



はじめに
ZOZO研究所ディレクターの松谷です。
ZOZO研究所では、イェール大学の成田悠輔氏、東京工業大学の齋藤優太氏らとの共同プロジェクトとして機械学習に基づいて作られた意思決定の性能をオフライン評価するためのOff-Policy Evaluation(OPE)に関する共同研究とバンディットアルゴリズムの社会実装に取り組んでいます(共同研究に関するプレスリリース)。また取り組みの一環としてOPEの研究に適した大規模データセット(Open Bandit Dataset)とOSS(Open Bandit Pipeline)を公開しています。これらのオープンリソースの詳細は、こちらのブログ記事にまとめています。
本記事では、ZOZO研究所で社会実装を行ったバンディットアルゴリズムを活用した推薦システムの構成について解説します。バンディットアルゴリズムを用いた推薦システムの構成と実際にどのように活用されたかについて、また公開されたデータセットがどのようなシステムで収集されたか、みなさまの参考になれば幸いです。
本システムの設計・開発と本記事のシステム概要解説については研究所アドバイザーの粟飯原が担当しています。
バンディットアルゴリズムとは
まず本プロジェクトのフォーカスであるバンディットアルゴリズムについて解説します。
アルゴリズムについて
環境に対する不完全な事前知識を活用して行動し、環境を観測してデータを集めながら最適な行動を発見する(探索と活用)アルゴリズムがバンディットアルゴリズムです。システム自身が試行錯誤しながら最適なシステム制御を実現する機械学習手法である強化学習の中で、代表的なアルゴリズムのひとつです。
バンディットアルゴリズムが扱う問題設定は「複数の選択肢または介入からできるだけ良いものを選択したい」というものです。例えば、推薦する商品Aと商品Bのどちらがより顧客にクリックされるか、新薬Aと新薬Bのどちらがある病気を効果的に治癒するのかというような状況です。この問題の難しさは、良い選択肢をできるだけ多く選択したいという活用と、とるべき選択肢が何であるかをできるだけ正確に知りたいという探索のトレードオフがあることによります。
このような状況で選択するためによく用いられるのは、A/Bテストと呼ばれる手法です。AとBの2つの介入をランダムに割り当ててどちらが平均的に優れているのかを統計的仮説検定に基づいて選択します。しかし典型的なA/Bテストでは純粋な探索を一定期間行ってから純粋な活用を行うため、無駄な探索をしてしまったり誤った活用をしてしまうリスクがあります。
バンディットアルゴリズムは過去の経験に基づく予測の活用と探索のトレードオフをデータから最適化し、累積報酬(例えばクリック数)を最大化するように意思決定を行います。
Web広告配信や推薦システムでよく利用されており、またトップ棋士に勝ち越したことで有名なAlphaGo(アルファ碁)にもその技術が応用されています。
Multi-Armed Bandit Algorithm
強化学習において状態が変化しない最も単純な設定です。アーム(選択肢)を引くとスロットマシンがある確率に基づいて報酬が得られるという設定のもと、行動の主体であるエージェントは腕を引くという行動だけ行います。これは、例えば商品アイテムの推薦においては実際に推薦結果として提示する商品アイテムの選択になります。
Contextual Bandit Algorithm
バンディットアルゴリズムは拡張によりユーザーの属性に合わせパーソナライズを扱うことが可能です。ユーザー属性/履歴などの埋め込みベクトルを用い、ユーザーそれぞれに最適な行動(何を表示するか)を決定します。どのようにパーソナライズするかは、コンテキストの設計により調整が可能です。実際の応用としては、Spotifyホーム画面のパーソナライズやNetflixのアートワークパーソナライズなど、推薦に力を入れているサービスにおいて利用されている例が挙げられます。
ユースケース
例1)良いクリエイティブの選択
バンディットアルゴリズムは複数ある商品画像のうちどのクリエイティブを表示するかなどにも利用されています。よりクリックされやすいクリエィティブに自動で寄せるなど、無駄なインプレッションを減らしつつKPIの向上を目指すことが可能です。
例2)良い推薦アイテムの選択
バンディットアルゴリズムはEコマースなどの推薦において、対象アイテムを絞り込んだ後のリランキングなどに使用されることもあります。通常のランキング集計よりも新しいアイテムなどの追加にも早く対応でき、機会損失を減らしつつコンバージョンなどKPIの改善を目指すことが可能となります。
ZOZOTOWNにおけるバンディットアルゴリズムを用いた推薦
ZOZO研究所では、多腕バンディットアルゴリズム(Multi-Armed Bandit Algorithm)を用い、数あるファッションアイテムの中からユーザーごとに適したアイテムを推薦するシステムを開発し、ZOZOTOWNのトップページにおいて実際に配信を実施しました。
トップページ来訪ユーザーに対してRandomまたはBernoulli Thompson Sampling(BernoulliTS)という2種類の意思決定policyを振り分けて適用しています。
ユーザーの属性に合わせた商品の推薦
コンテキストを合わせて選択するように拡張することで(Contextual Bandit Algorithm)、ユーザーの属性に合わせた商品のパーソナライズ推薦も可能です。ZOZOTOWNではユーザーひとりひとりに、より価値のあるサイト上での発見・経験を提供するべく、推薦や検索結果のパーソナライズをすすめています。本プロジェクトの理論部分の成果でもあるオフライン評価の手法(OPE)を用いることで、どのような特徴量を利用すればよいのか効率的に提案することが可能となります。ZOZO研究所では開発したパイプラインを用いて、効率よくどのようなパーソナライズを実際のサービスで用いるべきかを評価・比較して提案につなげています。
本共同研究プロジェクトの取り組み
ZOZO研究所では、機械学習による予測値などに基づいて作られる意思決定policyの性能を評価する手法であるOPEに関しての研究を進めています。
機械学習は予測のための技術として広く利用されていますが、実際の応用場面に目を向けてみると、予測値をそのまま使うのではなく予測値に基づいて何かしらの意思決定を行うことが目的である場合が多くあります。
例えばクリック率の予測値に基づいてユーザーごとにどのアイテムを推薦すべきか選択する場合、予測そのものよりも、それに基づいて作られる推薦や広告配信などの意思決定が重要です。従って、評価自体もクリック率の予測精度よりも最終的な意思決定policy自体の性能を直接評価する方か適切と言えます。
意思決定policyの性能評価において、実際にサービスへ実装しKPIの挙動を確認するオンライン実験には大きな実装コストやユーザー体験の毀損・KPIへのマイナス影響など大きなリスクを伴うため、オフラインで同様に性能を評価する手法が模索されてきました。
この、新たな意思決定policyの性能を過去の蓄積データを用いて推定する問題のことをOPEと呼びます。
NetflixやSpotify、Criteoなどの研究所がこぞってトップ国際会議でOPEに関する論文を発表しており、特にテック企業から大きな注目を集めています。
正確なOPEは多くの実務的メリットをもたらします。例えば現行の推薦ロジックとは異なる新たな推薦ロジック候補がもたらすKPIの値を既にあるデータを用いて見積もることができます。ハイパーパラメータや機械学習アルゴリズムの組み合わせを変えることによって多数生成される候補のうち、どれをオンライン実験に回すべきなのかを事前に絞り込むこともできます。これにより、実装コストやリスクを抑えつつ、より効率的なビジネス・サービス改善が可能となります。
本共同研究プロジェクトではOPEの実証研究と実サービスへの組み込みを目的とし、バンディットアルゴリズムをZOZOTOWNにおけるファッションアイテム推薦枠に実装しました。これにより、A/Bテストを必要としない低コストな継続的サービス改善のための評価フレームワーク構築を目指しています。
次の章では、そのバンディットシステムの構成について解説します。
バンディットシステムの構成
本プロジェクトの理論的な新規性とデータ・評価パイプライン公開についての詳しい解説はこちらの記事に任せるとして、本研究を進めるにあたりZOZO研究所で開発を進めてきた配信とログ集計基盤について解説します。
本記事で解説するシステムの導入により、ZOZOTOWN上で実際のサービスを改善しつつオフライン評価手法の構築を進めることが可能となりました。
早速本システムの構成の概観から説明します。
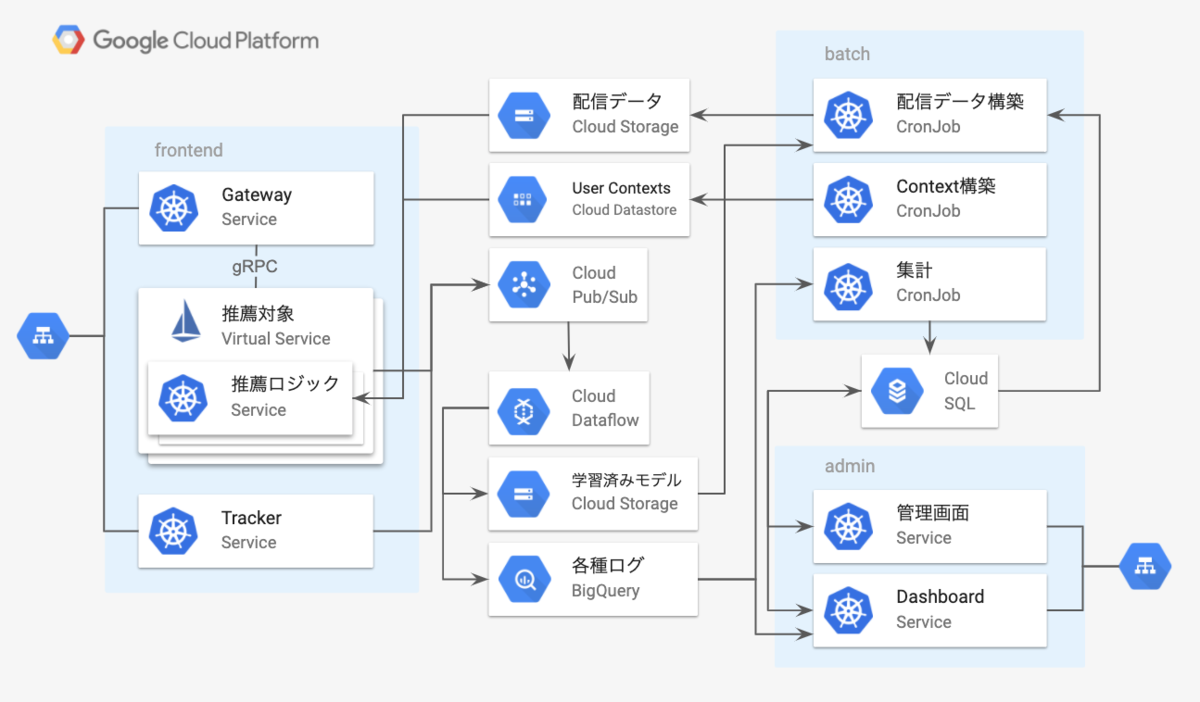
インフラとしてGCPを利用しており、配信・ログ収集・バッチ系などはGKE上で動かしています。
内部の通信にはgRPCを用いており、gRPCのロードバランシングや振り分け制御を行うためにIstioを有効にしています。
ユーザーの画面に推薦対象が表示された場合や、クリックした場合、購買があった場合などはトラッキングサーバーにイベントログを送るようにしており、それらの情報を元に配信パラメータを更新します。現状JavaScriptの表示・イベント送信のSDKを用意しており、Web面への配信をしています。ログ周りはBigQueryに保存して、Contextual Banditのパラメータの学習を行うストリーミング処理系としてCloud Dataflowを使っています。
以下それぞれのコンポーネント毎に簡単に説明していきます。
Gatewayサーバー
アプリやブラウザなどのクライアントからのHTTPリクエストを受け取とって、gRPCを喋る推薦サーバーにリクエストをプロキシするサーバーです。Istio Ingress GatewayによるgRPC<->httpブリッジの利用も考えましたが、GKE Ingressの裏にGoで書いたGatewayサーバーをおいています。配信対象やA/Bテスト時の振り分けなどを全てIstioの機能で実現できるような構成も可能であったと考えていますが、以下の2つの理由で独自のGatewayを用意することにしました。
- GKE IngressにTLS終端を任せられる
- 振り分けの条件などを柔軟に構成できる
Gatewayサーバー側では、リクエストを元にA/Bテストの振り分けのフラグに用いるヘッダ(Request metadata)を付与して推薦サーバーにリクエストを送るようにしています。
推薦サーバー
推薦サーバーは、GCS上に配置された配信データ(配信対象・配信アルゴリズム・コンテキスト情報・配信パラメータの組)のパスを環境変数で指定してデプロイされます。定期的にファイルの更新をチェックしては配信データに更新があるとデータの取得を行って内部のデータを更新しています。推薦サーバーはGoで実装されており、計算部分はOpenBLASをBLASバックエンドにしたgonumを用いています。そして、ユーザーのコンテキスト情報はCloud Datastoreに配置してgRPCリクエスト毎に取得しています。
推薦サーバーは、それぞれ配信データ毎にgRPCサーバーとしてDeploymentを作成しています。その上で同一の配信対象のDeploymentはIstioのVirtual Serivceとして1つにまとめて、A/Bテストなどが行えるようになっています。Virual ServiceのHttpMatchRequestを用いてどのDeploymentにリクエストを送るかの振り分けを行っています。
上記の設定を行った配信対象毎のVirtual Serviceのイメージは以下のようなものになります。
apiVersion: v1 kind: Service metadata: name: DELIVERYTYPE namespace: bandit-api labels: app: DELIVERYTYPE spec: ports: - port: 3000 targetPort: 3000 protocol: TCP name: grpc-DELIVERYTYPE selector: app: DELIVERYTYPE --- apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: DELIVERYTYPE namespace: bandit-api spec: host: DELIVERYTYPE trafficPolicy: loadBalancer: simple: RANDOM subsets: - name: contexuala labels: deliveryname: contexuala - name: contextualb labels: deliveryname: contexuala - name: random labels: deliveryname: random --- apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: DELIVERYTYPE namespace: bandit-api spec: hosts: - "msp" http: - match: - headers: some-header: exact: X route: - destination: host: DELIVERYTYPE subset: random - match: - headers: some-header: exact: Y route: - destination: host: DELIVERYTYPE subset: contexualb - match: route: - destination: host: DELIVERYTYPE subset: contexuala
DestinationRuleにはsubsets以下に配信を振り分けるDeploymentの名前をdeliverynameに列挙します。
VirtualServiceのHttpMatchRequestルールに、Gatewayサーバが付与するA/Bテスト用のヘッダの条件を記載します。条件にマッチしたリクエストが設定されたsubsetと対応するDeploymentにルーティングされます。
このようにIstioの機能を利用することでリクエストの振り分けが実現でき、推薦サーバーのコードを変更することなく複数のA/Bテストを実施することが可能になります。
トラッキングサーバー
推薦サーバーが返却したアイテム毎にユニークなID(以下、配信ID)を付与しており、それに紐づく形で以下のような詳細情報を記録しています。以下の項目は一部の項目例です。
- 配信対象
- 配信名
- 配信データのバージョン(配信時に使用したパラメータなどは全てGCS上にバージョニングして保存している)
- 配信アイテムのID
- 予測したclick確率
- 表示あたりの予測収益
- アイテムに関するメタデータ
- 予測時に用いたユーザーのコンテキスト情報
このIDはimpression・click・conversion・その他の関連するユーザの行動がある度にトラッキングサーバーへ送信されます。送信された配信IDを元に、紐付けて記録されている詳細情報と合わせてCloud Pub/Subへ送信されCloud Dataflowを介してBigQuery上に記録されます。
集計・配信データ構築
BigQueryからの集計や、配信データの構築はk8sのCronJobとして実行しています。コンテキストの情報を用いない通常のバンディットにおいては、CTRやCVRなどの計算はBigQueryのログを定期的に集計してパラメータを更新しています。
Contextual Banditの学習をCloud DataflowのStreaming処理でどのように行っているのかについては、次の章で細かく解説します。
Dataflowを用いたContextual Banditパラメータの学習
Contextual Banditの学習はログの突き合わせが必要になるので、ログを一度DWHに保存した後で定時バッチにて実行されることが多いと思われます。tracker上でのオンライン学習も考えられますが、clickがなかったimpressionログをどう扱うのかや、複数台で学習したパラメータの混合など考慮しないといけないことが出てきます。
そこで本システムではStreaming処理系を用いて学習モデルパラメータの更新間隔を早められるのではと考え、Cloud Dataflowを用いた半オンラインでの学習を試みました。
CTRの予測をLogistic Thompson Samplingで行うため、Cloud Dataflowを用いて文献1にあるラプラス近似を用いたBayesian Logistic Regressionモデルを学習します。
同様の枠組みでCVRの予測なども可能ではありますが、CVは遅れて来ることも多いためストリーミングでの学習は現状CTRのみ行っています。
シリアライズされたcontextの情報を含むimpressionとclickのログをtrackerからCloud Pub/Subへ書き込み、それをDatadlowで読み込む構成になっています。
Streamingの全体の流れとしては以下のようになります。
- 配信ID(以下コードではBidId)をキーにSession Windowを掛けてGroup Byしてまとめる
- clickのみのログ(セッションの時間内にclickが届かなかった物)をフィルタリング
- まとめたclickありなしのログを更に配信アイテムのIDと配信モデル名のtupleをキーにSession Windowを掛けて更新に十分なログが到達するまで保持
- 配信アイテムのIDと配信モデル名でセッションにまとめたログの中で、ログが含まれない空のセッションを除去
- シリアライズされたコンテキストの情報をデシリアライズ
- MiniBatchでセッション内のログを用いてパラメータを更新して保存
以下のコードのように上記の処理をpipelineとしてつなげています。
def run(argv): mbu_options = MiniBatchUpdateOption(argv, streaming=True, save_main_session=True) logging.getLogger().setLevel(mbu_options.log_level.get()) with beam.Pipeline(options=mbu_options) as pipeline: log = pipeline | 'Read log' >> ReadPubSubAndUnmarshalJson(mbu_options.log_subscription) (log | 'GroupBy ID' >> GroupByBidID(mbu_options.session_gap) | 'Filter invalid value' >> beam.Filter(filter_invalid_value) | 'GroupBy item and model' >> GroupByItemAndModel(mbu_options.wait_count, mbu_options.wait_process_time) | 'Filter zero window' >> beam.Filter(filter_zero_window) | 'Deserialize context' >> beam.ParDo(ContextDeserializer()) | 'Mini batch update' >> beam.ParDo( MiniBatchUpdater(mbu_options.output_path, mbu_options.batch_size)))
MiniBatchUpdaterの中で、GCS上に保存されている前回までの学習結果の取得と、出力されたWindow分のデータの更新とGCSへの保存を行っています。MiniBatchUpdaterの詳細は割愛しますが、以下で、半オンラインでの学習の肝となるSession Windowをどのように適用しているか解説します。
GroupByBidID
一定時間内に到達した同一配信IDのimpressionログとclickログをSession Windowを用いてまとめます。
以下のPythonコードはclickとimpressionをSession Windowを用いてまとめるためのTransformのコードです。同一Window内にimpressionとclickのログがある物を「clickあり」、impressionのみの物を「clickなし」として扱います。clickのみのログは後段の処理で取り除いています。DataflowのSession Windowでは、同一キーのログがギャップ期間以内に到達した場合、同じセッションとしてまとめられます。
以下のコードではsession_gapという形でギャップ時間を渡しています。
class GroupByBidID(beam.PTransform): def __init__(self, session_gap): beam.PTransform.__init__(self) self._session_gap = session_gap.get() self._mandatory_fields = (BID_ID,) def add_timestamp(self, value): """ Add timestamp in order to groupby bid id using session window. """ return beam.window.TimestampedValue(value, datetime.timestamp(datetime.now())) def filter_invalid_value(self, value): return all(field in value for field in self._mandatory_fields) def expand(self, pcoll): return (pcoll | 'Filter invalid value' >> beam.Filter(self.filter_invalid_value) | 'Add key' >> beam.Map(lambda elem: (elem[BID_ID], elem)) | 'Session window' >> beam.WindowInto( window.Sessions(self._session_gap), accumulation_mode=AccumulationMode.DISCARDING) | 'Groupby bid id' >> beam.GroupByKey())
impressionとclickの突き合わせにSession Windowを用いていることから実際のCTRよりは少なく見積もられてしまうことになります。現状はimpressionとclickの突き合わせのギャップ時間は10分とっており、本システムの1日分のログから計算したところ98%は突き合わせができているようです。
GroupByItemAndModel
学習済みのパラメータ自体はメモリ上に保持しているわけではなくGCS上に保存しています。1ログ毎にパラメータの取得と保存を行うのは効率が悪いため、一定量のログが溜まった後、GCSから取得して学習を行います。impressionのログとclickのログをSession Windowでまとめた後は配信アイテムID・配信種別・配信名毎にグルーピングを行います。その後、再度Session Windowを適用して、指定したサイズ以上のチャンクにまとめます。
clickとimpressionがまとめられた後は、腕毎に目的とするbatch size分のログが貯まるまで、再度Session Windowに掛けられます。流量が少なく、指定したサイズ分溜まるまで非常に時間がかかる場合もあり得えます。以下のコードのようにtriggerの設定で、AfterAnyを利用して複数のトリガーを設定して、一定期間内にデータがたまらなかった場合も後段へ流すようにしています。
class GroupByItemAndModel(beam.PTransform): def __init__(self, wait_count, wait_process_time): beam.PTransform.__init__(self) self._wait_count = wait_count.get() self._wait_process_time = wait_process_time.get() self._mandatory_fields = (ITEM_ID, MODEL_NAME, TARGET, CONTEXT, ACTION) def map_item_model(self, value): key = (value[1][0][ITEM_ID], value[1][0][MODEL_NAME], value[1][0][TARGET]) action_list = [v[ACTION] for v in value[1] if ACTION in v] # CASE both imp and click exist: 1 # CASE otherwise: -1 # logging.info(action_list) feature = 1 if IMP in action_list and CLICK in action_list else -1 return (key, [feature, value[1][0][CONTEXT]]) def filter_invalid_value(self, value): for val in value[1]: if not all(field in val for field in self._mandatory_fields): return False return True def expand(self, pcoll): return (pcoll | 'Filter invalid value' >> beam.Filter(self.filter_invalid_value) | 'Map item id and model' >> beam.Map(self.map_item_model) | 'Window into' >> beam.WindowInto( window.Sessions(self._wait_process_time*60), trigger=Repeatedly(AfterAny(AfterWatermark(), AfterCount(self._wait_count))), accumulation_mode=AccumulationMode.DISCARDING) | 'Groupby item id and model' >> beam.GroupByKey())
triggerとしてAfterCountを利用した場合、指定した数ちょうどのチャンクが出力されるわけではなくそれをオーバーしたものが来る点に注意が必要です。
終わりに
本プロジェクトに関する公開データセットとOSSについて
本記事で紹介したバンディットアルゴリズムのシステムを実装した際に収集したデータを、先日Open Bandit Datasetとして一般公開しました。この公開データは合計2600万以上のログを含む大規模なものであり、それぞれのデータは特徴量・方策によって選択されたファッションアイテム・過去の方策による行動選択確率・クリック有無ラベルによって構成されます。これらの特徴により、OPEの正確さを現実的かつ再現可能な方法で評価でき、非常に学術的な価値の高いデータとなっています。
また開発したオフライン評価フレームワークOpen Bandit PipelineをOSSとして併せて公開しています。このパイプラインにより、研究者はOPEの部分の実装に集中して他の手法との性能比較を行うことができるようになります。
公開データセットとパイプラインに関して、詳しくはこちらのブログ記事をご覧ください。
解説記事・寄稿・学術論文
本取り組みに関連して、以下の雑誌に寄稿しています。
また、オープンリソースの特徴やその活用方法などを以下の学術論文としてまとめ、公開しています。
公開データセットに関する詳細な記述など、ご興味ある方はぜひチェックしてみてください。
国内外での研究発表
本取り組みに関する研究成果を、トップ国際会議のワークショップを含む国内外の多くの場で発表しています。上に併せまして、ご興味ある方はぜひチェックしてみてください。
- ICML 2020 Workshop on Real World Experiment Design and Active Learning (RealML2020)
- RecSys 2020 Workshop on Bandit and Reinforcement Learning from User Interactions (REVEAL2020)
- NeurIPS 2020 Workshop on Offline Reinforcement Learning
NeurIPS 2020 Workshop on Consequential Decision Making in Dynamic Environments
- IBIS2020
- 第五回統計・機械学習シンポジウム 招待講演
メディア
本取り組みに関する成果を以下のメディアなどに取り上げていただきました(抜粋)。
ZOZOテクノロジーズでは一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
-
Chapelle, Olivier and Li, Lihong. An Empirical Evaluation of Thompson Sampling. In Advances in Neural Information Processing Systems 24, 2011.↩