



はじめに
こんにちは、データシステム部推薦基盤ブロックの寺崎(@f6wbl6)と佐藤(@rayuron)です。
私たちは2024年10月14〜18日にイタリアのバーリにて開催されたRecSys 2024(18th ACM Conference on Recommender Systems)に現地参加しました。本記事では現地でのワークショップやセッションの様子をお伝えすると共に、気になったトピックをいくつか取り上げてご紹介します。
RecSysとは
RecSysとは米国計算機学会(ACM)が主催する推薦システムに関する国際的なカンファレンスです。今回で18回目の開催となるRecSys 2024は2024年10月14〜18日にイタリアのバーリで開催されました。
RecSysでは推薦システムに関わる各国の大学の研究チームや、Google、Amazon、Netflix、Spotifyをはじめとする推薦の関連分野で活動する世界有数の企業を集め、推薦システムの幅広い分野における新しい研究成果を発表します。今回は、アメリカや中国などの53カ国から1,123人の研究者や開発者がRecSysに参加しました。
初日と最終日にチュートリアルとワークショップがバーリ工科大学で行われ、その他の日付でペトゥルッツェッリ劇場(Teatro Petruzzelli)を会場としてメインカンファレンスが行われました。全日程を通して発表は全て英語で行われます。どの日も9:00頃からカンファレンスが開始され、朝夕2回のコーヒーブレークやランチを挟んで18:30頃に終了します。夜にはレセプションパーティーやソーシャルディナーが実施されたりと多くの人と交流できます。また今回は、メインカンファレンス終了後にオーケストラコンサートにも参加できました。
開催地のバーリについて

今回の開催地であるバーリは、アドリア海に面した南イタリアの美しい港町です。街には白を基調とした外壁の建物が多く、青い海や空とのコントラストが印象的で魅力的でした。コーヒーブレークの合間に沿岸沿いを散策する参加者の姿が多く見られ、気分をリフレッシュしている様でした。
会場の様子

初日と最終日には、チュートリアルとワークショップがバーリ工科大学で行われました。発表テーマは教室によって分かれているため、聞きたいプログラムを自分で選択し聴講しました。特にワークショップではMuRSやVideo Recsysの様に音楽や動画という特定のドメインに特化したテーマの他、FAccTRecやCARSのように推薦を考える上で重要な観点に重きをおいたテーマでの発表がありました。

10/15〜10/17にメインカンファレンスがペトゥルッツェッリ劇場で行われました。荘厳な雰囲気が魅力的な会場でした。劇場の椅子に座り全員が同じ基調講演とセッションを聴講しました。Michael I. Jordan氏をはじめとする研究者が基調講演し、セッションでは大学の研究チームの発表やGoogleをはじめとする会社の研究チームの発表が行われました。セッションは以下のテーマで構成され、全体を通してLLMとSequential Recommendationに関する発表が多い印象でした。
- Large Language Models
- Bias and Fairness
- Collaborative Filtering
- Cross-domain and Cross-modal Learning
- Multi-Task Learning
- Cold Start
- Sequential Recommendation
- Graph Learning
- Optimisation and Evaluation
- Robust RecSys
- Off-Policy Learning
- Women in RecSys
研究内容の紹介
ここからは、カンファレンスを通して特に気になった論文について取り上げてご紹介します。
Bootstrapping Conditional Retrieval for User-to-Item Recommendations
Hongtao Lin, Haoyu Chen, Jaewon Yang, Jiajing Xu
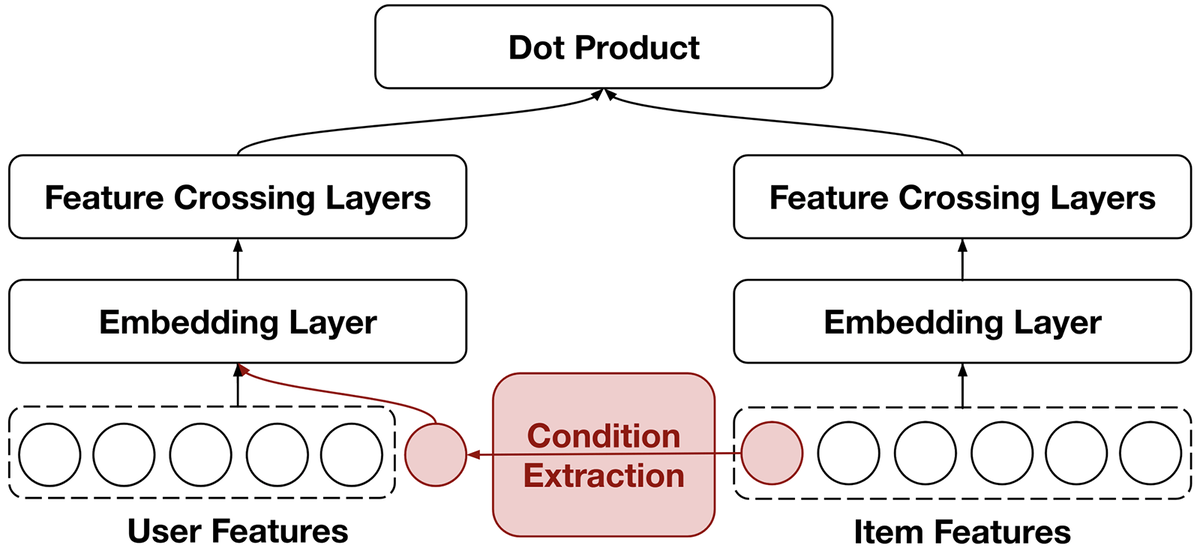
この発表はPinterestの研究で、Two-Towerモデルによるretrievalタスクにおいて条件付けして取得するアイテムを制御する方法を提案しています。以降、条件付けしたretrievalのことを”conditional retrieval”と記載します。conditional retrievalの実現方法として大量のアイテムを取得して後処理で条件に一致するアイテムのみを抽出する方法や、近似近傍探索時にフィルタ条件を考慮する方法が考えられます。これらの方法だとフィルタリング項目に対してモデルが最適化されているわけではないため、フィルタリング項目との関連度は高いがユーザーとの関連度は低い、といった状況が生じると考えられます。
この研究ではアイテムのメタデータを特定のフィルタリング項目にマッピングするCondition Extraction Moduleという機構を設け、そこから得られたembeddingをユーザータワーで利用する手法を紹介しています。
提案手法は特定のトピックで抽出したアイテムをメール通知またはプッシュ通知するタスクで評価しており、複数の手法と比較しています。
| 手法 | 概要 |
|---|---|
| index | 指定されたトピックのアイテムを全件抽出して人気順の上位N件を取得するもの |
| LR: Learned Retrieval | 通常のTwo-Towerモデル + 内製のストリーミングトピックフィルタ*を適用したもの |
| CR1: Conditional Retrieval(提案手法 A) | 内製のストリーミングトピックフィルタを適用しないもの |
| CR2: Conditional Retrieval(提案手法 B) | 内製のストリーミングトピックフィルタを適用したもの |
*指定したトピックのアイテムを一定数取得または時間予算に達するまで取得するトピックフィルタの機構。
オンラインテストの結果、提案手法がCTR・コストの両方で優れていることが示されています。注目すべきポイントはインフラコスト面で、LRにストリーミングトピックフィルタを適用することでコストが大幅に増加している点に対し、CRのコスト増はLRの4〜6分の1程度に抑えられていました。これはLRの場合だと条件に合致するアイテムを大量にフェッチして処理する必要があるためで、この点から提案手法では条件に合致するアイテムを効率的に取得できていることがわかります。
発表時にはlimitationとして複数の条件によるconditional retrievalが行えないことや、必ずしも条件に合致したアイテムが取得できるわけではない点を挙げており、検索機能の代替にはならない点に言及していました。
感想・考察
こちらの手法はサービスのユースケース次第では簡単にconditional retrievalを実現できるため、非常に参考になる発表でした。クエリ実行時にアイテムのconditionにあたるembeddingをユーザーのfeatureとして入力するという発想はシンプルなので、これでconditionに沿ったアイテムが取得できるようになるのは意外な結果です。比較対象として用いているTwo-Tower+トピックフィルタはよくあるconditional retrievalの構成なので、似たような構成のシステムを運用している方は参考にしてみると良いでしょう。
Short-form Video Needs Long-term Interests: An Industrial Solution for Serving Large User Sequence Models
Yuening Li, Diego Uribe, Chuan He, Jiaxi Tang, Qingyun Liu, Junjie Shan, Ben Most, Kaushik Kalyan, Shuchao Bi, Xinyang Yi, Lichan Hong, Ed Chi, Liang Liu
この発表はGoogleとDeep Mindの研究で、YouTubeのショート動画など尺の短い動画コンテンツ(Short-Form Videos, SFVs)を大量に消費するサービスにおいてユーザーシーケンスを効率的に扱う方法を提案しています。SFVsでは尺の長い動画(Long-Form Videos, LFVs)と異なりユーザーシーケンスが長くなる傾向にあるため、モデルをサービングする際にどの程度のシーケンス長を考慮するかがポイントになります。シーケンス長をできるだけ長く扱うようにしたところオンラインメトリクスは大幅に向上したものの、サービングコストの増加が確認されたため、できるだけこれらの影響を小さくすることがこの研究のモチベーションです。なお論文中には記載がありませんが、使用するユーザーシーケンスを長くすることでモデルサービング時のレイテンシも悪化した、と発表中に言及されていました。
| Online Metric | Serving Cost (naive) | |
|---|---|---|
| User Model (sequence length 200) | +0.14% | +5.6% |
| User Model (sequence length 1000) | +0.38% | +28.7% |
使用するユーザーシーケンスを長くするとメトリクスは改善するがコストやレイテンシが悪化している。
提案手法はユーザーシーケンスをembeddingにするモデルの推論処理をサービングから切り離して非同期に行うというもので、embeddingのキャッシュと更新手続きの手順をフレームワークとして提案しています。
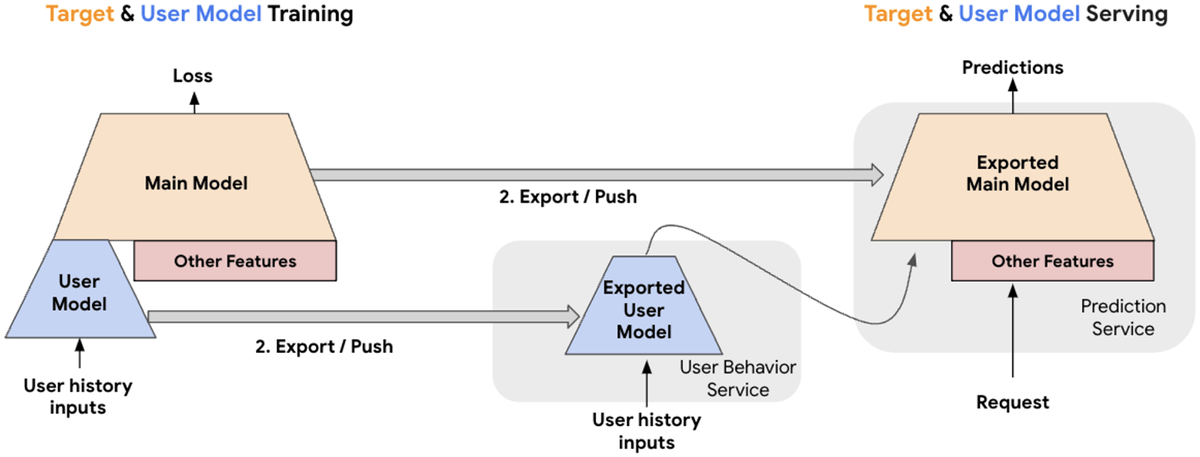
このような構成を取るメリットとしてサービング時のインフラコスト改善だけでなく、ユーザーシーケンスをembeddingにするモデルをLLMなどの大規模モデルにできる点を挙げています。特にユーザーシーケンス長の限界を意識する必要がなくなるので、ユーザーの長期的な嗜好を捉えられるようになる点が大きなメリットと言えるでしょう。
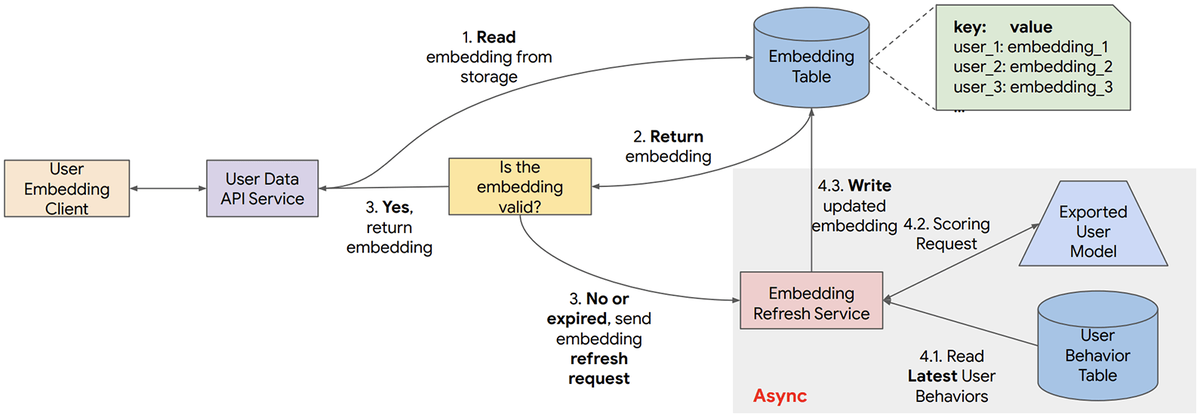
embeddingのキャッシュと更新の手続きは以下のような流れで行われます。
- キーバリューストアからユーザーIDに対応するembeddingを取得する
- embeddingが有効な場合はそのまま返却
- embeddingが無効や期限切れだった場合はembeddingのリフレッシュ処理をトリガー
- 最新のユーザーシーケンスを取得してユーザーモデルでembeddingを計算しキーバリューストアに格納・embeddingを返却
提案手法の評価としてSFVsの推薦タスクとLFVsの推薦タスクでA/Bテストをしており、SFVsではインフラコストの大幅な削減を達成し、LFVsでは一部のメトリクス改善につながったと報告しています。この発表の質疑では「ユーザーのembeddingが無効であるとどのように判断しているのか」という質問が出ており、一定期間で無効にする方法とユーザーの属性やコンテキストの変化で無効にする2つのパターンがあるとのことでした。
感想・考察
まず、YouTubeのような巨大サービスにおけるembeddingの扱いに関する方法などの詳細を直接聞けるのがRecSysに参加する大きな意義だと感じました。ZOZOTOWNでも似たようなシステム構成を採っている推薦システムは存在しますが、本発表でのembeddingの管理方法はさすが痒いところまで手が届いている、という印象です。YouTubeほどのサービス規模になるとインフラコストの削減やレイテンシの改善によるインパクトは計り知れず、メトリクスが改善していてもインフラコストがかかりすぎてリリースができないというのはこの規模のサービスならではの課題だと思います。
MARec: Metadata Alignment for cold-start Recommendation
Julien Monteil, Volodymyr Vaskovych, Wentao Lu, Anirban Majumder, Anton van den Hengel
この発表はAmazon Machine Learningによる研究で、ウォームアイテムに対する精度を保ちつつコールドアイテムの精度を改善する手法を提案しています。推薦システムにおけるコールドアイテムとは「ユーザーのインタラクションが少ない・もしくは全くないアイテム」を指しており、こうしたアイテムへのアプローチとして以下が挙げられています。
- 協調フィルタリングとコンテンツベース推薦のハイブリッド
- メタラーニングアプローチ
- ニューラル埋め込みアプローチ
- retrieval拡張
よく使われるのはひとつ目の手法ですが、コンテンツベース推薦のアプローチでコールドアイテム、協調フィルタリングでウォームアイテムへの推薦に対応しているため、モデルアーキテクチャが複雑かつ学習が収束しにくくなるという問題に繋がります。またそれぞれのモデルに対する影響もあり、ウォームアイテムへの推薦精度を悪化させるケースもあります。この研究ではウォームアイテムへの精度を変えずにコールドアイテムへの推論精度を高めつつ、よりスケーラブルなアプローチを提案しています。
提案手法はMetadata Alignment for cold-start Recommendation (MARec)と呼ばれるもので、バックボーンモデル、embeddingモデル、アライメントモデルの3つのモデルを組み合わせたアーキテクチャを採っており、それぞれのモデルの出力を使って損失を計算する構成となっています。
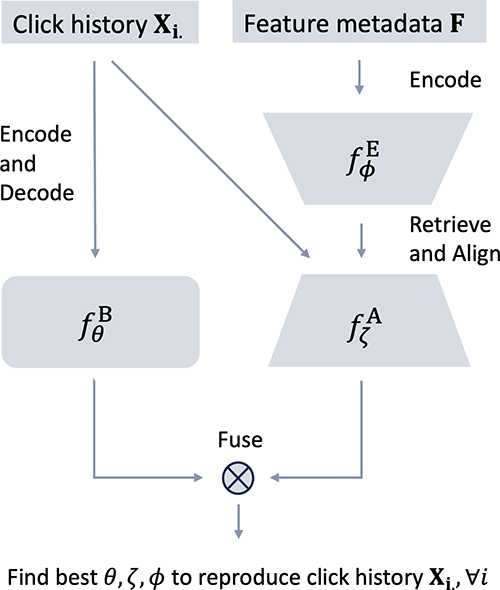
バックボーンモデルは図中のfBで表されているモデルでクリックデータを入力としており、図中のfEで表されているembeddingモデルはアイテムのメタデータをembeddingに変換します。そしてfAで表されているアライメントモデルはfBの学習で使用するクリックデータとfEから得られるembeddingのバランスをとるためのもので、ここが提案手法のキモになっています。
提案手法の評価は公開データセットに対するオフライン評価のみですが、コールドアイテムでの評価指標が最大47.9%アップリフトしており、一方ウォームアイテムでは最大マイナス1.5%の精度低下に抑えられていることが確認されました。
感想・考察
今回のRecSysではコールドスタート問題に関する発表が数多くありましたが、手法が最もシンプルかつ広範に渡る評価を行っている発表だったと思います。「コールドアイテムへの対策をしたモデルはウォームアイテムへの精度を悪化させる懸念がある」という観点も説明されると納得ですが自分たちのプロダクトで考慮できていなかった点なので、新たな観点として得られたのが個人的に良かったポイントです。課題として挙げていた「アーキテクチャが複雑化する」という点について提案手法も複雑そうには見えますが、中身としてはアライメントモデルを追加しているのみなので比較的簡単にこの手法を試せそうな印象です。今後、プロダクトへの導入結果が報告されるのを楽しみにしている研究のひとつです。
Building a Scalable, Real-time Sequence and Context-Aware Ranking
Marjan Celikik, Jacek Wasilewski*, Ana Peleteiro Ramallo, Alexey Kurennoy, Evgeny Labzin, Danilo Ascione, Tural Gurbanov, Géraud Le Falher, Andrii Dzhoha and Ian Harris
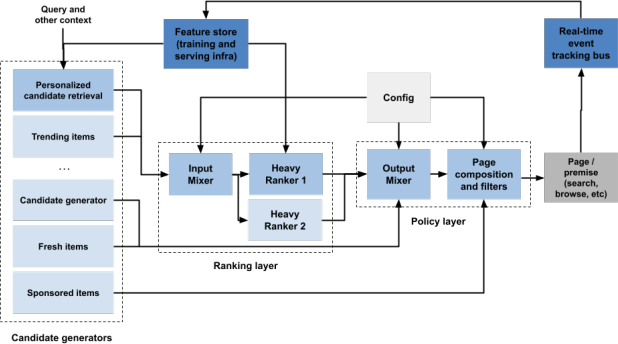
こちらの研究は、CARSというワークショップで取り上げられた、ファッションECサイト「Zalando」の発表内容です。
オンラインショッピングサイトでは、膨大な商品データベースから、ユーザーの行動やコンテキストに基づきリアルタイムでパーソナライズされた商品を効率的に推薦することが重要です。本研究では、2ステージの推薦モデルを採用し、推薦精度とレイテンシの両方を向上させるアプローチが取られています。
候補生成フェーズでは、Two-Towerモデルが使用されています。このモデルは、ユーザーとアイテムの特徴を独立して処理し、ユーザーの行動履歴やコンテキストを基にユーザーembeddingを生成し、アイテムのembeddingと組み合わせて商品候補を生成します。embeddingの生成方法としては、以下の3つが提案されています。
- RCGntr: 事前学習されたembeddingを使用するモデル
- RCGtr: 事前学習されたembeddingを初期値として、学習されたembeddingを使用するモデル
- RCGtr+ctx: RCGtrに加え、検索クエリや閲覧カテゴリなどのコンテキスト情報を組み込んだモデル
RCGtrは、従来のGradient Boosting Treesを使用した候補生成と比較して4.48%のエンゲージメント向上を達成しています。
ランキングフェーズでは、ユーザーの行動履歴とコンテキストに基づいて、クリック、カート追加、購入といった複数のアクションを予測するポイントワイズのマルチタスク学習が採用されています。学習時にはすべてのターゲットアクションに対して等しい重み付けが行われますが、サービング時にはユースケースに応じて各アクションのスコアに動的な重み付けが適用され、ビジネスニーズに合わせて最適化されています。
上記のモデルは、従来のWide & Deep Learningモデルと比較して4.04%のエンゲージメント向上を実現しました。また、ランキングモデルの候補生成にRCGtr+ctxを使うと、RCGtrと比較して+2.40%のエンゲージメント向上を実現しました。そして、システム全体では、リアルタイムで約200ミリ秒のレイテンシを維持しています。
感想・考察
ランキングフェーズにポイントワイズなマルチタスク学習を適用しており、学習とサービング時に異なるタスクごとに異なる重みを使用する点がユニークでした。重みはユースケースに応じて動的に設定されると言及されていたので具体的な決め方について知りたいと思いました。
Dynamic Stage-aware User Interest Learning for Heterogeneous Sequential Recommendation
Weixin Li, Xiaolin Lin, Weike Pan and Zhong Ming
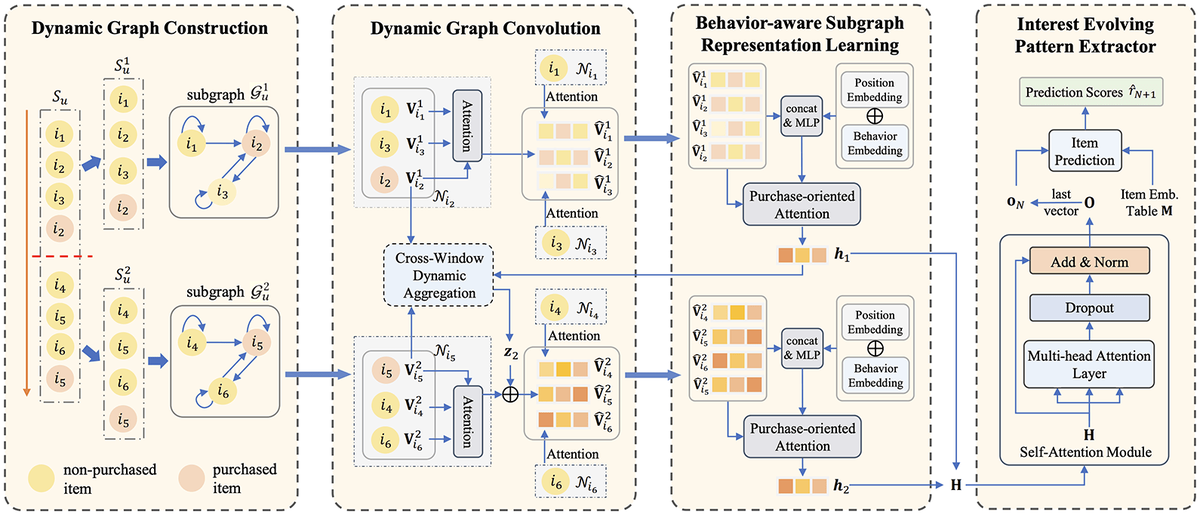
こちらは、Session 8: Sequential Recommendation 1で発表された、深圳大学の研究です。従来の推薦システムは、ユーザーの行動履歴に基づいて商品を提案していましたが、ユーザーの興味が時間の経過や特定の行動によって段階的に変化することを十分に反映できていませんでした。この課題に対処するため、DSUIL(Dynamic Stage-aware User Interest Learning)という新しいモデルを提案しました。DSUILは、ユーザーの行動シーケンスを「購入」などの重要な行動を基準に複数の段階に分割し、各段階でユーザーの興味がどう変化するかを学習します。
DSUILは、以下の4つの主要なモジュールから成り立ちます。
- Dynamic Graph Construction: ユーザーの過去の行動に対し購入行動を境界としてサブグラフを作成する
- Dynamic Graph Convolution: 各サブグラフ内のアイテム間の依存関係を学習する
- Behavior-aware Subgraph Representation Learning: 閲覧や購入など異なる行動間の依存関係を捉え、サブグラフ内のユーザーの興味を表現する
- Interest Evolving Pattern Extractor: 複数のサブグラフを結合し最終的なアイテムを予測する
実験結果から、DSUILは既存の最先端手法と比較して優れた性能を示し、特に異なる段階間の依存性をモデル化することが、推薦精度の向上につながることを示しています。
感想・考察
消費者行動モデルのAISAS(Attention, Interest, Search, Action, Share)で説明される様に、消費者行動が段階的に変化することは明らかだと思います。この研究は従来のSequential Recommendationで考慮し切れていなかったユーザーの段階的な行動をモデリングする点で筋が良いなと思いました。
Self-Auxiliary Distillation for Sample Efficient Learning in Google-Scale Recommenders
Yin Zhang, Ruoxi Wang, Xiang Li, Tiansheng Yao, Andrew Evdokimov, Jonathan Valverde, Yuan Gao, Jerry Zhang, Evan Ettinger, Ed H. Chi and Derek Zhiyuan Cheng
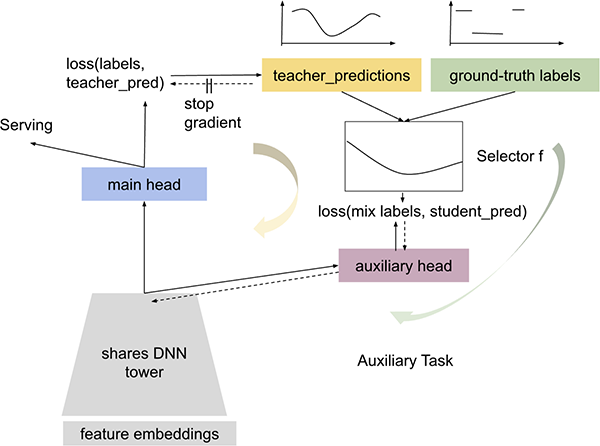
こちらは、Session 11: Optimisation and Evaluation 1で発表されたGoogle DeepMindによる研究です。こちらの研究は、Googleの大規模な推薦システムにおいて、限られたデータから効率よく学習を進めるSelf-Auxiliary Distillationという手法を提案しています。
推薦システムでは、フィードバックデータをそのまま使用してモデルをトレーニングしますが、これらのラベルの情報価値は均一ではありません。例えば、クリック予測モデルでクリックされずにラベルを0とした中でも、ポジティブに近いネガティブや、完全なネガティブが存在します。そのため、否定的なラベルを単純に0とするのではなく、もっと細かく評価することが有効とされました。
Self-Auxiliary Distillationは、信頼性の高いポジティブラベルに重点を置いて学習を進めつつ、信頼性の低いネガティブラベルに対しては蒸留を通じて解像度を高め、モデル全体の精度を向上させる手法です。この方法では、次の2つのタスクを同時に処理します。
- Main Task: ground-truthに基づいてモデルをトレーニングし、教師として確率的なソフトラベルを生成する
- Auxiliary Task: 教師モデルから生成されたソフトラベルと正解ラベルの両方を学習する
この手法を使用することで、あるGoogle Appsの推薦システムではオフラインでのAUCが+17%向上し、オンラインの主要ビジネスメトリクスにおいても大きな成果が見られました。また、補助タスクを追加することで、モデルのサービング時のコストが増大することはなく、トレーニングにかかるコストもほとんど増加しません。
AppleのiOSのプライバシーポリシーによってラベルデータの取得が難しくなった環境でも、この手法が有効に機能しています。同意を得られないユーザーのデータが「真のネガティブラベル」と区別できない問題に対して、補助タスクで生成されたソフトラベルを使用することで、推薦システムのパフォーマンスを維持することに成功しました。
感想・考察
pseudo-labelを使用することで、ユーザーの潜在的な関心度を学習に取り入れている点は、純粋に賢いアイデアだと感じました。プラットフォームのプライバシー規制に対して適応力があるという点は面白い観点だと思いました。他にもbotアクセスによる推薦精度の低下への対応策にもなり得るのではないかと考えました。
おわりに
RecSys 2024に参加して、豊富なインスピレーションを得ると共に自社の推薦機能に改善の余地があることを再確認しました。前述の通り今年のRecSysはSequential Recommendationの発表が多く、発表中の課題設定としてECでの購買行動を扱っているものも多かったためZOZOTOWNにおける推薦機能の改善にそのまま活かせそうな内容ばかりでワクワクしました。Industrial Paperの発表はサービス特有の課題設定を解くものでしたが、課題設定の観点とそのアプローチは自分たちがプロダクトを改善していく上でとても参考になります。

RecSys 2025はチェコのプラハで開催されるとのことで、自分たちも発表者の立場として参加できるように推薦システムをアップデートしていきたいと思います。
ZOZOでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!