



はじめに
こんにちは、SRE部MLOpsチームの児玉(@dama_yu)です。この記事では、ZOZOTOWNのおすすめ順を支える検索パーソナライズ基盤について紹介します。
ZOZOTOWNのおすすめ順について
ZOZOTOWNにおいて検索機能は非常に重要な機能の1つで、売上のうち多くの割合が検索経由です。ZOZOTOWNでは、検索結果の並び順として、おすすめ順、人気順、新着順など複数あり、現在おすすめ順がデフォルトになっています。
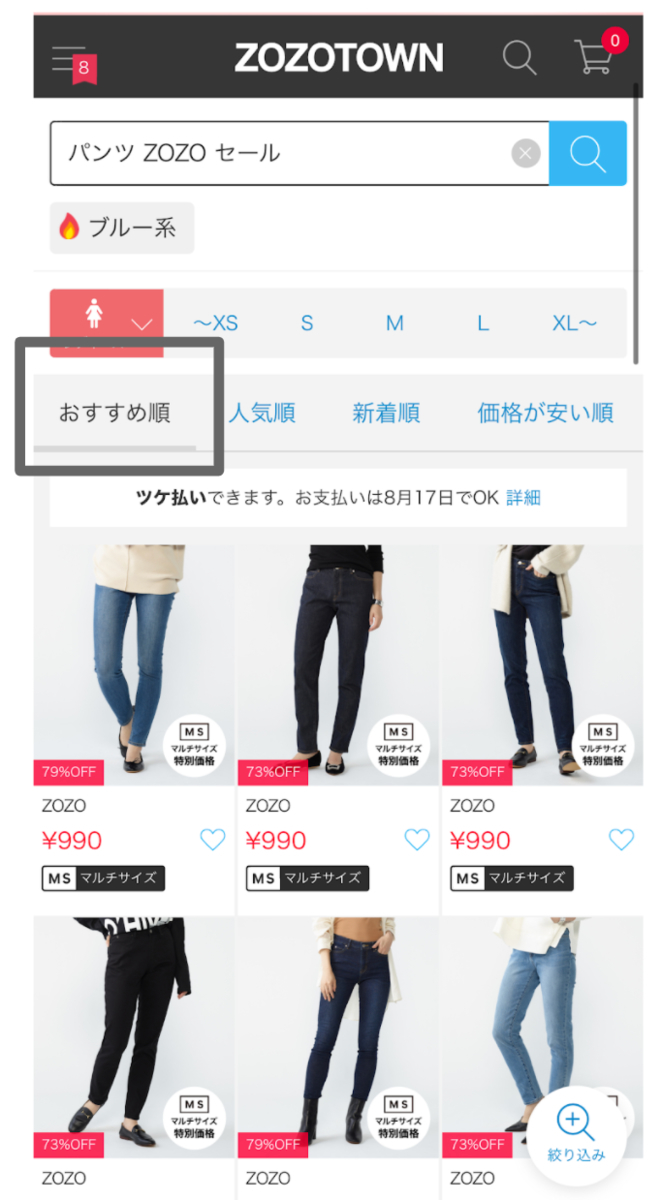
元々は人気順がデフォルトだったのですが、ユーザの嗜好に合わない商品まで検索結果に並んでしまうという課題がありました。そこで、この課題へのアプローチとしてユーザの行動履歴や属性を元にパーソナライズされた順番で検索結果を並べた、おすすめ順を新規追加することになりました。
この施策の結果、検索結果経由の商品CTRが向上しました。ユーザが求めている商品が並ぶようになったのではないかと考えています。
この記事では、この施策で構築されたおすすめ順のための検索パーソナライズ基盤のアーキテクチャや設計上のポイントについて、説明していきます。
検索パーソナライズ基盤のアーキテクチャ
この章では、検索パーソナライズ基盤の全体感を見た後に、API・インデクシング基盤についてそれぞれアーキテクチャの詳細、設計段階での検証ポイントを説明します。
アーキテクチャ概観
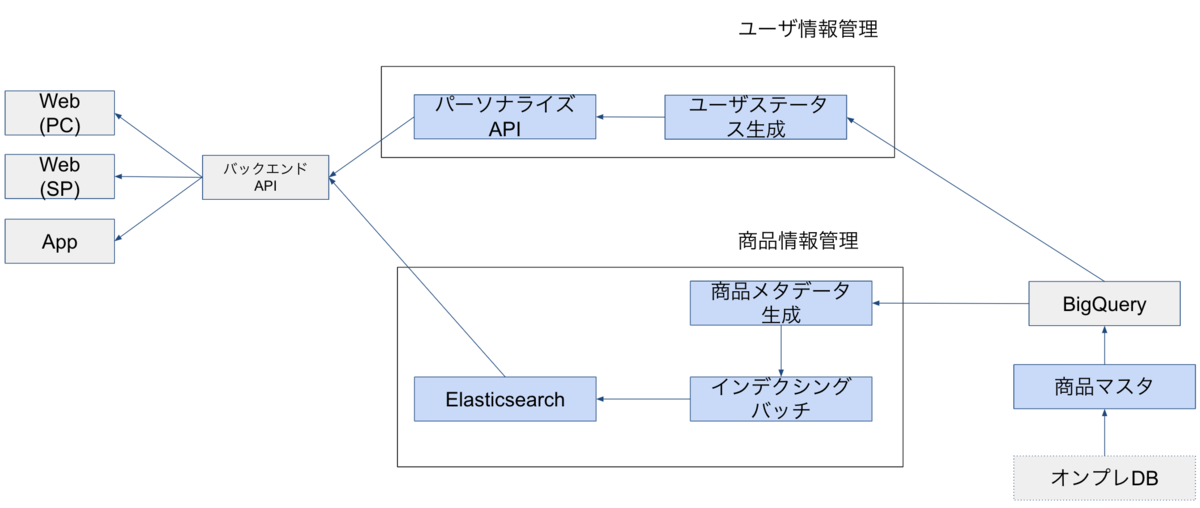
検索パーソナライズAPIはマイクロサービスとして構築されており、ZOZOTOWNのバックエンドAPIから参照される構成になっています。
パーソナライズAPIはユーザ情報を元に、Elasticsearchのクエリ構築に必要なパラメータを生成します。そのパラメータを使用して構築したクエリを元に、ZOZOTOWNのバックエンドAPIがElasticsearchにアクセスします。
Elasticsearchにはインデクシングバッチで商品情報を登録しています。
アーキテクチャ詳細(API)
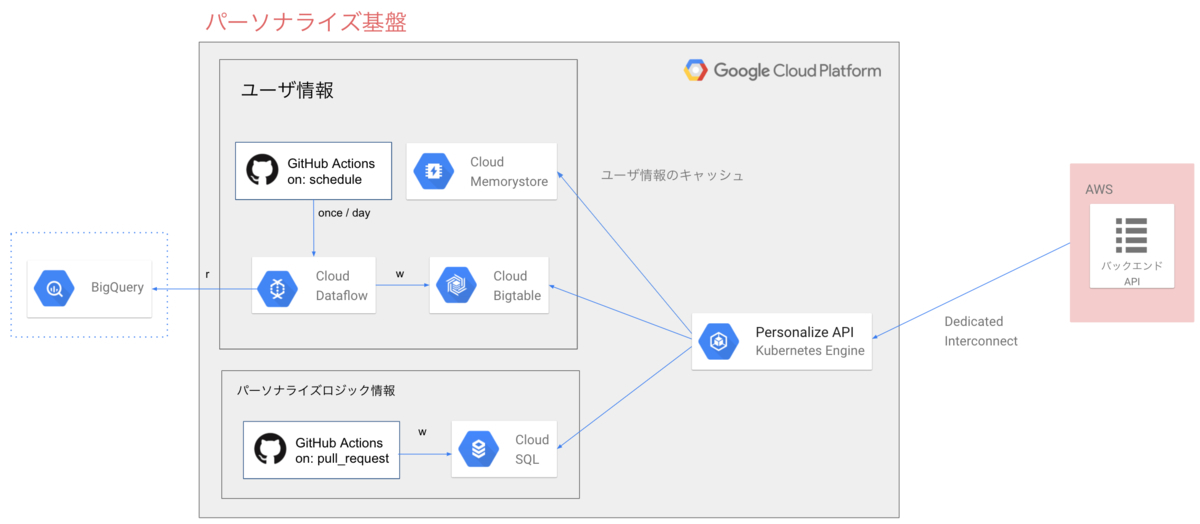
ここでは、APIのアーキテクチャについて説明します。
先ほどの説明では省略していましたが、ZOZOTOWNのバックエンドAPIはAWS上に、検索パーソナライズAPIはGCP上にそれぞれ構築されています。このAWS-GCP間のレイテンシを軽減するためAWSは Direct Connect、GCPは Dedicated Interconnect という専用線サービスを利用してオンプレ経由でアクセスするようにしています。パーソナライズロジック内で参照する必要のあるユーザ情報(年齢や性別、お気に入りに追加したショップやブランドなど)については、1日1回の頻度でDataflowを用いてBigQueryからCloud Bigtableに書き込んでいます。BigQueryにデータを連携している基盤についての詳細は、以前 ZOZOTOWNを支えるリアルタイムデータ連携基盤 というタイトルで紹介しているので参照してみてください。 techblog.zozo.com
パーソナライズAPIはユーザIDをキーにして、パーソナライズロジックに必要な変数の値と係数の組み合わせのリストをJSONのレスポンスとして返します。そのパラメータと検索ワードを使用して構築したクエリを元に、ZOZOTOWNのバックエンドAPIがElasticsearchにアクセスします。パーソナライズAPIはリクエストが来たタイミングでキャッシュされていない場合、Cloud Bigtableに保存されているユーザ情報はMemorystoreにキャッシュされることで、APIのレスポンスを高速化しています。
アーキテクチャ詳細(商品情報インデクシング)
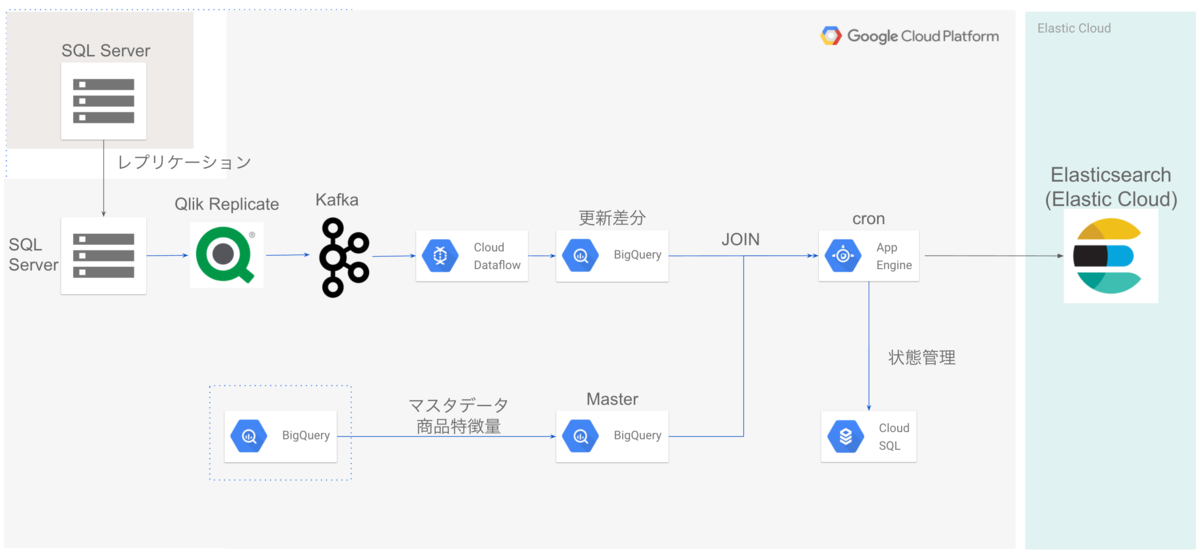
次に、商品情報のインデクシングについて説明します。
ZOZOTOWNの商品情報を保存しているSQL Serverのレプリケーションから、Qlik Replicate を用いて、Kafka(マネージドサービスとしてConfluentを使用)-> Dataflow経由で、BigQueryに商品情報の更新差分を保存しています。その更新差分とBigQueryの商品情報のマスタデータをJOINし、App Engine上に構築したバッチで1日1回、Elasticsearchに商品情報インデックスを作成しています。
アーキテクチャ設計の検証
検索パーソナライズ基盤のアーキテクチャ検討段階において、最初の設計からいくつか変更した点がありました。ここでは、API基盤、ユーザ情報更新バッチ、商品情報インデックス作成バッチ、それぞれについて設計の変更点を説明します。
API基盤
今回、AWSから専用線経由でアクセスするため、内部IPでサービスを提供する必要性がありました。
そのため、外部IPしか利用できないGAE(Google App Engine)はNGとなり、GKE(Google Kubernetes Engine)またはCloud Runが候補として上がりました。GCPのフルマネージドなサーバレスコンテナプラットフォーム、Cloud Runは弊チームでまだ採用事例がなく、実際に構築して検証を行いました。
検証の結果、Cloud Runは以下のような挙動をすることがわかりました。
- リクエストが来た時に始めてコンテナが起動し、何リクエストか捌くと停止する
- Javaコンテナ(主にJVM)の起動が遅く、我々の場合20秒以上かかる
- 結果として、初回もしくは複数リクエストのうち1回の、コンテナが起動するタイミングでユーザにレスポンスを返すまで20秒以上かかってしまう
これにより、今回はCloud Runの採用は止め、GKEを使用することにしました。
なお、現在ではこの「Cold Start問題」は解消しているようです。
ユーザ情報更新バッチの定期実行
当初Dataflowで構築したユーザ情報更新バッチはCloud Scheduler + Cloud Functionsで定期実行をする予定でしたが、プロジェクトのCI/CDで用いていた、GitHub Actionsでの定期実行に切り替えました。
GitHub Actionsのon schedule機能を用いることで、シンプルなyamlファイル定義のみで定期実行の設定が可能になりました。
Elasticsearchインデックス作成バッチ
元々、Elasticsaerchのインデックス作成バッチは、以下の理由でDataflowを採用する予定でした。
- GCPのサービスでBigQuery -> ElasticsearchのETLを楽に開発したい
- 運用の手軽なサーバレスが良い
しかしDataflowのApache Beamが設計当時Elasticsearch 7系のVersionに対応していなかったので、代わりに、GAE上で、インデックス作成のためのバッチを動かしています。2020年10月現在では、Apache BeamのElasticsearch IOはElasticsearch 7系をサポートしていますが、Elasticsearch 8系が使えるようになった場合でも再度同じ状況になることが考えられます。クライアントライブラリの制約で使えなくなる基盤よりは、自由にライブラリをインストールできるGAEのほうが、今後も柔軟性が高く優位性があると判断しました。
なお、現在ではβではありますが、DataflowでもDockerfileを指定できるようになったとのことなので、この制約は弱まった可能性があります。次の案件では、そちらも使えないか検討してみたいと考えています。
GAEについては、メモリ制限の都合でStandard Environmentではなく、Flexible Environmentを採用しました。
Elastic Cloudについて
弊社では、Elasticsearchのマネージドサービスとして、Elastic社が提供するElastic Cloudを用いています。マネージドサービスなので運用の負担が小さい、かつElastic社の公式サポートが利用できるという理由でElastic Cloudを選定しました。ここでは、Elastic Cloudの監視・運用方法について紹介します。
Elastic Cloudの監視
Elastic Cloudの監視には、Datadog(dashboard, montior)を使用しています。Datadogの設定は、Terraformを使ってIaC化しています。メトリクスは、Datadog Agentから送ることができないものについては、GKE上に構築したCronJobバッチで定期的にメトリクス送信を行っています。
Datadog Dashboardは各メトリクスの状況を一覧で見るのに使用しています。主に、query/secやCPU使用率を見ることが多いです。
Datadog monitorは、しきい値アラートの設定に使用します。
Elsatic Cloudの運用について
運用上の作業で最も多いのは、ElasticsearchのNode数変更です。セールなどのキャンペーンごとに、過去の負荷傾向からNode数を見積もっています。基本的にはキャンペーン前日までに運用担当がNode数変更を行います。
当初は手動で、Elastic Cloudコンソールからノード数を変更していたのですが、現在はecctlというCLIツールがElastic社から公開されており、GitHub Actionsを用いたCI/CDでノード数を変更できる仕組みを構築しています。
つい先日Elastic Cloudのterraform-providerが公開されたので、そちらも使えないかまた検討してみたいと考えています。
さいごに
今回は、ZOZOTOWNおすすめ順のための検索パーソナライズ基盤について紹介しました。おすすめ順はロジック面・システム面どちらもまだまだ改善の余地が残されていて事業インパクトも大きいため、重要度の高いプロジェクトの1つとして、引き続き絶賛改善中です。
SRE部MLOpsチームでは、データや機械学習を用いてサービスを成長させたいエンジニアを募集しています。ご興味のある方は、以下のリンクからぜひご応募ください!