



こんにちは、WEARバックエンドブロックの天春です。バックエンドの運用・開発に携わっています。本記事では、以前公開したWEARにおけるプッシュ通知システムのリプレイス のフェーズ2を終え、旧環境のプッシュ通知システムのリプレイスを完了したのでシステム構成や移行手順をご紹介します。
目次
1:Nのプッシュ通知システム
WEARには2種類の通知が存在しており、それをフェーズ1(1:1通知リプレイス)とフェーズ2(1:N通知リプレイス)に分けてリプレイスを行いました。今回フェーズ2のリプレイスを完了し、全てのリプレイスを完了しました。
- 1人のユーザーに送る通知(フェーズ1)
- 複数のユーザーに送る通知(フェーズ2)

リプレイス前の1:Nのプッシュ通知システム
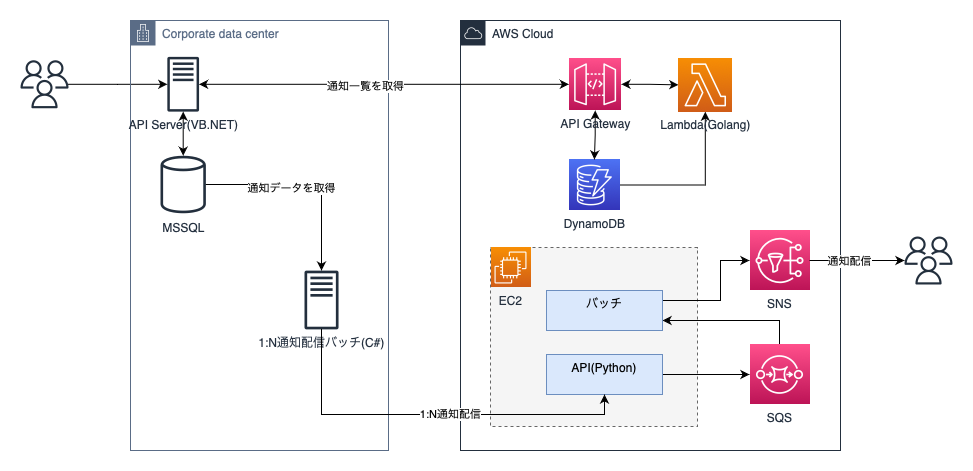
Windowsサーバー上で稼働する1:N通知処理バッチがタスクスケジューラに登録されて定期的に通知配信API経由で通知を配信していました。通知サービスはAWSのSNS経由でAppleプッシュ通知サービス(APNs)とFirebase Cloud Messaging(FCM)を使っていました。
リプレイス前のシステム構成
問題点
既存の1:N通知はバッチで配信していたのですが、以下のような問題がありました。
- cronジョブで一定量ずつ処理するため、大量の通知が発生した場合に遅延する場合がある
- 1:N通知対象を取得するバッチ・配信処理API・配信バッチ・通知データを修正するLambdaなどで問題が発生したとき複数言語で開発された実装の理解・修正・影響範囲を調査するのに時間がかかる
- 再試行のためリモートデスクトップ経由でバッチを手動実行する必要がある
- エラーログの不足でエラーを検知しても原因把握まで時間がかかる
リプレイス後の1:Nのプッシュ通知システム
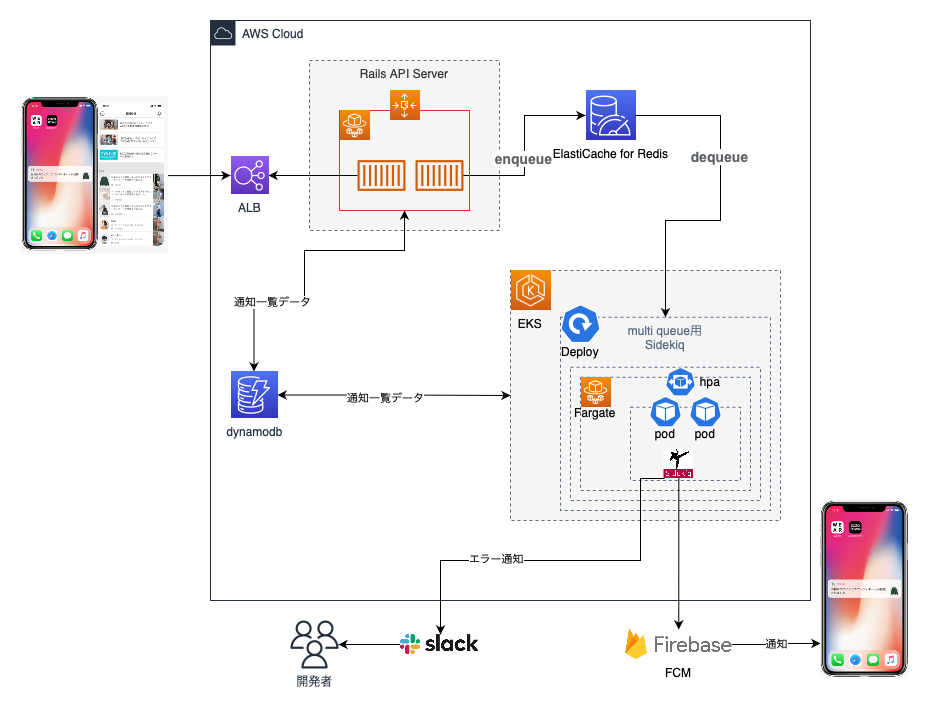
リプレイス後はAmazon Elastic Kubernetes Service (EKS) 導入により負荷が多い時の非同期処理(Sidekiq)のスケールアウトが可能になりました。1:N通知専用のキュー(multi)は2つのPod1で構成されています。各Podにはスレッドを10に設定したSidekiqのプロセスが動いています。プロセスが2つ動いているので20件のジョブを同時に実行できる環境になりました。それに加えて1つのジョブが500件単位で配信・通知履歴書き込みを行っているので1万件の通知を同時に配信できるようになっています。
- Sidekiq導入でダッシュボードから遅延の状況をリアルタイムでわかるようになった。
- EKS化されているのでPodを増やすことで遅延の調整も可能になった。
- エラーが発生した場合Slackの通知からSidekiqダッシュボードに遷移できるのでエラー確認・再試行が簡単になった。
- APM導入でリアルタイムなアプリケーションの性能監視ができるようになった。
リプレイス後のシステム構成
Amazon ElastiCache for Redisにenqueueした通知データをSidekiqプロセスがdequeueしてFCM経由で通知配信し、DynamoDBに通知履歴を保存します。
1:Nキュー(Sidekiqダッシュボード)

負荷テスト
1:1通知と違って1:N通知の場合は大量の通知が同時に発生するため、システムの負荷を事前に把握して負荷に耐えられるシステム設定をしました。
目標
WEARの既存通知の配信状況を把握して想定以上の通知が発生しても問題ないシステムを構築する。
対象
通知配信に必要なAmazon ElastiCache for Redis、DynamoDB、Sidekiqサーバーに対して負荷検証を行いました。
事前準備
- WEARの既存通知の配信と今後増える通知を想定した同時実行数を設定
- 負荷の調整が可能な負荷テスト用API(通知の種類と同時配信数が指定可能)
負荷テスト実施
負荷テスト用のAPIを実行して目標とする件数の通知が同時に発生した時のシステムのCPU・メモリ負荷を検証しました。
- Amazon ElastiCache for Redis:キューに紐づくジョブを処理するためのSidekiq WorkerのPodに割り当てるメモリ・CPUを確定
- DynamoDB:WEARのDynamoDBの読み取り・書き込みキャパシティモード はプロビジョンドキャパシティモード。オンデマンドモードの方が費用削減になるケース もある

- Sidekiq:SidekiqのダッシュボードとDatadogを利用して遅延・処理時間・負荷をモニタリング
負荷テスト結果
負荷テストの結果、メモリ・CPUはかなり余裕がある状態でしたがメモリリークは発生していることがわかりました。
2023/4/4修正:負荷テストの結果、メモリ・CPUはかなり余裕がある状態でしたがメモリの膨張は発生していることがわかりました。
負荷テスト実施後の改善内容
メモリリークについて、Sidekiqの公式サイト に対応方法が記載されていたので対応しました。
2023/4/4修正:メモリの膨張について、Sidekiqの公式サイト に対応方法が記載されていたので対応しました。
- クエリキャッシュ削除
読み取りを正しく実行した場合でもActiveRecordクエリキャッシュはクエリ結果を余計に保存することでメモリの膨張を引き起こす可能性があります。
Sidekiqの公式サイト からRails 5.0以降クエリキャッシュはSidekiqワーカーを含むバックグラウンドジョブに対してデフォルトで有効になっていることがわかりました。
大量のメモリを使用している場合はクエリキャッシュを無効にするか手動でクエリキャッシュをクリアしたら改善されるとのことでした。
WEARではクエリキャッシュをクリアしました。
以下はSidekiqの公式サイト のサンプルです。
# クエリキャッシュ無効 ActiveRecord::Base.uncached do User.find_each { |u| u.something } end # クエリキャッシュクリア User.find_in_batches.each do |users| users.each { |u| u.something } ActiveRecord::Base.connection.clear_query_cache end
- メモリ断片化対応
Sidekiqの公式サイト に以下の内容が記載されていたのでMALLOC_ARENA_MAX=2を追加しました。
Linux環境のRubyはデフォルトのglibc実装を使用してすべてのメモリを割り当てるのでメモリ断片化が非常に起こしやすく、肥大化につながる可能性があります。最も簡単なメモリ断片化の対応方法は、Rubyプロセスの環境にMALLOC_ARENA_MAX=2を追加することです。
大量の通知の遅延を減らす
FCMの通知配信とDynamoDBの書き込み処理をまとまった単位で処理することで、通知の負荷と遅延を減らしました。ここからは具体的にどのような処理を行ったのか紹介します。

同時実行数の調整
Sidekiqは起動時に以下のようにキューと並列実行数の設定が可能です。
sidekiq --verbose --queue multi --concurrency 10
並列実行数は、データベースのconnection pool数を超えないように設定する必要があります。
ActiveRecord::ConnectionTimeoutError: could not obtain a connection from the pool within 5.000 seconds (waited 5.009 seconds); all pooled connections were in use
500件単位でFCM通知配信
FCMの複数のデバイスにメッセージを送信する機能 を利用してSidekiqの1つのジョブが500件のFCM通知を配信するようにしました。
1:N通知配信の親ジョブ
class ParentMultiPushNotification < ApplicationJob # 省略 def perform(member_ids) # 省略 member_ids.each_slice(500) do |member_ids_group| ChildMultiPushNotification.set(queue: :multi).perform_later(member_ids_group) end end end
500件単位でFCM配信を行う1:N通知配信の子ジョブ
FCMの batch APIのリクエストボディに boundary名 区切りの500件の messages:send APIのリクエストを追加して実行することで500件単位のFCM配信ができました。詳細内容は FCMの複数のデバイスにメッセージを送信する機能 を参考にしてください。
class ChildMultiPushNotification < ApplicationJob # 省略 def perform(to_member_ids) # 省略 bearer_token = 'bear_token' request_body = '' # payloadsには500件のpayloadが保存されている payloads.each do |payload| request_body += <<REQUEST_BODY --boundary名 Content-Type: application/http Content-Transfer-Encoding: binary Authorization: Bearer #{bearer_token} POST https://fcm.googleapis.com/v1/projects/#{project_id}/messages:send Content-Type: application/json accept: application/json #{payload} REQUEST_BODY end request_body += '--boundary名--' Faraday.new('https://fcm.googleapis.com/batch').connection.post('batch') do |request| request.headers['Content-Type'] = 'multipart/mixed; boundary=boundary名' request.body = request_body end end end
500件単位でDynamoDBに書き込み
FCMと同じくDynamoidのimportメソッド を使って500件単位でDynamoDBに書き込みを実行することでDynamoDBの接続を減らしました。
Datadog APM導入
Sidekiq Pro からDatadogのAPMが使えます。WEARではSidekiq Proを使っているのでDatadogのAPM を導入してリアルタイムなアプリケーションの性能監視ができるようになリました。

APM設定
config/initializers/datagog_tracer.rb
c.tracing.instrument :sidekiq, service_name: 'service_name'
config/initializers/sidekiq.rb
require 'datadog/statsd' Sidekiq::Pro.dogstatsd = -> { Datadog::Statsd.new('localhost', 8125, namespace: 'sidekiq') } Sidekiq.configure_server do |config| config.server_middleware do |chain| require 'sidekiq/middleware/server/statsd' chain.add Sidekiq::Middleware::Server::Statsd end end
現在の状況
想定した件数以上の通知が発生したら遅延は発生しますが、サービス上緊急性がない通知も存在するので、費用を考慮した許容できる範囲で運用しています。またWEARでは緊急度が高い通知は専用の「critical」キューから配信しています。遅延が発生しても問題ない1:Nの通知は「multi」キューに分けることで緊急度・優先度が高い通知に遅延が起きないように考慮しています。
今後の課題
- Sidekiqが大量の通知を処理した後にメモリの数値が高い状態のままになるケースがある。
- 旧システムのバッチ停止、関連API・AWSリソースの廃止。
最後に
複数の開発言語で開発された複雑なレガシー通知システムをすべてRubyを使った非同期システムにリプレイスするまで1年程度かかりました。特に問題なくリリースできたので嬉しく思います。
特にSidekiqの導入によってリアルタイムで非同期ジョブの状態が確認できて再試行も簡単にできるので運用しやすくなりました。Sidekiqを検討しているならSidekiq Pro がおすすめです。Datadog APM以外にSidekiq::Batch も使えるので並行実行するすべてのジョブが終了したときにコールバック処理が可能です。
本記事ではWEARにおけるプッシュ通知システムを全て完了した話でした。大量のFCM通知配信・DynamoDB書き込み処理・非同期システムの導入を検討している方や未経験の方の参考になれば幸いです。WEARではサービスを一緒に盛り上げていける方を募集しています。少しでもご興味のある方は以下のリンクからぜひご応募ください。