



はじめに
こんにちは。SRE部プラットフォームSREブロックの松石です。
12月2日〜12月6日にラスベガスで開催されたAWS re:Invent 2024に、弊社から13名のエンジニアが現地参加しました。この記事では熱気あふれる会場の様子と現地参加したメンバーのそれぞれが印象に残ったセッションについてご紹介します。
目次
AWS re:Inventとは
re:InventはAmazon Web Services(AWS)が主催するAWS最大のカンファレンスです。このイベントでは、AWSの様々なサービスのアップデートや新サービスが発表されます。今年は世界中から約60,000人、日本から約1,700人の参加者がラスベガスに集まりました。今年のre:Inventでは、昨年から盛り上がりを見せる生成AIブームの影響が新サービスの発表や各セッション、EXPOでの企業ブースに多く見られました。
現地の様子
私は本イベントへの参加が今回初めてだったのですが、会場の熱気や日本では味わえない国際的な雰囲気とスケールの大きさに終始圧倒されました!
会場の入口
会場の入口にはAWS re:Invent 2024と書かれたWelcomeボードがありました。

EXPO
こちらは会場内のEXPOエリアです。今年は国内外の総勢数百社の企業がブースを出しており、各社のプロダクトのデモを直接見たり触れたりできます。また、EXPOでは各プロダクトに精通するエンジニアやその他のスタッフに気軽に質問や相談したり、議論を交わしたりもできます。



さらに、EXPOでは恒例のSWAG集めも活発に行われており、現地参加したメンバーがたくさんのSWAGを集めていました!

基調講演
基調講演では生成AI関連やクラウド運用の効率化などの新サービスや新機能が発表されました。
以下の画像は新しいNewSQLデータベースであるAmazon Aurora DSQLが発表された瞬間です。

朝食や昼食
イベント開催期間中は、朝食や昼食が無料で提供されます。さらには、会場内の各所でドリンクや軽食が提供され、Workshopに持ち込むこともできました。


AWS認定者ラウンジ
会場内には、AWSの認定資格の保有者のみが使える休憩スペースがありました。ここでも参加者同士の交流や認定資格の保有者限定のSWAGなどが配布されていました。


その他
イベントの初日には、APJ on Tour ’24というAWS主催のパーティが開催されました。このイベントは、アジア太平洋地域のイベント参加者が交流できるコミュニティイベントです。

3日目には参加したメンバーのうち3名が毎年恒例の5Kマラソンに参加しました。定員は先着2,000名とのことでした。朝6時とかなり早かったですが、昇ってくる朝日を横目に走り、ゴール後には参加者に限定SWAGと記念メダルが渡されました。このイベントでは、ラスベガスの街中を走るというとても貴重な体験ができました!

re:Invent 4日目には「re:Play」というパーティが開催され、ライブステージや巨大滑り台など音楽やアクティビティを楽しむことができました!

セッションレポート
ここからは現地参加メンバーが気になったセッションを紹介します。
- Breakout Session
- Multi-Region strong consistency with Amazon DynamoDB global tables (DAT425-NEW)
- Understanding security & privacy on Amazon Bedrock, featuring Remitly (AIM360)
- Achieving scale with Amazon Aurora PostgreSQL Limitless Database (DAT420)
- The Future of Kubernetes on AWS (KUB201)
- Deep dive into Amazon Aurora DSQL and its architecture (DAT427)
- Chalk Talk
- Code Talk
- Innovation Talk
- Workshop
Multi-Region strong consistency with Amazon DynamoDB global tables (DAT425-NEW)
SRE部カート決済SREブロックの飯島です。
KeynoteではAmazon DynamoDB global tablesがマルチリージョンで強い整合性をサポートすることが発表されました。現在はプレビューであり、利用可能なリージョンはus-east-1(バージニア北部)とus-east-2(オハイオ)、us-west-2(オレゴン)の3つです。

この発表後に新たに追加されたBreakoutセッションに参加してきました。このようにre:InventではKeynoteで発表された新機能に関するセッションが追加されます。注目度が高いものだとすぐに予約が埋まってしまうため要チェックです。

Amazon DynamoDB global tablesとは選択したマルチリージョン間でDynamoDBテーブルを自動的にレプリケーションしてくれるフルマネージドな機能です。この機能を利用することで以下のメリットが得られます。
- 低遅延:ユーザは最も近いリージョンでデータにアクセスできる。
- 高可用性・対障害性:単一リージョン障害が発生しても他のリージョンからデータにアクセスし続けられる。
今回globale tablesのオプションで結果整合性(最終的な一貫性)と強い整合性(強固な一貫性)が選択できるようになりました。

これまでデフォルトの設定だった結果整合性では、タイミングによっては古いデータへアクセスすることもあります。例えば以下キャプチャのus-east-1のテーブルで更新があった場合、もし更新がレプリケーションされる前にus-west-2へアクセスすると古いデータが返ってきます。

一方で、強い整合性ではいつどのリージョンのテーブルにアクセスしても最新のデータが返ってきます。

以下の表はマルチリージョンにおける結果整合性と強い整合性の比較です。
| マルチリージョンの結果整合性 | マルチリージョンの強い整合性 |
|---|---|
| 強い整合性のある読み取り (ConsistentRead: true) は古いデータを返すことがある | 強い整合性のある読み取り (ConsistentRead: true) は古いデータを返さない |
| 書き込みと強い整合性のある読み取り (ConsistentRead: true) のレイテンシが低い | 書き込みと強い整合性のある読み取り (ConsistentRead: true) のレイテンシが高い |
| 競合は最後の書き込みを優先して解決される | 競合が発生すると ReplicatedWriteConflictException が返される |
| RPO (Recovery Point Objective) は 1 桁秒 | RPO (Recovery Point Objective) はゼロ |
先述した通りマルチリージョンの強い整合性は古いデータを返しませんが、結果整合性よりも「書き込みと強い整合性のある読み取り」のレイテンシが高く、整合性とレイテンシの間にはトレードオフがあります。異なるリージョンにおいて同じデータへの書き込みにより競合が発生した際の挙動や、RPO(Recovery Point Objective)にも違いがあります。
以下は強い整合性を使用する際の注意点です。
- プレビュー機能のため本番環境での使用には適さない
- 強い整合性はすべてのレプリカテーブルに適用される
- global table作成後は整合性の切り替えができない
- 利用可能な3つのリージョンに展開が必要
- 例:us-east-1にDynamoDB tableを作成した場合、us-east-2とus-west-2にレプリカテーブルが作られる
強い整合性でglobal tableを作成すると結果整合性に変更はできません。逆も然りです。一度すべてのレプリカテーブルを削除してからglobal tableを再度作成する必要があります。
本セッションではデモや強い整合性をどのように実現しているか詳細な説明も行われました。興味のある方はリンクからぜひご覧ください。
AWS re:Invent 2024 - Multi-Region strong consistency with Amazon DynamoDB global tables (DAT425-NEW)

Increase your database agility with Amazon FSX (STG404-R)
SRE部基幹プラットフォームSREブロックの斉藤です。普段はZOZOの倉庫システムやブランド様向けの管理ページなどのサービスのオンプレミスとクラウドの構築・運用に携わっています。またDBREとしてZOZOTOWNのデータベース全般の運用・保守も兼務しています。
ZOZO Advent Calendar 2024にて、技術セッション以外の場面でのre:Inventの魅力について紹介していますので併せてご覧ください。
目的と概要
Amazon FSx for NetApp ONTAPを活用し、データベースのクローンを作成する手法を学ぶための2時間のWorkshopに参加しました。事前準備されたEC2インスタンスやAmazon FSx環境を使用するため、ラップトップを持参し、会場内のWi-Fiを利用して操作します。
主な内容
- Amazon FSxを用いたAmazon EC2上でのセルフマネージドデータベース「SQL Server、PostgreSQL、MySQL」の中から選択して操作する(SQL Serverを選択)。
- 高度な機能「スナップショット、クローン作成、バックアップ、レプリケーション」の中でもクローン作成に焦点を当て、データベースの迅速なコピーについて学習する。

Amazon FSx for NetApp ONTAPとは
NetAppのデータ管理ソフトウェアであるONTAPをクラウド上で利用できるようにした、AWSのマネージドサービスです。エンタープライズ向けのデータ管理やストレージニーズに対応しており、オンプレミス環境やハイブリッドクラウド環境で広く使われているNetApp ONTAPの機能をそのまま活用できるというものです。

SnapCenterのインストールとFSx for ONTAP ファイルシステムの確認
用意されたEC2インスタンスにリモートデスクトップで接続できる状態にしてWindows Serverにログインします。
PowerShellを起動してFSx for ONTAPファイルシステムにSSHで接続し、ボリュームの状態を確認しておきます。さらに、snapcenter.exeを起動して、NetApp SnapCenterをインストールします。
NetApp SnapCenterとは
データ保護・管理ソリューションで、データベース、仮想マシン、アプリケーション、ファイルシステムのバックアップ、リストア、クローン作成を一元管理できるツールです。

SnapCenterへストレージシステムの追加
SnapCenterにクローン元とクローン先のストレージシステムを追加します。
- SnapCenterのナビゲーションペインから「Storage Systems」を選択します。
- 「New」をクリックします。
- ストレージシステムの情報を入力していきます。
- Storage System:データベースの管理IPアドレスを入力します。
- Username:ストレージにアクセスするためのユーザーで、操作可能な権限が割り当てられます。
- Password:ユーザーのパスワードを入力します。

SnapCenterへホストの追加
SnapCenterにクローン元とクローン先のホストを追加します。
- SnapCenterのナビゲーションペインから「Hosts」を選択します。
- 「Managed Hosts」タブから「Add」をクリックします。
- 表示されたポップアップにデータベースのホスト情報を入力します。
- Host Name:データベースのホスト名を入力します。
- Credentials:実行に使用する認証情報を選択します。
- Select Plug-ins to Install:「Microsoft Windows」と「Microsoft SQL Server」を選択します。SQL Serverホストを追加すると、必要なプラグインをデータベースホストに適用し、自動検出ができるようになります。
- 「Submit」をクリックして完了です。

クローンの作成
クローンを作成して別のインスタンスにデータベースのコピーを作成します。
- SnapCenterのナビゲーションペインから「Resources」を選択し、さらにユーザーデータベースを選択します。
- クローンを作成する対象となるバックアップを選択し、「Clone」を選択します。

- 画面が切り替わったら、「Clone settings」配下の「Clone Options」を入力します。
- Clone server:クローン先のデータベースホスト名を入力します。
- Clone instance:クローン先のデータベースインスタンス名を入力します。
- Clone name:インスタンス内にクローンされるデータベース名を入力します(一意である必要があります)。
- Choose mount option:「Auto assign volume mount point under path」を選択します。さらに、FSx for ONTAPのディスク上のディレクトリを指定します。このディレクトリは、クローン作成時に新しいボリュームとしてマウントされるルートロケーションに使用されます。
- 「Next」をクリックして完了です。
※「Logs」から「Summary」は、今回特に設定せずにデフォルト値で進行していました。

クローンの確認
SQL Server Management Studioから確認するとクローンしたデータベースがDEVSQLインスタンス上に作成されました。

PowerShellを起動してFSx for ONTAPファイルシステムに再度SSHで接続し、ボリュームの状態を確認してみるとクローンしたボリュームが追加されていることが確認できました。

まとめ
re:Inventで初めて海外のWorkshopに参加しました。不安や緊張を感じていましたが、スタッフが親切でサポートも手厚く、ブラウザベースで進行する形式だったため、手順を翻訳して学習を進められました。
今回は、Amazon FSx for NetApp ONTAPの一部機能について学びましたが、他にも多くの高度な機能が提供されています。これを機にさらなる理解を深め、弊社のEC2インスタンス上で稼働するSQL Serverの運用改善やコスト効率化に活用できる可能性を検討したいと思います。
Understanding security & privacy on Amazon Bedrock, featuring Remitly (AIM360)
ブランドソリューション開発本部FAANS部バックエンドブロックの田島です。今年のAWS re:Inventでは、生成AIに関するセッションが昨年以上に強い存在感を放っている印象でした。その中でも、個人的に印象に残った「生成AIアプリケーションにおけるセキュリティ」に関するセッションについて紹介します。生成AIアプリケーションの開発においても、セキュリティやプライバシーの配慮は欠かせません。それに加え、「責任あるAI(Responsible AI)」というキーワードに示されるように、生成AI特有の考慮事項に対応する仕組みが求められます。
このセッションでは、まず生成AIアプリケーションのセキュリティについて、包括的な考え方が紹介されました。具体的には、セキュリティを3つのステージに分けて整理し、それぞれの要件が説明されました。
生成AIモデルの安全性の確保 安全な訓練データの使用や、事後学習フェーズでモデルの振る舞いを調整するアラインメントなど、生成AIモデル自体に関わるセキュリティ要件です。
モデルのアクセス制御と管理 モデルへの安全なアクセス制御や、運用中の監視・管理に関する要件です。
アプリケーション全体のセキュリティ モデルにアクセスする前のデータフロー管理や、ハルシネーションの防止、出力がポリシーに準拠しているかの確認などが含まれます。
さらに、多層的なセキュリティアプローチとして以下の決定論的制御と確率論的制御を組み合わせる重要性が強調されていました。
決定論的制御(Deterministic Controls) 再現性や説明可能性が求められる制御方法です。例えば、IAMを用いたアクセス制御やKMSによる暗号化などが該当します。
確率論的制御(Probabilistic Controls) 入力が意図したユースケースに沿っているかの確認や、出力結果の有害性をチェックするなど、生成AIモデル特有のアプローチです。例えば、機械学習モデルを用いて出力内容を評価する方法が該当します。この制御は柔軟性が高い反面、完全な再現性は保証できないため、一定のリスクを伴います。
続いて、これらの概念がAmazon BedrockというAWSの生成AIサービスと関連付けて解説されました。Bedrockはさまざまな生成AIモデルが利用でき、また、それを使ったアプリケーションの構築を容易に実現できるフルマネージドサービスです。責任あるAIを実現する仕組みとして「Guardrails for Amazon Bedrock」という機能が昨年発表されました。今回個人的に特に気になったのはGuardrailsの新機能である「Automated Reasoning checks」です。
Automated Reasoning checksは、前述の3つステージのうち3つ目の「アプリケーション全体のセキュリティ」に該当します。そして、この機能は決定論的制御と確率論的制御を組み合わせたアプローチを採用し、具体的には以下のような仕組みで動作します。

まず、ソースドキュメントとその内容をもとに回答を生成する目的をAutomated Reasoningサービスに送信し、自動推論ポリシーが生成されます。このポリシーは「以上」「以下」といった論理式を含む決定論的なルールとして構築されます。続いて、ユーザーからの質問やそれに対する回答が、このポリシーに準拠しているかどうかが判断されます。この検証部分は決定論的であるため、結果に再現性があります。一方で、ポリシー自体を生成するプロセスは確率論的です。ただし、この生成されたポリシーは人の手で修正可能なため、柔軟性と信頼性の両立を図りやすい点が特徴的です。
本セッションを通じて生成AIアプリケーション構築時のセキュリティに関する包括的な考え方を頭の中で整理できたのがまず大きな学びでした。また、Automated Reasoning checksは、論理式を使った決定論的なアプローチで生成AIアプリケーションの信頼性と説明可能性を高めるための画期的で興味深い仕組みだと感じました。実用的な生成AIアプリケーションの構築において、信頼性や説明可能性が障壁になりやすいと考えています。今後もその課題のための仕組みが強化されていくことで、生成AIアプリケーションの実用性がさらに広がることを期待しています!
Streamline Amazon EKS operations with generative AI (KUB321)
計測システム部SREの土田です。ZOZOMATやZOZOMETRY等の計測技術のSRE業務を担当しております。計測システム部ではAIを活用した業務効率化に力を入れており、re:inventではAIを用いた様々なソリューションを紹介するセッションがあり、それらに参加しました。
本パートではEKSの障害時のオペレーションをAI活用して迅速に行えるようにするCodeTalkのセッション内容を紹介します。
目的と概要
CodeTalkとは、ライブコーディングやコードサンプルを使用して、AWSのエンジニアが実装したソリューションを詳細に解説するセッションです。他のセッションと異なり、POCレベルで作ってみたようなものも紹介されていて、新しいことがたくさん学べたセッションタイプでした。
このセッションでは、EKSの障害発生時にアラートとともに改善策を提案するSlack通知およびWebコンソールの実装を行なっていました。
実装されたもの
Slack通知ではCloudWatchアラームの内容に加えて、具体的に問題がありそうなリソースについても記載を加えています。

エラーログや対処をまとめたRunbookを元に推奨されるActionが提案されるWebコンソール

構成
CodeTalkで解説されたソリューションの構成は以下の通りです。

このセッションではデータのembeddingおよびsemantic searchはfaissを使用して行っていましたが、フルマネージドのBedrock Knowledge Baseでも実現可能と思っています。
処理の流れは以下の通りです。
1. KubernetesのログやRunbookのベクトル化
KubernetesのログやRunbookをチャンクに分割し、埋め込みモデル(Titan Text Embeddings V2)でembeddingを行い、ベクトルストアに保存します。
ユーザーの質問処理
ユーザーが「なぜ私のアプリの応答時間が長いのか?」といった質問を入力します。この質問も埋め込みモデルによってembeddingを行い、ベクトル化されます。セマンティック検索
ユーザーの質問のベクトルデータをもとに、ベクトルストアでベクトルの近傍検索が行われ、質問に関連するKubernetesのログやRunbookが取得されます。コンテキストの構築
セマンティック検索によって得られた関連情報がユーザーの質問と組み合わされ、コンテキストが構築されます。プロンプト拡張
構築されたコンテキストと元のユーザーの入力が結合され、プロンプトが拡張されます。大規模言語モデルでの応答生成
拡張されたプロンプトがAmazon Bedrockの基盤モデル(Amazon NovaやClaude3.5等)に送られ、対応策を含む応答が生成されます。

このセッションで作られたソースコードおよび資料は以下のリポジトリに格納される予定です。
まとめ
実際に実装されたコードを見ながら、ソリューションの解説を受けると、具体的な手順が分かりやすく、すぐに手を動かしたくなりました。
EKSの運用はハイコンテキストで、CloudWatchやDatadogと睨めっこすることが多いですが、生成AIを活用してこれらの作業を少しでも効率化できないか模索していきたいと思います!
Gen AI incident detection & response systems with Aurora & Amazon RDS (DAT307)
EC基盤開発本部SRE部商品基盤SREブロックの佐藤です。私は生成AIを活用したインシデント検知および対応(IDR)を行うシステムのワークショップに参加しました。
ワークショップの概要
AWSには以前より、AWS Incident Detection and Response というエンタープライズサポート向けの有人インシデント対応サービスが提供されています。今回のワークショップは人間ではなく生成AIを活用し、インシデントの検知および対応を自動化するシステムをハンズオン形式で構築しました。
Amazon Bedrockについて
Amazon Bedrockがどのようなサービスか整理します。
- Amazon Bedrock:主要なAI企業やAWSが提供する生成AIの基盤モデル(Foundationモデル・FM)を簡単に統合・利用できるサービス。インフラ管理不要で機械学習に関する専門知識がなくても利用可能。
- Amazon Bedrock Agents:生成AIエージェントを簡単に作成できるBedrockの機能。ユーザーのリクエストに対して基盤モデルを拡張して追加情報を収集し、複数のステップに分解したアクションを実行する。
- Amazon Bedrock Knowledge Bases:基盤モデルの検索拡張生成(RAG)を行うために、様々なデータソースと接続させるサービス。
関連資料
用語
ワークショップの冒頭では前提となる用語の説明がありました。
- 基盤モデル(FM):事前トレーニングされたディープラーニングモデル。知識が不十分な場合、FMはハルシネーションと呼ばれる誤った出力を生成する傾向がある。
- ベクトルの埋め込み:データを数値表現に変換しベクトルとしてマッピングしたもの。データ間の固有の特性と関係性を捉える数学的表現。
- 検索拡張生成(RAG):ハルシネーションの対策として新しいデータソースから情報を取得するための情報検索コンポーネントを導入すること。
- エージェントワークフロー:データを収集し、そのデータを使用して自己決定したタスクを実行し、定められた目標を達成できるプログラム。目標は人間が設定するが、AIエージェントはその目標を達成するために必要なアクションを独自に選択する。
システム概要

使用するサービス
- Amazon CloudWatch
- Amazon DynamoDB
- Amazon Bedrock
- Amazon Aurora PostgreSQL
- Amazon API Gateway
- AWS Lambda
処理の流れ
- AuroraとRDSをCloudWatchが監視し、インシデントが発生するとその情報をDynamoDBに書き込む。
- 事前にインシデントに対するRunbooksをS3にアップロードしBedrock Knowledge Basesと同期し基盤モデルの拡張(RAG)を行う。
- ユーザーはWebアプリケーションを操作してインシデントとRunbookの確認、AuroraとRDSの復旧をする。
- ユーザーからの指示によって、Bedrock AgentsがBedrock Knowledge BasesからRunbookの取得とAuroraとRDSの設定変更を行う。
ワークショップの内容
ワークショップは以下の順番で進みました。
- セットアップ
- 基盤モデルの拡張
- エージェントの設定
- インシデントのシミュレート
- Webアプリケーションをデプロイし復旧する
1. セットアップ
このワークショップでは基盤モデルとしてAnthropicのClaude3とAmazon Titanを利用しました。
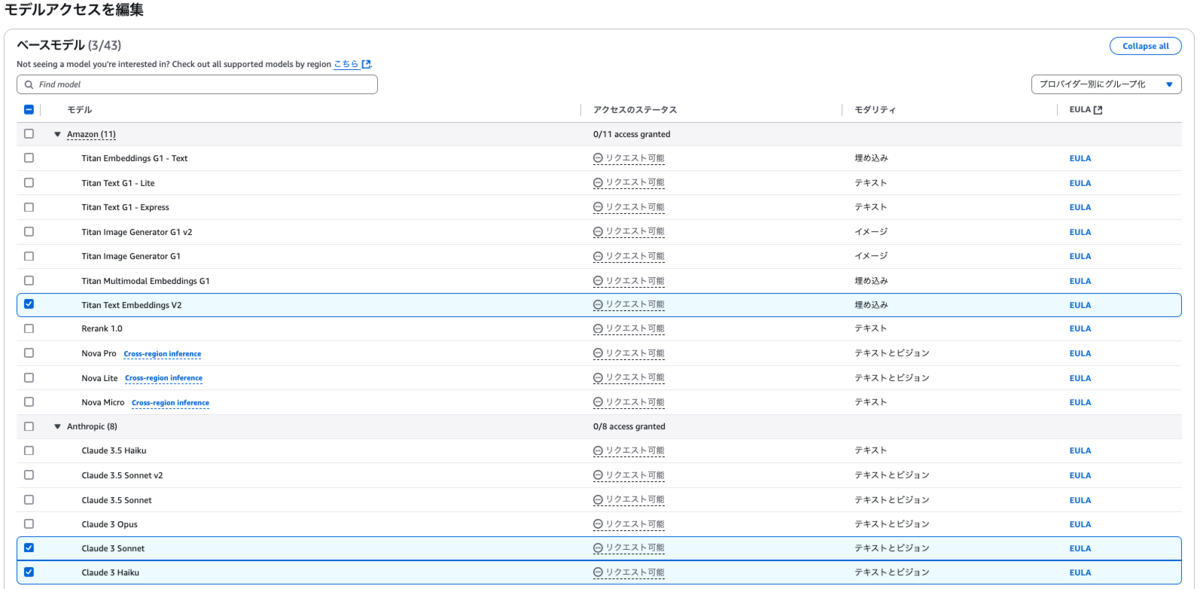
なお、Bedrock Knowledge Bases、Bedrock Agentsは事前に用意されたものを使用しました。
2. 基盤モデルの拡張
Runbookと呼ばれるインシデントの対応手順が書かれたMarkdownファイルをBedrock Knowledge BasesにアタッチしたS3へアップロードしました。以下は、CPUインシデントに対するRunbookの例です(引用元)。
# Title Runbook to remediate RDS CPU Utilization alert ## Issue PostgreSQL database instance is running out of high CPU utilization. ## Description This run book provides the step by step instructions to address the high CPU Utilization in the RDS instance. Follow the instructions in this run book to remediate the high CPU utilization incident. ## Steps 1. Check if the RDS instance is in available state. If the status is available, continue otherwise abort the process. 2. Get the current CPU utilization metrics for the last 1 hour for the RDS instance. . 3. Check if the maximum CPU utilization from the CPU metrics is above 80% , then scale up the RDS instance to the next availabe instance type.
アップロードしたRunbookは、Bedrock Knowledge Basesのコンソール上で「同期」を実行することで、埋め込まれた基盤モデルによって解析されます。

解析されたデータは、小さなブロック(チャンク)に分割され、PostgreSQLの拡張機能である pgvector を利用してベクトルデータとして保存されます。これだけでRAGによる基盤モデルの拡張とベクトル埋め込みが簡単に実現できました。
3. エージェントの設定
Bedrock Knowledge BasesをBedrock Agentsにアタッチし、アクショングループと呼ばれるAIエージェントが実行するLambda関数を確認しました。下記はアクショングループに定義されたDBインスタンスの状態を確認する関数です(引用元)。
def check_rds_state(db_instance_identifier): """ Function to check the current state of the RDS cluster """ try: response = get_instance_details_helper(db_instance_identifier) status = response['DBInstanceStatus'] message = f"The RDS status is {status}." if status != 'available': message += " It is unavailable state, please try again later." lambda_logger.info(message) return message except Exception as e: lambda_logger.error(f"Error checking status: {str(e)}") lambda_logger.error(traceback.format_exc()) return f"Error: {str(e)}"
4. インシデントのシミュレート
pgbench を使用してデータベースのCPUまたはI/Oに高負荷のワークロードを発生させ、CloudWatchアラームをトリガーします。そのインシデント情報がDynamoDBに正しく保存されることを確認しました。
5. Webアプリケーションをデプロイし復旧する
Streamlit で構築したWebアプリケーションをデプロイし、以下の動作を確認しました。
- DynamoDBから取得したインシデント情報を画面に表示する。
- UIを操作してBedrock Knowledge Basesにインシデントを照会し、関連するRunbookを取得する。
- UIを操作してBedrock Agentsを呼び出す。Bedrock AgentsはBedrock Knowledge BasesからRunbookを取得し、ステップに基づいて、対応するアクショングループの関数を呼び出して実行する。
さらに、時間が足りず完成には至りませんでしたが、DBのインフラストラクチャに関する質問に答えるエージェントを作成する項目もありました。これはBedrock AgentsからDynamoDBやAurora、RDSなどのデータベースにリアルタイムでクエリを送信し、情報を取得することで実現する内容でした。
感想
初めて生成AIを活用したシステムを作成しましたが、作業自体は非常に簡単で、Amazon Bedrockの使いやすさに感心しました。生成AIの複雑さをうまく隠して、多くの人に普及させようとするAWSの意図が伝わってきた気がします。今までは、業務にどのように利用すべきか具体的なアイデアが浮かんでいませんでしたが、このワークショップを通じて、普段の運用にも取り入れられる可能性があると感じました。今後はこの経験をもとに、業務で生成AIを活用する方法を検討していきたいと思います。
Achieving scale with Amazon Aurora PostgreSQL Limitless Database (DAT420)
ZOZOMO部SREブロックの蔭山です。普段はFulfillment by ZOZOやZOZOMOのSREを担当しています。
今回は興味を持っていたサービスの1つであるAmazon Aurora PostgreSQL Limitless Databaseがどのように実現されているかが紹介されたセッションに参加しました。その内容について簡単ではありますがご紹介します。
内容
今回のセッションはBreakoutセッション形式で実施され、以下の内容が話されました。

まずデータベースでのスケーリングの問題が取り上げられました。データベースでスケーラビリティを確保するにシャーディングが必要となる、シャーディングを実現しようにも以下の4つの大きな問題があると述べられました。
- Querying(クエリの実行)
- Consistency(一貫性の維持)
- Re-sharding(再シャーディング)
- Database capacity management(キャパシティ管理)

それらの問題を解決するためにAmazon Aurora PostgreSQL Limitless Databaseが誕生したとのことです。ちなみにAuroraが誕生してちょうど10周年とのことでした。

Aurora PostgreSQL Limitless Databaseの特徴について、サンプルとしてCustomer(会員)、Order(注文)、Tax Rate(税率)を使って説明されました。


このあとは実際のAurora PostgreSQL Limitless Databaseのアーキテクチャについて詳しく説明がありました。
シャードグループは通常のAuroraクラスタと同じ操作が可能となっており、それぞれ以下の責務を担っているとのことでした。
- Distributed transaction routers(Routers): スキーマ構成やシャーディングされたデータの位置情報を保持
- Data access shards(Shards): シャーディングされた各データを保持

PostgreSQLと同じトランザクションレベルを獲得するため、各ノードで正確に時間を同期できるクロックサーバーを実現し、時間をベースにトランザクションを実現しているとのことでした。

クエリ実行に関してはPostgreSQL互換を保ちつつ、独自にカスタマイズされたDBエンジンが実行計画を作ってクエリの実行を担っているとのことでした。

実際に測定されたパフォーマンスについても語られており、複数のアプリケーションから1秒あたり250万回以上の更新処理を行ってもレイテンシは数ミリ秒程度とのことでした。

まとめ
今回深くまで説明いただいたことでAurora PostgreSQL Limitless Databaseがどれほど工夫されて実現されているかを身近に感じることができました。
将来使いたいと思っていたデータベースサービスの1つだったので、ユースケースを想定しやすくなったのも良かったなと感じました。
IT transformation for nonprofits: Maximize impact with modernization (IMP205)
YSHP部YSHPブロックの川俣です。YSHP部では主にZOZOとYahoo!ショッピング間のデータ連携を担当しております。今後システムリプレイスを控えており、そのタイミングでモダン化も予定しております。今回はモダン化の流れや手法を学習するChalk Talkに参加いたしましたので紹介させていただきます。
まず今回のChalk Talkの大きな要素としては下記5つで構成されていました。

まずは「Why modernize?(なぜモダン化するのか?)」という目的とメリットの確認です。
「機敏性、スピード、革新性」「パフォーマンスと復元力」「効率性とコストの最適化」
これらは「モダン化」自体が目的とならないように事あるごとに立ち返りたい観点です。YSHP部としては効率性を重視して運用改善を図りたいところです。

「Strategy(戦略)」の中ではマネージドサービスを利用することで「機敏性」を確保しつつトータルの運用コストを下げるという大まかな戦略について話がありました。その中で述べられていた一文を紹介させてください。
Migration and modernization is a journey
私が参加したその他のセッションでも共通してモダン化を「旅」と表現していました。「決断疲れ」や「スキルギャップ」などシステム面以外の課題も解決していき目的に辿り着く様はまさに「旅」と言っても過言ではないと感じます。

次に「Modernization pathways(モダン化の道筋)」です。段階的に何から始めれば良いのか悩みがちな部分なので体系的なアプローチを示して貰えるのは非常に助かります。この部分はモダン化を推進していく際のステップになるため重要なポイントです。

「Whiteboarding」のセクションでは講師の方がその場で参加者の方のシステム構成をヒアリングし、ホワイトボードにモダン化したパターンを示していきます。左側がオンプレミス環境の構成図ですが、YSHP部の構成と近しいものがあり、既存構成は世界共通なんだなと非常に親近感を覚えました。
右側のモダン化後の構成図は複数AZ、なおかつAmazon ECSを想定した構成です。AWS A2C(App2Container)を利用しながらアプリケーション部分をコンテナ化していき運用していくケースです。A2Cを利用してコンテナをECRに登録し、コントロールプレーンはECS、データプレーンはFargateという構成です。Fargateを利用する事で運用管理のコストを少なくしていく狙いがあります。
既存アプリケーションをいきなりAWS Lambda等の複数サービスに分解せず、まずはコンテナ化していく手法は先述の「Modernization pathways(モダン化の道筋)」に沿った形です。

こちらは別のモダン化パターンです。オンプレのDBをVIEWを介し、AWS Schema Conversion ToolやAWS Database Migration Serviceを利用してDynamoDBに移行していくケースです。当該Chalk Talkでは触れられませんでしたがAWS DMSはスキーマの変換に生成AIを用いる機能が追加されました。この機能の詳細はAWS Database Blogの記事「New – Accelerate database modernization with generative AI using AWS Database Migration Service Schema Conversion」をご覧ください。

「Wrap-up」でまとめられた要点はこちらです。
- モダン化は価値実現のために複数の経路を採用しながら進める漸進的なプロセスです。
- 「どこから始めるべきか、何を使うべきか」という疑問を解決するために、「モダン化の道筋」を活用します。
- 「モダン化の道筋」に沿ったAWSサービスとパートナーツールをモダナイゼーションプラクティスに組み込みます。

AWSには、それぞれの状況や段階に応じて最適なサービスがあると改めて実感しました。今回具体的な手法やサービスを知れたことで今後のモダン化に対する熱量がぐっと上がりました! 「Modernization pathways(モダン化の道筋)」に沿って段階的なおかつ確実にモダン化を推進していこうと思います。
Security insights and innovation from AWS (SEC203-INT)
フロントSREブロックの江島です。ZOZOTOWNのエンドユーザーに近い部分(フロントエンド、BFF等)を担当領域としています。また、全社のAWS管理者としての役割も担っています。私からは「Security, compliance & identity」の分野におけるInnovation talkの内容を紹介します。
Innovation talkとは、AWSのシニアリーダーが登壇するトーク型セッションです。各分野の重要課題に関してAWSにおける最新の取り組みが紹介されます。BreakoutセッションやWorkshop等よりもやや抽象度が高めな内容かなと思います。セッションはAWSのCISOであるChris Betz氏を中心に進められました。内容としては、大きく3つのトークテーマに沿った話がありました。
1つ目のトークテーマは「セキュリティに関するオーナーシップの重要性」についてです。このトークテーマでは、どんなに優れたツールがあってもオーナーシップ無しではセキュリティは成立しないということが述べられ、それを達成するための手段として「ガーディアンプログラム」が取り上げられました。これは、各開発チームの一部メンバーをセキュリティ有識者に育て上げ、開発チームの内側からセキュリティ推進を図っていくというものです。

2つ目のトークテーマは「最新サービス紹介」でした。Vice President & Distinguished EngineerのBecky Weiss氏より、考え方の根底にあるメッセージと共に最新のセキュリティサービスの紹介がありました。

特に非常に興味深かったのがDeclarative Policies(宣言型ポリシー)です。

これは以下のような特徴を持ちます。
- AWSサービスの設定状態を定義するポリシー機能
- 宣言されたポリシーに反する設定は拒否される(強制される)
- メンバーアカウントから設定変更を行おうとした場合にはカスタムエラーメッセージを返せる
- 現時点ではEC2の一部ユースケースのみが対象(サポート範囲は今後拡大される予定)
個人的にはAWS Security Hubのコントロールに対応するポリシーが増えてくればコンプライアンス遵守を効率よく進められそうな気がしており、今後のサポート範囲拡大に期待しています。
3つ目のトークテーマは「量子コンピューティングや生成AIといった最新技術に対するセキュリティについて」でした。量子コンピュータによる攻撃にも耐えることができる暗号アルゴリズムの開発、生成AIの時代においてモデルに対するセキュリティを確保するための仕組みが紹介されました。
最後は挑戦的なメッセージで締めくくられ、非常に刺激を受けました。

全体感を掴むためにも自身の興味がある分野についてはInnovation talkを聴講して頂くことをお勧めします。
Next-generation SaaS tenant isolation strategies (SAS312)
こんにちは。計測プラットフォーム開発本部バックエンドブロックの髙橋です。普段はZOZOMAT、ZOZOGLASS、ZOZOMETRYなどの計測プロダクトのバックエンドの開発・運用をしています。
直近リリースしたZOZOMETRYはSaaS型のサービスです。そのため、よりSaaSプロダクトの設計について知見を深めたく、「Next-generation SaaS tenant isolation strategies」というセッションに参加しました。本セッションではまず、「SaaSでのテナント分離とは?」という基本的な部分から始まりました。

その後、次の内容を講師が説明しました。
- テナント分離をどのようにして行うか?
- サイロモデル
- ブリッジモデル
- プールモデル

- なぜやるか?
- プライバシー、セキュリティのため
- コンプライアンス強化
- スケーラビリティ、コストコントロールを含めたプロダクトのアジリティを上げるため

一般的にテナントを分離する際はJWTの中にテナント情報を入れ込み、その情報からどのテナントのリソースにアクセスするかを判別するような設計が多いかと思います。ZOZOMETRYでは、JWT内のCognitoのアカウントIDを使ってテナントの照合をしていました。

本セッションでは、STSとJWTを用いた次世代のテナント制御について説明がありました。具体的には、JWTをSTSのAssumeRoleWithWebIdentityと組み合わせて使用し、一時的な認証情報を取得する方法が紹介されました。これにより、JWT検証の責務をSTSに移譲することが可能になり、アプリケーション側でのJWT検証の実装負荷やバグによるセキュリティ上の脆弱性のリスクを軽減できるというメリットがあります。ご興味のある方はセッション中に紹介された以下のGitHubリポジトリに関連した要素を持ったコンテンツがありますので、触れてみることをおすすめします。
- https://github.com/aws-samples/data-for-saas-patterns/tree/main/samples/tenant-isolation-patterns
- https://github.com/aws-samples/aws-saas-tenant-usage-and-cost-attribution
- https://github.com/aws-samples/aws-saas-operations-workshop/tree/v2
- https://github.com/aws-samples/aws-saas-cell-based-architecture
大きめのセッションだとどうしても登壇者→聴衆の一方向になりがちですが、Chalk Talkでは講師が参加者に話を振ったり、参加者側がセッション中に質問出来たりしたことはとても新鮮でした。
Build resilient, high-performance applications with Amazon Aurora DSQL (DAT334)
ブランドソリューション開発本部WEARバックエンド部SREブロックの小林です。ここからは新規発表されたDSQLに関連するセッションを2本ご紹介します。まずは私からDSQL概要や従来のAuroraデータベースとの違いに関するセッションを、続いてDSQLアーキテクチャにDeep diveしたセッションとWorkshopについて遠藤より紹介いたします。
このセッションはChalk Talk形式でAmazon Auroraの歴史やAurora DSQLの特徴について解説されました。スライドタイトルとセッション名が不一致ですが、セッション内容に違いはありませんのでご安心ください。

まずはAuroraの歴史について言及されました。Amazon Auroraは2014年にMySQL互換としてリリースされ、2017年にPostgreSQL互換にも対応しました。その後もAurora Serverless、Limitless Databaseなど様々なサービスを発表しています。

続いてAurora DSQLの紹介です。DSQLはPostgreSQL互換の分散データベースです。2024/12/4セッション当日の時点ではPostgreSQL 16互換としてプレビューされています。クエリの実行結果や実行計画にほとんど違いはないとされ、JOINやAGGREGATE、DML、DDLもサポートされています。また、Ruby on Railsをはじめとしたほとんどのドライバも標準ドキュメントの通りに動くと説明されていました。

しかし、一部未対応の機能も存在します。外部キー制約やPL/pgSQL、地理情報で使用するPostGISなどはサポートしていないようです。特に外部キー制約は分散システム上でオーバーヘッドになりうるため、初期リリースでは対応が見送られるとのことでした。ロードマップ自体には含まれているそうなので、今後のリリースに期待です。
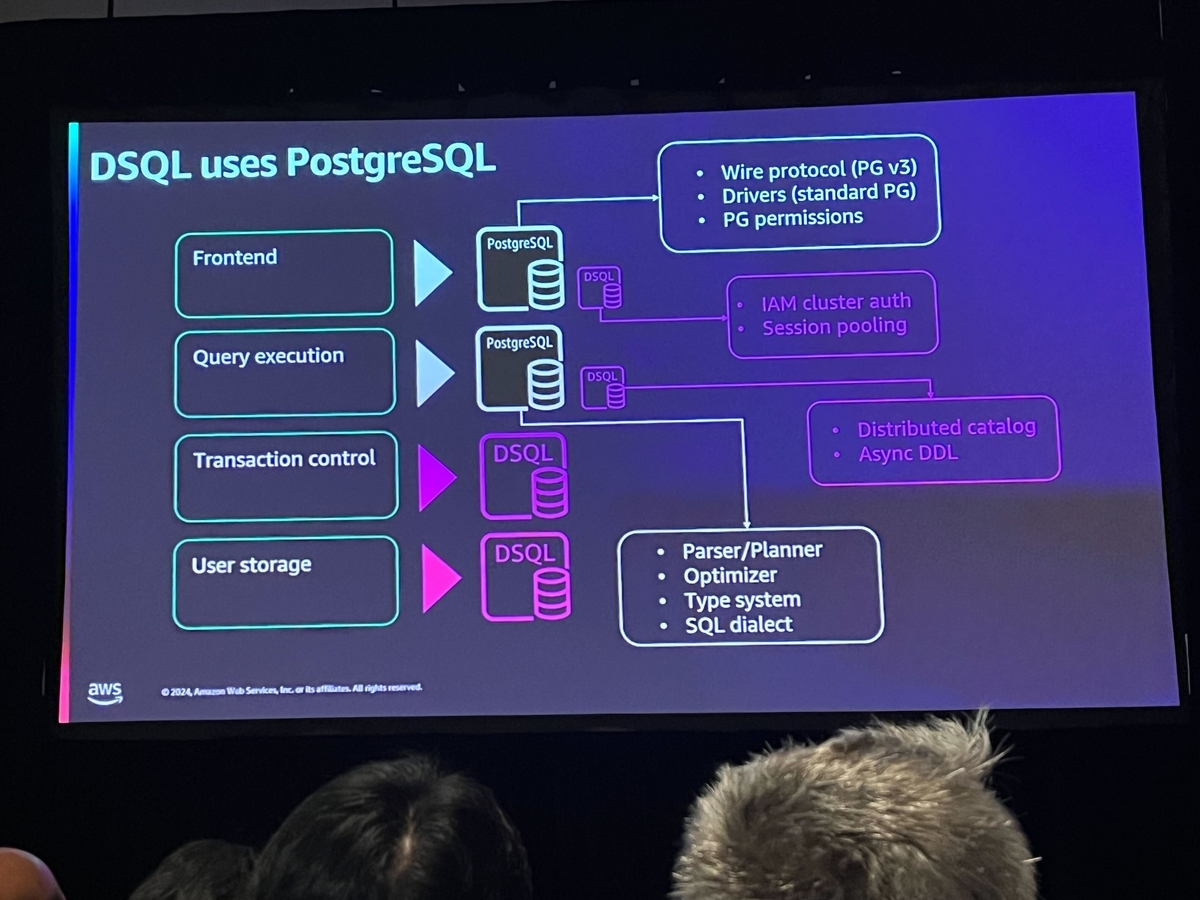
この中でAuroraとDSQLの違いについても取り上げられました。Aurora自体はPostgreSQLやMySQLのオープンソースバージョンを基盤にして作成されています。しかし、DSQLはPostgreSQLのコードを「約半分」利用しつつ、独自に構築した箇所が存在するという説明がありました。
具体的にはFrontend、Query executionはPostgreSQL由来ですが、Transaction control、User storageはDSQL独自のものです。User storageには「ジャーナル」という機能があり、これはDSQLの根底にある技術だと説明されていました。ジャーナルはデータの永続化を確保するための中心要素であり、ストレージへの書き込みとは異なり、書き込みが確認された時点で「永続化」とみなされるとのことでした。この仕組みにより、ストレージ層へのアクセスが大幅に最適化され、システム全体のスループットが向上します。
続く大きなトピックはトランザクション管理の同時実行制御に関する説明です。DSQLでは同時実行制御に楽観的同時実行制御(OCC:Optimistic Concurrency Control)を採用しています。ロックを使用しないOCCを採用することで、クライアントの遅延や長時間実行されるクエリによる他トランザクションへの影響を最小限に抑えるとのことです。
個人的にはこの同時実行制御部分に注意が必要だと感じました。たしかにOCCではPCC(悲観的同時実行制御:Pessimistic Concurrency Control)のように行やテーブルに対してロックを取得しません。しかし、コミット段階には競合のチェックはもちろん行われるため、競合が発生した場合は何らかの対策が必要です。スピーカーもこの点には触れており、アプリケーション側でリトライやアボートのロジックを組み込む必要があります。

その他マルチリージョンにおけるActive/Active構成の仕組みや、分散データベースのコア部分である時刻同期についても解説されました。特に自動復旧メカニズムへの信頼性が強調され、他リージョンとのデータ整合性を確実に維持する仕組みが解説されました。
まとめ
DSQLはAuroraと名前を冠しているものの、ある意味Auroraとは別のデータベースとして位置づけられるべきものであると感じました。同時実行制御や各種機能のサポート状況など、まだまだ検証が必要な箇所は多くありますが、今後のリリースに期待が持てる内容でした。どこかで実際の検証を通したアウトプットができればと思います。
Deep dive into Amazon Aurora DSQL and its architecture (DAT427)
はじめに
EC基盤開発本部SRE部カート決済SREの遠藤です。普段はカート・注文関連のマイクロサービス構築と、DBREとしてデータベースの保守・改善に携わっています。
今回のre:Inventの新発表の1つであるAurora DSQLについて、Deep diveセッションとWorkshopに参加しました。
Aurora DSQLのアーキテクチャ
前述の通りTime Sync Serviceによって正確な時刻同期が可能になりました。これにより分散DBの課題であるノード間のレイテンシの問題がある程度解消されています。その上で非常に興味深い技術選定とアーキテクチャ選定によって、強い整合性と短いレイテンシを実現しています。

Deep diveセッションでは、Aurora DSQLのアーキテクチャについて解説されました。特徴はレイヤー間の独立性です。各レイヤーは特定のワークロードの要求に基づいて、水平方向に独立してスケール可能です。
読み取りが多いワークロードではStorageレプリカが増加し、書き込みが多い場合はJournalというコンポーネントが分割され水平にスケールします。

以下が各コンポーネントの概要です。
1.Router
Transaction and Session Routerと紹介されていました。PostgreSQLプロトコルを受け取りPG Bouncerのように接続プーリングを提供します。トランザクションの開始時に各接続を適切な場所にルーティングします。
2.Query Processor
リクエストはRouterを通してQuery Processorへ流れます。Query ProcessorはPostgreSQLのデータベースエンジンにあたり、AWS Lambdaの高速なスケーラビリティを可能にしているFirecracker上で稼働しています。
書き込みはQuery Processor内に留まり直接Storageへはアクセスしません。Commit処理は後続のAdjudicatorが担い、Query Processor間の通信も不要なためスケーラビリティが確保されています。

3.Adjudicator
Adjudicatorは、書き込み時に複数のトランザクション間の競合を検証し処理の分離性を確保します。Query Processorは複数のAdjudicatorに対して「このトランザクションをコミットしても良いか?」と問い合わせます。問題なければAdjudicatorがJournalへログを書き込みトランザクションを終了します。
分散DBのため、複数のAdjudicatorが協調して動作し、分散合意アルゴリズムを使用してデータの一貫性を保ちます。従来、NewSQLと呼ばれる他の分散DBではPaxos、Raftといったアルゴリズムが主流ですが、DSQLはよりシンプルでパフォーマンスの優れた異なるアルゴリズムを採用しているようです。
ここについてはさらなる情報公開を期待したいです。
4.Journal
Journalはデータの永続性と原子性を保証します。ログをStorageへ書き込みます。このJournalは、S3、DynamoDB、Kinesis、Lambdaなど多くのAWSサービスを支えるインフラの一部として10年以上かけて構築されたもののようです。必ず1つのJournalがStorageへ書き込むことで原子性が保たれています。
5.Storage
効率的なデータ検索に特化したストレージエンジンです。役割が分離されているため、永続性や同時実行制御の責任は負いません。
パフォーマンス最適化策の1つとして、本来Query Processor上で行われる一部の処理をStorage側にプッシュダウンできます。WHERE句のフィルター操作などをストレージノードで行うことにより、通信にかかるラウンドトリップとデータ量の削減に繋がりレイテンシが向上します。
Workshop
最終日にはDSQLワークショップが開催されたので参加しました。大変人気で予約できなかったのですが、1時間並んで当日参加できました。

実際にAurora DSQLを構築して以下のようなことを確認しました。
- マルチリージョンでの書き込みとOCCによる楽観ロックの挙動
- データモデリングのベストプラクティス
- アプリケーション側のリトライを考慮した実装
DSQLはPostgreSQL互換ですが、FK制約が作成できなかったり、ビューや一時テーブルが使えないなど、制約も大きいです。今後のアップデートに期待したいです。
まとめ
Deep diveセッションとWorkshopに参加して、分散DBそのものにとても興味が湧きました。正確な時刻同期など技術の発展に伴い少しずつCAP定理の壁を突破していると実感しました。新しい概念や用語も多く理解するまで苦労しましたが、腰を据えて分散DBのアーキテクチャを学ぶ良い機会になりました。
The Future of Kubernetes on AWS (KUB201)
計測システム部SREの纐纈です。今回2回目のre:Invent参加となりました。私からはAmazon EKS周りのアップデートや今後の開発方針についてのセッションについてまとめたいと思います。
こちらのセッションでは、AWSのKubernetesプロダクト部門統括であるNathan Taber氏が、Kubernetesの最新動向とAmazon EKSの進化について解説しました。
Kubernetesは多くの企業で本番環境に導入されている一方で、その運用は特に大規模環境や分散環境で複雑化しています。AWSはこれに対応するため、Amazon EKSの機能強化を継続的に行っています。
今回のセッションでは以下の新機能や改善点などが紹介されました。
- Extended Version Support: Kubernetesバージョンのサポート期間を延長。
- Upgrade Insights: アップグレード時に互換性や影響を事前に把握できるツール。
- Enhanced Control Plane Observability: コントロールプレーンの状態を可視化し、トラブルシューティングを容易化。
サービス開始以後7年が経過しようとしていますが、より使いやすいプラットフォームになるよう様々な改善が施されていることも示されていました。

さらに、EKS Auto ModeやEKS Hybrid Nodesといった新機能により、Kubernetes運用の自動化やハイブリッド環境の対応が一層強化されました。
特にEKS Auto Modeに関しては、クラスタのノード管理が不要になり、適切なリソースをAWS側で選択してくれるのでコスト最適化にも繋がります。

最後に、AWSの今後の方針としては、マルチクラスター管理や開発者体験の向上に注力し、Kubernetesの運用をよりシンプルで効率的にする方針を示しています。Kubernetesの専門知識を持ったチームでなくともEKSを運用できるようにすることで、より多くのユーザーに使ってもらえるプラットフォームにすることを目指しているようです。

おわりに
AWS re:Invent 2024に参加し、Keynoteやセッション、EXPOで多くのことを学べました。また、国内外のエンジニアの方々と交流し、日本では味わえないことを体験できるのが現地参加の醍醐味です!
今回得た知見を社内外に共有しながら、これからもAWSを活用してプロダクトとビジネスの成長に貢献していきます。
ZOZOではAWSが大好きなエンジニアを募集しています。奮ってご応募ください!