



こんにちは。検索基盤部の橘です。ZOZOTOWNでは、商品検索エンジンとしてElasticsearchを利用し、大規模なデータに対して高速な全文検索を実現しています。
Elasticsearchに関する取り組みは以下の記事をご覧ください。
検索基盤部では、ZOZOTOWNの検索結果の品質向上を目指し、新しい検索手法の導入を検討しています。本記事ではベクトル検索と呼ばれる検索手法に関して得た知見を紹介します。
※本記事はElasticsearchバージョン8.9に関する内容となっています。
目次
- 目次
- ベクトル検索とは
- ベクトル検索に期待すること
- Elasticsearchを使用したベクトル検索の導入
- ハイブリッド検索とは
- Elasticsearchを用いたハイブリッド検索
- ベクトル検索の定性評価
- ベクトル検索の導入に伴う課題
- まとめ
- おわりに
ベクトル検索とは
ベクトル検索とは、データを高次元のベクトル空間にマッピングし、類似性に基づいて情報を検索する技術です。
一般的なベクトル検索の方法は、ユーザーの検索クエリをベクトル化し、同じベクトル空間にマッピングされた商品データとの類似度を計算します。類似度が高い商品から順に検索結果としてユーザーに表示します。
下図において商品Aは商品Bより検索クエリとの角度が小さく、類似度が高いため、検索結果では商品Aの方が上位に表示されます。
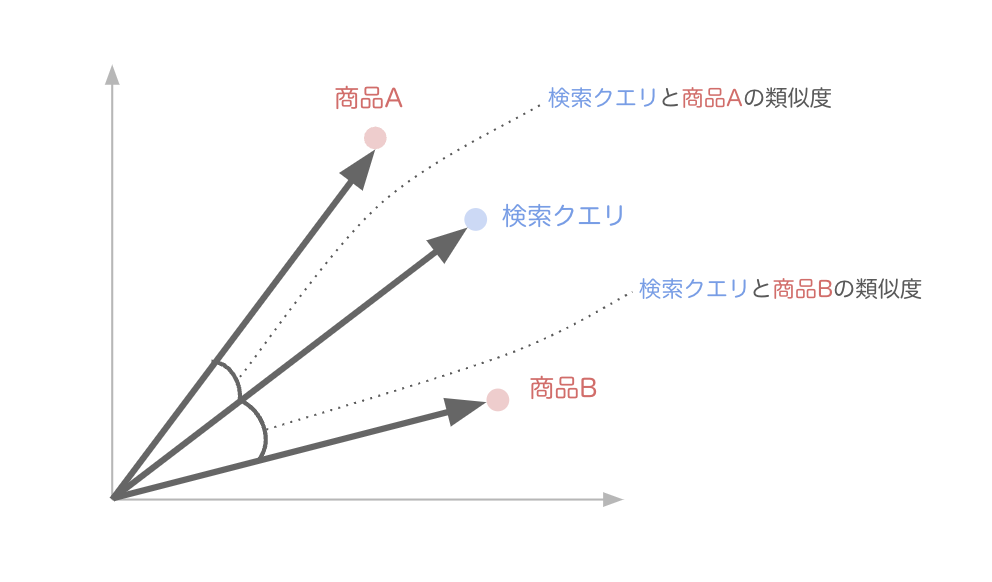
検索クエリや商品データのベクトル化には埋め込み(Embedding)モデルを利用する方法が一般的です。CLIPなどのマルチモーダルモデルを使うことで文字列データに加え画像データも同じ空間にベクトル化できます。
ベクトル検索に期待すること
ベクトル検索で特に期待できる点は、曖昧なクエリに対してより良い結果を出力できることです。
例えば、ZOZOTOWNでは次のような曖昧な検索クエリが見られます。
- ベビー用品
- きれいめワンピース
- フォーマルなスーツ
例えば「ベビー用品」という検索クエリの場合、「用品」という単語は広い意味を持ちます。全文検索では「用品」という文字が商品情報と完全に一致する必要があるため、検索結果が限定されます。
一方、ベクトル検索では「ベビー用品」という検索クエリで次のような商品を検索できます。
- ベビー服
- ベビー用おもちゃ
- ベビーカー
その他ベクトル検索に期待できる点は以下です。
- テキスト以外のデータでの検索:画像などのデータも検索に利用可能
- 表記揺れクエリに対して堅牢:検索クエリ「バック」で「バッグ」を検索可能
- 多言語への対応:検索クエリ「Tshirt」で「Tシャツ」を検索可能
Elasticsearchを使用したベクトル検索の導入
Elasticsearchは上述のベクトル検索をサポートしており、Elasticsearchでのベクトル検索導入には次のメリットがあります。
スケーラビリティ:Elasticsearchは分散アーキテクチャを採用しており、大規模なデータに対しても効率的にスケールアップできます。
高速な検索性能:ベクトル検索を含む大量のデータに対する複雑な検索を高速で処理できます。特にZOZOTOWNのように検索対象の商品数が多い場合の使用に適しています。Elasticsearch8.0以降ではHSNWをベースとした近傍検索による高速な検索が可能です。
統合された検索環境:Elasticsearchは全文検索とベクトル検索の両方をサポートしています。全文検索とベクトル検索の組み合わせで検索精度の向上が期待できます。
導入の簡略化:埋め込みモデルをElasticsearchにデプロイし、ベクトル検索導入を簡略化できます。
導入の簡略化
ベクトル検索を実現するためには検索クエリと商品データを埋め込みモデルによりベクトル化する必要があります。これらのベクトル化処理のためのバッチやAPIの開発は、ベクトル検索導入の際のハードルとなります。
Elasticsearchでは、埋め込みモデルをElasticsearchにデプロイする方法が用意されており、これによりベクトル検索の導入を簡略化できます。
詳しい導入手順は以下の記事をご覧ください。
Elasticsearchで日本語NLPモデルを利用してセマンティック検索を実現する | Elastic Blog
簡単な手順としては次の通りです。
- Elasticが提供するPythonのElasticsearchクライアントライブラリelandを使用して、Hugging Face上のモデルをアップロードしデプロイ
- インジェストパイプラインを作成し、推論プロセッサーでフィールドのデータをベクトル化しインデックスを作成
- knnクエリ(後述)のquery_vector_builderオプションを使うことで検索クエリをベクトルに変換し、類似度の高い順の検索結果のレスポンスを取得
このように、埋め込みモデルをElasticsearchにデプロイすることで、ベクトル化処理のためのバッチやAPIの開発を省略してベクトル検索を導入できます。
デプロイ可能な埋め込みモデル
ベクトル検索に使うモデルはHugging Faceに登録してあるモデルの中からFeature Extractionのタスクに対応しているモデルを選ぶ必要があります。例えば、multilingual-e5-largeが該当します。
Hugging Face上にある事前学習済みモデルをファインチューニングしたモデルも使用できます。その場合、ファインチューニングしたモデルをHugging Face上のリポジトリにアップロードし、elandを使ってElasticsearchにアップロードします。
ベクトル検索のクエリ
knnクエリを使うことにより、Elasticsearchでベクトル検索できます。
クエリ例は以下の通りです。
{ "knn": { "field": "text_embedding.predicted_value", "query_vector_builder": { "text_embedding": { "model_id": "cl-tohoku__bert-base-japanese-v2", "model_text": "shoes" } }, "k": 10, "num_candidates": 100, "similarity": 0.8, "boost": 1, "filter": { フィルタリング条件を記載 } } }
knnクエリのパラメータは次の通りです。
| パラメータ名 | 説明 |
|---|---|
| field | 検索対象のフィールド |
| query_vector_builder | ベクトル化に使うモデルidとベクトル化するテキスト |
| k | 結果出力数 |
| num_candidates | 各シャードから抽出する候補数 |
| similarity | 類似度の下限閾値 |
| boost | 類似度(スコア)に掛ける重み |
| filter | フィルタリング条件 |
ハイブリッド検索とは
上記でベクトル検索の利点を紹介しましたが、全文検索にもいくつか利点があります。
- 実装や導入が比較的容易
- 大規模な情報に対して高速な検索が可能
- 検索クエリとドキュメントのマッチ方法が明確で、結果の解釈が容易
全文検索とベクトル検索はそれぞれ利点が異なります。両方を組み合わせることで、それぞれの利点をうまく活かし、より高い検索精度を期待できます。全文検索とベクトル検索を組み合わせる検索手法は「ハイブリッド検索」と呼ばれます。
Elasticsearchにはハイブリッド検索を実現する機能が用意されています。
Elasticsearchを用いたハイブリッド検索
ここではElasticsearchを使ったハイプリッド検索のパターンをいくつか紹介します。
RRF(Reciprocal rank fusion)を使うパターン
RRFは異なる検索結果のランキングを統合し、ランキングを生成するアルゴリズムです。
RRFは以下の数式で表されます。
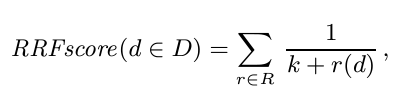
| パラメータ名 | 説明 |
|---|---|
| 統合するランキングの数 | |
| ドキュメントのランキング順位 | |
| 調整定数 | |
| ランキング対象となるドキュメントの集合 |
RRFを利用し、全文検索のランキングとベクトル検索のランキングを統合するクエリ例は以下の通りです。ベクトル検索と全文検索のランキングスコアのスケールは異なりますが、RRFを使うことでスコアのスケールを合わせる必要なくランキングを統合できます。
{ "size": 10, "query": { "term": { "text": "shoes" } }, "knn": { "field": "text_embedding.predicted_value", "k": 10, "num_candidates": 100, "query_vector_builder": { "text_embedding": { "model_id": "cl-tohoku__bert-base-japanese-v2", "model_text": "shoes" } } }, "rank": { "rrf": { "window_size": 10, "rank_constant": 1 } } }
上記のクエリでは、まずshoesという用語に一致するドキュメントを全文検索で取得し、次に同じshoesを基にベクトル検索で最も近いドキュメント上位10件を取得します。その後、全文検索とベクトル検索の結果を統合し、RRFを適用して最終的なランキングを生成しています。
RRFクエリのパラメータは次の通りです。
| パラメータ名 | 説明 |
|---|---|
| window_size | 各ランキングにおいてRRFアルゴリズムを適用する上位N件 |
| rank_constant | 各ランキング内のドキュメントが最終的なランキングにどれだけ影響を与えるかを決定する調整定数(値が高いほど、低ランクのドキュメントがより大きな影響を与える) |
rescoreを使うパターン
rescoreクエリによって全文検索とベクトル検索の結果をリランキングし統合できます。
rescoreを利用し、全文検索のランキングとベクトル検索のランキングを統合するクエリ例は以下の通りです。
{ "size": 10, "query": { "term": { "text": "shoes" } }, "knn": { "field": "text_embedding.predicted_value", "k": 10, "num_candidates": 100, "query_vector_builder": { "text_embedding": { "model_id": "cl-tohoku__bert-base-japanese-v2", "model_text": "shoes" }, "boost": 0.0001 } }, "rescore": [ { "window_size": 10, "query": { "rescore_query": { リスコアのロジックを記載 }, "query_weight": 0, "rescore_query_weight": 1.0, "score_mode": "total" } } ] }
上記のクエリでは、全文検索の結果とベクトル検索の結果を組み合わせてリスコアを行い、最終的に上位10件の結果を取得しています。また、knnクエリのboostの値を低く設定することで、全文検索の結果が優先してリスコアされるようにしています。
クエリ内でRRFとrescoreクエリは併用できないので注意が必要です。
ベクトル検索の定性評価
社内で全文検索の結果とベクトル検索の結果をオフライン定性評価しました。定性評価では、被験者がいくつかの評価用クエリに対する全文検索の結果とベクトル検索の結果を見比べて、どちらの検索結果が良いかを評価します。
ZOZOTOWNで実施している定性評価の詳細は以下の記事をご覧ください。
以下は、オフライン定性評価でベクトル検索が良い結果を出したクエリと悪い結果を出したクエリの例です。
| ベクトル検索が良い結果となったクエリ | ベクトル検索が悪い結果となったクエリ |
|---|---|
| ペット用品 きれいめドレス 小さめリュック スポーツウェアー |
いちご柄 卒業式 女の子 小学生 フォーマル ブランド名全般 キャラクター名全般 |
これらのクエリと検索結果を考察し、ベクトル検索が適用可能だった語と適用困難だった語は次の通りでした。
| ベクトル検索が適用可能だった語 | 説明 |
|---|---|
| 曖昧な語 | 「用品」「きれいめ」など曖昧なクエリに対しては近い意味の商品を検索可能 |
| 多言語 | 「小さめ」のクエリに対して「small」という語を含んだ商品を検索可能 |
| 表記揺れ | 「ウェアー」のクエリに対して「ウエア」「ウェア」という語を含んだ商品を検索可能 |
| ベクトル検索が適用困難だった語 | 説明 |
|---|---|
| 明確な語 | 「いちご柄」のクエリに対してドット柄のような商品を誤って検索 |
| 複雑な語 | 「卒業式 女の子 小学生 フォーマル」のような様々な意味を含む複雑なクエリに対して「ネクタイ」を誤って検索 |
| ドメイン性が強い語 | ブランド名やキャラクター名などドメイン性が強いクエリに対して似たブランドやキャラクターの商品を検索することは不可能 |
このようにベクトル検索が適用可能な語と適用困難な語を評価することで、どのような検索クエリに対してベクトル検索が効果的かを理解できました。
ベクトル検索の導入に伴う課題
ベクトル検索の導入を検討するにあたり、いくつかの課題がありました。代表的な内容をいくつか紹介します。
類似度の閾値設定
類似度の低い商品はクエリとは無関係である可能性があります。クエリとは無関係な商品が含まれることを防ぐために、適切な類似度の閾値を設定する必要があります。
この閾値の設定方法はいくつか考えられますが、1つの方法としてアノテーションによる閾値設定の方法が考えられます。
以下はアノテーションの例で、アノテーション結果にはクエリと商品の関連性がある場合に正解、関連性がない場合に不正解を付与します。
| クエリ | 商品 | 類似度 | アノテーション結果 |
|---|---|---|---|
| きれいめワンピース | 商品A | 0.94 | 正解 |
| きれいめワンピース | 商品B | 0.85 | 正解 |
| きれいめワンピース | 商品C | 0.65 | 不正解 |
この結果を基に、適切な類似度を設定することが可能になります。
モデルの埋め込み精度の問題
以下の表はある事前学習済みモデルを用いて、検索クエリ「ダウン」と商品名のcosine類似度を算出した結果です。
| 商品名 | 類似度 |
|---|---|
| ダウンコート | 0.67 |
| 下駄 | 0.64 |
| ダウン ティペット | 0.61 |
「ダウン」と検索された際に、「ダウンコート」と「ダウン ティペット」が検索結果に表示されるのは適当ですが、「下駄」が表示されることは望ましくありません。この場合、類似度の閾値を0.65に設定し「ダウンコート」のみを検索結果に表示するか、閾値を下げて「下駄」を含めすべて検索結果に表示するかの判断が必要です。
モデルの埋め込みに問題がある場合、検索結果に意図しない商品が含まれてしまいます。この問題を解決するには、モデルのファインチューニングなどにより出力ベクトルを最適化する必要があります。
クエリごとの類似度のばらつき
以下の図は、いくつかのクエリに対してcosine類似度が高いZOZOTOWNの商品TOP100を示しています。
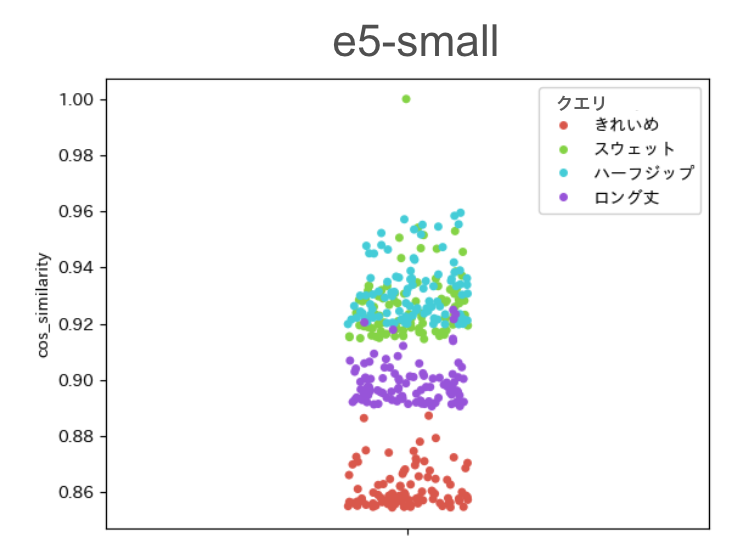
クエリごとにcosine類似度の分布にばらつきが見られます。例えば「スウェット」のクエリに対してcosine類似度の高いTop100の商品は全て類似度が0.91以上であるのに対し、「きれいめ」のクエリに対してはTop100商品すべて0.90以下になっています。
この場合、類似度の閾値の設定が難しいです。例えばcosine類似度の閾値を0.88にした場合、「きれいめ」というクエリはベクトル検索で殆ど対応できないことになります。cosine類似度の閾値をより低く設定すると、無関係な商品が検索結果に含まれる可能性が高くなります。
このように、クエリと商品によっては類似度にばらつきが発生し、類似度の閾値を一意に決めることが難しくなることに注意が必要です。この閾値を動的に変える場合は、サービス側でクエリに応じて変更する必要があります。
モデルの変化による類似度の分布の変化
利用しているモデルのパラメータを変更すると、検索クエリと商品の類似度の分布が変わります。
次の図は、e5-smallモデルとuniversal-sentence-encoderモデルでcosine類似度が高いZOZOTOWN商品TOP100をプロットした図です。
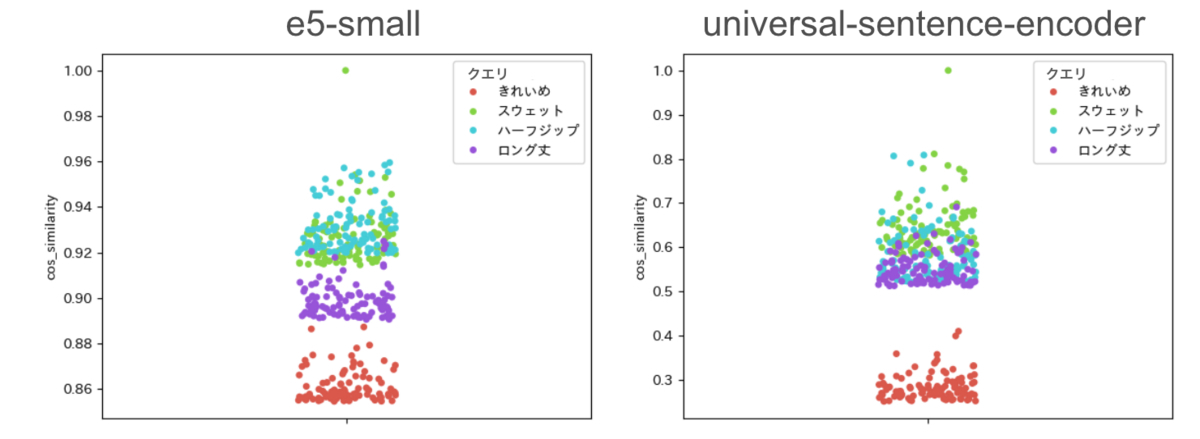 モデルによってcosine類似度の分布が異なります。モデルの変更に応じて類似度の閾値のパラメータを調整する必要があります。
モデルによってcosine類似度の分布が異なります。モデルの変更に応じて類似度の閾値のパラメータを調整する必要があります。
よって、モデルの変更に応じて類似度の閾値のパラメータを調整できるようにしておく必要があります。
まとめ
本記事ではベクトル検索の導入において得た知見をご紹介しました。ベクトル検索の導入に関しては本記事で取り上げた課題があり、現状導入には至っていませんが、引き続き検討を重ねていく予定です。
おわりに
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。