



はじめに
こんにちは。SRE部USED基幹インフラの先崎です。
ZOZOUSEDは2016年、当時の株式会社ZOZOUSED システム部のインフラチームにて、基幹のデータベース(以下DB)をMySQLからMicrosoft SQL Server(以下MS SQL)に移行しました。
移行してから今日まで、データロストなどの大きなトラブルは起きておりません。そのため、当時の変更理由から選定時に検討した内容、その際に発生した課題の解決方法を簡単に紹介させていただきます。MySQLからMS SQLへ移行を検討しているどなたかのお役に立てられたら幸いです。
MySQLからの移行検討
当時、自動切替(フェイルオーバー)を実現しようとすると費用が大きくかかってしまうため、手動切替(スイッチオーバー)の形をとっていたことが最大の要因でした。
| MySQLの正常時イメージ図 | MySQLの障害時イメージ図 |
|---|---|
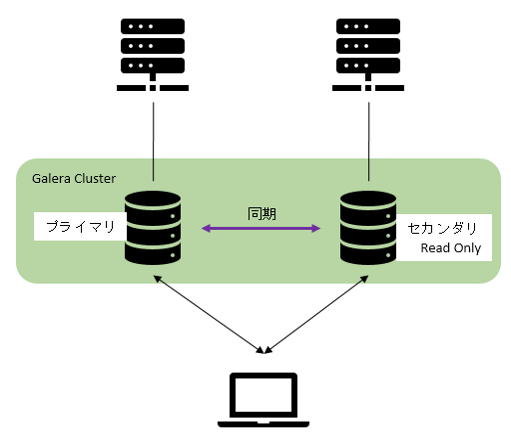 |
 |
まず、当時のMySQLの構成と、前述以外の問題点についてご紹介します。
移行前の構成
構成
ライセンス費用がかからないもので構成していました。
- CentOS 2台
- MariaDB(Galera Cluster冗長化)
問題・課題点
スペック起因の可能性もありますが、当時課題として感じていた点は以下の通りです。
- リスナーなどはなかったため、DBの切替時はDNSレコード変更かプログラムで見ているDBのIPやホスト名を手動変更しないといけなかった
- バックアップ・リストアに非常に時間がかかっていた
- レプリケーション(同期)の遅延があり、時々整合性が取れていないことがあった
良い点
反対に、MySQLを運用していてメリットに感じた点もご紹介します。
- 安価
- セカンダリDBもReadDBとして使用可能
- phpMyAdminでスロークエリ、ログ取得など監視可能
- テーブル単位のバックアップ・リストアが可能
移行後の必須要件
上記の状況を踏まえて、移行後の必須要件を以下の2点に設定しました。
- 2台以上での冗長化かつ障害時の自動切替が可能であること
- 監査的の観点から、個人情報の入ったデータへのアクセスを監視できること
この観点で製品選定を実施しましたので、その際の比較した内容をご紹介します。
比較選定のための調査
オンプレ、AWS、Azure、GCPの各サービスを比較検討することにしました。
オンプレミスサーバー「MS SQLのAlways On構成」
構成
必要条件を満たす構成を検討しました。Enterpriseエディションは予算的に選択できませんでした。
- Windows Sever 2016 Standard + MS SQL Server 2016 Standard
- Always On 可用性グループでの冗長化
問題・課題点
上記構成にてMySQLと比較した場合に生じた課題点は以下の通りです。
- StandardエディションでのAlways Onのため、冗長化のセカンダリDBがReadもできず、分析・開発に使えない
- テーブル単位でのバックアップやリストアができない
- スロークエリなどの監視をどうするか検討が必要
- クライアント数が多くてCALライセンスでは非常に高額になってしまうため、CPUコアライセンスを選択せざるを得ず、さらにCPUコア数でも金額が変わるため、CPUコアを少ないもので抑える対策が必要
- オンプレのため、老朽化対策のため数年後にはリプレイスが必要
- 監査のクエリ取得の検討が必要
良い点
検証時にMS SQLの良いと感じた点は以下の通りです。
- 冗長化がMS SQL任せでよく、レプリケーションの遅延もほぼ気にならない
- Always Onのリスナーがあるので、切り替えダウンタイムがほぼない
- Microsoft SQL Server Management StudioでGUI操作が容易
AWS「Aurora or RDS(MariaDB)」
既存MySQLを踏襲し、MariaDBで検討しました。
問題・課題点
以下のような、クラウド環境特有の課題がネックとなりました。
- 社内ネットワークとAWSネットワークの連携は複雑になりがちだが、Direct Connectなどを使うと高額
- 個人情報をクラウドに預けるというセキュリティ面の懸念(2016年当時)
- 監査のクエリ取得の検討が必要
- AWS経験者不足(2016年当時)
良い点
AWS検討時に良いと感じた点をご紹介します。
- 高可用性、基本的にはブラウザからのGUIベースで設定が可能
- MySQLからMariaDBへの移行を想定のため、データ変換はそこまで大変ではない
- オートスケールやインスタンスタイプの変更など柔軟に可能
MS Azure「Azure SQL Database」
早々に費用面がネックになり、調査はあまり行いませんでしたが、簡単に課題点、良い点をご紹介します
問題・課題点
- 当時のマネジメントパネルが非常に使いづらく、わかりにくかった
- DTUなども検討したが、想定よりも高額だった
良い点
- 高可用性、基本的にブラウザからのGUIベースで設定が可能
GCP「Google Cloud SQL」
当時、情報が少なく、カスタマイズもあまりできない状況だったので早々に断念しました。
以上の検討内容を元に、選定の際に重要視していた点をまとめたのが以下の表です。
検討結果とMS SQLの選定理由
| 可用性 | フェイルオーバー | コスト | バックアップ | 監査対応 | |
|---|---|---|---|---|---|
| オンプレ | 〇 | 実装容易 | 〇 | 〇 | 〇 |
| AWS | ◎ | 実装可能 | △ | ◎ | × |
| Azure | ◎ | 実装可能 | × | ◎ | 不明 |
| GCP | 〇 | 不明 | 不明 | 不明 | 不明 |
以上の調査結果を踏まえて、MS SQLを選定することにしました。理由について以下で説明します。
MS SQLの選定理由
細かい理由は他にもありますが、下記6点が大きな選定理由となりました。
AWSとイニシャル・ランニングコストで比較計算したが、オンプレのMS SQL構成は数年以内にペイできてしまう結果となった
当時のZOZOUSED内では、AWSやAzureの導入実績がなかったため、コアシステムの構築・運用が不安視された
Always Onによる冗長化が簡単で高性能であり、リリースまでが短期間で済む想定だった
Webサーバーはオンプレに置いておく想定だったため、DBをクラウドにしてしまうと流れるデータのセキュリティや欠損率を考慮しなないといけなくなる
クラウドでのクエリ監査対応が、当時の環境では実現が難しかった
構築当時「ZOZOUSEDのお客様の重要な個人情報」をクラウドに置くことに対して社内での懸念があった
| Always On正常時のイメージ | プライマリ障害時のイメージ(自動切換え) |
|---|---|
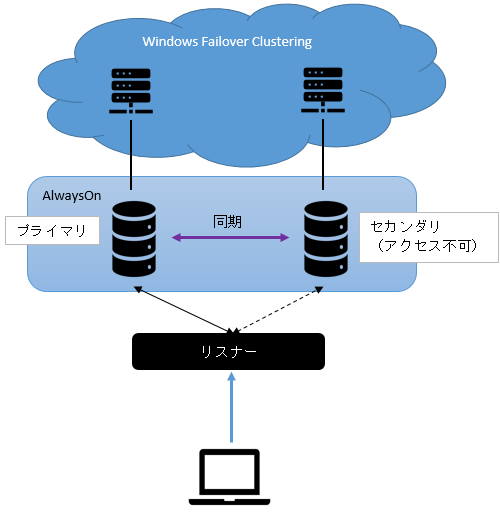 |
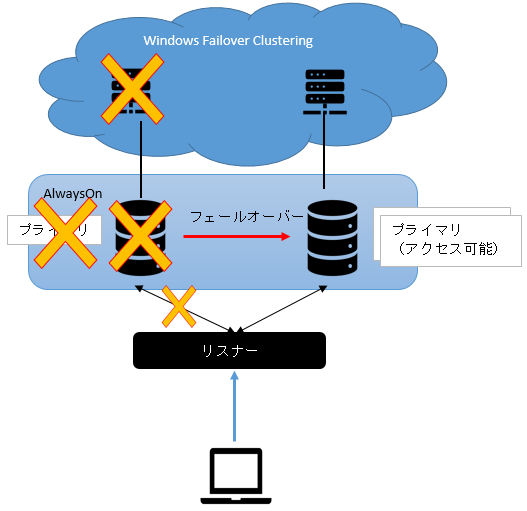 |
以上のことから、MS SQLを導入しました。その結果フェイルオーバーなど、MySQL運用時に抱えていた課題を解決できました。ただし、導入~運用フェーズにおいていくつか別の課題に直面したので、それらをどう解決したかご紹介します。
MS SQLで生じた課題と解決方法
1. 冗長化のためのセカンダリDBがReadもできず、分析・開発に使えない
分析チームからは「AM5:00に同期される前日のデータを使った解析をしなければならない」という要件がありましたが、本番DBは個人情報があること、また分析の高負荷を容認できないことから直接の本番DBへのアクセスは不可としていました。
さらに、StandardエディションでのAlways Onのため、冗長化のセカンダリDBがReadもできません。
しかしながら、移行のおかげでバックアップおよびリストアにかかる時間がMySQLに比べて飛躍的に短くなりました。そのため、同期完了後にバックアップし、そのバックアップデータを別サーバーにリストアするスクリプトを作成することで、前日のデータが入った開発用DBを始業開始までに用意することが可能になりました。これにより、上記の要件を解決することができました。700GB程度のDBがバックアップ開始からリストア完了まで3時間程度で完了できています。
2. テーブル単位でのバックアップやリストアができない
業務上、稀にバックアップから復元したいデータが出てきてしまうということがありました。MySQLであれば、バックアップからテーブル単位などでリストアできました。MS SQLではそれができないのですが、MS SQLへ切り替えた結果、フルバックアップのリストアが1時間程度で済むようになったため、フルリストアしたものからテーブル単位などでデータを移動することが可能なため、この制約は問題にはなりませんでした。
3. 個人情報の入ったデータへのアクセスを監視しなければならない
今まで通り、監査要件として個人情報の入ったテーブルへのアクセス履歴を追えるようにする必要があったため、MS SQLの監査機能を利用し、ファイルにクエリを吐き出し、そのファイルをDBサーバーにインサートすることでこの要件を満たすことができました。実際に設定した監査の例をご紹介します。
MS SQL監査設定の例
まず、SQL Server Auditを使用してサーバーの監査オブジェクトを作成します。
こちらでは、吐き出すログファイルの保存先や容量、クエリ遅延秒数などを設定しています。
USE [master]
CREATE SERVER AUDIT [インスタンスの監査名称]
TO FILE
( FILEPATH = N'ファイルを吐き出すパス'
,MAXSIZE = 200 MB
,MAX_ROLLOVER_FILES = 2147483647
,RESERVE_DISK_SPACE = OFF
)
WITH
( QUEUE_DELAY = 1000
,ON_FAILURE = CONTINUE
,AUDIT_GUID = '****************'
)
ALTER SERVER AUDIT [サーバーの監査名称] WITH (STATE = ON)
GO
続いて、データベース監査の仕様を作成します。
監査要件から、すべてのテーブルに対する「DELETE、INSERT、UPDATE」と特定のテーブルに対しての「SELECT」を取得するように設定しています。
USE [データベース名]
CREATE DATABASE AUDIT SPECIFICATION [作成するDB監査の名称]
FOR SERVER AUDIT [サーバーの監査名称]
ADD (DELETE ON DATABASE::[データベース名] BY [dbo]),
ADD (INSERT ON DATABASE::[データベース名] BY [dbo]),
ADD (UPDATE ON DATABASE::[データベース名] BY [dbo]),
ADD (SELECT ON OBJECT::[dbo].[テーブル名] BY [dbo]),
ADD (SELECT ON OBJECT::[dbo].[テーブル名] BY [ユーザー名])
WITH (STATE = ON)
GO
4. スロークエリなどの監視をどうするか検討が必要だった
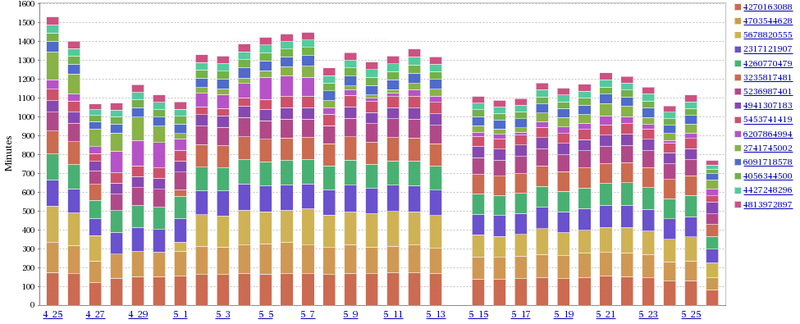
SolarWinds社のDPA(Database Performance Analyzer)を導入することで解決しました。2016年当時、国内実績はあまりなかったようですが、試用してみて有用だと判断し導入しました。トラブルシューティング時の調査、インデックス不足、日次業務の変化把握などに役立っています。
| Database Performance Analyzerの画面 | |
|---|---|
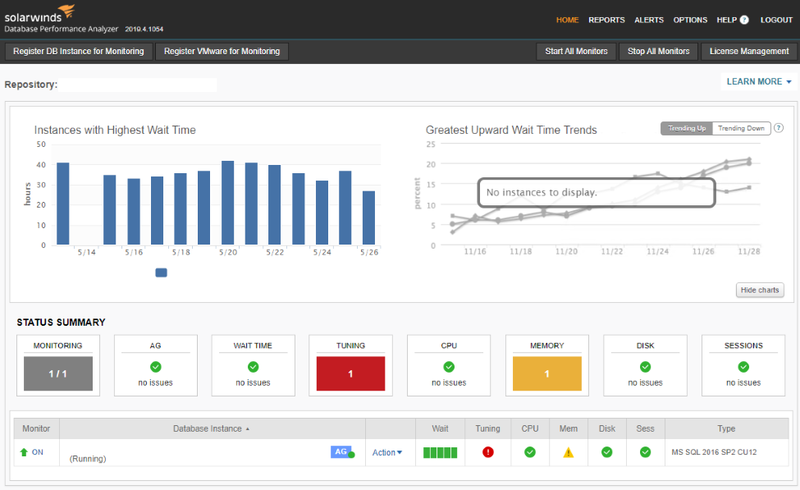 |
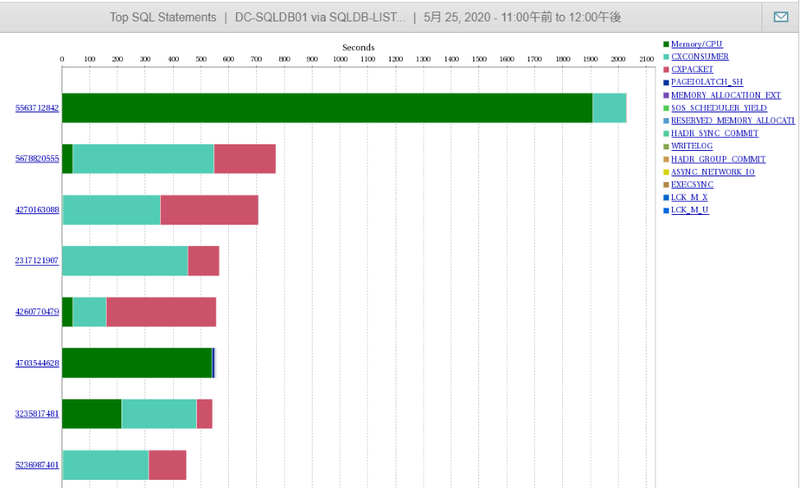 |
| トップ画面 | 何が要因で時間がかかっているのかわかる |
 |
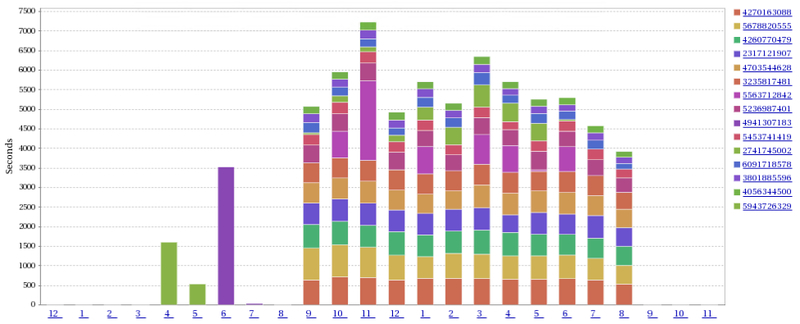 |
| 日毎のクエリ実行時間が可視化 | 時間毎のクエリ実行時間が可視化 |
5. Always Onのリスナー(ADへのコンピュータアカウント)が自動で作成されない
Webに公開されている構築手順やブログを頼りに構築検証していましたが、なぜか手順通りにいきませんでした。Always Onの設定時、AD上にリスナー用のコンピュータアカウントを事前に作成し、アカウントのセキュリティに対して使用するクラスターアカウントのフルコントロールのアクセス権を付与しなければならないということがありました。
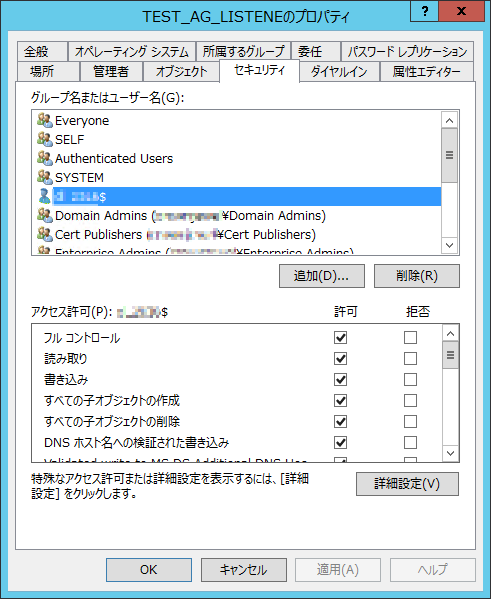
6. フェイルオーバー後にユーザーがログインできなくなる
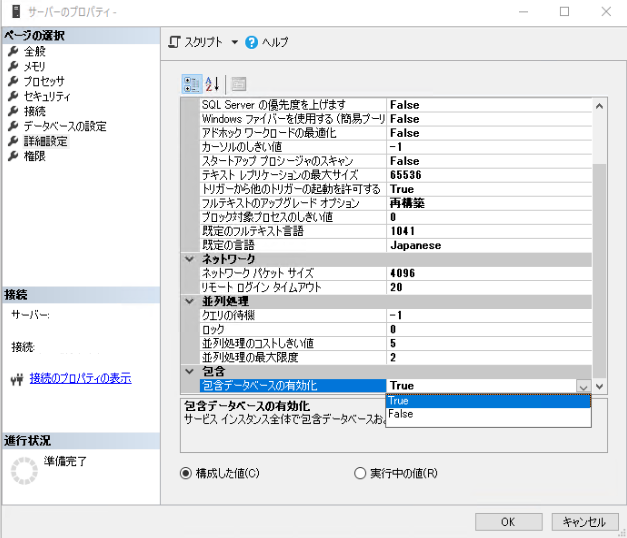
包含データベースの有効化はしていましたが、ユーザーが包含ユーザーになっていませんでした。
そのため、サーバーユーザーとデータベースユーザーの紐づけが切れてしまっていました。
包含データベース設定 + 包含ユーザーを作成することで、フェイルオーバーしても包含ユーザーでアクセスできるようになりました。
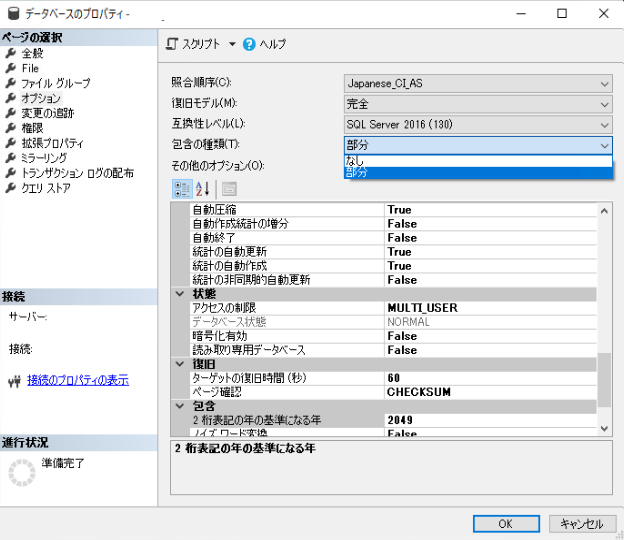
| 包含データベースの有効化 | 包含データベースに設定 |
|---|---|
 |
 |
7. 包含ユーザーだとbulkのコマンドが使えない
サーバーにユーザーを作成し、bulkadminのロールに属する必要がありました。

8. 上記bulkユーザーがフェイルオーバー後にログインできなくなる
包含ユーザーではないため、フェイルオーバー時にサーバーユーザーと包含ユーザーの紐づけが切れてしまうことが発覚しました。フェイルオーバー後に手動で以下のコマンドを実行し、サーバーユーザーと包含ユーザーの紐づけを修正することで解決しています。
USE [データベース名]; ALTER USER [包含ユーザー名] WITH LOGIN = [サーバーユーザー名];
9. トランザクションログが肥大化する
データベースの復旧モデルは完全復旧モデルを選択しました。完全復旧モデルの場合は、トランザクションログはログファイルにどんどん蓄積されてしまい、何も対応しないとディスクが枯渇し、書き込み操作が一切できなくなってしまう恐れがあります。1日1回の完全バックアップに加えて、メンテナンスプランで15分ごとにトランザクションログをバックアップすることでこまめにログの切り捨てを行うことでこの懸念点を解消しました。
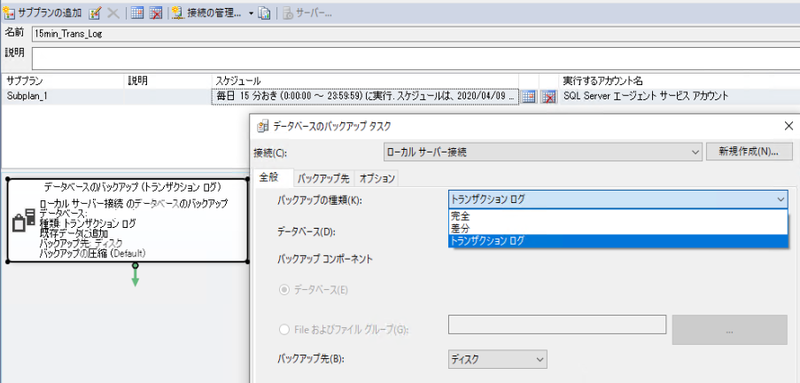
10. ファイアウォールによりAlways Onの同期が停止する
Windowsファイアウォールでアクセスを絞る案件がありました。その際、レプリケーションに使われているポート(デフォルトは5022)に気づかず同期を止めてしまいました。Windowsファイアウォールにそのポートを開けて復旧しました。
これは、バックアップデータが非常に増えたことから発覚しました。データベースのログファイルが肥大化しており、トランザクションログが退避されなくなったことによるものと推測しています。

さいごに
SRE部USED基幹インフラでは、導入後からOS、DB、NWでチューニングを続けています。今期、Webサーバーをクラウドに移行する予定もありチューニングや見直しを引き続き実施し、さらなる高速化・安定化を目指しています。
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!