



ZOZO研究所の清水です。弊社の社会人ドクター制度を活用しながら、「社内外に蓄積されているデータからビジネスへの活用が可能な知見を獲得するための技術」の研究開発に取り組んでいます。
弊社の社会人ドクター制度に関しては、以下の記事をご覧ください。 technote.zozo.com
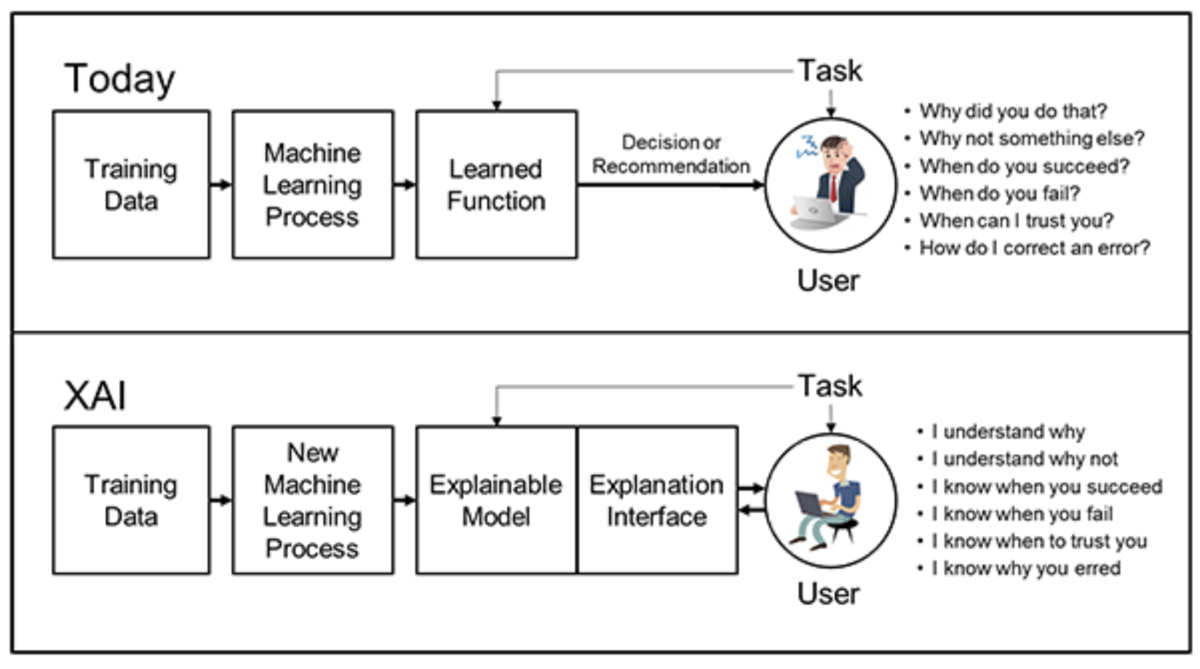
私が現在取り組んでいるテーマの1つに、「機械学習が導き出した意思決定の理由の可視化」があります。この分野は「Explainable Artificial Intelligence(XAI)」と呼ばれ、近年注目を集めています。

その中でも今回はユーザに対するアイテムの推薦問題に焦点を当て、「なぜこのユーザに対して、このアイテムが推薦されたのか?」という推薦理由の可視化が可能なモデルを紹介します。
本記事の概要
- 機械学習から得られた意思決定の理由を明確にすることの必要性が増している
- 「XAI」と呼ばれる研究領域が注目されている
- Attentionを用いて推薦理由を可視化・解釈可能な、Knowledge Graph Attention Networkという手法を紹介する
- ZOZOTOWNに蓄積されているデータにKnowledge Graph Attention Networkを適用してみた結果の一部を紹介する
目次
背景
機械学習が抱える解釈性の課題
近年、機械学習が人間の意思決定を支援したり、代替するような場面が徐々に増えてきています。弊社のサービスにおいても、例えばZOZOTOWNでユーザに推薦するアイテムの選定をする場面など、あらゆる場面で機械学習が活用されています。
機械学習によるアイテムの推薦では、蓄積された過去の購買履歴データなどの情報から、「このユーザにこのアイテムを推薦すべき」という情報を得ます。そして、得られた情報に基づいて、アイテムの推薦が行われています。以下では、この一連を仕組みを「推薦システム」と呼びます。なお、推薦システムの内部で利用されている技術に関しては、過去の記事で紹介しているので、併せてご覧ください。 techblog.zozo.com
しかし、この推薦システムを含む、機械学習を用いた意思決定システムは「なぜそのような決定に至ったのか」という意思決定の理由については不明瞭である場合が多いです。不明瞭なままでは良くないとされる場面の分かりやすい具体例としては、自動運転の技術を搭載した自動車に関するものが挙げられます。自動運転の技術を搭載した自動車が事故を起こした場合、事故を起こした際の意思決定の理由が解釈できなければ、改善点を考察することや責任の所在を明らかにすることは困難です。そして、この問題が自動運転の技術を実用化する上での1つのハードルとなっていることは間違いないでしょう。
なお、このような機械学習が抱える解釈性の課題から、消費者庁が発表したAI利活用ガイドラインにおける「AI利活用原則(AI利用者が留意すべき事項)」には「透明性の原則」が含まれています。
Explainable Artificial Intelligence
この問題に対して、「なぜそのような決定に至ったのか」を説明するための研究分野が存在します。この分野はExplainable Artificial Intelligence(XAI)と呼ばれ、特に中身が複雑なディープラーニング技術の実応用が話題となっている現代において注目を集めています。
下図はディープラーニングやアンサンブル学習を用いるような精度の高いモデルほど、モデルの解釈性は低くなるというトレードオフの関係を表しています。

図における「高い精度であるが解釈性は低い」と位置付けされているモデルが、近年多くの分野で大きな成果を発揮しています。このことを背景とし、モデルを解釈しようとする当分野も注目を集めています。
この分野の研究に関する情報は、以下の資料にまとまっています。
- 私のブックマーク「説明可能AI」(Explainable AI)
- Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI
- Interpretable Machine Learning
Explainable Recommendation
説明可能な推薦システムに関する研究も多数発表されており、Explainable Recommendation: A Survey and New Perspectives にはそれらが体系的にまとまっています。対象問題が推薦システムであるため、機械学習によって「なぜこのユーザに、このアイテムが推薦されたのか」という推薦理由を把握することを目的としています。
前述の文献などにおいてEplainable Recommendationは、説得力・有効性・ユーザ満足度などを向上させるのに役立つとされています。そして、実際に様々な企業からこの分野に関連する研究成果が発表されています。
以下はその一例です。
- Spotify
また、以下の事例が実際にサービス化されている分かりやすい例です。
- Facebook(app)
このEplainable Recommendationのアプローチの仕方は、大きく分けて以下の2種類です。
- model-agnostic approach(=post-hoc approach)
- 推薦モデルとは別に推薦理由を解釈(説明)するためのモデルを学習する方法
- model-intrinsic approach
- 何らかの工夫により、予め解釈可能な推薦モデルを学習する方法
model-agnostic approach
model-agnostic approachでは、まず推薦モデルを学習させ、その次に推薦の理由を説明するためのモデルの学習を別途行います。
このアプローチでは、事後の学習によって推薦理由の解釈を得るため、推薦モデルから直接理由が得られている訳ではありません。故に「本当に意思決定用のモデルを正確に説明できている(理由が正確に表現できている)」という保証はありません。また、そこに対して様々な工夫もされていますが、今回は詳しく扱いません。
しかし、この方法を用いると意思決定モデル自体を、どれだけ複雑にしても問題にならないというメリットがあります。
また、人間の意思決定メカニズムは以下のステップで行われる場合もあります。
- まず直感的な意思決定を行う
- その意思決定に対して、後から理由付けを行う
この意思決定のパターンを再現しているという意味では面白いアプローチです。具体的には、「とあるアイテムに一目惚れして購入を決意した後に、なぜこのアイテムが気に入ったのかを後から考える」ような流れを再現していると言えます。
このアプローチの関連研究として以下のものが挙げられます。
- Explanation Mining: Post Hoc Interpretability of Latent Factor Models for Recommendation Systems
- Posthoc interpretability of learning to rank models using secondary training data
- EXS: Explainable search using local model agnostic interpretability
- A Reinforcement Learning Framework for Explainable Recommendation
- Incorporating interpretability into latent factor models via fast influence analysis
- Explore, exploit, and explain: personalizing explainable recommendations with bandits
model-intrinsic approach
前述のmodel-agnostic approachと比較し、model-intrinsic approachは、意思決定の理由を推薦モデルから直接獲得できる点が異なります。
こちらのアプローチでは、最初から合理的な理由に基づいて意思決定を行うような状態の再現を目標としています。具体的には、どのポイント(ブランドや値段など)をどのくらい重要視するのかなどを考慮しながら、最終的にそのアイテムを購入するかを決定する流れを再現しています。この状況において、他者から「なぜそれにしたの?」と質問された場合に回答する理由は、後付けしたものではなく、購入に至った正確な理由であるはずです。
こちらのアプローチの難しい点としては、このモデルの出力が直接推薦に活用されるため、説明可能性を担保しながらも高い推薦精度を実現する必要があることです。また、闇雲に活用したい全ての補助情報をモデルに学習させることは推薦モデル自体の精度の低下や計算時間の増加を招くため、どの補助情報を活用するかについても精査する必要があります。
なお、関連研究を本記事の末尾にいくつか挙げているので、興味のある方はそちらをご覧ください。
Attentionを用いた意思決定の理由の解釈
model-intrinsic approachの中でも、近年注目されているAttentionなどを用いることで高い推薦精度を保ちながら、意思決定の理由を直接的に解釈可能とする方法があります。この方法を用いることで、分析者は「なぜこのユーザにこのアイテムを推薦したか」という理由を、いくつかの要素とその寄与の大きさに分けて把握することが可能になります。「いくつかの要素」の部分は入力データとした情報に含まれる要素(ユーザ・アイテム・それらの補助情報など)となり、「寄与の大きさ」の部分はAttentionで表現します。
この類の手法は近年脚光を浴びており、多くの手法が提案されています。その中でも今回はKnowledge Graph Attention Network(KGAT)を次章で紹介します。KGATはAttentionを用いて、どの繋がりを重視するかを考慮しながら、グラフ構造のデータを学習するGraph Attention Networks(GATs)をベースとした推薦モデルの一種です。

Knowledge Graph Attention Network
概要
Wangらは、ユーザとアイテムの2部グラフと、アイテムとアイテムの補助情報からなる知識グラフを使ったGATsベースの推薦モデルを提案しました。アイテムの補助情報とは、ZOZOTOWNのデータで言えば、ショップやブランドなどのアイテムに付随する情報です。
このモデルはGraph Neural Networksと呼ばれるモデル群において、関係性の学習にAttentionを採用したGATsに、補助情報(知識グラフ)を取り入れたモデルとして位置付けられます。ディープラーニングにより特徴量を自動的に獲得するend-to-end方式の学習を実現することで、複雑な顧客の嗜好やネットワーク構造の学習を可能にしています。
また、補助情報を用いることで、購買履歴データが十分に蓄積されていないユーザに対しても精度の高い推薦を実現します。さらに、得られたAttentionを分析することで推薦の根拠を示すことができるため、このモデルはXAIの分野においてはmodel-intrinsic approachに位置付けられます。
構築された推薦システムの出力の根拠を人間が解釈可能な形で示してくれるため、実際のマーケティングにおけるデータに応用することで強力な成果を発揮することが期待できます。
モデル構造と学習
KGATは3つのレイヤーを通して学習を遂行します。
それぞれのレイヤーの概要を以下で解説します。
- CKG Embedding Layer
- Attentive Embedding Propagation Layer
- Prediction Layer
本記事では、より多くの方に概要だけでも理解していただけるよう、数式を記載せずに言葉で解説をしていきます。それが逆に分かりにくい方は、原著の論文と照らし合わせながら読んでいただけると幸いです。
KGATのモデルの全体像は以下の図の通りです。
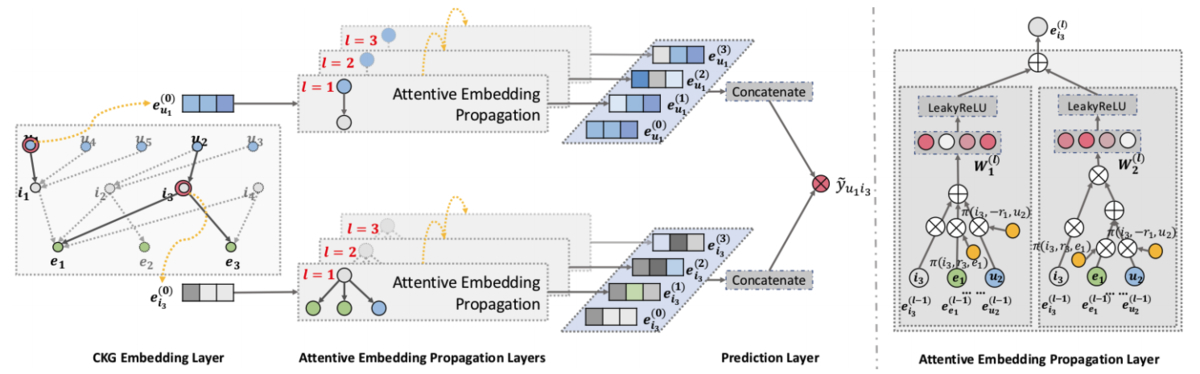
CKG Embedding Layer
ユーザとアイテムの2部グラフと、アイテムやユーザの補助情報からなる知識グラフを併せた「協調知識グラフ」の構造を保持した(各ノード・エッジに対する)埋め込み表現を獲得します。
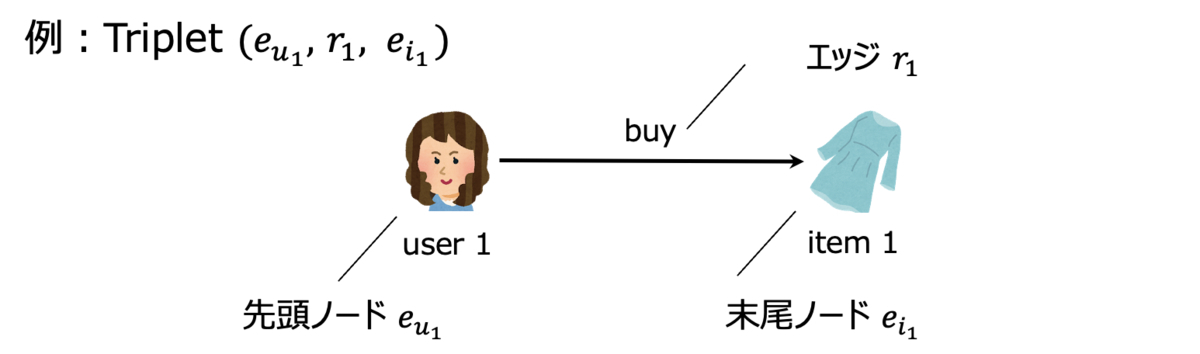
学習の際は、TransRというグラフ埋め込みの手法を用いて各Tripletをベクトル化し、グラフ上に存在するTripletと存在しないTripletの差を最大化するようにパラメータを更新します。なお、Tripletとは、先頭ノード・ エッジ・末尾ノードの3点セットのことを指します。
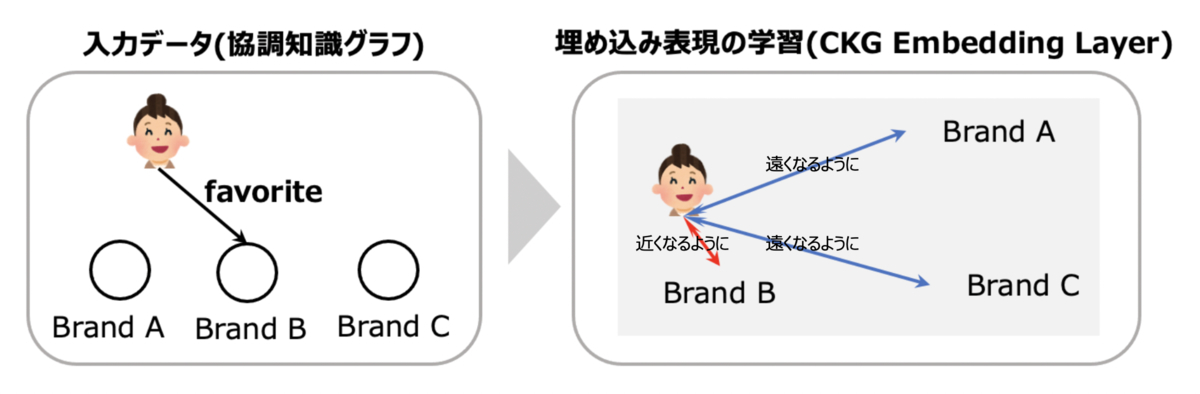
これにより、「ユーザ」と「ユーザが購入したアイテム」、「ユーザ」と「ユーザの補助情報」、「アイテム」と「アイテムの補助情報」のノード同士が埋め込み空間上で近くに配置されるように埋め込み表現が学習されていきます。
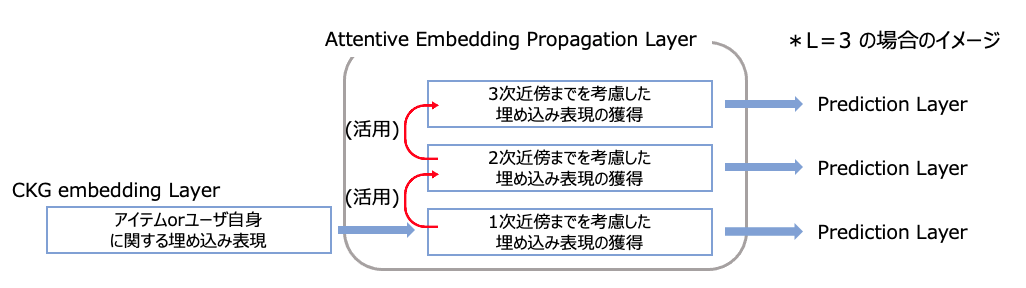
Attentive Embedding Propagation Layer
各ノードやエッジに対する埋め込み表現をもとに、各Tripletに対して重要度を算出します。そして、この重要度をもとにどの関係性を重視するかを考慮しながら、Prediction Layerにおいて購買確率の算出に利用するための埋め込み表現を、各アイテムとユーザに対して算出します。
この層は、層の構造を有しており、
次近傍(
個先の隣接したノード)までの関係性を考慮可能です。周辺ノードの埋め込み表現を各Tripletの重要度で重み付けした平均値を算出し、周辺ノードの特徴を集約することで新しい埋め込み表現を獲得します。そして、このレイヤーから得られた各アイテムとユーザに対する新たな埋め込み表現を、次のPrediction Layerにおいて購買確率の算出に利用します。
つまり、推薦において重要と判断される次近傍の関係性に従って、より洗練された、各ユーザとアイテムに関する購買確率の計算に用いるための埋め込み表現を獲得します。
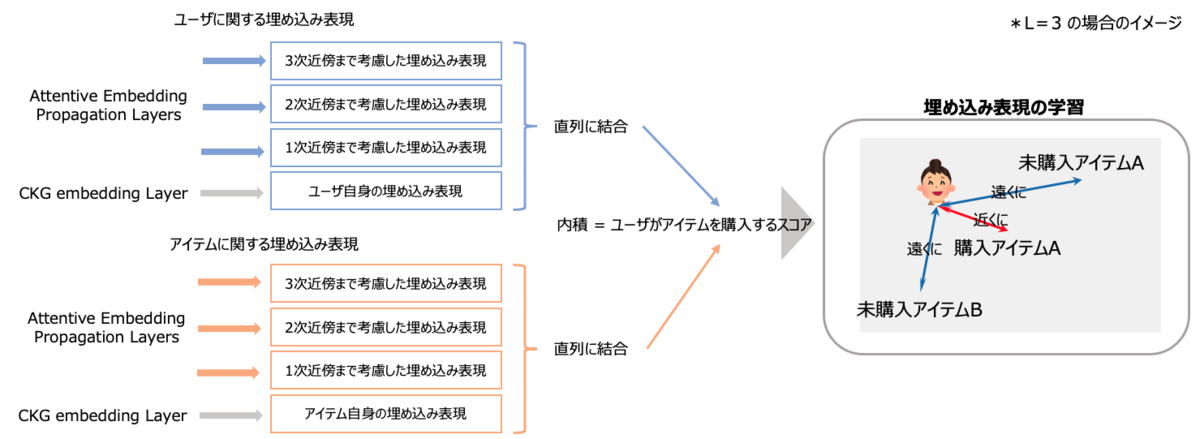
Prediction Layer
Attentive Embedding Propagation Layerから得られた各ユーザと各アイテムに対する埋め込み表現をもとに、各ユーザとアイテムのペアについて、購買確率を算出します。そして、実際に購買が発生したユーザとアイテムのペアに対して計算されるスコア(購買確率)と、発生していないペアに対して計算されるスコアの差が大きくなるように学習を遂行します。
学習の仕組み(まとめ)
長めの説明となってしまいましたが、学習の仕組みを簡単にまとめると、以下のようになります。
入出力
- 入力
- 購買履歴データと、アイテムやユーザの補助情報を併せたデータ
- 出力
- 各ユーザが各アイテムを購入する確率
損失関数
- Pairwise Ranking損失
- 埋め込み空間上におけるノードの位置関係が入力データの構造に則っているかに関する損失
- Bayesian Personalized Ranking損失
- 埋め込み表現などから算出した購買確率がユーザの行動を再現できているかに関する損失
上記の双方を考慮して学習を遂行。
実験
ここまで紹介してきたKGATを、ZOZOTOWNに蓄積されている購買履歴データと各ユーザとアイテムの補助情報に適用し、得られた結果を用いて実際に推薦理由の可視化を行ってみた例を紹介します。さらに、推薦精度の評価実験を行い、KGATが推薦精度の面でどの程度有効であるのかを確認した結果を紹介します。
実験条件
今回の実験では、2020年2月〜2021年1月の1年間の購買回数が5回以上60回未満のユーザからランダムにサンプリングを行い、抽出された購買履歴データを利用します。
補助情報にはアイテムのブランド・ショップ・カテゴリ・価格帯、ユーザの年代・性別・お気に入りブランドやショップなどの全17種類のデータを用いました。購買履歴データは約30万件、補助情報は約70万件です。
こちらの文献の実験条件を参考に、各グラフの埋め込み表現の次元数は64、Attentive Embedding Propagation Layerは[64・32・16]次元の3層としました。また、確認する精度指標も同様の決め方で、TopN精度(Recall・NDCG)としています。
比較手法は補助情報を用いない手法のベースラインとしてBPRMF、同じく補助情報を含んだグラフ構造を学習する手法であるCKEとCFKGとしています。
- BPRMF
- CKE
- CFKG
推薦理由の可視化の例
まず、記事の前半でメイントピックとして解説してきた「推薦理由の可視化」についてです。KGATの出力結果をそのまま用いることで、各ユーザに対して「なぜそのアイテムが推薦されたか」を容易に説明できます。今回はどのような形で説明可能になったのかを紹介するために1つだけ例を紹介します。
以下の図は、実際に得られた結果の中から抽出してきた例で、「ユーザに対してアイテム
が推薦されている」状況を表現しています。ユーザ
から、実際に推薦されたアイテム
までのノードとエッジを辿り、それらの重要度を確認することで推薦理由を把握できます。
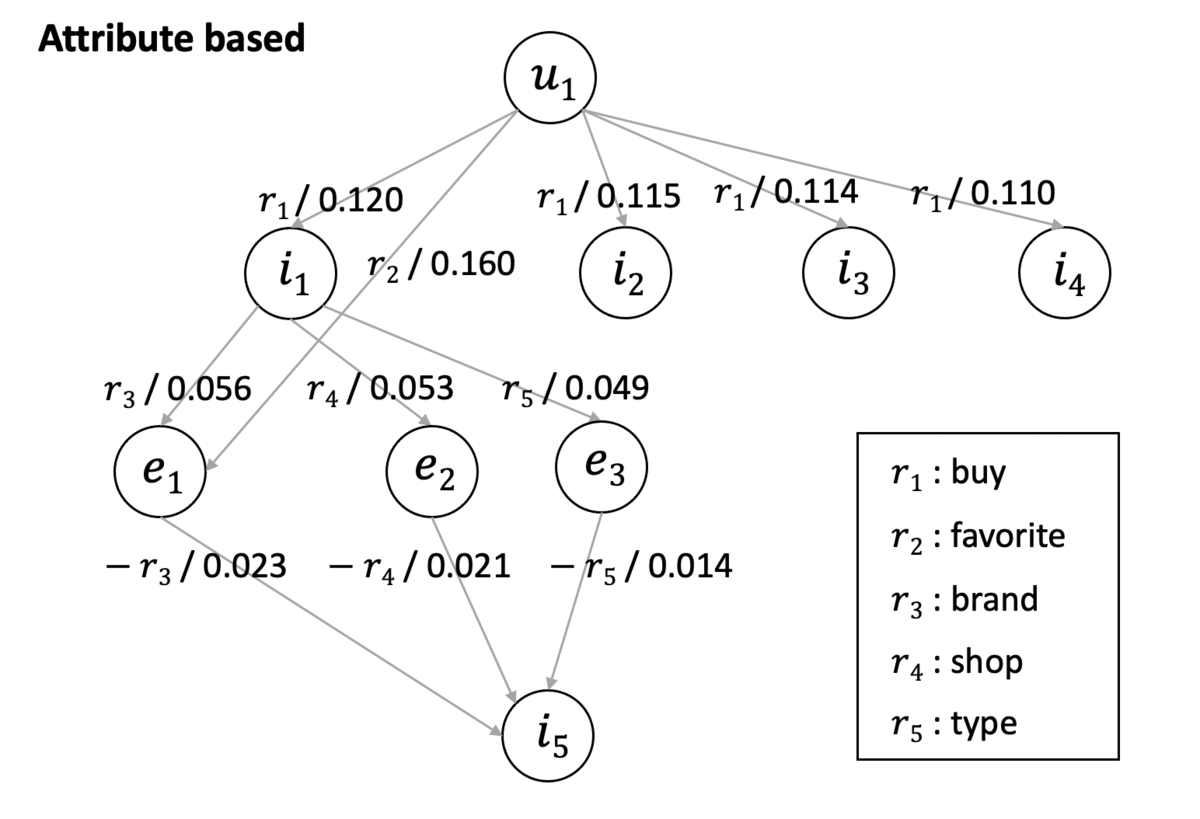
このグラフを見ると、ユーザに対してアイテム
が推薦された理由は、以下の点であることが分かります。
- 同ブランド
のアイテム
を過去に購入していること
- ブランド
- アイテム
のアイテムであること
- アイテム
のアイテムであること
また、重要度(エッジ上に記載されている数値)を確認することで、それぞれがどの程度推薦に寄与しているのかを定量的に把握できます。
この結果を活用し、ユーザにアイテム
を推薦する際、アイテム
がブランド
のアイテムであることを強調するなどの施策が容易に考えられます。また、推薦するアイテムと併せて、単純に推薦理由とスコアを並べて表示する施策も考えられます。これにより、ユーザは「だからこのアイテムを良いと感じるのか」「だからあまり良いと思わないアイテムが推薦されたのか」のように、納得感を持って買い物を楽しめるかもしれません。
今回は結果の活用事例として推薦理由の可視化のみを紹介しました。しかし、実際には他にも各ノード(アイテム・ユーザ・補助情報)やエッジに対して埋め込み表現が得られているので、これらを分析することも施策立案の一助となります。実際に適用して得られた結果を多角的に分析した結果、改めてとても汎用性の高いモデルだなと感じています。
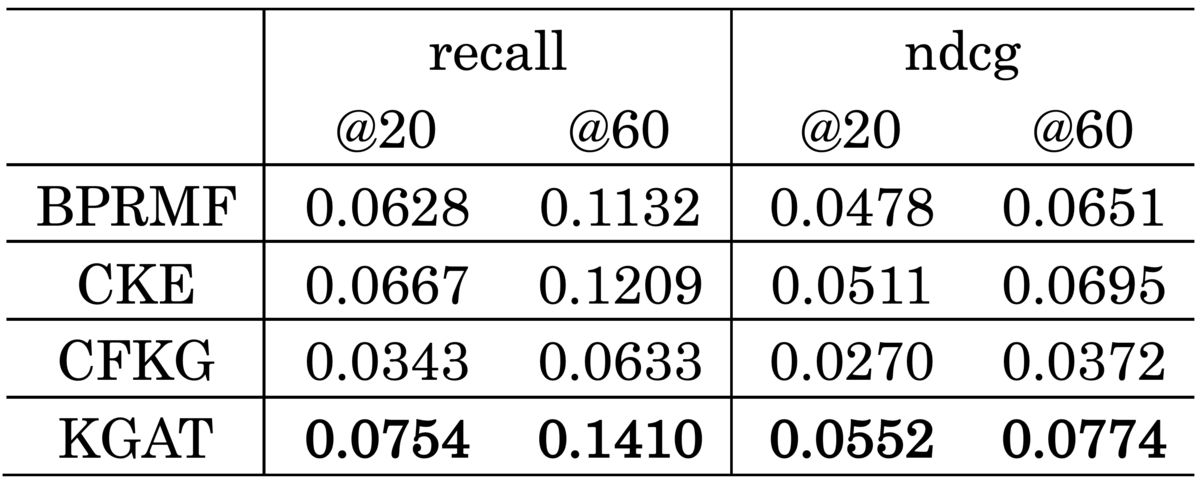
推薦精度に関する評価
以下に示す結果の表を見ると、KGATは同様の補助情報を用いる他の手法と比較して、精度面でも有効なモデルであることが分かります。特にBPRMFよりも精度が高いことから、補助情報を活用することの有効性を示唆しています。
また、CKEやCFKGよりも精度が高いことから、KGATが上述した学習アルゴリズムを通して補助情報を含んだグラフ構造を上手に学習できていることが考えられます。
また、下図より、他の手法と比較して学習データ内にまだ多くの購買履歴データが蓄積されていないユーザ群に対しても、ある程度頑健な推薦ができていることが分かります。つまり、コールドスタート問題にも対応できていると言えます。

推薦精度に関する評価実験の結果をまとめると、以下のことが分かります。
- KGATが他の類似したモデルと比較して、高い推薦精度が期待できるモデルであること
- 過去にZOZOTOWNであまり商品を購入していないユーザに対しても、ユーザやアイテムの補助情報を上手に学習し、効果的な推薦ができていること
関連手法
XAIの文脈でKGATを紹介しましたが、Attentionを活用した解釈可能な推薦システムの研究としては以下のものも挙げられます。
- Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction
- A Context-Aware User-Item Representation Learning for Item Recommendation
- Neural attentional rating regression with review-level explanations
- Sequential Recommendation with User Memory Networks
また、知識グラフの学習をベースとする解釈可能な推薦システムの研究としては、以下などが挙げられます。
- Explainable entity-based recommendations with knowledge graphs
- Improving sequential recommendation with knowledge-enhanced memory networks
- Learning Heterogeneous Knowledge Base Embeddings for Explainable Recommendation
- Reinforcement knowledge graph reasoning for explainable recommendation
終わりに
今回はXAIの文脈で、KGATの紹介をしました。この分野は現在非常にアツく、様々な方法が提案されているので、将来的にはそれらを網羅的に紹介する記事も執筆したいと思います。最後までお読みいただき、ありがとうございました!
ZOZOテクノロジーズでは一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!