



はじめに
こんにちは。ML・データ部/推薦基盤ブロックの佐藤(@rayuron)です。私たちは、ZOZOTOWNのパーソナライズを実現する機械学習を用いた推薦システムを開発・運用しています。また、推薦システムの実績を定常的に確認するためのシステムも開発しています。本記事では、Lookerを用いて推薦システムの実績をモニタリングするシステムの改善に取り組んだ件についてご紹介します。
改善の背景と課題
背景
運用しているシステムの1つにメール配信を利用してシューズアイテムを訴求するシステムがあり、私たちのチームではユーザーが興味を惹くアイテムを推薦するための機械学習システムを開発・運用しています。この推薦システムの実績を定常的にモニタリングするために、Looker Studio(旧 Data Portal)を用いてダッシュボードを構築していました。さらに、このダッシュボードに連携するためのデータを集計するシステム「モニタリングシステム」を運用しており、以下の図で構成されます。

Vertex AI PipelinesはCloud SchedulerとCloud Functionsによって1日1回定期実行されます。Vertex AI PipelinesではBigQueryのジョブを実行し、Looker Studioのダッシュボードに表示しやすい形式でデータを整形してその結果を連携用のテーブルとして保存します。Looker Studioではこの中間テーブルからデータを取得してダッシュボードを表示しています。また、週に1度、指標の変化率を以下の様にSlackで通知していました。
メール配信数: N 件(前週比:N %) 週間売上: N 円(前週比:N %) 1配信あたり流入数: N 件/配信(前週差:N pt) 1配信あたり注文数: N 件/配信(前週差:N pt) 1配信あたり売上: N 円/配信(前週差:N pt)
Vertex AI Pipelinesは一般的に機械学習システムのワークフロー管理ツールとして使用されますが、私たちのチームでは推薦システムの実績をモニタリングする用途でも使用しています。Vertex AI Pipelinesの導入事例については過去のテックブログでも紹介していますのでご参照ください。
課題
モニタリングシステムを運用してみて課題となったのは、指標の異常に気付くのが遅れたり、そもそも気付かないことでした。これまでは人が能動的にダッシュボードを見に行かなければ指標の異常に気づけないという状況でした。
課題解決のために
結論を申し上げると、上記課題を解決するためにVertex AI PipelinesとLooker Studioで構築していたモニタリングシステムをLookerを使用したシステムに置換しました。ここからは代替となるシステムを検討する際の3つの要件をご紹介します。
要件1. 指標異常時の自動アラート
課題の通り、指標の異常に気づくためには人がダッシュボードを見る工程が必要でした。この工程を自動化するため、指標異常時にはアラートを自動的に通知する仕組みを実現する必要があります。異常値の定義の方法には統計学や機械学習を用いる方法がありますが、今回は簡単な閾値の判定で異常値の検知をします。
要件2. サマリの定期配信
要件1を満たすことで明らかな異常値に気づくことはできるものの、こうした閾値判定だけでは中長期的な変化を捉えることができないため、少なからず人の目での定期的なチェックが必要です。また、プロダクトを管理するという観点で指標のトレンドを把握する必要があります。
要件3. 上記2つをSlack通知できること
また、私たちのチームでは通知をSlackで受け取るため上記2つをSlackに通知することが要件となります。
ダッシュボードの候補の比較
部署内では、ダッシュボードとしてLooker、Looker Studio、スプレッドシートを使用しています。そこで、活用事例があるこれらのサービスを使用して要件を満たすシステムが実現できないかを考えました。
| 要件 | Looker | Looker Studio | スプレッドシート |
|---|---|---|---|
| 1. 指標異常時の自動アラート | ○ | x | x |
| 2. サマリの定期配信 | ○ | ○ | x |
| 3. 上記2つをSlack通知できること | ○ | x | x |
スプレッドシートは標準機能で要件を満たさず、Looker Studioは要件2のサマリをメールで送ることができましたが、Slackには通知できませんでした。そのため、全ての要件を満たしたLookerを採用することに決めました。
要件を満たすための設計
上記の要件を実現するためにシステム設計をしました。Lookerのダッシュボードやアラートの細かな設定をすべてGitHubでバージョン管理できるようにすることと設定追加の拡張性を重視しています。
要件の実現方法
Lookerの標準機能を用いて指標異常時の自動アラートとサマリの定期配信のSlack通知を実現します。以下の図のシステム構成を考えました。

アラートと定期配信に関するyamlの設定ファイルを作成し、GitHub Actions上でLooker APIを使ってそれらの情報を設定します。アラートとサマリの定期配信の設定はLookerのUIからできますが、設定数の増大を想定してLooker APIを用います。
開発環境と本番環境
動作確認のために開発環境と本番環境に分け実装します。Lookerのインスタンスを2つ使用し、以下の図のような構成にしました。

Looker IDEからアラートと定期配信の対象となるダッシュボードのために必要なファイルを実装します。アラートと定期配信に関するyamlの設定ファイルに関しては、Looker IDE上でyamlが編集できないため、ローカルPCからPull Requestを作成します。GitHubとLookerのWebhookの設定とブランチの設定をすることで、それぞれのLookerインスタンスがGitHubの変更を反映するようにします。環境毎のブランチとGitHub Actionsの設定についてまとめると以下の様になります。
| 環境 | ブランチ | トリガー | 実行内容 |
|---|---|---|---|
| 開発環境 | main | feature branchを main branchにmerge |
設定ファイル記載のアラートの登録 設定ファイル記載の定期配信の登録 |
| 本番環境 | release | main branchを release branchにmerge |
設定ファイル記載のアラートの登録 設定ファイル記載の定期配信の登録 |
実装
このセクションでは上記で説明した設計の具体的な実装について説明します。
- ディレクトリ構成
- ダッシュボード
- GitHub Actions
ディレクトリ構成
ディレクトリ構成は以下です。異なるダッシュボードで同じLookMLファイルを参照する場合を考え、LookMLファイルを再利用しやすくするようにディレクトリを分けています。
.
├── .github
│ └── workflows
│ ├── main-push.yaml
│ ├── main-merge.yaml
│ └── release.yaml
├── README.md
├── config
│ └── project_name
│ ├── alert.yaml
│ └── scheduled_plan.yaml
├── dashboards
│ ├── *.dashboard.lookml
├── explores
│ ├── *.explore.lkml
├── models
│ └── *.model.lkml
├── scripts
│ ├── compare_dashboards.py
│ ├── set_alert.py
│ └── set_scheduled_plan.py
├── tests
│ └── *.test.lkml
└── views
└── *.view.lkml
ディレクトリ名と詳細は以下です。
| ディレクトリ名 | 詳細 |
|---|---|
| .github | GitHub Actionsの設定ファイル |
| README.md | READMEファイル |
| config | アラートと定期配信の設定ファイル |
| dashboards | LookML Dashboardファイル |
| explores | Lookerのexploreファイル |
| models | Lookerのmodelファイル |
| scripts | CIのスクリプト |
| tests | Lookerのtestファイル |
| views | Lookerのviewファイル |
ダッシュボード
指標異常時の自動アラートとサマリの定期配信は指定されたダッシュボードに対して行われるため、ダッシュボード構築が必要となります。
ダッシュボード構築の流れ
Looker内で定義できるダッシュボードにはユーザー定義ダッシュボードとLookML Dashboardの2種類があります。以下の表でそれぞれを簡単に比較します。2つのダッシュボードについてより詳細な比較は公式ドキュメントをご参照ください。
| 種類 | ダッシュボードの作成方法 | 編集可能なユーザー |
|---|---|---|
| ユーザー定義ダッシュボード | UIから作成 | ビジネスユーザーとLookerデベロッパー |
| LookML Dashboard | ファイルで定義 | Lookerデベロッパーの選択したグループ |
ユーザー定義ダッシュボードはビジネスユーザーにも編集権限があります。ビジネスユーザーが意図せずダッシュボードに変更を加えてしまうことを回避するために最終的にLookML Dashboardを使用します。
以下の流れでLookML Dashboardを構築します。
- Looker IDEからview、model、exploreファイルを定義
- Explore UIからユーザー定義ダッシュボードを作成
- ユーザー定義ダッシュボードをLookML Dashboardに変換
詳細については以下の公式ドキュメントをご参照ください。
配信実績に関して
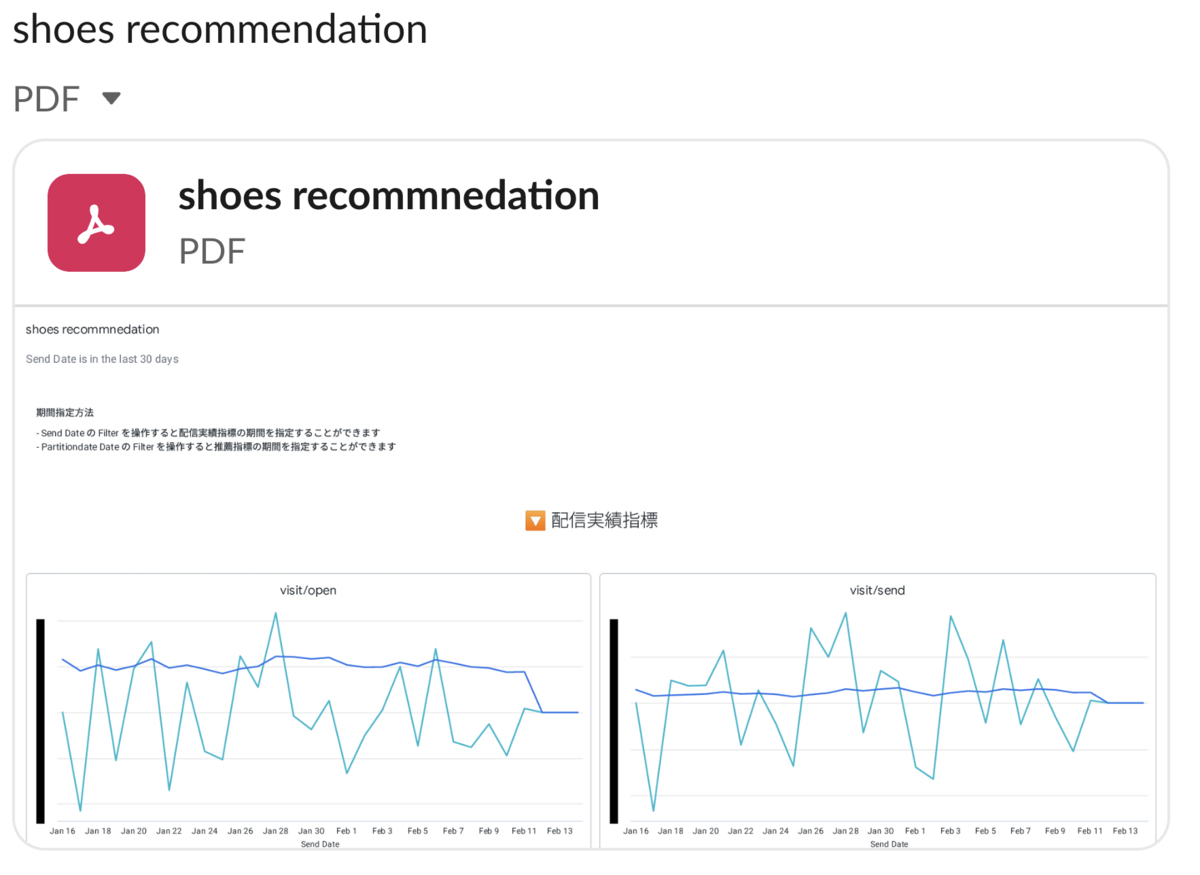
メール経由の注文率などの配信実績に関しては実績値と変化率を折れ線グラフで表示します。さらにそれらの指標を性別と年代別に分けてプロットしました。以下はダッシュボードの一例です。
メール流入率

世代別のメール流入率

推薦結果に関して
今回の改善に伴い、推薦を作成したユーザーの世代別割合やユーザーが推薦される商品画像の一部など推薦結果に関わる指標もモニタリング対象としました。
推薦を作成したユーザーの世代別割合

推薦される商品画像の一部

GitHub Actions
指標異常時の自動アラートとサマリの定期配信の設定についてGitHub Actionsを使用して実装します。
1. 指標異常時の自動アラート
アラートの設定用に以下のようなyamlファイルを作成し、CI実行時に内容をLookerへ登録します。
- lookml_dashboard_id: kpi_monitoring_shoes::shoes_recommendation alerts: - lookml_link_id: visit/open cron: "0 10 * * *" name: mail_result.visit_per_open lower: 0.1 upper: 0.5 - lookml_link_id: recommend_generation cron: "0 10 * * *" name: generation lower: 0.01 upper: 0.1 field_name: member.age_tier field_value: 19 to 22 ...
それぞれのパラメーターで指定できる内容は以下です。
| パラメーター | 内容 |
|---|---|
| lookml_dashboard_id | ダッシュボードのID |
| alerts | -- (alerts配下に情報を記載) |
| lookml_link_id | ダッシュボードの要素のID |
| cron | アラートのスケジュール |
| name | モニタリングする指標の列 |
| lower | 下限閾値 |
| upper | 上限閾値 |
| field_name | ピボットテーブルを使用した場合のモニタリングする指標の列 |
| field_value | ピボットテーブルを使用した場合のモニタリングする指標の値 |
上記のパラメーターにモニタリングしたい指標の情報を記述すると、CI実行時に設定が登録され同じタイミングですでに登録されていた設定を削除します。アラートのSlack通知のイメージは以下です。

2. サマリの定期配信
サマリの定期配信の設定用に以下のようなyamlファイルを作成し、CI実行時に内容をLookerへ登録します。
- lookml_dashboard_id: kpi_monitoring_shoes::shoes_recommendation_weekly cron: 0 10 * * thu title: shoes_recommendation_weekly slack_message: shoes_recommendation_weekly format: wysiwyg_png - lookml_dashboard_id: kpi_monitoring_shoes::shoes_recommendation_monthly cron: 0 10 4 * * title: shoes_recommendation_monthly slack_message: shoes_recommendation_monthly format: wysiwyg_png ...
それぞれのパラメーターで指定できる内容は以下です。
| パラメーター | 内容 |
|---|---|
| lookml_dashboard_id | ダッシュボードのID |
| cron | 定期配信のスケジュール |
| title | 定期配信のタイトル |
| slack_message | 定期配信時のメッセージ |
| format | 通知時のファイル形式 |
上記のパラメーターに定期配信したいダッシュボードの情報を記述すると、CI実行時に設定が登録され同じタイミングですでに登録されていた設定を削除します。定期配信のSlack通知のイメージは以下です。

工夫した点と苦労した点
全体を通して工夫した点と苦労した点を以下で説明します。
工夫した点
サマリの定期配信のフォーマット
当初は時系列のグラフをSlackに通知することを考えていましたが、視認性の向上のため最低限の指標を載せたシンプルなダッシュボードを定期配信するようにしました。PDFよりもロードが早いPNG形式で表示し、Slackの画像をワンクリックすることで指標を確認できるようにしました。具体的には変更前と変更後でSlack通知の様子は以下の様に異なります。
変更前
変更後

苦労した点
アラートの閾値の決め方
アラートの閾値の決め方に現状も苦労しています。配信実績の閾値はプロジェクトメンバーと議論することにより共通認識を持つことができます。一方、機械学習タスクは問題設定が様々であったり、モデルが時として人間の直感に反した結果を返したりするため、閾値決めは難しいものと考えています。この点は今後の検討事項としています。
改善の効果
これまで説明してきたシステムを構築することで、以下の2つの効果を得られました。
1つ目は、指標の異常時に自動で気づく体制ができたことです。以前は、指標の異常に気付くためには人による指標のモニタリングというオペレーションが必要でした。アラート機能を実装したことによって、指標の異常時に自動的に気付く体制ができました。
2つ目は推薦を以前より高い解像度で説明できる様になったことです。思わぬ効果でしたが、モニタリングする指標が増えたことでどのようなユーザーにどのようなアイテムが推薦されているかを以前より高い解像度で認識できました。これによりユーザーやアイテムの簡単な傾向をアドホック分析なしに定常的に確認できる様になりました。
今後の展望
実装を終えてみて、今後の展望は大きく以下の4つです。
1つ目は異常値のアラートに関してです。季節の影響を強く受けるファッションドメインで、常に同じ閾値で異常値を判定することは正しい状態かを考える余地があります。また、アラートが通知された後の意思決定フローについても考える必要があります。
2つ目はサマリの定期配信に関してです。定期配信は形骸化してしまう可能性が大いにあるので、今後形骸化しない方法を考える必要があります。
3つ目はダッシュボードに載せる指標に関してです。今回は配信実績と推薦結果に関わる指標をメインでダッシュボードに載せました。一方で、今回の改善を通してLookerで機械学習モデルに関わる指標をモニタリングできると感じたので、今後検証していきたいと考えています。
4つ目はOSSとしての公開です。本記事で紹介したモニタリングシステムは将来的にOSSとして公開することを考えています。
おわりに
本記事では機械学習を用いた推薦に関するモニタリングシステムの改善の話をしてきました。現在ZOZOではパーソナライズを強化している最中で、今回の話で挙がった推薦をモニタリングするシステムの構築もその一環です。推薦に関わるエンジニアを募集しているので、ご興味がある方は是非以下のリンクからご応募ください!