



こんにちは。アーキテクト部の廣瀬です。
私は2021年7月に、Data PlatformカテゴリにおいてMicrosoft MVPを受賞しました。昨年に続き2度目の受賞です。これからも受賞し続けられるように引き続きがんばります。
弊社ではサービスの一部にSQL Serverを使用しています。以前テックブログでSQL Serverの障害調査フローをご紹介しました。その中で動的管理ビュー(Dynamic Management View:以下、DMV)と拡張イベントの情報を保存(ロギング)しておき、障害調査に活用していることをご紹介しました。このロギングによって障害発生時の原因特定率が劇的に向上しています。具体的なトラブル解決事例を、以下のテックブログで紹介していますので、よろしければご覧ください。
techblog.zozo.com techblog.zozo.com techblog.zozo.com
本記事では、弊社で取り組んだSQL Serverロギングの仕組み作りについて詳しく紹介します。
SQL Serverロギングの有用性
パフォーマンスカウンターが提供するような数値ベースのメトリクスは、監視製品を導入すれば容易に可視化できます。そのため、クエリタイムアウト多発などの障害が発生した際に確認すれば、「CPU使用率が100%に張り付いていた」や「ワークスペースメモリの獲得待ちが多く発生していた」という事実が分かります。
しかし、これだけでは「どのクエリがそこまでの負荷増を招いたのか」「どのクエリがワークスペースメモリを逼迫させていたのか」といったクエリレベルでの原因特定には至りません。このようなパフォーマンスカウンターの値だけでは根本原因が特定できないケースに備え、他の情報も組み合わせて保存しておく必要があります。
例えば、「特定の日時において実行中だったクエリリスト」と「各クエリが消費したCPU時間と、獲得したワークスペースメモリサイズ」が後から確認できるとします。それが実現すればパフォーマンスカウンターの情報と組み合わせてクエリレベルでの根本原因を特定できます。原因が特定できれば、クエリチューニングなどの再発防止に繋がる具体的なアクションをとることが可能です。このように、障害発生時の原因特定率を向上させるためには、SQL Serverのロギングを如何に充実させるかが重要です。
ロギングの機能を備えた監視製品
監視製品の中には、例えばSpotlightのように、「現在実行中のクエリ」を約1分間ごとに保存してUI上で後追いできるものもあります。とても便利なのですが、以下の点で物足りなさがあります。
最短1分というインターバルが長い
Spotlightでは、サーバーの過去の状況を最短1分単位で遡って確認できます。しかし、OLTPワークロードメインのWebサービスでは、クエリタイムアウト時間が数秒から数十秒であることがほとんどだと思います。5秒でタイムアウトするWebサービスで、現在実行中のクエリを1分ごとにロギングしても、クエリの情報がログに保存される可能性は低いです。したがって、タイムアウトした原因を後追いできる可能性も低いでしょう。
取得したい情報を拡充できない
Spotlightでは、テーブルの統計情報がいつ更新されたのかを調べることができません。一方で、原因調査にあたっては、この情報が重要な手がかりになることが少なくありません。自前でロギングの仕組みを作っていれば簡単に取得情報の拡充が可能ですが、既成の監視製品を使う場合は、追加での情報取得が難しいことがあります。
以上がSQL Serverのロギングを充実させることの重要性と、ロギングの仕組みを内製化する動機です。ここからは、その仕組み作りについて説明します。SQL Serverが元々提供している情報を適切に蓄積することで、これを実現します。
ロギングの仕組み作り
ロギングは、DMVと拡張イベントを元にしたクエリを使って実現します。それぞれ解説します。
DMVを元にしたログ
本記事で作成したロギングの仕組みでは、DMVから大半の情報を取得しています。DMVとはSQL Serverの状態情報が格納されたViewのことで、沢山種類があります。私の環境では、SQL Server2016で237種類、2019で275種類のDMVが用意されていました。DMVには以下のような特徴があります。
- サーバースコープ(=どのDBでSELECTを実行しても結果が同じ)と、DBスコープ(=各DBによってSELECTの実行結果が変わる)の二種類がある
- 内部状態を管理しているViewなので、SELECTしか実行できない
- 更新はSQL Server内部で自動的に行われる
- SELECTするときは、スキーマ名(sys)をつける必要がある
- 例:select * from sys.dm_os_wait_stats
例えば、以下のクエリを実行することで「取得時点で、実行時間が1秒以上のクエリリスト」を取得できます。
select top 500 getdate() as collect_date ,der.session_id as spid ,der.blocking_session_id as blk_spid ,datediff(s, der.start_time, getdate()) as elapsed_sec ,db_name(der.database_id) as db_name ,des.host_name ,des.program_name ,der.status ,dest.text as command_text ,replace(replace(replace(substring(dest.text, (der.statement_start_offset / 2) + 1, ((case der.statement_end_offset when - 1 then datalength(dest.text) else der.statement_end_offset end - der.statement_start_offset) / 2) + 1), char(13), ' '), char(10), ' '), char(9), ' ') as current_running_stmt ,datediff(s, der.start_time, getdate()) as time_sec ,wait_resource ,wait_type ,last_wait_type ,der.wait_time as wait_time_ms ,der.open_transaction_count ,der.command ,der.percent_complete ,der.cpu_time ,(case der.transaction_isolation_level when 0 then 'Unspecified' when 1 then 'ReadUncomitted' when 2 then 'ReadCommitted' when 3 then 'Repeatable' when 4 then 'Serializable' when 5 then 'Snapshot' else cast(der.transaction_isolation_level as varchar) end) as transaction_isolation_level ,der.reads ,der.writes ,der.logical_reads ,der.query_hash ,der.query_plan_hash ,des.login_time ,des.login_name ,des.last_request_start_time ,des.last_request_end_time ,des.cpu_time as session_cpu_time ,des.memory_usage ,des.total_scheduled_time ,des.total_elapsed_time ,des.reads as session_reads ,des.writes as session_writes ,des.logical_reads as session_logical_reads ,der.scheduler_id ,der.dop ,deq.grant_time ,deq.granted_memory_kb ,deq.requested_memory_kb ,deq.required_memory_kb ,deq.used_memory_kb ,deq.max_used_memory_kb ,deq.query_cost ,deq.queue_id ,deq.wait_order from sys.dm_exec_requests der join sys.dm_exec_sessions des on des.session_id = der.session_id left join sys.dm_exec_query_memory_grants deq on deq.session_id = der.session_id outer apply sys.dm_exec_sql_text(der.sql_handle) as dest where des.is_user_process = 1 and datediff(s, der.start_time, getdate()) >= 1 order by datediff(s, der.start_time, getdate()) desc option (maxdop 1)
以下は、取得結果の例です。

この結果からは、waitforで1分待つクエリが2秒間実行中であることが分かります。ただし、あくまで「今現在の情報」なので、過去に遡って「2021/08/01 22:00時点で1秒間実行中だったクエリリスト」の後追いはできません。そこで専用のテーブルを作成し、1分間隔など定期的に実行結果をINSERTしておけば、特定日時のDBの状態を後追いできるようになります。
拡張イベントを元にしたログ
拡張イベントとは、SQL Serverに関する様々なイベントの発生を収集できる機能です。例えばログイン、ストアドプロシージャのリコンパイル、クエリの中断(abort)、ブロッキングの発生などです。弊社では主にブロッキングの検出に拡張イベントを使用しています。検出したブロッキングイベントはxmlフォーマットで保存されます。xmlをパースするクエリを書くことで、ブロッキングイベントのクエリベースでの解析も可能です。しかし、ブロッキングのイベント数が多い環境下ではクエリ実行に数分かかることも珍しくありません。そこで、DMVのロギングと同様に専用のテーブルを作成し、拡張イベントの解析クエリ実行結果を定期的に保存しています。これにより、ブロッキングに関する調査クエリの実行時間が劇的に短縮化され、調査スピードが向上しました。
以上がロギングの仕組みです。次に、弊社で実際に使用しているロギング用のクエリをご紹介します。
ロギング用クエリ(MITライセンス)のご紹介
こちらに、SQL Serverの情報取得用のクエリを公開しています。MITライセンスでどなたでもご自由にお使いいただけます。本記事で紹介したロギングについては「sqlserver_logging」ディレクトリにクエリをまとめています。使い方はREADMEをご覧ください。本記事では、工夫した点を説明します。
1. 情報ごとに適切な取得間隔を設定
リポジトリの「使用例」ディレクトリに、各情報をどれだけの時間間隔で収集しているかをまとめています。基本的には1分間隔ですが、以下のようにいくつかのケースでは取得間隔を変更しています。
- DBのデータサイズは1日ごとの推移が確認できれば十分と判断して1日間隔にする
- 拡張イベントのブロッキングイベントのパースクエリは実行時間が長くなるため、1時間に1回まとめてデータを保存する
- 「現在実行中のクエリ」はOLTPワークロードの後追い用に5秒間隔、バッチ処理の後追い用に1分間隔でそれぞれ取得する
このように取得する情報の種類を適切に充実させるだけではなく、適切な間隔でロギングすることで欲しい情報を取得できる確率を向上させています。
2. 解析の精度向上
以前はこちらの記事で紹介している方法で解析していました。この方法はcpu使用時間など、累積されていく値を2点間の差分をとって集計する、という思想に基づいた解析方法です。この方法でもある程度は正確にボトルネッククエリをリストアップできますが、以下のようなケースの内、クエリAとクエリBしか考慮できていませんでした。
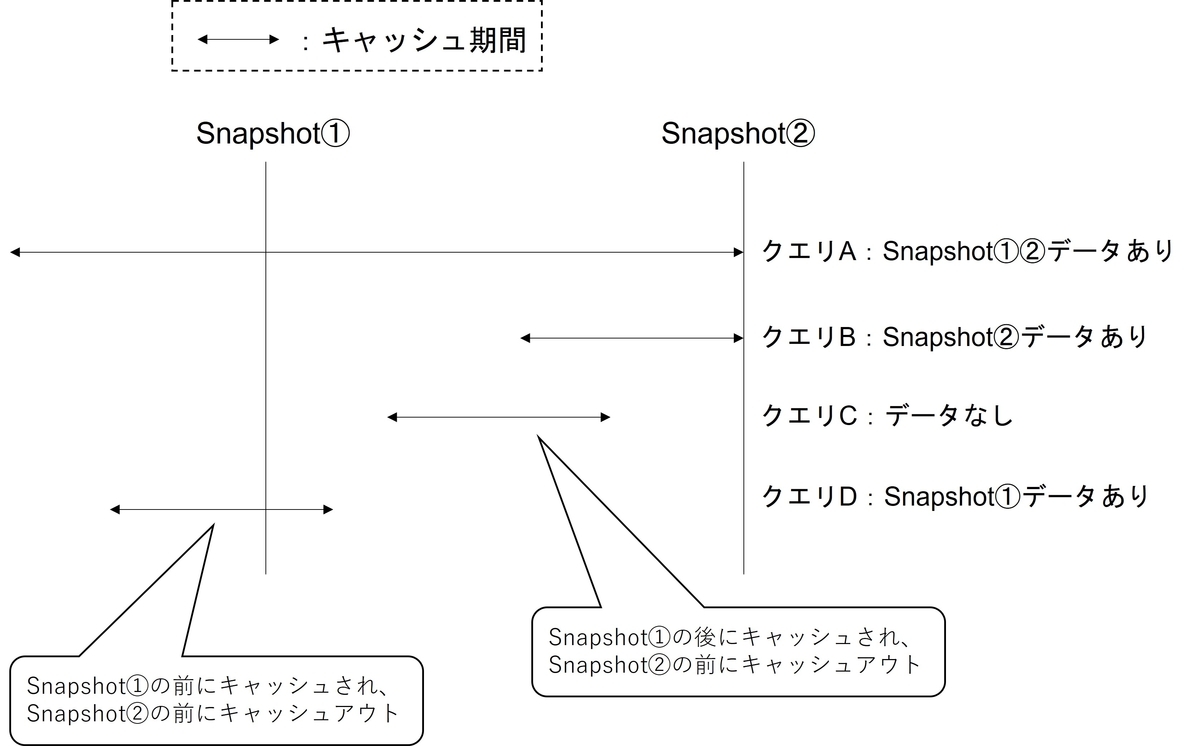
Snapshot①と②の間隔が数分など短い場合や、DBサーバーのメモリに余裕があってほぼキャッシュアウトされない環境であればこれでも問題ありません。しかし、1時間や1日単位でボトルネック調査をしたい場合や、頻繁にキャッシュアウトされる環境下では精度低下の懸念があります。Snapshot間隔の間でキャッシュインとキャッシュアウトが起こったり、Snapshot②を取得する前にキャッシュアウトされることも十分考えられるためです。そこで、解析精度を向上させるために2点の情報を使うのではなく、抽出期間に存在する全てのSnapshotを利用する方針にしました。例えば、特定の1時間のCPUボトルネックを調査したい場合、Snapshot①とSnapshot②の間には約60個のSnapshotが存在します。
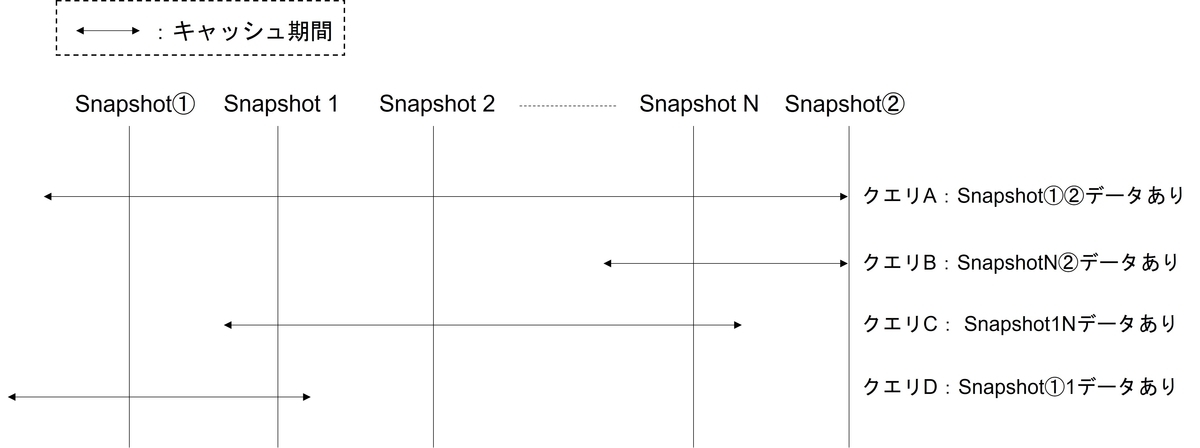
これらの情報も使うことで、今までの方法であれば見落としていたクエリCやクエリDも抽出できるようになり、解析精度が向上しました。
オーバーヘッドについて
取得する情報のサイズや詳細度と、サーバーにかける負荷(オーバーヘッド)はトレードオフの関係であることがほとんどです。DMVを使った定期的なクエリ実行も拡張イベントの取得も、オーバーヘッドはかかってきますが、弊社では許容できる範囲内と判断しました。ただし、環境ごとに状況は異なってきますので、取得する情報を増やした際は必ずパフォーマンスへの影響を確認しましょう。
推奨のアプローチは次のとおりです。
- パフォーマンスカウンターの収集、可視化を有効にし、 パフォーマンスのベースラインを設定する
- DMVや拡張イベントを順次有効にする
- それぞれの設定前後でCPU、メモリ、I/Oなどのリソースの変化を確認することでオーバーヘッドが許容できるかを判断する
また、SQLServer:Batch Resp Statisticsを使って実行時間とCPUに関するクエリ分布の変化を確認するのも有効です。このメトリックを使ったパフォーマンス影響の調査事例としては以下の記事がありますので、よろしければご覧ください。
クエリストアとの使い分け
SQL Server2016以降では、クエリストアという機能が提供されています。この機能を有効にすることで、以下のような調査、対応が可能になります。
- クエリプランの後退が発生しているクエリの特定とプランの修正
- CPUや実行時間、I/Oなどリソース消費量の多いクエリの特定
クエリストアで取得可能な情報については、クエリストアを使用した方が簡単かつ高精度な情報を得ることができます。上記のようなトラブルシューティングではクエリストアを使用しつつ、以下のようなシナリオで内製ロギングの情報を使用する、というように使い分けると良いでしょう。
1. クエリストアの設定値よりも短い時間枠で調査したい
クエリストアは、1時間など特定の時間枠ごとにパフォーマンス情報を蓄積していきます。この時間枠は短くもできますが、短くするほどクエリストアの保存データが増加していきます。したがって、通常は15分や30分、1時間などの時間枠で設定することが多いかと思います。このとき「特定の5分間で最もCPUを消費したクエリを特定したい」という場合は、内製ロギングの情報を使用することでより正確に後追いできる可能性があります。
2. クエリストアでは取得されない情報を確認したい
各インデックスごとのseek、scan、lookup回数などはクエリストアでは確認できません。したがってロギングの仕組みで保存した情報を活用します。
ロギングする情報の継続的な拡充
最初にリポジトリを公開した時点でも、収集したログが多種多様な障害の原因調査に役立っていました。しかし、原因が特定できないケースもあります。そのときは「どんな情報があれば原因を後追いできたか?」という疑問を出発点にして、取得する情報を拡充してきました。このように、ログを使った調査と取得情報の拡充というサイクルを回し続けることで、原因の特定に至る確率を向上させ続けています。
今後の展望
最後に、ロギングの仕組みの今後の展望について説明します。
仕組みの改善
現在はロギングの処理をSQL Serverのジョブとして各サーバーで実行し、各DBにログを直接保存しています。したがって以下のような課題を抱えています。
- ロギングの仕組みの修正コストが高い
- ログ容量を気にする必要がある
- 多少の負荷増につながっている
そこで、今後はログの収集基盤を別途構築し、ログ収集クエリや実行頻度などの修正コストも大幅に下げらえるよう仕組みを改善していきたいと考えています。
開発者にとって使いやすいログ解析の仕組みの提供
現在は「dm_exec_requests_dump」など元となったDMVの名前を意識したテーブル名にしています。また、できる限り様々な事象を後追いできるように保存しているカラムも多岐にわたります。SQL ServerのDMVに馴染みのある人には使いやすいと思うのですが、そうでない人たちにとっても使いやすい仕組みへと改善したいと考えています。例えばテーブル「dm_exec_requests_dump」を「requests_log」という名前のViewでラップし、カラムも必要最小限に限定した上で、使い方をドキュメントにまとめて共有会を開催するといったことを考えています。
まとめ
本記事では、障害時の調査などに活用できるSQL Serverロギングの仕組み作りについて説明しました。この仕組みによってSQL Server起因のトラブルの原因特定率が劇的に向上しました。弊社で使用しているロギング用のクエリをOSSとしてGitHubに公開しておりますので、よろしければお使いください。
最後に
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!