



はじめに
こんにちは。ブランドソリューション開発本部 WEAR部 SREの和田(@wadason)です。普段は「ファッションコーディネートアプリ WEAR」のSREとしてクラウドの運用やリプレイスをおこなっています。
WEARはサービス開始から10年が経ち、クラウドやオンプレミスを含む大小様々なシステムが稼働しています。アプリケーションを動かすための基盤にはAmazon ECSのようなコンテナを前提としたものから、オンプレミスのAPIやBatchを動かすIISまで幅広く扱っています。そうした中で、約1年前にSREチームが結成され、技術負債の脱却やクラウドを中心としたインフラの運用を行なってきました。当初取り組んでいた大規模なリプレイス案件も落ち着き、チームメンバーが増えてきたので、現在では分散した技術スタックをKubernetesへ統一するリプレイスプロジェクトを開始しています。
本記事ではWEARにKubernetesを導入した背景や、移行にあたり工夫した事例を紹介します。Kubernetesの導入を検討している方やSREの活動事例を知りたい方に向けて、少しでも参考になれば幸いです。
目次
導入の背景
技術負債の脱却による運用負荷の低減
こちらはWEARで利用するクラウドやAWS内のシステムを中心に利用状況をまとめた概要図です。

Fastlyによるオンプレクラウド間のパスルーティング、Akamaiによる画像リサイズなど、様々なクラウドサービスを活用しています。AWS内ではOpsWorksで構成管理するDigdagというワークフロー基盤やECSクラスタで稼働するRailsのAPIを運用しています。その他にもプッシュ通知を扱うインスタンス群が別のAWSアカウントに存在します。プッシュ通知に関する構成は後述します。
これらのシステムは構築されてから数年が経過しています。次第にシステムの複雑性が増していき、ノウハウを引き継げていない状態でした。そのため、障害や日々の運用に関して、なかなか対応のスピードを出せないという課題がありました。そこで、全社的にも広く利用されており、チーム内でも経験者が多いKubernetesに全てのアプリケーションをリプレイスしようと考えました。
GitOpsによる開発者体験の向上
アプリケーションをデプロイするために、OpsWorksスタックの仕組み1や、AWSのCodeBuild、CodePipelineと様々なサービスを利用しています。障害などのイレギュラーな事象が発生した際に、このようなバリエーションの多さは素早い判断のボトルネックになってしまう傾向がありました。
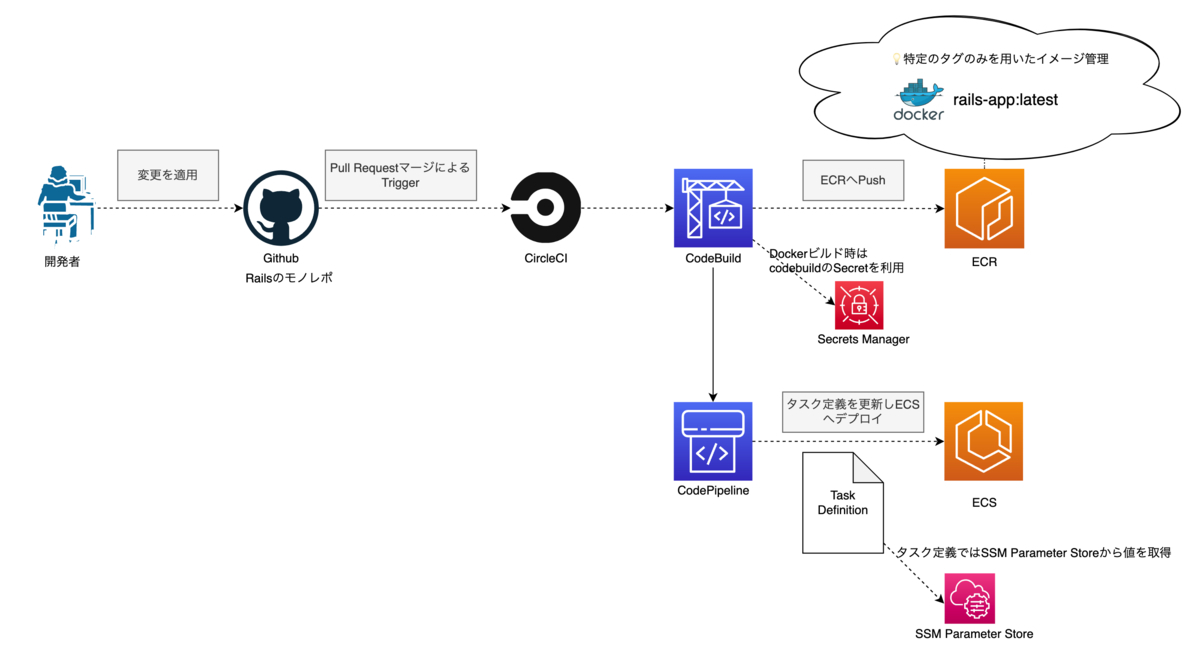
普段の開発では特に課題を感じることはありませんでしたが、障害時は上の図ような複数のサービスの構成を思い出しながら調査を進めることになります。
例えば、CI/CDで利用する環境変数だけに焦点を当てても、以下を利用しています。普段は頻繁に設定を変更しないため、どこで何を設定しているのかが分かりにくい状態にありました。
また、Railsアプリケーションをロールバックする際に、時間がかかってしまう課題がありました。 Dockerイメージをlatestタグのみで管理しているので、ECSのタスクを1つ前にビルドしたイメージでデプロイし直すことができないからです。 アプリケーションはRailsのモノレポであるため、ロジックが膨大でありテスト項目も多いです。もう1度ビルドする場合はRevertしてPull Requestを再作成し、CIによるテストを待たなければいけません。さらに、Pull Requestを適用するとDockerイメージのビルドやECSのタスクを更新するパイプラインを再度実行することになります。
そこで、従来のさまざまな仕組みを利用した複雑なデプロイパイプラインを、可視性が高くシンプルなものへ変更したいと考えGitOps4を採用することにしました。GitOpsはGitを「Single Source of Truth」5として、普段行うデプロイから緊急時のロールバックまで一通りの操作を開発者が普段から利用するGitに集約できます。
GitOpsを実現するツールにはArgo CD6やFlux7、Jenkins X8などがあります。WEARでは充実したGUIに魅力を感じArgo CDを選びました。

このGUIは、機能追加を行う開発チームも利用することを想定しています。 Kubernetesの導入にあたり調査や検証を行なってきたSREとは違い、ECSやOpsWorksを中心に利用してきた開発チームにとってはEKSにも慣れていく必要があります。 全社的にKuberntesの利用は活発ですが、WEARでの採用は初めてであるため、こういった分かりやすさも重要な点と考えました。
リプレイス後の構成
上述の背景を踏まえ、EKSを中心とするシステム構成へと変更しました。以下はその概要図です。 上で紹介したオンプレミスやFastly, Akamaiは今回のリプレイスの対象外となるので省略しています。
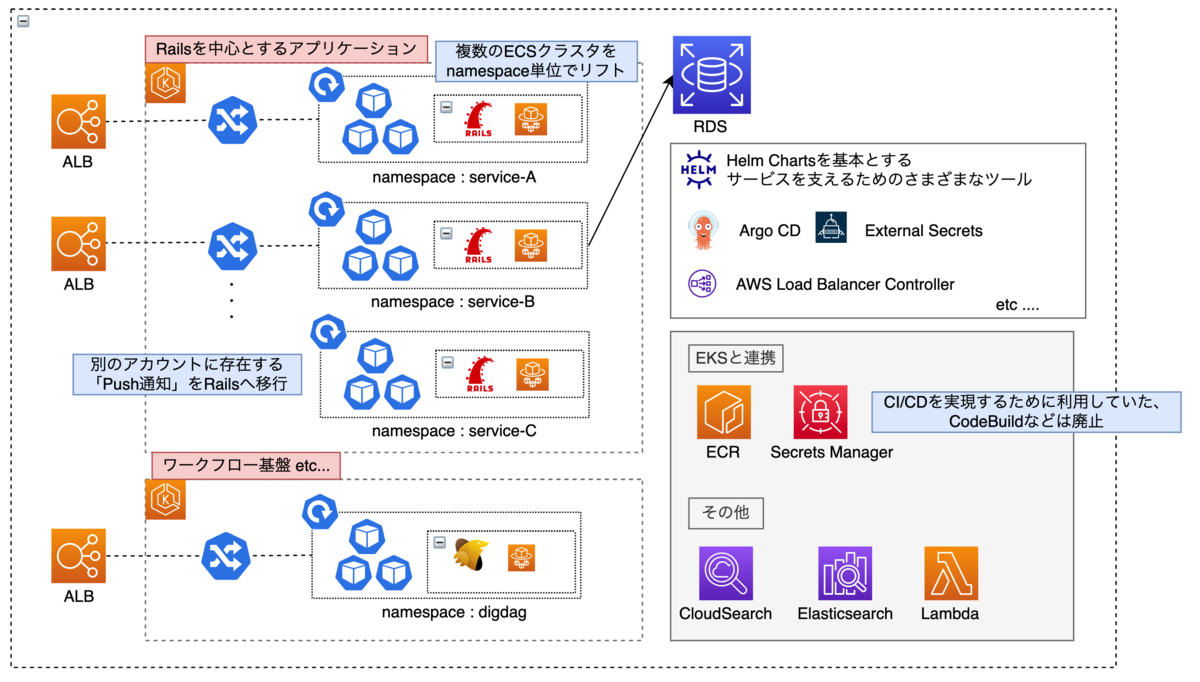
以下に重要な変更点を列挙します。
- ワークフロー基盤を扱うOpsWorksを廃止してEKSへリプレイス
- Railsアプリケーションを扱うECSの各クラスタをnamespace単位でEKSへリプレイス
- 別アカウントに存在するPush通知を扱うシステムをRailsに置き換えEKSへリプレイス(詳細は後述します)
- AWS CodeBuildやAWS CodePipelineを廃止し、すべてのシステムを後述するGitOpsによるデプロイ方法へ統一
また、リプレイスにあたり以下のAWSサービスを廃止します。
- AWS CodeBuild
- AWS CodePipeline
- AWS OpsWorks
- AWS Systems Manager Parameter Store
- Amazon ECS
- 別アカウントに存在するAmazon EC2インスタンス
- 別アカウントに存在するAmazon SQS
- 別アカウントに存在するAmazon SNS
AWSのサービスだけでも廃止できるものが多く、シンプルになったことが分かります。
EKS内で利用する様々なツール
リプレイスにあたり、他のAWSサービスと連携したりモニタリングを行うための様々なツールを導入しました。以下はその一覧です。
| ツール | 用途 |
|---|---|
| argoproj/argo-cd | デプロイ, GUI |
| external-secrets/external-secrets | AWS Secrets Manager等と連携しsecretを作成 |
| kubernetes-sigs/aws-load-balancer-controller | Ingressと連携しAmazon Elastic Load Balancingを作成 |
| kubernetes-sigs/external-dns | Ingressと連携しAmazon Route 53 Recordを作成 |
| kubernetes-sigs/prometheus-adapter | モニタリング, HPA |
| prometheus-operator/prometeheus-opereator | モニタリング, HPA |
| prometheus-community/postgres-exporter | モニタリング, HPA |
| DataDog/datadog-agent | モニタリング |
| aws/aws-for-fluent-bit | ロギング |
これらのツールはHelm Chartsで管理しています。Argo CDでは通常のマニフェストの他に、Helm Chartsのリポジトリを指定できるので、Argo CD Applicationを宣言してそれぞれのChartを導入しています。以下はArgo CDをApplicationで管理する例です。
apiVersion: argoproj.io/v1alpha1 kind: Application # Argo CDのカスタムリソースであるApplicationを宣言 metadata: name: argocd spec: project: default source: repoURL: 'https://argoproj.github.io/argo-helm' targetRevision: 4.5.0 # Helm Chartのバージョンを指定 chart: argo-cd helm: values: | # values.ymlと同じように設定を記述 server: service: type: NodePort parameters: # パラメータでもvalues.ymlと同じような設定が可能 - name: "server.ingress.hosts[0]" value: "xxxxxxx" destination: server: 'https://kubernetes.default.svc'
Helm Chartsやマニフェスト一式はApp Of Apps Pattern9で管理しており、以下のようになっています。

複数のEKSクラスタを用意する理由
Kubernetesのクラスタを構築するにあたり、大まかに以下のパターンが一般的です。
- 1つのクラスタで複数のシステムを扱うマルチテナント(シングルクラスタ)
- 複数のシステムをクラスタ単位で扱うシングルテナント(マルチクラスタ)
WEARでは基本的にはマルチテナントにする方針です。理由は以下です。
- モノレポのRailsアプリケーションで複数のシステムを扱い、内部通信が行われるため
- 少人数のSREチームでKubernetesクラスタを運用しており、運用負荷や改善の横展開を容易にするため
しかし、EKSを導入して間もないWEARでは、極端にマルチテナントに振り切らず、ユーザーへの影響度という観点で分離しました。
- ワークフロー基盤を中心とするクラスタ
- Railsアプリケーションを中心とするクラスタ
ワークフロー基盤を中心とするクラスタは、一部のシステムが停止した場合に直ちに影響があるわけではありません。一方で、Railsアプリケーションを中心とするクラスタは、停止してしまうとコーデを閲覧できなどサービスを提供する上でユーザーに影響を及ぼします。
さらに、Railsアプリケーションを中心とするクラスタは、それぞれのシステムが内部通信する場合を想定できます。同じクラスタ内で管理することは余計な認証処理を実装する必要がなくなる実装上のメリットもあります。
このように、サービスレベルに応じてEKSクラスタを分離することで、 バージョン更新などの運用による影響範囲を縮小できます。 さらに、システムが拡大してもEKSクラスタの数が増えないので、運用負荷が上がることはなく改善のスピードも落ちません。
デプロイ
続いてKubernetesの導入に伴うデプロイパイプラインのリプレイスについて紹介します。
WEARではRailsアプリケーションをモノレポで管理しています。
新たな環境では、開発者がRailsアプリケーションのリポジトリへPull Requestを送り、変更が適用されるとGitHub Actionsのワークフローが起動します。
ワークフローは2つのステップになっています。まずArgo CDがSyncするリポジトリのDockerイメージタグを書き換えます。次にSync先のリポジトリが変更されるとArgo CDが変更内容を検知しEKSへデプロイを行います。
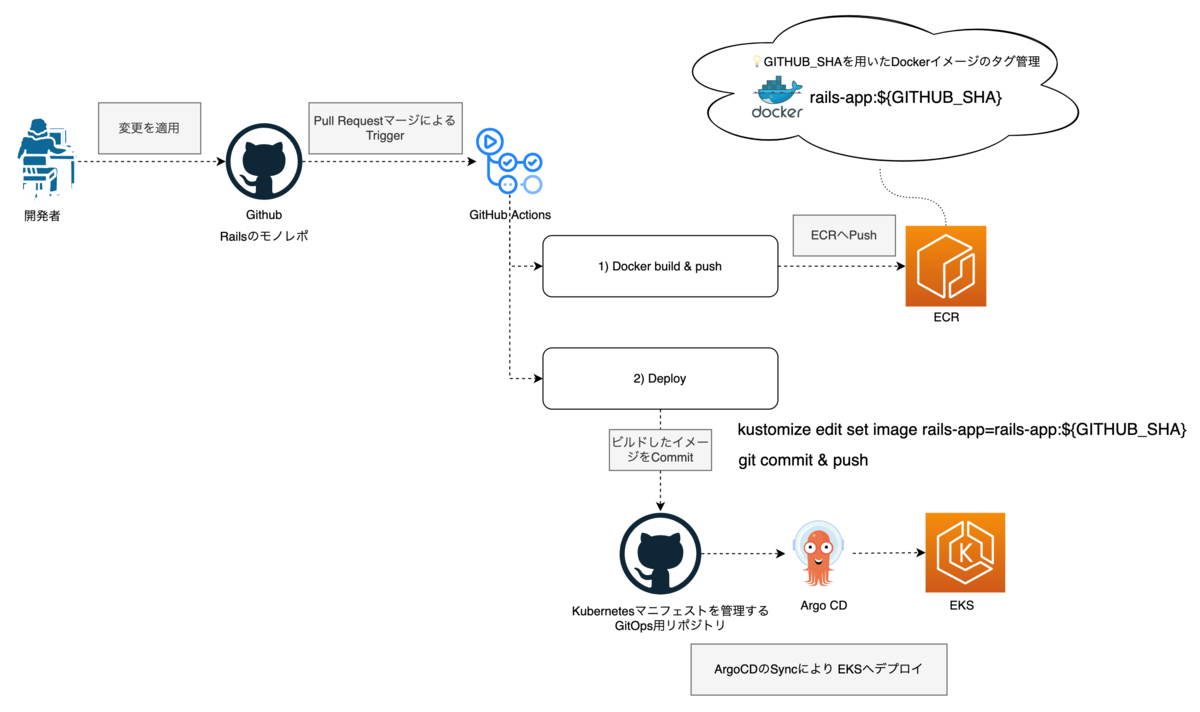
GitHub Actionsにおける最初のステップではDockerイメージをビルドしECRへプッシュします。このとき、GitのコミットハッシュをDockerイメージのタグに登録します。こうすることでコミットごとにユニークなタグを管理できます。
次のステップはGitOps用のリポジトリを取り込み、新たにビルドしたイメージのタグに書き換えます。
Kustomizeではkustomization.yamlというファイルのnewTagでDeploymentに適用するイメージタグを保持しています。
kustomizeの設定は以下です。
apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization resources: - ../../base patchesStrategicMerge: - deployment.yaml images: - name: rails-app newName: rails-app newTag: a3bc8c6fa529fcc64ae6f51dd6133521a28c7468
GitHub ActionsでnewTagを変更する処理は以下です。
$ cd ./path/to/overlays/ $ kustomize edit set image ${IMAGE_URI}=${IMAGE_URI}:${GITHUB_SHA}
このようにすると新しいイメージタグがkustomization.yamlに適用されるので、リモートリポジトリをGitのコマンドを用いて変更します。
また、デプロイ時に行うGitOps用のリポジトリへの変更は、ロールバックにも応用できます10。デプロイ前に格納したイメージタグを取得し、newTagを変更するだけです。

工夫した点
Digdag WorkerにおけるConfigMapの動的管理
RailsのRakeタスクなどを動かすワークフローは、Digdagの機能であるCommand Excecuter11を用いて実現しています。 Digdag WorkerのPodに格納されているKubernetesマニフェストをkube-jobというツールを用いて実行します。この辺の細かい設計は@calorieが考えてくれました。 詳細はKubernetes上でDigdagとEmbulkを動かすワークフロー基盤に記載してあります。
ここでは、しばらく運用してから発生した課題に触れたいと思います。
Digdag Worker内で保持するマニフェストはConfigMapで生成しており、Pod起動時にマウントすることで参照が可能になります。
ConfigMapでファイルを生成するにはdataを用います。
apiVersion: v1 kind: ConfigMap metadata: name: sample-batch data: task.yaml: |+ apiVersion: batch/v1 kind: Job (省略)
当初は課題に感じなかったのですが、yamlのシンタックスの不備やマニフェストとして正しいかを検知できず、誤った内容でリリースしてしまう可能性がありました。 開発者もKubernetes secretや起動コマンドの調整などの変更を加える機会が多く、なるべく管理しやすい方法を模索しました。
この問題を解決するために、KustomizeのconfigMapGenerator12を採用しました。 configMapGeneratorは名前とファイルを指定することで、動的にConfigMapを生成してくれます。
続いてはその方法です。/config内にファイルを配置しています。
このtask.yamlは上述のConfigMapにおけるdata内で記載したマニフェストがそのまま格納されています。
└── base
├── config
│ └── task.yaml # `configMapGenerator`で指定するファイル
├── deployment.yaml
└── kustomization.yaml
次にconfigMapGeneratorにファイルパスを指定します。
また、Argo CDのSyncを前提としているためConfigMapを再作成するようにgeneratorOptionsを設定しています13。
apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization resources: - deployment.yaml configMapGenerator: - name: batch-sample files: - ./config/task.yaml generatorOptions: annotations: argocd.argoproj.io/compare-options: IgnoreExtraneous # Argo CDでSync時に更新を行うために必要
DeploymentにはconfigMapGeneratorで指定した名前を記述します。
apiVersion: apps/v1 kind: Deployment metadata: name: digdag-worker spec: template: spec: volumes: - name: batch-sample-volume configMap: name: batch-sample # configMapGenerator.nameと同様 containers: - name: digdag-worker volumeMounts: - name: batch-sample-volume mountPath: /sample
このように設定した後に、kustomize buildを実行すると動的にConfigMapが生成されます。
apiVersion: apps/v1 kind: Deployment # (省略) volumes: - configMap: name: batch-sample-ccfh9mc2t6 # ハッシュ付きでConfigMapを読み込んでいる name: batch-sample-volume
batch-sample-ccfh9mc2t6というConfigMapが動的に生成され、Deploymentにも反映されています。
Push通知におけるリアルタイム性を意識した構成
Railsアプリケーションを中心とするEKSクラスタの最初の移行対象としてプッシュ通知を扱うシステムを選定しました。
冒頭の構成図では省略しましたが、以下のようになっています。
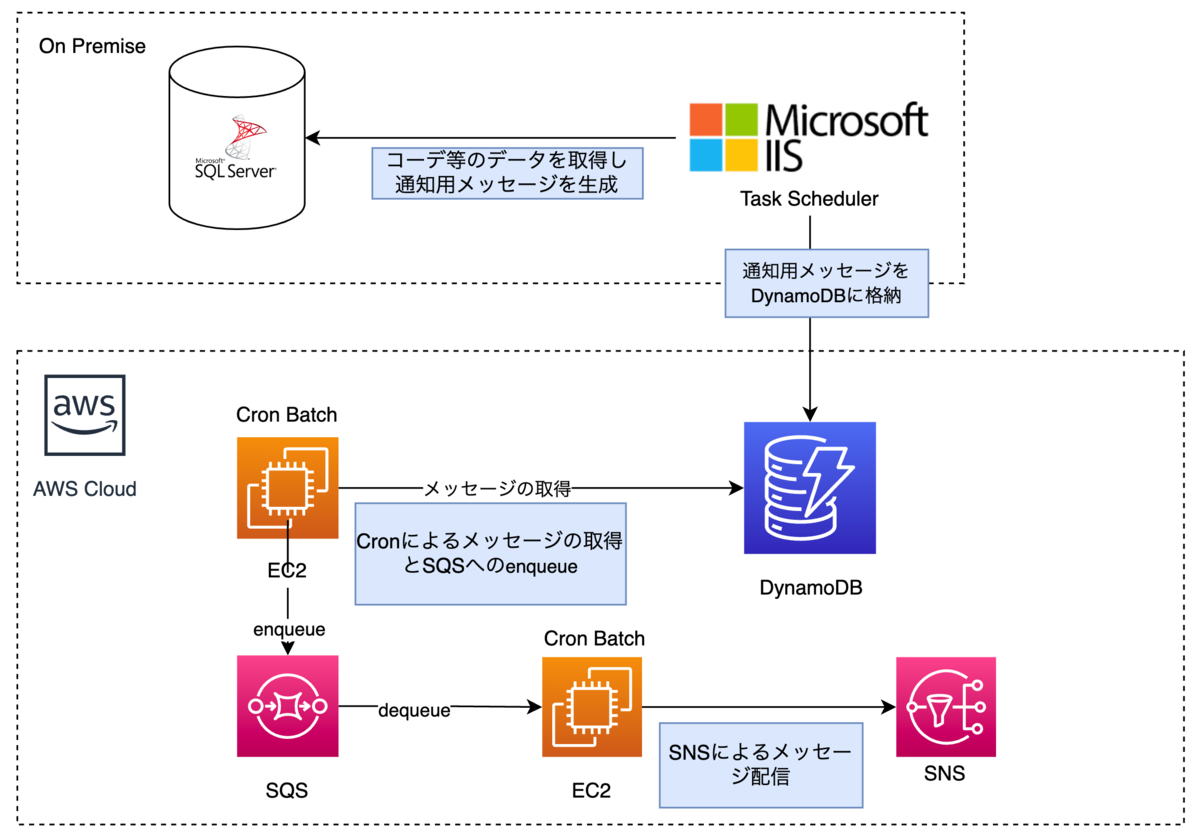
プッシュ通知を扱うシステムは非常に古く、当時運用が活発だった頃のドキュメントが少ないため、運用負荷が高い状態でした。 また、サービスの成長に伴い配信する通知の量が増加し、細かい部分に改善を加える必要がありました。そのためSidekiq14へリプレイスすることになりました。 ここではSREとバックエンド両チームで工夫してきたことをご紹介します。
WEARで扱う通知は大まかにリアルタイム性が重要かそうでないものに分類できます。
それらを分類してピッチコントロールできるように、以下のような構成にしました。

今後は新規の機能追加に通知が伴う場合、キューを分けるべきかを案件の特性に合わせて決めることができます。現状の負荷と照らし合わせて、HPA等の細かいチューニングを行うことができるはずです。 また、頻繁にスケールすることが想定されているのでヘルスチェックやGraceful Shutdownにも対応しました15。
振り返り
運用負荷が下がり積極的な改善に集中できる体質に
OpsWorksの運用負荷は高い状態でした。具体的な運用として以下のようなものがありました。
- メンバー異動時のOpsWorks Stacks Usersの管理16
- OpsWorksで管理するEC2インスタンスの台数やオートスケールの見直し
- インスタンス内で動作するミドルウェアの運用(Chefのcookbookの調整)
- EC2インスタンス内で実行するDigdagジョブのインフラ起因のトラブルシューティング(OOMなど)
切り替えは2022年2月に行いました。下のグラフが示す通り、2021年8月と約8倍ジョブが実行されていることがわかります。
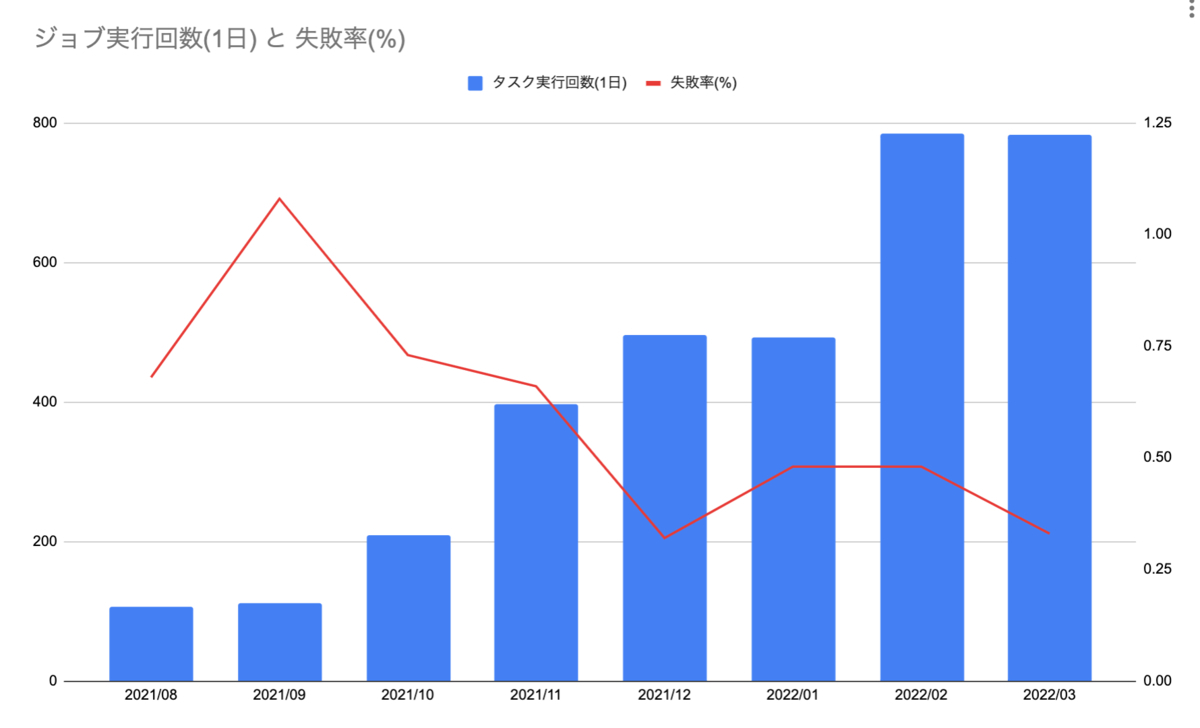
またDigdag Workerとジョブのインフラが切り離されたことで、実行回数が増えても失敗率を減少傾向に止めることができました。 もちろん今後も個別のジョブがメモリ不足により落ちるケースは想定できます。そういった場合はKubernetesマニフェストを修正して対応すれば良く、これまでのようにインスタンス自体のキャパシティに引きずられることはありません。
さらに、ジョブ全体の停止につながる障害も2022年2月以降は発生しなくなりました。

リプレイス前は、月に1件以上インスタンスがOpsWorksのLayerに紐づかなくなる障害が発生していました。

 このようにOpsWorksのLayerにプロセスが存在しない場合を検知しています。構成管理の設定が原因で起動できず、調査や復旧に時間を割いていました。
このようにOpsWorksのLayerにプロセスが存在しない場合を検知しています。構成管理の設定が原因で起動できず、調査や復旧に時間を割いていました。
運用負荷が下がったことで、本記事で紹介してきたような改善に集中できました。
継続的に改善に取り組むことが大事
Kubernetesを導入した目的はその拡張性を活かして現行のシステム課題を大きな枠組みで捉え直し、サービスを運営する上で発生する様々な問題を継続的に改善することにあります。プロジェクト発足時の計画に捉われすぎず、解決策や課題を共有し合う取り組みが重要です。
SREチームでは、本記事で取り上げたKubernetesへのリプレイスプロジェクト以外にもさまざまな活動を行なっています。 リプレイスを行う主担当だけでなく、チーム全員がKubernetesによる改善を行えるように「運用改善」という取り組みを始めました。 これは、キャッチアップや日々の学習で得た知識や課題をアウトプットする場です。週に1度、Kubernetesの新しい技術をモブプロで検証してみたり、日々の運用で感じた課題に取り組み結果を共有しあうというものです。
上に挙げたconfigMapGeneratorもこの取り組みの中で実施しました。既に半年ぐらいこの活動をやっていますが、今ではKubernetesに限らずさまざまなことが議論されています。参考までに、運用改善で行った取り組みをいくつか挙げます。
- ローリングアップデートによるKubernetesバージョンの更新方法の検証
- kube-toolsを利用したkubevalによるマニフェストチェックをCIに導入
- aws-loadbalancer-controllerとCognitoを組み合わせてDigdagやArgo CDのGUIに認証を導入
- Podのログ基盤をS3、Athenaへ統一
- Prometheusとpostgres_exporterを導入しDigdagのキューサイズに応じてスケールするHPAを導入
- GitHub ActionsとAWS間の認証をOIDCへ統一
- GitHub Runnerを活用し
digdag pushなどの内部通信をKubeDNSへ置き換える - ECRにPrivate Linkを導入してNAT Gatewayのコストを削減
今後の展望
アプリケーションの段階的な移行
引き続きECSクラスタを移行していきます。 残りのECSクラスタで稼働するシステムは既に移行を終えたRailsアプリケーションと同じであり、起動方法を変更すれば良いものがほとんどです。 しかし、移行作業の難易度は低くてもWEARの中心を担うAPIであるため、非機能面での課題や切り替え作業に関して考慮すべき点は増えるはずです。 半期ごとに対象を定め、重要度が低いシステムから順次移行します。
サービスに寄り添う継続的な改善
移行と並行しながら改善を進めることができたのはチーム全員が改善を楽しみながらアイデアを出し合い積極的に取り組んでくれたからです。 今後もKubernetesに限らずですが、運用改善やモブプロをはじめとしたチームでの取り組みを継続する予定です。
おわりに
クラスタの構築方針やGitOpsの採用など土台となる部分を整備しつつ、設計の見直しが必要であるワークフロー基盤やPush通知の移行を終えることができました。 Kubernetesやその周辺の技術は変化が激しいので、当初は最善と思えてもあっという間に新しい方法が出てきます。そういった変化を楽しみつつ、より良いサービスにしていきます!
WEARでは一緒にサービスを改善してくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
https://hrmos.co/pages/zozo/jobs/0000021hrmos.co
- AWS OpsWorks | Deploying Apps↩
- 詳細はcircleci|環境変数の使用を参照してください。↩
- AWS Systems Manager Parameter Store↩
- GitOps | What is GitOps?↩
- wearveworks | Guide To GitOps↩
- 詳細はArgo CDを参照してください。↩
- 現在ではv1はmaintenance modeとなっており、v2であるflux2を参照してください。↩
- 詳細はjenkins-xを参照してください。↩
- App Of Apps Pattern↩
- Argo CDにはGUIやCLI上で1つ前のrevisionに戻す機能があるものの、緊急時の場合でも普段から行なっている手法で対処できる方が良いと判断しました。↩
- Digdag|Command Executor↩
- Declarative Management of Kubernetes Objects Using Kustomize|Generating Resources↩
- Configmapが差分として検知されることでSyncに失敗する事象が発生しました。Argo CDのSync時の挙動を制御するためのアノテーションを設定しました。詳細はIgnoring Resources That Are Extraneousに記載されています。↩
- Sidekiq↩
- sidekiqはバージョン6以前とそれ以降でGraceful Shutdownの手法が異なっており、詳細をこちらにまとめました。↩
- Managing AWS OpsWorks Stacks Users↩