



初めまして。MLデータ部データ基盤ブロックの小泉です。
本記事ではGartner社から提唱されたActive Metadata Managementに着目し、BigQueryのCompute費用を削減した方法についてご紹介します。
目次
- 目次
- Active Metadata Managementとは
- 結局どんなことを行なったのか、ざっくりまとめ
- Compute費用のpricing modelとReservationについて
- Metadataを使用して最安値のpricing modelを求める方法
- マート集計クエリ実行時、pricing modelを切り替える方法
- まとめ
Active Metadata Managementとは
Active Metadata Managementとは、Gartner社が提唱するメタデータ管理の新しい考え方です。
簡単に一言で説明すると、システムが自らメタデータを収集、分析、洞察し、具体的なアクションを起こすことです。この一連のプロセスが継続的に行われることもポイントです。これにより、データの品質管理、セキュリティ、コストなどの最適化が期待される考え方になります。
詳細な解説がされているGartner社の記事はこちらです。
上記記事を要約すると、Active Metadata Managementには以下4つの特徴があります。
Active metadata platforms are always on.
人間が手作業でメタデータを入力することなく、常にあらゆるメタデータを自動収集する。Active metadata platforms don’t just collect metadata. They create intelligence from metadata.
メタデータを収集するだけでなく、収集したメタデータを分析して洞察する。加えて時間と共に洞察の精度を向上させる。
(例)クエリログからSQLコードを解析して自動的にカラムレベルのリネージを作成し、どのテーブルが最もクエリされているかを推察する。Active metadata platforms don’t just stop at intelligence. They drive action.
収集したメタデータを分析して洞察した結果を、自ら活用する。
(例)過去のログを使用して、どのデータセットが最も利用されているかを分析。その分析結果をデータパイプラインシステムに送り、データパイプラインの実行スケジュールを自動的に最適化する。Active metadata platforms are API-driven, enabling embedded collaboration.
外部ツールとAPI連携が可能。
(例)あるデータへのアクセスをリクエストされた際、データ所有者はSlack上でリクエストを受け取り、承認または拒否ができる。
今回私たちは、3つ目の特徴(Active metadata platforms don’t just stop at intelligence. They drive action.)に着目しCompute費用削減を行ないました。
3つ目の特徴についてもう少し詳しく説明します。
この特徴を言い換えると「メタデータを使用し、システムに対して自動的に何かをする」ということです。この「自動的に何かをする」というところが重要になります。先ほど挙げた例においては、「データパイプラインの実行スケジュールを自動的に最適化する」という部分が「自動的に何かをする」を指しています。また、データパイプラインの実行スケジュールが最適化されるまでに、人間が手を加える必要がないことも重要です。
つまり、人間が介入することなく、システムが自動的にメタデータを分析し、アクションを起こすことが3つ目の特徴となります。
以上がActive Metadata Managementの特徴です。本記事がActive Metadata Management活用のきっかけとなれば幸いです。
では、本題に入ります。
結局どんなことを行なったのか、ざっくりまとめ
費用削減までの工程をざっくりまとめると以下の通りです。
各工程における詳細な情報は後述します。
- 各種pricing modelを設定したReservationを用意し、各々専用のprojectを割り当てる
- INFORMATION_SCHEMA.JOBS_BY_PROJECTから取得した過去の集計実績を元に、データマート毎に最安値のpricing modelを求める
- マート集計クエリ実行時、クエリを実行するprojectを最安値のpricing modelを設定しているprojectに切り替えて集計する
改めまして、ここからCompute費用の削減方法について詳しくご紹介していきます。
Compute費用のpricing modelとReservationについて
今回のCompute費用削減においては、Compute費用のpricing modelとReservationへの理解が重要になります。特に後述するReservationへprojectを割り当てる「Assignment」は、Compute費用削減に利用する機能です。それでは、Compute費用のpricing modelとReservationについて説明していきます。
pricing model
まず、Compute費用のpricing modelについて簡単に説明します。
※私たちはUSリージョンでBigQueryを使用しているので、USリージョン版単価での説明となります。
Compute費用のpricing modelを簡単な図にまとめました。
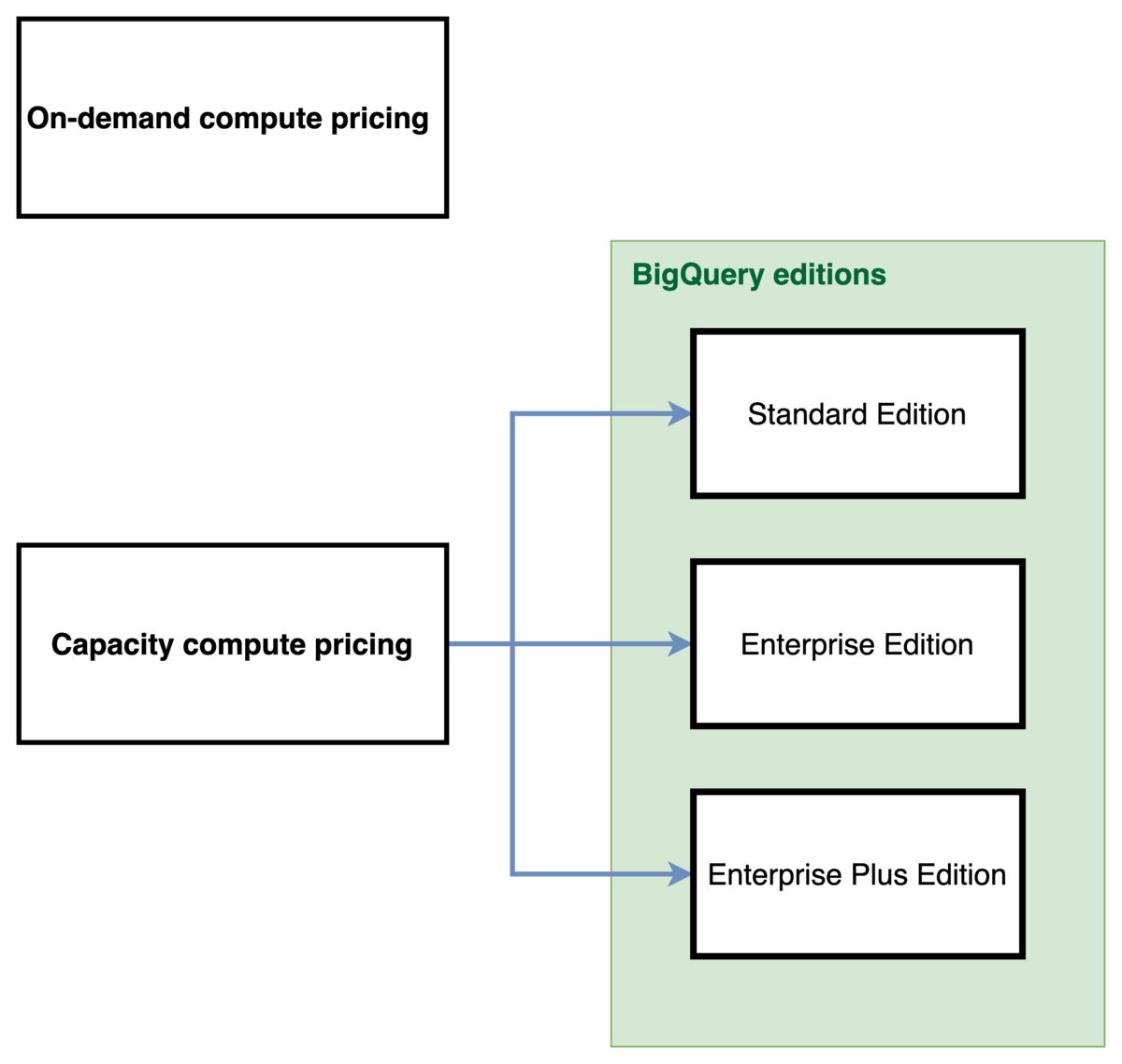
順を追って説明していきます。
まず、Compute費用のpricing modelはOn-demand compute pricingとCapacity compute pricingの2種類に分類されます。違いは以下の通りです。
- On-demand compute pricing:クエリ実行時にスキャンされたデータ量に対して課金される
- Capacity compute pricing:クエリ実行時に使用された計算リソース(Slot)に対して課金される
それぞれのpricing modelについてもう少し詳しく解説していきます。
On-demand compute pricingはクエリ実行時にスキャンされたデータ量に対して1TBあたり6.25USDが課金されます。従って、クエリ実行時にスキャンされるデータ量が多いほど費用が高くなります。そしてCompute費用削減の観点からは、クエリ実行時にスキャンされるデータ量を少なくすることが重要になります。以下がOn-demand compute pricingを適用した方がお得になるクエリのイメージです。
(例)On-demand compute pricingを適用した方がお得になるクエリのイメージ
SELECT Window関数等の複雑な計算 FROM 小さいテーブル_1 CROSS JOIN 小さいテーブル_2 CROSS JOIN 小さいテーブル_3
上記クエリは、複雑な計算を行なっているのでSlot使用量は多くなりますが、小さいテーブル_1,2,3のデータ量が少ないため、クエリ実行時にスキャンされるデータ量が少なくなります。従ってOn-demand compute pricingを適用した方がお得になります。
一方、Capacity compute pricingはクエリ実行時に使用された計算リソース、いわゆるSlotに対して課金されます。つまり、クエリ実行時に使用されるSlot数が多いほど費用が高くなります。Compute費用削減の観点からは、クエリ実行時に使用されるSlot数を少なくすることが重要になります。以下がCapacity compute pricingを適用した方がお得になるクエリのイメージです。
(例)Capacity compute pricingを適用した方がお得になるクエリのイメージ
SELECT * FROM 巨大なテーブル LIMIT 10
上記クエリは、処理がシンプルなのでSlot使用量は少なくなりますが、巨大なテーブルのデータ量が多いため、クエリ実行時にスキャンされるデータ量が多くなります。従ってCapacity compute pricingを適用した方がお得になります。
また、Capacity compute pricingは、BigQuery editionsという、利用可能な機能・単価に違いがある3種類のplanから選択をする必要があります。以下がBigQuery editionsの一覧です。
| pricing model | 課金単位 | 単価 |
|---|---|---|
| Standard Edition | Slot(hour) | 0.04USD |
| Enterprise Edition | Slot(hour) | 0.06USD |
| Enterprise Plus Edition | Slot(hour) | 0.1USD |
料金の傾向として、Standard Editionsが最安値のpricing modelになります。
各Editionの違いに関する詳細は以下をご確認下さい。
各Editionで使用できる詳細な機能の違いについては上記ドキュメントをご確認いただければと思いますが、ここでは今回のCompute費用削減に関係する2点をご紹介します。
まず1点目は、3つのEditionでは費用の計算方法が異なることです。詳細はReservationでご紹介しますが、以下が各Editionでの課金方法です。
- Standard Edition:Autoscale Slot
- Enterprise Edition:Autoscale Slot + Baseline Slot
- Enterprise Plus Edition:Autoscale Slot + Baseline Slot
2点目は、Fine-grained security controlsの使用可否です。Fine-grained security controlsとは、BigQueryテーブルのカラムに対して、以下のようなことができる機能(他にもいくつかあります)です。
- policy_tagというタグを付与することで特定カラムのデータへのアクセス権限を制限すること
- 特定カラムのデータをマスキングすること
この機能についても3つのEditionで使用できるかどうかが異なります。今回、このFine-grained security controlsの使用可否は重要なポイントになりますので、念頭に置いておいていただけると幸いです。
- Standard Edition:使用不可
- Enterprise Edition:使用可能
- Enterprise Plus Edition:使用可能
Fine-grained security controlsの詳細は以下をご確認下さい。
ここからは私たちが採用している3つのpricing modelについてご紹介します。
Compute費用削減前の私たちは、全てのデータマートをEnterprise Editionのみで集計していましたが、今回新たにOn-demandとStandard Editionを導入しました。現在はこの3つのpricing modelからデータマート毎に最安値のpricing modelを求め、Compute費用を削減しています。
- On-demand
- Standard Edition
- Enterprise Edition
以上がCompute費用のpricing modelについての説明です。続いてReservationについて説明します。
Reservation
まず、Compute費用削減においてなぜReservationが関係するのか説明します。
現状(2024年2月時点)ではクエリ実行時に使用するpricing modelをダイレクトに切り替える機能がありません。そのため、今回のCompute費用削減ではReservationのAssignment機能を利用してpricing modelを切り替えることにしました。では、最初にReservationの解説に入ります。
Reservationとはクエリ実行に使用するSlot数をあらかじめ予約できるBigQueryの機能です。作成時は以下の設定をします。On-demand用のReservationに関しては、Explicit On Demand ResourcesというReservationがデフォルトで用意されていますのでこちらを使用しています。
- Reservation:Reservationの名前
- Location:リージョン
- Editions:Reservationへ適用するBigQuery editions
- Max Reservation size:クエリ実行中、必要に応じて自動的に追加されるSlot(Autoscale Slot)の上限
- Baseline Slot:常時Reservationへ割り当てるSlot数
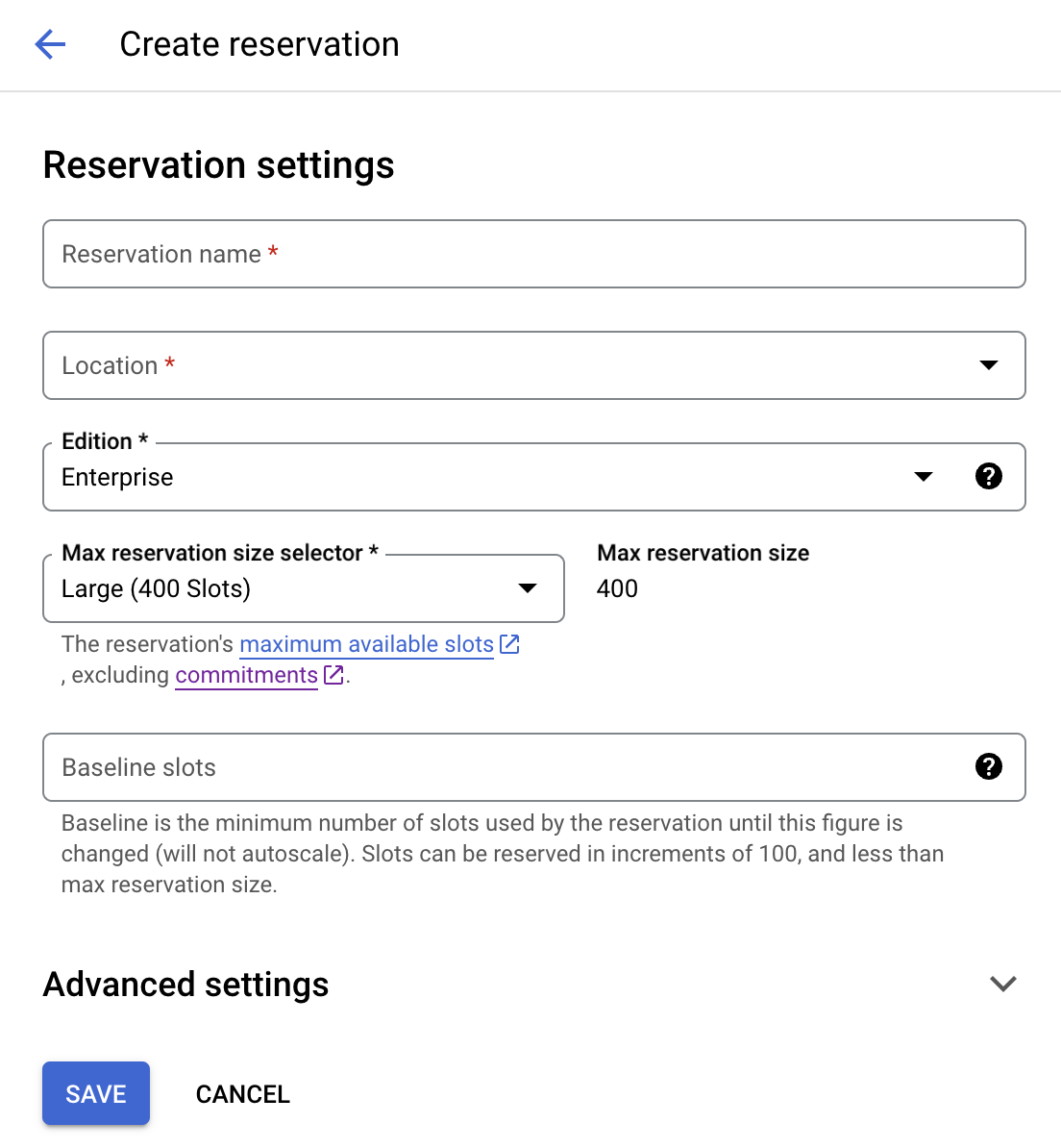
以下がOn-demand用のReservation、Explicit On Demand Resourcesです。

詳細なReservationの設定方法は以下をご確認下さい。
またpricing modelでも触れましたが、Reservation作成時に選択したBigQuery editionsによって課金されるCompute費用の計算方法が異なりますのでご注意ください。
Standard Editionを選択した場合は、以下の計算方法で課金されます。加えて設定できるMax Reservation sizeの上限は1600Slotです。
クエリ実行中、自動的に追加されるSlot数(Autoscale Slot)のみ
Enterprise EditionとEnterprise Plus Editionは以下の計算方法で課金されます。こちらはMax Reservation sizeの上限がありません。
Baseline Slot + クエリ実行中、自動的に追加されるSlot数(Autoscale Slot)
加えてこの2つのEditionはクエリ実行をしていない場合でも、設定したBaseline Slot分の料金が常に課金されるので注意してください。
以上がBigQuery editionsにおける費用の計算方法の違いです。Baseline SlotやAutoscale Slotの詳細については以下をご確認下さい。
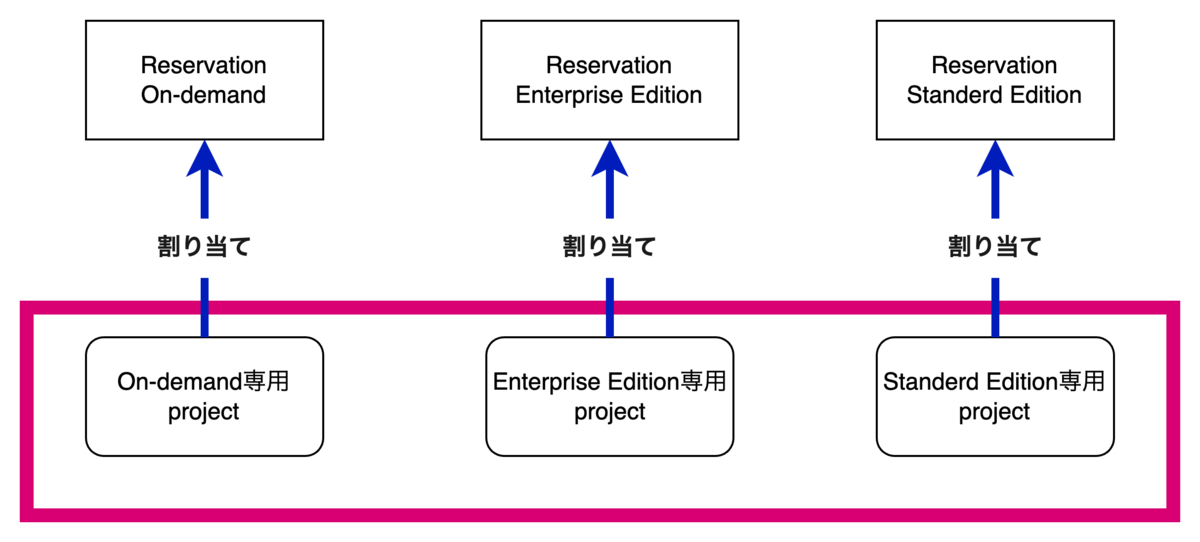
続いてAssignmentについて説明します。AssignmentとはReservation作成後、設定したSlotを使用するため、project, folder, organizationのいずれかを割り当てる機能のことです。今回のCompute費用削減においては、projectをAssignmentするパターンを採用しているので、projectをAssignmentする方法について説明します。
まず、ReservationへprojectをAssignmentする効果は設定したprojectで実行されるクエリがReservationのSlotを確保できるということです。
そして最大のポイントは、クエリ実行する際にAssignmentしたprojectを選択すると、Reservationで設定したpricing modelを使用して費用課金されるということです。今回はこのポイントを利用してCompute費用削減を行なっています。
具体的なAssignmentの方法ですが、BigQuery editionsを採用しているReservationの場合は、コンソールから操作が可能です。
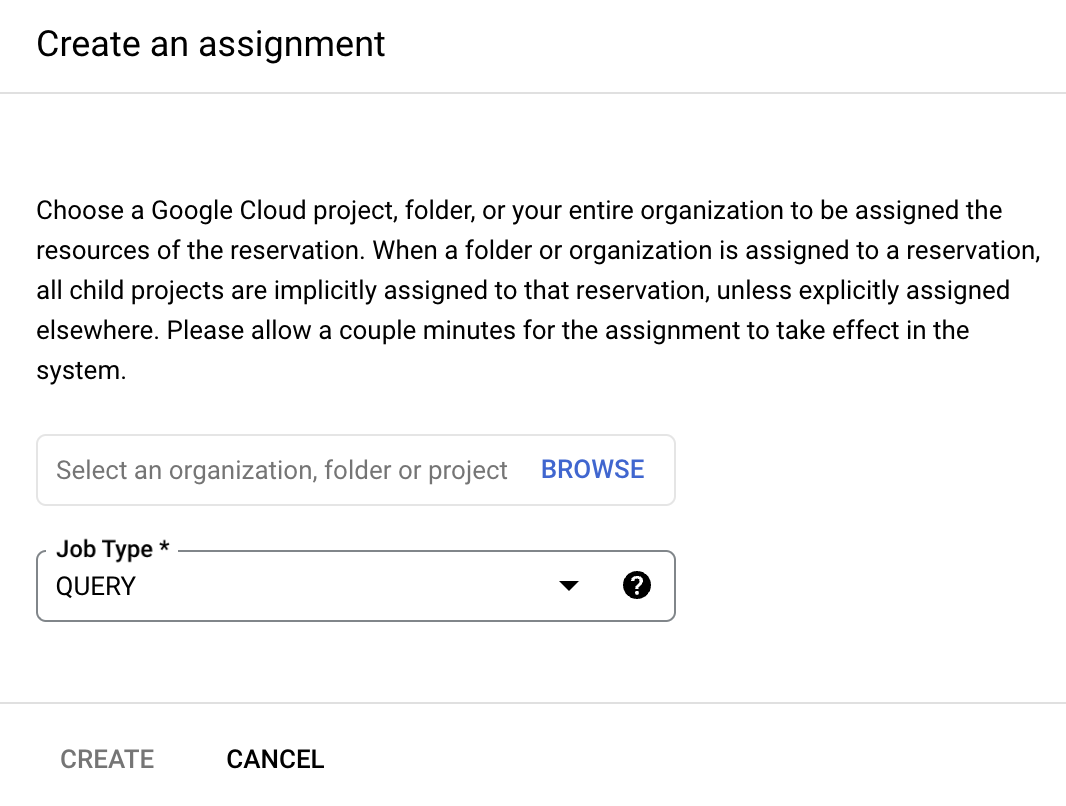
注意点は、On-demand用Reservation(Explicit On Demand Resources)にはコンソールからprojectのAssignmentができないことです。On-demand用Reservation(Explicit On Demand Resources)へprojectをAssignmentする方法は2種類あります。
- bqコマンドを実行する
- CREATE ASSIGNMENT DDLステートメントをコンソールから実行する
今回私たちは、bqコマンドを実行する方法を採用しました。
bq mk \ --location=LOCATION \ --reservation_assignment \ --reservation_id=none \ --job_type=QUERY \ --assignee_id=PROJECT_ID \ --assignee_type=PROJECT
reservation_id=noneに設定することで、指定したprojectはOn-demand用Reservationを使用したクエリ実行が可能になります。加えて、On-demandはQUERYジョブ(job_type=QUERY)のみのサポートとなりますのでご注意下さい。
CREATE ASSIGNMENT DDLステートメントをコンソールから実行する方法を含む詳細なAssignment設定方法は以下をご確認下さい。
ここからは私たちのReservation設定についてご紹介します。
1つのReservationに複数のprojectを割り当てることも可能ですが、今回私たちは各price modelを設定したReservationに対し、1つずつ専用projectを割り当てました。
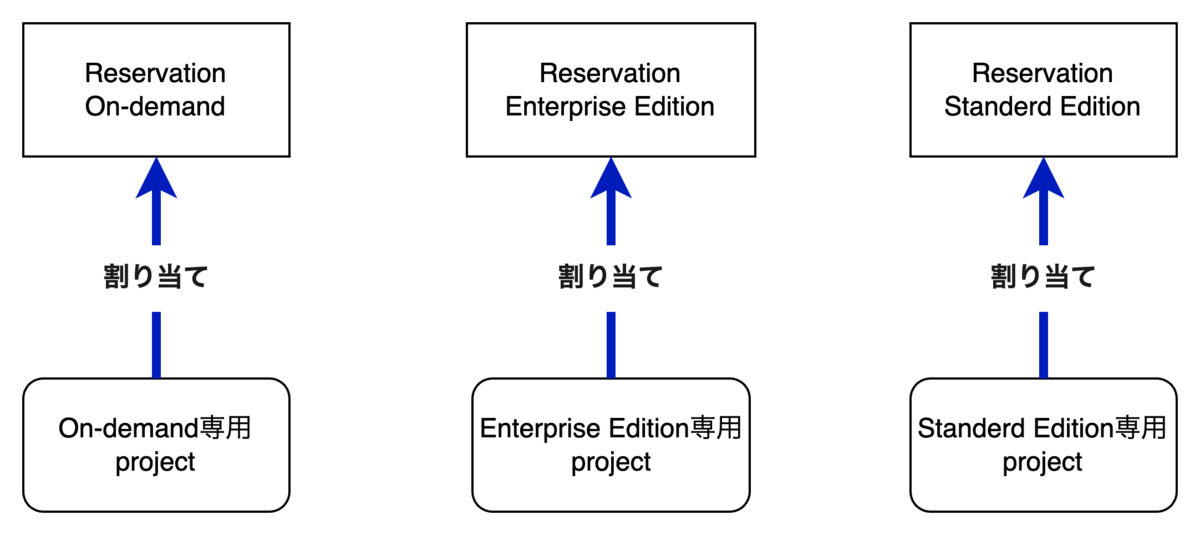
以上がReservationについての説明です。続いて、Compute費用削減における各工程について説明します。
Metadataを使用して最安値のpricing modelを求める方法
まず、私たちが採用している3つのpricing modelを使用する際の注意点について説明します。
pricing modelでご紹介した通り、今回のCompute費用の削減に伴い新たにOn-demandとStandard Editionを導入しました。3つのpricing modelからデータマート毎に最安値のpricing modelを求め、Compute費用削減をしています。
- On-demand
- Standard Edition
- Enterprise Edition
しかし、pricing modelでも触れた通り、Standard EditionはFine-grained security controlsが使用できません。つまり、policy_tagが付与されているテーブルを使用したクエリには適用不可能ということになります。従って、Standard Editionを適用するには以下の注意点を考慮する必要があります。
- 実行クエリ内でpolicy_tagが付与されているテーブルを参照していないこと
この条件を判定するにはpolicy_tagが付与されているテーブル情報が必要になりますが、現状(2024年2月時点)ではINFORMATION_SCHEMAからこの情報を取得できません。そのため、私たちはpolicy_tagが付与されているテーブルの一覧情報を管理するテーブルを自作しています。こちらの管理テーブルからpolicy_tagが付与されているテーブルの一覧を取得することでStandard Editionを適用する条件を満たしているかどうかを判定できます。
以下が最安値のpricing modelを求めるクエリです。このクエリを実行していただければ、全データマートの最安値pricing model情報を一括で求めることが可能です。
WITH -- policy_tagが付与されているテーブル一覧を全て取得 GetSensitive AS ( SELECT DISTINCT TableName FROM `プロジェクトID.データセットID.policy_tag管理テーブル` ), -- 集計されているデータマート情報を各3種類の料金プランが設定されているプロジェクトから取得 --(On-demand, Standard Edition, Enterprise Edition) JOBS_BY_PROJECT AS ( SELECT destination_table, total_bytes_processed, total_slot_ms, referenced_tables, creation_time, user_email, job_type FROM `On-demand設定のプロジェクトID.region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` UNION ALL SELECT destination_table, total_bytes_processed, total_slot_ms, referenced_tables, creation_time, user_email, job_type FROM `Standard Edition設定のプロジェクトID.region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` UNION ALL SELECT destination_table, total_bytes_processed, total_slot_ms, referenced_tables, creation_time, user_email, job_type FROM `Enterprise Edition設定のプロジェクトID.region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` ) --データマート毎に過去7間の平均価格を各3種類の料金プランで算出(On-demand, Standard Edition, Enterprise Edition) SELECT destination, ondemand_avg_price, enterprise_avg_price, standard_avg_price, policy_tag_flag, IF (policy_tag_flag ,CASE WHEN enterprise_avg_price > ondemand_avg_price THEN 'On-demand設定のプロジェクトID' ELSE 'Enterprise Edition設定のプロジェクトID' END ,CASE WHEN standard_avg_price > ondemand_avg_price THEN 'On-demand設定のプロジェクトID' ELSE 'Standard Edition設定のプロジェクトID' END ) AS lowest_project FROM ( SELECT CONCAT(destination_table.project_id,'.',destination_table.dataset_id,'.',destination_table.table_id) AS destination, SUM((total_bytes_processed / 1024 / 1024 / 1024 /1024 ) * 6.25) / 7 AS ondemand_avg_price, SUM((total_slot_ms / 1000 / 60 / 60) * 0.06) / 7 AS enterprise_avg_price, SUM((total_slot_ms / 1000 / 60 / 60) * 0.04) / 7 AS standard_avg_price, -- policy_tagが付与されているテーブルを参照しているかどうかを判定 LOGICAL_OR(ARRAY_LENGTH(ARRAY(SELECT referenced_table.table_id FROM UNNEST(referenced_tables) AS referenced_table INNER JOIN GetSensitive ON referenced_table.table_id = TableName)) > 0 ) AS policy_tag_flag FROM JOBS_BY_PROJECT WHERE DATE(creation_time, "Asia/Tokyo") BETWEEN DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 8 DAY) AND DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 1 DAY) AND user_email ='データマート集計に使用するサービスアカウント' AND job_type = 'QUERY' GROUP BY destination )
クエリをご覧いただければわかる通り、データマート毎に過去7間の平均価格を各3種類の料金プランで算出及び比較をして最安値のpricing model(lowest_projectカラム)を求めています。特にlowest_projectカラムは、pricing modelを切り替える際に使用する情報ですのでご注目ください。
INFORMATION_SCHEMA.JOBS_BY_PROJECTの詳細については以下をご確認下さい。
以上がMetadataを使用して最安値のpricing modelを求める方法の説明です。
マート集計クエリ実行時、pricing modelを切り替える方法
続いて、マート集計クエリ実行時にpricing modelを切り替える方法について説明します。流れとしては、データマート集計クエリ実行時、取得した最安値のpricing modelへ切り替えをしてから、集計・更新するというものなっています。該当部分のコードを抜粋します。
from google.cloud import bigquery client = bigquery.Client(project='Enterprise Edition設定のプロジェクトID') query_job = client.query(project='最安値のプロジェクトID', query='データマート集計クエリ', job_config='集計結果を格納するテーブル設定など')
一番下のquery_jobに注目して下さい。ここで、bigquery.Clientのprojectパラメーターに先程のlowest_projectカラム情報を指定しています。この設定をすることで、最安値のpricing modelを使用して集計ができます。つまり、以下3つのprojectの内、最安値のReservationにAssignmentされているprojectがパラメーターに設定されます。現状(2024年2月時点)ではbigquery.Clientにpricing modelを切り替えるパラメータが存在しないため、このような手法を採用しています。
また、clientにてbigquery.Clientを定義する際、projectパラメータへ初期値としてEnterprise Edition専用projectを設定しています。これにより、最安値のpricing model情報が取得できなかったデータマートは、初期値に設定したproject(Enterprise Edition)で集計が行われます。
以上がマート集計クエリ実行時、pricing modelを切り替える方法です。
まとめ
本記事では、Active Metadata Managementに着目し、BigQueryのCompute費用を削減する方法についてご紹介しました。Compute費用の削減前は、全てEnterprise Editionでデータマート集計しておりましたが、この方法を採用した結果、以下のような割合でデータマート集計がされています。
- On-demand:約20%
- Enterprise Edition:約30%
- Standard Edition:約50%
Compute費用削減後、約50%のデータマートがStandard Editionを使用しています。Standard EditionはMax Reservation sizeの上限が1600Slotとなっています。そのため、集計遅延が発生する懸念をしておりましたが、Compute費用削減後も集計遅延は起きておらず削減前と変わらない速度で集計が完了しています。
そして本記事のタイトルにもなっていますが、トータルのCompute費用は約40%削減ができました。
比較的お手軽にCompute費用削減ができる方法ですので、是非お試しください。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください。