




はじめに
こんにちは、SRE部カート決済SREブロックの伊藤です。普段はZOZOTOWNのカート決済機能のリプレイス・運用・保守に携わっています。また、チームを跨いだ横断活動としてデータベース(以下DB)周りの運用・保守・構築に関わっています。
ZOZOTOWNではSQL Serverを中心とした各種DBMSが稼働しています。本記事はSQL Serverのパフォーマンスを調査する上で進めた可視化についての取り組みをご紹介します。
従来の方法
以前下記のテックブログで紹介させていただきましたが、弊社では動的管理ビュー(Dynamic Management View:以下、DMV)や拡張イベントの情報をロギングしています。
これらの情報を用いることで何かトラブルが起こった際には後追いできる状況を整えています。
例えば特定の時間帯にクエリが滞留した際には次のクエリを実行することで、滞留していたクエリの詳細な情報を調べることができます。
SELECT collect_date, count(*) AS [クエリの滞留数(全体)] FROM [dbo].[dm_exec_requests_dump_per_several_seconds_20230502] WHERE collect_date between @start_date and @end_date GROUP BY collect_date ORDER BY collect_date ; SELECT collect_date, wait_type, count(*) AS [クエリの滞留数(wait毎)] FROM [dbo].[dm_exec_requests_dump_per_several_seconds_20230502] WHERE collect_date between @start_date and @end_date GROUP BY collect_date, wait_type ORDER BY collect_date, wait_type ; SELECT collect_date, current_running_stmt, count(*) AS [クエリの滞留数(statement毎)] FROM [dbo].[dm_exec_requests_dump_per_several_seconds_20230502] WHERE collect_date between @start_date and @end_date GROUP BY collect_date, current_running_stmt ORDER BY collect_date, current_running_stmt ;

他にも、ストアドプロシージャ(以下、ストアド)の実行統計 sys.dm_exec_procedure_statsもDumpしています。
ストアドに修正を行なった際の監視や、特定のストアドが突然パフォーマンス劣化した際などはこちらを確認することで具体的なパフォーマンスを調べることができます。
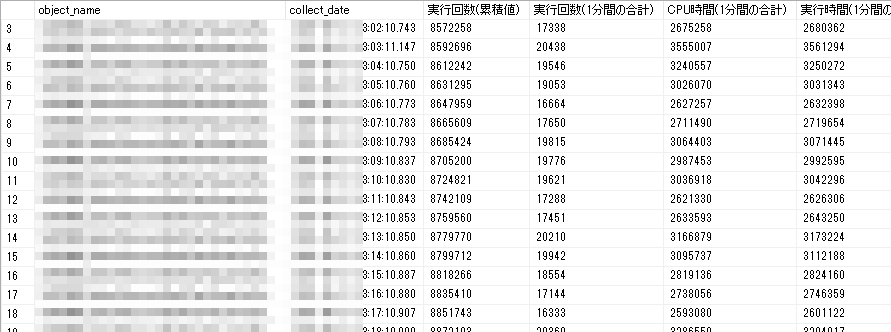
オリジナル情報は累積値となっているため、LAG関数を使用して1分前の情報と差分を取ることで1分間の実行回数や実行時間を出力しています。
SELECT object_name, collect_date, execution_count AS '実行回数(累積値)', -- リセットされていたらキャッシュアウトされた可能性あり CASE WHEN cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date) THEN CONVERT(nvarchar, execution_count - LAG(execution_count, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS '実行回数(1分間の合計)', CASE WHEN cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date) THEN CONVERT(nvarchar, total_worker_time - LAG(total_worker_time, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS 'CPU時間(1分間の合計)', CASE WHEN cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date) THEN CONVERT(nvarchar, total_elapsed_time - LAG(total_elapsed_time, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS '実行時間(1分間の合計)', CASE WHEN cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date) THEN CONVERT(nvarchar, total_logical_reads - LAG(total_logical_reads, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS '論理読み込み量(1分間の合計)', CASE WHEN cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date) THEN CONVERT(nvarchar, total_logical_writes - LAG(total_logical_writes, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS '論理書き込み量(1分間の合計)' FROM dbo.dm_exec_procedure_stats_dump WITH(NOLOCK) WHERE collect_date BETWEEN @start_date AND @end_date AND object_name = '<絞り込みたいストアドの名前>' ORDER BY object_name, collect_date
DMV運用の課題
ロギングしたDMVは上記のようにトラブルシューティング時に役立てることができますが、周りのメンバーに対応してもらうにあたってハードルの高さを課題として感じていました。
まず、上記のSQLを作るにはDMVについて理解を深める必要があります。SREの全員がDBに精通しているわけではなく、普段SQLを書かないメンバーもいるので学習コストが必要となります。
また、DBに接続するためにはプライベートなネットワークを経由する必要があるなど一手間かかります。本番環境で稼働しているDBサーバーに対してSQLを実行する必要があるので、日常的な運用には向いていません。
SQL Server 2016からはクエリの実行履歴を保存して可視化できるクエリストアの機能も追加されました。トラブルシュートする上で有用ではありますが、上記と同様の課題や表示速度なども含めて、運用の利便性が高いものとは言えませんでした。
そのためパフォーマンス悪化の徴候があったとしても後手に周り、問題が発生してからでないと気付きにくい側面がありました。
Splunkによるダッシュボード化
DMVの課題を解決するために取り組んだのがまずSplunkによるダッシュボード化です。
弊社ではさまざまな場所でSplunkを活用しています。過去のテックブログにもSplunkに関する記事がありますので、興味のある方は是非ご覧ください。
今回使用したのはSplunk DB Connectというアドオンです。Splunk DB Connectではデータベースの情報を直接インポートできる他に、カスタムクエリを定期的に実行して結果をSplunkに送信できます。
Splunk DB Connect自体のインストール方法やDBとの接続方法に関しましては公式ドキュメントをご参照ください。
DMVの可視化例
冒頭でDMVの活用例としてストアドのパフォーマンス調査を挙げましたが、まずはこちらをSplunk DB Connectで毎分実行し、Splunk側へ蓄積されるようにしました。作成したのが下記クエリです。
ストアド毎に、3分前から1分前の間にdumpとして保存された2つのレコードを取得し、差分を出力しています。SQL内のコメント文はSplunk DB Connectで設定する際に動作影響が出るため削除しています。
DECLARE @start_date DATETIME2 = dateadd(mi, -3, GETDATE()); DECLARE @end_date DATETIME2 = dateadd(mi, -1, GETDATE()); SELECT object_name AS 'stored_procedure', collect_date, exec_count_sum_1m, cpu_time_sum_1m, exec_time_sum_1m, logical_read_sum_1m, logical_write_sum_1m FROM (SELECT object_name, collect_date, CASE WHEN (object_id = LAG(object_id, 1, 0) OVER (ORDER BY object_name, collect_date)) and (cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date)) THEN CONVERT(nvarchar, execution_count - LAG(execution_count, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS 'exec_count_sum_1m', CASE WHEN (object_id = LAG(object_id, 1, 0) OVER (ORDER BY object_name, collect_date)) and (cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date)) THEN CONVERT(nvarchar, total_worker_time - LAG(total_worker_time, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS 'cpu_time_sum_1m', CASE WHEN (object_id = LAG(object_id, 1, 0) OVER (ORDER BY object_name, collect_date)) and (cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date)) THEN CONVERT(nvarchar, total_elapsed_time - LAG(total_elapsed_time, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS 'exec_time_sum_1m', CASE WHEN (object_id = LAG(object_id, 1, 0) OVER (ORDER BY object_name, collect_date)) and (cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date)) THEN CONVERT(nvarchar, total_logical_reads - LAG(total_logical_reads, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS 'logical_read_sum_1m', CASE WHEN (object_id = LAG(object_id, 1, 0) OVER (ORDER BY object_name, collect_date)) and (cached_time = LAG(cached_time, 1, 0) OVER (ORDER BY object_name, collect_date)) THEN CONVERT(nvarchar, total_logical_writes - LAG(total_logical_writes, 1, 0) OVER (ORDER BY object_name, collect_date)) ELSE '-' END AS 'logical_write_sum_1m' FROM dbo.dm_exec_procedure_stats_dump WITH(NOLOCK) WHERE collect_date BETWEEN @start_date AND @end_date AND object_name not like 'sp[_]%' AND exists ( select * from sys.objects ob with(nolock) where ob.object_id = object_id(object_name) and is_ms_shipped = 0 ) ) AS sample WHERE NOT exec_count_sum_1m='-' ORDER by collect_date, object_name
上記のクエリで収集した情報を次のようなサーチ文で可視化できます。
index="heavy_forwarder_db" sourcetype="dbconnect" host=XXX source="XXX-procedure-stats" | timechart span=1m useother=false limit=20 sum(exec_count_sum_1m) by stored_procedure

収集に使用した時間とSplunkが受信する時間に差があるので表示上少しのずれは発生してしまいますが、許容範囲としています。
また、上記のサーチ文では上位20件の情報を表示させていますが、別途テキスト入力欄を設けて特定のストアドを追えるダッシュボードも提供しています。
インストールされているServerのログ情報の送信
Splunk DB Connectとは別に、サーバーにSplunk Universal Forwarderをインストールすることでパフォーマンスモニタやイベントログを送信できます。
同一ダッシュボード内でイベントログとクエリのパフォーマンス情報を表示することで両者の相関関係を結びつけることができ、以下の切り分けが容易になります。
- サーバー自体の問題なのか
- サーバー上で動いているSQL Serverの問題なのか
- SQL Server上で実行された特定のクエリの問題なのか

Splunkによるダッシュボード化を行うことで、DMVやSQLに精通していないメンバーがトラブルシュートのために必要な情報を容易に取得できるようになりました。またプライベートなネットワークを経由して本番環境のDBサーバーにSQLを実行する必要がなくなり、運用の利便性と安全性の向上を実現しました。
DatadogのDatabase Monitoringについて
弊社ではDatadogも活用しています。
2022年8月、DatadogのDatabase Monitoring機能がSQL Serverに対してもサポートされるようになったため、オンプレミス環境の主要DBへの導入を進めました。
Datadog Agentのインストール方法については公式サイトをご参照ください。
データ収集は以下の理由からKubernetesクラスタ上にDatadog Agentのpodを立ててDBにアクセスする方法を採用しました。
- 元々RDSに接続してメトリクスを取得するための雛形を用意していたこと
- 何か問題があった場合にAgentのアンインストールが不要であること
- オンプレの場合は直接Agentをインストールした方がOSのメトリクスなど取得できる情報は増えるが別手段で収集済みであり、そこまで重要視しないこと
Database Monitoringを使用して改善した例
CPU使用率の高いクエリの検出と改善
Database Monitoringを有効化することで使用できるようになるクエリメトリクスビューではクエリ毎のリソース使用率を見ることができます。
次の画像はWORKER TIME(CPU)順で並び替えた画像であり、特定のクエリでCPUを多く使っていることがわかります。
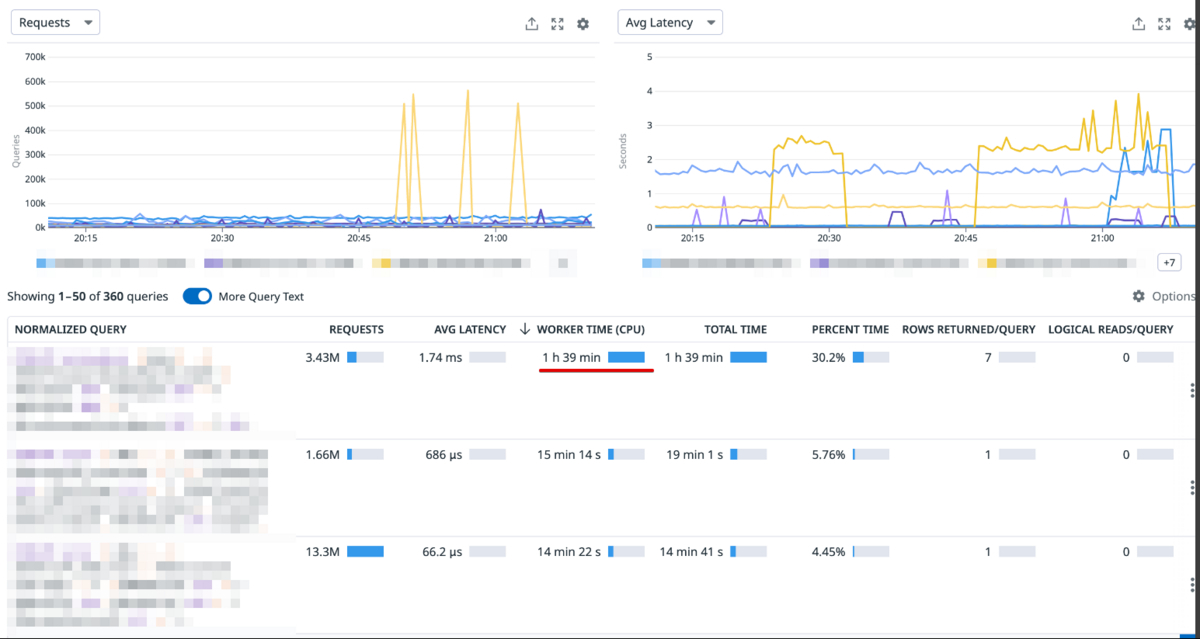
クエリの詳細を確認した結果が次の画像となりますが、グラフから実行時間が安定していないことがわかりました。それぞれの時間帯で記録されていた実行計画を見たところ、遅い時間帯のみ特定のテーブルでスキャンが発生していました。



スキャンするプランは望んでいないためFORCESEEKヒントを追加したところクエリパフォーマンスが改善し、DB全体のCPU使用率の改善も確認できました。

Database Monitoringの導入により、視野が広がったことで今まで問題視していなかった部分に対しても先回りして修正できるようになりました。手動で実施していたパフォーマンス情報の収集やキャッシュからの実行計画の収集もクエリメトリクスビューから閲覧可能なので不要となり、作業の効率化へと繋げられました。
パフォーマンスが急に悪化した場合の原因調査
実行計画の変化や特定の負荷がかかった場合などパフォーマンスが急激に悪化することが度々ありました。その場合はDMVを利用して深掘りを行なっていましたが、最初のアクションとしてDatabase Monitoringを確認するという手段が取れるようになりました。
画像はハードウェア起因のトラブルが発生し、エラーが多発してしまった際のものです。

WriteLogのWaitが大量に発生してしまっており、何らかの要因でトランザクション書き込みが待たされていることがわかります。
緊急時には一刻も早い原因特定が求められるため、簡単に確認ができ、また対応できるメンバーを増やせることは非常に嬉しいポイントです。
今までだと問題に応じて様々なDMVを使い分ける必要があり、対応メンバーにはDMVに対する知見が必要でした。Database Monitoringを活用することで様々な角度から初期調査ができ、属人化の削減に繋げられました。
今後の展望
以上のように、SplunkとDatadogを用いてDBのパフォーマンスを可視化する取り組みを進めました。
現状の両者の使い分けとしては、Datadogによって自動でパフォーマンスを取得し、カバーしきれていない範囲をSplunkのダッシュボードにまとめています。
ただしその理由は時系列的な側面が強く、例えばDatadogでもカスタムクエリを使用したメトリクス化は実現可能であるためそれらをDatadog側に寄せていくことも可能です。
一方でSplunkは自社ではDBに関連する様々なリソースのログも蓄積されてきているため、相関的に情報を得やすいというメリットが存在します。
両者のメリットを活かしつつ、さらに最適なDBパフォーマンスの可視化戦略を今後考えていきたいと思います。
また、現状一部のDBにしか対応できていないため、他のDBに対しても同様の可視化を進めていきたいです。
最後に
ZOZOでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!