




はじめに
こんにちは、推薦基盤部の与謝です。ECサイトにおけるユーザの購買率向上を目指し、レコメンデーションエンジンを研究・開発しています。最近ではディープラーニングが様々な分野で飛躍的な成果を収め始めています。そのため、レコメンデーション分野でも研究が進み、精度向上に貢献し始めています。本記事では、ディープニューラルネットワーク時代のレコメンド技術について紹介します。
目次
- はじめに
- 目次
- パーソナライズレコメンドとは
- 深層学習より前の推薦手法
- 深層学習を使った推薦手法
- General Recommendationに分類されるアルゴリズム
- Graph Recommendationに分類されるアルゴリズム
- Knowledge Aware Recommendationに分類されるアルゴリズム
- Sequential Recommendationに分類されるアルゴリズム
- 深層学習×推薦のまとめ
- 短いライフサイクルで推薦を可能にするための計算時間を短縮する工夫
- 最後に
パーソナライズレコメンドとは
レコメンドエンジンとは、ECサイトやWebサイト上で、ユーザにおすすめの商品やコンテンツを表示するためのシステムです。
「新着順」や「人気順」などの汎化されたレコメンドもありますが、個々のユーザにパーソナライズすることによって、閲覧や購買を促進します。ユーザの閲覧履歴や購入履歴などから関連性のある商品やコンテンツ情報を表示させることで、サイト運営側は売り上げや閲覧数を増加させ、ユーザはより自分の気にいる商品やコンテンツを発見しやすくなります。
次章以降、このパーソナライズレコメンドについて掘り下げていきます。
深層学習より前の推薦手法
まずは深層学習より前のレコメンデーションをいくつか見ていきましょう。
協調フィルタリング
Aという商品を閲覧・購入した人はBという商品も閲覧・購入した人が多いため、Aという商品を閲覧・購入した人にはBという商品を薦める。といったように、協調フィルタリングはWebのアクセス履歴やユーザの行動履歴に基づいて商品をレコメンドする手法です。この手法は、商品情報などのコンテンツ情報の必要がない、という点がポイントです。協調フィルタリングでは、ユーザ同士またはアイテム同士のコサイン類似度を計算し、レコメンドを行います。
 (引用:協調フィルタリング入門)
(引用:協調フィルタリング入門)
Matrix Factorization
Matrix Factorizationは、協調フィルタリングに対する次元削減によって、より良いレコメンドを行います。協調フィルタリングの場合、ユーザやアイテムの数が増えるとそれだけ次元が増えてしまい、計算が困難になります。これが次元の呪いと呼ばれる問題です。そのため、このような高次元のデータを扱うために、高次元データの特徴をできるだけ保持したままデータを低次元データに変換します。これが次元削減です。2008年に行われた推薦システムのコンテスト、Netflix Prizeで最も成果を上げたモデルの1つです。
 (引用:Simple Matrix Factorization example on the Movielens dataset using Pyspark)
(引用:Simple Matrix Factorization example on the Movielens dataset using Pyspark)
SVD(Singular Value Decomposition)
SVDは特異値分解によって次元削減する手法です。特異値分解は行列の低ランク近似や擬似逆行列の計算などに使われ、特異値を成分とした対角行列を生成します。
 (引用:Recommender Systems with Python — Part III: Collaborative Filtering (Singular Value Decomposition))
(引用:Recommender Systems with Python — Part III: Collaborative Filtering (Singular Value Decomposition))
Factorization Machine
Factorization Machine(FM)は、Matrix Factorizationを使いやすく進化させ、より精度の高いレコメンドエンジンを作成できます。Matrix Factorizationでは、ユーザとアイテムの情報しか扱えなかったため、性別、年齢などをレコメンドエンジンの作成に用いる事ができませんでした。Factorization Machineは、それ以外の情報も扱えるため、性別、年齢を考慮できます。さらに特徴量の間で影響を与えあう相互作用(Interaction)を考慮できるので、相関関係がある特徴量も扱えます。
 (引用:
(引用:深層学習を使った推薦手法
次に深層学習を使ったレコメンデーションをいくつか見ていきましょう。
ニューラルネットワーク推薦手法に対する警鐘
RecSys 2019と2020の2年連続で、推薦システムの公平なベンチマークに向けた調査と提案に関する論文が発表されました。RecSysとは推薦システムに関するACM主催の国際学会で、この分野ではトップカンファレンスです。
- Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
- Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison
上記の論文では、近年流行しているニューラルネットワークベースの推薦手法に対し、有効性やロバスト性(あらゆるデータセットに対して安定したパフォーマンスを出しているか)を検証しました。論文では、多くのDNNベースの推薦手法では旧来の協調フィルタリングやBPRFM手法に勝つことができないと主張しており、DNNベースの推薦手法に疑問符が付きました。
Recboleプロジェクト
レコメンドの研究コミュニティでは、レコメンデーションアルゴリズムのオープンソース実装の標準化に対する関心が高まりつつあります。包括的かつ効率的なレコメンダーシステムライブラリとして、Recboleプロジェクトが発足されました。PyTorchを元に開発され、研究者が推奨モデルを再現・開発する支援をします。本ライブラリの特徴は公式ページには以下のように書かれています。
- 一般的で拡張可能なデータ構造
- さまざまな推奨データセットのフォーマットと使用法を統一するために、一般的で拡張可能なデータ構造を設計する
- 包括的なベンチマークモデルとデータセット
- 65の一般的に使用される推奨アルゴリズムを実装し、28の推奨データセットのフォーマットされたコピーを提供する
- 効率的なGPUアクセラレーションによる実行
- ライブラリの効率を高めるために、GPU環境で多くの調整された戦略を設計する
- 広範で標準的な評価プロトコル
- レコメンデーションアルゴリズムをテストおよび比較するために、一般的に使用される一連の評価プロトコルまたは設定をサポートする
Recboleプロジェクトを用いた各アルゴリズムの検証
一般的に使用される推薦データセットの1つであるMovieLens 100K Datasetに対し、Recboleに用意されている推薦アルゴリズムを実行し、実行時間やパフォーマンスを計測しました。なお、計測不能なものは除いており、数値は参考値としてご覧ください。
| Model | Step | 秒数 | recall@10 | mrr@10 | ndcg@10 | hit@10 | precision@10 |
|---|---|---|---|---|---|---|---|
| BPR | 53 | 28.66 | 0.2358 | 0.4711 | 0.2801 | 0.7646 | 0.1882 |
| ConvNCF | 18 | 68.74 | 0.1035 | 0.2341 | 0.1235 | 0.5111 | 0.0941 |
| DGCF | 83 | 417.9 | 0.2421 | 0.4787 | 0.2862 | 0.7773 | 0.1916 |
| DMF | 45 | 52.47 | 0.226 | 0.4149 | 0.2521 | 0.7678 | 0.1783 |
| FISM | 33 | 72.4 | 0.2237 | 0.4573 | 0.2689 | 0.7519 | 0.1777 |
| GCMC | 15 | 31.97 | 0.1835 | 0.3841 | 0.2136 | 0.6872 | 0.1419 |
| ItemKNN | 0 | 2.25 | 0.247 | 0.4623 | 0.2834 | 0.7847 | 0.1931 |
| LightGCN | 136 | 92.4 | 0.2467 | 0.4838 | 0.2895 | 0.7826 | 0.1949 |
| LINE | 85 | 56.52 | 0.2025 | 0.3875 | 0.2284 | 0.7243 | 0.1601 |
| NAIS | 18 | 126.54 | 0.2389 | 0.4586 | 0.2764 | 0.7741 | 0.1894 |
| NeuMF | 35 | 40.08 | 0.238 | 0.4567 | 0.2768 | 0.7678 | 0.191 |
| NGCF | 74 | 64.83 | 0.2476 | 0.4978 | 0.2983 | 0.7869 | 0.1994 |
| Pop | 0 | 1.624 | 0.0289 | 0.1244 | 0.0558 | 0.2694 | 0.0492 |
| SpectralCF | 26 | 22.44 | 0.1133 | 0.2686 | 0.1363 | 0.5578 | 0.1014 |
| CFKG | 13 | 12.88 | 0.1109 | 0.2664 | 0.1368 | 0.5408 | 0.1027 |
| CKE | 88 | 84.38 | 0.243 | 0.4813 | 0.2863 | 0.7752 | 0.1954 |
| KGCN | 39 | 51.26 | 0.2159 | 0.4401 | 0.2566 | 0.7476 | 0.1749 |
| KGNNLS | 39 | 72.5 | 0.2159 | 0.4401 | 0.2566 | 0.7476 | 0.1749 |
| KTUP | 60 | 82.16 | 0.1716 | 0.3374 | 0.2006 | 0.6808 | 0.1503 |
| MKR | 64 | 145.2 | 0.194 | 0.4016 | 0.2315 | 0.7041 | 0.1601 |
| RippleNet | 27 | 258.06 | 0.198 | 0.3873 | 0.2281 | 0.7094 | 0.1642 |
| BERT4Rec | 29 | 584.83 | 0.1113 | 0.0335 | 0.0513 | 0.1113 | 0.0111 |
| FDSA | 43 | 1130.45 | 0.1273 | 0.0403 | 0.0601 | 0.1273 | 0.0127 |
| FOSSIL | 41 | 42.06 | 0.1007 | 0.032 | 0.0476 | 0.1007 | 0.0101 |
| FPMC | 23 | 13.65 | 0.0838 | 0.0244 | 0.0382 | 0.0838 | 0.0084 |
| GCSAN | 17 | 3490.54 | 0.1241 | 0.0398 | 0.0591 | 0.1241 | 0.0124 |
| GRU4Rec | 33 | 103.96 | 0.1304 | 0.0483 | 0.0671 | 0.1304 | 0.013 |
| GRU4RecF | 24 | 160.15 | 0.1463 | 0.0473 | 0.07 | 0.1463 | 0.0146 |
| HGN | 11 | 11.76 | 0.0339 | 0.0136 | 0.0182 | 0.0339 | 0.0034 |
| HRM | 27 | 69.26 | 0.0997 | 0.0305 | 0.0465 | 0.0997 | 0.01 |
| NARM | 40 | 158.06 | 0.1347 | 0.0431 | 0.0642 | 0.1347 | 0.0135 |
| NPE | 42 | 28.43 | 0.0626 | 0.0136 | 0.0247 | 0.0626 | 0.0063 |
| RepeatNet | 30 | 1792.03 | 0.193 | 0.0734 | 0.101 | 0.193 | 0.0193 |
| SASRec | 24 | 317.61 | 0.1251 | 0.0389 | 0.0588 | 0.1251 | 0.0125 |
| SASRecF | 35 | 496.47 | 0.1283 | 0.0406 | 0.0606 | 0.1283 | 0.0128 |
| SHAN | 23 | 80.48 | 0.105 | 0.0356 | 0.0516 | 0.105 | 0.0105 |
| STAMP | 34 | 47.94 | 0.105 | 0.0452 | 0.0657 | 0.1347 | 0.0135 |
| TransRec | 17 | 14.73 | 0.07 | 0.0178 | 0.0297 | 0.07 | 0.007 |
これらのレコメンドは以下の4種類に大別できます。
- General Recommendation
- Graph Recommendation
- Knowledge Aware Recommendation
- Sequential Recommendation
特に、NGCFやLightGCNといったGraph Recommendationは、ItemKNNやBPRなどの旧来手法を超える精度を出しています。
また、ZOZOTOWNではレコメンドを活用するシーンが多く存在します。類似アイテムの推薦にはKnowledge Aware Recommendation。ユーザの短期のクリック予測にはSequential Recommendation。クーポン配信にはGraph Recommendation。各機能との相性を考慮し、最適なレコメンドアルゴリズムを選択する必要があります。
次の章では、これら4種類のレコメンダーシステムの特徴を紹介します。
General Recommendationに分類されるアルゴリズム
GMF(Generalized Matrix Factorization)
GMFはユーザとアイテムのembeddingをelement-wiseにかけたものから、マトリックスの中身を推定する線形モデルです。通常のMatrix Factorizationと同じモデルです。
NCF(Neural Collaborative Filtering)
NCFはユーザとアイテムのembeddingを結合したものから多層パーセプトロンを用いてマトリックスの中身を推定する非線形モデルです。Matrix Factorizationの内積表現の部分をニューラルネットワークベースの関数に置き換えて学習します。
 (引用:論文リンク)
(引用:論文リンク)
NeuMF(Neural Matrix Factorization)
NeuMFではGMFとNCFの出力を結合してマトリックスの中身の推定します。線形モデルと非線形モデルの組み合わせです。
 (引用:論文リンク)
(引用:論文リンク)
Graph Recommendationに分類されるアルゴリズム
グラフ構造は、ノード(頂点)とエッジ(辺)で構成されるデータ型を表します。GNN(Graph Neural Networks)は、グラフ構造を加味しながら各ノードをembeddingします。そして、レコメンド領域でのグラフ構造では、ユーザノードとアイテムノードからなる2部グラフを考えます。2部グラフとは、頂点集合を2つに分割して各部分の頂点は互いに隣接しないようにできるグラフのことです。
グラフベースレコメンドでは、GCN(Graph Convolutional Network)によってノードのembeddingを行います。CNNでは画像データは上下左右斜めの8方向から情報の畳み込み処理を行っているのに対し、GCNでは対象ノードの周辺あるいはグラフ全体の情報から畳み込みを行います。
 (引用:繋がりを可視化するグラフ理論入門、グラフ理論 (2)、介入効果推定の方法)
(引用:繋がりを可視化するグラフ理論入門、グラフ理論 (2)、介入効果推定の方法)
NGCF(Neural Graph Collaborative Filtering)
NGCFでは、ユーザとアイテムのembeddingにグラフ畳み込み処理を行うことで、明示的にユーザとアイテムの交互作用を考慮します。
 (引用:論文リンク)
(引用:論文リンク)
LightGCN(Light Graph Convolutional Network)
LightGCNでは、先のNGCF加えてグラフ上の特徴を平準化することによって計算量を抑えます。これによりGCNの最も重要なコンポーネントである近隣集約のみを考慮しています。
 (引用:論文リンク)
(引用:論文リンク)
DGCF(Disentangled Graph Collaborative Filtering)
DGCFでは、ユーザとアイテムの間にインテント層を用意します。これによりユーザがアイテムを購入した潜在的な意図を表現し、購買理由を説明可能にします。

 (引用:論文リンク)
(引用:論文リンク)
Knowledge Aware Recommendationに分類されるアルゴリズム
ナレッジグラフは、柔軟かつ双方向的に事実「エンティティ」を格納する脳のような構造化データベースで、エンティティの相互にリンクされた意味付けを自由に表現します。レコメンド領域のナレッジグラフでは、エンティティとしてユーザとアイテムの他に、アイテムのジャンルやユーザの年齢層/性別などの各特徴量も表現可能です。
さらにナレッジグラフは意味ネットワークとして構築されるため、エンティティ間のセマンティック類似性(意味の類似性)を計算し、各アイテムの類似商品を推薦します。また、ナレッジグラフでは推薦理由を可視化し、データのスパース性問題を解決します。
 (引用:A Survey on Knowledge Graph-Based Recommender Systems)
(引用:A Survey on Knowledge Graph-Based Recommender Systems)
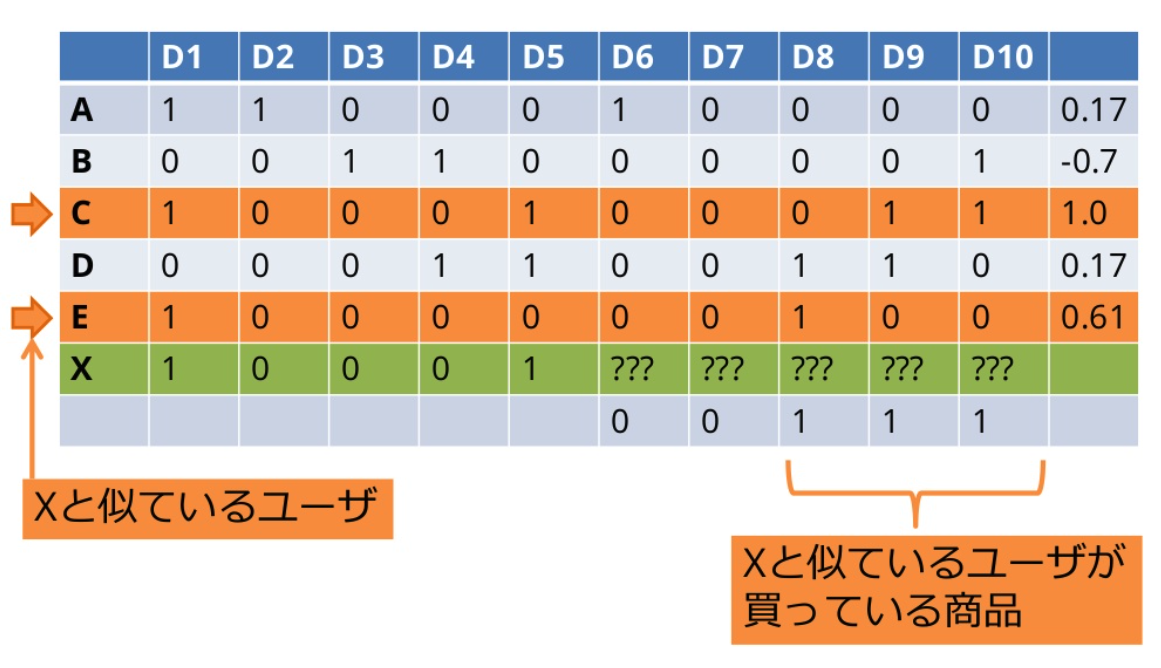
RippleNet
RippleNetは、ナレッジグラフのリンクに沿ってユーザの潜在的な関心を自動的かつ反復的に拡張することにより、知識エンティティのデータセットに対するユーザの好みをembeddingします。ユーザによってアクティブ化された複数の波紋に従って、過去にクリックされたアイテムは候補アイテムに関するユーザの嗜好分布を形成し、最終的なクリック確率を予測します。
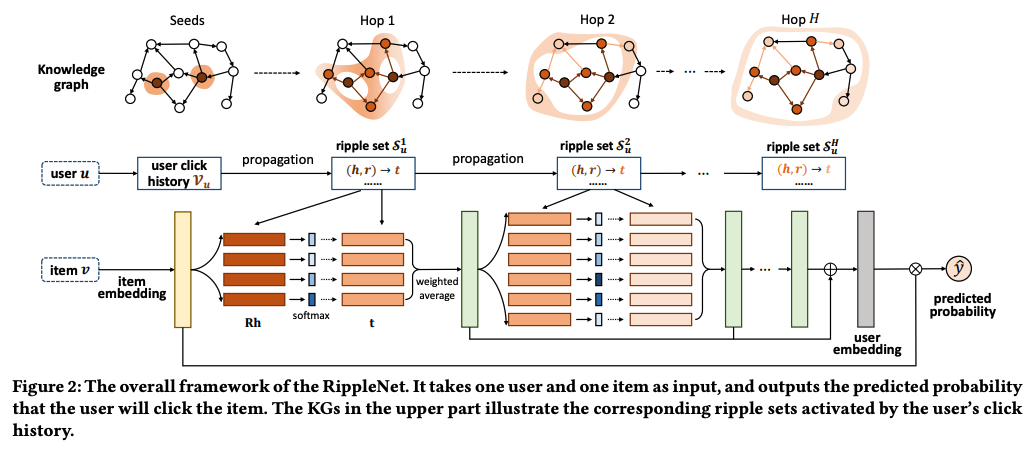 (引用:論文リンク)
(引用:論文リンク)
CKE(Collaborative Knowledge Base Embedding for Recommender Systems)
CKEでは、以下の3つを用いてアイテムのembeddingを取得します。
- ナレッジグラフを用いたembedding(structural knowledge)
- 画像解析によって得られたembedding(visual knowledge)
- テキスト解析によって得られたembedding(textual knowledge)
 (引用:論文リンク)
(引用:論文リンク)
Sequential Recommendationに分類されるアルゴリズム
通常のGeneral Recommendationでは、ユーザがアイテムを消費する順序は考慮せず、長期予測としてユーザが最終的に消費するアイテムを予測します。シーケンシャルレコメンドの場合は、ユーザがアイテムを消費した順序に基づいて推薦を行い、ユーザが次に買いそうなアイテムを予測します。
シーケンシャルレコメンドの領域は、自然言語処理の分野と強い相関があります。自然言語処理では、単語の並ぶ方向からID化した単語をembeddingします。シーケンシャルレコメンドでも、ユーザの商品への消費履歴からアイテム情報をembeddingしていきます。ほとんどのシーケンシャルモデルは、自然言語モデルを元に作られています。
RNNRecommender
RNNRecommenderは、ユーザの1Session分の短期の行動(クリック履歴)から時系列データを取得し、RNNによってユーザのembeddingを行う手法です。RNNの層にGRUやLSTMを使用したり、双方向モデルを使用したりと、様々なアーキテクチャが存在します。
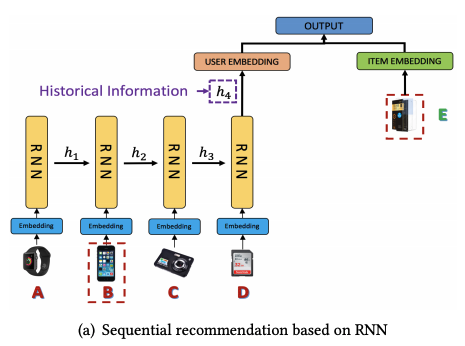 (引用:Sequential Recommendation with User Memory Networks)
(引用:Sequential Recommendation with User Memory Networks)
Item2Vec
Item2Vecは、自然言語処理で文脈から単語のembedding処理を行うWord2Vecを応用し、ユーザの行動履歴からアイテムのembeddingを行います。
 (引用:Item2Vec-based Approach to a Recommender System)
(引用:Item2Vec-based Approach to a Recommender System)
BERT4Rec
BERT4Recの「BERT」はBidirectional Encoder Representations from Transformersの略です。2018年10月にGoogleのJacob Devlinらの論文で発表された自然言語処理モデルです。「AIが人間を超えた」と言わしめるほどのブレークスルーをもたらし、多様なタスクにおいて当時の最高スコアを叩き出しています。このBERTモデルをレコメンドに応用したものがBERT4Recです。
 (引用:論文リンク)
(引用:論文リンク)
なお、自然言語処理の領域では、BERTの他にもALBERTやXLNetやGPT-xなど様々なモデルが登場しているため、それらを生かしたレコメンドモデルも試していきたいです。
深層学習×推薦のまとめ
ここまで、ディープニューラルネットワーク時代のレコメンド技術の動向について4種類にわたり紹介してきました。一口にディープラーニングといっても、様々な分野の技術がレコメンドに生かされていることをご理解いただけたでしょう。ここで紹介した内容以外にも、強化学習を用いたレコメンド、深層学習を使わないレコメンドなどもあります。各分野のレコメンド技術に加え、特徴量エンジニアリング、ハイパーパラメータチューニングなど、さらなる精度向上を目指していきたいです。
短いライフサイクルで推薦を可能にするための計算時間を短縮する工夫
コラムとして本章では、推薦における計算時間を短縮するためのテクニックを紹介します。ZOZOTOWNでは、毎日100万以上のアクティブユーザと、100万のアイテム数を取り扱っています。ファッションアイテムは商品のライフサイクルが短いため、推薦結果を出すまでの計算時間は重要です。
スパースマトリックスによるデータ量削減
数百万のアクティブユーザと、数百万のアイテムのマトリックスデータを扱おうとすると、数TBのメモリが必要になります。そのようなサーバーを用意するのも大変ですが、用意できたとしてもインフラコストが格段に高いため、レコメンドによる売り上げ増加を食い潰してしまいます。
そのため、データ量を削減する工夫として、スパースマトリックス(疎行列)をインプットとして用います。レコメンドのインプット成分のほとんどがゼロであるため、疎行列の非零要素だけを工夫してうまく格納することにより大次元の問題を扱うことが容易になり、比較的少ない手間でベクトルと行列の積を計算できます。
ZOZOTOWNの場合、スパースマトリックスを用いることでインプットのデータ量を約10万分の1に削減できます。
Cython
Pythonはインタプリタ言語であるため、処理速度は遅い部類に属します。そこで、コンパイラ言語であるC/C++に変換することにより高速化しようというのがCythonです。Factorization Machineモデルでは、Cythonベースのライブラリを用いることで、高速化を実現しています。ZOZOTOWNのリアルデータでも10分強でモデルの作成を終えることができます。
GPU
embeddingの計算は、TensorFlowやPyTorchを用いてテンソルの処理をGPUで行います。NumPyに比べてテンソル計算は100倍以上、GPUを用いるとさらに3倍早くなる印象です。
最後に
ZOZOテクノロジーズでは一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!