



はじめに
ML・データ部推薦基盤ブロックの佐藤(@rayuron)です。私たちはZOZOTOWNのパーソナライズを実現するために、機械学習モデルとシステムを開発・運用しています。本記事ではクーポン推薦のための機械学習モデルとシステム改善に取り組んだ話を紹介します。
背景
ZOZOTOWNでは一部の提携するショップで使用可能なクーポンが発行されます。クーポンが発行されていることをユーザーに知らせるため、メールやPush通知のチャネルを通してクーポン対象のショップとアイテムの訴求を行なっています。以下はメール配信のイメージ画像です。
クーポン対象となるショップおよびアイテムが決まっている条件下において、メール配信の対象者と推薦ショップ、推薦アイテムを決定するために機械学習モデルとシステムを運用しています。以降、この機械学習モデルをクーポン推薦モデルと表現して紹介します。
課題
既存のクーポン推薦モデルとシステムには以下の課題がありました。
1. 古い基盤でシステムが運用されている
弊社の機械学習パイプラインはVertex AI Pipelinesを標準としているのですが、既存のクーポン推薦のパイプラインは標準化前のCloud Composerで運用されていました。Vertex AI Pipelinesは運用を簡易化するために内製の整備が進んでいる一方、Cloud Composerは整備されていないため運用業務が煩雑で時間を要します。さらにCloud Composerで機械学習パイプラインを作成している社員がほぼいないので属人性が高いという課題がありました。
2. KPIに改善の余地がある
前述の様にクーポン推薦モデルでは配信対象者の選定、ショップ推薦、アイテム推薦という3つの観点を考えます。

各観点に対する既存のアプローチは以下の通り大部分がルールベースのロジックで構成されているため、機械学習モデルに置き換えることでKPIを改善できると考えられます。
| 推薦の観点 | 既存のアプローチ |
|---|---|
| 配信対象者の選定 | Matrix Factorizationとルールベース |
| ショップ推薦 | ルールベース |
| アイテム推薦 | ルールベース |
3. 機械学習モデルの評価体制がない
既存システムでも配信対象者の選定で機械学習モデルが利用されていますが、その当時は現在ほどMLOpsが整備されていなかったため、機械学習モデルを評価する体制がありませんでした。モデルやデータに変更がある際に精度の変化を確認できないためモデルの改善サイクルを回しにくく、意図せず低品質なモデルをデプロイしてしまう危険性がありました。
課題解決のために
上記の課題解決のために以下の3つに取り組みました。
- Vertex AI Pipelinesへの移行
- Two-Stage Recommenderの導入
- 機械学習モデルの評価と体制整備
1. Vertex AI Pipelinesへの移行
既存のシステムはCloud Composer上で機械学習パイプラインを構築していたため、現在弊社で機械学習基盤として利用されているVertex AI Pipelinesへ移行しました。移行に際し、2021年に公開した「Kubeflow PipelinesからVertex Pipelinesへの移行による運用コスト削減」という記事で今後の展望として挙げられていたパイプラインテンプレートを利用しています。パイプラインテンプレートはGitHubのテンプレートリポジトリ機能を利用し、Vertex AI Pipelinesの実行・スケジュール登録・CI/CD・実行監視等をテンプレート化したものです。以下のテックブログでもVertex AI Pipelinesの導入事例についてご紹介しているので是非ご覧ください。
techblog.zozo.com techblog.zozo.com
2. Two-Stage Recommenderの導入
KPIを改善するために、推薦分野で広く利用されているTwo-Stage Recommenderという推薦手法を導入します。このモデルアーキテクチャは推薦に関するコンペティションの上位解法でよく使用されており、最近だとKaggleのH&M Personalized Fashion Recommendationsなどで使用されていました。その名の通りCandidate GenerationとRerankingという2つのステージで構成されています。ユーザーとアイテムの全ての組み合わせに対するスコア計算が困難な場合に、ユーザーとアイテムに対するスコアの計算を一部の組み合わせに限定できます。
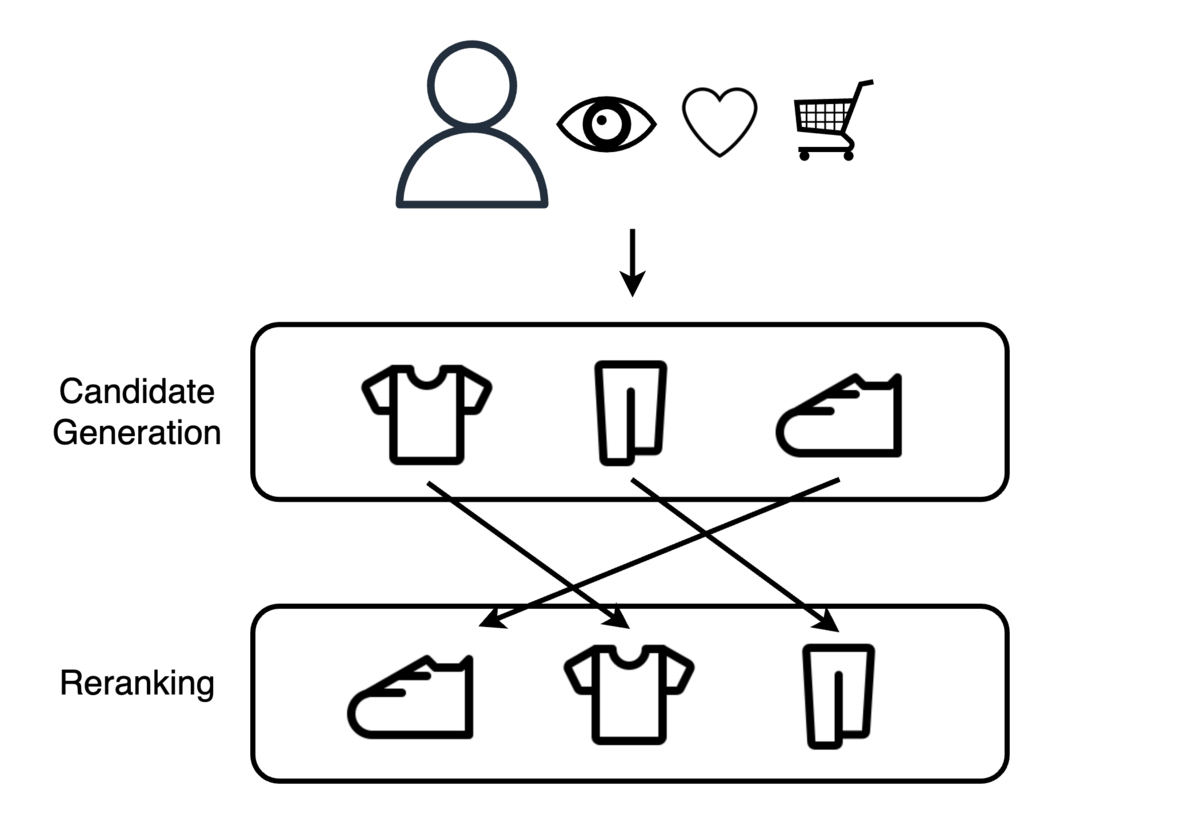
Two-Stage Recommenderは以下の工程で推薦を実現します。
- Candidate Generationステージで、ユーザーと関連度の高いアイテムの集合を取得する
- Rerankingステージで、取得したアイテムをユーザーの関心度に基づいて並べ替える
プロジェクトへの導入
本プロジェクトでは前述の3つの推薦の観点を以下の様に変更します。
| 推薦の観点 | 変更前のアプローチ | 変更後のアプローチ |
|---|---|---|
| 配信対象者の選定 | Matrix Factorizationとルールベース | Two-Stage Recommender |
| ショップ推薦 | ルールベース | Two-Stage Recommender |
| アイテム推薦 | ルールベース | ショップ推薦を考慮したルールベース |
配信対象者の選定とショップ推薦では同一のTwo-Stage Recommenderを使用しています。配信対象者の選定ではユーザー毎にTwo-Stage Recommenderのスコアの最大値を集計し、集計値が高い上位Nユーザーを配信対象とします。ショップ推薦ではTwo-Stage Recommenderのスコアが大きい順にショップを掲載します。アイテム推薦ではショップ推薦を考慮したルールベースのロジックを使用しますが、本記事では取り上げません。
ZOZOTOWNに出店しているショップは複数のブランドを取り扱うことがあるため、同じショップ内でもブランドによってユーザーの興味は異なるという仮説をモデルに反映します。以上を踏まえて、以下では本プロジェクトのTwo-Stage Recommenderの詳細について説明します。
Candidate Generation
Candidate Generationステージではユーザー、クーポン対象ショップ、取り扱いブランド、日付の組み合わせを取得します。
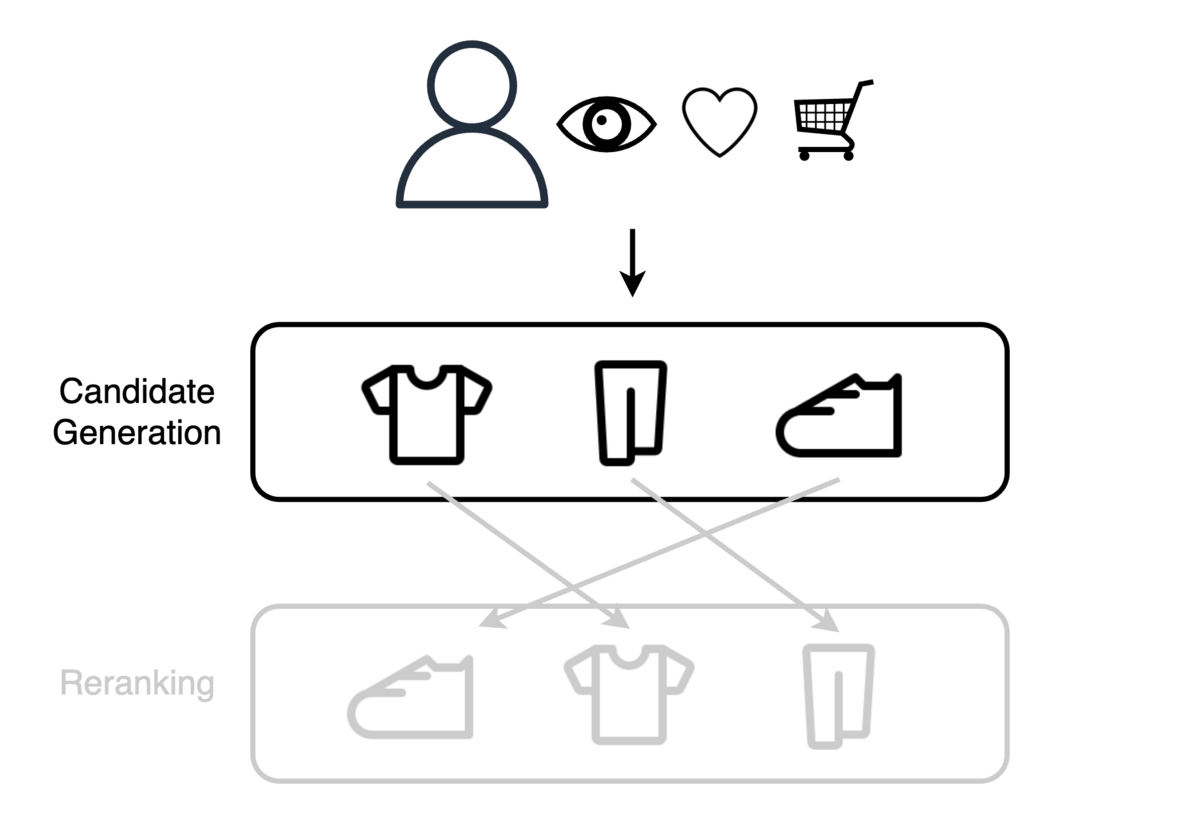
以下の3つの軸を考慮してCandidate Generationを行いました。
- 過去の実績
- 人気ブランド
- 興味を持っているブランドの類似ブランド
1. 過去の実績
リターゲティング施策はコンバージョンにつながりやすいことが分かっているため、ユーザーのお気に入りブランドと過去N日間で閲覧したアイテムのブランドを推薦候補とします。
2. 人気ブランド
トレンドを考慮した推薦をするため、性年代別の人気ブランドの上位N件を取得しユーザーに紐付けます。
3. 興味を持っているブランドの類似ブランド
多様性のある推薦をするため、ユーザーが閲覧したブランドを元に以下の手順で類似ブランドを取得します。
- ユーザーのブランドに対する行動を学習データとしたMatrix Factorizationモデルを学習
- 学習の中間生成物であるブランドのEmbeddingを取得
- Embeddingから全ブランド同士のコサイン類似度を計算
ライブラリはLightFMを使用しています。指定可能なLogistic、BPR、WARPのロスを変えた時の精度を比較し、最終的には次項で説明する評価指標が最も良かったWARPロスを使用しました。
評価方法
Candidate Generationの評価は後述する全レコード数に対するRerankingモデルの正例の割合を使用します。使用データの日数や人気ブランドの取得件数などのパラメータは正例の割合と推薦に必要な最低ユーザー数を考慮して決定します。
Reranking
RerankingステージではCandidate Generationステージで取得した組み合わせを使用して、ユーザーが興味を持つ順番でクーポン対象ショップ、取り扱いブランドを並び替えます。

学習データの作成
ユーザーのブランドへの興味を数値化しランク付けをしたいのですが、興味を直接数値化することは困難です。そこで、ユーザーのブランドへの興味をアイテム閲覧データを用いて表現します。閲覧アイテムに紐づくブランドを取得し、アイテム閲覧データをブランド閲覧データに変換します。これをCandidate Generationで取得したデータに紐付けることでZOZOTOWN会員が次の日にあるブランドを閲覧することを正例とした学習データを作成します。ブランド推薦をメール配信以外でも展開したいという要件があったため、クーポン施策に関わるユーザー行動を正例とするのではなくZOZOTOWN全体のユーザー行動を正例としています。
アンダーサンプリング
前述の通りに学習データを作成するとCandidate Generationで取得したレコードでは正例の割合が1〜2%程度となります。学習時間の短縮と不均衡データへの対処を目的とし、学習と検証データに負例のアンダーサンプリングを行いました。後述するオフライン評価指標が低下しないことを確認し、最終的に正例:負例 = 1:1を採用します。
特徴量エンジニアリング
特徴量としてユーザーとアイテムのマスタデータに加えてユーザーの行動データを用います。行動データとはZOZOTOWN上での注文、検索、カートイン、お気に入り、閲覧などのデータです。特徴量は全てBigQueryを使用して作成します。
ユーザー軸
- デモグラフィック属性
- 価格に関わる指標
ブランド軸
- ユーザー行動を集計した指標
- 価格に関わる指標
- クーポン付与ポイント
- Candidate Generationで使用したモデルのEmbeddingを主成分分析した第N主成分
ユーザーとブランド軸
- ユーザー行動を集計した指標
- 価格に関わる指標
- ブランドロイヤルティを表す指標
特に特徴重要度が高かった特徴量は以下です。
- 価格に関わる特徴量
- Embeddingを主成分分析した特徴量
学習
推薦モデルの学習にはLightGBMを使用し、スコアが0〜1の範囲に収まる様に二値分類をします。これはスコアが閾値以上の時に配信対象者とすることで将来的にはクーポンに興味があるユーザーのみに配信を送りたいという要件のためです。
バリデーション
Time Series Hold outによって検証データを作成します。最新のN日間のデータを取得し、約20〜30%が検証データとなります。アーリーストッピングを設定し検証データに対するロスが最善の時点で学習を終了します。
推論
Dataflowを使用して並列推論を行います。実験中に推論の実行時間に課題感を感じていましたが、導入後はテストデータと推薦対象データを対象に100GB超のデータに対して約20分で推論が完了します。
3. 機械学習モデルの評価と体制整備
上記の機械学習モデルを評価するためにオフライン評価の体制を整備します。具体的にはオフライン評価と実験管理の導入について紹介します。
オフライン評価
オフライン評価は定量評価と定性評価の2軸で評価をし、特に定量評価ではメトリクスの評価と過去の施策を活用したオフライン評価をします。
メトリクスのオフライン評価
テストデータに対するモデルメトリクスが向上していることを確認すると同時にvalidation lossやユーザーユニーク数などのメトリクスが異常ではないかを確認します。具体的には以下のメトリクスを確認します。
- テストデータに対するprecision@k
- テストデータに対するrecall@k
- train loss
- validation loss
- 学習/推薦ユーザーのユニーク数
- 学習/推薦ブランドのユニーク数
過去の施策を活用したオフライン評価
過去の施策によって変更前、変更後のモデルに関わらないメール配信者やメール経由サイト流入者のデータが手に入っていました。このデータを活用することで以下の指標を擬似的に再現し、変更前のモデルと変更後のモデルを評価します。
- N万位以内のユーザーの配信流入率
- メール経由流入者がN万位以内である割合
定性評価
定量評価に加えて、定性評価をチームメンバーに行なってもらいます。具体的には各自のZOZOTOWNアカウントを用いて推薦結果に対するフィードバックをしてもらいます。以下の様なフィードバックをもらい、モデル改善の方向性を決定する際の参考にしました。
- 変更前の推薦は人気ブランドに偏っているが変更後の推薦はブランドのバリエーションが増えていて良い
- ライトユーザーは変更前の推薦を好むが、ミドル/ヘビーユーザーは変更後の推薦を好みそう
- 変更後の推薦は未知のブランドが多いが、その中に興味を持っているブランドがある時はかなり嬉しい
実験管理の導入
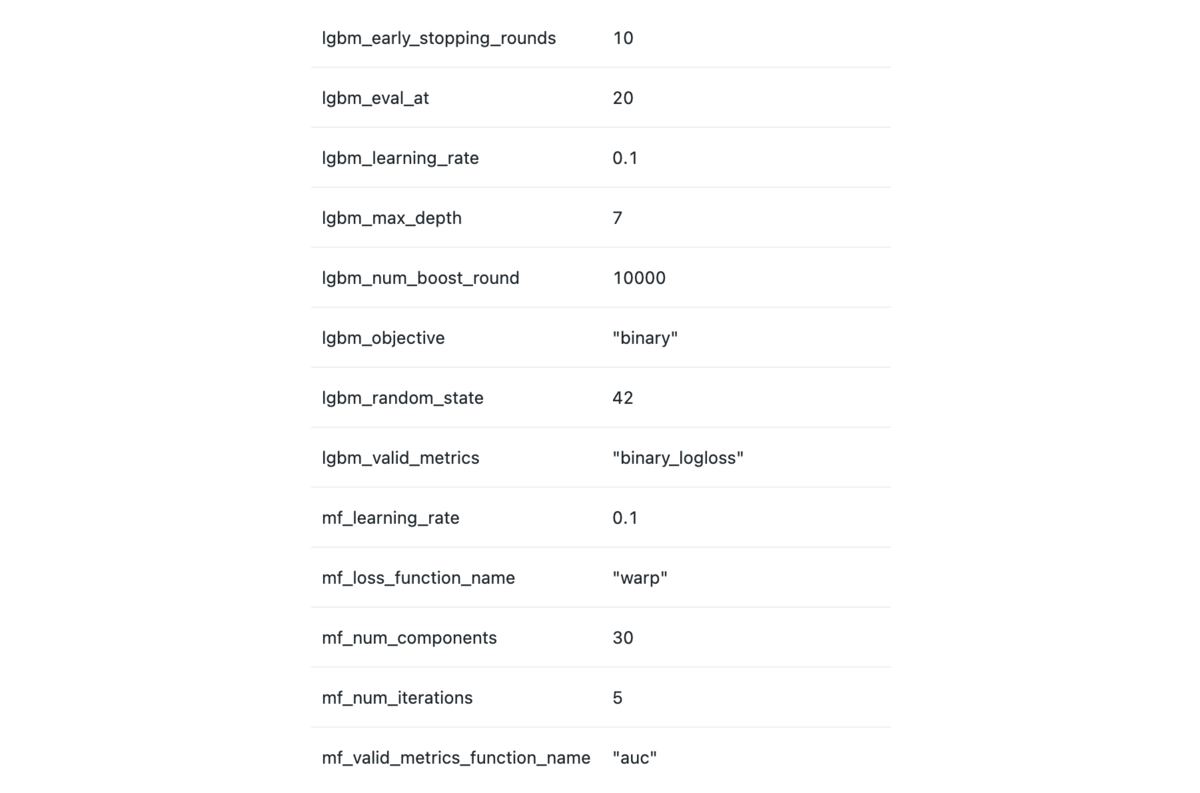
変更前の機械学習モデルは評価指標を保存する場所がなく他のモデルとの比較ができませんでした。対策として、オフライン評価指標の保存と参照を簡易化するために実験管理ツールであるMLflowを導入します。パラメータはパイプラインの実行時に保存され、メトリクスは学習や評価の際にMLflowへ保存します。保存したデータは以下の画像のように確認できます。メトリクスにはダミーの値を入れています。
▼ パラメーター
▼ メトリクス

▼ メトリクスの推移
結果
運用業務の簡易化
今回のシステム移行によってVertex AI Pipelinesを利用した他システムと同様の方法で簡単に運用業務が行えるようになりました。また、Cloud Composerを使用した機械学習モデルの運用が全社的に終了しVertex AI Pipelinesへと完全移行できました。
KPIの改善
配信対象者の変更とショップ推薦の変更に対して実施したA/Bテストではcontrolと比較してKPIが以下の様に改善しました。絶対数を表す指標は比率を、割合を表す指標は差を示しています。
| KPI | 配信対象者の変更 | ショップ推薦変更 |
|---|---|---|
| 売上 | 124.69 % | 104.02 % |
| 1配信あたりの売上 | 123.81 % | 104.40 % |
| 注文者数 | 120.08 % | 103.76 % |
| 配信流入率 | + 0.12 pt | + 0.01 pt |
| 配信注文率 | + 0.004 pt | + 0.001 pt |
リリースサイクルの改善
MLflowの導入によってモデルの精度比較が簡単にできるようになったため、モデル改善のサイクルが早まりました。また、モデルに関わらない変更をリリースする際も精度が低下していないことを確認できるためリリースの安全性が向上しました。
今後の展望
バイアスの考慮
現在はアイテムを閲覧したブランドを学習データとしてショップ推薦をしています。このデータは推薦経由であっても記録されるため推薦モデルが自己の学習データに影響を与えることになります。推薦したブランドは再び推薦されやすくなるというバイアスを生み出しているため、このバイアスを考慮した設計をする必要があります。
評価体制の改善
評価指標の探求
現在の評価指標は推薦の精度に着目したものが多いです。一方で推薦には多様性、新規性、意外性等の精度以外にも考慮すべき指標が提案されています。弊社でも長期的な推薦の価値を捉えた指標を明らかにし、モニタリングする必要があると考えています。
定性評価の体制整備
今回のプロジェクトでは定量評価の体制を整備しましたが、定性評価がモデル改善の方針の参考になることが多かったため、定性評価の方法も標準化することでモデル改善を加速させたいと考えています。
おわりに
本記事ではクーポン推薦モデルとシステムの改善について紹介しました。現在ZOZOでは「ワクワクできる『似合う』を届ける」という経営戦略のもとパーソナライズを強化している最中です。推薦を含め機械学習に関わるエンジニアを募集しているので、ご興味がある方は是非以下のリンクからご応募ください。