cluster-resources │ ├── falco │ ├── iap-ingress │ ├── istio │ ├── knative │ ├── kubeflow-apps │ │ ├── argo │ │ ├── centraldashboard │ │ ├── jupyter-web-app │ │ ├── katib │ │ ├── kfserving │ │ ├── metadata │ │ ├── minio │ │ ├── ml-pipeline │ │ ├── notebook-controller │ │ ├── poddefaults │ │ ├── profiles │ │ ├── pytorch │ │ └── tfjob │ ├── kubeflow-issuer │ ├── kubeflow-istio │ ├── metacontroller │ └── nvidia-driver-installer ├── dev # baseを参照する ├── stg # baseを参照する └── prd # baseを参照する
generated/kubeflow/.build以下のディレクトリに先ほど生成したManifest群が格納されています。生成したManifestへは直接変更を加えずbase以下のディレクトリに格納するkustomization.yamlから参照、Patchを加えます。
例えば、base/kubeflow-apps/argo/kustomization.yamlで記述されているArgo Workflowsの設定は以下のようになります。
apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization namespace: kubeflow resources: - ../../../generated/kubeflow/.build/kubeflow-apps/apiextensions.k8s.io_v1beta1_customresourcedefinition_workflows.argoproj.io.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/app.k8s.io_v1beta1_application_argo.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/apps_v1_deployment_argo-ui.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/apps_v1_deployment_workflow-controller.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/networking.istio.io_v1alpha3_virtualservice_argo-ui.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/rbac.authorization.k8s.io_v1beta1_clusterrole_argo-ui.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/rbac.authorization.k8s.io_v1beta1_clusterrole_argo.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/rbac.authorization.k8s.io_v1beta1_clusterrolebinding_argo-ui.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/rbac.authorization.k8s.io_v1beta1_clusterrolebinding_argo.yaml # NOTE: We use the configMapGenerator instead of these files. # - ../../../generated/kubeflow/.build/kubeflow-apps/v1_configmap_workflow-controller-configmap.yaml # - ../../../generated/kubeflow/.build/kubeflow-apps/v1_configmap_workflow-controller-parameters.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/v1_service_argo-ui.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/v1_serviceaccount_argo-ui.yaml - ../../../generated/kubeflow/.build/kubeflow-apps/v1_serviceaccount_argo.yaml configMapGenerator: # ref. https://github.com/argoproj/argo/blob/v2.3.0/docs/workflow-controller-configmap.yaml - name: argo-workflow-controller-config files: - config=config/workflow-controller.yaml configurations: - varReference.yaml vars: - name: ARGO_WORKFLOW_CONTROLLER_CONFIGMAP_NAME objref: kind: ConfigMap name: argo-workflow-controller-config apiVersion: v1 fieldref: fieldpath: metadata.name patchesStrategicMerge: - apps_v1_deployment_workflow-controller.yaml - v1_serviceaccount_argo.yaml
このような定義をKubeflowに含まれる全てのコンポーネントに行っていきます。そして、各環境用ディレクトリからbaseを参照する構成です。
先ほど課題に挙げていたPersistent Volumeへの依存もbaseでPatchを当てることで解消しました。
Kubeflowが公式に用意しているkubeflow/manifestsというリポジトリには様々なパターンへ対応するためのManifestが格納されています。そこに、MySQL for Cloud SQLやMinIO GCS Gatewayを利用するパターンも用意されていました4。
ここまでの内容でKubeflowの構築が完了しました。構築に関する知見共有の最後にNode Poolの構成について触れておきます。
MLOps基盤ではKubeflowのController系Podを載せるNode Poolと、ワークフローのPodを載せるNode Poolを別々に管理する方針にしています。
KubeflowのController系Podを載せるNode Poolは、用途毎に占有のNode Poolを作成しました。用途以外のPodが配置されないようにtaintを設定し、占有対象のPodが配置されるようにtolerationsとnodeAffinityを設定します。
以下のようなPatchを定義し、kustomization.yamlでPatchを当てます。
# dedicated-node-pool-patch.yaml - op: add path: /spec/template/spec/affinity value: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: cloud.google.com/gke-nodepool operator: In values: - kubeflow - op: add path: /spec/template/spec/tolerations value: - key: dedicated operator: Equal value: kubeflow effect: NoSchedule
# kustomization.yaml apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization namespace: kubeflow resources: - <...snip...> patches: - target: kind: StatefulSet path: dedicated-node-patch.yaml - target: kind: Deployment path: dedicated-node-patch.yaml
一方で、ワークフローのPodを載せるNode Poolは占有のNode Poolを作っていません。Node Auto Provisioningでワークロード毎にNode Poolを自動でプロビジョニングするようにしています。
なお、Node Auto ProvisioningはGKEのアドオンの1つです。このアドオンを有効化するとScheduleされたPodのResource Request、nodeAffinityやlabelSelector、taintとtolerationsから最適な設定のNode Poolが自動で作成されます。MLOps基盤として利用者のワークフローがどれだけのリソースを必要とするのか事前に把握するのは困難であるため、Node Auto ProvisioningでオンデマンドにNode Poolが作成される構成としました。
Node Auto Provisioningの良いところは、GPUのプロビジョニングもサポートしているところです。利用者が必要なタイミングで何の相談も無くGPUが利用できる状態を作ることができます。
最終的には以下のようなNode Poolができています。nap-から始まるNode PoolがNode Auto Provisioningによって生成されたNode Poolです。

ここからは運用課題をいくつか紹介します。
Kubeflowで利用されるIstioはv1.4です。Istioの最新バージョンはv1.9ですので非常に古いです。
また、v1.5でこれまでマイクロサービスとして存在していたコンポーネント群がistiodに統合される大きなアーキテクチャ変更がありました。そのため、現状のv1.4からバージョンが上がらないことに大きな危惧を感じています5。このGKEクラスタ上でサービングを始める前に解消されるべき課題です。
実は、Argo Workflowsも非常に古いバージョンである2.3.0(最新は3.0.0)を使用しています。Argo Workflowsに関しては、Kubeflow Pipelinesが依存しているのみなので、Istioほど大きな危惧は抱いていません。しかし、Kubeflowの依存コンポーネントがバージョンアップできない問題は今後も頭を悩ませ続けそうです。
kubernetes-sigs/applicationはアプリケーションを構成する全てのコンポーネントを束ねて扱えるCustom Resource Definitionsを提供するプロジェクトです。Kubernetesで定義可能なDeploymentなどの単位ではアプリケーション全体を管理できないという課題から作られたようです。kubernetes-sigs/applicationはKubeflowの依存コンポーネントですが、構築直後からデフォルトで非常に大量のログを出力するようになっています。

私が構築したときは秒間1000件以上のログを出力していました。GKE上でこの量のログが出力されるとCloud Loggingのコストが高額になってしまいます。この問題はKubeflow側でも認識されていて、Issue(Stackdriver Logs are very expensive for kubeflow - kubeflow/gcp-blueprints#184)になっています。その、kubeflow/gcp-blueprints#184ではkubernetes-sigs/applicationのログを全て/dev/nullに捨てるという豪快なアプローチで解決が図られています。しかし、私たちはkubernetes-sigs/applicationを削除することにしました。なぜなら、kubernetes-sigs/applicationが存在しなければ動かないコンポーネントがKubeflowに存在しないからです。
Kubeflow Pipelinesは自身のDBに持つ状態を正として扱います。
一方、Kubernetes上の状態がKubeflow Pipelinesの持つ情報と異なっていても、Kubernetes上の状態を修正しません。また、Kubeflow PipelinesのUIからはDBに格納されている情報が表示されるのみで、その不整合状態を確認できません。そのため、Kubeflow Pipelinesの持つ情報とKubernetes上の状態との差異が発生すると、実際の状態を誤認してしまいます。
そして、この不整合状態は比較的高い確率で起こることが確認できています。原因が不明なものもあるため、確実に原因が分かっている2つのケースを紹介します。
1つ目はKubeflow Pipelinesによって作成されたObjectを削除するケースです。このケースは手動運用が禁じられている本番環境では起きえないので深く考える必要はありません。
もう1つはOwnerReferenceによって親Objectと共にObjectが削除されてしまうケースです。分かりにくいと思うので図を用いて説明します。

Kubeflow PipelinesではSchedule実行のためにRecurring Runという機能があります。Recurring Runは時間になったらRunという機能でワークフローを実行します。Recurring RunとRunはKubernetes上でOwnerReferenceによって親子関係ができています。そのため、Runを実行中にRecurring Runを削除した場合、Runも一緒に削除されてしまいます。
しかしながら、Kubeflow Pipelines上で明示的に削除が行われたわけではないため、Kubeflow PipelinesのUIではRunは実行中ステータスのままになってしまうのです。
非常に危険な問題なので、Kubeflow Pipelinesの保持する状態とKubernetes上の状態を比較、監視する仕組みを導入しようと思っています。
本記事では現在構築中のMLOps基盤を紹介しました。記事内で取り上げた課題は解決に向けて絶賛取り組んでいるところです。特にIstioの最新化は急ピッチで進めています。また、インフラ部分だけではなく、MLOps基盤としてMLエンジニアをサポートする機能強化を実施していきたいと思っています。折を見て記事を書きますので期待して待っていて頂けると嬉しい限りです。
本記事に載せた内容以外にも様々な観点で機能を検証追加しています。絶賛構築中なので、関心を持たれた方は1度お話しをさせてもらえるとありがたいです。是非助けてください!
ZOZOテクノロジーズでは一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
https://tech.zozo.com/recruit/tech.zozo.com hrmos.co

こんにちは、推薦基盤部の与謝です。ECサイトにおけるユーザの購買率向上を目指し、レコメンデーションエンジンを研究・開発しています。最近ではディープラーニングが様々な分野で飛躍的な成果を収め始めています。そのため、レコメンデーション分野でも研究が進み、精度向上に貢献し始めています。本記事では、ディープニューラルネットワーク時代のレコメンド技術について紹介します。
レコメンドエンジンとは、ECサイトやWebサイト上で、ユーザにおすすめの商品やコンテンツを表示するためのシステムです。
「新着順」や「人気順」などの汎化されたレコメンドもありますが、個々のユーザにパーソナライズすることによって、閲覧や購買を促進します。ユーザの閲覧履歴や購入履歴などから関連性のある商品やコンテンツ情報を表示させることで、サイト運営側は売り上げや閲覧数を増加させ、ユーザはより自分の気にいる商品やコンテンツを発見しやすくなります。
次章以降、このパーソナライズレコメンドについて掘り下げていきます。
まずは深層学習より前のレコメンデーションをいくつか見ていきましょう。
Aという商品を閲覧・購入した人はBという商品も閲覧・購入した人が多いため、Aという商品を閲覧・購入した人にはBという商品を薦める。といったように、協調フィルタリングはWebのアクセス履歴やユーザの行動履歴に基づいて商品をレコメンドする手法です。この手法は、商品情報などのコンテンツ情報の必要がない、という点がポイントです。協調フィルタリングでは、ユーザ同士またはアイテム同士のコサイン類似度を計算し、レコメンドを行います。
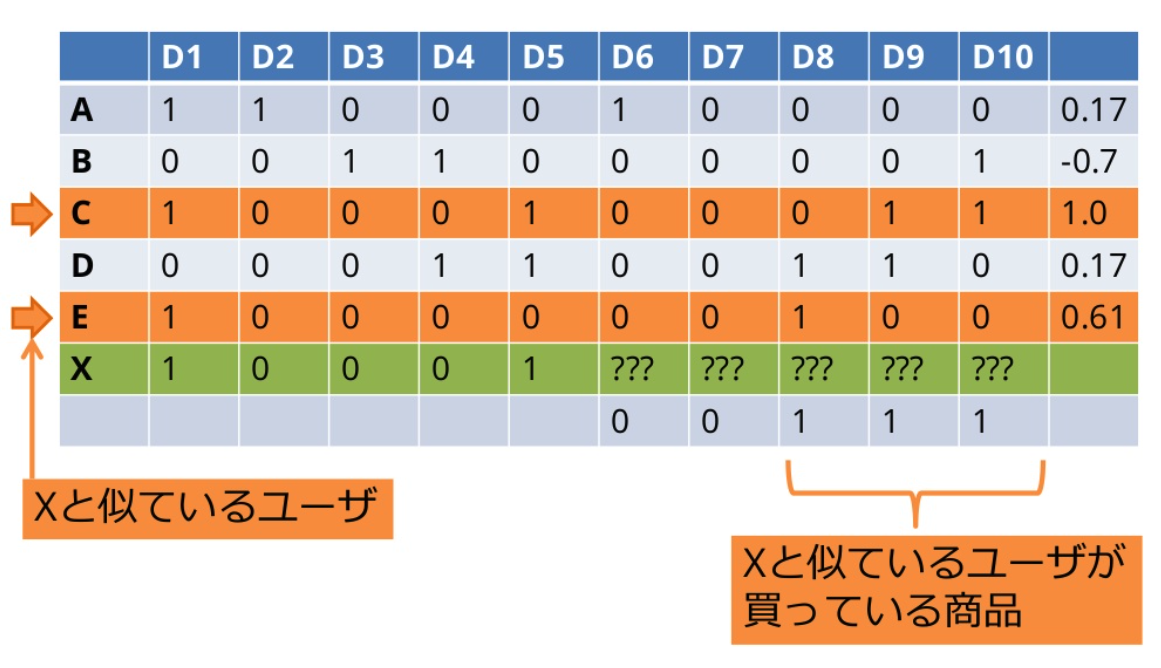 (引用:協調フィルタリング入門)
(引用:協調フィルタリング入門)
Matrix Factorizationは、協調フィルタリングに対する次元削減によって、より良いレコメンドを行います。協調フィルタリングの場合、ユーザやアイテムの数が増えるとそれだけ次元が増えてしまい、計算が困難になります。これが次元の呪いと呼ばれる問題です。そのため、このような高次元のデータを扱うために、高次元データの特徴をできるだけ保持したままデータを低次元データに変換します。これが次元削減です。2008年に行われた推薦システムのコンテスト、Netflix Prizeで最も成果を上げたモデルの1つです。
 (引用:Simple Matrix Factorization example on the Movielens dataset using Pyspark)
(引用:Simple Matrix Factorization example on the Movielens dataset using Pyspark)
SVDは特異値分解によって次元削減する手法です。特異値分解は行列の低ランク近似や擬似逆行列の計算などに使われ、特異値を成分とした対角行列を生成します。
 (引用:Recommender Systems with Python — Part III: Collaborative Filtering (Singular Value Decomposition))
(引用:Recommender Systems with Python — Part III: Collaborative Filtering (Singular Value Decomposition))
Factorization Machine(FM)は、Matrix Factorizationを使いやすく進化させ、より精度の高いレコメンドエンジンを作成できます。Matrix Factorizationでは、ユーザとアイテムの情報しか扱えなかったため、性別、年齢などをレコメンドエンジンの作成に用いる事ができませんでした。Factorization Machineは、それ以外の情報も扱えるため、性別、年齢を考慮できます。さらに特徴量の間で影響を与えあう相互作用(Interaction)を考慮できるので、相関関係がある特徴量も扱えます。
次に深層学習を使ったレコメンデーションをいくつか見ていきましょう。
RecSys 2019と2020の2年連続で、推薦システムの公平なベンチマークに向けた調査と提案に関する論文が発表されました。RecSysとは推薦システムに関するACM主催の国際学会で、この分野ではトップカンファレンスです。
上記の論文では、近年流行しているニューラルネットワークベースの推薦手法に対し、有効性やロバスト性(あらゆるデータセットに対して安定したパフォーマンスを出しているか)を検証しました。論文では、多くのDNNベースの推薦手法では旧来の協調フィルタリングやBPRFM手法に勝つことができないと主張しており、DNNベースの推薦手法に疑問符が付きました。
レコメンドの研究コミュニティでは、レコメンデーションアルゴリズムのオープンソース実装の標準化に対する関心が高まりつつあります。包括的かつ効率的なレコメンダーシステムライブラリとして、Recboleプロジェクトが発足されました。PyTorchを元に開発され、研究者が推奨モデルを再現・開発する支援をします。本ライブラリの特徴は公式ページには以下のように書かれています。
一般的に使用される推薦データセットの1つであるMovieLens 100K Datasetに対し、Recboleに用意されている推薦アルゴリズムを実行し、実行時間やパフォーマンスを計測しました。なお、計測不能なものは除いており、数値は参考値としてご覧ください。
| Model | Step | 秒数 | recall@10 | mrr@10 | ndcg@10 | hit@10 | precision@10 |
|---|---|---|---|---|---|---|---|
| BPR | 53 | 28.66 | 0.2358 | 0.4711 | 0.2801 | 0.7646 | 0.1882 |
| ConvNCF | 18 | 68.74 | 0.1035 | 0.2341 | 0.1235 | 0.5111 | 0.0941 |
| DGCF | 83 | 417.9 | 0.2421 | 0.4787 | 0.2862 | 0.7773 | 0.1916 |
| DMF | 45 | 52.47 | 0.226 | 0.4149 | 0.2521 | 0.7678 | 0.1783 |
| FISM | 33 | 72.4 | 0.2237 | 0.4573 | 0.2689 | 0.7519 | 0.1777 |
| GCMC | 15 | 31.97 | 0.1835 | 0.3841 | 0.2136 | 0.6872 | 0.1419 |
| ItemKNN | 0 | 2.25 | 0.247 | 0.4623 | 0.2834 | 0.7847 | 0.1931 |
| LightGCN | 136 | 92.4 | 0.2467 | 0.4838 | 0.2895 | 0.7826 | 0.1949 |
| LINE | 85 | 56.52 | 0.2025 | 0.3875 | 0.2284 | 0.7243 | 0.1601 |
| NAIS | 18 | 126.54 | 0.2389 | 0.4586 | 0.2764 | 0.7741 | 0.1894 |
| NeuMF | 35 | 40.08 | 0.238 | 0.4567 | 0.2768 | 0.7678 | 0.191 |
| NGCF | 74 | 64.83 | 0.2476 | 0.4978 | 0.2983 | 0.7869 | 0.1994 |
| Pop | 0 | 1.624 | 0.0289 | 0.1244 | 0.0558 | 0.2694 | 0.0492 |
| SpectralCF | 26 | 22.44 | 0.1133 | 0.2686 | 0.1363 | 0.5578 | 0.1014 |
| CFKG | 13 | 12.88 | 0.1109 | 0.2664 | 0.1368 | 0.5408 | 0.1027 |
| CKE | 88 | 84.38 | 0.243 | 0.4813 | 0.2863 | 0.7752 | 0.1954 |
| KGCN | 39 | 51.26 | 0.2159 | 0.4401 | 0.2566 | 0.7476 | 0.1749 |
| KGNNLS | 39 | 72.5 | 0.2159 | 0.4401 | 0.2566 | 0.7476 | 0.1749 |
| KTUP | 60 | 82.16 | 0.1716 | 0.3374 | 0.2006 | 0.6808 | 0.1503 |
| MKR | 64 | 145.2 | 0.194 | 0.4016 | 0.2315 | 0.7041 | 0.1601 |
| RippleNet | 27 | 258.06 | 0.198 | 0.3873 | 0.2281 | 0.7094 | 0.1642 |
| BERT4Rec | 29 | 584.83 | 0.1113 | 0.0335 | 0.0513 | 0.1113 | 0.0111 |
| FDSA | 43 | 1130.45 | 0.1273 | 0.0403 | 0.0601 | 0.1273 | 0.0127 |
| FOSSIL | 41 | 42.06 | 0.1007 | 0.032 | 0.0476 | 0.1007 | 0.0101 |
| FPMC | 23 | 13.65 | 0.0838 | 0.0244 | 0.0382 | 0.0838 | 0.0084 |
| GCSAN | 17 | 3490.54 | 0.1241 | 0.0398 | 0.0591 | 0.1241 | 0.0124 |
| GRU4Rec | 33 | 103.96 | 0.1304 | 0.0483 | 0.0671 | 0.1304 | 0.013 |
| GRU4RecF | 24 | 160.15 | 0.1463 | 0.0473 | 0.07 | 0.1463 | 0.0146 |
| HGN | 11 | 11.76 | 0.0339 | 0.0136 | 0.0182 | 0.0339 | 0.0034 |
| HRM | 27 | 69.26 | 0.0997 | 0.0305 | 0.0465 | 0.0997 | 0.01 |
| NARM | 40 | 158.06 | 0.1347 | 0.0431 | 0.0642 | 0.1347 | 0.0135 |
| NPE | 42 | 28.43 | 0.0626 | 0.0136 | 0.0247 | 0.0626 | 0.0063 |
| RepeatNet | 30 | 1792.03 | 0.193 | 0.0734 | 0.101 | 0.193 | 0.0193 |
| SASRec | 24 | 317.61 | 0.1251 | 0.0389 | 0.0588 | 0.1251 | 0.0125 |
| SASRecF | 35 | 496.47 | 0.1283 | 0.0406 | 0.0606 | 0.1283 | 0.0128 |
| SHAN | 23 | 80.48 | 0.105 | 0.0356 | 0.0516 | 0.105 | 0.0105 |
| STAMP | 34 | 47.94 | 0.105 | 0.0452 | 0.0657 | 0.1347 | 0.0135 |
| TransRec | 17 | 14.73 | 0.07 | 0.0178 | 0.0297 | 0.07 | 0.007 |
これらのレコメンドは以下の4種類に大別できます。
特に、NGCFやLightGCNといったGraph Recommendationは、ItemKNNやBPRなどの旧来手法を超える精度を出しています。
また、ZOZOTOWNではレコメンドを活用するシーンが多く存在します。類似アイテムの推薦にはKnowledge Aware Recommendation。ユーザの短期のクリック予測にはSequential Recommendation。クーポン配信にはGraph Recommendation。各機能との相性を考慮し、最適なレコメンドアルゴリズムを選択する必要があります。
次の章では、これら4種類のレコメンダーシステムの特徴を紹介します。
GMFはユーザとアイテムのembeddingをelement-wiseにかけたものから、マトリックスの中身を推定する線形モデルです。通常のMatrix Factorizationと同じモデルです。
NCFはユーザとアイテムのembeddingを結合したものから多層パーセプトロンを用いてマトリックスの中身を推定する非線形モデルです。Matrix Factorizationの内積表現の部分をニューラルネットワークベースの関数に置き換えて学習します。
 (引用:論文リンク)
(引用:論文リンク)
NeuMFではGMFとNCFの出力を結合してマトリックスの中身の推定します。線形モデルと非線形モデルの組み合わせです。
 (引用:論文リンク)
(引用:論文リンク)
グラフ構造は、ノード(頂点)とエッジ(辺)で構成されるデータ型を表します。GNN(Graph Neural Networks)は、グラフ構造を加味しながら各ノードをembeddingします。そして、レコメンド領域でのグラフ構造では、ユーザノードとアイテムノードからなる2部グラフを考えます。2部グラフとは、頂点集合を2つに分割して各部分の頂点は互いに隣接しないようにできるグラフのことです。
グラフベースレコメンドでは、GCN(Graph Convolutional Network)によってノードのembeddingを行います。CNNでは画像データは上下左右斜めの8方向から情報の畳み込み処理を行っているのに対し、GCNでは対象ノードの周辺あるいはグラフ全体の情報から畳み込みを行います。
 (引用:繋がりを可視化するグラフ理論入門、グラフ理論 (2)、介入効果推定の方法)
(引用:繋がりを可視化するグラフ理論入門、グラフ理論 (2)、介入効果推定の方法)
NGCFでは、ユーザとアイテムのembeddingにグラフ畳み込み処理を行うことで、明示的にユーザとアイテムの交互作用を考慮します。
 (引用:論文リンク)
(引用:論文リンク)
LightGCNでは、先のNGCF加えてグラフ上の特徴を平準化することによって計算量を抑えます。これによりGCNの最も重要なコンポーネントである近隣集約のみを考慮しています。
 (引用:論文リンク)
(引用:論文リンク)
DGCFでは、ユーザとアイテムの間にインテント層を用意します。これによりユーザがアイテムを購入した潜在的な意図を表現し、購買理由を説明可能にします。

 (引用:論文リンク)
(引用:論文リンク)
ナレッジグラフは、柔軟かつ双方向的に事実「エンティティ」を格納する脳のような構造化データベースで、エンティティの相互にリンクされた意味付けを自由に表現します。レコメンド領域のナレッジグラフでは、エンティティとしてユーザとアイテムの他に、アイテムのジャンルやユーザの年齢層/性別などの各特徴量も表現可能です。
さらにナレッジグラフは意味ネットワークとして構築されるため、エンティティ間のセマンティック類似性(意味の類似性)を計算し、各アイテムの類似商品を推薦します。また、ナレッジグラフでは推薦理由を可視化し、データのスパース性問題を解決します。
 (引用:A Survey on Knowledge Graph-Based Recommender Systems)
(引用:A Survey on Knowledge Graph-Based Recommender Systems)
RippleNetは、ナレッジグラフのリンクに沿ってユーザの潜在的な関心を自動的かつ反復的に拡張することにより、知識エンティティのデータセットに対するユーザの好みをembeddingします。ユーザによってアクティブ化された複数の波紋に従って、過去にクリックされたアイテムは候補アイテムに関するユーザの嗜好分布を形成し、最終的なクリック確率を予測します。
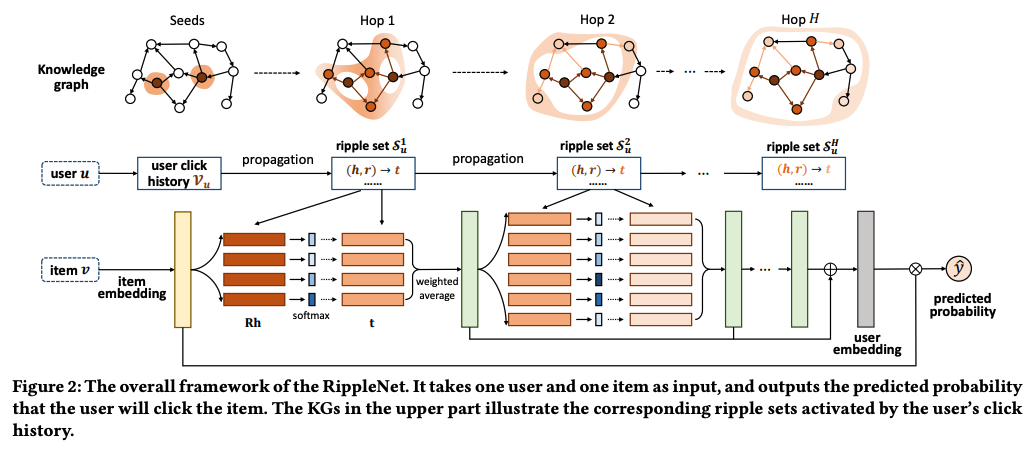 (引用:論文リンク)
(引用:論文リンク)
CKEでは、以下の3つを用いてアイテムのembeddingを取得します。
 (引用:論文リンク)
(引用:論文リンク)
通常のGeneral Recommendationでは、ユーザがアイテムを消費する順序は考慮せず、長期予測としてユーザが最終的に消費するアイテムを予測します。シーケンシャルレコメンドの場合は、ユーザがアイテムを消費した順序に基づいて推薦を行い、ユーザが次に買いそうなアイテムを予測します。
シーケンシャルレコメンドの領域は、自然言語処理の分野と強い相関があります。自然言語処理では、単語の並ぶ方向からID化した単語をembeddingします。シーケンシャルレコメンドでも、ユーザの商品への消費履歴からアイテム情報をembeddingしていきます。ほとんどのシーケンシャルモデルは、自然言語モデルを元に作られています。
RNNRecommenderは、ユーザの1Session分の短期の行動(クリック履歴)から時系列データを取得し、RNNによってユーザのembeddingを行う手法です。RNNの層にGRUやLSTMを使用したり、双方向モデルを使用したりと、様々なアーキテクチャが存在します。
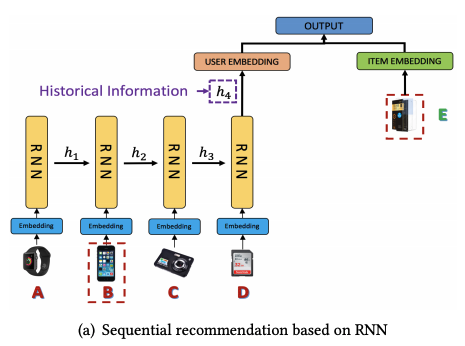 (引用:Sequential Recommendation with User Memory Networks)
(引用:Sequential Recommendation with User Memory Networks)
Item2Vecは、自然言語処理で文脈から単語のembedding処理を行うWord2Vecを応用し、ユーザの行動履歴からアイテムのembeddingを行います。
 (引用:Item2Vec-based Approach to a Recommender System)
(引用:Item2Vec-based Approach to a Recommender System)
BERT4Recの「BERT」はBidirectional Encoder Representations from Transformersの略です。2018年10月にGoogleのJacob Devlinらの論文で発表された自然言語処理モデルです。「AIが人間を超えた」と言わしめるほどのブレークスルーをもたらし、多様なタスクにおいて当時の最高スコアを叩き出しています。このBERTモデルをレコメンドに応用したものがBERT4Recです。
 (引用:論文リンク)
(引用:論文リンク)
なお、自然言語処理の領域では、BERTの他にもALBERTやXLNetやGPT-xなど様々なモデルが登場しているため、それらを生かしたレコメンドモデルも試していきたいです。
ここまで、ディープニューラルネットワーク時代のレコメンド技術の動向について4種類にわたり紹介してきました。一口にディープラーニングといっても、様々な分野の技術がレコメンドに生かされていることをご理解いただけたでしょう。ここで紹介した内容以外にも、強化学習を用いたレコメンド、深層学習を使わないレコメンドなどもあります。各分野のレコメンド技術に加え、特徴量エンジニアリング、ハイパーパラメータチューニングなど、さらなる精度向上を目指していきたいです。
コラムとして本章では、推薦における計算時間を短縮するためのテクニックを紹介します。ZOZOTOWNでは、毎日100万以上のアクティブユーザと、100万のアイテム数を取り扱っています。ファッションアイテムは商品のライフサイクルが短いため、推薦結果を出すまでの計算時間は重要です。
数百万のアクティブユーザと、数百万のアイテムのマトリックスデータを扱おうとすると、数TBのメモリが必要になります。そのようなサーバーを用意するのも大変ですが、用意できたとしてもインフラコストが格段に高いため、レコメンドによる売り上げ増加を食い潰してしまいます。
そのため、データ量を削減する工夫として、スパースマトリックス(疎行列)をインプットとして用います。レコメンドのインプット成分のほとんどがゼロであるため、疎行列の非零要素だけを工夫してうまく格納することにより大次元の問題を扱うことが容易になり、比較的少ない手間でベクトルと行列の積を計算できます。
ZOZOTOWNの場合、スパースマトリックスを用いることでインプットのデータ量を約10万分の1に削減できます。
Pythonはインタプリタ言語であるため、処理速度は遅い部類に属します。そこで、コンパイラ言語であるC/C++に変換することにより高速化しようというのがCythonです。Factorization Machineモデルでは、Cythonベースのライブラリを用いることで、高速化を実現しています。ZOZOTOWNのリアルデータでも10分強でモデルの作成を終えることができます。
embeddingの計算は、TensorFlowやPyTorchを用いてテンソルの処理をGPUで行います。NumPyに比べてテンソル計算は100倍以上、GPUを用いるとさらに3倍早くなる印象です。
ZOZOテクノロジーズでは一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!

こんにちは、ZOZO研究所の平川(@china_syuke)です。
ZOZO研究所では今年度から、ファッションコーディネートアプリ「WEAR(ウェア)」のデータを用いた調査リリースを執筆しています。一般的によく見るアンケート調査と違い、機械学習を用いてこれまで数値化されていない情報を調査しました。
この記事では、リリースした中でも面白いアプローチで調査した、第二弾「洋服の「丈」に関する流行の変化」に焦点を当てながら調査リリースの進め方・工夫したこと・課題に感じたことを紹介します。
https://press-tech.zozo.com/entry/20200820_WEAR_Research2press-tech.zozo.com
最近では様々な企業が自社でのアンケートや蓄積されたデータを使用した調査リリースを出しています。サービスなどで蓄積されたデータを解析していくことは、消費者の動向や社会情勢を分析していく上でもとても意義のある調査です。また、自社サービスの宣伝や保有しているデータのアピールにも繋がります。
今回の記事では以下に注目して順を追って執筆の工程を説明していきます。
通常の調査リリースでは、アンケートを調査対象として仮説を立てていくことが多いです。今回の調査リリースではアンケートは集計せずに、自社サービスであるWEARに投稿されたコーディネート画像を利用して仮説を立てていきます。
もちろん立てた仮説が上手く立証できることは少なく、1と2の手順を繰り返し行いブラッシュアップしていきます。
今回の例で言うと、「最近はトップス短め/ボトムス長めの傾向がある」という仮説のもと小規模のデータでどのような傾向が出るか確認をしていきます。そして、何か面白いものが見えてきそうであれば、実際にデータの範囲を広げより細かな調査をしていきます。
アンケート調査の場合はすでに数値として結果が出ているため、統計データとして扱って執筆が行えます。画像データの場合はそのままでは数値として扱うことができません。統計による集計をするためにまずは「画像データから何を数値化したら調査を行えるのか」を検討します。
今回は「コーディネート画像上でのトップスとボトムスの比率」を知ることができれば良いので、それを得るための解き方を考えていきます。
画像データを数値化するための機械学習の手法を検討していきます。今回の例で言うと、以下のような仮説立証への筋道が考えられます。
ここで、「なぜ実際の商品サイズや検出された矩形の長さをそのまま扱うのではなく骨格検出などを用いて比率を出したのか?」という疑問が生じます。コーディネート画像から洋服のサイズを検出する際には以下のような状況が考えられます。
これらを解決するために骨格検出を採用しました。
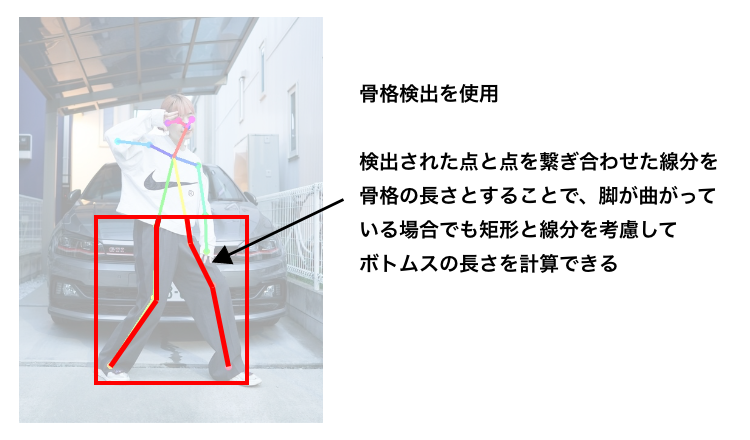
このように、1つの調査に対して様々な手法を組み合わせて問題を解いていきます。
アンケート調査と違い機械学習を用いた調査は、調査工程が複雑になります。調査リリースの読者ターゲットは幅広く、弊社の場合はファッション関係のリリースのため技術系の読者でないことも想定されます。いかに前提知識のない読者に対して分かりやすく伝えるかが重要になってきます。
上図で示したように画像を用いて視覚的に分かりやすく説明するなど「可視化」を意識して記事を書くよう心がけました。
調査リリースの醍醐味は「目には見えないファッションの流行を数値化し、複雑な内容を分かりやすく読者に伝えられる」ことです。
今まで街角などで「こういうコーディネートや色が増えてきたなぁ」と感覚として感じていたものが実際に数値として出てファッションの動向も観測できました。機械学習をファッションと繋げてイメージしやすく伝えることで、難しく感じる機械学習という分野がより親しみやすくなり興味を持つきっかけになることを感じました。また、ファッションの動向は社会の動向にも密接に関係していると言われます。調査で出た数値が社会とどのような関係を持っているのかを読み解いていく過程も醍醐味の1つと言えます。
これまでに調査リリースを3本出せましたが様々な課題が見つかりました。
四半期に1回のリリースを目標としていたため、仮説立てからリリースまでのスケジュールが3か月程度でした。
調査リリースごとに仮説が異なるため、使用する機械学習の手法も異なります。多様な手法を取り入れることは、それぞれに対して調査が必要になるためスケジュールの遅延が発生しやすいです。そのため、様々な手法を短期間で扱えるよう機械学習のライブラリを準備しておく必要があります。また、画像の背景除去に使用するセマンティックセグメンテーションなどの前処理は非常に時間がかかります。そのような処理を高速化できる環境の整備をしていく必要があります。
これはどの調査リリースにも言えるのですが、仮説が必ずしも正しいとは限りません。
今回で言うと「最近はトップス短め/ボトムス長めの傾向がある」という仮説に対し、「トップス短め/長めの二極化している」という結果が得られました。もし得られた結果からうまくストーリーが立てられないと調査期間を延ばす、もしくは仮説自体を変更するという選択をしないといけません。
このようなリスクを回避するために初めから仮説を複数用意しておくか、下記の「仮説の質を上げる」ことが必要になってきます。
結論を言うと、調査リリースのキモは仮説の質を上げるに尽きます。
今回の調査で得られた、年毎のトップス丈の割合推移の図を紹介します。

年毎にグラフの山が左へ移動しトップス丈が短くなることを予想しましたが、実際はその山が徐々に二極化していくという面白い様子が観測できます。
当初は「トップス短め/ボトムス長めの傾向」という仮説でした。調査の工程で単純な商品サイズのデータではなく、画像から読み取れるコーディネートの比率に焦点を当て、コーディネートの傾向も考慮するように仮説の質を高めていきました。このように当初の仮説の質を上げることはストーリーの肉付けに繋がり、より面白いストーリーを構築できます。機械学習を用いた調査リリースは、調査を細分化する傾向があるので仮説の質を上げやすいと感じました。
仮説を細分化して質を上げると、仮説を複数検討しながら調査できるので、結果的に仮説の立て直しの手戻りを減らすことが期待できます。
通常のアンケートベースの調査リリースと違い、機械学習を用いて数値化されていないデータを調査することは調査の難易度が上がります。機械学習を使用することで調査スケジュールは不安定になり、アンケートベース以上の課題が生まれました。しかし、数値のみのデータでは観測できないより深い調査が行えるため、仮説自体も質が高くなり面白いストーリーに仕上げることができると感じました。
この取り組みを通して研究所が何を行っているかをよりライトに発信できる仕組み作りができました。運用フローの課題を改善しつつ、ファッションの動向を素早く感知できるようなプラットフォームを開発して、より読者に興味を持ってもらえる調査リリースを出していきたいです。
今回取り上げた記事の他にも調査リリースを出しているので読んでみてください。
https://press-tech.zozo.com/entry/20200610_WEAR_Resarch1press-tech.zozo.com
https://press-tech.zozo.com/entry/20201218_WEARsearch3press-tech.zozo.com
ファッションの動向は社会・経済・様々なことに密接に関係し変化していきます。ZOZO研究所には様々な観点からファッションに関する謎を解明する環境が整っております。
ZOZO研究所ではMLエンジニア、バックエンドエンジニアのメンバーを募集しております。今回紹介した調査リリースもまだまだ始まったばかりの取り組みで、一緒に調査していただけるメンバーを募集しております。ご興味のある方は、以下のリンクからぜひご応募ください! hrmos.co

こんにちは。ZOZO研究所の shikajiro です。主にZOZO研究所のバックエンド全般を担当しています。
先日のテックブログ ZOZOTOWN「おすすめアイテム」を支える推薦システム基盤 をご覧いただけたでしょうか。ZOZO研究所と連携するMLOpsチームのTJこと田島が執筆した記事なので是非御覧ください。
この 推薦システム基盤の推薦アルゴリズム を研究開発する際に利用した 実験基盤 の開発メンバーとして参加し、そこでAI PlatformやKubeflowを活用して効率的なML開発を試みました。今回はこの実験基盤の開発を紹介したいとおもいます。
また、推薦基盤チームのてらちゃんこと寺崎が執筆した AI Platform Pipelines (Kubeflow Pipelines)による機械学習パイプラインの構築と本番導入 はKubeflowの基本を知る上で大変参考になりますので、合わせて御覧ください。Kubeflowの説明についてはこちらの記事が充実していますので、本記事では省略しています。
さらに、私が半年前に執筆した 近似最近傍探索Indexを作るワークフロー を読んでいると少しだけ楽しさが増すのでぜひご覧ください。
プロダクション環境の推薦基盤はGCP上で動いているため、ZOZO研究所による推薦アルゴリズムの研究開発もGCP上で行いました。
ZOZO研究所の研究開発メンバーは普段AWS環境での開発に慣れており、GCPで同等のサービスを模索しました。AI Platformである程度の開発効率を見込めそうなので、AI Platform Pipelinesを使って開発を進めました。
当時はAI PlatformやKubeflowに慣れているメンバーが居なかったため、試行錯誤しながら実験基盤の開発体験の向上を行っていきました。
開発当初のAI Platform PipelinesのKubeflowはversion 0.2と古く、何度か実験を動かすと原因不明のエラーで止まったり、実験結果が表示されない事もあり大変不安定でした。

AI Platform PipelinesではブラウザでKubeflow Pipelinesの構築ができます。しかし、バージョンの追従はGCP次第であり、自由に選択できません(執筆時点ではブラウザからKubeflow Pipelines 1.0が構築可能)。
そこで、AI Platform Pipelines運用を一旦諦め、当時最新のKubeflow Pipelines 1.0をGKEに独自に構築することで安定化させました(執筆時点ではKubeflow Pipelines 1.2が最新)。
その後、Kubeflow Pipelines 1.1がリリースされたのでインストールを試みたのですが、当時のドキュメントの完成度が高くなかった こともあり、うまくいかず一旦諦めました。
当初、開発者のローカルマシンでビルドしたDockerコンテナをGCRにアップロードしてパイプラインを実行していました。
latestタグを使ってしまうと予期せぬコンテナが使われてしまったり、かと言って都度異なるtagを指定するとパイプラインの中の実装を変える必要があったりと、なかなか手間がかかっていました。さらに、開発者のローカルマシンのCPUがDockerビルドにより消費してしまい、開発がし辛い状況でした。
そこで、DockerのビルドはすべてCloud Buildに変更しました。これによりローカルマシンのCPUを使うことはなくなり、一貫したビルドフローを使うことができるので、安定した開発を行うことができるようになりました。

この流れはこちらの記事を参考にしています。 cloud.google.com
開発時は開発者の任意のタイミングで何度も何度も学習と予測を行います。Kubeflow Pipelinesは一度作成したパイプラインをWeb画面からパラメータを変えて何度も実行できることが長所の1つです。
しかし、多くのパラメータがあるパイプラインの場合、実験の度にパラメータをすべて入力するのは少々手間です。開発者からは「気軽にコマンドラインから実験したい」と要望があったので、パラメータをyamlで管理してパイプラインにyamlを渡すことで、開発者のマシンから気軽に実行できるようになりました。
ファイルで管理することにより、設定したパラメータにコメントを残したり、Git管理できたり、入力ミスを減らすことができました。
settings.yamlの例
# project 全体の設定値
project_id: hello-zozo
webhook: https://hooks.slack.com/services/hogehoge
# Kubeflow Pipelines の設定値
experiment_name: Default
run_name_base: example
gcr_image: gcr.io/{project_id}/example:{tag}
# 学習や検証・予測などで使うパラメータ
number: 100
パイプラインを実行するPythonコードに Typer を導入しました。TyperはPythonのCLIアプリケーションを簡単に作れるライブラリです。代表的なものにargparseやClickがありますが、Typerはさらに使いやすくされたものです。
普段の実験は以下のコマンドで実行しています。
# python <パイプラインを実行するTyper実装> run <パイプラインを定義したPythonファイルがあるディレクトリ> python pipeline.py run helloworld
複数のyamlファイルを指定し、連続して実験を行うこともできます。
python pipeline.py run helloworld --settings hoge.yaml --settings fuga.yaml
前回ビルドしたDockerをそのまま利用する場合、tag名を指定してCloud Buildをスキップすることもできます。
python pipeline.py run helloworld --tag 'docker-tag-name'
パイプラインには学習パートと検証パートがあります。学習部分は前回実行して生成されたモデルを使って、検証部分だけ実装を変更して実行したい要望がありました。
Kubeflow Pipelinesには任意の位置から実行する機能はありません。新しくパイプラインを作ってはじめから実行する必要があります。
そこで、パイプラインの中にスキップフラグによる条件分岐する仕組みを追加し、生成済みのモデルを使って検証パートだけを行える仕組みを作りました。
パイプラインの実装はConditionで分岐させました。スキップする時、しない時両方のパイプラインの流れを定義することで、スキップを実現させています。
@dsl.pipeline(name="hello", description="hello world pipeline")
def pipeline(skip_build: bool, ...):
first = dsl.ContainerOp(...)
last = dsl.ContainerOp(...)
with dsl.Condition(skip_build == False, name="build"):
# とても重たい処理
build = dsl.ContainerOp(...)
build.after(first)
last.after(build)
with dsl.Condition(skip_build == True, name="skip-build"):
last.after(first)
パイプライン管理画面のGraphを見ると、スキップされていることが分かります。

みんな大好き失敗談を紹介します。
パイプラインの実行処理高速化、管理の利便性向上のため、次の改善を行いました。
この対応が原因でパイプライン実行時にエラーが頻出し、MLエンジニアが研究開発し辛い状況を作ってしまいました。
理由の説明の前に、Kubeflow Pipelinesで使われる3つの要素について説明します。
| 項目 | 必須 | 説明 |
|---|---|---|
| Run | 必須 | 最小実行単位。実行したワークフローをRunと表現する。 |
| Experiment | 必須 | Runを束ねる存在。Pipelineを指定するか、同等のyamlを直接指定して動かす。Experimentの粒度はチーム内で取り決めるのが良さそう(アルゴリズム単位、日付単位、パラメータ単位など)。 |
| Pipeline | 任意 | DAGの事。パラメータを指定すればすぐ動かせる。バージョン管理可能。繰り返し実行などする場合はPipelineが必要。 |
Run、Experiment、Pipelineの関係がちょっとややこしいため、注意が必要です。
Run
実行の最小単位です。Pipelineの1つの実行はRunで表されます。
Experiment
Runを分かりやすく分類するために名前をつけるものです。複数のRunを束ねることができます。Runには必ずExperimentが必要です。指定しない場合はDefaultになります。1つのExperimentに異なるPipelineのRunをまとめても構いません。ディレクトリに近い感覚です。
Pipeline
ここが曲者です。PipelineはDAGを定義したものになります。DAGを定義したソースコードを登録すれば、Pipelineとして一覧に表示されます。Pipelineを選びExperimentを指定して実行すれば、Runが新たに生成され実行されます。しかし、ワークフローを定義したPythonコードがあれば、Pipelineを登録していなくても実行できます。
「Pipelineが無くてもPipelineが実行できます」
何を言ってるか分からないと思いますが、Kubeflow PipelinesでのRunの実行にPipelineを登録しておく必要は無いのです。ソースコードがあれば直接実行できます。
Pipelines SDKを使って実行する場合、パイプラインとソースコードを同時に指定して実行できてしまいます。その時エラーにはならず、パイプラインが謎の挙動をするため気づくまで解決が困難になります。
これらが原因でしばらくの間、パイプラインの実行がややこしく、エラーが起きがちになっていました。現在はPipelineを登録せず、ExperimentとRunだけを使って実験を行うようにし、ある程度安定したらPipelineとして登録するようにしています。
ワークフローエンジンは他にAirflow(Composer)やDigdagがあります。それぞれ触ってみた私なりの感想を書いてみたいと思います。
その前に、MLにおいてワークフローはどうあるべきかを定義したManifest for ML in production を紹介します。
Reproducible 9ヶ月前に学習したモデルが全く同じ環境で、同じデータで再学習でき、ほぼ同じ(数%以内の差)の精度を得られるべきである
Accountable 本番で稼働しているどのモデルも、作成時のパラメータと学習データ、更に生データまでトレースできるべきである
Collaborative 他の同僚の作ったモデルを本人に聞くことなく改善でき、非同期で改善とコードやデータのマージができるべきである
Continuous 手動での作業0でモデルはデプロイできるべき。統計的にモニタリングできるべき
https://docs.google.com/presentation/d/17RWqPH8nIpwG-jID_UeZBCaQKoz4LVk1MLULrZdyNCs/edit#slide=id.g6ad50e93e5_0_59docs.google.com docs.google.com
ただワークフローを動かすのではなく、関連したデータを正しく管理できるかがMLのワークフローエンジンに求められます。
Airflow
GCPではComposerという名前でマネージドサービスになっており、世界的に人気があるワークフローエンジンです。画像検索の裏側 でもComposerを使っています。少し前まではComposerで動いているAirflowのバージョンがかなり古く不安定でしたが、今は割と落ち着いています。Airflowの仕組み上、「ワークフロー実行中にDAGファイルを更新すると途中からは更新した内容で動き出してしまう」ようになっています。これはインタラクティブに開発できて自由度が高いといえば聞こえは良いですが、過去に動いたワークフローがどのバージョンのDAGで動いたか全く分からず保証も無いため、運用管理コストがとても高くなります。
Digdag
GCPではマネージドサービスがなく、自前で構築する必要があります。Airflowと違ってDAGがきちんと管理されるので実行したワークフローがどのDAGで動いたのか、パラメータはなんだったのかが明白でとても扱いやすいです。しかし、最初に書きましたが自前で構築する必要があるため、初期構築・運用管理が大変になります。
Kubeflow
AI PlatformとしてマネージドサービスがありDigdagと同じようにDAGがパイプラインとして管理されているので、実行したワークフローに使ったDAGやパラメータが一目瞭然です。実行がすべてk8sのpodとして動くのでCPU/GPU・メモリなどのリソース管理、スケールしやすいのもとても良いです。まだ1.0になったばかりで新機能が続々と追加されており、技術を追っていくのが大変ですが、MLの開発効率には大きく寄与しそうです。
Manifest for ML in production をふまえると、Airflowでは実現できないことが分かります。Digdagでもできそうですが、MLに特化したKubeflowはパラメータ管理に秀でておりManifestを実現するための第一の選択肢になりそうです。ただ、そもそも目的とするものが違うため「Kubeflowは良い、Airflowはだめだ」ということではないです。それぞれにメリット・デメリットがあるので見極める必要があります。
このような実験基盤の改善を経て、研究開発を日々行い、 推薦システム基盤の推薦アルゴリズム はできあがっていっています。
「Kubeflow Pipelinesを導入すれば全部うまくいく!」ということはなく、チームメンバーで使いやすいように日々改善を行い、安定させていく事が重要になります。まだまだKubeflow Pipelinesの力を最大限発揮できていませんが、今後はより安定したワークフローエンジンとして動かせるよう、改善していきたいと思います。
ZOZOテクノロジーズではZOZO研究所のMLエンジニア、バックエンドエンジニアのメンバーを募集しております。 https://hrmos.co/pages/zozo/jobs/0000029hrmos.co hrmos.co

ZOZOテクノロジーズ推薦基盤チームの寺崎(@f6wbl6)です。ZOZOでは現在、米Yale大学の経営大学院マーケティング学科准教授である上武康亮氏と「顧客コミュニケーションの最適化」をテーマに共同研究を進めています。
推薦基盤チームでは上武氏のチームで構築した最適化アルゴリズムを本番環境で運用していくための機械学習基盤(以下、ML基盤)の設計と実装を行っています。本記事ではML基盤の足掛かりとして用いたAI Platform Pipelines (Kubeflow Pipelines) の概要とAI Platform Pipelinesの本番導入に際して検討したことをご紹介し、これからKubeflow Pipelinesを導入しようと考えている方のお役に立てればと思います。記事の最後には、推薦基盤チームで目指すMLプロダクト管理基盤の全体像について簡単にご紹介します。
上武氏との共同研究のより詳しい内容については弊社のニュース記事を参照ください。
続きを読む
こんにちは。SRE部MLOpsチームの田島(@tap1ma)です。
現在、ZOZOTOWNの「おすすめアイテム」に使われていたアイテム推薦ロジックを刷新するプロジェクトを進めています。既に一部のユーザに向けて新しいアイテム推薦ロジックを使った「おすすめアイテム」の配信を開始しています。その刷新に伴い推薦システムのインフラ基盤から新しく構築したので、本記事ではその基盤について解説したいと思います。
この記事で扱う「おすすめアイテム」とは、ZOZOTOWNで取り扱っている各アイテムの詳細ページ内にある「おすすめアイテム」枠のことです。アイテム詳細ページのアイテムやそのページを閲覧しているユーザに合わせて、おすすめのアイテムを複数表示しています。
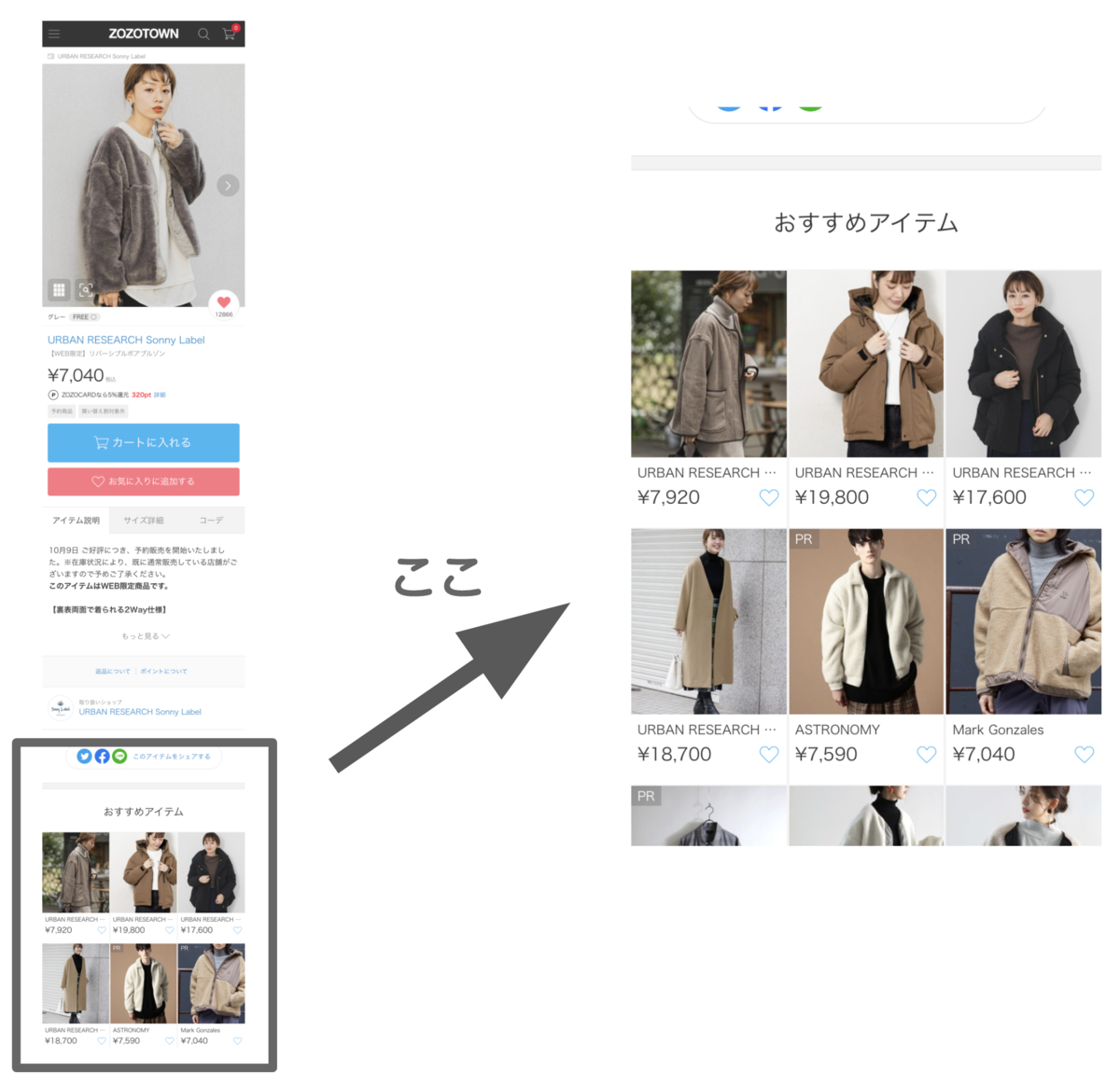
アイテムの詳細ページは、アイテムの詳細な説明やサイズ毎の在庫状況、商品画像といった情報を含み、ユーザがアイテム購入時に必ず通る重要なページです。そして、アイテム詳細ページ内に設置された「おすすめアイテム」枠もまたZOZOTOWNの重要な要素の1つです。
しかし、これまで使われていた推薦ロジックは10年以上前に開発されたもので、ストアドプロシージャとしてオンプレミスのSQL Serverに保存されているなど非常にレガシー化したシステムの上で動いていました。そのため、大きな技術的負債となっていました。
この度、より高性能な推薦ロジックの導入とそのためのシステムをインフラ基盤から新しく構築することで、推薦ロジックの性能向上と推薦システムの技術的負債の回収を同時に実現できました。
推薦ロジックの刷新に際し、以下の2種類の推薦ロジックを開発しました。
2種類の推薦ロジックの開発を並行で行い、互いに性能を競わせながら、より高性能な推薦ロジックの実現を目指して日々開発に取り組んでいます。
Recommdendations AIはECサイトに特化し、ユーザにパーソナライズされた商品の推薦システムを機械学習の高度な知識を必要とせずに簡単に構築できるGCPのフルマネージドサービス(本稿執筆時点でベータ版)です。
推薦ロジックのモデル構築に必要なデータを入力することで推薦ロジックの機械学習モデルの構築から、そのモデルを使って商品の推薦結果を返す推論用のWeb APIのサービングまで自動で行ってくれます。
また、データの入力に対してリアルタイムでモデルを更新できること、推論用のWeb APIがスケーラブルであることといった特徴を持ちます。
詳しくはこちらの資料をご覧ください。
弊社が有する研究機関「ZOZO研究所」によって独自で開発された推薦ロジックです。
現在は、ランダムウォークのアルゴリズムをベースとし、高速な推論速度、アイテムのカテゴリ分布の調整が可能(=推薦アイテムの多様性を制御できる)、などの特徴を持つ推薦ロジックとなっています。
手法の詳細は本記事では割愛しますが、現在もより高性能な推薦ロジックの実現を目指して様々な手法を用いた開発が進められています。
本章では、ユーザがアイテムの詳細ページへアクセスした際に詳細ページの「おすすめアイテム」枠に最適なアイテムを選出する新しい推薦システムについて詳しく解説します。
新しい推薦ロジックを使った推薦システムはGCP上でVPCから新規で構築しました。
以下が新しい推薦システムのシステム構成の概略図です。
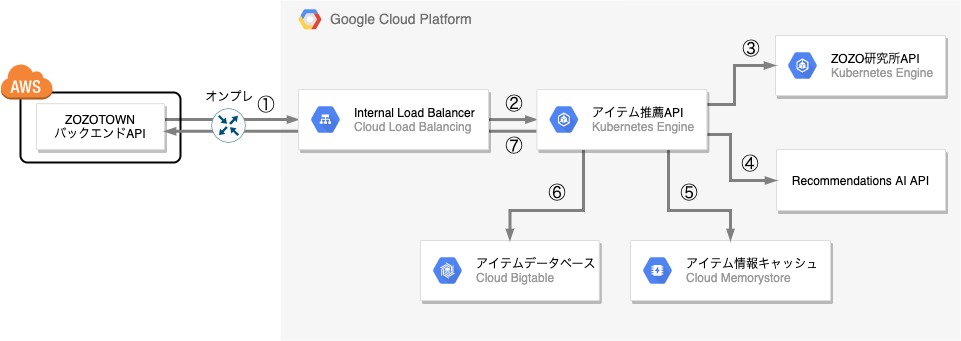
推薦システムはAWS上に存在するZOZOTOWNのバックエンドAPIからアクセスされ、推薦結果のアイテム情報をリストで返します。AWS→GCPのプライベート接続には、AWSではDirect Connect、GCPではDedicated Interconnectという専用線サービスを使用しオンプレ経由での専用線接続を行うことで高可用・低レイテンシーな通信を実現しています。
ZOZOTOWNバックエンドAPIからきたリクエストを推薦システムが処理して推薦結果となるアイテムのリストを返すまでの流れを、図の番号に沿って説明します。なお、登場するコンポーネントの説明は後述します。
以下、図の各コンポーネントを解説します。
Internal Load Balancer
ZOZOTOWNのバックエンドAPIからのアクセスを捌くL7ロードバランサーです。今回GKE(Google Kubernetes Engine)クラスタを新規で構築し、後述する「アイテム推薦API」及び「ZOZO研究所API」のサーバーをGKEクラスタのPod上で稼働させています。このGKEクラスタはプライベートネットワーク内に閉じているため、GKEクラスタの受け口にL7内部負荷分散を立てる必要がありました。GKEのバージョン1.16.5-gke.10からGCPのL7内部負荷分散に対応したIngress for Internal HTTP(S) Load Balancingが使用できるようになったので、今回初めて採用しました。
アイテム推薦API
アイテム推薦APIはZOZOTOWNバックエンドAPIからInternal Load Balancer経由で届いたリクエストに対して、最終的な推薦結果となるアイテムをリストで返すAPIサーバーです。ZOZOTOWNバックエンドAPIから届くリクエストのパラメータには閲覧しているアイテムの情報とユーザの情報、推薦結果として取得したいアイテムの件数が含まれています。Java製フレームワークSpring Bootを用いて作られており、GKEのPod上で稼働しています。
ZOZO研究所API
ZOZO研究所が開発した推薦ロジックを用いた推論用のAPIサーバです。アイテム推薦APIからきたリクエストに対してそのアイテムの詳細ページの「おすすめアイテム」枠に最適なアイテムを推論し、アイテムIDのリストを返します。Python製フレームワークのFlaskを用いて作られており、GKEのPod上で稼働しています。
Recommendations AI API
GCPのRecommendations AI上で構築したアイテム推薦の推薦ロジックの機械学習モデルによる推論を行うWeb APIです。ZOZO研究所API同様、アイテム推薦APIからきたリクエストに対して推論したアイテムIDのリストを返します。
アイテムデータベース
ZOZOTOWNの最新のアイテム情報のデータが格納されているデータベースで、GCPのフルマネージドな大規模分散データベースであるCloud Bigtableを使用しています。Cloud Pub/Sub経由で送られてくるアイテムのデータの更新情報がリアルタイムで反映されるので、常に最新のアイテムデータが格納されています。
アイテム情報キャッシュ
GCPのフルマネージドなRedisサービスを利用しています。Bigtableへの負荷軽減のためにアイテム推薦APIがBigtableから取得したアイテムの情報は一定期間Redisにキャッシュさせています。
以下、工夫した点についていくつか紹介します。
ZOZOTOWNの最新のアイテムの情報を格納しておくデータベースとして以下の要件から高スループットかつ低レイテンシーなGCPのCloud Bigtableを採用しました。
しかし、実際にアイテム推薦APIからBigtableへアクセスしてみると期待通りの応答性能が出なかったため、パフォーマンスチューニングを行い応答性能を改善しました。ここでは、実際に行ったチューニング方法について説明します。
前提として、アイテム推薦APIは以下のような実装となっていました。
Multi-Get という参照系の操作です。調査したところ、上記のBigtableクライアントライブラリによるBigtableへのアクセスエラー発生時のリトライ処理は以下のような挙動をしていることが分かりました。
今回、アイテム推薦システムのタイムアウト時間の要件は5秒であったため、元々の設定であった設定値Aとタイムアウト時間を減らしてその分タイムアウト後のリトライ回数を増やした設定値B、2つの設定値でアイテム推薦APIに負荷をかけてBigtableへのアクセス時の応答性能を測定しました。

実験の結果、設定値Bの応答速度は設定値Aに比べて99パーセンタイル値の比較で平均約29%速いことが分かりました。つまり、応答が想定時間で返ってこない場合はそのまま待つよりも再度リクエストを投げた方がより速く応答を返しやすいようです。
以上の結果を踏まえてBの設定値となるように更新し、パフォーマンスを改善できました。
アイテム推薦APIのデプロイ時にPodがローリングアップデートされた際、Ingress for Internal HTTP(S) Load Balancing(以下、Ingress)でステータスコード503のエラーが出る事象が発生しました。調査したところ、原因はGKEのIngressのコネクションドレインのタイムアウト時間がデフォルトの0秒であったためコネクションドレインが機能せずリクエスト処理の途中でコネクションが切られてしまっていたからでした。そこで、適切なコネクションドレインのタイムアウト時間を設定したのですが、ここではその設定の際に考えたことについて説明します。
PodがIngressから登録解除されて停止する際にPodではpreStopフックの実行処理が、Ingressではコネクションドレインの処理が同時に非同期で実行されます。そして、PodではpreStopフックの実行終了後にコンテナのルートプロセスに対してSIGTERMが送られ、サーバーがGraceful Shutdownされます。実際に計測してみるとアイテム推薦APIのpreStopフックの処理が始まって10〜15秒後にコネクションドレインの処理が始まっていることが分かりました。そのため、まずはpreStopフックでは15秒のsleep処理を走らすことで、PodがIngressから登録解除されてコネクションドレイン処理開始する前にサーバーのGraceful Shutdownが始まらないように調整しました。また、サーバーのGraceful Shutdownに要する時間は約20秒だったので、この場合のコネクションドレインのタイムアウト時間はPodのpreStopフックの開始から正常にGraceful Shutdownされるまでの時間である(15秒+20秒=)35秒以上に設定すべきであることが分かります。実際には少し余裕を持ってコネクションドレインのタイムアウト時間として45秒を設定しました。
ZOZO研究所APIに対して負荷試験を行ったところ、クエリとなるアイテムIDによって応答速度に大きなばらつきがあり、CPUスパイクも頻繁に起こしていました。
調査したところ、以下のことが判明しました。
上記の特性を踏まえて、アクセス数上位のアイテムに関しては推論結果をキャッシュするようにしました。ZOZO研究所APIのPod起動時に推論を行い、サーバーのメモリ上に推論結果を展開しています。キャッシュしたアイテムの数は総アイテム数のわずか0.2%ですが、システムパフォーマンスが大幅に向上し、観測されていたCPUスパイクも起きなくなり安定化できました。
ZOZO研究所製の推薦ロジックに使用するモデルの更新は毎日1回行われています。
ここでは、そのモデル更新時のワークフローを解説したいと思います。以下が、そのワークフローの概略図です。

Cloud ComposerとBigQueryで日次集計された最新のアイテムデータを読み込み、Pythonスクリプトによって推薦ロジックのモデルファイルを生成します。この日次集計処理は今回のプロジェクト以前から運用されていて、かつ、異なるGCPプロジェクトで存在していました。そのため集計完了の通知をCloud Pub/Subで受け取るようにし、本プロジェクトのモデルファイル生成Jobを実行するトリガーとしています。Cloud RunはCloud Pub/Subからメッセージを受け取りGKEのJobを実行するトリガーとしてのみ利用しています。なお、Cloud Run・GKEのJobの選定に関しては後述します。
モデル更新時の流れを図の番号に対応する手順で説明します。
kubectl rollout restart コマンドによって再起動させて処理が終了します。以下、推薦ロジックのモデル更新時のワークフローで工夫した点についていくつか紹介します。
前述の通り、既存のCloud Composerとは別のGCPプロジェクトでモデル更新のジョブを実行する必要がありました。そこで、Cloud Composerの日次集計のワークフローの最後にCloud Pub/Subへ通知を送り、その通知をトリガーに別のGCPプロジェクトでモデル更新のジョブを実行する設計としました。
1日1回Cloud Pub/SubからくるPOSTリクエストをトリガーにワークロードを実行する用途として、リクエストが実際に処理されている時間のみ課金が発生する以下の3つのサーバレスソリューションを検討しました。
ただし、現在弊チームではAnthos環境を運用していないので、Cloud Runの場合はCloud Run for Anthos on Google Cloudではなくフルマネージド版のCloud Runのみに限ります。
また、これらのメモリの上限値は以下の通りです。
| App Engine(スタンダード環境) | Cloud Functions | Cloud Run(フルマネージド) | |
|---|---|---|---|
| メモリ上限 | 2Gi | 2Gi | 4Gi |
モデル更新ジョブのメモリ消費量は上記のどのソリューションにおいてもそのメモリ上限値を超えてしまうので、モデル更新処理をそれだけで完結することはできません。そこで、モデル更新ジョブをアイテム推薦APIのPodなどが稼働しているGKEクラスタ内のハイメモリなインスタンス上でKubernetes Jobとして実行することにし、そのJobの作成処理を上記のサーバレスソリューションのいずれかで実行することにしました。理想を言うと、Cloud Pub/Subへの通知をトリガーとして直接GKEのJobを作成できるようなソリューションがあったら嬉しいですね。
検討の末、他の2つに比べてワークロードのランタイムに縛りがなく、Dockerfileで管理できる開発のしやすさの点で優れたCloud Runをチームで今回初めて採用しました。また、Cloud Runでは、Cloud Pub/Subからきたリクエストのトークン認証処理を組み込みでサポートしているので、簡単な設定でCloud Pub/SubとCloud Run間を安全に通信することができます。GCPの公式ドキュメントには記載が見当たりませんでしたが、Cloud RunとCloud Pub/Subが異なるGCPプロジェクトに存在しているケースでもトークン認証処理を利用することができます。便利。
Cloud Pub/Subはat-least-once配信方式を採用しているため、同一のメッセージが複数回配信される可能性があります。そのため、たとえCloud ComposerからCloud Pub/Subへのメッセージのパブリッシュは1日1件であっても、そのメッセージが複数回配信されてCloud Runのエンドポイントが1日に複数回叩かれてしまう場合を考慮しないといけません。
まず、Cloud Runで日に複数回GKEのJobの作成処理が実行される可能性があるため、GKEのJobの処理が冪等である必要があります。今回GKEのJobで実行するモデル作成処理は冪等であるため、この要件は満たしていました。
また、Cloud RunによるGKEのリソースへの操作が並列で行われる可能性も考慮する必要があります。Cloud Runの処理ではGKEのJobを作成するためにKubernetes APIを使ってGKEのリソースを操作します。実際の処理ではJobの作成処理だけでなく、昨日分のJobの設定をクリーンアップしたりJob作成時に立ち上がったPodの情報を取得したりと、Cloud Runのエンドポイントへのリクエスト毎に複数回Kubernetes APIへのアクセスが発生します。もしCloud Pub/Subからほぼ同時に複数のリクエストがきた場合、これらのKubernetes APIへの操作が並列で実行されるため、Jobの作成処理が同時に2度実行されてしまい片方の処理がエラーになるといった問題に繋がる可能性があります。一方で、Kubernetes APIを使った操作は非同期なこともあり、このようなエッジケースにも対応した並行性制御を実装するのはなかなか大変です。そこで、複数リクエストが同時にきてもCloud Runではリクエストを並列では処理しないようにすることでGKEのリソースへの一連の操作を排他制御するようにしました。具体的には、Cloud Runではコンテナあたりの最大同時リクエスト数とスケールアウト時の最大コンテナインスタンス数を簡単に設定できるので、どちらも最大値を1とすることで複数リクエストを並列で処理しないようにしました。
GKEのJobの監視を導入時にいくつか躓いた点があるので、それらの点も踏まえてどのような設定をしたのかをここでは説明したいと思います。
以下の2種類の監視が現在設定されています。
当初はJobが異常終了した時、すなわち、Jobが作成したPodのステータスがFailedとなった時にアラートが鳴るようにCloud Monitoringで監視を導入しようと試みました。しかし、Cloud MonitoringではPodのFailedステータスを直接カウントしアラートのトリガーとするような設定方法はサポートされておりませんでした。そこで、代わりにPod内のコンテナの再起動回数であるrestart countをトリガーに使用できることを利用し、Pod内のコンテナの異常終了後の再起動処理が発生(restart count > 0)したらアラートが鳴るように設定しました。ただし、このやり方は以下の点において理想的な監視とは言えない妥協策です。
もっと適切な方法ご存知の方いましたら教えてください!
Jobが失敗した時の監視だけでは以下のような異常時のケースを拾うことができません。
上記のケースが発生した際にアラートが飛ぶように、日次で実行されるJobがその日のうちに正常終了していない時にアラートがなるような監視も導入しました。しかし、Cloud MonitoringではPodのFailedステータスと同様Succeededステータスを直接カウントしアラートのトリガーとするような設定方法もサポートされておりませんでした。また、Cloud Monitoringでは24時間周期の監視もサポートされていませんでした。そこで、妥協策として以下の手順で監視を設定しました。
このやり方もPodの成功ステータスを直接監視できていない複雑な設計となってしまっています。もっと適切な方法ご存知の方いましたら教えてください!(2回目)
本記事ではZOZOTOWNの「おすすめアイテム」枠に使われている新しい推薦システム基盤のアーキテクチャについて解説しました。私が今年入社して最初に取り組んだプロジェクトでしたが、ネットワーク設計から任せてもらい、個人的に思い入れの深いプロジェクトです。ユーザの皆さんが気に入るアイテムをより簡単に見つけやすくできるように引き続き改善に取り組んでいきます。
SRE部MLOpsチームでは、データや機械学習を用いてサービスを成長させたいエンジニアを募集しています。ご興味のある方は、以下のリンクからぜひご応募ください!

ZOZO研究所ディレクターの松谷です。
ZOZO研究所では、イェール大学の成田悠輔氏、東京工業大学の齋藤優太氏らとの共同プロジェクトとして機械学習に基づいて作られた意思決定の性能をオフライン評価するためのOff-Policy Evaluation(OPE)に関する共同研究とバンディットアルゴリズムの社会実装に取り組んでいます(共同研究に関するプレスリリース)。また取り組みの一環としてOPEの研究に適した大規模データセット(Open Bandit Dataset)とOSS(Open Bandit Pipeline)を公開しています。これらのオープンリソースの詳細は、こちらのブログ記事にまとめています。
本記事では、ZOZO研究所で社会実装を行ったバンディットアルゴリズムを活用した推薦システムの構成について解説します。バンディットアルゴリズムを用いた推薦システムの構成と実際にどのように活用されたかについて、また公開されたデータセットがどのようなシステムで収集されたか、みなさまの参考になれば幸いです。
本システムの設計・開発と本記事のシステム概要解説については研究所アドバイザーの粟飯原が担当しています。
まず本プロジェクトのフォーカスであるバンディットアルゴリズムについて解説します。
環境に対する不完全な事前知識を活用して行動し、環境を観測してデータを集めながら最適な行動を発見する(探索と活用)アルゴリズムがバンディットアルゴリズムです。システム自身が試行錯誤しながら最適なシステム制御を実現する機械学習手法である強化学習の中で、代表的なアルゴリズムのひとつです。
バンディットアルゴリズムが扱う問題設定は「複数の選択肢または介入からできるだけ良いものを選択したい」というものです。例えば、推薦する商品Aと商品Bのどちらがより顧客にクリックされるか、新薬Aと新薬Bのどちらがある病気を効果的に治癒するのかというような状況です。この問題の難しさは、良い選択肢をできるだけ多く選択したいという活用と、とるべき選択肢が何であるかをできるだけ正確に知りたいという探索のトレードオフがあることによります。
このような状況で選択するためによく用いられるのは、A/Bテストと呼ばれる手法です。AとBの2つの介入をランダムに割り当ててどちらが平均的に優れているのかを統計的仮説検定に基づいて選択します。しかし典型的なA/Bテストでは純粋な探索を一定期間行ってから純粋な活用を行うため、無駄な探索をしてしまったり誤った活用をしてしまうリスクがあります。
バンディットアルゴリズムは過去の経験に基づく予測の活用と探索のトレードオフをデータから最適化し、累積報酬(例えばクリック数)を最大化するように意思決定を行います。
Web広告配信や推薦システムでよく利用されており、またトップ棋士に勝ち越したことで有名なAlphaGo(アルファ碁)にもその技術が応用されています。
強化学習において状態が変化しない最も単純な設定です。アーム(選択肢)を引くとスロットマシンがある確率に基づいて報酬が得られるという設定のもと、行動の主体であるエージェントは腕を引くという行動だけ行います。これは、例えば商品アイテムの推薦においては実際に推薦結果として提示する商品アイテムの選択になります。
バンディットアルゴリズムは拡張によりユーザーの属性に合わせパーソナライズを扱うことが可能です。ユーザー属性/履歴などの埋め込みベクトルを用い、ユーザーそれぞれに最適な行動(何を表示するか)を決定します。どのようにパーソナライズするかは、コンテキストの設計により調整が可能です。実際の応用としては、Spotifyホーム画面のパーソナライズやNetflixのアートワークパーソナライズなど、推薦に力を入れているサービスにおいて利用されている例が挙げられます。
バンディットアルゴリズムは複数ある商品画像のうちどのクリエイティブを表示するかなどにも利用されています。よりクリックされやすいクリエィティブに自動で寄せるなど、無駄なインプレッションを減らしつつKPIの向上を目指すことが可能です。
バンディットアルゴリズムはEコマースなどの推薦において、対象アイテムを絞り込んだ後のリランキングなどに使用されることもあります。通常のランキング集計よりも新しいアイテムなどの追加にも早く対応でき、機会損失を減らしつつコンバージョンなどKPIの改善を目指すことが可能となります。
ZOZO研究所では、多腕バンディットアルゴリズム(Multi-Armed Bandit Algorithm)を用い、数あるファッションアイテムの中からユーザーごとに適したアイテムを推薦するシステムを開発し、ZOZOTOWNのトップページにおいて実際に配信を実施しました。
トップページ来訪ユーザーに対してRandomまたはBernoulli Thompson Sampling(BernoulliTS)という2種類の意思決定policyを振り分けて適用しています。
コンテキストを合わせて選択するように拡張することで(Contextual Bandit Algorithm)、ユーザーの属性に合わせた商品のパーソナライズ推薦も可能です。ZOZOTOWNではユーザーひとりひとりに、より価値のあるサイト上での発見・経験を提供するべく、推薦や検索結果のパーソナライズをすすめています。本プロジェクトの理論部分の成果でもあるオフライン評価の手法(OPE)を用いることで、どのような特徴量を利用すればよいのか効率的に提案することが可能となります。ZOZO研究所では開発したパイプラインを用いて、効率よくどのようなパーソナライズを実際のサービスで用いるべきかを評価・比較して提案につなげています。
ZOZO研究所では、機械学習による予測値などに基づいて作られる意思決定policyの性能を評価する手法であるOPEに関しての研究を進めています。
機械学習は予測のための技術として広く利用されていますが、実際の応用場面に目を向けてみると、予測値をそのまま使うのではなく予測値に基づいて何かしらの意思決定を行うことが目的である場合が多くあります。
例えばクリック率の予測値に基づいてユーザーごとにどのアイテムを推薦すべきか選択する場合、予測そのものよりも、それに基づいて作られる推薦や広告配信などの意思決定が重要です。従って、評価自体もクリック率の予測精度よりも最終的な意思決定policy自体の性能を直接評価する方か適切と言えます。
意思決定policyの性能評価において、実際にサービスへ実装しKPIの挙動を確認するオンライン実験には大きな実装コストやユーザー体験の毀損・KPIへのマイナス影響など大きなリスクを伴うため、オフラインで同様に性能を評価する手法が模索されてきました。
この、新たな意思決定policyの性能を過去の蓄積データを用いて推定する問題のことをOPEと呼びます。
NetflixやSpotify、Criteoなどの研究所がこぞってトップ国際会議でOPEに関する論文を発表しており、特にテック企業から大きな注目を集めています。
正確なOPEは多くの実務的メリットをもたらします。例えば現行の推薦ロジックとは異なる新たな推薦ロジック候補がもたらすKPIの値を既にあるデータを用いて見積もることができます。ハイパーパラメータや機械学習アルゴリズムの組み合わせを変えることによって多数生成される候補のうち、どれをオンライン実験に回すべきなのかを事前に絞り込むこともできます。これにより、実装コストやリスクを抑えつつ、より効率的なビジネス・サービス改善が可能となります。
本共同研究プロジェクトではOPEの実証研究と実サービスへの組み込みを目的とし、バンディットアルゴリズムをZOZOTOWNにおけるファッションアイテム推薦枠に実装しました。これにより、A/Bテストを必要としない低コストな継続的サービス改善のための評価フレームワーク構築を目指しています。
次の章では、そのバンディットシステムの構成について解説します。
本プロジェクトの理論的な新規性とデータ・評価パイプライン公開についての詳しい解説はこちらの記事に任せるとして、本研究を進めるにあたりZOZO研究所で開発を進めてきた配信とログ集計基盤について解説します。
本記事で解説するシステムの導入により、ZOZOTOWN上で実際のサービスを改善しつつオフライン評価手法の構築を進めることが可能となりました。
早速本システムの構成の概観から説明します。
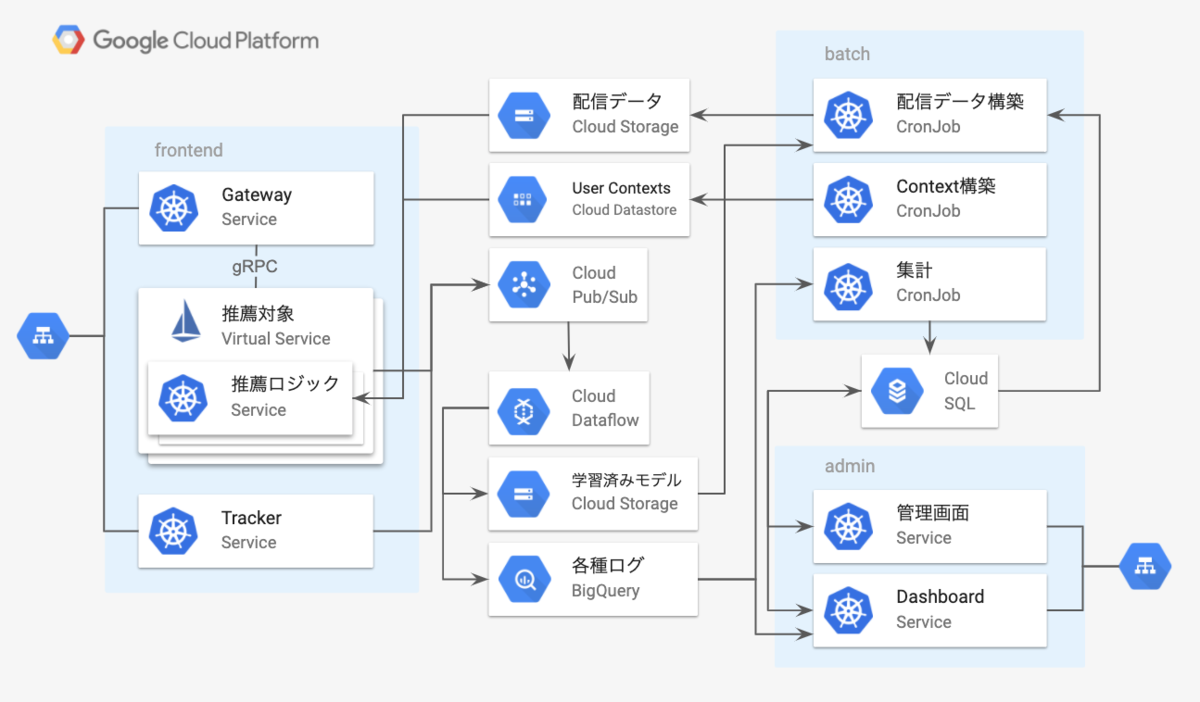
インフラとしてGCPを利用しており、配信・ログ収集・バッチ系などはGKE上で動かしています。
内部の通信にはgRPCを用いており、gRPCのロードバランシングや振り分け制御を行うためにIstioを有効にしています。
ユーザーの画面に推薦対象が表示された場合や、クリックした場合、購買があった場合などはトラッキングサーバーにイベントログを送るようにしており、それらの情報を元に配信パラメータを更新します。現状JavaScriptの表示・イベント送信のSDKを用意しており、Web面への配信をしています。ログ周りはBigQueryに保存して、Contextual Banditのパラメータの学習を行うストリーミング処理系としてCloud Dataflowを使っています。
以下それぞれのコンポーネント毎に簡単に説明していきます。
アプリやブラウザなどのクライアントからのHTTPリクエストを受け取とって、gRPCを喋る推薦サーバーにリクエストをプロキシするサーバーです。Istio Ingress GatewayによるgRPC<->httpブリッジの利用も考えましたが、GKE Ingressの裏にGoで書いたGatewayサーバーをおいています。配信対象やA/Bテスト時の振り分けなどを全てIstioの機能で実現できるような構成も可能であったと考えていますが、以下の2つの理由で独自のGatewayを用意することにしました。
Gatewayサーバー側では、リクエストを元にA/Bテストの振り分けのフラグに用いるヘッダ(Request metadata)を付与して推薦サーバーにリクエストを送るようにしています。
推薦サーバーは、GCS上に配置された配信データ(配信対象・配信アルゴリズム・コンテキスト情報・配信パラメータの組)のパスを環境変数で指定してデプロイされます。定期的にファイルの更新をチェックしては配信データに更新があるとデータの取得を行って内部のデータを更新しています。推薦サーバーはGoで実装されており、計算部分はOpenBLASをBLASバックエンドにしたgonumを用いています。そして、ユーザーのコンテキスト情報はCloud Datastoreに配置してgRPCリクエスト毎に取得しています。
推薦サーバーは、それぞれ配信データ毎にgRPCサーバーとしてDeploymentを作成しています。その上で同一の配信対象のDeploymentはIstioのVirtual Serivceとして1つにまとめて、A/Bテストなどが行えるようになっています。Virual ServiceのHttpMatchRequestを用いてどのDeploymentにリクエストを送るかの振り分けを行っています。
上記の設定を行った配信対象毎のVirtual Serviceのイメージは以下のようなものになります。
apiVersion: v1 kind: Service metadata: name: DELIVERYTYPE namespace: bandit-api labels: app: DELIVERYTYPE spec: ports: - port: 3000 targetPort: 3000 protocol: TCP name: grpc-DELIVERYTYPE selector: app: DELIVERYTYPE --- apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: DELIVERYTYPE namespace: bandit-api spec: host: DELIVERYTYPE trafficPolicy: loadBalancer: simple: RANDOM subsets: - name: contexuala labels: deliveryname: contexuala - name: contextualb labels: deliveryname: contexuala - name: random labels: deliveryname: random --- apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: DELIVERYTYPE namespace: bandit-api spec: hosts: - "msp" http: - match: - headers: some-header: exact: X route: - destination: host: DELIVERYTYPE subset: random - match: - headers: some-header: exact: Y route: - destination: host: DELIVERYTYPE subset: contexualb - match: route: - destination: host: DELIVERYTYPE subset: contexuala
DestinationRuleにはsubsets以下に配信を振り分けるDeploymentの名前をdeliverynameに列挙します。
VirtualServiceのHttpMatchRequestルールに、Gatewayサーバが付与するA/Bテスト用のヘッダの条件を記載します。条件にマッチしたリクエストが設定されたsubsetと対応するDeploymentにルーティングされます。
このようにIstioの機能を利用することでリクエストの振り分けが実現でき、推薦サーバーのコードを変更することなく複数のA/Bテストを実施することが可能になります。
推薦サーバーが返却したアイテム毎にユニークなID(以下、配信ID)を付与しており、それに紐づく形で以下のような詳細情報を記録しています。以下の項目は一部の項目例です。
このIDはimpression・click・conversion・その他の関連するユーザの行動がある度にトラッキングサーバーへ送信されます。送信された配信IDを元に、紐付けて記録されている詳細情報と合わせてCloud Pub/Subへ送信されCloud Dataflowを介してBigQuery上に記録されます。
BigQueryからの集計や、配信データの構築はk8sのCronJobとして実行しています。コンテキストの情報を用いない通常のバンディットにおいては、CTRやCVRなどの計算はBigQueryのログを定期的に集計してパラメータを更新しています。
Contextual Banditの学習をCloud DataflowのStreaming処理でどのように行っているのかについては、次の章で細かく解説します。
Contextual Banditの学習はログの突き合わせが必要になるので、ログを一度DWHに保存した後で定時バッチにて実行されることが多いと思われます。tracker上でのオンライン学習も考えられますが、clickがなかったimpressionログをどう扱うのかや、複数台で学習したパラメータの混合など考慮しないといけないことが出てきます。
そこで本システムではStreaming処理系を用いて学習モデルパラメータの更新間隔を早められるのではと考え、Cloud Dataflowを用いた半オンラインでの学習を試みました。
CTRの予測をLogistic Thompson Samplingで行うため、Cloud Dataflowを用いて文献1にあるラプラス近似を用いたBayesian Logistic Regressionモデルを学習します。
同様の枠組みでCVRの予測なども可能ではありますが、CVは遅れて来ることも多いためストリーミングでの学習は現状CTRのみ行っています。
シリアライズされたcontextの情報を含むimpressionとclickのログをtrackerからCloud Pub/Subへ書き込み、それをDatadlowで読み込む構成になっています。
Streamingの全体の流れとしては以下のようになります。
以下のコードのように上記の処理をpipelineとしてつなげています。
def run(argv): mbu_options = MiniBatchUpdateOption(argv, streaming=True, save_main_session=True) logging.getLogger().setLevel(mbu_options.log_level.get()) with beam.Pipeline(options=mbu_options) as pipeline: log = pipeline | 'Read log' >> ReadPubSubAndUnmarshalJson(mbu_options.log_subscription) (log | 'GroupBy ID' >> GroupByBidID(mbu_options.session_gap) | 'Filter invalid value' >> beam.Filter(filter_invalid_value) | 'GroupBy item and model' >> GroupByItemAndModel(mbu_options.wait_count, mbu_options.wait_process_time) | 'Filter zero window' >> beam.Filter(filter_zero_window) | 'Deserialize context' >> beam.ParDo(ContextDeserializer()) | 'Mini batch update' >> beam.ParDo( MiniBatchUpdater(mbu_options.output_path, mbu_options.batch_size)))
MiniBatchUpdaterの中で、GCS上に保存されている前回までの学習結果の取得と、出力されたWindow分のデータの更新とGCSへの保存を行っています。MiniBatchUpdaterの詳細は割愛しますが、以下で、半オンラインでの学習の肝となるSession Windowをどのように適用しているか解説します。
一定時間内に到達した同一配信IDのimpressionログとclickログをSession Windowを用いてまとめます。
以下のPythonコードはclickとimpressionをSession Windowを用いてまとめるためのTransformのコードです。同一Window内にimpressionとclickのログがある物を「clickあり」、impressionのみの物を「clickなし」として扱います。clickのみのログは後段の処理で取り除いています。DataflowのSession Windowでは、同一キーのログがギャップ期間以内に到達した場合、同じセッションとしてまとめられます。
以下のコードではsession_gapという形でギャップ時間を渡しています。
class GroupByBidID(beam.PTransform): def __init__(self, session_gap): beam.PTransform.__init__(self) self._session_gap = session_gap.get() self._mandatory_fields = (BID_ID,) def add_timestamp(self, value): """ Add timestamp in order to groupby bid id using session window. """ return beam.window.TimestampedValue(value, datetime.timestamp(datetime.now())) def filter_invalid_value(self, value): return all(field in value for field in self._mandatory_fields) def expand(self, pcoll): return (pcoll | 'Filter invalid value' >> beam.Filter(self.filter_invalid_value) | 'Add key' >> beam.Map(lambda elem: (elem[BID_ID], elem)) | 'Session window' >> beam.WindowInto( window.Sessions(self._session_gap), accumulation_mode=AccumulationMode.DISCARDING) | 'Groupby bid id' >> beam.GroupByKey())
impressionとclickの突き合わせにSession Windowを用いていることから実際のCTRよりは少なく見積もられてしまうことになります。現状はimpressionとclickの突き合わせのギャップ時間は10分とっており、本システムの1日分のログから計算したところ98%は突き合わせができているようです。
学習済みのパラメータ自体はメモリ上に保持しているわけではなくGCS上に保存しています。1ログ毎にパラメータの取得と保存を行うのは効率が悪いため、一定量のログが溜まった後、GCSから取得して学習を行います。impressionのログとclickのログをSession Windowでまとめた後は配信アイテムID・配信種別・配信名毎にグルーピングを行います。その後、再度Session Windowを適用して、指定したサイズ以上のチャンクにまとめます。
clickとimpressionがまとめられた後は、腕毎に目的とするbatch size分のログが貯まるまで、再度Session Windowに掛けられます。流量が少なく、指定したサイズ分溜まるまで非常に時間がかかる場合もあり得えます。以下のコードのようにtriggerの設定で、AfterAnyを利用して複数のトリガーを設定して、一定期間内にデータがたまらなかった場合も後段へ流すようにしています。
class GroupByItemAndModel(beam.PTransform): def __init__(self, wait_count, wait_process_time): beam.PTransform.__init__(self) self._wait_count = wait_count.get() self._wait_process_time = wait_process_time.get() self._mandatory_fields = (ITEM_ID, MODEL_NAME, TARGET, CONTEXT, ACTION) def map_item_model(self, value): key = (value[1][0][ITEM_ID], value[1][0][MODEL_NAME], value[1][0][TARGET]) action_list = [v[ACTION] for v in value[1] if ACTION in v] # CASE both imp and click exist: 1 # CASE otherwise: -1 # logging.info(action_list) feature = 1 if IMP in action_list and CLICK in action_list else -1 return (key, [feature, value[1][0][CONTEXT]]) def filter_invalid_value(self, value): for val in value[1]: if not all(field in val for field in self._mandatory_fields): return False return True def expand(self, pcoll): return (pcoll | 'Filter invalid value' >> beam.Filter(self.filter_invalid_value) | 'Map item id and model' >> beam.Map(self.map_item_model) | 'Window into' >> beam.WindowInto( window.Sessions(self._wait_process_time*60), trigger=Repeatedly(AfterAny(AfterWatermark(), AfterCount(self._wait_count))), accumulation_mode=AccumulationMode.DISCARDING) | 'Groupby item id and model' >> beam.GroupByKey())
triggerとしてAfterCountを利用した場合、指定した数ちょうどのチャンクが出力されるわけではなくそれをオーバーしたものが来る点に注意が必要です。
本記事で紹介したバンディットアルゴリズムのシステムを実装した際に収集したデータを、先日Open Bandit Datasetとして一般公開しました。この公開データは合計2600万以上のログを含む大規模なものであり、それぞれのデータは特徴量・方策によって選択されたファッションアイテム・過去の方策による行動選択確率・クリック有無ラベルによって構成されます。これらの特徴により、OPEの正確さを現実的かつ再現可能な方法で評価でき、非常に学術的な価値の高いデータとなっています。
また開発したオフライン評価フレームワークOpen Bandit PipelineをOSSとして併せて公開しています。このパイプラインにより、研究者はOPEの部分の実装に集中して他の手法との性能比較を行うことができるようになります。
公開データセットとパイプラインに関して、詳しくはこちらのブログ記事をご覧ください。
本取り組みに関連して、以下の雑誌に寄稿しています。
また、オープンリソースの特徴やその活用方法などを以下の学術論文としてまとめ、公開しています。
公開データセットに関する詳細な記述など、ご興味ある方はぜひチェックしてみてください。
本取り組みに関する研究成果を、トップ国際会議のワークショップを含む国内外の多くの場で発表しています。上に併せまして、ご興味ある方はぜひチェックしてみてください。
NeurIPS 2020 Workshop on Consequential Decision Making in Dynamic Environments
本取り組みに関する成果を以下のメディアなどに取り上げていただきました(抜粋)。
ZOZOテクノロジーズでは一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
Chapelle, Olivier and Li, Lihong. An Empirical Evaluation of Thompson Sampling. In Advances in Neural Information Processing Systems 24, 2011.↩

※AMP表示の場合、数式が正しく表示されません。数式を確認する場合は通常表示版をご覧ください
※2020年11月7日に、「Open Bandit Pipelineの使い方」の節に修正を加えました。修正では、パッケージの更新に伴って、実装例を新たなバージョンに対応させました。詳しくは対応するrelease noteをご確認ください。今後、データセット・パッケージ・論文などの更新情報はGoogle Groupにて随時周知する予定です。こちらも良ければフォローしてみてください。また新たに「国際会議ワークショップでの反応」という章を追記しました。
ZOZO研究所と共同研究をしている東京工業大学の齋藤優太です。普段は、反実仮想機械学習の理論と応用をつなぐような研究をしています。反実仮想機械学習に関しては、拙著のサーベイ記事をご覧ください。
本記事では、機械学習に基づいて作られた意思決定の性能をオフライン評価するためのOff-Policy Evaluation (OPE)を紹介します。またOPEを含めたバンディットにまつわる研究利用のためにZOZO研究所が公開したOpen Bandit Datasetと開発したパッケージOpen Bandit Pipelineの特徴や使い方を解説します。
なお、本記事はこちらのプレスリリースに関連する内容になっています。また本記事の内容は、先日arXivで公開した論文の内容を噛み砕いて日本語で紹介したものになっています。気になる方はぜひ元論文も参照してみてください。さらに、2020年8月27日にオンラインで開催されたCFML勉強会にて本記事の内容に関する発表を行っており、その際の発表資料も公開しています。この発表資料は、本記事の内容を補完するような例を紹介していたりするので、是非合わせてご覧ください。
続きを読む
こんにちは、ZOZOテクノロジーズ CTO室の池田(@ikenyal)です。
ZOZOテクノロジーズでは、6/22にZOZO Technologies Meetup -ZOZOテクノロジーズの大規模データ活用-を開催しました。 zozotech-inc.connpass.com
「ZOZOテクノロジーズの大規模データ活用に興味のある方」を対象としたイベントです。
弊社のエンジニア4名が登壇し、ZOZOテクノロジーズにおける大規模データ活用の事例紹介を行いました。
ZOZOテクノロジーズでは、プロダクト開発以外にも、今回のようなイベントの開催など、外部への発信も積極的に取り組んでいます。
一緒にサービスを作り上げてくれる方はもちろん、エンジニアの技術力向上や外部発信にも興味のある方を募集中です。 ご興味のある方は、以下のリンクからぜひご応募ください!

こんにちは。ZOZO研究所のshikajiroです。主に研究所のバックエンド全般を担当しています。ZOZOでは2019年夏にAI技術を活用した「類似アイテム検索機能」をリリースしました。商品画像に似た別の商品を検索する機能で、 画像検索 と言った方が分かりやすいかもしれません。MLの開発にはChainer, CuPy, TensorFlow, GPU, TPU, Annoy、バックエンドの開発にはGCP, Kubernetes, Docker, Flask, Terraform, Airflowなど様々な技術を活用しています。今回は私が担当した「近似最近傍探索Indexを作るワークフロー」のお話です。
corp.zozo.com

クラウドはGCPを採用しています。分析基盤にBigQueryを使っていること、KubernetesのマネージドサービスであるGKEが安定していること、TPUを活用していることなどが採用の理由です。図の上から簡単に紹介します。
ワークフローであるComposerは毎日販売中のおよそ300万の商品画像から特徴量抽出を行いIndexを作成しています。今回のお話のメインはここですが、もう少し全体像の説明を続けます。
アプリケーションのコードはGitHub, CI/CDはCircleCIで管理しており、モデルはGCSに、アプリケーションはDockerとしてGCRに登録します。デプロイはCircleCIやComposerを使っています。なお、ML部分のCI/CDはまだ完全には実現できてません。
ユーザーが指定した画像から似た商品画像を返すAPIのことを 推論API と呼びます。Kubernetesで構成しており、後で紹介するマイクロサービスが連携して動作しています。
Composerの説明をする前に、特徴量Indexの動きを知るために推論APIの流れを紹介します。API、物体検出、特徴量抽出、近似最近傍探索、それぞれをマイクロサービスとして動かしています。商品情報検索だけはk8s外の外部サービスです。
ユーザーが画像検索に画像を送ると画像の中に写っている服などのアイテムを検出します。これが 物体検出 です。ここでトップスやシューズなどに分類します。判別した画像のままでは計算に適さないので、検出した部位を多次元ベクトルの特徴量に変換します。この特徴量で距離や類似度などの計量を計算できるようにします。具体的には512次元のfloatの配列になります。これが 特徴量抽出 です。過去テックブログでも紹介していますのでぜひご覧ください。techblog.zozo.com
techblog.zozo.com
特徴量から予め準備していたZOZOTOWNの約300万画像のIndexを使って、似ている商品画像を高速に探します。これが 近似最近傍探索 です。近似最近傍探索については東京大学の松井先生の資料が大変分かりやすいので、興味がある方は御覧ください。 speakerdeck.com
近似最近傍探索の段階では似ている商品の画像までしか分かっていません。最新の商品情報を取得するため、ZOZOTOWNの商品データベースに問い合わせてデータの整合性を保ちます。この部分は画像検索とは直接関係ないですが、実際のサービスでは大事な部分ですので紹介しました。
上でも少し触れましたが、ZOZOTOWNが販売する約300万商品画像の中から最も似ている数十〜数百商品を高速に検索する必要があります。特徴量は多次元ベクトルであり対象商品も大量なため、普通に計算するととんでもない計算時間になってしまいます。ここで利用するのが近似最近傍探索です。これを実装した代表的なPythonのライブラリにSpotifyが開発しているAnnoy, Facebookが開発しているFaissなどがあります。画像検索の開発時に主にこの2つを検討し、Annoyを採用しました。理由は以下の2つです。
もっと速度が必要ならばFaissとGPUの組み合わせを検討していましたが、AnnoyとCPUの組み合わせで速度・精度ともに十分だったため、現状はFaissにする予定はありません。
Annoyを使って近似最近傍探索を行うには、予め検索対象である約300万画像の特徴量を抽出して Index を作っておく必要があります。ビルド処理自体は数行のコードで実現できるのですが、画像を準備するのがなかなか大変です。以下の手順で作成しています。
これらをバッチプログラムを書いて実装することも可能ですが、上記それぞれで必要なCPUリソースもバラバラで、特に特徴量抽出は多くの計算資源を必要とします。エラー時のリトライ、Slackなどへの通知、ロギングの仕組みなどを考えるととても2から作るのは大変です。
そこで利用したのがAirflowなどに代表されるワークフローツールです。
上でも触れましたが、バッチ処理を自前で書くとエラー処理、リトライ、ログ、通知処理など実装・運用コストが高いです。この辺りの面倒を見れくれるワークフローツールを検討しました。Airflow, Digdagなどがありますが、GCPのAirflowマネージドサービスであるComposerを採用しました。マネージドサービスだったのが一番の理由です。
AirflowなどのワークフローはDAG(Directed Acyclic Graph, 有向非巡回グラフ)という概念でタスク同士の依存関係を定義しています(詳しくは公式サイトに委ねます)。上記の1〜6の流れを簡潔に書けるようになり、途中からの実行などが容易になります。
ComposerのAirflowバージョンはGCPが管理しているため、最新のAirflowより遅れています。そのため、解決されていないバグや対応していないGKEオペレーションなどがあり、使い勝手・保守性に問題がありました。最近はバージョンでは追従できており、安定して稼働しています。

ざっと流れを紹介します。BigQueryから現在販売中の商品の画像URLをすべてダウンロードし、Filestoreに保存します。実際は前日までの画像がすでに存在するので、前日までの分と本日分の差分だけをダウンロードしています。
準備した画像を元に物体検出、特徴量抽出、近似最近傍探索Indexのビルドを行うのですが、大変重い処理なうえ、GPUも使うのでComposerのインスタンスで実行することはできません。そのため、別途GKEのクラスターを準備し、重い計算部分はそちらで計算しています。トップス、ボトムスなどのカテゴリ単位でPodを並列で動かし高速化しています。それでもまだ300万画像すべてを計算すると全体で24時間以上かかるので、日々改善を行っています。
特徴量は一部キャッシュとして保存しており、推論API側で利用しています。ZOZOTOWNの画像で画像検索する場合はこのキャッシュを流用できるため、推論APIのGPU資源を軽減させています。
ビルドしたIndexはモデルと同じGCSバケットに保存します。推論APIのGKEクラスターに対して近似最近傍探索PodのRollingUpdateを指示し、新しいIndexで動作する近似最近傍探索Podを起動します。ユーザーは更新された事に気が付かないまま、新しい結果を得ることができます。
エラーが起きた場合はSlackに通知しており、開発者がいつでも対応できるようにしています。
ワークフローは日々改善を行っています。リリース後に行った改善を紹介します。
当初、早急にリリースする事を優先しており、ワークフローを簡素化していたため毎日販売中の画像300万画像すべての特徴量を計算しIndexを作成していました。これでは大変時間がかかりコストも高いので「昨日と比較して新しく追加された画像だけ計算する」ように変更しました。コストは大幅に下がり、数時間で計算が終わるようになりました。
開発当初はユーザーが画像をPostして、その画像から似た商品を返却する予定で開発をしていました。ですが、ZOZOTOWNにある商品と似た商品を返却した方が良さそうとのことで、ZOZOTOWNの画像を推論するようになりました。その場合、ZOZOTOWNに既にある商品画像はIndexを作成する際に特徴量抽出を一度行っているため、キャッシュに使えることが分かりRedisを追加しました。これにより、推論APIで物体検出と特徴量抽出を行わなくてもよい状況が増えたので、GPU負荷が大幅に下がりコストが削減できました。
 ※一部簡略化しています。すべてのリクエストでキャッシュを利用してるわけではありません。
※一部簡略化しています。すべてのリクエストでキャッシュを利用してるわけではありません。
現在トップスを始めとした8つのカテゴリに対応しており、日々新たなカテゴリに追加するため物体検出、特徴量抽出のモデルを開発しています。そこで特徴量抽出のモデルを更新する際にいくつかの問題が分かってきました。
ここで、カテゴリ毎に特徴量を抽出するようにモデルを作り変える決断をしました。さらに、学習を高速化をするためTPU x TensorFlowへの変更も行いました。モデルが大きく変わったため特徴量は現版(v1)と新版(v2)でまったく異なります。v2でIndexを1から作り直すのに数日かかり、その間もv1でAPIは稼働し続けないといけないため、v1, v2のIndex作成ワークフローを並列で行う必要があります。今回は推論APIのPod、キャッシュストレージなどをv2用に予め作り、v2のDAGがIndexを作り終わったタイミングで、推論APIのPodの向き先をv2に切り替えるという対応を行いました。
 ※一部簡略化しています。
※一部簡略化しています。
今後も機能追加、精度向上、コスト削減など様々な施策を実施していく予定です。ご期待ください。
みんな大好き失敗談を紹介します。
300万近くの画像はZOZOTOWNの画像サーバーから取得しています。300万画像を1つずつ取得していたら数週間かかるので、CloudFunctionsを使って無尽蔵に並列化して取得しました。案の定、サーバーに負荷をかけて怒られました。今は負荷をかけない程度の並列処理を実行しています。
実装自体は大したことないなと思っても、動作検証に大変時間がかかるため、実装に実質3日、検証に1か月みたいな事が平気で起きたりします。開発を効率化するためのスクリプト作り、安定した基盤づくり、可能な限り高速でタスクが完了するための高速化の工夫などがとても大事になります。
これから解決していかなくてはならない課題たちです。
例えばネットワークなどの都合で「特定のPythonパッケージがダウンロードできない」などが発生するとワークフローが止まってしまい、Indexを構築できません。これはクラウド時代には仕方がない部分ですが、ワークフロー中に外部依存する処理を減らしていく必要があります。
昨日まで動いていたのに動かなくなることが当たり前のようにあります。自分たちのコードのバグ、Airflowのバグ、商品画像数が増えたことでタイムアウトが発生した、依存している外部サービスに変更があった、など様々な要因があります。いつでも柔軟に対応できるよう、日々改善していくことが大事です。
現在Kubeflowを検証中で、モデルの精度が上がったら自動でデプロイされるような仕組みを検討しています。
当初ワークフローの開発はそこまで大したこと無いだろうと考えていたのですが、API開発の10倍(個人の感想)くらい困難なものでした。これから新たに機械学習プロジェクトでワークフローを作る方は開発の初期段階からざっくり作り始めることをおすすめします。
私が携わった次期プロジェクトではこの知見が活き、迅速に開発・リリースができました。 lab.wear.jp
このワークフローは一人で作ったわけではありません。研究所の研究者、開発者、特にMLOpsチームの協力があり安定したワークフローに成熟していきました。今後もZOZOテクノロジーズのメンバーで様々なサービスを提供していきますので、今後とも宜しくお願いします。
techblog.yahoo.co.jp techblog.zozo.com
ZOZOテクノロジーズでは福岡研究所のMLエンジニア、バックエンドエンジニア、MLOpsチーム(東京)のメンバーを募集しております。 https://hrmos.co/pages/zozo/jobs/0000029hrmos.co hrmos.co hrmos.co
 (引用:
(引用: