



目次
- 目次
- はじめに
- 我々のチームについて
- ZOZOMETRYについて
- ZOZOMETRYでのBtoB開発で取り入れたこと
- プールモデルによるマルチテナント管理
- RLSの利用を見送った理由
- MySQLを採用した理由
- PostgreSQLを採用したいケース
- Gitの運用フロー
- まとめ
- 最後に
はじめに
こんにちは。計測プラットフォーム開発本部バックエンドブロックの髙橋です。
先日、ZOZOMETRYという新規サービスをローンチしました。
本記事ではZOZOMETRYをローンチするにあたり発生したBtoB開発における考慮すべきポイントと対応について解説します。
我々のチームについて
計測プラットフォーム開発本部バックエンドブロックでは、「世界中に計測技術を通じて、新しい価値をプラスする」をミッションとして掲げています。このミッションのもとZOZOMAT、ZOZOGLASS、ZOZOMETRYなどの計測プロダクトのバックエンド開発・運用をしています。主にScalaを使用し、堅牢で拡張性の高いシステムを目指しています。
ZOZOMETRYについて
ZOZOMETRYとは、事業者の採寸業務を効率化し、採寸が必要な服の売上拡大やコスト削減に貢献するサービスです。以前、ZOZOTOWNで提供していたサービスでは、ZOZOSUITを着用しての計測が必須でしたが、ZOZOMETRYではZOZOSUIT着用あり、ZOZOSUIT着用なしの異なる計測方法が提供されています。
ZOZOMETRYでのBtoB開発で取り入れたこと
我々のチームでは、過去にBtoCサービスを開発・ローンチしており、BtoBサービスの開発経験はありませんでした。しかしZOZOMETRYは法人向けのBtoBサービスであり、BtoCサービスとは異なる課題がありました。特に契約企業ごとにマルチテナンシーなサービスを提供する必要のあるユースケースで我々が取り組んだ方法をご紹介します。
プールモデルによるマルチテナント管理
SaaS型のBtoBサービスでは、多くの場合、契約企業ごとにデータを分離する必要があります。これらの分離モデルとして、サイロモデル・プールモデル・ブリッジモデルが知られています。
ZOZOMETRYのバックエンドシステムではローンチしたばかりのサービスである点からも、テナントごとに専用のリソースを用意することに関しては管理コストの増大につながる懸念がありました。そのためZOZOMETRYではテナントごとにAPIを用意することはせず、共通の1つのリソースでサービスを提供するためにプールモデルを採用しました。これにより、テナントごとに独立したリソースを用意することなく、複数のテナントを1つのリソースで運用できます。
Cognito+DBによるユーザー情報の管理
ユーザー認証はAWSが提供するCognitoを採用しています。外部サービスであるCognitoには認証に必要な最小限の情報(アカウントID、メールアドレスなど)のみを定義しています。各組織を区別するために必要なテナントIDも含めた、ユーザーの氏名などのmetadataはRDSに紐づける形で管理する方針としています。これにより、metadataの参照や更新が行われた場合にCognitoを経由する必要がなく、パフォーマンスや拡張性の観点から管理が容易となります。
CognitoのユーザープールとDBのテーブルの関係は以下のようになっています。CognitoのアカウントIDと、DB上のアカウントIDを紐づけることで、Cognitoのユーザー情報とDBのテナント情報を紐づけ、DB上のmetadataを取得しています。
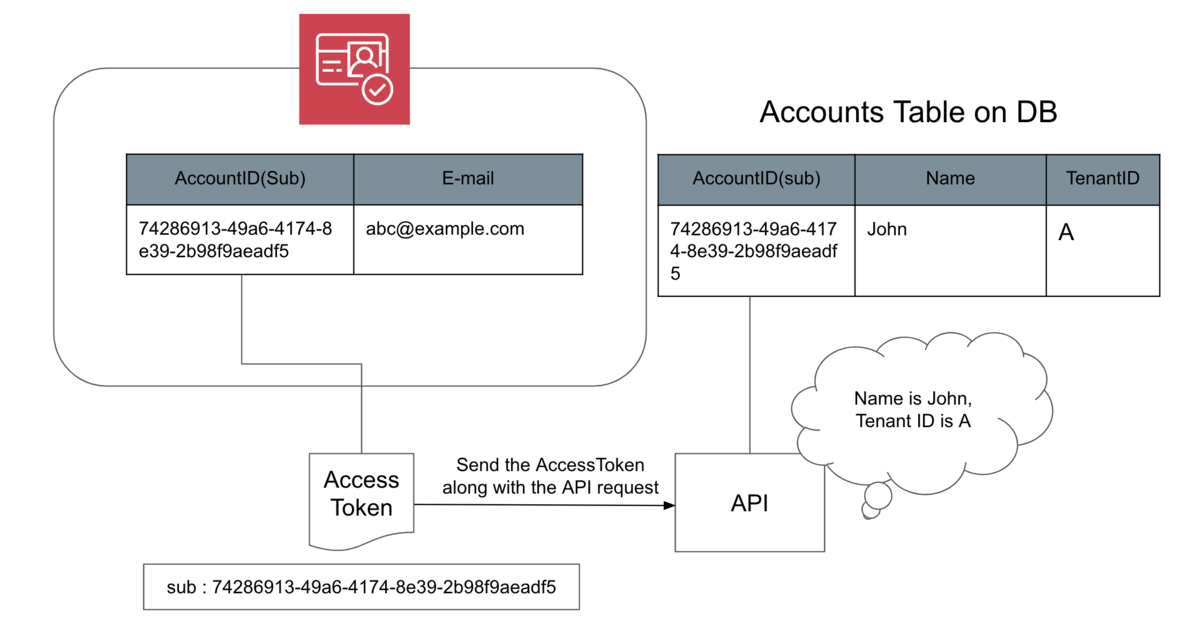
また、この構造をユーザー認証にも用いています。Cognitoから発行されたアクセストークンのペイロードには、CognitoのアカウントIDがsub属性として含まれています。アプリケーション側では、アクセストークンからCognitoのアカウントIDを取得し、DB上のアカウントIDを取得してユーザーを特定します。
しかしプールモデルでは、上段で説明したように1つのリソースで全ての顧客のデータを保持し、1つのサーバーで運用するような形になります。そのため、リソースごとにテナントごとのデータ分離をアプリケーション側で意識する必要があります。我々はアプリケーション側でテナントIDを保持することで、テナント間のデータを分離した状態でサービスを提供することが可能になりました。
RLSによる行単位でのデータアクセス制御
プールモデルにおけるマルチテナント管理の手段としては一般的にいくつか存在しています。我々は当初、PostgreSQLが提供するRLS (Row Level Security)を利用する想定で設計を進めていました。
RLSはテーブルに対して行単位でアクセスを制御できる機能です。詳細はPostgreSQLのドキュメントをご覧ください。私たちのユースケースでは、RLSを利用して、テナントIDをセッション変数として保持し、テナントIDに紐づくデータのみを参照することを想定しました。これにより、以下のコードのようにテナント間のデータをアプリケーション側で意識することなく分離できると考えました。
-- テーブルの作成 CREATE TABLE users ( user_id SERIAL PRIMARY KEY, tenant_id INT, first_name VARCHAR(50), last_name VARCHAR(50) ); -- サンプルデータの挿入 INSERT INTO users (tenant_id, first_name, last_name) VALUES (1, 'Alice', 'Smith'); INSERT INTO users (tenant_id, first_name, last_name) VALUES (2, 'Bob', 'Jones'); SELECT * FROM users; /* user_id | tenant_id | first_name | last_name --------+-----------+------------+----------- 1 | 1 | Alice | Smith 2 | 2 | Bob | Jones */ -- テーブルにRLSを適用 ALTER TABLE users ENABLE ROW LEVEL SECURITY; -- ポリシーの作成 CREATE POLICY users_rls_policy ON users FOR SELECT USING (tenant_id = current_setting('service.tenant_id')::int); -- RLSを用いたSELECT SET LOCAL service.tenant_id = 1; SELECT * FROM users; /* user_id | tenant_id | first_name | last_name --------+-----------+------------+----------- 1 | 1 | Alice | Smith */
RLSの利用を見送った理由
しかし、我々は以下の理由からRLSを使ったテナントごとのデータ分離手法の採用を断念することにしました。以下に、その理由について説明します。
理由1 : コネクションプールの管理
PostgreSQLのRLSは、ポリシーでパラメーターから得られるテナントIDが一致する行を条件にしています。DBセッション内でテナントIDを設定することで、そのテナントに対するデータにアクセスが許可されます。しかし、コネクションプールを利用する場合、同じコネクションを使いまわすことで違うテナントのデータを参照してしまう可能性があります。
そのため、セッションごとにコネクションを張ることになり、コネクションプールの効率を悪くする懸念がありました。また、プールモデルでシステムを構成しているため、コネクションが枯渇した際に全てのテナントに影響が出る可能性もありました。
理由2 : O/RマッパーでのRLSの利用
RLSを用いる場合はO/Rマッパー側でセッション変数を設定する必要があります。しかしながらユーザーごとにポリシーを分けておらず、コネクションのポリシーを都度切り替える必要がありました。結果的にコネクションにテナントIDをアタッチするための生クエリを発行するコンポーネントを作らなければならず、カスタム実装が必要でした。
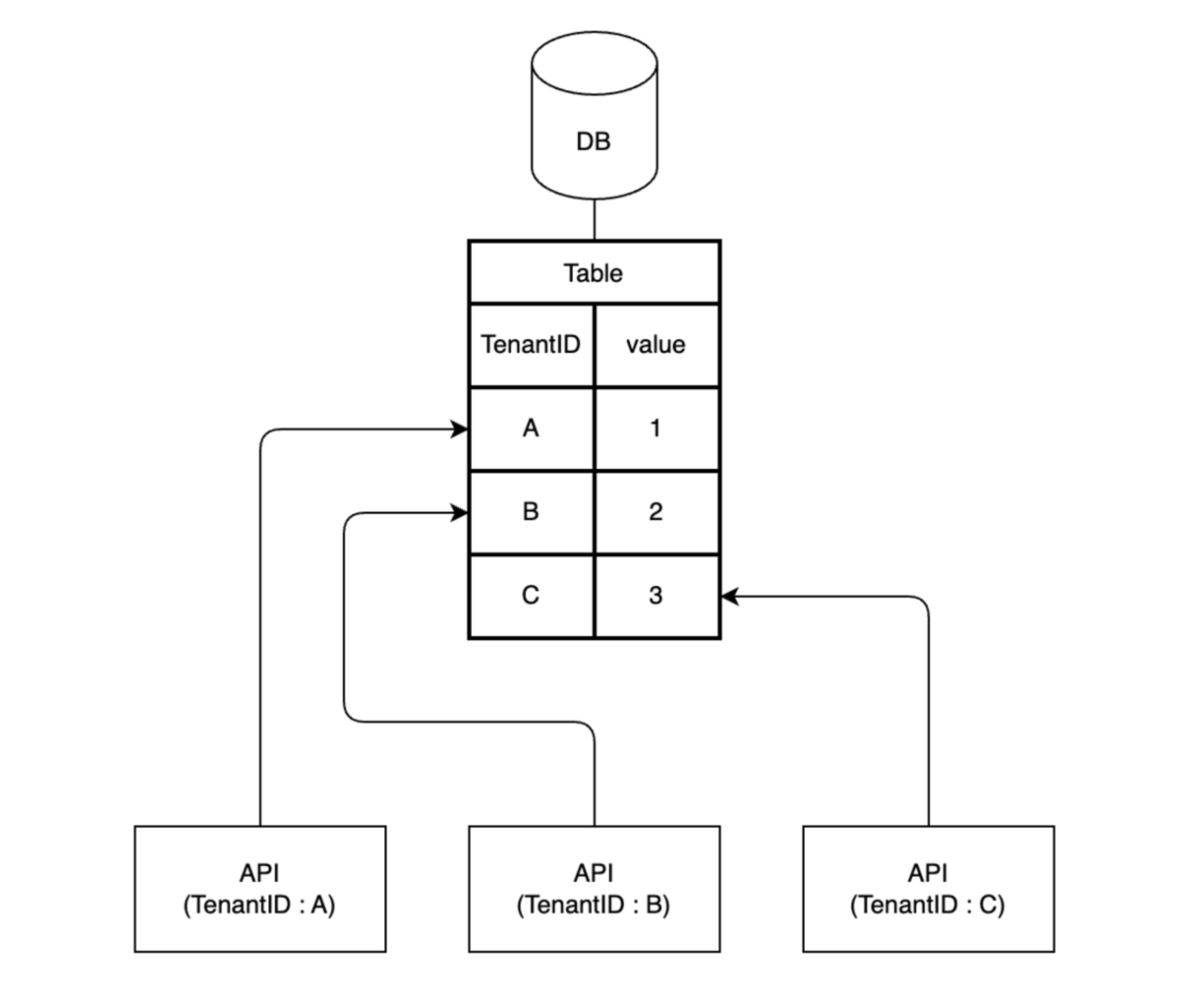
我々はプール型のシステムであり、共通のAPIサーバーを利用しています。そのため、ユーザーごとにポリシーをアタッチするような手法を用いるのが難しく、結果としてWHERE句にテナントIDを付加する手法と比較し、コストとリスクがあまり変わらないと判断しました。下図のように、テナントごとに異なるAPIサーバーを持っている場合であれば、RLSの効果的な利用が可能であったと考えています。
上記で触れたように、RLSを利用しない場合、内部的にはSQLクエリ上でテナントIDを指定する必要があります。これをエンドポイントごとに実装することなく、我々はアプリケーション側、実際はDDDにおけるユースケース層で定義し、実装することにしました。DDDにおけるテナントIDの取り扱いについては、以下に詳しく説明します。
DDDにおけるテナントのアクセス制御
DDDとは「Domain Driven Design」の略で、日本語では「ドメイン駆動設計」と呼ばれる設計手法です。DDDは、主にそのソフトウェアが対象とする領域(ドメイン)に焦点を当てて、それをソフトウェアに対して抽象化して適用し、その領域における問題を解決するための設計手法です。業務システムにおいて、ドメインとは主にビジネスロジックを表現するための概念です。バックエンドにおいては、システムのビジネスロジックを処理する主要な場所であることが多いことから、我々もシステムの設計にDDDを取り入れています。
そのため、我々はRLSが担うはずだった特定のテナントIDが割り当てられたデータのみのアクセス制限を行う処理を、共通に呼び出すビジネスロジックを集約するユースケース層に実装しました。これにより、実装者による実装漏れの懸念をほぼなくすことができます。ユースケース層に集約することにより、以下のメリットがあります。
- コードの可読性と保守性の向上
- ビジネスロジックが明確に分離されるため、テストの容易さが向上。コードの重複を避けることができる
- ユースケース層に集約されたビジネスロジックは、他のユースケースやアプリケーション層からも再利用可能
これらの点を考慮しながら、ユースケース層にビジネスロジックを集約し、DDDの原則に従った堅牢なアプリケーションを構築できます。
以下に、ユースケース層におけるテナントIDの取り扱いについてのコード例を示します。このコードでは、ユースケース層においてテナントIDを保持し、テナントIDに紐づくデータのみを参照する処理を実装しています。全てのユースケースがこのtraitをmixinすることで、チェック処理が漏れる懸念もありません。
trait UserUseCaseProtocol[Req <: UseCaseRequest[?], Res <: UseCaseResponse[?, ?]] { val userRepository: Repository[User] protected def execute(request: Req)(implicit ec: ExecutionContext): Future[Res] private def response(request: Req): Future[Res] = { for { _ <- ensureBelongingTo(request.userId, request.tenantId) res <- execute(request) } yield res } private def ensureBelongingTo( userId: Id[User], tenantId: Id[Tenant] )(implicit ec: ExecutionContext): Future[User] = { userRepository .resolveById(userId) .flatMap(ensureSameTenantId(_, tenantId)) } private ensureSameTenantId(user: User, tenantId: Id[Tenant]): Future[User] { if (user.tenantId == tenantId) Future.successful(user) else Future.failed(NotBelongingToTenantException(entity.id)) } } // --- Exception --- class NotBelongingToTenantException(userId: Id[User]) extends Exception
このように、我々はPostgreSQLのRLSを使ったデータ分離を見送ることにしました。
MySQLを採用した理由
我々はZOZOMETRYでRLSを使わない意思決定をしたに過ぎず、このままPostgreSQLを使い続ける余地もありました。しかし、最終的に我々はPostgreSQLでの開発を断念し、MySQLを採用することに決定しました。その理由は以下の通りです。
AWS Auroraとの互換性
まず、我々はデータベースにAWSのAuroraを使用しています。AWSがAuroraの新機能をリリースする際、基本的にはMySQLファーストで行われます。現時点でも、クロスリージョンリードレプリカやマルチマスタークラスターなどはMySQLでしか対応されていません。
PostgreSQL独自の機能の不使用
次に、我々はhstore型などのPostgreSQL独自の型は使用しません。json型やhstore型については、RDBではなくドキュメントDBやKVSなど、本質的にそれらを扱うことに適したデータベースへ永続化するように分離します。また、今まで説明していたようにRLSも利用しないため、PostgreSQLの独自機能を使うメリットが少ないと判断しました。
チームの経験と学習コスト
さらに、チームはこれまでのMySQLでの開発・運用経験を再利用可能です。新たにチームにジョインする人にはMySQLの知識が期待されます。MySQLを初めて扱う人には、例としてMySQLの固有なネクストキーロックなど、学習コストがかかりますが、チームとしての技術スタックを統一できます。
計測プロダクトとの整合性
最後に、我々のチームでは計測プロダクトの開発・運用にMySQLを採用しています。PostgreSQLの採用は計測プロダクトの中でもイレギュラーな技術スタックの決定となります。また、Auroraを使う上であってもMySQLを利用するメリットが大きいため、ZOZOMETRYでもMySQLを他の計測プロダクト同様に使用することにしました。
PostgreSQLを採用したいケース
一方で、PostgreSQLを採用したいケースもあります。例えば、複雑なクエリのパフォーマンス向上を図りたい場合や、hstore型などPostgreSQLにのみ存在する独自の型を使いたい場合です。しかし、我々のチームではこれらに遭遇するケースが少ないため、最終的にMySQLを採用することに決定しました。Auroraを使用する以上、PostgreSQLで機能の制限を受けることは避けたいと考えておりました。また、バックエンド側ではデータベースでJOINを行わない方針で開発を進めています。これは、データベースはアプリケーション層に比べてスケールが難しく、データベースに多くの仕事をさせないためです。
Gitの運用フロー
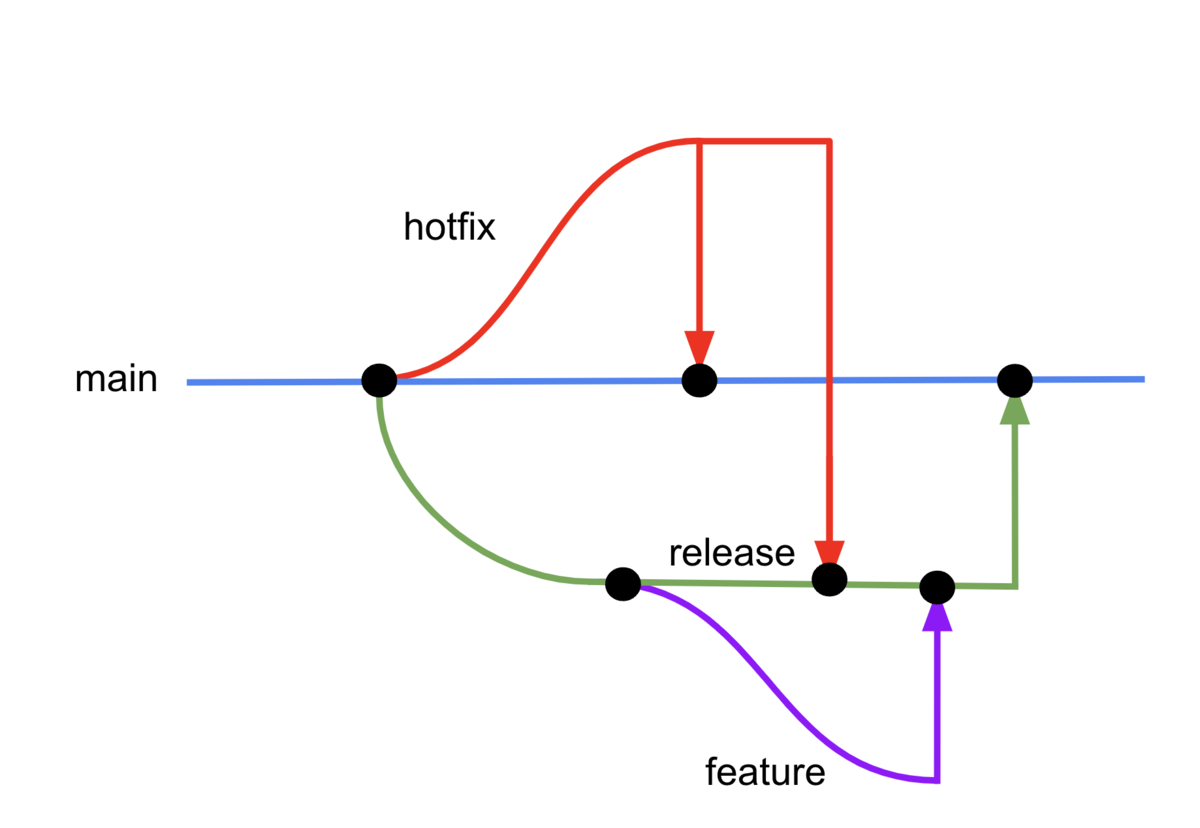
ZOZOMETRYでは、リリースのタイミングや内容の管理が重要です。以前記事として出したように、チームで開発・運用しているプロダクトではGitHub Flowを採用し、以下のように運用しています。
ZOZOMETRYでは定期リリースを採用することが決まったこと、BtoB向けのプロダクトであり変更に伴う顧客説明が必要となることから、定期リリースにおける最適なブランチ戦略を見直す必要があります。我々はGitHub Flowをベースに、releaseブランチを付加した運用フローを採用しました。これにより、リリースのタイミングや内容を管理し、リリース前に必要な調整ができます。
まとめ
本記事では、ZOZOMETRYのBtoBサービスにおける課題とその解決策について紹介しました。BtoBサービスではBtoCサービスとは異なる課題があり、それに対応することが求められますが、マルチテナンシーなサービスをプールモデルで提供し効率的なサービス提供を実現しました。また、アプリケーション側でテナントIDを保持することで、テナント間のデータを分離した状態でサービスの提供が可能になりました。引き続き、計測技術を用いて新しい価値を提供するために、技術的な課題に立ち向かいながらサービスの開発を進めていきます。
最後に
計測プラットフォーム開発本部バックエンドチームでは、グローバルに計測技術を開発していくバックエンドエンジニアを募集しています。ご興味のある方は、以下のリンクからぜひご応募ください!