



はじめに
こんにちは、データシステム部推薦基盤ブロックの上國料(@Kamiko20174481)とMA推薦ブロックの住安(@kosuke_sumiyasu)です。
私たちは2025年9月22日〜9月26日にチェコのプラハにて開催されたRecSys2025(19th ACM Conference on Recommender Systems)に現地参加しました。本記事では会場の様子や現地でのワークショップ、セッションの様子をお伝えすると共に、気になったトピックをいくつか取り上げてご紹介します。
- はじめに
- RecSys とは
- 開催地のプラハについて
- 会場の様子
- 論文の紹介
- Orthogonal Low Rank Embedding Stabilization
- Suggest, Complement, Inspire: Story of Two-Tower Recommendations at Allegro.com
- Recommendation and Temptation
- Time to Split: Exploring Data Splitting Strategies for Offline Evaluation of Sequential Recommenders
- Enhancing Embedding Representation Stability in Recommendation Systems with Semantic ID
- VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings
- 終わりに
RecSys とは
RecSys(ACM Recommender Systems Conference)は、推薦システム分野における最も権威のある国際会議の1つです。ここでは、各国の大学研究チームやGoogle、Netflix、Metaなどの世界有数の企業が参加し、幅広い研究成果を発表します。
この会議の特徴としては、アルゴリズムそのものを追求するような基礎的な研究にとどまらず、実際のサービス運用や評価方法、さらに法規則や倫理的な課題についても幅広く議論されることです。特に、今年はEUのDigital Services ActやAI ACTが整備されたことを背景として説明責任や透明性の担保が大きなテーマの1つとなっていました。
開催地のプラハについて
チェコの首都プラハで開催されました。街には石畳の路地や歴史的な建物が数多く見られ、旧市街広場やカレル橋といった観光名所も徒歩圏内に集まっています。学会会場のO2 universumは市内中心部から公共交通機関でアクセスしやすく、隣接するショッピングモールにはレストランやカフェが並んでいて食事や休憩にも便利でした。

日中は研究発表に没頭し、夕方には街歩きやソーシャルディナーでの交流を楽しめるなど、作業を切り替えやすい環境だったのが印象的でした。

会場の様子
初日と最終日には、特色のあるドメインのワークショップが開催されました。例えば、モデルに入力するコンテキストを扱うCARS、推薦のインタフェースや説明可能性に焦点を当てた IntRS、短期的なエンゲージメント最適化にとどまらず推薦が持つ長期的・社会的影響を考察するCONSEQUENCESなど、幅広いテーマが取り上げられました。そのほかにも、特定のドメインに特化したワークショップも人気を集めていました。音楽推薦を対象としたMuRSや、旅行分野に焦点を当てたRecTour、さらに実際のECサイトを題材に利益拡大やドメイン固有の課題解決について議論するGen AI for E-commerceなど、様々な関心を持つ参加者を満足させるテーマがありました。
本会議のセッションは、昨年のRecSys 2024でLLMやSequential Recommenderが目立っていたのに対し、今年はよりバランスよく多様なテーマが扱われていました。具体的には次のとおりです。
- Beyond the Headlines and Harmonies: The Focus on Music and News on Recommendation Generation and Evaluation
- Models that Reflect Us: The Focus on Users’ Interests and Preferences on the Recommendation Process
- Representation Meets Recommendation & Search
- Reflections on User Preferences leveraging LLMs
- Navigating User Journeys at Scale: Sequencing, Personalization, and Data-Driven
- Recommender Systems in the Wild: Domains and Society
- Recommender Systems Without Borders: Cross-domain Methods and New Recommendation Frameworks
- Multimodal Moments: Leveraging Vision, Sound, and/or Text for Recommendation
- Signals We Trust: Offline, Online, and Real World Evaluation of Recommender Systems
- Women in RecSys
セッションに加えて、会場の工夫による参加体験の満足度も高いと感じました。会期中には、午前・午後の軽食や昼食が提供されたのですが、形式は立食スタイルで参加者同士がテーブルを囲むことで会話が自然に生まれていました。雑談が研究議論へと発展する場面も多く、会場はとても活気にあふれていました。また、入場登録もスムーズに行えました。会場入口のセルフチェックイン端末に事前配布のQRコードをかざすだけで手続きが完了し、長い列はほとんどありませんでした。登録自体も2〜3分で済み、快適に入場できました。
論文の紹介
ここからは、カンファレンスを通して特に気になった論文を簡単に紹介します。
Orthogonal Low Rank Embedding Stabilization
Kevin Zielnicki, Ko-Jen Hsiao
この論文はNetflixの研究で、同社が運営する動画配信サービスにおける推薦システムの埋め込みベクトルを長期間にわたって安定して活用する方法を提案しています。具体的には、推薦モデルを定期的に再学習すると埋め込み空間の座標系が変化し、異なる学習回で得られた埋め込み同士の互換性が失われるという課題に取り組んでいます(例えば、埋め込みを特徴量として他のモデルに渡したり、ベクトル検索のためにデータベースに保存して活用したりする場合があります。その際、別の学習回で得られた埋め込みを混在させると整合性が崩れ、推薦結果が不安定になる可能性があります)。
著者らはこの課題を解決するため、モデル本体には一切手を加えず、後処理のみで埋め込みの座標系を揃える手法を提案しました。提案手法の流れは次の通りです。
- Low Rank SVD:埋め込みを主成分に基づく一意性の高い空間に移し替える
- Orthogonal Procrustes(直行変換):新規の学習で得られた埋め込みを、基準となる空間に揃える
この方法により、埋め込みベクトルを用いた推薦の精度を損なうことなく「次元ごとの意味」を固定でき、運用コストも小さく抑えられるとしています。
評価は異なる学習回の埋め込みを比較する実験で行われました。NetflixのTransformerベースの推薦モデルを用い、基準となる時点と2週間後・4週間後の埋め込みを比較しています。その結果、再学習を挟むと従来の方法ではコサイン類似度がほぼゼロでしたが、今回の手法を使うと0.75〜0.82に回復し、Rank-Biased Overlap(RBO)も0.5以上に改善しました。RBOは「2つのランキングがどのくらい重なっているか」を測る指標で、とくに上位の結果に重みを置いて比較します。著者らはこの結果について「安定化を行うことで、ユーザやコンテンツ表現が期間を超えて一貫性を持つようになり、再学習前と後におけるランキングの相関も優位に高まった」と述べています。
感想・考察
今回のNetflixの研究は、現場が抱えていた課題をシンプルに解決している点が印象的でした。学習プロセスには一切手を加えず、後処理として各埋め込みベクトルにd×dの直交行列を1回掛けるだけで埋め込み空間を安定化できるのが最大の特徴です。この計算は実務的に十分軽量と考えられるため既存システムにも容易に組み込め、導入コストに対して効果が大きいと感じました。
もちろん、基準となる座標系の定め方や長期運用での挙動には検討の余地がありますが、それでも「今すぐ現場で使える実装可能な解決策」を提示している点は今後の実務でも大いに参考にできる論文だと思いました。
Suggest, Complement, Inspire: Story of Two-Tower Recommendations at Allegro.com
Aleksandra Maria Osowska-Kurczab, Klaudia Nazarko, Mateusz Marzec, Lidia Wojciechowska, Eliška Kremeňová
ポーランド発の大手ECサイトAllegroが発表した本論文では、推薦システムで広く用いられているTwo-Towerモデルを基盤とし、簡単な拡張により1つのアーキテクチャで3種類の推薦タスクを実現しています。手法名と対応するタスクは以下です。
- Similarity-TT: 類似商品の検索
- Complementary-TT:補完商品の推薦
- Inspirational-TT:インスピレーションを促す商品の推薦
例えば「自転車」をクエリとした場合、Similarity-TTでは色違いや別モデルの自転車、Complementary-TTではヘルメットや膝あてといった関連アイテム、Inspirational-TTではベルやライトなど新しい発見を促すアイテムが推薦されます。
基盤となるTwo-Towerモデルは、商品カタログ内のクエリ商品を扱うクエリタワーと、ターゲット商品の埋め込みベクトルを扱うターゲットタワーから構成され、類似した商品の表現が近づくように学習されています。このモデルを用いて、以下の手法を行うことでタスクを実行します。
- Similarity-TT:クエリタワーに検索対象のアイテムを入力して埋め込みベクトルを獲得し、それをターゲットタワーの各アイテムのベクトルと比較することで、代替商品を推薦する。
- Complementary-TT:クエリタワーの出力に「どのカテゴリと一緒に購入されやすいか」という補完カテゴリ情報を組み込み、さらにFC層を追加することで補完の方向性を学習させ、補完関係にあるアイテムを推薦できるようにする。
- Inspirational-TT:事前準備として、商品埋め込みを事前にk-meansでクラスタリングを行う。そして、推論時には最も近いクラスタではなく、少し離れたクラスタから候補を取得する。そうすることで、単なる類似品にとどまらず、ユーザーに新しい発見を促す多様なアイテムを提示できる。

実験ではオンラインA/Bテストを実施し、Similarity-TTやComplementary-TTを従来の協調フィルタリングと比較した結果、CTRやGMVの向上が確認されました。さらにInspirational-TTでは、既存の商品ページとの比較で、CTAやCVRの改善に加え、離脱率の低下も確認されていました。
感想・考察
今回の学会では、この論文と同様に、タスクごとに個別の機械学習モデルを構築するのではなく、一つの汎用的なモデルを基盤として複数のタスクに応用するというアプローチがいくつかありました。その背景には、ユーザーの満足度を高めるためには、サイト上で関連商品をはじめ、類似商品、補完商品、インスピレーションを促す商品といった多様な切り口で商品を提示する必要が求められているからだと思います。そして、それをシステムとして効率的に実装・維持していくためには、個別最適化された多数のモデルを並行して運用するのではなく、共通の基盤モデルから様々な「見せ方」を生成できる設計が望ましいという強い流れを感じられました。
Recommendation and Temptation
Md Sanzeed Anwar, Paramveer S. Dhillon, Grant Schoenebeck
この論文では、従来の推薦システムが重視してきた「ユーザーエンゲージメントの最大化」とは異なる設計方針を提案しています。著者らは、短期的な行動を促すのではなく、ユーザーにとって長期的に価値のある選択を増やす推薦が望ましいと主張しています。
従来の推薦システムがエンゲージメント最大化を採用してきた背景には、ユーザーは常に自分にとって最も価値のあるアイテムを選ぶという前提がありました。しかし現実には、試験前に学習コンテンツではなく短い娯楽動画を見てしまったり、長編映画を観たいと思いつつSNSを延々とスクロールしてしまったりする、といった行動が多く見られます。
著者らはこの現象の原因を、人間の意思決定が「将来の自分の利益になる本質的な価値(Enrichment: 価値)」と「その場でつい惹かれてしまう即時的な魅力(Temptation: 誘惑)」のせめぎ合いによって決まるためだと考えております。従来の推薦システムはエンゲージメントを最優先するため、「誘惑の強いコンテンツ」を優先的に推薦することがあります。その結果、ユーザーは「つい見てしまったけれど後から後悔する」ような体験を繰り返し、長期的な満足度を損う恐れがあります。
本論文が提唱するのは、こうした従来の設計ではなく、ユーザーが実際に消費して得られる価値を最大化する推薦です。著者らは、価値と誘惑を組み込んだ行動モデルを導入し、消費された価値の最大化を目的関数として定式化するとともに、局所的に貪欲な戦略が最適であることを理論的に示しています。
さらに重要なのは、この設計方針がユーザーだけでなくコンテンツ提供者側にも作用する点です。推薦アルゴリズムが高い充実度を持つコンテンツを優遇すれば、動画などのコンテンツ制作者は自然と短期的な誘惑に依存しない質の高いコンテンツを作ろうとするようになります。これにより、プラットフォーム全体が長期的に健全な方向へ進むことが期待できます。
感想・考察
自分自身の体験としても、刺激の強いコンテンツには強く惹かれる一方で、そればかりが多いと結局は不満につながることがあります。逆に、将来的に自分にとって価値のあるコンテンツであっても、それが多すぎるとプラットフォーム自体に触れなくなってしまう、というジレンマも感じていました。本論文は、そうした感覚をうまく言語化し、さらに数理的に定式化しており大変学びが多かったです。
本研究は、推薦システムの設計思想におけるパラダイムシフトを提示しており、学術的な観点からも、実際のシステム設計という応用の観点からも大きな意義を持つ内容だと感じました。ただし、サービス運営の観点からは「長期的なユーザー満足度」をどのようなKPIで定量化すべきかはまだ明確でないため、今後も追うべき課題だと感じました。
Time to Split: Exploring Data Splitting Strategies for Offline Evaluation of Sequential Recommenders
Danil Gusak, Anna Volodkevich, Anton Klenitskiy, Alexey Vasilev, Evgeny Frolov
この論文は、シーケンシャル推薦のオフライン評価におけるデータ分割方法を整理したものです。
従来広く使われてきたLeave-one-out(LOO)は、各ユーザの最後の行動をテストとする方式です。しかしこの方法だと、例えば「ユーザーAの2020年の行動」を予測するときに「ユーザーBの2021年の行動」が学習データに含まれてしまうことがあります。つまり未来の情報が混ざり込むリークが起き、性能を実際以上に評価してしまう危険があります。
そこで著者らは、未来情報の混入を防ぐ Global Temporal Split(GTS) を検証しました。これはある時点で全体を過去と未来に分け、過去を学習に、未来をテストに使う方法です。ただし「未来側のどのイベントを予測対象にするか」で評価の特性が大きく変わります。論文では以下の5種類を比較しています。
- Last:テスト期間の最後のイベントを予測対象にする。
- First:テスト期間の最初のイベントを対象にする。
- Random:テスト期間からランダムに1件を選ぶ。
- All:テスト期間に含まれるイベントをすべて「正解」として扱う。
- Successive:テスト期間に含まれるイベントを順番にすべて予測対象とする。

加えて、検証データ(バリデーション)の分け方も検証されました。

- LTI(Last Training Item):各ユーザのテスト直前のイベントを使う。
- UB(User-based):一部のユーザをまるごと検証用にする。
- GT(Global Temporal):テスト前のある時点で切り、その直後からのデータを使う。
実験の結果、LastとRandomが計算効率と現実性のバランスが良く、実務に最も適していることが分かりました。Successiveは実際の利用状況を忠実に再現できる一方で、すべてのイベントを対象にするため計算コストが大きすぎます。Firstは前の行動から長い空白を挟んだイベントに偏りやすく、Allは「次の1件を当てる」という本来の目的から外れるため、いずれも不適切でした。
さらに、検証データの分け方を比較したところ、GTを使う方法が最も信頼できると示されました。ここでいう「信頼できる」とは、検証で良いと判断されたモデルや設定が、テストデータでも同様に良い結果を示す=検証結果とテスト結果が一貫しているという意味です。逆にLTIやUBのような方法では、検証とテストの結果が食い違いやすく、モデル選択を誤るリスクがあると言及しています。
加えて、学習と検証データを結合して再学習することで、モデル性能が大幅に向上することも確認されました。
感想・考察
まず、シーケンシャル推薦のオフライン評価におけるデータ分割について、ここまで体系的に比較した研究を聞けたのはとても意義深いと感じました。私自身もGTSのような手法を使う際に「どのイベントをターゲットにするか」で悩んだ経験があるので、この整理は非常に参考になります。
この研究が示すようにLastやRandomを基本に据え、GTでバリデーションを切る流れを押さえておけば迷いが減りそうです。モデル改善だけでなく評価設計そのものが精度に直結することを改めて実感し、今後のモデル開発にも役立つ知見だと思いました。
Enhancing Embedding Representation Stability in Recommendation Systems with Semantic ID
Carolina Zheng, Minhui Huang, Dmitrii Pedchenko, Kaushik Rangadurai, Siyu Wang, Fan Xia, Gaby Nahum, Jie Lei, Yang Yang, Tao Liu, Zutian Luo, Xiaohan Wei, Dinesh Ramasamy, Jiyan Yang, Yiping Han, Lin Yang, Hangjun Xu, Rong Jin, Shuang Yan
この論文はMetaの研究で、広告推薦におけるIDベース埋め込みの不安定さを、IDの設計と割り当てを作り替えることで解消しています。実務で一般的な割り当ては次の2つです。
- Individual Embeddings:各アイテムに専用の行を割り当てる方式
- Random Hashing:固定サイズの表へランダムに割り当てる方式
前者は、他アイテムとの干渉が起きない点では優れていますが、表がカタログ規模に比例して肥大化してしまいます。そのため出現頻度の低い、ロングテールアイテムや新規アイテムは十分に学習されず、表現が弱くなるという欠点があります。後者は、表のサイズを抑えられる点では実用的ですが、割り当てがランダムなので無関係なアイテムが同じ行を共有し勾配更新が干渉してしまいます。さらにIDが入れ替わると共有相手が変わるため、同じアイテムでも時間とともに表現が揺れてしまうという問題があります。
著者らはここに対し、アイテムのテキストや画像から得た特徴をRQ-VAEで階層コード列に量子化し、これをSemantic IDとして採用します。さらにprefix-ngramで上位からの接頭辞ごとにトークン化し、それぞれを埋め込み表の行に対応づけます。結果として以下のような実務上の利点を得られます。
- Semantic IDにより意味的に近いアイテムと重みを共有できるため、学習データが乏しいロングテールアイテムや新規アイテムでも安定した表現を獲得できる。
- prefix-ngramによって似たアイテムが同じ接頭辞を共有するため、IDの割り当て時におこる衝突が偶然ではなく意味に基づいて起き、学習をまたいでも表現が揺れにくい。
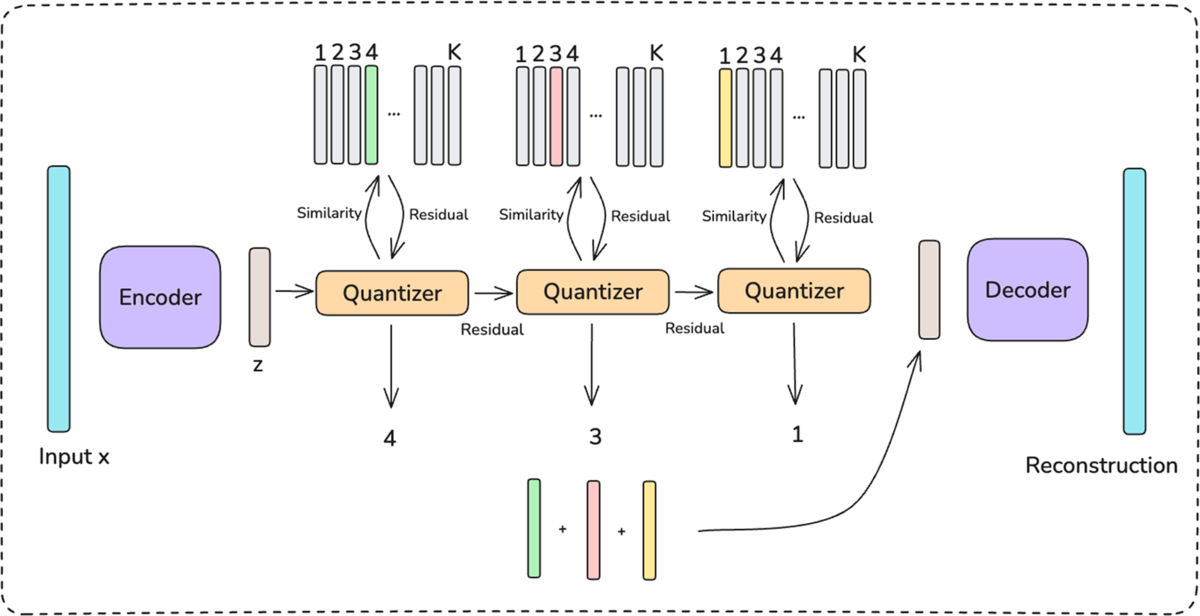
評価では、A/Aテストの予測ばらつきが43%減少、本番の広告配信でも主要オンライン指標が0.15%改善。加えて、長期学習下でも表現ドリフトが小さく、ロングテール・新規アイテムでの指標も一貫して向上しています。
感想・考察
この研究の新しさは、「IDの衝突を避ける」あるいは「IDをランダムに衝突させる」という従来の発想を捨て、衝突そのものを意味のある知識共有に変えた点だと思います。これにより、新規アイテムは「似ている既存アイテムの重み」を引き継いでスタートでき、ロングテールやコールドスタートに強くなります。さらに、IDが変わっても意味の近いコードに収まるため、埋め込みが揺らぎにくく、A/Bテストや本番配信でも安定性が高まります。
もちろん、この仕組みにはアイテムのテキストや画像から良い特徴を取り出すモデル(RQ-VAE)の学習・運用が前提となりますが、「ID自体に意味を与える」という発想で埋め込み表を根本から設計し直した点は実務的で、規模の大きなサービスで特に効果を発揮するアプローチだと感じました。
VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings
Ramin Giahi, Kehui Yao, Sriram Kollipara, Kai Zhao, Vahid Mirjalili, Jianpeng Xu, Topojoy Biswas, Evren Korpeoglu, Kannan Achan
こちらの論文は、米国大手ECプラットフォームWalmartの研究チームによるもので、Eコマース向けにCLIPの表現能力を高めることを目的とした研究です。CLIPとは、自然言語と画像を同一の埋め込み空間にマッピングすることで、相互に情報を補完しながら高い表現力を持つベクトル表現(Embedding)を生成できるモデルです。しかし、このCLIPをそのままEコマースの推薦システムに適用する際には、以下のような課題が存在します。
- CLIPは画像全体を処理するため、質感や金具の形状といった細粒度の特徴を十分に捉えられない
- 商品説明文は統一フォーマットで書かれているわけではなく、情報の質にばらつきや曖昧さがあるため、テキスト表現が安定しない
- CLIPはオープンドメインデータで学習されているため、プロが撮影した製品画像やEC特有のデータ分布には適応しにくい
これらの課題を解決するために、こちらの研究ではVL-CLIPを提案しています。VL-CLIPは、画像とテキストの入力を改善することで、CLIPの埋め込み表現を強化する仕組みです。画像側の改良では、画像をもとに自然言語から指示された物体を特定するVisual Groundingを用いて、製品画像の重要領域を抽出し背景などのノイズを除去します。それにより、製品そのものの特徴に焦点を当てた学習を可能にしています。テキスト側の改良では、LLMを活用して商品説明文・製品タイプ・性別などの属性情報を統合して初期クエリを生成し、その後LLMによる評価とフィードバックを繰り返すことで、精緻化された商品テキスト表現を作成しています。

実験の結果、検索タスクにおいてHIT@5はCLIPの0.3080に対し、VL-CLIPは0.6758と大幅に改善しました。加えて、実サービス環境で行ったオンラインA/BテストでもCTRやCVRが改善され、VL-CLIPが実用的かつ有効な手法であることが確認されました。
感想・考察
こちらの研究では、画像埋め込み生成に広く利用されているCLIPをEコマースドメインに適応させる手法を体系的に説明しています。商品アイテムのベクトル表現は複数のモデルやサービスで汎用的に利用される表現であるため、その精度を高めることは検索や推薦に限らず様々なタスクやサービス全体に好影響をもたらすと考えられます。実装コストはかかるものの、精度改善に向けて需要の高いアプローチだと感じました。
また、本論文で採用されているLLMを用いたテキスト生成・評価・クエリ精緻化のプロセスは、学会中に他の論文でも見られた方法で、特徴量生成において一般化しつつある手法だと感じました。特に、ノイズの多い商品説明文をLLMによって整理し、視覚情報と整合するテキスト表現に変換する点は、実運用における品質向上に大きく貢献していると考えられます。
終わりに
今回は、RecSys2025の内容の一片をお伝えしました。参加して良かった点は、現在のZOZOTOWNにおける推薦の立ち位置とその発展の方向性についてインスピレーションを得られたことです。特に、Industrial Paperで議論されている課題は自分たちも同じ課題を持っていることが多く、その解決の方向性を知れて、すぐにでも取り入れたくなるようなものが多かったという印象があります。さらに、日本人の参加者の方々とお話しする機会にも恵まれ、実際に各会社で運用している推薦システムに共通する課題やその解決方法について議論でき、とても学びの多い時間となりました。
RecSys 2026はアメリカのミネアポリスで開催されるということなので、自分たちも発表者の立場で参加できるように推薦システムをアップデートしていきたいと思います。

ZOZOでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!