



こんにちは、MLデータ部データ基盤ブロックの奥山(@pokoyakazan)です。趣味の範疇ですが、「ぽこやかざん」という名前でラジオ投稿や大喜利の大会に出たり、「下町モルモット」というコンビで週末に漫才をしたりしています。私は普段、全社データ基盤の開発・運用を担当しており、このデータ基盤はGCPのBigQuery上に構築されています。そして、データ基盤内の各テーブルは、大きく分けて以下の2種類に分類されます。
- システムDBのデータやログデータなどが、特に加工されることなく連携されている一次テーブル
- 一次テーブルから必要なデータを使いやすい形に集計したデータマート
本記事では、後者のデータマートを集計するジョブを制御するワークフローエンジンを、DigdagからCloud Composerに移行した事例について紹介します。Cloud Composerとは、GCPにてApache Airflowをマネージドに提供するサービスです。
なお、本記事では、Cloud Composer・Apache Airflowそれぞれのバージョンは以下のものとして話を進めます。
- Cloud Composer:
composer-2.0.24-airflow-2.2.5 - Apache Airflow:
2.2.5
そのため、記事内で参考情報リンクとして貼っている公式ドキュメントについても、こちらのバージョンのものとなります。
目次
- 目次
- データマート集計ジョブの仕組み
- 各データマートの依存関係について
- 移行前のシステムのデータマート集計方法
- データマート集計ジョブの課題
- DigdagからCloud Composer(Airflow)への移行
- Cloud Composer移行によって得られた効果
- Cloud Composerの運用Tips
- まとめ
データマート集計ジョブの仕組み
以下の記事でもご紹介した通り、マート集計処理の実体はデータ基盤利用者が作成したSQLファイルで、全てGitHubで管理されています。
SQLファイルにはSELECT文のみが記述されており、UPDATEやDELETEといったDMLは記載されていません。
各データマートの依存関係について
あるマートが他のマートを参照している(依存関係がある)場合、集計の順番を間違えるとデータに不整合が発生してしまいます。例えば、existing_table1, existing_table2という一次テーブルが存在するとし、以下のような集計クエリを持つ5つのマートを構築したい場合を考えます。
table1.sql
SELECT * FROM `project.dataset.existing_table1`;
table2.sql
SELECT * FROM `project.dataset.existing_table2`;
table3.sql
SELECT * FROM `project.dataset.table2`;
table4.sql
SELECT * FROM `project.dataset.table1` UNION ALL SELECT * FROM `project.dataset.table3`;
table5.sql
SELECT * FROM `project.dataset.table3`;
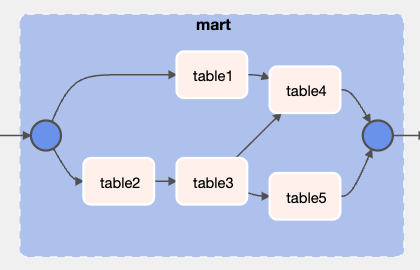
この場合、「table3の前にtable2」「table4の前にtable1とtable3」「table5の前にtable3」が集計されている必要があります。
移行前のシステムのデータマート集計方法
Digdagでマート集計する場合、以下の流れで行います。
- 各マートのSQLファイルからマート間の依存関係グラフの作成
- 並列に処理しても問題ないマートをまとめた集計グループを作成
- 各集計グループごとにマート集計を並列実行
各マートのSQLファイルからマート間の依存関係グラフの作成
マート間の依存関係は、各マートのSQLファイル内の、FROMもしくはJOINの直後にくるマート(自己参照は除く)を調べるとわかります。FROM, JOINの後ろに書かれているマートは、SQLを実行するマートよりも前に集計しなければなりません。そのため、「FROM, JOINの後ろのマート」→「SQLを実行するマート」というように依存関係グラフを作成していきます。例えば、上記の5つのSQLからマート間の依存関係グラフを作成すると以下のようになります。
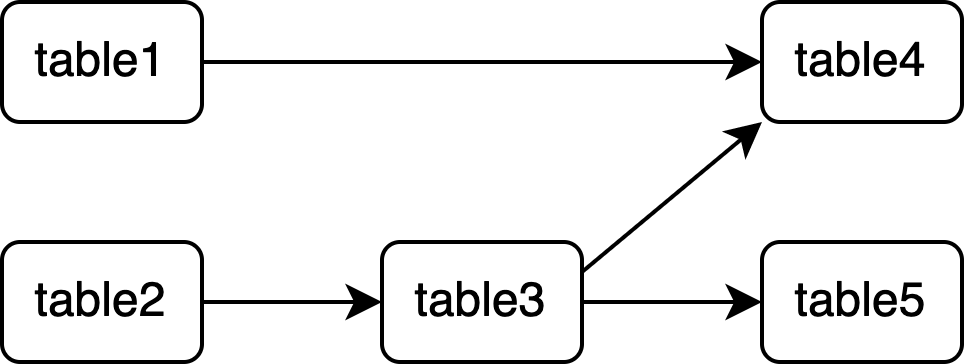
これをPythonコードで実装していきます。まず、各マートのSQLファイルから以下の正規表現を使って参照先となるマートを抽出します。
(?i)(?<=FROM|JOIN)[\s \n]*`(.+?)`
そして、参照元: 参照先という形のDictを作成します。
{
'table1': [], # table1の依存先
'table2': [], # table2の依存先
'table3': ['table2'], # table3の依存先
'table4': ['table1', 'table3'], # table4の依存先
'table5': ['table3'] # table5の依存先
}
並列に処理しても問題ないマートをまとめた集計グループを作成
作成した依存関係グラフを利用し、マートの集計順序を担保したまま、可能な限り処理を並列化していきます。具体的には、並列実行しても問題のないマート同士をグループ化します。まず、親ノードがないマート群をリストに追加し、追加したマートをグラフから削除します。そして、もう一度親ノードがないマート群をリストに追加し、追加したマートをグラフから削除…というのを繰り返していきます。
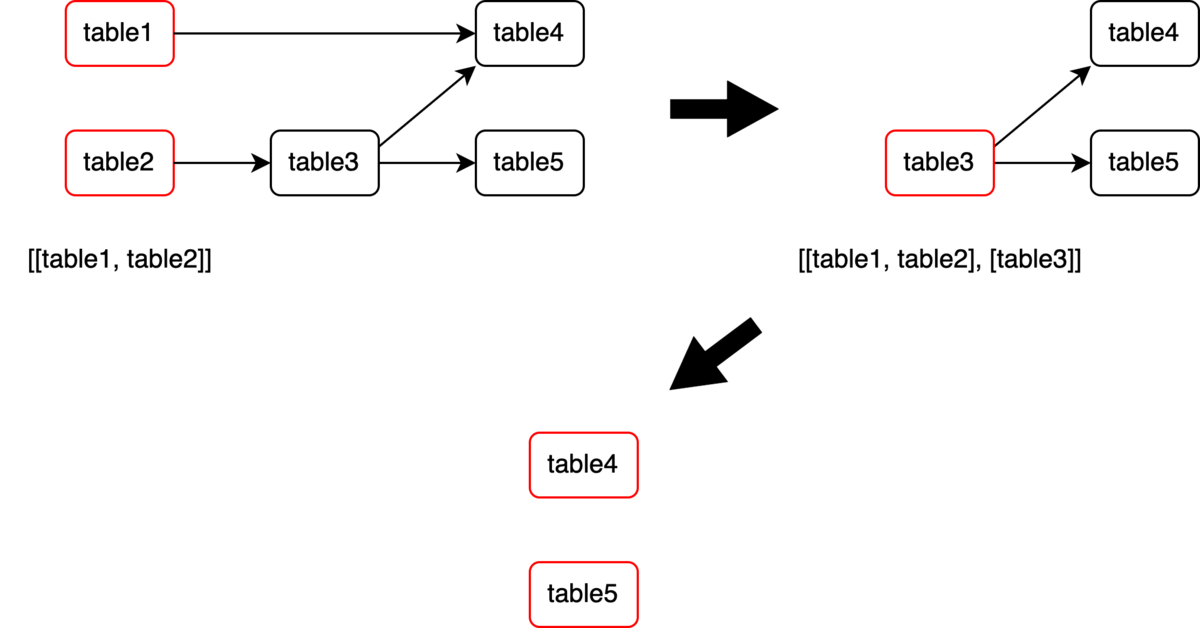
結果として、以下のような集計グループのリストができあがります。
[[table1, table2], [table3], [table4, table5]]
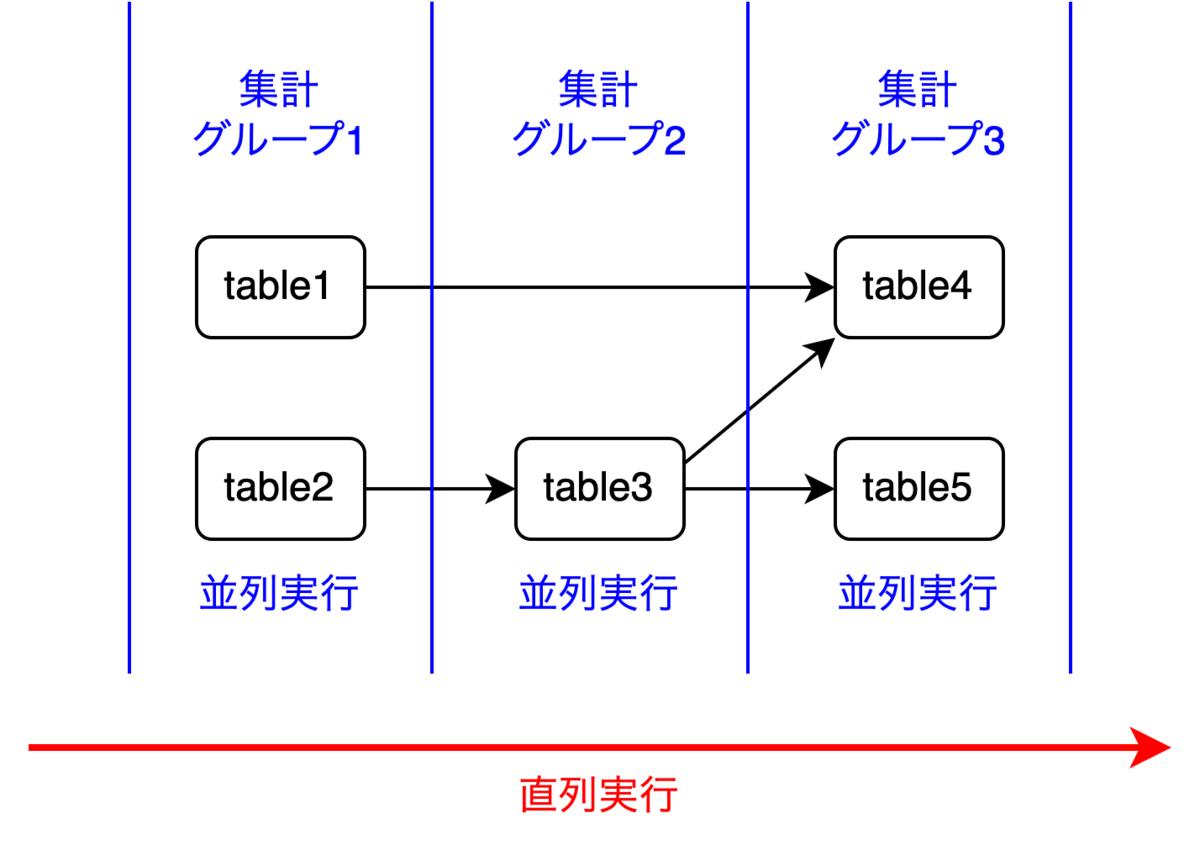
各集計グループごとにマート集計を並列実行
各集計グループ(マートのリスト)は、リストの先頭から順番に実行可能で、同じ集計グループ内のマートの集計は並列化できます。結果として、集計の流れは以下のようになります。
[table1, table2]を並列実行[table3]を実行[table4, table5]を並列実行
データマート集計ジョブの課題
上記の方法で集計すると、依存関係に沿った集計順序が担保され、同じ集計グループ内では処理を並列化できます。ただし、この方法にはいくつか課題も存在します。
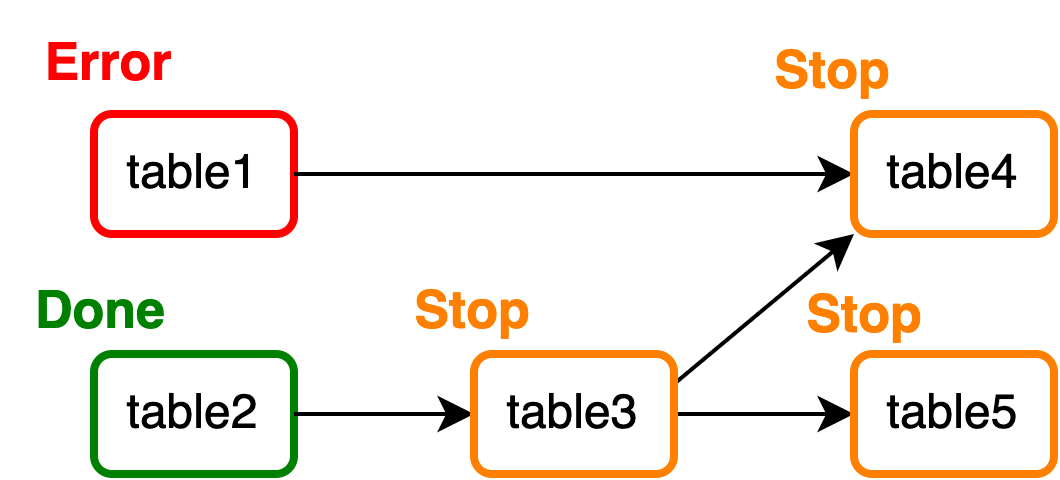
1つのマートの集計が失敗すると後続のグループに属する全てのマートの集計が停止する
あるマートの集計ジョブがエラー終了した場合、このマートと同じ集計グループに属するマートについては、処理が並列化されているため影響を受けません。しかし、失敗したマートが属する集計グループより後のグループは、全て処理が停止してしまいます。例えば、table1の集計がこけた場合、以下のようになります。
[table1, table2]→table2は実行される[table3]→ 実行されない[table4, table5]→ 実行されない
集計グループ単位で見ると、先頭の集計グループの処理が失敗しているので、2番目と3番目の集計グループの処理は開始されません。そのため、table1に依存しないtable[3, 5]の集計は実行されてほしいところですが、これらのマートの集計も停止してしまいます。
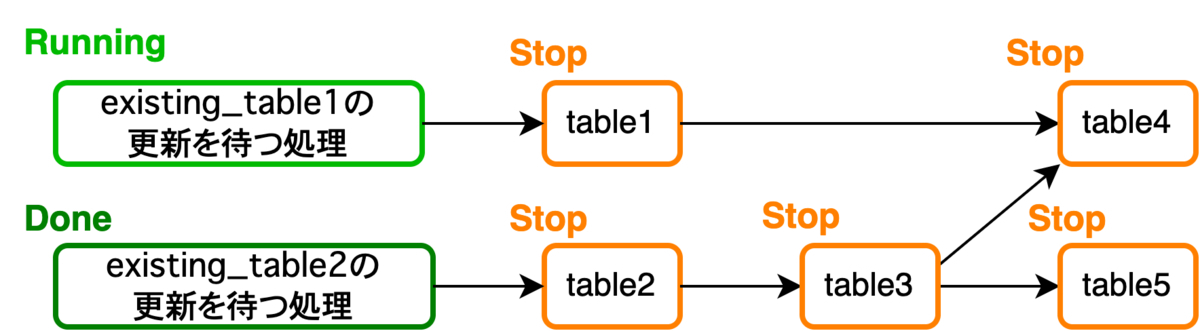
一次テーブルの更新遅延がデータマート集計全体の遅延に繋がる
データマートは、一次テーブルから必要なデータを使いやすい形に加工し抽出したテーブルです。そのため、一次テーブルが更新される前に、一次テーブルを参照しているマートの集計が行われるとデータの不整合が発生します。そこで、一次テーブルを参照するマートは、一次テーブルが正常に更新されるまで集計開始を待つ必要があります。さらに、集計グループ内の1つのマートのみ集計を停止させることはできないため、その場合は集計グループ自体の実行を停止(グループ内の全マートの集計を停止)させる必要があります。つまり、なんらかの理由で一次テーブルの更新が失敗・遅延すると、この一次テーブルを参照するマートが属する集計グループ内全てのマートの集計タスクが実行されません。また、一次テーブルに依存するマートの集計タスクは先頭の集計グループに属することが多いため、一次テーブルの更新遅延はマート集計ジョブ全体の大幅な遅延に繋がります。例えば、一次テーブルexisting_table1の更新が遅延している場合、以下のようになります。
[table1, table2]→ 実行されず待機[table3]→ 実行されず待機[table4, table5]→ 実行されず待機
集計グループ単位で見ると、先頭の集計グループの処理が開始されないため、2番目と3番目の集計グループの処理も開始されません。そのため、existing_table1に依存しないtable[2, 3, 5]の集計は実行されてほしいところですが、これらのマートの集計も停止してしまいます。
集計グループの増加に伴いデータマート集計ジョブの実行時間が長くなる
現在、データマートの数は900を超えており、今も日々増え続けています。さらに、各マートは複雑に依存しあっているため、マート数の増加に伴い集計グループが増えることもあります。各集計グループごとの処理は直列に実行されるため、集計グループが増加すると、マート集計ジョブ全体の実行時間も一気に増加してしまいます。
DigdagからCloud Composer(Airflow)への移行
移行の契機
Digdagではあるマートの集計が失敗した場合、失敗した集計クエリの修正対応などを行った後に、停止していた集計グループからジョブをリトライします(RETRY FAILED)。そして、リトライしたジョブの完了時間と、エラーが発生しなかった場合の普段のジョブ完了時間との差分が遅延時間となります。マート数が少ないうちは、Digdagでも特に遅延時間が大きくなることはありませんでした。むしろ、DAG(Directed Acyclic Graph)と呼ばれるタスク間に依存関係があるジョブを、YAML書式で簡潔に定義できる点でDigdagは非常に優れています。しかし、マート数が1000近くにまで増えたため、エラーが発生した際の遅延時間がとても大きくなり、上記課題の解決が急務となりました。これらの課題は、マート1つ1つに対して依存関係を定義して集計グループを作らずに集計順序を制御できれば解決が可能ですが、現状Digdagではこういった柔軟な依存関係の定義が難しいです。そこで、より柔軟にタスク間の依存関係を定義できるAirflowへの移行を検討し始めました。Airflowを実行するインフラについては、データ基盤がGCPにあるため、他GCPサービスとの連携のしやすさを考慮しCloud Composerを利用することにしました。マネージドサービスを利用することにより、運用負荷を低減することも狙いの1つです。
Airflowでのデータマート集計方法
Airflowでも、DAGと呼ばれるジョブに、タスクと呼ばれる実際の処理の内容を定義していきます。さらに、タスクの実行設定・タスク間の依存関係を追加で設定していくことで、あとはAirflow Schedulerが設定に従ってDAGを実行してくれます。実際にマート集計DAGを記述していきます。
タスクの定義
こちらのPythonコードは、毎日7:00に実行されるマート集計DAGの一部です。
import pendulum from airflow import DAG from airflow.operators.python import PythonOperator from airflow.utils.task_group import TaskGroup def _update_datamart(**kwargs): datamart_id = kwargs['datamart_id'] ''' データマート更新処理 ''' with DAG( dag_id='dailybatch_datamart', start_date=pendulum.datetime(2023, 1, 1, 7, 0, tz='Asia/Tokyo'), schedule_interval='0 7 * * *', catchup=False, ) as dag: datamart_ids = [ 'table1', 'table2', 'table3', 'table4', 'table5', ] with TaskGroup(group_id='mart') as mart: for datamart_id in datamart_ids: globals()[datamart_id] = PythonOperator( task_id=datamart_id, on_failure_callback=_failure_notify, python_callable=_update_datamart, op_kwargs={'datamart_id': datamart_id}, )
datamart_idsというマート名が格納されたリストを作成し、ループで回してタスクを定義しています。マート更新処理(SQLの実行)は、全マート共通のため、全タスクで同じ関数_update_datamartを呼び出しています(※on_failure_callbackについては後述)。
タスク間の依存関係の設定
タスク定義の次は、タスク間の依存関係を設定していきます。こちらは上記「移行前のシステムのデータマート集計方法」内の「各マートのSQLファイルからマート間の依存関係グラフの作成」までは同じ手順となります。Airflowではタスク間の依存関係を>>で定義するため、正規表現を使ってSQLファイルから参照先のマートを抽出した後に、依存関係を以下のような文字列型で定義します。
'table1 >> table4'
そしてこの文字列を2次元配列に格納していきます。
datamart_dependencies = [
[], # table1の依存先
[], # table2の依存先
['table2 >> table3'], # table3の依存先
[
'table3 >> table4', # table4の依存先
'table1 >> table4', # table4の依存先
],
]
最終的に、データマート集計DAGは以下のようになります(※on_failure_callbackについては後述)。
import pendulum from airflow import DAG from airflow.operators.python import PythonOperator from airflow.utils.task_group import TaskGroup def _update_datamart(**kwargs): datamart_id = kwargs['datamart_id'] ''' データマート更新処理 ''' with DAG( dag_id='dailybatch_datamart', start_date=pendulum.datetime(2023, 1, 1, 7, 0, tz='Asia/Tokyo'), schedule_interval='0 7 * * *', catchup=False, ) as dag: datamart_ids = [ 'table1', 'table2', 'table3', 'table4', 'table5', ] with TaskGroup(group_id='mart') as mart: for datamart_id in datamart_ids: globals()[datamart_id] = PythonOperator( task_id=datamart_id, on_failure_callback=_failure_notify, python_callable=_update_datamart, op_kwargs={'datamart_id': datamart_id}, ) # タスク間の依存関係の設定 for dependenies_of_one_mart in datamart_dependencies: for dependency in dependenies_of_one_mart: eval(dependency) other_task1 >> mart >> other_task2
また、AirflowのWeb UI上から確認できるタスク間の依存関係グラフは以下のようになります。
一次テーブルの更新待ち処理追加
Airflowを使うことで、一次テーブルが更新途中であっても「一次テーブルに依存するマートのみ待機し、依存しないマートについては影響を受けることなく集計を進める」といったことが可能になりました。これにより、一次テーブルの更新遅延がマート集計ジョブ全体の遅延に繋がる問題を解決できます。具体的には、まず一次テーブルの更新を待機する「更新待ちタスク」を定義します。更新待ちタスクは、existing_table[1, 2]の更新時間チェックを行うBigQueryのクエリを実行し続け、更新されていることが確認できたらタスクを完了させるような内容にしています。そして、一次テーブルを参照するマートの集計タスクが、この更新待ちタスクの後にくるよう依存関係を設定します。
[
['wait_existing_table1 >> table1'],
['wait_existing_table2 >> table2'],
]
結果として、AirflowのWeb UI上から確認できるタスク間の依存関係グラフはこのようになります。
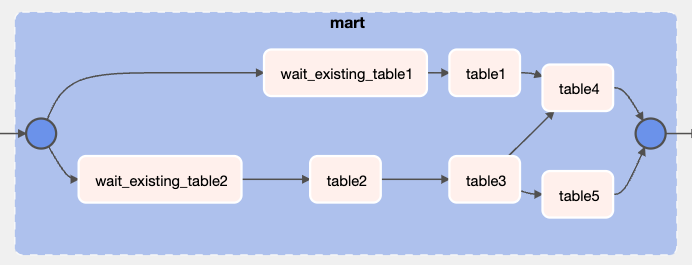
これにより、一次テーブルの更新遅延による影響を極限まで小さくできました。
Cloud Composer移行によって得られた効果
Composer(Airflow)に移行することで、タスク間の依存関係を柔軟に設定できるようになりました。結果として、あるマートの集計でエラーが発生しても、そのマートと依存関係のないマートは影響を受けずに集計を進められるようになりました。例えば、table1の集計がエラー終了した場合、table1を参照するtable4のみ集計がストップし、他のtable[2, 3, 5]については影響を受けることなく集計が行われます。
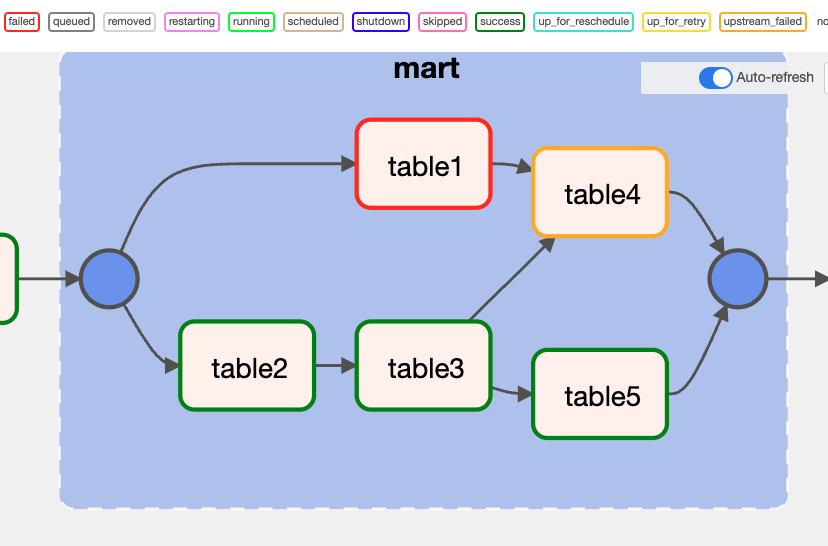
さらに、一次テーブルの更新待ちタスクを定義し、一次テーブルを参照するマートの集計タスクとの依存関係を設定しました。結果として、一次テーブルに依存するマートのみ更新を待ち、それ以外のマートは一次テーブルの更新タイミングに影響されることなく集計を進められるようになりました。例えば、existing_table1の更新処理が遅延し完了していない場合、table1とtable4のみ更新を待ち、他のtable[2, 3, 5]については影響を受けることなく集計が行われます。

また、以下の記事で紹介した通り、DigdagではAWSのEC2インスタンス・Aurora DBを組み合わせてマート集計基盤を構築していました。
対して、ComposerではAirflowの環境クラスタがGKEのAutopilotモードによってマネージドに構築されるため、インフラ管理の運用負荷を下げることができました。
Cloud Composerの運用Tips
最後に、タスクの依存関係とは関係ありませんが、Composerを運用していくにあたって得た知見を記載します。Composerを運用するにあたっての参考になれば幸いです。
Tips1: メタデータの読み込み方法は「読み込まれるタイミング」によって使い分ける
Airflowには、DAGの実行中に読み込みたいメタデータを、key/valueの形で、AirflowのメタデータDBに保存しておくことができるVariablesという機能があります。DAG内に直接記載したくない機密情報、アクセス情報などをVariablesに保存しておき、実行中のタスクから読み込むといったことが可能です。しかし、このVariablesは「読み込まれるタイミング」に注意して利用する必要があります。
SchedulerによるDAG解析
Variablesの注意点の前に、Airflowのアーキテクチャについて触れておきます。Airflowのアーキテクチャは、以下のコンポーネントから成り立っています。
- ジョブ実行のスケジュールを管理する
Scheduler - ジョブを実際に実行する
Worker - Web UIを提供する
Web Server
ここで重要なのが、SchedulerがDAGファイル(Pythonコード)の解析を行い、Workerがタスクを実行するということです。Schedulerには、ジョブ実行のスケジュール管理以外にもDAGs folderと呼ばれるフォルダ内にあるPythonファイルを読み込み、DAGやタスクの設定・依存関係を解析する役割があります。そして、このDAG解析は頻繁(デフォルトでは1分に1度)に行われます。詳細についてはこちらの公式ドキュメントを参照ください。
つまり、Airflow環境で動くコードは以下の2つに大別されます。
Schedulerによって解析されるコード:Top level codeWorkerによって実行されるタスクのコード:Operator内のコード
例として、以下のようなDAGについて考えてみます。
def _task1: ''' task1の処理 ''' def _task2: ''' task2の処理 ''' with DAG( # ~~~ ) as dag: task1 = PythonOperator( task_id='task1', python_callable=_task1, ) task2 = PythonOperator( task_id='task2', python_callable=_task2, ) task1 >> task2
関数_task1, _task2の外のコードは、Schedulerによって解析されるためTop level codeとなります。一方で、関数_task1, _task2内のコードは、Workerが実行するPythonOperatorによってDAG実行時に初めて呼び出されるOperator内のコードとなります。ここでの大事なポイントは、Top level code内でサイズが大きいライブラリのインポートやDB接続といった重たい処理を行うと、DAGの解析時間が著しく遅くなってしまうという点です。
Variablesの読み込みはTop level codeで行わない
VariablesはAirflowのメタデータDBに保存されています。そのため、Top level codeでVariablesを読み込むと、DAG解析の度にSchedulerによるメタデータDBへの接続が作成されます。結果として、DAGの解析が著しく遅くなり、Scheduler全体のパフォーマンスが劣化してしまいます。Composerの検証時、DAGを実行しても、タスクがQueueに停滞して実行されないという問題が発生しました。これは、DAG解析時に読み込んでいるPythonモジュール内に、Variablesを読み込む処理を記述していたことが原因と考えられます。DAGが定義されているPythonファイルだけでなく、DAG解析時に呼び出される処理もTop level codeとなります。そのため、DAG解析時にVariablesの読み込み処理がSchedulerによって行われてしまい、パフォーマンスが劣化していました。Top level code内でメタデータを読み込みたい場合には2つの方法が考えられます。1つ目が、事前に環境変数として定義しておき、以下のようにDAG解析時に取得する方法です。
ENVIRONMENT = os.environ.get('ENVIRONMENT')
2つ目が、メタデータをYAMLファイルなどに保存しておき、DAG解析時に動的に読み込むようにする方法です。これらの方法で、DAG解析にかかる時間を抑えられ、Schedulerのパフォーマンス劣化を防ぐことができます。
メタデータの読み込み方法の使い分け
以上より、メタデータの読み込み方法の方針は以下のようにしました。
Schedulerによって解析されるTop level codeでは、環境変数やYAMLから動的に読み込むWorkerによって実行されるOperator内のコードでは、Variablesから読み込む
具体的には、configディレクトリ配下にdag_parse, variablesという2つのディレクトリを作成し、それぞれにメタデータが記載されたYAMLファイルを配置しています。※実際はprd, stg, dev など環境ごとに設定が分かれるため、ディレクトリ階層はもう一段深くなりますが、ここでは簡略化して記載します。
config
├── dag_parse
│ ├── datamart.yml
│ ├── ...
└── variables
├── database.yml
├── tables.yml
├── gcp.yml
├── ...
Composerでは、環境ごとにGCSバケットを持ち、このバケット内にdags, plugins, dataといったフォルダが配置されています。そして、それぞれのフォルダが、各Airflowコンポーネント(dataはWorkerのみ)のローカル環境と同期されています。
そこで、dag_parse配下のYAMLファイルはGCSバケットのdagsフォルダへアップロードし、DAG解析時に読み込みます。一方、variablesディレクトリ配下のYAMLファイルは、以下の流れでAirflowのVariablesとして登録していきます。
- YAMLをJSONに変換
- 変換したJSONをGCSバケットの
dataフォルダにアップロード dataフォルダと同期されているWorker内のdataフォルダからVariablesを登録
2と3について補足します。Composerでは、以下のコマンドでVariablesを登録できます。
gcloud composer environments run ${Composer環境名} variables -- import ${登録したいJSON}
しかし、この${登録したいJSON}は、Airflowコンポーネントのローカル環境に配置されている必要があります。そこで、GCSバケットのdataフォルダにJSONをアップロードし、Worker内のdataフォルダと同期させてからVariablesとして登録しています。Variables登録箇所のコードはこちらです。
# VARIABLES_YAML_DIR_PATH: config/variablesディレクトリのパス # VARIABLES_JSON_PATH: Variablesに登録するJSON # VARIABLES_YAML_DIR_PATH内のYAMLを1つのJSONに変換 python load_variables_from_yaml.py \ -c ${VARIABLES_YAML_DIR_PATH} \ -o ${VARIABLES_JSON_PATH} # 作成したJSONをGCSのデータフォルダにアップロード gcloud --project ${PROJECT} composer environments storage data import \ --environment ${COMPOSER_ENVIRONMENT} \ --location ${REGION} \ --source=${VARIABLES_JSON_PATH} # データフォルダに置かれたJSONの内容をAirflow Variablesとして登録 gcloud --project ${PROJECT} composer environments run \ ${COMPOSER_ENVIRONMENT} \ --location ${REGION} \ variables -- import /home/airflow/gcs/data/variables.json
load_variables_from_yaml.pyの中身はこちらです。単純にYAML→PythonのDict→JSONの順で変換しているだけです。
import yaml import json import glob import argparse def load_environment_yaml_to_variables(yamls): variables_dict = {} for yaml_path in yamls: with open(yaml_path, 'r') as rf: loaded_variables = yaml.load(rf, Loader=yaml.SafeLoader)[project] variables_dict = dict(**variables_dict, **loaded_variables) return variables_dict if __name__ == '__main__': parser = argparse.ArgumentParser(description='Argument to load variables') parser.add_argument('-c', '--conf', required=True, help='Input config dir path') parser.add_argument('-o', '--output', required=True, help='Output json path') args = parser.parse_args() config_path = args.conf output_path = args.output yamls = glob.glob(f'{config_path}/*.yml') variables_dict = load_environment_yaml_to_variables(yamls) with open(output_path, 'w') as wf: json.dump(variables_dict, wf, indent=2)
上記の全ての処理を、GitHub Actionsから行うことで自動化しています。
Tips2: DAG・タスクのエラーハンドリングは目的に応じてパラメータを使い分ける
各マートの集計タスクがエラー終了した場合、目的に応じて以下2つのエラーハンドリングを行っています。
- 1つでもタスクがエラー終了したら保守担当者に架電
- エラー終了したタスクの分だけSlack通知
1つでもタスクがエラー終了したら保守担当者に架電
マート集計ジョブ自体にエラーが発生した場合、保守担当者へ架電されるようにしています。架電の目的は「問題が起きていることを知らせること」なので、エラー終了したタスクの数によらず架電される回数は1回で十分です。そんな時は、trigger_ruleパラメータを使ったタスクを新たに定義します。デフォルトでは、タスクは上流(upstream)にある全てのタスクが成功しないと実行されません(trigger_rule=all_success)。ただし、このtrigger_ruleパラメータの値を変えることで、タスクの起動条件を変更できます。今回はtrigger_ruleにone_failedを指定することで目的が達成できます。
one_failed: At least one upstream task has failed (does not wait for all upstream tasks to be done)
# 具体的な架電処理はfailure_on_call.shに記述 failure_on_call = BashOperator( task_id='failure_on_call', trigger_rule='one_failed', bash_command='failure_on_call.sh', env={'message': '[ERROR] {{ task_instance.dag_id }}'}, ) other_task1 >> mart >> other_task2 >> failure_on_call
エラー終了したタスクの分だけSlack通知
一方Slack通知に関しては、エラー終了したタスクの分だけ通知が飛ぶようにしました。Slackのメッセージ内容にタスク名、エラー内容、ログへのリンクを載せることで、調査・対応をやりやすくすることが目的です。そんな時は、on_failure_callbackパラメータを使って各マートの集計タスクを定義します。こうすることで、タスクが失敗した際に、on_failure_callbackに指定した関数が呼び出されます。
def _failure_notify(context): ''' Slack通知処理 ''' with DAG( # ~~~ ) as dag: with TaskGroup(group_id='mart') as mart: for datamart_id in datamart_ids: globals()[datamart_id] = PythonOperator( task_id=datamart_id, on_failure_callback=_failure_notify, # タスク失敗時に_failure_notifyを呼び出す python_callable=_update_datamart, op_kwargs={'datamart_id': datamart_id}, )
Tips3: Composer環境自体の外形監視を設定する
DAGのエラーハンドリングを設定することで、DAGの実行中の発生したエラーを検知できるようになりました。しかし、このままではComposerの環境自体に問題が発生し、そもそもDAGが実行されなくなった場合に検知できません。そこで、GCPのCloud Monitoringを使って、Composer環境自体の外型監視を入れています。Composerには、airflow_monitoringという、環境が正常に動作しているかを監視するためのDAGが最初から用意されています。
そのため、このairflow_monitoringが無事動作しているかを監視するAlert PolicyをCloud Monitoringに設定すれば、外型監視が可能となります。外型監視のAlert PolicyはTerraformで作成しており、そのTerraform定義は以下のようにしています。
resource "google_monitoring_alert_policy" "composer_healthy" { display_name = "Cloud Composer Environment Healthy" combiner = "OR" conditions { display_name = "Composer Environment Healthy" condition_threshold { aggregations { alignment_period = "60s" per_series_aligner = "ALIGN_COUNT_TRUE" cross_series_reducer = "REDUCE_SUM" group_by_fields = [ "resource.label.environment_name", ] } comparison = "COMPARISON_LT" duration = "0s" filter = <<EOT resource.type="cloud_composer_environment" AND ( resource.labels.environment_name=${Composer環境名} ) AND metric.type="composer.googleapis.com/environment/healthy" EOT threshold_value = 1 trigger { count = 1 percent = 0 } } } documentation { # ~~~ } notification_channels = [ # ~~~ ] }
このように、他のGCPのマネージドサービスと組み合わせることができるのもComposerのメリットです。
Tips4: 集計遅延の検知の仕組み
DAGの実行中のエラー、Composer環境自体のヘルス不良は検知できるようになりました。しかし、まだ「普段3時間で終わるマート集計DAGが6時間経っても終わっていない」といったような、集計遅延は検知できません。そこで、DAGの実行時間のSLAを定め、その時間を超えた場合にアラートを飛ばす仕組みを入れました。具体的には、監視用のDAG(sla_check_dailybatch_datamart)を新たに作成しました。この監視用DAGでは、ExternalTaskSensorを使って、マート集計DAGを監視しています。ExternalTaskSensorを利用するタスクでは、以下のパラメータを指定します。
external_dag_idexternal_task_idallowed_status
そして、external_task_idに指定したタスクの状態がallowed_statusの状態へ遷移すると、ExternalTaskSensorを利用するタスクがSuccessとなります。また、ExternalTaskSensorは、BaseSensorOperatorというクラスを継承したクラスです。BaseSensorOperatorクラスでは、timeoutを設定でき、タスクの実行時間が指定した時間を過ぎるとエラー終了させることが可能です。マート集計DAGでは、全マートの集計完了後にSlack通知をするsuccess_notifyというタスクを定義しています。そこで、ExternalTaskSensorから、このsuccess_notifyタスクを監視し、timeoutパラメータにSLA時間を指定しています。そうすることで、マート集計DAGの実行時間がSLA時間を超えた場合に、ExternalTaskSensorタスクが失敗するようになります。最後に、このExternalTaskSensorタスクが失敗した時に起動しアラートを飛ばすsla_violation_alertタスクを定義することで、集計遅延の検知が可能となります。
CHECK_DAG_ID = 'dailybatch_datamart' CHECK_TASK_ID = 'success_notify' # 対象DAGのSLA違反となる実行時間(秒) SLA_VIOLATION_TIMEOUT = 60 * 60 * 3 def _sla_violation_alert(**kwargs): ''' アラート発報処理 ''' with DAG( # ~~~ ) as dag: sla_check_dailybatch_datamart = ExternalTaskSensor( task_id='sla_check_dailybatch_datamart', external_dag_id=CHECK_DAG_ID, external_task_id=CHECK_TASK_ID, timeout=SLA_VIOLATION_TIMEOUT, allowed_states=['success'], failed_states=['failed', 'skipped'], # poke or reschedule: センサーの待機時間が長いのでスロットを解放するrescheduleを選択 mode="reschedule", ) sla_violation_alert = PythonOperator( task_id='sla_violation_alert', trigger_rule='one_failed', python_callable=_sla_violation_alert, ) sla_check_dailybatch_datamart >> sla_violation_alert
今回はExternalTaskSensorを使う方法を採用しましたが、他に検討した集計遅延の検知方法についても記載します。
採用しなかった方法1: タスクにslaパラメータを指定
Airflowでは、各タスクのSLA時間を、slaパラメータを使って設定できます。
例えば、SLA時間を30秒にしたい場合、以下のようにPythonOperatorの引数にsla=timedelta(seconds=30)を追加します。
def sla_callback(): ''' SLA違反の際の処理 ''' with DAG( # ~~~ ) as dag: task = PythonOperator( task_id='task', pythonc_collable=_collable, sla=timedelta(seconds=30), sla_miss_callback=sla_callback, )
すると、30秒以上タスクが実行されるとSLA違反となり、sla_miss_callbackに設定している関数sla_callbackが呼び出されます。最後に設定したsla_callback内からSlack通知なり架電を行うことで、集計遅延を検知できます。しかし、slaパラメータによるSLA違反のチェックタイミングは、SLA違反したタスクの次のタスクの実行前です。そのため、遅延しているマート集計タスクが実行中の間(完了しない限り)は、遅延を検知できません。遅延しているタスクが実行中であっても、即座に遅延を検知したかったため、このslaパラメータとsla_miss_callbackを組み合わせる方法は見送りました。
採用しなかった方法2: DAG・タスクのいずれかにタイムアウト値を設定
Airflowでは、DAG・タスクそれぞれに対してdagrun_timeout・execution_timeoutといったパラメータを指定することで、実行時間のタイムアウト値を設定できます。
これらのパラメータを使うと、指定した時間内にDAGまたはタスクが終わらなかった場合、強制的にエラー終了させられます。しかし、今回は集計遅延の検知さえできれば良く、実行中のタスクを強制的にエラー終了させる必要はありませんでした。また、集計遅延の原因はBigQueryジョブに時間がかかっているケースがほとんどです。遅延しているマートの集計クエリの調査・BigQueryジョブのプロファイリングを行った上で、タスクを実行させたままにするか、エラー終了させるかを運用者側で判断したいという要望もありました。そのため、このdagrun_timeout・execution_timeoutを使う方法も見送りました。
Tips5: プライベートIP環境で構築
公共ネットワークや外部サービスからComposer環境(GKEクラスタ)へインバウンドアクセスする用途はなかったため、よりセキュアなプライベートIP環境としてComposer環境を構築しました。また、Cloud NATを利用することで、外部からはアクセスできないが、外部へはアクセスできるようにしています。構築手順は以下の公式ドキュメントに沿って行っています(詳細は割愛します)。
まとめ
データマートの集計ジョブを制御するワークフローエンジンを、DigdagからCloud Composerに移行した事例について紹介しました。移行により、タスク間の依存関係を柔軟に設定できるようになり、1つのマートの集計エラーがマート集計ジョブ全体に及ぼす影響を小さくできました。ZOZOでは、一緒にデータ基盤を作ってくれる方を大募集しています。ご興味がある方は以下のリンクから是非ご応募ください!