



こんにちは、WEARバックエンドブロックの天春(@AmagA001)です。バックエンドの運用・開発に携わっています。WEARはサービス開始から10年ほどの古いVBScriptを使った環境からRuby on Rails環境にシステムリプレイスを行なっています。本記事では、リプレイスの中でも既存環境が複雑で問題や課題が多くあったPUSH通知システムのリプレイスについてご紹介します。
目次
- 目次
- PUSH通知システムとは
- リプレイス前のPUSH通知システム
- リプレイス前のPUSH通知システムの問題点
- リプレイスの背景
- リプレイス後のPUSH通知システム
- 既存システムの問題解決
- ローカル開発環境
- 現在の状況
- 今後の課題
- 最後に
PUSH通知システムとは
WEARアプリにPUSH通知を配信するために構築しているシステムのことを呼んでいます。PUSH通知は次の2種類が存在します。
- 1:1通知:一人のユーザーに対して1回だけ送る通知
- 1:N通知:同じ通知を同時に複数のユーザーに対して送る通知
リプレイス前のPUSH通知システム
リプレイス前のPUSH通知システムはオンプレミスのMicrosoft SQL Server、.NET FrameworkとAWSのサービスで構成されています。AWSのサービスはEC2、DynamoDB、API Gateway、Lambda、SNS、SQSが使われています。開発言語はVBScript、C#、Golang、Pythonです。
1:1用通知処理バッチ(Golang)と1:N用通知処理バッチ(C#)がWindowsバッチサーバーのタスクスケジューラに登録されて定期的に通知配信API(Python)経由で通知を配信していました。通知サービスはAWSのSNS経由でAPNsとFCMを使っていました。
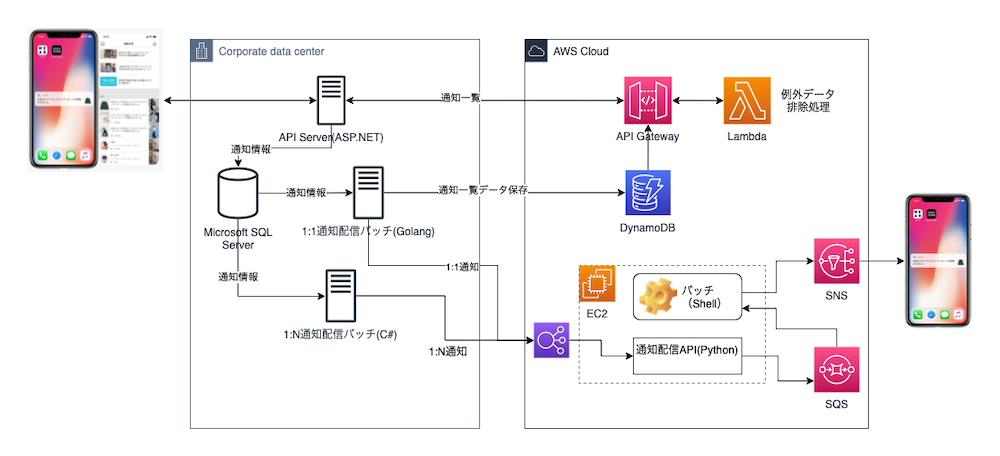
リプレイス前のPUSH通知システムの問題点
通知送信バッチのスケールアウトが出来ない
通知送信バッチはスケールアウトが考慮されてなく決まった時間に通知を送る仕組みになっていたので1:Nの通知の場合、通知が多い時は1日以上の遅延が発生している状態でした。
障害対応・運用が難しい状況
障害・エラーが発生した場合、開発当時の資料と開発メンバーの不在、必要なログデータの不足により原因特定・障害対応・運用に時間がかかりました。原因が判明して修正できたとしても影響範囲が特定できないこととテスト環境がないことも問題でした。
複数の開発言語による運用・改修コストが高い
APIとバッチの改修のためにはVBScript、C#、Golang、Python、シェルスクリプトの修正が必要になるため、関連言語の学習コスト発生や経験者が必要になりました。
ステージング環境で通知確認ができない
ステージング環境でバッチが動いてない状態だったので通知の改修や追加時にQAテストが出来ず、本番環境で動作確認するしかない状況でした。
リプレイスの背景
WEARサービスにコーディネート動画1やフリマ機能2の追加により新規通知を追加する必要がありました。既存システムを改修する方法もありましたが、既存システムが複雑すぎて障害・エラー発生時に原因調査・対応が難しい状況だったのでリプレイスを選びました。
リプレイス後のPUSH通知システム
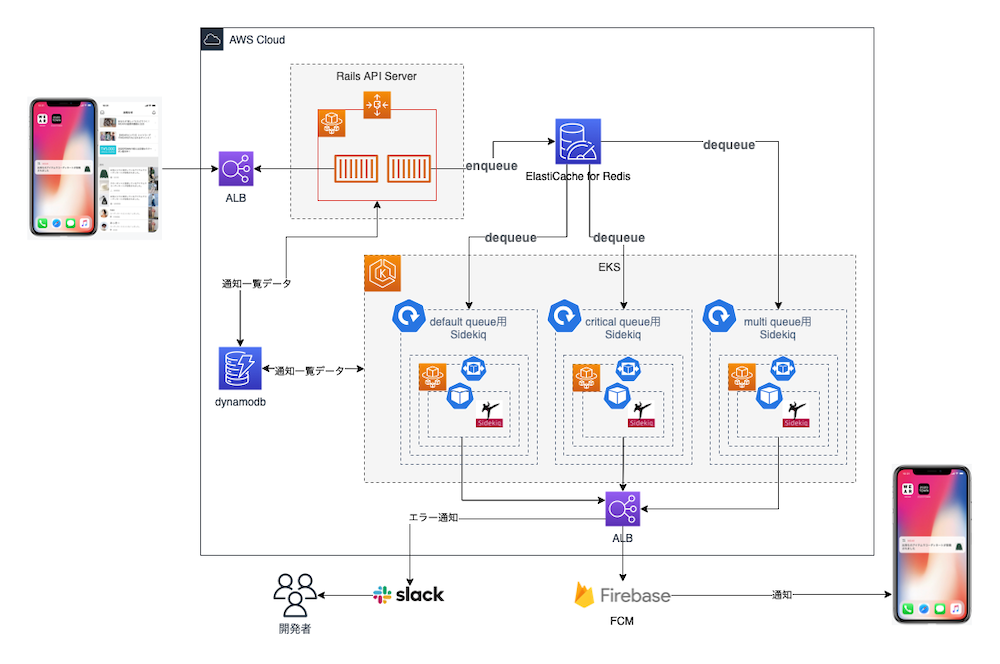
非同期システム・EKS導入
Ruby on Rails環境ではActiveJobを使うことでキューイングライブラリを気にせずジョブの作成、キュー登録、実行が可能です。キューイングライブラリはジョブをキューに登録して非同期でジョブを実行できるライブラリのことです。Railsガイド3にも書かれているSidekiq、Resque、Delayed Jobを対象に検討しました。結果、Sidekiqがマルチスレッド対応で大量のジョブ処理に向いていることとメモリあたりのパフォーマンスがいいことでした。WEARには同時に200万回以上の大量通知が発生することもあるのでSidekiqを選定しました。チームメンバーにSidekiqの経験者がいたことも1つの理由でした。
既存配信バッチはMicrosoft SQL Serverのテーブルをキューとして利用してテーブルから通知対象を取得して通知配信後、通知一覧に必要なデータをDynamoDBに登録していました。リプレイス後はバッチをなくしてMicrosoft SQL Serverを使わずに非同期ジョブを利用して直接DynamoDBに通知一覧データを登録しています。EKSの導入により拡張可能なシステムになったのも大きな変化です。通知配信サービスはFirebase Cloud Messaging(FCM)だけを使うようにしました。
既存システムの問題解決
バッチのスケールアウトが出来ない
EKS導入により負荷が多い時の非同期ジョブ処理(Sidekiq)のスケールアウトが可能になりました。オートスケールはKubernetesのHPA(Horizontal Pod Autoscaler)を使っています。
障害対応・運用が難しい状況
エラー検知と障害検知についてはエラーログをSlackに通知することで解消しました。また、Sidekiqのダッシュボード機能によりエラー確認・ジョブ再実行が簡単にできるようになったので運用も楽になりました。
複数の開発言語による改修コストが高い
C#・Golangのバッチ処理をやめてRuby on Railsに非同期システムを導入したことで開発言語はRubyだけになりました。
ステージング環境で通知確認ができない
非同期システムのステージング環境を構築したのでQA時に通知確認ができるようになりました。
その他
その他考慮したのは緊急度が高い通知は「critical」キューから配信、既存通知は「default」キューから配信しています。遅延が発生しても問題ない1:Nの通知は「multi」キューに分けることで緊急度・優先度が高い通知に遅延が起きないように考慮しています。これらのキューは処理の性質や負荷が異なるので、キュー単位でReplica数やリソース割り当てができるようにKubernetesのDeploymentを用意しました。Deploymentの定義には以下のようにSidekiq起動時キューを指定しています。
spec: serviceAccountName: sidekiq shareProcessNamespace: true containers: - name: sidekiq-critical imagePullPolicy: Always command: ["bundle", "exec"] args: - | sidekiq \ --verbose \ --queue critical \ --pidfile ./tmp/pids/sidekiq.pid lifecycle: preStop: exec: command: [ "/bin/bash", "-c", "SIDEKIQ_PID=$(ps aux | grep sidekiq | grep busy | awk '{ print $2 }'); kill -SIGTSTP $SIDEKIQ_PID", ]
EKSについての詳細は以前WEAR部SREチームから公開した記事を参考にしてください。
ローカル開発環境
docker-composeを利用してローカル開発環境からRedis, Sidekiq, dynamodb-local, dynamodb-adminを使っています。
redis: image: "redis:6.0.16" ports: - "6379:6379" volumes: - "./db/redis:/data" sidekiq: depends_on: - redis links: - redis build: context: . args: - SIDEKIQ_PRO_CREDENTIALS=${SIDEKIQ_PRO_CREDENTIALS} dockerfile: dockerfiles/Dockerfile.app command: bundle exec sidekiq -C config/sidekiq.yml environment: REDIS_URL: redis://redis:6379 dynamodb-local: container_name: dynamodb-local image: amazon/dynamodb-local:1.17.0 user: root command: -jar DynamoDBLocal.jar -sharedDb -dbPath /data volumes: - "./db/dynamodb:/data" ports: - 8001:8000 networks: - dynamodb-local-network dynamodb-admin: container_name: dynamodb-admin image: aaronshaf/dynamodb-admin:latest environment: - DYNAMO_ENDPOINT=dynamodb-local:8000 ports: - 8002:8001 depends_on: - dynamodb-local networks: - dynamodb-local-network
Sidekiqについて
APMを導入したい場合Sidekiq Proを使う必要があるため、WEARではSidekiq Proを導入しました。データを失うことなくネットワークの問題に耐える機能とジョブのバッチ処理ができるのも導入した理由です。
Sidekiqにはキューの状態確認やジョブの管理できるダッシュボード機能があり、簡単にWebサイトへ追加できます。Railsにダッシュボードを追加したい場合はこちらを参考にしてください。追加する際にSidekiqへの管理画面のアクセス制限追加も忘れないでください。Basic認証とDeviseを使った方法、セッションを使う方法があります。本記事では詳細なコードは省略します。WEARでは管理サイトがあるので管理サイトのメニューに追加して使用しています。

Sidekiqダッシュボードの再実行とデッド状態について
Sidekiqジョブは約21日間で25回、再試行します。その時間内にバグ修正をデプロイすると再試行され正常に処理されます。25回後にも再実行できないジョブについては手動の介入が必要になると想定してそのジョブはデッド状態になります。WEARではデッド状態の監視のため、以下のように再実行設定とデッド状態時にSlackへメッセージを送っています。
Sidekiq.configure_server do |config| config.redis = { url: redis_url } config.death_handlers << ->(job, ex) do message = "エラー: #{ex.message}." params = { channel: slack_channel, username: 'Sidekiq', attachments: [ { fallback: message, pretext: 'Job 再実行失敗', color: '#D00000', title: "class: #{job['class']}, job_id: #{job['jid']}", title_link: "/sidekiq/morgue", fields: [ { title: 'detail', value: message } ] } ] } Slack::Message.send(webhook_url: slack_webhook_url, params: params) end end Sidekiq.default_worker_options['retry'] = 3
Sidekiqのエラー処理方法や再実行ルールの詳細についてはこちらを参考にしてください。
Sidekiqキューについて
SidekiqはRedisで「default」と呼ばれる単一のキューを使用します。複数のキューを使用する場合は、Sidekiqコマンドの引数として指定するか、Sidekiq構成ファイルで設定できます。各キューは、オプションの重みを追加できて重みが2のキューは、重みが1のキューの2倍の頻度でチェックされます。以下の「- [キュー名、重み]」という書式がそれに該当します。
# config/sidekiq.yml :concurrency: 25 :pidfile: ./tmp/pids/sidekiq.pid :queues: - [critical, 3] - [default, 2] - [multi, 1]
以下のコマンドでSidekiqデーモンを起動できます。
$bundle exec sidekiq -C config/sidekiq.yml
ジョブを実行する時に以下のようにキューを指定して非同期ジョブを実行しています。
class ExampleJob < ActiveJob::Base # Defaultキュー設定 queue_as :default def perform(*args) # ジョブ実装 end end ExampleJobJob.set(queue: :default).perform_later
Sidekiqについて説明しているYouTubeのチャンネルもあるので参考になると思います。
ローカルDynamoDB環境
ローカル環境でAWSのDynamoDBを接続したくなかったのでdynamodb-local, dynamodb-adminを使ってAWS環境と同じ環境で開発・テストができるようにしました。dynamodb-adminはローカル環境のサイトからDynamoDBに直接データ登録・編集・検索ができるので便利です。

Dynamoid
DynamoidはRuby on Railsで動作するDynamoDBのO/Rマッパーです。Dynamoidを使うとActiveRecordのようにモデルを定義してそのモデルに対するデータの読み書きができます。Gemfileにdynamoidを追加するだけで簡単にDynamoDBのCRUDが可能になるので便利です。
gem 'dynamoid'
class Dynamodb::Example include Dynamoid::Document table name: :example, key: :id field :id, :integer ... end
Dynamoidのテスト設定はDynamoidのGitHubリポジトリを参考にしてください。
現在の状況
WEARのPUSH通知システムリプレイスは2段階にフェーズを分割して実施しています。フェーズ1は既に完了しコーディネート動画やフリマ機能に必要だった新規通知については新しいシステムで問題なく運用中です。
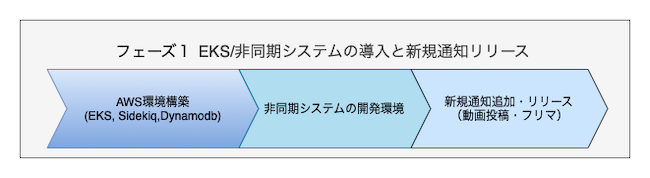
フェーズ2は現在進行中で既存通知のリプレイスと1:N通知を改善する予定です。フェーズ2の話も次回のテックブログで書く予定なのでご参考になればと思います。

今後の課題
大量の1:N通知についての負荷検証・対応と非同期ジョブのバッチ処理が今度の課題になるかと思います。FCMの複数のデバイスにメッセージ送信機能とSidekiqのバッチを利用して大量の1:N通知の対応を検討しています。既存通知のリプレイスと不要になった既存通知システムの廃止作業も今後の課題です。
最後に
本記事ではPUSH通知リプレイスフェーズ1を紹介しました。個人的にRuby on Railsに非同期システムを導入した経験がなかったので導入の事例・必要なライブラリ・ツール、開発環境についてとても悩みました。同じ悩みを抱えている非同期システムの導入を検討している方や未経験の方の参考になれば幸いです。
WEARではまだリプレイスを必要とされる機能がたくさん残っています。サービスを一緒に盛り上げていける方を募集しています。少しでもご興味のある方は以下のリンクからぜひご応募ください。