はじめに
こんにちは。ML、データ部データサイエンス2ブロックの吉本です。
ZOZOTOWNの商品には「長袖」「クルーネック」「花柄」といった、アイテムの特徴を示すタグ(アイテム特徴タグ)や「ベーシック」「モード」「結婚式」といった、アイテムに合うシーンやスタイルを表すタグ(シーン・スタイルタグ)が付与されています。これらは商品情報の登録時、ブランドさんに付与していただいているものです。
これらタグに関する課題として、タグ付与の手間、シーン・スタイルタグのタグ付与率の低さがあります。アイテム特徴タグは例えばTシャツ/カットソーカテゴリでは約50種類、シーン・スタイルタグは約130種類のタグがあり、一つ一つの商品に対してこれらの中から該当するものを選んで付与することは手間のかかる作業となります。またシーン・スタイルタグについてはZOZOTOWNに導入されてから2年弱とまだ日が浅いことから、認知度が低くタグが付与される商品の割合が小さくなっています。
そこでZOZOではタグ登録の手間の軽減、タグ付与率の向上を目標に画像認識によるタグ予測に取り組んでいます。2023年1月からは、ブランドさんが商品にタグを登録する際に、予測したタグを推薦するという仕組みとして導入されています。
また現在稼働しているシーン・スタイルタグ推薦のモデルでは、予測精度が高いタグに限って推薦を行っていますが、モデル開発では引き続き対応タグを増やすための精度の向上に取り組んでいます。こちらの取り組みでは、スタイルタグを人手でアノテーションすることによって、学習データを改善し精度の向上を目指しました。
本記事では、はじめに現時点のタグ推薦で用いられているアイテム特徴タグ、シーン・スタイルタグのモデル(商品タグによるモデル)に関して簡単に紹介したのち、スタイルタグの対応タグ数増加のための取り組み(アノテーションデータによるモデル)に関して紹介します。
ZOZOTOWNの商品タグ
ZOZOTOWNでは、見た目の特徴や素材などに関するアイテム特徴タグや、活用シーンや合うスタイルを表すシーン・スタイルタグが商品に対して付与されています。
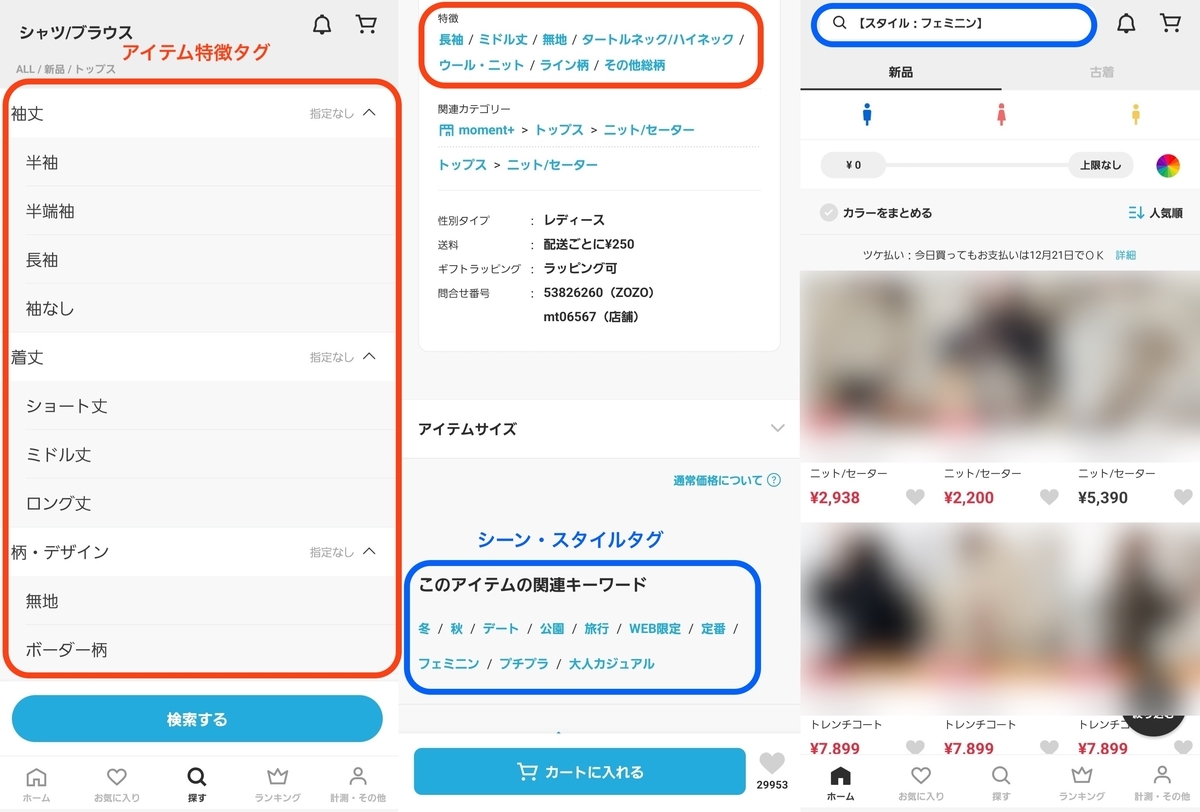
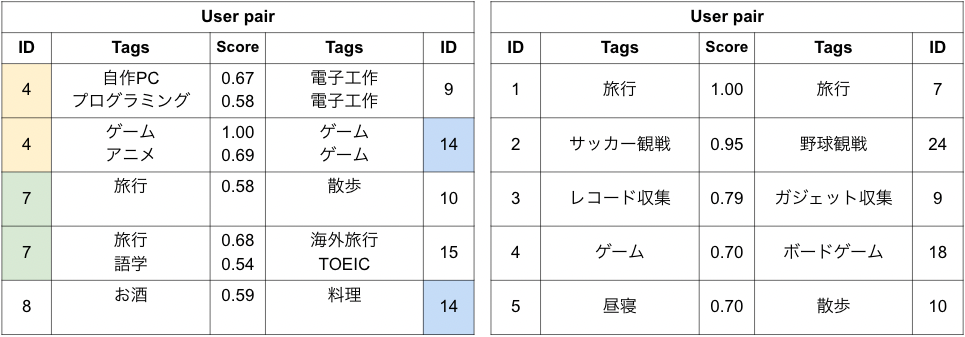
アイテム特徴タグは「着丈」「袖丈」「柄、デザイン」といったタググループに分かれていて、その中に例えばシャツ/ブラウスカテゴリなら「着丈」の「ショート丈」「ミドル丈」「ロング丈」といったタグがあります(上図左)。アイテムのカテゴリ(シャツ/ブラウス、ニット/セーターなど)ごとに対象のタググループが決まっていて、ブランドさんはそこから選んでタグを付与できるようになっています。ユーザーさんは各タググループごとにタグを指定することで、求める特徴を持つ商品に絞り込んで検索できます。アイテム特徴タグの付与率は比較的高く、Tシャツ/カットソーの「ネック」だと約84%の商品にタグが付与されています。
シーン・スタイルタグに関しては130個ほどあり、商品ページでは「このアイテムの関連キーワード」の欄に表示されています(上図中央)。商品ページからこれらのタグをクリックすることで、当てはまる商品を検索できるようになっています(上図右)。導入されてからまだ2年弱しか経過していないということもあり、何らかのタグが1つ以上付与されている商品は全体の10%程度であり、タグがついてる商品は未だ多いとは言えない状態です。
商品タグによるモデル
はじめに現在タグ推薦で利用されている、商品タグを用いて作成したモデルに関して簡単に紹介します。
アイテム特徴タグ
アイテム特徴タグは多くのタグで学習に十分なデータ量がありました。このためZOZOTOWNの商品画像と、商品に付与されたアイテム特徴タグを学習データとして用いました。
モデルとしてはベースネットワークの上に、タググループごとにタグを1つ予測する層を載せたモデルを学習しました。損失関数にはSoftmax Cross Entropy Lossを用いました。ベースネットワークとしては、速度と精度ともに良い数値が報告されていたEfficientNetV2-Sを用いました。
プロダクト導入に際しては社内の他部署に評価を依頼しました。各カテゴリごとに約100画像を用意し、各タググループに関して予想したタグが正しいかどうかを評価しました。この評価において、正解率が事前に定めた閾値を上回ったカテゴリ×タググループを導入することに決定しました。
シーン・スタイルタグ
シーン・スタイルタグは前述の通りタグ付与率が低い状態でした。そのため商品に付与されたシーン・スタイルタグだけでは十分なデータ量を確保できないタグが多くありました。データ量の確保のため、商品説明にシーン・スタイルタグと一致する文字列が含まれる場合、そのタグが付与されているとみなして、商品に付与されたシーン・スタイルタグに加えて用いました(以後これも合わせて商品タグと呼びます)。
モデルとしてはベースネットワークの上に、各タグを付与するべきかどうかを予測する層を載せたモデルを学習しました。損失関数には負例を多く含むデータセットで高い精度が報告されているAsymmetric Lossを用いました。ベースネットワークとしてはアイテム特徴と同じくEfficientNetV2-Sを用いました。
画像認識を用いるともに、人手によりカテゴリごとに対象タグを洗い出しました。これにより精度を細かく評価できるようになるとともに、評価作業や後ほどお話するアノテーション作業の手間を軽減できました。
アイテム特徴と同じく、プロダクト導入に際しては社内の他部署に評価を依頼しました。訓練画像が十分に存在するカテゴリ×タグを評価対象とし、対象画像は各カテゴリ×タグ中で予測スコアが上位5%に入るものから50枚ずつ抽出しました。アイテム特徴と異なり、シーン・スタイルタグはそのシーンやスタイルに当てはまるか、当てはまらないかではっきりと分けることができないため、タグとしてどのくらい妥当かを4段階で評価しました。
評価の結果、評価対象としたカテゴリ×タグの約91%に当たる約300個に関して、社内で定めた閾値を上回ったため導入を決定しました。ただ評価対象としなかったものを中心に、導入を見送ったカテゴリ×タグも多く残りました。
アノテーションデータによるモデル
商品タグによるシーン・スタイルタグのモデルでは、上述のとおり精度が足りないことから導入を見送ったタグが多くありました。これらの多くは、付与数が少ないタグや商品説明文の中であまり使われない用語に関するタグでした。例えばTシャツ/カットソーのスタイルタグでは「マリン」「ロック」「セクシー」「カレッジ」「ギャル」「リゾート」の6種類のタグが該当しました。
また商品タグによるデータセットの問題点として、タグが付与されるべき商品にタグが付与されているとは限らないという問題がありました。これは精度への悪影響に加え、このデータセットを用いて信頼のできる定量評価ができない、本来タグが付与されるべき商品の割合を知ることができないといった問題につながっていました。
そこで次のステップとして、人手によるスタイルタグのアノテーションを行ったデータセットを作成することで、上記の問題を解決し対応タグ数の増加を目指しました。
アノテーション
アノテーションは過去に実績のあるFastLabel社に依頼しました。65のカテゴリに対して、前述の人手で作成したカテゴリごとの対応タグリストを用いて、アノテーション対象のタグを設定しました。より主観的な要素が強いシーンタグは、アノテーション作業の効率や導入時の効果の観点から今回の対象から外し、スタイルタグのみを対象としました。
また、今回1つの画像に対して3人のアノテータにタグを付与していただきました。これは人によって各スタイルのイメージが異なり、社内で行った少量のアノテーションにおいても、人によってタグ付与の基準がばらつくという結果が出ていたためです。
アノテーション対象画像としては、約1年間分のZOZOTOWNの商品から約35万画像を抽出しました。この際に多くの商品で、1つの商品からは1カラーバリエーションの画像のみを選定するようにしました。アノテーション後、同じ商品の異なるカラーバリエーションの画像にも自動的に同じタグを付与することで、約70万の画像からなるデータセットとなりました。
予測スコアを用いた抽出
このアノテーション対象商品の選定方法ですが、今回の主目的が対応タグ数の増加にあるため、新たに対応を目指すタグが付与されそうな商品を重点的に抽出することを考えました。このために、新たに対応したいタグを対象に上述のモデルを用いて予測を行い、カテゴリ×タグごとに予測スコアが上位20%に入る商品からランダムに商品を抽出しました。トレーニングデータにおいて、この予測スコアを用いて集めた商品と、全商品からランダムに収集した画像をあわせて用いました。具体的なデータ数の目安としてはランダムに2500個(カテゴリごとにばらつきはありますが)、予測スコアを用いた分に関してはカテゴリ×タグごとに500個と設定しました。バリデーションデータ、テストデータに関しては、ZOZOTOWN上でのタグの分布と同じ分布のデータで評価するために、全量を全商品からランダムに集めたものとしました。4カテゴリに関してテスト発注、分析を行い効果が期待できそうであったため、残りの分もこの方法で収集しアノテーションを依頼しました。
結果分析
まずアノテーションデータと商品タグデータでタグ付与率を比較しました。この結果アノテーションデータでのタグ付与率の方が、商品タグデータでの付与率より4.14倍大きいことがわかりました。
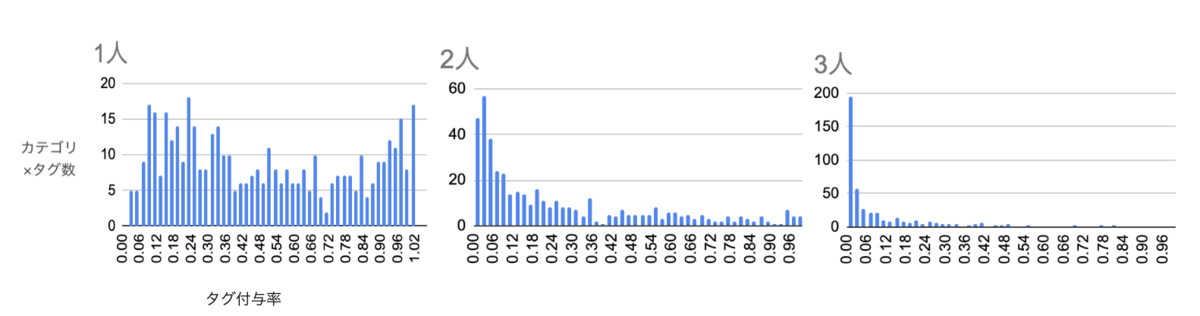
3人のアノテータ間のタグの一貫性に関しても集計を行いました。カテゴリ×タグ内でタグが1人、2人、3人に付与された画像の割合を横軸に、各範囲に該当するカテゴリ×タグ数を縦軸にプロットしたヒストグラムを見ると以下のようになっています。
予測スコアを用いた収集方法の効果検証として、予測スコアを用いて収集された画像とランダムに収集された画像のそれぞれで、別々にタグ付与率を算出し比較しました。この結果、予測スコアを用いたカテゴリ×タグの30/31個において、予測スコア収集分の付与率の方が高いことがわかりました。また平均では1.7倍高いという結果になりました。予測スコア収集の対象外のタグに関しては、予測スコア収集分ではタグ付与率が下がる傾向があり、最も下がっていたTシャツ/カットソーの「エレガント」「フェミニン」「キレイめ」「ガーリー」「ナチュラル」タグでは0.65-0.77倍となっていました。
モデル作成
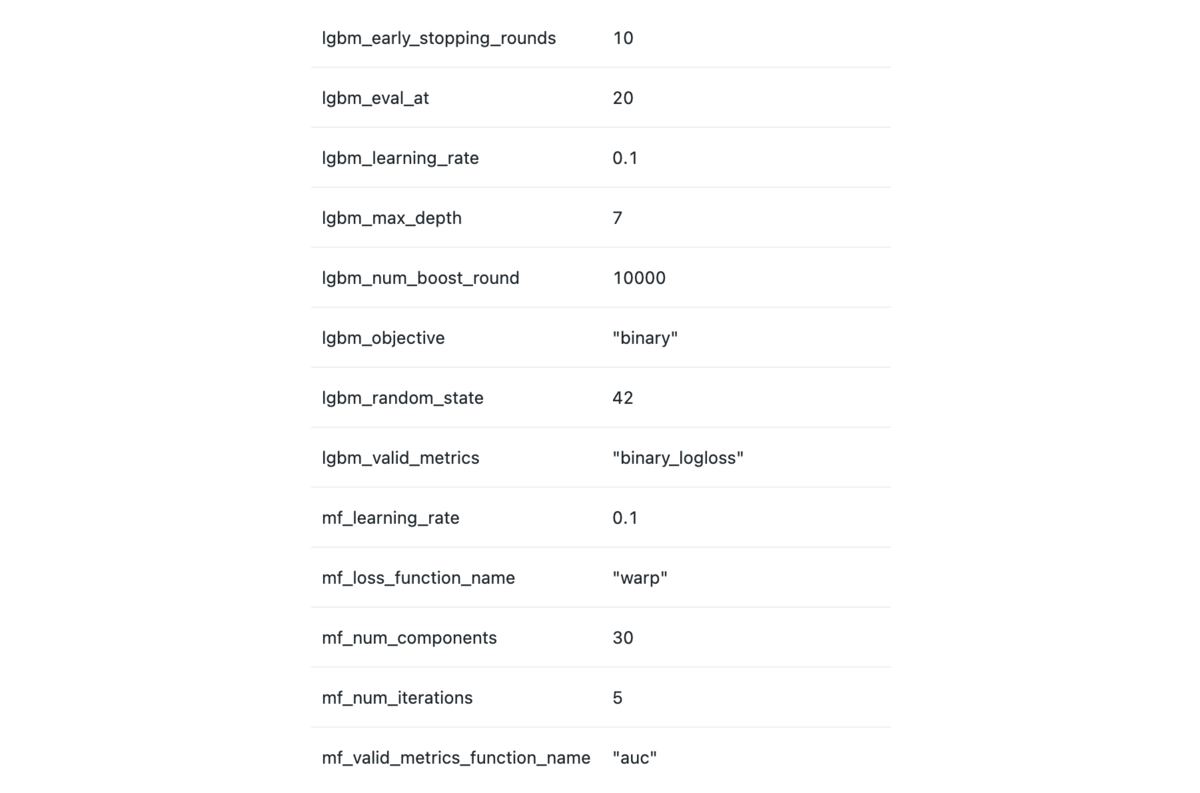
アノテーションデータを用いた検証をする前に、商品タグを用いたデータセットでベースネットの精度検証を行いました。前述のEfficientNetV2-Sに加えて、CoAtNet-0、CoAtNet-2、VOLO-D2を試しました。新しく試したネットワークについてはkeras_cv_attention_modelsを用いて検証しました。報告されているImageNet上での精度と同様、順当にパラメータ数が多いものほど高い精度が出るという結果になり、最も精度が高かったVOLO-D2を採用しました。
データセットはアノテーション対象データの抽出元となった約1年分の商品から作成しました。ラベルとしてはアノテーションと商品タグを別に使えるように用意しました。モデルの方でもベースネットワークの上にアノテーションタグ、商品タグそれぞれに対して別に層を用意して、別に予測、学習を行うようにしました。プロダクトで用いる際には、アノテーションで十分なラベル量があるタグはアノテーションタグの方の予測(以下アノテーションタグ予測と呼びます)を用いることにし、そうでないタグ(主にアノテーションの対象としなかったシーンタグ)に関しては商品タグの方の予測(商品タグ予測と呼びます)を用いることにしました。
損失関数には前回と同様にAssymmetric Lossを用いました。またタグを付与したアノテータ数の情報を活かすため、付与した人数×0.5で正例を重み付けしました。
評価
アノテーションデータ上での評価
評価指標としては、Precision(モデルがそのタグと予測したもののうち、正解データでアノテータ3人中2人以上がそのタグをつけた割合)、Recall(3人中2人以上がそのタグをつけたもののうち、予測できた割合)をカテゴリ×タグごとに算出し用いました。
タグを付与する/しないを決定する閾値には、タグ付与率(そのカテゴリにおいて3人中2人以上がそのタグを付与した割合)に応じた値を設定しました。
結果、Precisionは対象カテゴリ×タグの中央値では0.31、Recallは0.42でした。またPrecision算出時の正解データの条件を変更し「1人以上がそのタグを付けた割合」とすると0.72でした。
リリースに向けた分析項目
リリースに向けて以下の項目を確認しました。
- タグ付与率とPrecisionの関係
- アノテーションデータ上での評価と社内評価の相関
- アノテーションタグ予測と商品タグ予測の相関
1はタグによる絞り込み検索の効果の参考として用いました。仮に検索対象の全商品に予測したタグを付与し、タグを指定して絞り込み検索をしたとすると、Precisionは絞り込み結果に正しくそのタグが該当する商品が含まれる割合を表します。絞り込まない場合にそのタグが含まれる割合はタグ付与率となります。タグ付与率とPrecisionを比較することで、絞り込み検索をした際にどの程度そのタグに該当する商品が増えるかを知ることができます。
2に関しては、一部のカテゴリ×タグについて商品タグを用いたモデルのときと同じく他部署の人に4段階で評価していただき、アノテーションデータでの評価が社内での評価と乖離していないかを確認しました。
3では、これまで用いてきた商品タグ予測とアノテーションタグ予測の間に大きな乖離がないかを見るため、ランキング指標を用いて確認しました。
分析結果
以下の左図が1のタグ付与率とPrecisionの関係を、カテゴリ×タグを1サンプルとしてプロットしたものになります。タグ付与率に比べてPrecisionが中央値で2.3倍となり、さらに付与率0.15以下のものに限ると4.6倍という結果になりました。絞り込みにより対象商品が数倍増えるという結果を得ることができました。
絞り込みにより対象タグの割合が増えても、タグと全く関係のない商品が検索結果の大半を占めると使われづらいことが予想されます。そこで正解データの条件を緩め、3人中1人以上がタグをつけたものとした場合のPrecisionも見てみました(下図右)。タグ付与率が0.01から0.05のものに限ると0.5、0.01以下だと0.26となりました。タグ付与率が低いカテゴリ×タグにおいても、絞り込み結果中のタグに関連する商品の割合を高くできそうなことがわかりました。
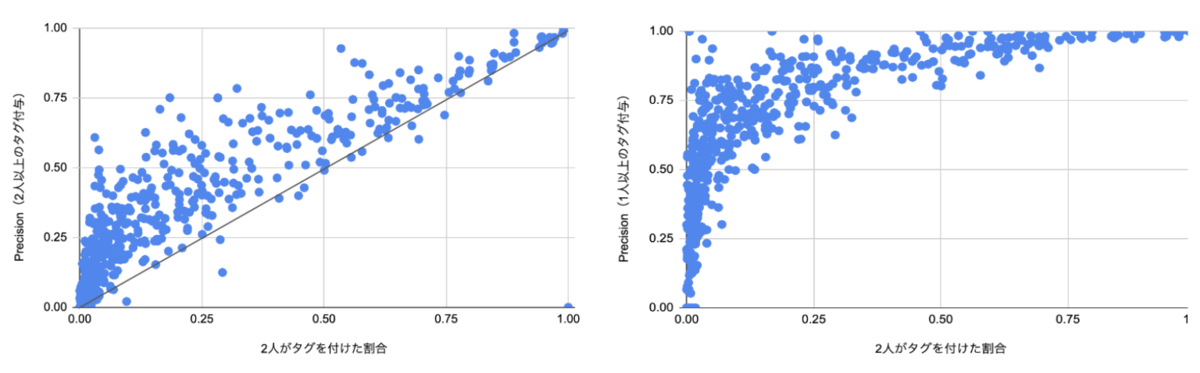
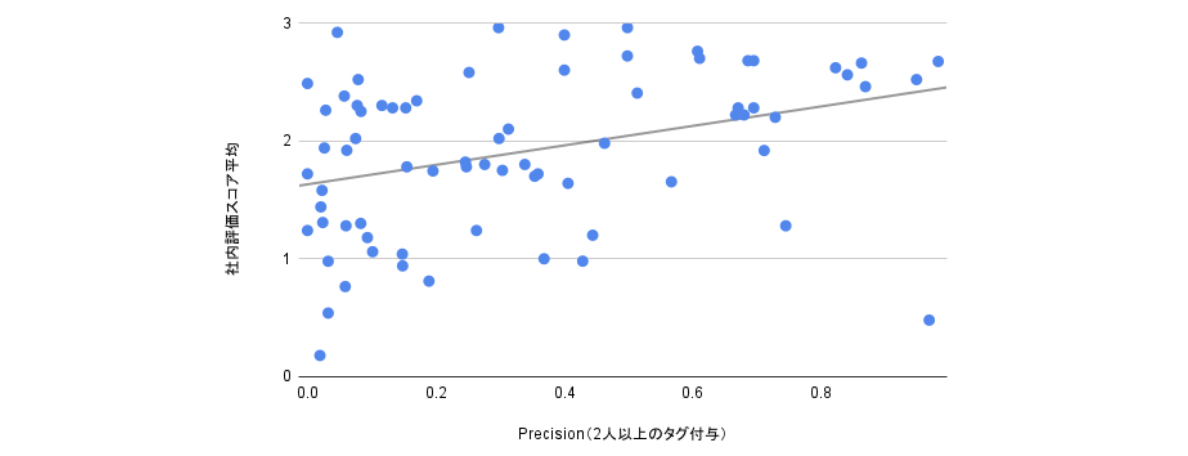
2のアノテーションデータ上での評価と社内評価の相関に関しては下図右になります。アノテーションデータでのPrecisionが高いほど、定量評価の点数が高いという傾向が見て取れます。
3の確認には、商品タグ予測とアノテーションタグ予測の間のケンドールの順位相関係数を用いました。全カテゴリ×タグのうち約97%で正の相関があることが確認できました。
対応タグの増加、タグ推薦対象の増加
これらの結果と人手でのタグリストのチェックの結果、217個のカテゴリ×タグについて、アノテーションタグ予測を用いて追加で対応することが決定しました。また現在稼働中のタグ推薦において既に対応済みのカテゴリ×タグのうち、スタイルタグの大部分になる164個に関してアノテーションタグ予測を用いることになりました。
このモデルでの改善点として、対応タグの増加の他に、推薦対象商品の増加があります。前節の商品タグを用いたデータセットでは、正確なタグ付与率を計算できませんでした。そのため社内で行った定性評価の結果などを元に、各カテゴリ×タグの中で上位10%に当たるスコアを持つ商品に対して、タグを推薦することにしていました。この方法だと、大部分の商品にそのタグが当てはまるようなカテゴリ×タグにおいては、そのタグが推薦される商品の割合が理想より小さくなってしまうといった問題がありました。今回のモデルでは、アノテーションされたタグの割合に応じて推薦のための閾値を定めたため、上記の問題を解決しタグ推薦対象の商品を増やすことができました。
さいごに
本記事では画像認識を用いた商品タグ予測に関する取り組み、特にアノテーションデータを用いた精度改善について紹介しました。今後も検索体験の向上や商品登録の手間の軽減に向けて、機械学習、システム面ともに改善を進めていきます。
ZOZOではMLエンジニアを募集しています。以下のリンクからご応募ください。
hrmos.co