



こんにちは。検索基盤部の山﨑です。検索基盤部では、検索基盤の速度改善やシステム改善だけではなく検索の精度改善にも力を入れて取り組んでいます。
検索システム改善についての過去の取り組み事例は、こちらのリンクをご参照ください。
また、ZOZOTOWNの検索ではElasticsearchを活用しています。Elasticsearchに関する取り組み事例はこちらのリンクをご参照ください。
本記事では、ZOZOTOWNで近年実施した検索の精度改善の取り組み事例を紹介します。
目次
はじめに
ZOZOTOWN検索の処理フロー
ZOZOTOWN検索では、ユーザーが検索クエリを入力してから検索結果を出力するまで大きく3つのステップに分けられます。

- Step 1: ユーザーから入力された検索クエリを受け取る。
- 検索クエリの支援のために検索クエリサジェスト機能があります。
- サジェスト改善の取り組みについては、ユーザーログを活用したZOZOTOWNの検索サジェスト改善をご覧ください。
- Step 2: 検索クエリの意図を解釈した結果を基にElasticsearchのクエリを作成する。
- クエリ分割をQuery Segmentation、クエリの属性の引当をEntity Recognitionと呼ぶことがあります。
- Step 3: 作成されたElasticsearchのクエリを基に、検索結果に表示される商品の絞り込みと並べ替えを行う。
本記事では特に以下の内容について紹介します。
- 全ステップに共通するZOZOTOWN検索改善の方針について
- Step 3の仕組みの概要と特徴量ロギングの導入について
- Step 2の現状と今後の展望について
次節では、全ステップに共通する改善方針について説明します。
ZOZOTOWN検索改善の方針について
プロダクトを成長させるためには、良い評価指標の設計と施策の試行回数が必要です。全ての施策はA/Bテストで検証するため、各ステップでA/Bテストが容易に実施可能な状態となるようにシステム改修を進めました。
各ステップでA/Bテストが実施できる状態になった後は、評価指標の設計を進めました。評価指標の設計はZOZOTOWN全体のKGI/KPIまで関わるため、非常に難しい内容です。
私たちは、まず「良いZOZOTOWN検索とはなにか?」を議論してKPIツリーを作成しました。このKPIツリーをベースに、ガードレール指標を定めました。ガードレール指標とは、ビジネス上毀損したくない指標で、例えばZOZOTOWN全体の売上などが該当します。ガードレール指標をA/Bテストの度に計測することで、思わぬ事故を未然に防ぐ効果があります。こちらは、A/B Testing at Scale Tutorialなどで紹介されています。
ガードレール指標を決めた後は各ステップでのA/Bテストの評価指標(Overall Evaluation Criterionを略してOEC指標とも呼ばれます)の設計を進めました。
評価指標の設計に際して、[2019 KDD-tutorial] Challenges, Best Practices and Pitfalls in Evaluating Results of Online Controlled Experiments で紹介されている下記5つの特性を参考にしています。
- Sensitivity: 変更に対してどれだけ指標が変化するか
- Trustworthiness: 得られた指標がどれだけ信頼できるか
- Efficiency: 指標の計測がどれだけ効率的か
- Debuggability and Actionability: 指標の変化を説明できる状態か
- Interpretability and Directionality: 指標を改善したとき、最終的な目標値が改善するか
A/Bテストの基盤と運用を整備すると、1回当たりのA/Bテストの実行コストが小さくなるため、小さな改善でも気軽にA/Bテストを実施できるようになります。また、Sensitivityの高い指標を定義できていれば、1回当たりのA/Bテスト期間も短くできます。そのため、Sensitivityが高い指標を見つけることは試行回数を増やす上でも大切です。
小さな改修を重ねてA/Bテストを繰り返すと、Sensitivityの高い指標については有意な差が計測され、機能に変化が出ていることが確認できました。 一方で、Sensitivityの低いKPIについては一度のA/Bテストで有意な差が計測されることが少ないため、小さな改善の積み重ねがKPIに正しく影響を与えているのか疑問視されていました。 この疑問に対応するため、ZOZOTOWN検索では、改善を積み重ねた現行ロジックと1年前のロジックをA/Bテストで比較するネガティブテストを行いました。結果として、現行のロジックと1年前のロジックではKPIに大きな差が観測され、小さな改善の積み重ねがKPIの改善に有効であったことが分かりました。
以上をまとめると、各ステップにおいて下記のサイクルを回しながら改善を進めています。
- A/Bテストが可能な状態にシステムを改修する。
- A/Bテスト後のリリース判断に用いるガードレール指標と評価指標を設計する。
- A/Bテストを何度か実施してリリースを進める。
- 複数の改修をリリースした後に、1年前のロジックと比較してKPIの改善を確認する。
- KPIと評価指標の見直しを行う。
次章では、近年特に改善が進んだStep 3の商品の並べ替え(以下リランキングと呼ぶ)について紹介します。
商品のリランキングロジックについて
ZOZOTOWNのおすすめ順検索では、機械学習モデルを活用することでユーザー1人当たりの購入率を大幅に改善しました。
商品のリランキングロジックの概要
ZOZOTOWN検索では、検索したユーザーの情報と検索クエリを入力として、パーソナライズされた商品一覧の結果を返します。毎回全ての商品を機械学習モデルでランキングすると、計算コストが膨大になります。そこで、商品のランキングロジックを2つのフェーズに分けることで、計算コストを軽量化しました。
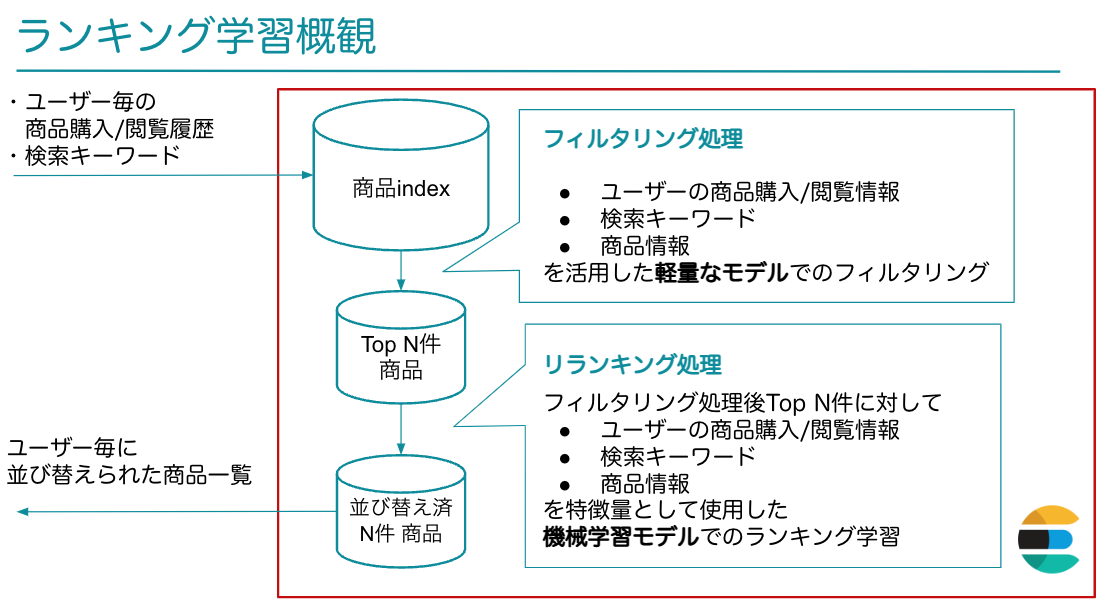
最初のフェーズでは、再現率を高めることを目的にルールベースのロジックや軽量な機械学習モデルを用いて、商品のフィルタリングを行います。
Elasticsearchでは、入力されたクエリと商品indexの各フィールドとのマッチスコアの重みを設定できます。下記のクエリ例の "brand_name^0.1" の 0.1部分です。この重み付けを線形モデルで学習する手法を採用しています。
{ "query": { "bool": { "must": [ "multi_match": { "query": "クエリ1", "fields": [ "brand_name^0.1", "shop_name^0.2", ... ] }, "multi_match": { "query": "クエリ2", "fields": [ "brand_name^0.1", "shop_name^0.2", ... ] } ] } }, "score_mode": "sum", "boost_mode": "sum" }
次のフェーズでは、適合率を高めることを目的に商品間の順序関係を学習する「ランキング学習」と呼ばれる手法の機械学習モデルを用いて、商品を並べ替えます。
フィルタリングされた全商品に対してランキング学習を走らせるのではなく、フィルタリング時のElasticsearchのスコア結果トップN件に絞ってリランキング処理を行います。リランキング処理でのランキング学習では、ElasticsearchのLearning to Rankプラグインを使用しています。詳しくはElasticsearch Learning to Rankプラグインの使い方とポイントをご覧ください。
また、機械学習モデルの開発にはVertex AI Pipelinesを利用しています。詳しくはVertex AI Pipelinesによる機械学習ワークフローの自動化をご覧ください。
機械学習モデルの導入前後でネガティブテストを実施することで、ユーザー当たりの商品購入率が大幅に改善することを確認しました。
次節では、機械学習モデル改善の取り組みの中でも評価指標が大きく改善した、特徴量ロギングの導入について説明します。
特徴量ロギングの導入について
ZOZOTOWN検索の処理フローの概要は下記のとおりです。
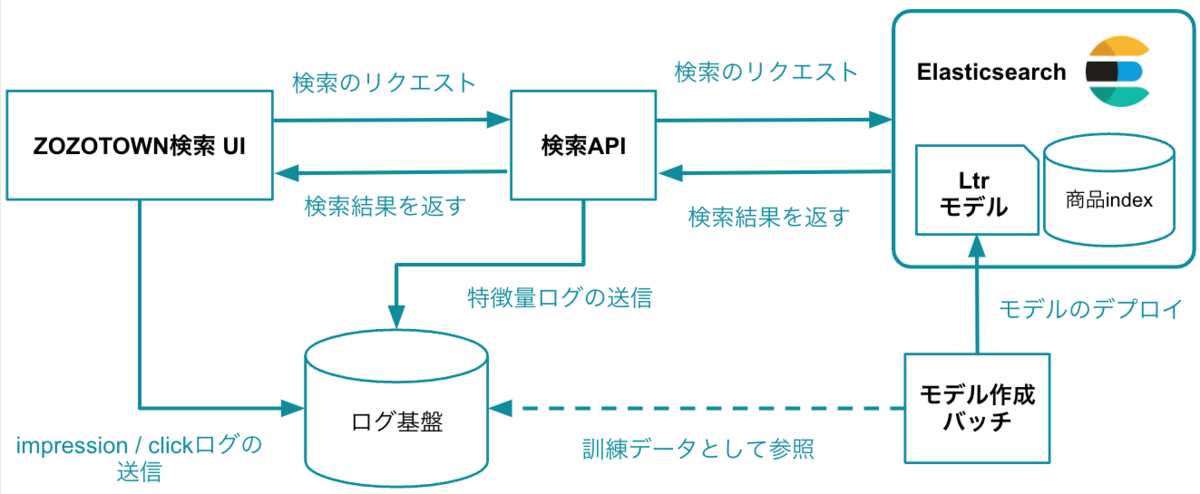
Elasticsearchにリクエストした時点の特徴量をロギングしておくことは、機械学習モデルを構築する上での訓練データの作成の観点で重要です。
機械学習モデル構築の最初期は、ユーザーの行動ログ(ユーザーの商品インプレッションとクリックのログ)と訓練時点でElasticsearchに格納されている商品情報を紐付けることで訓練データを作成していました。
しかし、ZOZOTOWNの商品情報は高頻度で更新されているため、この訓練データの作成方法だと行動ログが記録された時点の商品情報と現在の商品情報が一致しないという課題がありました。そこで、ユーザーが検索するタイミングでの商品情報に基づいて計算された特徴量をログとして記録し、モデル学習の際に活用するように仕組みを整えました。結果として、上記の課題は解決され、さらに評価指標も改善しました。
なお、ZOZOTOWN検索では、特徴量ログを出力するためにLearning to rankプラグインを活用しています。しかし、特徴量ログを落とすとスコアの計算時とログの出力時に二重で特徴量の計算が走ってしまい、CPUに負荷がかかり検索のパフォーマンスが劣化してしまう課題がありました。私たちはプラグインに特徴量キャッシュ機能を実装することで、この課題に取り組みました。こちらの取り組みの詳細は、以下の記事をご覧ください。
今後のZOZOTOWN検索の展望
現行のZOZOTOWNの検索では、Step 2のクエリの意図解釈は辞書の引当てで実現しています。クエリの意図解釈に関しては、下記に記すような現行のZOZOTOWN検索には実装されていない機能が既にいくつも提案されています。
- スペル修正
- 検索クエリのスペル等を修正することで、ユーザーが意図した結果を返す
- 例:
Tシャルで検索 ->Tシャツで検索
- クエリ拡張
- ユーザーが入力した検索クエリに関連するクエリを追加して検索することで、ユーザーの検索クエリに類似した結果も併せて返す
- 例:
Tシャツで検索 ->Tシャツ OR シャツで検索
- クエリ緩和
- ユーザーが入力した検索クエリから一部のキーワードを削除して検索することで、より広範な結果を返す
- 例:
Tシャツ 白で検索 ->Tシャツで検索
クエリ解釈については、下記の外部記事などで詳しく解説されています。
私たちは、上記に紹介した機能を追加した下記のような処理フローを実現することで、一層ユーザーの意図に沿った検索結果を返すことを目指しています。

おわりに
ZOZOでは検索エンジニア・MLエンジニアのメンバーを募集しています。今回紹介した検索技術に興味ある方はもちろん、幅広い分野で一緒に研究や開発を進めていけるメンバーも募集しています。
ご興味のある方は、以下のリンクからぜひご応募ください!