



こんにちは。カート決済部カート決済基盤ブロックの斉藤とSRE部カート決済SREブロックの飯島です。普段はZOZOTOWNカート決済サービスのリプレイスに携わっています。
弊社はモノリスからマイクロサービスへのリプレイスを進めており、カート決済サービスもその一環としてリプレイスを進めています。
よろしければ、カートリプレイスPhase1としてカート投入リクエストのキャパシティコントロールを実現させた事例もご覧ください。
本記事ではリプレイスの中でも、カートリプレイスPhase2としてZOZOTOWNで扱う在庫データをクラウドリフトした事例を紹介します。
はじめに
本章ではまず、リプレイス前のZOZOTOWNの在庫データの概要を説明します。
ZOZOTOWNの在庫データはオンプレミス環境で稼働しているSQL ServerのDB・テーブルで管理されています。CartDBとFrontDBという2つのDBで管理しており、CartDBはユーザのカート操作に関わる在庫データ、FrontDBはユーザの注文確定に関わる在庫データを管理しています。CartDBとFrontDBの在庫データの概要を以下に示します。
- CartDBの在庫テーブル
- 販売可能数を管理している
- メタデータとして販売種別や販売開始日、販売価格等も管理している
- カート投入操作で更新される
- CartDBのカートテーブル
- ユーザがカートに確保している販売可能数を管理している
- カート投入・カート削除操作で更新される
- FrontDBの在庫テーブル
- 販売可能数を管理している
- メタデータとして販売種別や販売開始日、販売価格等も管理している
- 注文確定で更新される
上記テーブルのデータの流れを以下の図に示します。

CartDBとFrontDBの在庫テーブルは過去1つのDBで管理されていました。しかしZOZOTOWNの成長に合わせてカート投入と注文確定という在庫データへの主要なユーザアクションによるDBへの負荷を分散させるために分離されました。在庫テーブル・カートテーブルはSQL Serverのトランザクションで更新することによって販売可能数の整合性を担保していました。
背景・課題
昨今のZOZOTOWNの成長やカートリプレイスPhase1でも触れていた特定商品へのカート投入リクエストの集中によって在庫データへのアクセスが増加しており、負荷が上昇していました。また、上述した通り在庫データの管理にオンプレミス環境で稼働しているSQL Serverを使用しているため、耐障害性やスケーラビリティに課題がありました。このような課題から現在の在庫データの構成だと数年後には限界を迎えると考えられます。
具体的な負荷上昇につながっているボトルネックについて説明します。
CartDBで管理している在庫テーブルはカート投入時に以下のようなクエリが実行されます。
update 在庫テーブル set 販売可能数 = 販売可能数 - 1 where PK = ***
上記のクエリが同一の特定商品へ大量に実行されると、在庫テーブルへの読み取り要求・更新要求の競合が発生し、クエリの実行時間の大幅な遅延やタイムアウトが発生します。最悪のケースでは、クエリの遅延によりワーカースレッドが枯渇しCartDB全体のスループットが著しく下がるという障害が発生することもあります。SQL Serverの読み取り要求・更新要求の競合については以下に詳しく記載されていますので気になる方はご覧ください。
解決へのアプローチ
この問題を解決するためにCartDBで管理していた販売可能数をAmazon DynamoDB(以下、DynamoDB)へ移行することにしました。
DynamoDBはオンプレミス環境で稼働しているSQL Serverと比較して以下のようなメリットがあります。
- 耐障害性が高い
- スケーラビリティが高い
- 自動でキャパシティがスケールイン・スケールアウトされる
また、カートリプレイスPhase1でも採用されているため、既に運用ノウハウがある点も採用に至った理由です。弊社の半澤がカートリプレイスプロジェクトでDynamoDBを採用した背景について説明している記事がAmazon Web Serviceブログに掲載されていますので、そちらもぜひご覧ください。
アプリケーションの説明
ここからカートリプレイスPhase2のシステム構成について説明します。
システム構成図は以下のようになっています。

DynamoDB
SQL Serverから移行された在庫データを持ちます。テーブル定義の例を以下に示します。
| AttributeName | Type | KeySchema | Description |
|---|---|---|---|
| stock_id | N | Hash | 商品のサイズ・カラーを特定できるID |
| goods_id | N | 商品を特定できるID | |
| stock_quantity | N | 販売可能数 | |
| created_at | S | 作成日時 | |
| updated_at | S | 更新日時 |
上記のようにZOZOTOWN上で更新頻度が高い販売可能数をDynamoDBへ移行しました。これによって同一の特定商品へカート投入リクエストが集中した場合でも負荷に耐えられることが可能となりました。
上記のテーブルが生まれたことにより、ZOZOTOWNの在庫データの流れは以下のようになりました。
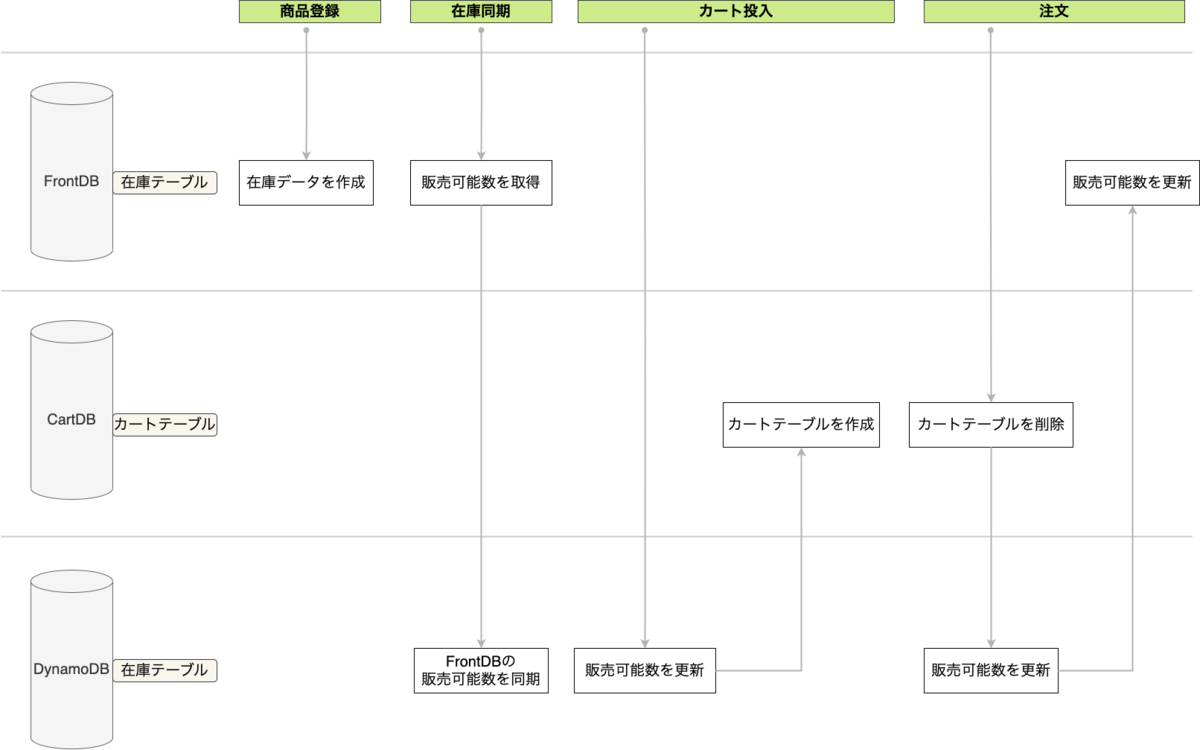
在庫同期については後述します。
今回、読み取り/書き込みスループットの課金方法と管理方法についてはオンデマンドモードを採用しています。その理由としては、ZOZOTOWNはカート投入リクエスト数がイベントや時間帯によって大きく異なり、また人気商品の発売による突発的なリクエスト増加もあるためキャパシティを予測することが困難なためです。リクエストが少ない時はキャパシティが縮小されてコストが抑えられ、逆にリクエストが増加した際には自動で拡張されるため柔軟性と拡張性を担保できます。
バックアップについてはPoint-in-time recovery(以下、PITR)を採用しています。PITRとは自動で継続的な増分バックアップを作成し、直近5分より以前の特定の状態に復元できるDynamoDBの機能です。バックアップの保持は35日間であるためそれ以前の状態には復元できません。他にも定期的にフルバックアップを作成するオンデマンドバックアップ機能もありますが、今回は以下の理由からPITRを採用しました。
- 在庫データは常に変動するため、何日前の何時いつの状態にリカバリするといった要件がない
- 運用ミスでテーブルを削除してしまった時の念のためのバックアッププランがほしい
- 復旧時間を短縮するためにできるだけ直近のデータにリカバリしたい
API
在庫データをDynamoDBに移行するとともに、在庫データを操作する機能をCartAPIという名称のAPIとして切り出しています。元々はオンプレミスのWebサーバで稼働していたClassic ASPをJavaにリプレイスし、Amazon EKS上(以下、EKS)でマイクロサービス化しました。
CartAPIが持つエンドポイントは以下のものがあります。
- 販売可能数を取得する参照系
- 販売可能数を減少、増加する更新系
またSQL ServerとDynamoDBの在庫同期や不整合を防ぐためのバッチから呼び出されるCartBatchAPIも誕生しています。CartAPIと同様にClassic ASPからJavaにリプレイスし、EKS上でマイクロサービス化しました。バッチについては後述します。
CartBatchAPIが持つエンドポイントは以下のものがあります。
- 販売可能数を取得する参照系
- 販売可能数を同期、補正する更新系
その他、AWSリソース
DynamoDBの更新内容はAmazon Kinesis Data Streams(以下、KDS)を用いてキャプチャし、Amazon Aurora MySQL(以下、MySQL)に保存しています。KDSにキャプチャされたデータはKinesis Client Library (以下、KCL)アプリケーションによって取り出し、MySQLに書き込みます。このMySQLのデータは後述する在庫を補正するバッチで参照されます。KCLアプリケーションの仕様の詳細についてはカートリプレイスPhase1のテックブログで触れているのでご参照ください。
在庫の同期・補正を行うバッチ
今まではFrontDBの在庫データをCartDBに同期していましたが、リプレイス後はFrontDBの在庫データ内の販売可能数をDynamoDBに同期するように変更しました。
同期のフローは以下のとおりです。
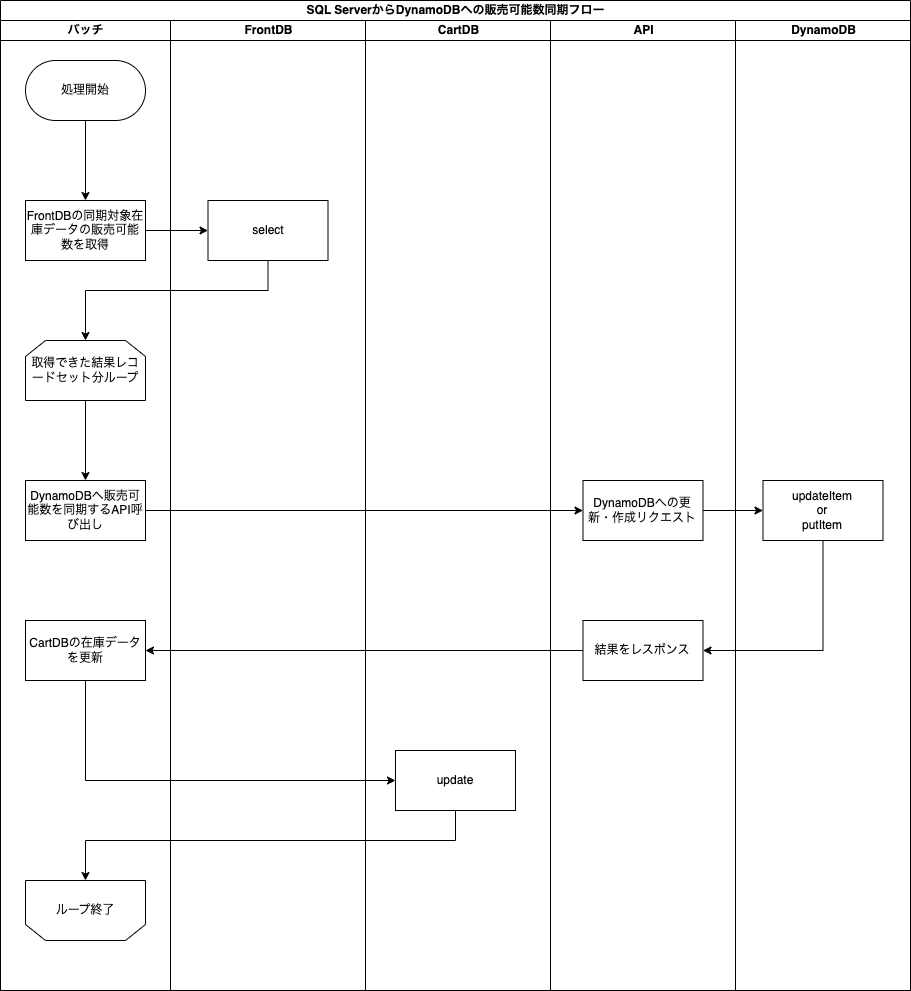
上述のバッチが常に稼働しているためニアリアルタイムでSQL Serverの販売可能数の変更がDynamoDBに反映されます。
しかし、DynamoDBとSQL Serverの更新処理は別トランザクションであるため、ユーザのカート操作によって以下のような不整合が考えられます。
- カート投入時
- DynamoDBの更新が成功したがCartDB(カートテーブル)の更新に失敗する
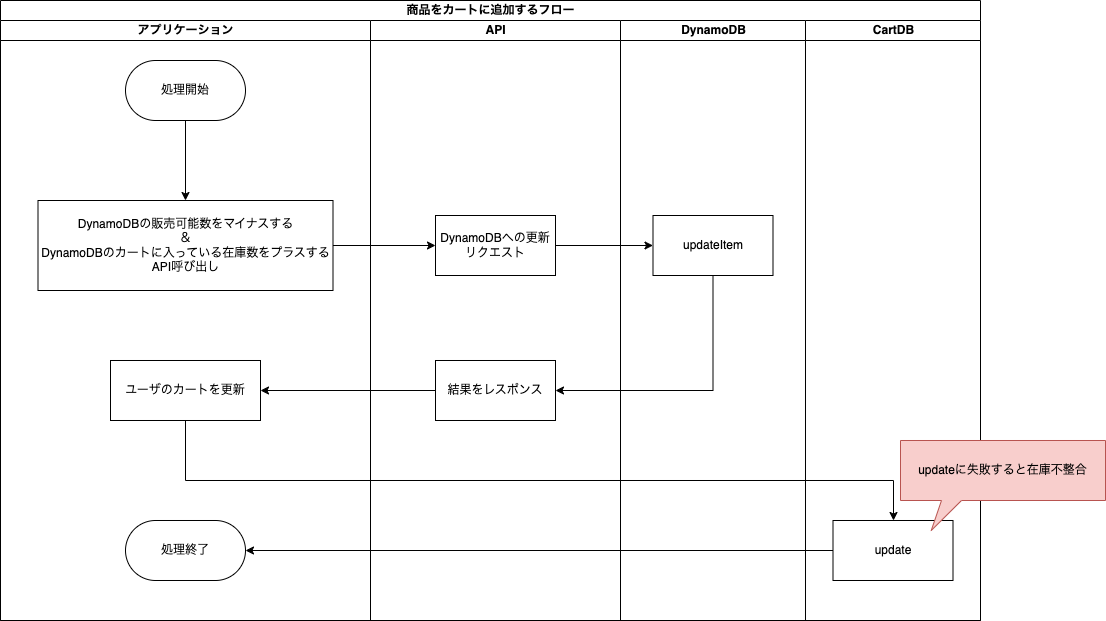
- カート削除時
- CartDB(カートテーブル)の更新が成功したがDynamoDBの更新に失敗する

上記のような不整合を防ぐために不整合を検知して補正するバッチを作成しました。
バッチの仕組みとしては以下の2つの履歴から在庫変動があったデータをターゲットとします。ターゲットとなる在庫に対して、オンプレミスの販売可能数とユーザのカートに確保されている販売可能数を用いてDynamoDBの販売可能数を補正するというものです。
- ユーザのカート操作の履歴(SQL Server)
- DynamoDBの操作履歴(MySQL)
上記2つのバッチ処理によって常にDynamoDBの販売可能数はSQL Serverの販売可能数と一致するようになります。
リリースまでの道のり
負荷試験
在庫を同期するバッチや在庫を補正するバッチの負荷試験を行いました。在庫データの更新される件数をもとに同期の件数を処理し切れるか、また同期の処理時間がどの程度かを検証しました。検証結果に応じてチューニングを行い、バッチの並列度・処理間隔を決定しました。
リリース
本番環境におけるSQL ServerからDynamoDBへの在庫データの移行はN%リリースで行いました。以下がN%リリースの手順です。
- 初期データの移行
- ZOZOTOWN内で扱う販売可能数のN%がDynamoDBの販売可能数を参照するように変更するリリース
各ステップの詳細を以下に説明します。
1. 初期データの移行
最初のステップとして、本番環境のSQL Serverの在庫データをDynamoDBに同期しました。SQL Serverの在庫データをCSV形式で出力し、AWSのブログで紹介されているソリューションを参考にしたスクリプトを使用してDynamoDBにインポートしました。
スクリプトではBoto3(AWS SDK for Python)というPythonからAWSリソースを操作できるライブラリを使用しています。DynamoDBへの書き込みはbatch_writerを使用し、1回の書き込みリクエストの上限を気にすることなく、大量のデータを効率良く処理させています。
以下はスクリプトから一部抜粋、加工したもので、動作は保証しませんのでご了承ください。
import boto3 import csv s3 = boto3.resource('s3') dynamodb = boto3.resource('dynamodb') def main(s3_bucket=s3_bucket, csv_file=csv_file, dynamodb_table=dynamodb_table): obj = s3.Object(s3_bucket, csv_file).get()['Body'] table = dynamodb.Table(dynamodb_table) batch_size = 100 batch = [] for row in csv.DictReader(codecs.getreader('utf-8')(obj)): if len(batch) >= batch_size: write_to_dynamo(batch, table) batch.clear() batch.append(row) if batch: write_to_dynamo(batch, table) def write_to_dynamo(rows, table): with table.batch_writer() as batch: for i in range(len(rows)): batch.put_item( Item=rows[i] )
今回Lambdaには以下の制約があるためスクリプトの実行環境はEC2を選択しました。
- Lambdaのタイムアウトが15分
- 15分で処理できる件数は約100万件
対象の在庫データの件数は1500万件を超えており、また日々増え続けていました。Lambdaのタイムアウト値や並列数の計算せずにシンプルに考えるためそのような制約がないEC2を選択しました。以下が手順と実行環境の全体図です。
- CartDBから在庫データをCSV形式でエクスポート
- CSVをS3にアップロード
- EC2にS3のCSVをダウンロード
- EC2上でスクリプトを実行してCSVの中身をDynamoDBにインポート

次に、インポート時に発生した問題とその解決方法、またインポート後に整合性を確認するために行なった作業をご紹介します。
DynamoDBのキャパシティ
対象の在庫データは1500万件以上で、SQL Serverとの差分を小さくするためできる限り短時間での同期が望まれました。そのため複数台のEC2上でスクリプトを並列実行したところ、オンデマンドモードでの書き込みキャパシティの拡張が間に合わず、スロットリングエラーが多発しました。この問題に対して以下のように解決しました。
- 同期前にオンデマンドモードからプロビジョニングモードに切り替える
- 事前にキャパシティを手動で拡張する
DynamoDBはオンデマンドモードからプロビジョニングモードに切り替えた場合、24時間経過しないと再度オンデマンドモードに戻せませんのでご注意ください。
整合性の担保
同期完了後に、SQL Serverから出力したCSVファイルとDynamoDBのデータにズレが生じていないか確認しました。スクリプトでログ出力やリトライ設定などは行っているので異常時には検知やリカバリができますが、より厳密に整合性を担保するためです。まずはデータの件数が一致しているかAWS CLIで確認しました。
$ aws dynamodb scan --table-name <table-name> --select COUNT --return-consumed-capacity TOTAL
補足ですが、上記コマンドでDynamoDBの読み込みキャパシティがある程度必要になります。そのため同期前に書き込みだけでなく読み込みのキャパシティも拡張しています。
次にSQL Serverから出力したCSVファイルを正として、データ1件1件をDynamoDBのデータと照らし合わせる作業を実施しました。先述の在庫同期と同じ環境下で、こちらもスクリプトを使用しました。同期完了後はすぐにDynamoDBのテーブルとSQL Serverとの差分を補正するためのバッチ処理を実行する必要がありました。そのため照合作業は以下のように非同期で行いました。
- 同期した直後のDynamoDBをPITRで復元する
- 復元元DynamoDBはバッチ処理の対象となりデータが更新されていくためバッチ処理開始前に復元する
- 復元先のDynamoDBに対してCSVと差分がないか確認する
同期後のデータの件数の一致と、データ内容に差分がないことを確認し、在庫同期において整合性を担保できました。
2. リリース
当然、在庫データはZOZOTOWNでも重要なデータなので影響範囲を限定するためにN%リリースを実施しました。その際、ZOZOTOWNで扱っている全在庫をN%に区切りながらリリースすることが難しかったため、以下のように決めました。
- ZOZOTOWNで扱っている特定の1ショップだけクラウド対象にする
- ZOZOTOWNで扱っている特定の10ショップだけクラウド対象にする
- ZOZOTOWNで扱っているショップのN%をクラウド対象にする
- ZOZOTOWNで扱っているショップの100%をクラウド対象にする
というように、段階的にクラウド対象を増やしていきました。最終的にはZOZOTOWNで扱っているすべてのショップをクラウド対象にしました。
効果
本リプレイスの効果について説明します。
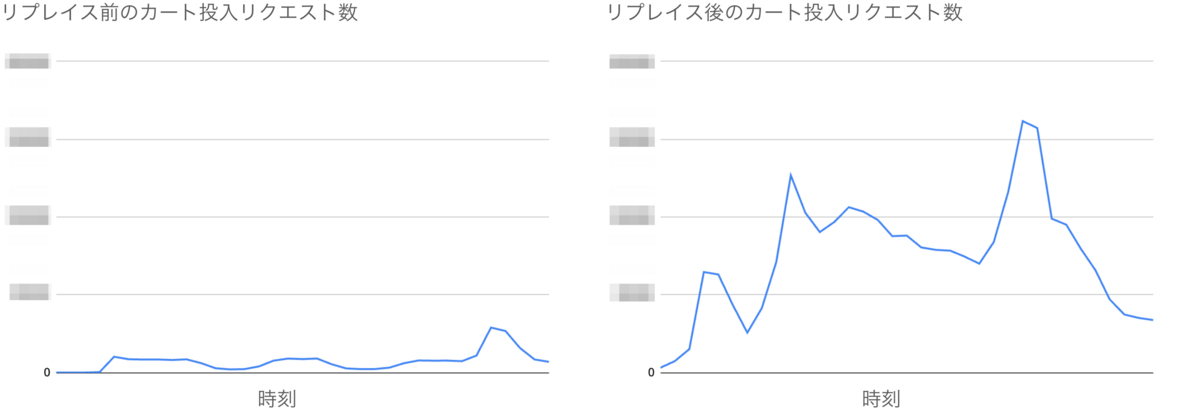
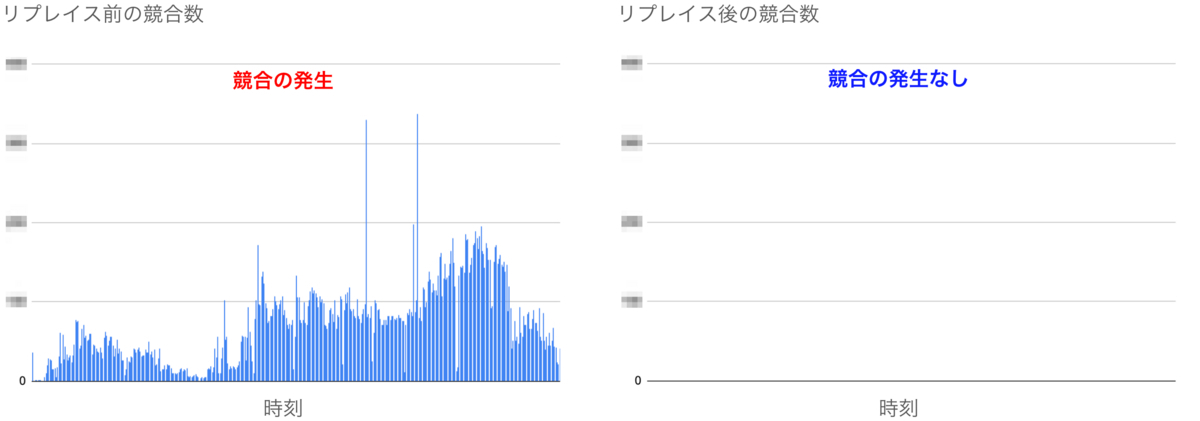
リプレイス前は同一の特定商品へ大量のカート投入リクエストが実行されると、在庫テーブルにおいて読み取り要求・更新要求の競合が発生していました。その結果CartDBの負荷が上昇していました。しかしリプレイス後では競合の発生を防ぎ、CartDBの負荷を抑えられました。
下図はリプレイス前後で、同一の特定商品へ大量のカート投入リクエストが行われた某日を比較しています。リプレイス後はリプレイス前より5倍近いカート投入リクエストが実行されているにもかかわらず、競合は発生せずにCartDBの負荷も上昇していないことがわかります。

他の施策との相乗効果
カート決済チームではリプレイス以外にもカート機能の改善に取り組んでいます。本リプレイスと同時期にCartDBの負荷を下げる施策として、Istio Rate Limitを用いた商品単位でのカート投入リクエスト制限を導入しています。先述した本リプレイス後の結果はこの施策との相乗効果といえます。
Istio Rate Limitについては注文リクエストの制限に導入した事例が公開されているのでご覧ください。
さいごに
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。