



こんにちは。検索基盤部の山﨑です。検索基盤部では、ZOZOTOWNの検索機能の改善を目的とした施策の有効性をA/Bテストで検証しています。
A/Bテストは、新たな施策の有効性を評価する手法として信頼性の高い手法ではあるものの、下記のような制約があります。
- 統計的に有意な差が出るためには、多くのユーザーからのフィードバックが必要である
- 比較手法を実際のユーザーに提示するため、ユーザー体験に悪影響を与えるリスクがある
これらの制約から、実験したい全ての施策をA/Bテストで検証することは困難なため、事前に有効な可能性が高い施策に絞った上でA/Bテストに臨むことが大切です。
事前に有効な可能性が高いことを示すためには、オフラインでの評価結果を活用します。しかし、オフライン評価とA/Bテストの結果は必ずしも一致しないことが知られており、ZOZOTOWNにおいても同様の問題が発生しています。
このような課題に対しては、反実仮想機械学習の分野で研究されているOff-Policy Evaluation(OPE: オフ方策評価)が有効であると考えられます。OPEについての詳細は、下記の記事を参照してください。
本記事ではOPEの詳細を説明しませんが、OPEの考え方を踏まえながら、オフライン評価とA/Bテストの結果が一致しない問題に対しての実践的な対応策について紹介します。
まず、ZOZOTOWN検索においてオフライン評価とA/Bテストの結果が一致しない問題と、その実践的な対応策を解説します。そしてデータの選択バイアスを中心に、この問題の解決策をいくつか紹介します。
目次
オフライン評価とA/Bテストの結果が一致しない問題
オフライン評価結果とKPI(ここでは、A/Bテストの結果とKPIを同義に扱います)が一致しない問題は、多くの研究で報告されています。
例えば、Bernardi et al, KDD 20191ではオフライン評価の改善率とA/Bテストでのコンバージョン率の改善率を比較したところ、それらの結果が相関しないことを報告しています。
相関しない理由として、KPIの代理変数を過剰最適してしまうことやA/Bテストという短期間でビジネスインパクトに影響のある変更の検知が難しいことなど、幾つかの要因が挙げられています。
同様にZOZOTOWNにおける検索改善の施策でのランキングベースのオフライン評価とA/Bテストを比較した結果を下図に示します。x軸がオフライン実験での購入ベースのnDCG(nDCGの詳細は次章の説明を参照してください)の改善率、y軸がA/Bテストでの商品購入率の改善率です。

この図の示す通り、1つのオフライン評価とA/Bテスト結果が必ずしも相関しない問題はZOZOTOWNの検索改善においても発生しています。
この問題を解決するための研究は今も盛んに研究されていますが、ユーザーの行動ログの様々なバイアスの問題ゆえに、根本解決が難しい問題です。そのため、まずはオフライン評価とA/Bテストの結果は一致しないという前提で、それぞれの評価手法の特性を活用する方針で進めました。
オフライン評価でのnDCGの弱点とそれを補う評価指標
nDCGは情報検索の評価指標として広く使われている指標ですが、過去に一度でもクリック/購入されている商品や検索クエリしか評価できないという弱点があります。この問題はD. Turnbull, BSM 20232でも取り上げられています。
実際にZOZOTOWNでも数%程度の検索クエリにしか購入のイベントが発生していないため、前章で紹介した「購入ベースのnDCG」では、この数%の検索クエリしか評価できていないことが分かりました。
この弱点を補うためには、購入イベントが発生していない検索クエリに対しても評価できるような評価指標が必要です。
我々はこの評価指標として、nDCGのような順序を評価するランクベースの指標の他に、検索結果を集合として扱う集合ベースの評価指標を採用しました。詳細はZOZOTOWN検索の精度評価への取り組みの記事で紹介していますが、概括として下記2つの指標を使用します。
- 購入数カバー率: 購入イベントが発生している商品をどれだけカバーできているか(通常の再現率を購入数に重み付けした指標)
- 商品一覧の類似度: 旧ロジックと新ロジックが表示する商品の一覧がどれだけ類似しているか
購入数カバー率が高く商品一覧の類似度が低い場合、新ロジックが旧ロジックではカバーできていない、かつ購入確率の高い商品をカバーできる可能性が高いことを示しています。
商品の絞り込みロジックを改善した場合に、これらの指標を活用することで有効な可能性が高い施策を絞れます。
ヘルスチェックとしてのオフライン評価指標の活用
前節で紹介した各オフライン評価指標の考え方を整理すると、下記のようになります。
| 評価指標 | 悪化した場合 |
|---|---|
| nDCG | 機械学習モデルが適切に学習できていない可能性がある |
| 購入数カバー率 | 検索結果が悪化する可能性がある |
| 商品一覧の類似度(類似していないほど良い) | 検索結果がほぼ同じ結果となる可能性がある |
ZOZOTOWNの検索改善では、これらの評価結果をA/Bテストに進むかの判断軸として活用しています。
ただし、オフライン評価はあくまでヘルスチェックとして活用し、実際のビジネスインパクトはA/Bテストで検証する方針を採用しています。Bernardi et al, KDD 2019やD. Turnbull, BSM 2023と同様の考え方を採用しています。
つまり、これらの指標はあくまで大幅な悪化が無いことを確認することで、想定外の施策内容をA/Bテストに進めることを防ぐことを目的としています。
本章では、オフライン評価とA/Bテストの結果が必ずしも一致しない問題に対しての実践的な対応策について紹介しました。次章では、結果の乖離が発生するのかを分析する目的で、特にデータの選択バイアスに着目した評価手法と実験結果について紹介します。
データの選択バイアスを考慮したオフライン評価手法
ランキング学習の機械学習モデルの学習方法は、人手でラベルづけしたデータを用いる方法と、ユーザーの行動ログを用いる方法があります。
人手でラベルづけしたデータを用いて学習する場合、データの選択バイアスを考慮する必要がありませんが、データの収集にコストがかかります。
ユーザーの行動ログを使用することでデータ収集コストを下げられますが、そのデータは観測・未観測の傾向が異なる、いわゆるMNAR(Missing Not At Random)と呼ばれるデータです。
MNARなデータでは、例えばポジションバイアスと呼ばれる、検索結果の上位に表示された商品の方が観測されやすいという選択バイアスが存在します。
本章では、このようなユーザーの行動ログに含まれるデータの選択バイアスを考慮したオフライン評価手法について紹介します。
一般的な情報検索の評価指標
まず、情報検索の評価指標で広く使われているnDCG(normalized Discounted Cumulative Gain)と MRR(Mean Reciprocal Rank)について説明します。
検索クエリに対して商品の一覧が返されるとき、
を
に対する
番目の商品の関連性スコアと定義します。
関連性スコアは任意に定義でき、例えばユーザーがその商品を購入したら1で、クリックしなかったら0などを指定できます。
このとき、に対する
番目までの検索結果を評価するための指標としてDCG (Discounted Cumulative Gain) を求めます。DCGはC. Burges et al, ICML 20053の定義に従うと、以下のように定義されます。
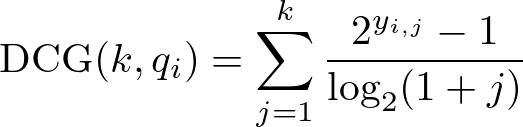
さらに、関連性スコアが高い商品から順番に並べた理想的なランキングにおけるDCGをmax DCGとします。このとき、nDCGは全てのクエリにおけるmax DCGで正規化済みのDCGを合算することで、下記のように定義されます。

次に、検索クエリに対して、最初に関連性スコアが1となる商品のランクを
とすると、MRRは以下のように定義されます。

MRRのような逆数の平均値を計算する手法は、順序尺度の平均値を計算しているため、情報検索の評価指標として適切な結果とならないケースがあることに注意してください。
直感的な理由として、ランキングの順位が1番目と2番目の差はである一方で、2番目と3番目の差は
となり、MRRは上位のランクを過剰に評価してしまうためです。
平均値を計算するためには、順序尺度ではなく間隔尺度などの数量データを使用する必要があります。
例えば、M. Ferrante et al, IEEE 20214では、MRRを適切な間隔尺度にマッピングした上で評価した場合と比較して、30%以上の結果が変わることを報告しています。nDCGも同様の問題があるもののMRRほど深刻ではないことが報告されています。
本記事ではこの問題についての詳細を割愛しますが、興味のある方は上記の論文やN. Fuhr, SIGIR 20205を参照してください。
選択バイアスを考慮した情報検索の評価手法
近年、前節で紹介したnDCGやMRRに対して選択バイアスを考慮するように拡張した評価手法が提案されています。
X. Wang et al, SIGIR 20166では、選択バイアスを考慮したMRRの拡張手法を提案しています。また、L. Yan et al, SIGIR 20227やY. Zhang, KDD 20238では、選択バイアスを考慮したnDCGの拡張手法を提案しています。
どちらも、Inverse Propensity Score(IPS: 逆傾向スコア)と呼ばれる推定量を用いて、バイアスを軽減した評価指標を定義しています。IPSは傾向スコア(Propensity Score)と呼ばれる推定量を活用します。
検索の文脈において傾向スコアは、例えば、ポジションごとの商品の見られ易さと定義できます。この傾向スコアの逆数を使用することで、ポジションによる見られ易さ、すなわちポジションバイアスを軽減できます。
ここで、を
の観測頻度、傾向スコア
を
が実際に表示されたときのクリック率と定義します。つまり、
のポジションが上位なほど、高い値を取る傾向があります。
傾向スコアを用いると、IPS推定量はと表せます。
このIPS推定量を用いて、選択バイアスを考慮したIPSMRRは以下のように拡張されます。

また、ポジションごとのIPS推定量を
と定義すると、選択バイアスを考慮したIPSDCGは以下のように拡張されます。

IPSDCGをnDCGのDCGに適用することで、選択バイアスを考慮したIPSnDCGを定義できます。
実際に過去にZOZOTOWN上でA/Bテストを行ったモデルの評価をIPSMRRで再評価しました。特にポジションバイアスを軽減したモデルとそうでないモデルの比較に対して、通常のnDCGよりもA/Bテストの結果に相関する傾向を観測できました。
インターリービングを活用した情報検索の評価手法
最後に、オフライン評価とA/Bテストの結果が一致しない問題に対して、インターリービングを活用している事例を紹介します。
インターリービングは、2つのランキング結果を混ぜ合わせて1つのランキング結果を生成する手法です。インターリービングについての詳細はEffective Online Evaluation for Web Search9で詳しく解説されています。
F. Radlinski and N. Craswell, SIGIR 201010では、nDCGとインターリービングでのモデルの良し悪しの傾向が強く相関することを示しています。
また、Wang et al, SIGIR 202311でも、nDCGとインターリービングの結果がほぼ一致していることを示しています。
このことから、インターリービングを活用することで、オフライン評価とA/Bテストの結果が一致しない問題に対して、より信頼性の高い評価手法を構築できる可能性があります。
まとめ
本記事では、オフライン評価とA/Bテストの結果が一致しない問題に対しての実践的な対応策と、特にデータの選択バイアスを考慮することでこの問題を軽減する方法について紹介しました。
データの選択バイアス削減や反実仮想な機械学習を導入することで、より性能の高いモデルや事前のオフライン検証を進めることを期待できます。
おわりに
ZOZOでは検索エンジニア・MLエンジニアのメンバーを募集しています。今回紹介した検索技術に興味ある方はもちろん、幅広い分野で一緒に研究や開発を進めていけるメンバーも募集しています。
ご興味のある方は、以下のリンクからぜひご応募ください!
参考文献
- Bernardi, L., Mavridis, T., & Estevez, P. (2019, July). 150 successful machine learning models: 6 lessons learned at booking. com. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining (pp. 1743-1751).↩
- Doug Turnbull. (2023, October). NDCG IS OVERRATED. Berlin Search Meetup.↩
- Burges, C., Shaked, T., Renshaw, E., Lazier, A., Deeds, M., Hamilton, N., & Hullender, G. (2005, August). Learning to rank using gradient descent. In Proceedings of the 22nd international conference on Machine learning (pp. 89-96).↩
- Ferrante, M., Ferro, N., & Fuhr, N. (2021). Towards meaningful statements in IR evaluation: Mapping evaluation measures to interval scales. IEEE Access, 9, 136182-136216.↩
- Breuer, T., Ferro, N., Fuhr, N., Maistro, M., Sakai, T., Schaer, P., & Soboroff, I. (2020, July). How to measure the reproducibility of system-oriented IR experiments. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 349-358).↩
- Wang, X., Bendersky, M., Metzler, D., & Najork, M. (2016, July). Learning to rank with selection bias in personal search. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval (pp. 115-124).↩
- Yan, L., Qin, Z., Zhuang, H., Wang, X., Bendersky, M., & Najork, M. (2022, July). Revisiting two-tower models for unbiased learning to rank. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 2410-2414).↩
- Zhang, Y., Yan, L., Qin, Z., Zhuang, H., Shen, J., Wang, X., ... & Najork, M. (2023, August). Towards Disentangling Relevance and Bias in Unbiased Learning to Rank. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (pp. 5618-5627).↩
- Drutsa, A., Gusev, G., Kharitonov, E., Kulemyakin, D., Serdyukov, P., & Yashkov, I. (2019, July). Effective online evaluation for web search. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 1399-1400).↩
- Radlinski, F., & Craswell, N. (2010, July). Comparing the sensitivity of information retrieval metrics. In Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval (pp. 667-674).↩
- Xiaojie Wang, Ruoyuan Gao, Anoop Jain, Graham Edge, and Sachin Ahuja. 2023. How well do offline metrics predict online performance of product ranking models? In Proceedings of the 46th International ACM SIGIR conference on Research and Development in Information Retrieval.↩