



はじめに
こんにちは、技術本部SRE部ZOZOSREチームの堀口です。普段はZOZOTOWNのオンプレミスとクラウドの構築・運用に携わっています。またDBREとしてZOZOTOWNのデータベース全般の運用・保守も兼務しております。
ZOZOTOWNではSQL Serverを中心とした各種DBMSが稼働しています。その中でZOZOTOWNサービスの根幹となるいわゆる基幹データベース(以下、基幹DBと呼ぶ)を5年ぶりにリプレースしました。
基幹DB群は、商品情報、在庫情報、注文情報、会員様情報、ブランド様情報、配送管理、キャンペーン情報、分析系情報などZOZOTOWNサービスにおけるほぼ全ての情報を管理しているものとなります。
リプレースのモチベーションは5年のハードウェア(以下、HWと呼ぶ)保守期限終了およびSQL ServerのEnd Of Life(以下、EOLと呼ぶ)を迎えるため、HWの更改/SQL Server、OSのバージョンアップが必要となったことです。
本記事では、どのようにこれら基幹DBリプレースを推進したか、ZOZOTOWNサービスを引き続き快適に利用して頂けるよう案件を推進したかという内容を紹介させて頂きます。
目次
- はじめに
- 目次
- 基幹DBのリプレース方針
- 機器選定
- 機器スペック選定
- OS/SQL Server/各種ミドルウェアのバージョン選定
- 切替計画
- SQL Server2012と2019のクエリ互換性
- 基幹DBの理解
- 設計・構築
- テスト
- 切替リハーサル
- 本番切替
- 終わりに
基幹DBのリプレース方針
基幹DB群はZOZOTOWN創業時から存在すること、サービスにおける絶大な影響を持つことから、いかに安全かつ革新的にこのリプレース案件を成功させるかをずっと考えていました。
その結果、以下の方針でリプレースすることにしました。
- 改善したいところはあるものの、手を出さずにオンプレミスサーバ⇒オンプレミスサーバへの単純リプレースとする
- ベンダー依存の体制から脱却する
- 各種連携システム(主に人)と完璧に情報を共有し「漏れ」をなくす
1つ目の単純リプレースとした理由は「安全にリプレースする」ことを最優先としたためです。改善したかった所としては以下のものがありましたが、本プロジェクトのスコープからは除外しました。
- 不要オブジェクトやデータ連携ルートの削除、既存オブジェクトの適切なDBへの移動
- オンプレミスサーバに存在する理由のないテーブルや処理は「Amazon RDS」,「Amazon Aurora」,「Google Cloud BigQuery」などに部分移行
2つ目のベンダー依存に関しては、前例と実績を重視するあまり機器選定からリリースへ至るまで(言い方は少々悪いですが)ベンダー任せにしてしまっているところがありました。機器選定時、適切な検証と選択を行なわず、また運用に関しても自社エンジニアでできることはほとんどなくベンダーに頼り切りとなっている体質があったため、今回はこれも是正したいと強く思っていました。
3つ目に、基幹DBと連携するサーバやシステムが多数あるため、リリース時には複数システムで切替作業が必要となります。この方針決めの時点では全容は把握できていませんでしたが、日々のDBREとしての活動の中で容易に想像できました。
以降、上記方針に基づいてあらゆる事を判断していくこととなります。
機器選定
対象となるHW機器は大きく分けて以下の3つです。
- サーバ製品
- ストレージ製品
- スイッチ製品
また選定した機器と委託するベンダーとは関連があり、選定した機器に対してそれを得意とするベンダーを構築担当としてお願いすることになります。そのため、
機器選定=ベンダー選定である
という事を念頭に置いて選定を行なっていくことになります。
機器選定においては、A社とB社の製品を比較・検討していくことにしました。まず実施したことはストレージ製品の性能比較です。性能比較にあたっては、以下の方針を立てました。
- 同一条件で同一処理を実行し、ストレージ単体の秒間スループット、IOPS、レイテンシを比較する
- 同様にSQL Server経由での性能を比較する
- 読み込み/書き込み、ブロックサイズ(8K、64K、256K)、スレッド数(1、32)、sequential/randomの全ての組み合わせパターンを比較する
- SQL Serverを経由したselect/insert/update/deleteのパターンを比較する
- 製品間の性能差を計測するものであり本番環境の性能を保証するレベルのテストではない(≒限界値テストは行わない)
この検証をするための検証環境は各ベンダーに用意して頂きました。
ディスク単体の性能計測はMicrosoft社(以下、MS社と呼ぶ)製のベンチマークツールである「DiskSpd」を使用しました。これは弊社内でノウハウがあったことと、オプションが多数あり細かい動作を指定できること、outputが見やすいことから採用しました。
DISKSPD を使用してワークロード ストレージのパフォーマンスをテストするを参考に実行したDISKSPDコマンド例は次のとおりです。
Diskspd.exe -c1G -b8K -t1 -o1 -L -h -si -d120 T:\test.dat
- c1G:テスト用ファイルサイズ1GB
- b8K:ブロックサイズ8KB
- t1:同時スレッド数1
- o1:キューデプス1
- L:レイテンシー統計出力
- h:ソフトウェア/ハードウェアキャッシュを無効化する
- si:シーケンシャルアクセス
- d120:120秒間実行
- T:\test.dat:テストファイル名
上記のコマンドを実行するとこのように細かく性能値を出力してくれます(少々長いです)。
Diskspd結果
Command Line: Diskspd.exe -c1G -b8K -t1 -o1 -L -h -si -d120 T:\test.dat
Input parameters:
timespan: 1
-------------
duration: 120s
warm up time: 5s
cool down time: 0s
measuring latency
random seed: 0
path: 'T:\test.dat'
think time: 0ms
burst size: 0
software cache disabled
hardware write cache disabled, writethrough on
performing read test
block size: 8KiB
using interlocked sequential I/O (stride: 8KiB)
number of outstanding I/O operations per thread: 1
threads per file: 1
IO priority: normal
System information:
computer name: PE640-SP01
start time: 2021/12/13 12:26:03 UTC
Results for timespan 1:
*******************************************************************************
actual test time: 120.01s
thread count: 1
proc count: 32
CPU | Usage | User | Kernel | Idle
-------------------------------------------
0| 20.71%| 0.65%| 20.06%| 79.29%
1| 0.03%| 0.01%| 0.01%| 99.97%
2| 0.01%| 0.00%| 0.01%| 99.99%
3| 0.03%| 0.00%| 0.03%| 99.97%
4| 0.01%| 0.01%| 0.00%| 99.99%
5| 0.74%| 0.34%| 0.40%| 99.26%
6| 0.14%| 0.05%| 0.09%| 99.86%
7| 0.18%| 0.08%| 0.10%| 99.82%
8| 0.13%| 0.07%| 0.07%| 99.87%
9| 0.04%| 0.03%| 0.01%| 99.96%
10| 0.12%| 0.09%| 0.03%| 99.88%
11| 0.08%| 0.04%| 0.04%| 99.92%
12| 0.13%| 0.12%| 0.01%| 99.87%
13| 0.00%| 0.00%| 0.00%| 100.00%
14| 0.33%| 0.10%| 0.22%| 99.67%
15| 0.03%| 0.00%| 0.03%| 99.97%
16| 1.76%| 0.00%| 1.76%| 98.24%
17| 0.04%| 0.03%| 0.01%| 99.96%
18| 0.03%| 0.00%| 0.03%| 99.97%
19| 0.00%| 0.00%| 0.00%| 100.00%
20| 0.04%| 0.03%| 0.01%| 99.96%
21| 0.04%| 0.03%| 0.01%| 99.96%
22| 0.03%| 0.01%| 0.01%| 99.97%
23| 0.00%| 0.00%| 0.00%| 100.00%
24| 1.05%| 0.00%| 1.05%| 98.95%
25| 0.00%| 0.00%| 0.00%| 100.00%
26| 0.01%| 0.00%| 0.01%| 99.99%
27| 0.00%| 0.00%| 0.00%| 100.00%
28| 0.07%| 0.05%| 0.01%| 99.93%
29| 0.00%| 0.00%| 0.00%| 100.00%
30| 0.00%| 0.00%| 0.00%| 100.00%
31| 0.05%| 0.03%| 0.03%| 99.95%
-------------------------------------------
avg.| 0.81%| 0.05%| 0.75%| 99.19%
Total IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev | file
-----------------------------------------------------------------------------------------------------
0 | 6798966784 | 829952 | 54.03 | 6915.95 | 0.144 | 0.115 | T:\test.dat (1GiB)
-----------------------------------------------------------------------------------------------------
total: 6798966784 | 829952 | 54.03 | 6915.95 | 0.144 | 0.115
Read IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev | file
-----------------------------------------------------------------------------------------------------
0 | 6798966784 | 829952 | 54.03 | 6915.95 | 0.144 | 0.115 | T:\test.dat (1GiB)
-----------------------------------------------------------------------------------------------------
total: 6798966784 | 829952 | 54.03 | 6915.95 | 0.144 | 0.115
Write IO
thread | bytes | I/Os | MiB/s | I/O per s | AvgLat | LatStdDev | file
-----------------------------------------------------------------------------------------------------
0 | 0 | 0 | 0.00 | 0.00 | 0.000 | N/A | T:\test.dat (1GiB)
-----------------------------------------------------------------------------------------------------
total: 0 | 0 | 0.00 | 0.00 | 0.000 | N/A
total:
%-ile | Read (ms) | Write (ms) | Total (ms)
----------------------------------------------
min | 0.111 | N/A | 0.111
25th | 0.131 | N/A | 0.131
50th | 0.137 | N/A | 0.137
75th | 0.147 | N/A | 0.147
90th | 0.161 | N/A | 0.161
95th | 0.185 | N/A | 0.185
99th | 0.226 | N/A | 0.226
3-nines | 0.478 | N/A | 0.478
4-nines | 0.960 | N/A | 0.960
5-nines | 2.050 | N/A | 2.050
6-nines | 100.823 | N/A | 100.823
7-nines | 100.823 | N/A | 100.823
8-nines | 100.823 | N/A | 100.823
9-nines | 100.823 | N/A | 100.823
max | 100.823 | N/A | 100.823
これらの結果から重要なメトリクスを抽出し、一覧化し比較しました。

結果より、ストレージへの純粋なアクセス性能においては、ほぼ全てのパターンでA社の方がB社より優秀 ということがわかりました。
次にSQL Serverを経由したアクセス性能を検証しました。 対象クエリについてはOLTP/バッチ処理を想定した本番環境に実際に発行されている「select/update/insert/delete」文の中から重いと判断したものを抽出しました。それをテスト用クエリとしシングル/並列スレッドでSSMSから実行しました。
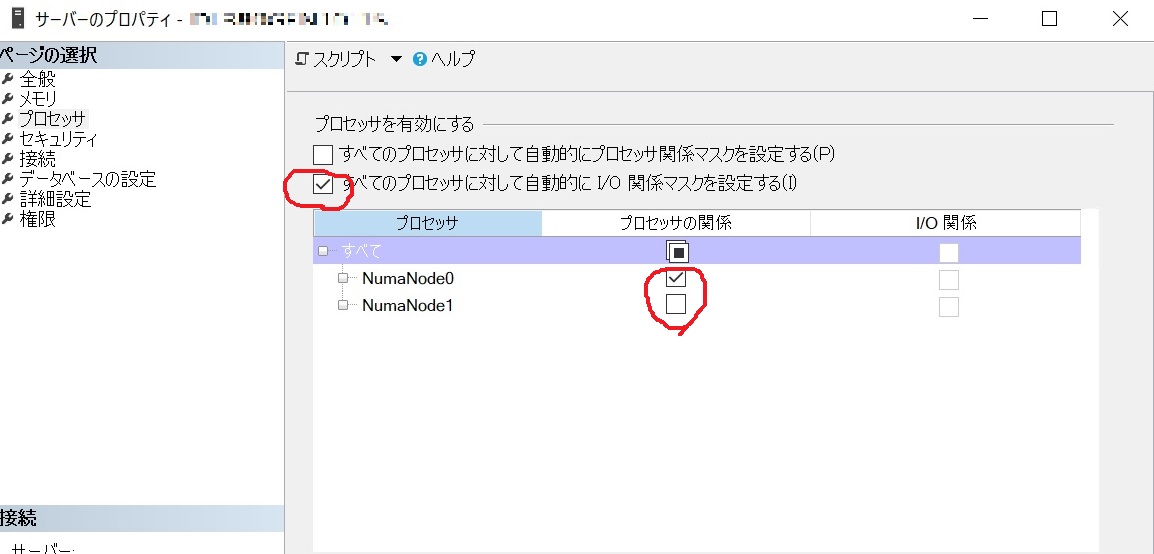
また検証用サーバ機は調達の問題により両社でCPUのスペック差が発生していたため、以下の設定をSQL Serverに行うことで条件を統一しました。
- SQL Serverが使用するCPUについて、A社のCPUのコア数をB社の32コアに合わせ32コアへ縮小する
- 関係マスクを自動→固定に変更(両社とも)
観察すべきメトリクスは色々ありますが、レスポンス時間、リソース使用状況を取得するため、以下の取得設定を事前に仕込み、性能測定に使用しました。
- クエリストア
- パフォーマンスモニタ
- DMV情報
またオプティマイザによって作成される実行プランに違いが出てしまうと純粋な比較とならないため、実行プランが同じであることは項目毎に確認していきました。テスト結果はDiskSpdと同様に一覧化し比較しました。結果的としては、DiskSpdの結果と同様にA社製品の方が性能的に”上”という結果となりました。
レスポンス

リソース状況

A社 or B社?
上で書いた通り機器選定=ベンダー選定でもあり、システム構築や5年後までを見据えた保守サポートなど長いお付き合いとなります。また当然ですがコストについても比較しなければ決定するには不十分です。基幹DBのワークロードにおける性能比較はA社の方に分がありましたが、果たしてその結果だけで評価してよいものか考えました。
全体の評価には、以下の評価項目について両社を比較し合計点の大きい方を採択するという方針を決めました。
| 評価項目 | 分類 |
|---|---|
| 信頼性 | 企業信用力 |
| 資質・能力 | 取り纏めSE能力 |
| 提案力 | |
| 適合性1 | 製品 |
| 性能 | |
| 適合性2 | 提案内容 |
| 業務の理解度 業界知識 業務知識 実現性のある提案か |
|
| 実現性 | 日程・体制 |
| 将来性 | 拡張/保守 |
| 経済性 | 見積金額 |
なるべく公平な評価を目指した結果このような点数制になりました。これでも主観が入ってしまうことは否めませんが、最終的にはこの点数を根拠として、本リプレース案件はA社製品を採択することになりました。
5年前のリプレース以前からZOZOTOWNが採用してきた基幹DBのHWベンダーを今回の基幹DBリプレースから一新することになりました。
機器スペック選定
基幹DBはオンプレミスなサーバ群のため当然ですがクラウド環境のように容易なスペック変更はできません。そのためこの時点でスペック不足とならないよう慎重にCPU/メモリ/ディスクサイズを決定する必要があります。選定の方針としては以下の2つです。
- 現行で稼働する基幹DBのスペックとリソース使用率を基準に将来的な成長率を考慮し決定する
- 多少のオーバースペックは許容する
ここについては、HWベンダーのアセスメントサービスを利用して最終的なスペックを提案して頂き決定しました。
OS/SQL Server/各種ミドルウェアのバージョン選定
基本方針は以下の通りです。
- 原則最新バージョンで構成する
- SQL Serverについては連携するシステムとの互換性に注意する
SQL Serverのバージョンは最新である2019を採用することを軸に検討しました。また互換性レベルも150として現行の100から大幅に引き上げることにしました。
基幹DBは各種システム(サーバ)とのデータ連携にSQL Serverのトランザクションレプリケーション機能を利用してます。パブリッシャー側とサブスクライバー側のSQL Serverバージョンは仕様上、互換性の制約があり3世代以上のバージョンの隔たりは許容されていません。このため最新のSQL Server2019にバージョンアップするDBとSQL Server2016を採用せざるを得ないDBが混在することになりました。このバージョン互換性問題は後述するシステム切替方式にも影響することになります。
OS/ミドルウェアについては特段問題なかったので最新バージョンを選択しました。
切替計画
切替計画を立てる際、一番に考えたのはZOZOTOWNサービスの無停止での切替ができないかでした。現行DBサーバの横に新DBサーバ群を構築しテストし、切替当日クライアント側で向き先を一気に切り替える方式はほぼ決定していましたが、以下の理由で無停止での切替は断念しました。
- 新旧サーバ間のデータ同期にDBリストアを行う必要があるが、その後レプリケーションを再作成する必要があり、一時的にテーブルのDROP/CREATEが走ること
- クライアント側が点で切り変わらない限り一部のクライアントは新DB、一部のクライアントは旧DBを更新することになりデータの不整合が発生すること
そこで以下の全体方針を立てました。
- 切り替え当日は、レプリケーションの張り直し作業が必要となるため、数時間のZOZOTOWNのサービス停止が必要となる
- 1日のサービス停止時間の削減および切り戻しの容易さを考慮し、切り替えは2段階で行う(以降、フェーズ1、フェーズ2と呼ぶ)
- フェーズ1およびフェーズ2の間の過渡期ではSQL Server2019(FrontDB/BackDB)とSQL Server2012(ReportDB/BatchDB)が両立しサービスすることになる
- SQL Server2019と2012はレプリケーションの互換性がないため、互換性を保つため一時的に2016のSQL Serverを中継用に挟むことにより対応する
ZOZOTOWNを停止することは避けられないとしても、停止時間が9時間になるのと18時間になるのとではZOZOTOWNユーザーへの影響度が変わってきます。また一度に変更する範囲を狭めることで問題が発生した際の切り分けや対応範囲が限定され解決しやすくなるという理由から、FrontDB/BackDBの切替とReporDB/BatchDBの切替を別日になるよう日程を2つに分けて切替を行うことにしました。
本番環境の状態遷移を図にしてみます。上段が現行DB、下段が新DBとなります。矢印はレプリケーションの線になります。

FrontDB、BackDBだけ切り替えた状態がフェーズ1完了時となります。この時、SQL Serverのバージョン互換性の問題で新FrontDB/新BackDBと旧ReportDB/旧BatchDBとの間で直接レプリケーションを張ることができません。このため新ReportDB上に中間となるバージョンを持った中継用SQL Serverインスタンスを暫定的に挟むことでバージョン互換性の問題をクリアしました。

フェーズ2完了時点では中間インスタンスを削除し、新DBのみで稼働することになります。
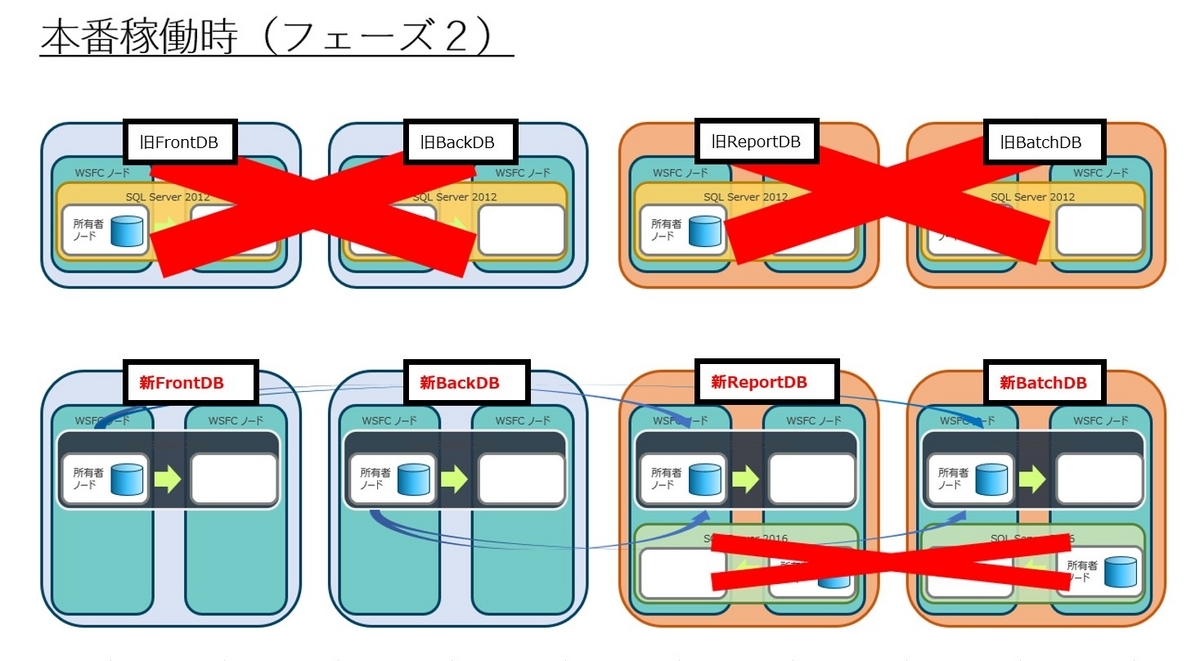
レプリケーションの互換性の詳細はSQL Serverマニュアル(レプリケーションの下位互換性) をご参照ください。 フェーズ1完了時は、「SQL Server 2019」→「SQL Server 2016」→「SQL Server 2012」という構成でデータ連携することにしました。
SQL Server2012と2019のクエリ互換性
バージョンアップにおける既存クエリの互換性のチェックについてはMS社が提供する「Data Migration Assistant(DMA)」を利用しました。このサービスの詳細は弊社テックブログ(Data Migration Assistant)を参照頂くとして、簡単に言うとクエリを渡すと異なるSQL Serverのバージョン間で互換性があるか、つまり動くかをチェックしてくれるものです。
本案件では、下記の両方についてDMAを利用してチェックをかけました。
- ストアドプロシージャなどの静的クエリ
- アプリケーション側で動的に発行されるアドホックなクエリ
影響のあるクエリは以下の3つのタイプという結果になりました。
| 内容 | 説明 |
|---|---|
| Unqualified Join(s) detected | JOIN句の書き方が正しくない LEFT OUTER JOINなどのようにJOIN句を省略せずに書く 悪い例) select * from table1, table2 where table1.col1 = table2.col1 |
| SET ROWCOUNT used in the context of DML statements such as INSERT,UPDATE,or DELETE | INSERT,UPDATE,DELETE文においてROWCOUNTで行を絞る機能が無効となる。代わりにTOP XXXを使う必要がある 悪い例) SET ROWCOUNT 100 UPDATE~ |
| ORDER BY specifies integer ordinal | ORDER BY句に指定するカラムを列番号で指定しない。代わりにカラム名で指定する 悪い例) order by 1 |
こちらについては、クライアント処理を担当する各チーム(以下、業務チームと呼ぶ)に確認/修正を依頼しました。
基幹DBの理解
私がこの案件のPMを任された時、基幹DB群に対する理解度は半人前(勉強中)な状態でした。それまではクラウドベースの商品系APIのインフラ(とデータベース)の運用/保守担当だったので基幹DB群については知見があまりない中で、いかにリプレースを成功させるかをずっと考えていました。
DBに限らず1つのシステムの運用を理解するには、「いつ」「だれが」「どこで」「なんのために」「どのように」「何する」といういわゆる5W1Hを全てのオブジェクトに対して整理することだと考えています。データベースに関していえば上記を全テーブルに対して整理することです。
それが理想ではあるものの1つのDBで1000テーブル近くのテーブルを所有する基幹DBにおいて全てを整理するには時間が足りません。まずはデータベース視点で、基幹DBへ接続して来ているクライアント達についてDB単位で整理することから始めました。
基幹DBを用途別に整理すると、以下の6種類のデータベースに分かれます。
| DB名 | 用途 |
|---|---|
| FrontDB | セール情報 ショップニュース 会員情報 クーポン情報 ファッションまとめ 注文情報 メンバー情報 ポイント履歴 在庫情報 |
| BackDB | 商品系情報 ショップ、ブランド系情報 拠点情報 メルマガ |
| ReportDB | 分析系情報 |
| BatchDB | 人気順情報 検索系 コーディネイト系 |
| ReadonlyDB | 商品詳細情報 |
| DmsDB | データ連携中継用 |
これらに対してアクセスしているサーバやユーザをSQL ServerのDMVから情報を取得しました。
--クエリ1 select host_name,login_name,count(*) AS [num of sessions] from dm_exec_requests_dump_per_several_seconds with(nolock) group by host_name,login_name order by host_name,login_name
上記の「dm_exec_requests_dump_per_several_seconds」というテーブルは我々が後からワークロードを都合よく確認できるよう定期的に(5秒間隔)DMV情報をサマリしたものを貯めておくワークテーブルです。
このクエリを実行すると、10日分のクライアント別/ユーザ別のアクセス状況、おおよそのセッション数が分かります。

この結果を元に、下記項目を一覧化し整理していくことから基幹DBの使われ方や運用を理解していきました。
- アクセス元のユーザ名毎のクライアント処理
- アクセス元サーバ群を機能別にカテゴリ化
- アクセス元の担当部署
設計・構築
設計については冒頭で書いた通り、本案件は単純移行を方針としているため原則、現行踏襲で設計する、HWのスペックアップなど差分に関わる箇所においては設計変更するという方針ですすめました。構築においても同様です。こちらは外部ベンダー主導で作業して頂き、弊社でレビューする形式にしてすすめました。
テスト
本案件で実施した各種テストとテスト観点について以下に整理します。
| テスト名 | 観点 |
|---|---|
| アプリケーションテスト | ・SQL Serverバージョンの違いによるクエリの正常性確認 ・DB接続切替箇所の特定・手順・網羅性の確認 |
| 性能テスト | ・SQL Serverバージョンアップに伴うオプティマイザのバージョンアップにより現行よりも劣化した実行プランが生成されないこと ・クエリ処理時間が現行と同等、または改善すること ・リソース使用量に異常性がないか |
| 障害テスト | ・基幹DBを構成する一連のシステム内で障害が発生した場合にきちんとリカバリができサービス再開ができること ・期待したアラートが発報され障害時に運用担当者が気づける仕組みができていること |
| 運用テスト | ・各種運用手順書の妥当性 |
| 品質管理テスト | ・各種URLを発行し想定通りの結果となること(ノンリグレッションテスト) |
アプリケーションテスト
アプリケーションテストは、言うまでもなくバージョン差異に影響することなくクエリが正常に動作することです。クライアント処理をテストするための環境として動作させるため、本番サーバからコピーしたほぼ全てのを各種テスト用クライアントをVMゲストとして起動させました。

もう1つDBへの接続箇所の洗い出しという観点がありました。ここではテストの段階で間違えて本番DBにアクセスした場合のリスクと切替漏れに気付ける仕組みが必要です。テスト用クライアントは現行DB群にアクセスできないようWindowsFirewallの機能で本番DB宛てのアウトバウンド通信を全て拒否するような設定を入れました。
性能テスト
性能テストについては、あるべき論と限られた環境の中でどこまでやるのかという点において非常に悩みました。リプレースする基幹DBに求められる最大のミッションは、ZOZOTOWNで最も負荷のかかる大規模セール時のリクエストを捌けること となります。
さらにブレークダウンしていくと、性能テストとして担保したいことは概ね以下となります。
| 項番 | 指標 | 目標値 |
|---|---|---|
| (1) | 最大秒間バッチリクエスト数を捌けること | XXXXXバッチ/sec |
| (2) | 同時実行性が担保できること | ワーカースレッド数XXXX程度 |
| (3) | 応答時間が現行と同等もしくは向上すること | 95パーセンタイルでX ms以下 |
| (4) | HWリソース不足が発生しないこと | CPU使用率XX%以下 |
さて、上記をテストするには各DBサーバに対するクエリの種類やリクエスト数を本番サービス並みに発生させる必要がありますが、テスト用クライアントの台数が圧倒的に少ないため断念しました。
そこで性能テストとして実施可能な範囲で方針として以下に決定しました。
| 項番 | 方針 |
|---|---|
| (1) | DB単体での性能を計測する |
| (2) | 本番環境のクエリを一定のルールで抽出し性能を測定する |
| (3) | HWリソースの消費量が異常値とならないことを確認する |
(1)については、クライアントの性能に依存するURL経由での性能ではなくDBサーバ単体の性能を測定するということです。(2)については”問題となりうるクエリ”を抽出しその性能を測定することとしました。現状の環境とスケジュール感、工数を鑑みるとできることは少なく最低限の確認とならざるを得ないという感想です。
対象クエリの抽出方針
テストで使用するクエリは以下の条件で選定、抽出しました。
| 項番 | 方針 |
|---|---|
| (1) | OLTP/バッチの2パターン |
| (2) | 対象コマンドは、select/insert/update/delete |
| (3) | bulk insert(bcp処理) |
| (4) | リンクサーバ経由のクエリも含ませる(分散トランザクションの性能確認) |
(3)、(4)については基幹DBのワークロード特性から必要なものとなります。(1)のOLTP/バッチの判断基準は以下としました。
- OLTP : 実行回数が1時間に1000回以上
- バッチ : 実行回数が1時間に360回以下※最短実行間隔が5秒として5秒×12回×60分=360回
かつ負荷が高いものの抽出基準として以下を設定しました。
| 処理 | 抽出基準 |
|---|---|
| OLTP | 実行回数の多いもの(execution countが多いもの) 1時間のトータルの経過時間が多いもの(total elapsed time、total worker time) workspacememoryが大きいもの |
| バッチ | 処理時間、CPU時間が多いもの workspacememoryが大きいもの |
負荷ツールの選定
負荷をかけるツールはMS社の「OStress」を使用しました。
設定がシンプルであること、並列度、回数を指定するのに細かい設定が不要なことから選定しました。対抗馬はJMeterでしたがこちらは設定が複雑であるとの理由から却下しました。
ostress.exeコマンド例
ostress.exe -Sホスト名 -Uユーザ名 -Pパスワード -dDB名 -q -M6200 -r8000 -n100 -oD:\work\seino\2-1-1 -iD:\work\seino\2-1-1.sql
気を付けたのは、目標の負荷を掛けるためにオプションn(実行時のコネクション数)、r(1コネクションあたりの実行回数)を調整しつつ実行する必要があるということでした。
また複数のコネクションを並列で実行する場合、1つのクエリファイルが同時に実行されるためinsert文でキー重複が発生するのを避ける必要があります。このような場合はキー項目の値にsessionidと紐づいた値を設定するようにクエリを書き換えることで重複を排除しました。これは複数セッションから同一行へアクセスするのと別々の行へアクセスするのとでは性能が大きく変わってきてしまうことからも大事なことです。
サンプルとしては以下のようなクエリとなります。
declare @変数A int = @@SPID insert into テーブルA(キーカラムA,カラムB)values(@変数A,0); insert into テーブルA(キーカラムA,カラムB)values(@変数A + 1,0); insert into テーブルA(キーカラムA,カラムB)values(@変数A + 2,0); ・ ・ update テーブルA set カラムB = 0 where キーカラムA = @変数A; update テーブルA set カラムB = 0 where キーカラムA = @変数A + 1; update テーブルA set カラムB = 0 where キーカラムA = @変数A + 2; ・ ・ ・
あと細かいですが、OStressの仕様でオプションと値の間にスペースを入れてはいけません。
性能テスト結果
それぞれの観点と結果をまとめると以下の通りで、結論としては問題なしでした。ただしクエリパターンの全網羅はできていないため本番サービス後に非効率な実行プランが生成された結果、応答時間の長くなるクエリが出てくる懸念は残りますが、それらは個別でチューニングしていく判断をしました。
| 観点 | 結果 |
|---|---|
| SQL Serverバージョンアップに伴うオプティマイザのバージョンアップにより、現行よりも劣化した実行プランが生成されないこと | 現行と異なるプランが作成されたものがあったが、劣化したプランとは言えないため問題なしとする。 |
| クエリ処理時間が現行と同等、または改善すること | 1項目だけ想定よりも遅くなる事象が発生したが現行側のサンプルがパラメータの値により速度の幅があり、今回のテストではその範囲内で収まっているため問題なし |
| HWリソースの使用量が現行と同等、または改善すること | CPU、メモリ、ストレージについて余裕あり(無風なので当然だが異常値がなければ良いという判断) |
障害テスト
障害テストは、可用性が担保されているかだけでなく監視を通じて期待したアラートが発報されるかを確認するテストです。こちらは今回のリプレース対象サーバだけでなくWebサーバの挙動も影響してきますので、Webサーバに対しテストURLを常時発行している状態で障害を発生させる形で実施しました。確認ポイントとしては、サービス断の有無とサービス断が発生した場合の復旧時間の計測、監視設定の妥当性となります。
なお設計としては多重障害は救済対象外とし、あくまでSingle Point Of Failure(SPOF)を排除するのが方針となります。障害パターンとしてはHWの物理故障からミドルウェア障害までの範囲を対象としました。
| カテゴリ | 障害パターン |
|---|---|
| HW障害 | サーバ機(CPU) |
| サーバ機(メモリ) | |
| サーバ機(内蔵ディスク) | |
| サーバ機(NIC) | |
| サーバ機(電源) | |
| ストレージ(コントローラ部分障害) | |
| ストレージ(コントローラノード障害) | |
| ストレージ(ディスク) | |
| SANスイッチ | |
| OS障害 | OS停止 |
| リソース不足 | |
| DB障害 | アクセス不可 |
| クエリ遅延 | |
| レプリケーション遅延 | |
| データ損失 | |
| NW障害 | スイッチ(筐体) |
| スイッチ(LAG) | |
| スイッチ(ポート) | |
| スイッチ(電源) | |
| DRサイト障害 | ログ配布失敗 |
| サーバ機(CPU) | |
| サーバ機(メモリ) | |
| サーバ機(内蔵ディスク) | |
| サーバ機(NIC) | |
| サーバ機(電源) | |
| ミドルウェア障害 | WSFCプロセス障害 |
| VSRプロセス障害 | |
| ALogプロセス障害 | |
| SCOMプロセス障害 | |
| AD障害 | 認証不可 |
運用テスト
運用テストは、システム運用中に発生しうる運用作業を手順化し弊社エンジニアが実施できる状態となっているか確認することを目的としてます。このため弊社エンジニアがテストを実施し、手順書をブラッシュアップしていく作業となります。範囲としては従来ベンダーに依頼していた作業を弊社エンジニアが実施できるようになるというリプレースの大方針の1つ「ベンダー依存の体制から脱却する」を実現するためのアクションになります。
品質管理テスト
これはブラックボックスなノンリグレッションテストであり、ZOZOTOWNの品質を一定のレベルで保つために行うものとなります。データベースから見るとクエリバリエーションの網羅性が高いので、 ”全く返ってこないクエリ” を発見するのに非常に有用なものとなりました。
切替リハーサル
リハーサルは2フェーズでの切替方式に合わせ、フェーズ1、フェーズ2でそれぞれ行いました。
リハーサルの目的としては以下を策定しました。
| 目的 | 詳細 |
|---|---|
| 手順検証 | 計画・準備した移行手順が実用に耐えるか |
| 時間計測 | 時間内に移行処理、手順を完了できるか |
| 作業の慣らし | 事前演習することでの作業効率化 |
当たり前ですが、リハーサルでやったことをブラッシュアップしたものが本番切替になるのでこのタイミングで本番切替の詳細を詰め計画しなければなりません。本番切替については以下を決定しました。
| 項番 | 方針 |
|---|---|
| (1) | フェーズ1とフェーズ2の二段階で移行作業を行う※前述 |
| (2) | 移行作業中はZOZOTOWNのサービスを停止する(フェーズ1/フェーズ2それぞれ9時間を想定) |
| (3) | 移行当日の作業をできる限り最小化するため事前に移行可能なものは移行前日までに実施しておく |
| (4) | コンテンジェンシープランを準備する |
| (5) | 本番移行を実施する人がリハーサルを実施する |
(5)についてはリハーサルの方針として追加しました。上で書いた「作業の慣らし」が必要なためです。
切替方針として死守しなければならなかったのは、(2)の移行当日のZOZOTOWNの停止時間を守るということでした。これは売り上げに直結するというのはもちろんの事、切替方式の工夫次第で長くも短くもできるものという理由からです。
データ移行の方式は、まず移行当日までの作業SQL Serverの機能で現行DB→新DBへの完全リストアを行います。その後発生した更新は定期的なログ適用にて随時追いつきをかけていきます。そして移行当日はDBアクセスを完全に停止することで静止点を作り、最終ログ適用から静止点までの更新分のみを適用することで完全に同期させる方式で行いました。この作業後に、トランザクションレプリケーションの再同期およびインデックス作成という時間のかかる作業が必要になります。
作業手順のステップとしては487ステップ以上、関連チーム10チーム以上といった膨大な作業内容を9時間以内で収めるといったミッションとなりました。そして初回のリハーサルの結果は、”全然ダメ”でした。
切替リハーサル結果
”全然ダメ”だった主な理由は、作業時間が完全にオーバーしてしまったためです。机上計算および検証により見積もっていたものの、リハーサルを実施してみると時間が全然足りませんでした。
対策案としては3つ。
| 案 | 内容 |
|---|---|
| 案1 | ZOZOサイト停止時間を延ばす →例えばサイト停止9時間を12時間に |
| 案2 | 切り替えフェーズをDB毎に複数回に分ける →2段階切替を4段階切替に |
| 案3 | 今の手順を工夫して効率化、当初どおり9時間 |
案1/案2は共に売上げへの悪影響が避けられません。案3しか選択肢はありませんでした。各担当者に時間短縮のための仕組み改善を依頼し、並行作業できるところは極限まで並列化し、スクリプト化や半自動化で作業効率を上げるなど時間短縮をとにかく優先するよう作業内容を改善しました。
極限までの並列化により切替全体のタスクが複雑化してしまったものの、各作業チームの努力の甲斐あって再リハーサルでは予定時間に切替を終えることが可能だと分かりました。これはリハーサルの成果です。なおフェーズ2のリハーサルはフェーズ1のフィードバックを取り込むことで問題なく完了しました。
本番切替
さて本番リリースではサイト告知等、リハーサルではやれなかったタスクが入ることになります。作業時間帯もリハーサルは日中でしたが、本番切替は夜間のアクセスが少ない時間帯で行いました。
この辺の(一見影響なさそうな)違いに足元を救われて失敗するということを過去に何度も見てきているのでリハーサルやそれまでのテストで実施できなかった箇所が不安材料でした。結果的には、フェーズ1は予定時間より15分程度の遅れ、フェーズ2は予定時間内に完了しました。
トラブルについては、切替作業中に発生したものとサービス再開した後に発生したものを合わせると39件発生しました。内容的には一部のクエリの処理遅延、リハーサルでテストできなかったいう”出るべくして出た”トラブルと、リハーサルでの確認漏れやテストすべきだったのにできなかったものも多数ありこれは反省すべきことでした。
終わりに
現在、ZOZOTOWNはリプレースした基幹DB群で安定したサービスを提供しております。しかし本番リリース後、安定稼働するまでにはおよそ2~3ヵ月の日数がかかりました。リリース後発生したトラブル群とそれへの対処内容や新旧DB間での性能比較については、ここでは長くなってしまうのでまた別の機会にお話することとします。
何はともあれ、この案件に関わってくれた多くのチーム/担当者、そして機器選定からリリース、運用まで携わってくれたベンダーの方達の助けによってこの大型案件を終えることができたことに感謝します。
ZOZOでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!