



こんにちは、MA部の谷口(case-k)と@gachi-muchi-engineerです。
私達のチームではマーケティングオートメーションシステムの開発や運用をしています。ZOZOTOWNではマーケティングオートメーションによって、メールやPush、LINEなど各チャンネルに対して日々配信しています。配信方法は大きく2種類に分けられ、特定のユーザーセグメント向けの「マス配信」と、個別のユーザーに最適化された「パーソナライズ配信」があります。パーソナライズ配信基盤を社内ではリアルタイムマーケティングシステム「RTM」と呼んでいます。リアルタイムマーケティングシステムは随分と前に作られたこともあり、現在リアルタイムマーケティングシステム全体のリプレイスを進めています。本記事ではリアルタイムマーケティングシステムで用いられている、リアルタイムデータ連携基盤をリプレイスした事例をご紹介します。
- 既存のリアルタイムデータ連携システムの紹介
- 既存のリアルタイムデータ連携の仕組み
- なぜリプレイスをしたのか
- リプレイス後の配信用リアルタイムデータ基盤
- 変更前後のデータを取得する方法を検討
- アーキテクチャ概要と処理の流れ
- 初回の全量データ連携
- 移行前後の評価
- 監視設計
- リプレイスによる改善点
- 今後の課題
- まとめ
- 最後に
既存のリアルタイムデータ連携システムの紹介
既存のリアルタイムデータ連携システムについて紹介します。既存のリアルタイムデータ連携システムでは配信処理に必要なデータをリアルタイムにSQL Serverから取得しています。SQL Serverの変更データを検知して、必要な加工処理を施し、リアルタイムマーケティングシステムへ連携しています。連携されたデータはリアルタイムマーケティングシステムにキャッシュされ配信処理で使われます。ZOZO固有のユーザIDを配信用のトークンへ変換したり、配信のトリガーとしても用いられています。例えば在庫切れを起こしていた商品が入荷されたのをトリガーに配信する仕組みがあります。
以降、リアルタイムデータ連携基盤を「Tracker」、連携されたデータを用いて配信処理をしているアプリケーションを「Analyzer」と呼びます。TrackerとAnalyzerを含む基盤がリアルタイムマーケティングシステム「RTM」です。本記事ではTrackerをリプレイスした事例をご紹介します。
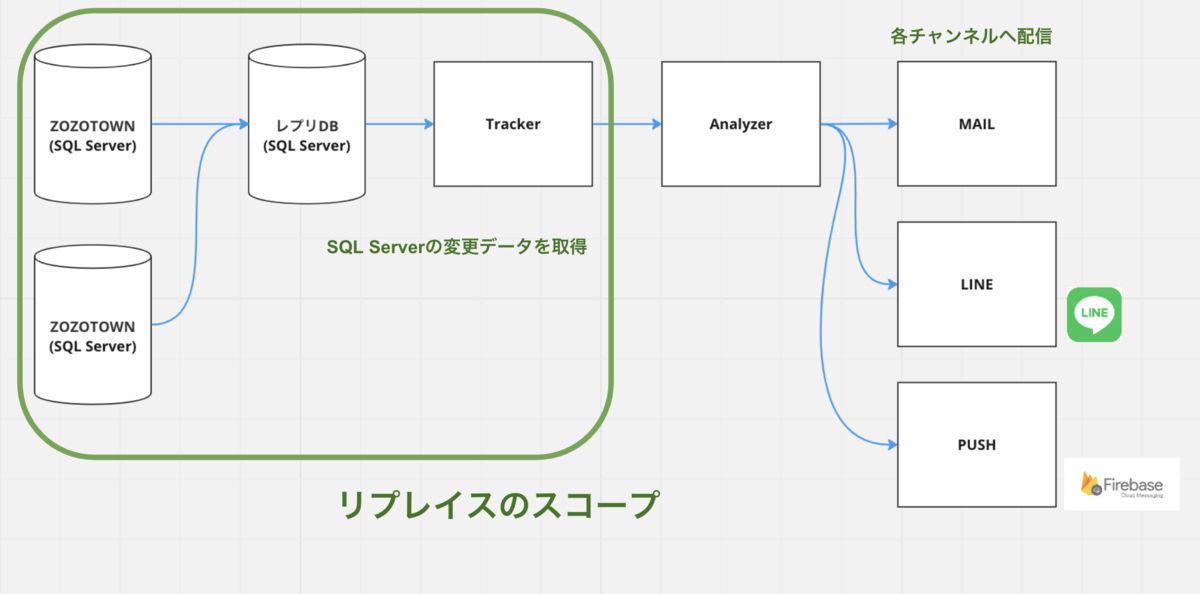
RTMについては以下の記事をご確認ください。
既存のリアルタイムデータ連携の仕組み
リプレイス前のTrackerのデータ連携の仕組みについてご紹介します。
TrackerはJavaで書かれており、Windows Server上のクラスタにデプロイされていました。TrackerはSQL Serverで変更のあったデータを取得し、加工処理を施した上でデータを連携しています。
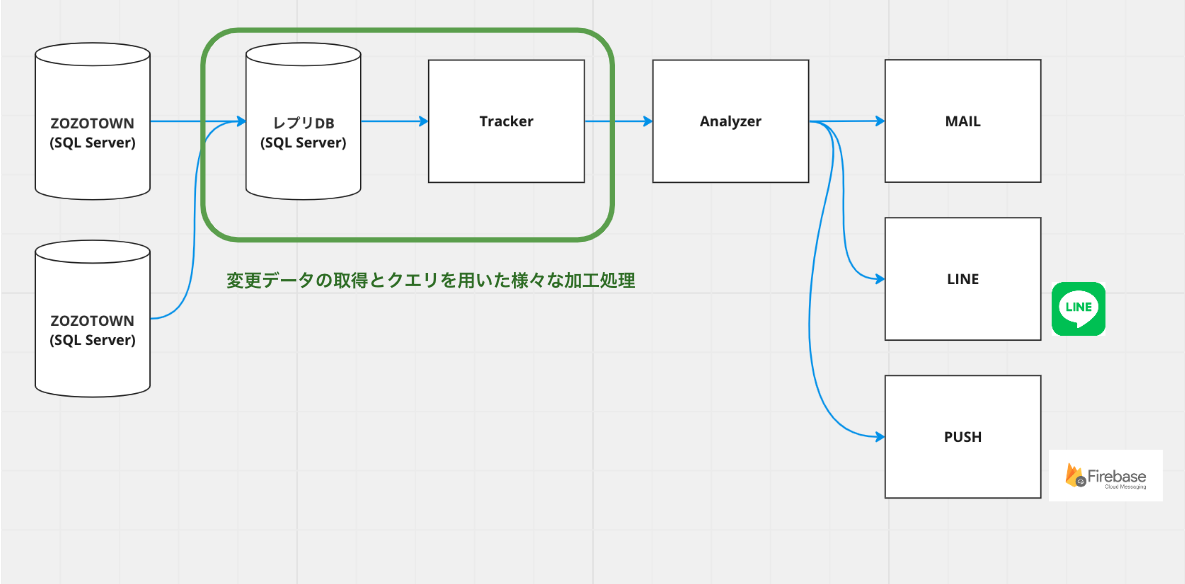
SQL Serverの変更データの取得にはChange Trackingと呼ばれるSQL Serverの機能を用いています。変更追跡を用いて60秒に1回SQL Serverへクエリを投げ、Analyzerで必要となる加工処理を施しています。加工されたデータは各テーブルごとに定義されたAnalyzerのエンドポイントへリクエストされます。リクエストされたデータはAnalyzerでキャッシュされています。
Trackerで定期的に投げている変更追跡クエリは以下のようになっています。
SELECT a.SYS_CHANGE_OPERATION as changetrack_type, a.SYS_CHANGE_VERSION as changetrack_ver, #{columns} FROM CHANGETABLE(CHANGES #{@tablename}, @前回更新したバージョン) AS a LEFT OUTER JOIN #{@tablename} ON a.#{@primary_key} = b.#{@primary_key}
変更追跡のバージョンは「SYS_CHANGE_VERSION」で取得でき、変更があるとインクリメントされます。最終同期した変更追跡のバージョン「@前回更新したバージョン」を渡すことで、渡したバージョン以降に変更のあったプライマリーキーを取得できます。取得したプライマリーキーを変更のあったテーブルと「LEFT JOIN」することで、変更後のデータを取得できます。変更追跡で取得できるのは変更後の最新のデータのみです。変更履歴の取得はできません。変更タイプには「SYS_CHANGE_OPERATION」には以下の3つの種類が存在します。どのような変更がSQL Serverで実施されたか確認できます。
| 変更タイプ | 説明 |
|---|---|
| I | 新規登録 |
| U | 更新 |
| D | 削除 |
SQL Serverの変更追跡については以下の記事をご確認ください。
また、Trackerでは変更前のデータも連携していました。Analyzerのキャッシュにはインメモリなデータストアを採用しており、KeyValue形式でデータを保存します。一部のキャッシュはKEYとしてSQL Serverのプライマリーキーではない、メンバーIDやEmailIDを用いています。データの削除や更新があった際これらのキャッシュに対して処理が必要でした。

変更追跡の仕組み上、取得できるのは変更のあったプライマリーキーと変更後のデータのみです。そこで、変更前のデータを取得するために、SQL Serverのトリガー機能を用いていました。トリガーとは、ストアドプロシージャに分類され、SQL Serverでイベントが発生したときに自動的に実行されます。今回は変更前のデータが必要であるため、トリガー機能の1つであるDMLトリガーを利用します。DMLトリガーはDMLイベントを介してデータを変更したときに実行されるトリガーです。DMLトリガーではdeletedとinsertedテーブルという2つの特別なテーブルが使用されます。この2つのテーブルはSQL Serverが自動で作成し、管理しています。
このテーブルの役割は以下の通りです。この2つのトリガーテーブルを用いて、Trackerでは変更前のデータを取得しています。
| テーブル名 | 説明 |
|---|---|
| deleted | 「DELETE」または「UPDATE」で変更される前に、影響を受ける行のコピー |
| inserted | 「INSERT」または「UPDATE」の後に、新しいまたは変更された行のコピー |
変更前のデータを取得する際は以下のようなトリガーを用いていました。物理削除された変更前のデータを取得する場合は直接deletedテーブルから取得するのではなく、データの整合性を担保するため別テーブルへ書き出したデータを利用していました。このテーブルからデータを取得することで、変更前のデータをAnalyzerに連携していました。
CREATE TRIGGER [Database].[SaveDeletedTable] ON [Database].[Table] AFTER INSERT, DELETE AS BEGIN -- SET NOCOUNT ON added to prevent extra result sets from -- interfering with SELECT statements. SET NOCOUNT ON; -- delete unused primary key from DeletedTable DELETE FROM Database.DeletedTable WHERE primary_key IN ( SELECT primary_key FROM deleted UNION ALL SELECT primary_key FROM inserted); INSERT INTO dbo.DeletedTable SELECT * FROM deleted; END
SQL Serverのトリガー機能の詳細は以下の記事をご確認ください。
なぜリプレイスをしたのか
なぜTrackerをリプレイスをしたのかご紹介します。
Windows Serverの運用負荷が高い
TrackerはWindows Server上で運用されていました。元々社外で作られた基盤であったため、チーム内にWindows Serverの知見も少なく、インフラのコード化やデプロイの自動化が難しいところもありました。また、Windows Serverのライセンス費用も高額でした。運用負荷の高いWindows Serverから脱却し、SQL Serverも廃止したいと考えていました。
リアルタイムマーケティングシステム全体のリプレイスに必要なデータ連携基盤が必要
リアルタイムマーケティングシステムの全体のリプレイスを進める上で、Analyzer以外の各マイクロサービスへもリアルタイムにデータ連携できる仕組みが必要でした。汎用的な要件に対応できる、同じような仕組みを作りたいと考えていました。今回のタイミングで新しく汎用的な基盤を構築し、Trackerをリプレイスすることにしました。
リプレイス後の配信用リアルタイムデータ基盤
先に述べたような課題があるため、既存の配信用リアルタイムデータ基盤の課題をリプレイスしました。以降リプレイス後の配信用リアルタイムデータ基盤を「新Tracker」、リプレイス前の基盤を「旧Tracker」と呼びます。
安全にリプレイスするための方針
既に述べたように旧Trackerでは変更前のデータをトリガー機能を用いて取得していました。リプレイスを進めるにあたり、変更前のデータを取得する方法を検討する必要がありました。本来は変更前のデータをリアルタイムマーケティングシステム側のキャッシュからとる方が望ましいです。しかし、連携先のAnalyzerに大きな手を加えることは困難でした。Analyzerのデプロイには数時間かかります。冒頭で紹介したとおり、インメモリなデータストアなので、障害等があった場合メモリ上のデータが吹き飛ぶ懸念もあります。データのリカバリにも8〜9時間ほどがかかり、ロールバックさせるのは難しい状態でした。また、移行対象となるクエリも22テーブルほどあり、クエリにて複雑な加工処理を施していました。
そこで、Analyzer側には手を加えない方針でリプレイスを進めることにしました。もしリプレイス後に問題が発生しても、Analyzer側に手を加えていなければ旧Trackerに切り戻しが可能です。また、リプレイスに伴うデータ評価の点でも、旧Trackerと新Trackerで出力されるデータを揃えることでデータの評価が可能になります。
変更前のデータをリアルタイムマーケティングシステムのキャッシュから取るようにすることは、新Trackerへリプレイス後でも可能で容易になります。今回のリプレイスが完了した後、対応していくことにしました。
変更前後のデータを取得する方法を検討
新Trackerでは、BigQuery上に構築された全社共通のデータ基盤であるリアルタイムデータ基盤から変更データを取得しています。リアルタイムデータ基盤にすることで、SQL Serverから脱却し、ライセンス費用等のコストや運用負荷の軽減、パフォーマンス面での改善が期待できます。
リアルタイムデータ基盤は数年前に作られ、同じようにSQL Serverの変更データを変更追跡の機能を用いて、リアルタイムでBigQueryへデータ連携しています。旧Trackerは全社共通のリアルタイムデータ基盤ができる前からあったシステムのため、独自でSQL Serverの変更データを集めていました。今回のリプレイスのタイミングでリアルタイムデータ基盤からデータを取得することにしました。
リアルタイムデータ基盤の詳細は以下の記事をご確認ください。
データソースをSQL Serverからリアルタイムデータ基盤にしたことで以下を考慮する必要がありました。
- データの重複
- データの順序
- 変更前データの取得方法
旧TrackerではSQL Serverの変更追跡を用いて、変更のあったデータを取得しているため、取得したデータの順序は保証されており、データの重複もありませんでした。
しかし、リアルタイムデータ基盤では運用しやすいよう「at-least-once」な設計になっています。データは重複し、遅延データも入るため順序は保証されていません。
また、旧TrackerではSQL Serverのトリガー機能を用いて変更前のデータを取得していました。リアルタイムデータ基盤へ移行したことで、データの整合性を担保しつつ変更前のデータを取得する方法の検討が必要になります。
変更前後のデータを取得するクエリ
これらの要件を満たすために、リアルタイムデータ基盤からデータを取得する際にデータの重複排除と順序保証をしています。また、変更前のデータは配信基盤へ連携済みの実績テーブルから取得するようにしました。具体的にどのようなクエリを実行しているかご紹介します。
変更前後のデータを取得するクエリはテーブル関数として用意しています。次のようにタイムスタンプを渡すことで、渡したタイムスタンプ以降に変更のあった変更前後のデータを取得できるようにしています。
テーブル関数の使い方は次の通りです。
SELECT * FROM `<table ID>`('2023-05-01')
テーブル関数には以下の2種類用意しています。
- 変更後のデータのみ取得する関数
- 変更前後のデータを取得する関数
テーブル関数内で具体的にどのような処理をしているかご紹介します。
変更ログの取得
リアルタイムデータ基盤より、変更のあったデータを取得しています。取得したデータは順序保証されておらず、データの重複もあります。詳細は後述の「変更ログの集計(変更データの取得)」でご紹介しますが、順序を保証し、データの重複を排除するためにプライマリーキーが必要になります。対象テーブルのプライマリーキーをカラムとして作ります。クエリ内の「last_sync_time」はTIMESTAMP型で、テーブル関数から渡されるパラメータです。最終同期したデータの時刻を渡すことで、該当時刻より後に変更のあったデータを取得できます。
取得期間を3時間にしているのは、リアルタイムデータ基盤の遅延データに対応するためです。前述したとおり、リアルタイムデータ基盤では順序保証されていないため遅延データを考慮する必要があります。実際3時間も遅れることはないのですが、最終同期された時刻である「last_sync_time」に遅延時間を考慮して変更データを取得しています。遅延データを考慮しないと、変更ログの取得の際にパーティション外となりデータが欠損してしまいます。変更ログの取得に旧Trackerのように変更追跡のバージョンではなく、タイムスタンプを用いているのも順序保証されず遅延した際のデータ欠損を防ぐためです。
streaming AS ( SELECT *, CONCAT(${join (",",primary_key)}) AS primary_key FROM `${project_changetracking}.${dataset_changetracking}.${table_changetracking}` WHERE bigquery_insert_time >= TIMESTAMP_SUB( CAST ( FORMAT_TIMESTAMP( "%Y-%m-%d" , TIMESTAMP_SUB(last_sync_time , INTERVAL 3 Hour) , "Asia/Tokyo" ) AS timestamp ) , INTERVAL 9 HOUR ) )
データ連携実績ログの取得
クエリで取得した変更前後のデータは実績テーブルに書き込まれます。以降「データ連携実績テーブル」と呼びます。データ連携実績テーブルの用途は後述しますが、データ連携実績テーブルに書き込まれたデータは書き込まれた順に各サービスへデータ連携されます。こうすることで、データ連携実績テーブルから変更前のデータを取得することで、Analyzerにキャッシュされているデータとの整合性をとることができます。
また、リアルタイムデータ基盤で取得したログから連携済みの実績を排除するためにも利用しています。この後の「変更前後のデータをマージ」にて説明します。
event_sync_logs AS ( SELECT realtime_message_unique_id, realtime_changetrack_ver, CONCAT(${ join (",",primary_key)}) AS primary_key,tracking_type FROM `${project}.${tracking_event_log_dataset}.${table_base}` WHEREå tracking_start_time >= TIMESTAMP_SUB( CAST ( FORMAT_TIMESTAMP( "%Y-%m-%d" , TIMESTAMP_SUB(last_sync_time , INTERVAL 36 Hour) , "Asia/Tokyo" ) AS timestamp ) , INTERVAL 9 HOUR ) )
取得期間を36時間にしているのは、変更前のデータの取得に全社共通データ基盤の全量データを用いるためです。データ連携実績ログで取得できるデータの範囲に変更前のログが含まれているとは限りません。例えば最後に更新されたログが5日前の場合パーティションの範囲外となります。
全社共通データ基盤では日次のバッチ処理で、SQL Serverにあるテーブルを全件BigQueryへ連携しています。もし、データ連携実績ログの取得の際、取得期間を数時間にしてしまうと、全社共通データ基盤では日次のバッチ処理連携後に変更のあった一部のデータが欠損してしまいます。日次連携された時刻よりも前から取得することでデータの欠損を防ぐことができます。データ連携側の遅延も考慮して、36時間としています。
全社共通データ基盤については以下の記事をご確認ください。
変更ログの集計(変更データの取得)
SQL Serverから共通基盤であるリアルタイムデータ連携基盤へのデータ連携には冒頭でご紹介したSQL Serverの変更追跡を用いています。テーブルのプライマリーキーと最新の変更追跡バージョンを集計し、変更履歴とJOINすることで最新の変更データを取得できます。この集計により、リアルタイムデータ基盤内のデータ重複を排除し、順序の保証もしています。変更後のデータのみ必要な場合は後述している変更前のデータを取得する処理は不要です。
streaming_latest_version AS ( SELECT primary_key, MAX (changetrack_ver) AS changetrack_ver_max, FROM streaming GROUP BY primary_key ), streaming_latest AS ( SELECT streaming.* FROM streaming INNER join streaming_latest_version ON streaming.primary_key = streaming_latest_version.primary_key AND streaming.changetrack_ver = streaming_latest_version.changetrack_ver_max ),
データ連携実績ログの集計(変更前データの取得)
データ連携実績ログより変更前のログを取得します。データ連携実績ログ内のデータを変更前のデータとして利用します。
streaming_before_latest_version AS ( SELECT primary_key, MAX (realtime_changetrack_ver) AS realtime_changetrack_ver_max FROM event_sync_logs WHERE primary_key IN ( SELECT primary_key FROM streaming_latest ) AND tracking_type = 0 GROUP BY primary_key ), streaming_before_latest AS ( SELECT a.* FROM streaming AS a INNER join streaming_before_latest_version AS b ON a.primary_key = b.primary_key AND a.changetrack_ver = b.realtime_changetrack_ver_max ),
データ連携実績ログに含まれていない変更前データの取得
前述の「データ連携実績ログの取得」で述べたとおり、変更前のログがデータ連携実績ログに含まれていない場合があります。データ連携実績ログに変更のあったプライマリーキーの変更前データがない場合は日次の全量データから変更前のデータを取得しています。データの整合性の観点でも、全量データから取得した変更前のデータはAnalyzerにキャッシュされているデータとも一致するため問題ありません。
daily_before_latest AS ( SELECT streaming_latest_id.massage_unique_id, "${dataset}" AS database_name, "${table_base}" AS table_name, CAST (NULL AS string) AS changetrack_type, CAST (NULL AS int64) AS changetrack_ver, CAST (NULL AS int64) AS changetrack_last_sync_ver, CAST (NULL AS timestamp) AS changetrack_start_time, CAST (NULL AS timestamp) AS bigquery_insert_time, streaming_latest_id.primary_key, ${join (",\n ",columns)} FROM ( SELECT *, CONCAT(${ join (",",primary_key)}) AS primary_key FROM `${project_snapshot}.${dataset_snapshot}.${table_base}_20*` AS snapshot_table WHERE _TABLE_SUFFIX IN ( SUBSTR( FORMAT_TIMESTAMP( "%Y%m%d", TIMESTAMP_SUB(last_sync_time, INTERVAL 1 day), "Asia/Tokyo" ), 3 ) ) ) AS snapshot_table INNER join ( SELECT massage_unique_id, primary_key FROM streaming_latest ) AS streaming_latest_id ON snapshot_table.primary_key = streaming_latest_id.primary_key WHERE snapshot_table.primary_key NOT IN ( SELECT primary_key FROM streaming_before_latest_version ) )
変更前後のデータをマージ
変更後と変更前のデータをマージして、変更前後のデータを取得しています。変更前後のデータを識別できるよう「tracking_type」を付与しています。変更後は「0」変更前は「1」としてます。また、実績ログを用いて連携済みのデータは排除しています。重複排除にはメッセージ単位でユニークとなるメッセージID「realtime_message_unique_id」を利用しています。
SELECT massage_unique_id AS realtime_message_unique_id, 0 AS tracking_type, * FROM streaming_latest UNION ALL SELECT CONCAT(massage_unique_id, "1") AS realtime_message_unique_id, 1 AS tracking_type, * FROM streaming_before_latest UNION ALL SELECT CONCAT(massage_unique_id, "2") AS realtime_message_unique_id, 1 AS tracking_type, * FROM daily_before_latest) WHERE realtime_message_unique_id NOT IN ( SELECT realtime_message_unique_id FROM event_sync_logs )
このようなクエリを用いて、変更前後のデータを取得しています。
アーキテクチャ概要と処理の流れ
新Trackerのアーキテクチャ概要と処理の流れについてご紹介します。
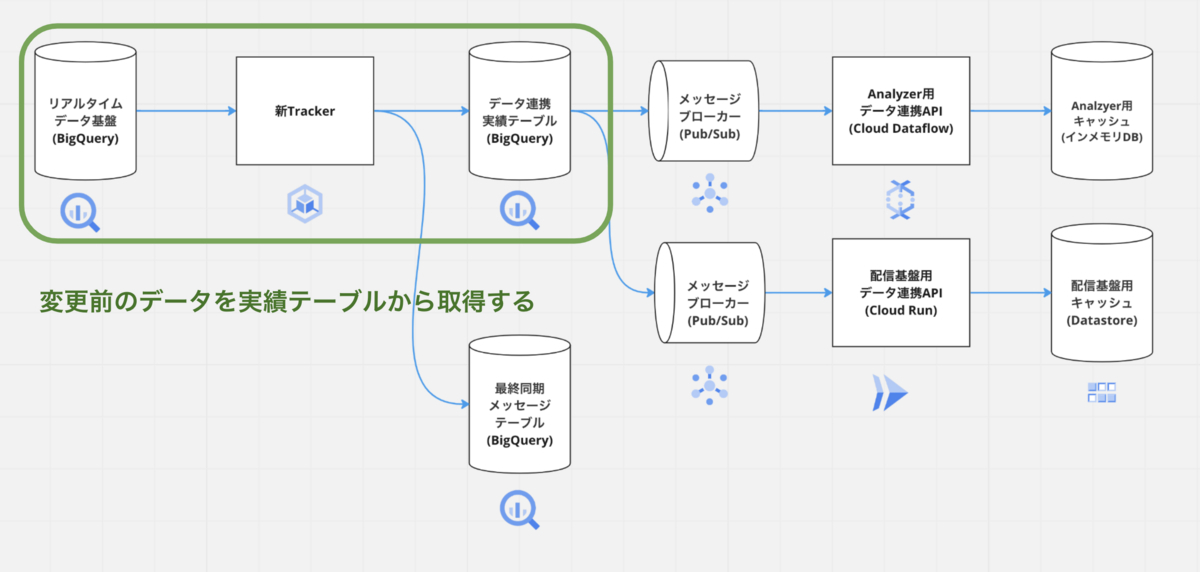
アーキテクチャの全体は次の通りです。新Trackerではリアルタイムデータ連携基盤から変更前後のデータを取得して、メッセージブローカーにパブリッシュしています。メッセージブローカーへパブリッシュされたデータはAnalyzerを含む各サービス毎に作られたデータ連携用のAPIを用いて連携されます。以降各処理の流れの詳細をご紹介します。
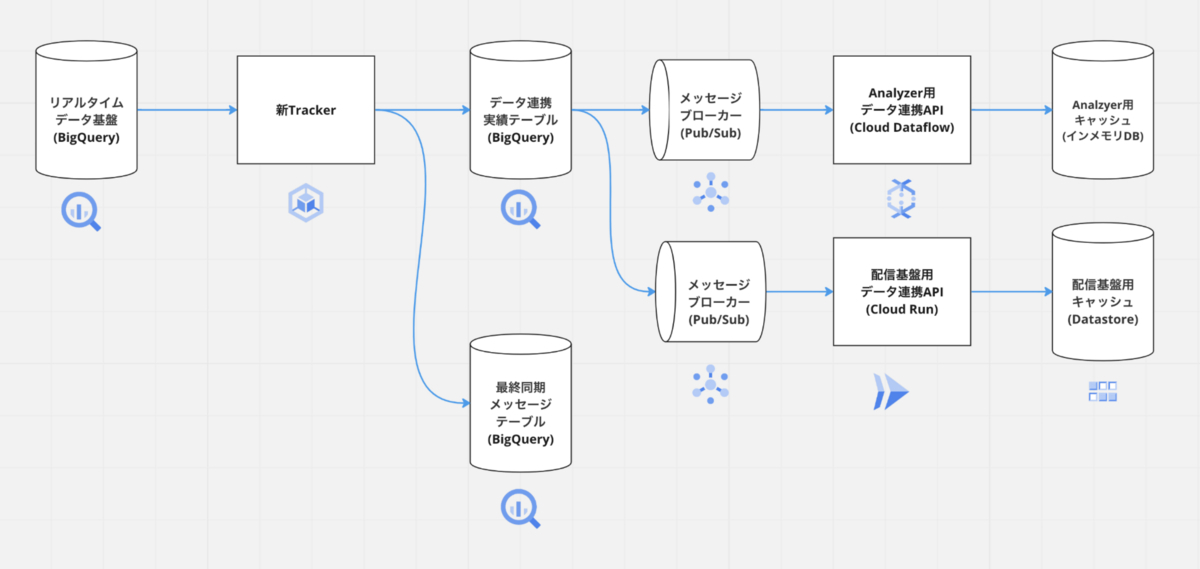
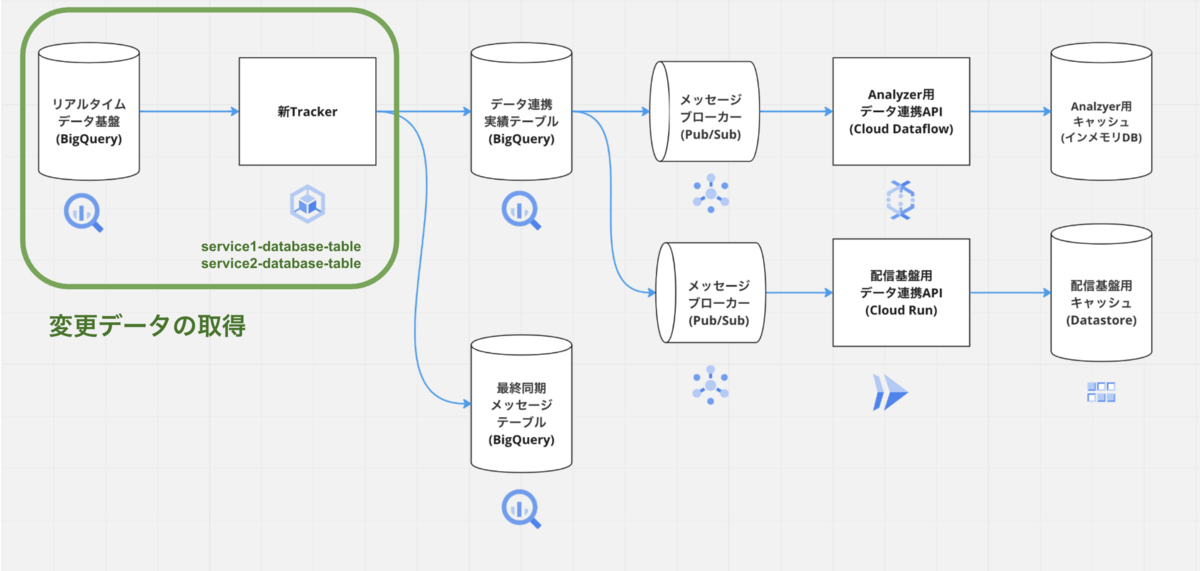
変更前後のデータ取得
新Trackerではリアルタイムデータ基盤から変更後のデータを取得しています。変更前のデータは後述するデータ連携実績テーブルから取得しています。
新TrackerはGKE上にネームスペースを分けてデプロイしています。各サービスごとに同じテーブルでも必要となるETL処理が異なります。また、同じテーブル名でもDB単位でデータは異なります。そのため、各リソースはサービス単位でテーブルの識別ができるように分けています。
「サービス名 × データベース名 × テーブル名」
GKEのデプロイメントは以下のようになっています。サービスとしては「analyzer」と「zozo-notification-delivery」があり、同じテーブルでも別のリソースとしてデプロイされています。
kubectl get pod -n realtime-datapump app-analyzer-table1-db1 1/1 Running 9 (46h ago) 25d app-analyzer-table2-db2 1/1 Running 8 (27h ago) 25då app-analyzer-table3-db3 1/1 Running 9 (16h ago) 25d ..... app-zozo-notification-delivery-table1-db1 1/1 Running 9 (2d4h ago) 25d app-zozo-notification-delivery-table2-db2 1/1 Running 9 (13h ago) 25d app-zozo-notification-delivery-table3-db3 1/1 Running 6 (46h ago) 25dåå
リソースごとに設定ファイルも分けています。デプロイする際に「サービス名 × データベース名 × テーブル名」を環境変数として渡し、環境変数に基づいて設定情報を取得しています。BigQueryやCloud Pub/Subのリソース情報を制御できるようにしてます。リカバリ等も考慮し、マイクロサービス単位でテーブル等リソースは分けて管理しています。
# analyzer [services.analyzer-db1-table1] gcp_project = "gcp_project" pubsub_topic_project = "pubsub_topic_project" message_reflesh_count = 50000 pubsub_topic = "<table1>" dataset_event_send_ids = "db1_tracking_event_send_ids" dataset_event_logs = "db1_tracking_event_logs" ... # zozo-notification-delivery [services.zozo-notification-delivery-db1-table1] gcp_project = "gcp_project" pubsub_topic_project = "pubsub_topic_project" message_reflesh_count = 50000 pubsub_topic = "<table1>" dataset_event_send_ids = "zozo_notification_delivery_<db1>_tracking_event_send_ids" dataset_event_logs = "zozo_notification_delivery_<db1>_tracking_event_logs"
デプロイされた新Trackerはステートレスになっており、まず最終同期したメッセージに紐づく時刻を取得します。後述の「最終同期メッセージを書き込む」でご紹介しますが、サービスにパブリッシュされた最後のメッセージは別テーブルで管理されています。新TrackerのPod起動時に最終同期したメッセージの時刻を取得します。

最終同期の時刻を、先ほどご紹介したテーブル関数に渡し、変更前後のデータを取得します。各マイクロサービスで必要となるETL処理をしています。
データ連携実績テーブル
加工されたデータは別テーブルへ書き込まれます。書き込まれたデータは古い順から全て配信基盤側へ連携されます。加工されたデータを一度書き出す理由としては、冪等性の担保と重複排除によりパフォーマンスをあげるためです。

変更前のデータをデータ連携実績テーブルから取らないと、リトライされた場合、変更前のデータがキャッシュされているデータと一致しなくなります。同じプライマリーキーに対して、複数回の更新処理が走った場合を考慮すると、リアルタイムデータ基盤にある変更前のデータとAnalyzerでキャッシュされている変更前のデータが一致しなくなるためです。リアルタイムデータ基盤にある変更データを別テーブルへ書き出すことで、変更前データの整合性を担保しています。また、前述した「変更前後のデータを取得するクエリ」で述べたとおり、変更前後のデータを取得するにはタイムスタンプを用いています。リアルタイムデータ基盤からデータ欠損がないよう遅延データも考慮して、変更データを取得するため、すでに連携済みのデータも取得されてしまいます。データ連携実績テーブルを用いることで、連携済みのデータを除外し、パフォーマンスを向上させるためにも利用します。データ連携実績テーブルに連携されたデータはサービスへ連携されるため、障害時の原因調査にも役立ちます。
メッセージブローカーへ連携
データ連携実績テーブルへ書き込まれたデータは古いデータから順に取り出され、メッセージブローカーへパブリッシュされます。メッセージブローカーを挟むことで、非同期処理が可能となり耐障害性が向上します。もし、メッセージブローカー内のデータを処理しているコンシューマが障害を起こした場合でも、メッセージブローカーへデータをパブリッシュするプロデューサは影響されずに処理を継続できます。また、メッセージブローカーを挟むことで、各マイクロサービスへのデータ連携で必要なインタフェースを揃えることができるため、汎用性の高いシステムを構築できます。

データ連携実績テーブルからデータを取り出すクエリは以下のようになっています。「LastSyncTime」メッセージブローカーへの配信が成功した最後のメッセージに紐づく時刻が入ります。データ連携実績テーブルに連携済みで、まだメッセージブローカーへ配信できていないメッセージのみ抽出します。
SELECT * FROM `zozo-ma-realtime-datapump-{{.Env}}.{{.EventLogsDataset}}.{{.EventName}}` WHERE tracking_start_time > "{{.LastSyncTime}}" ORDER BY tracking_start_time ASC
メッセージブローカーにはCloud Pub/Subを採用しています。Cloud Pub/Subで順序保証するには順序保証キー「OrderingKey」を用いる必要があります。SQL Serverのプライマリーキーを順序保証キーとして、パブリッシュしています。順序を保証するため、メッセージブローカーへのパブリッシュが1件でも失敗した場合、実績テーブル内の未連携データは全て再連携されます。
Cloud Pub/Subへのパブリッシュ時に以下のように属性情報「Attributes」も渡しています。
publishResult := t.Publish(ctx, &pubsub.Message{
Data: []byte(msg),
Attributes: map[string]string{
"event": event.EventSourceName() + "-" + event.EventDatabaseName() + "-" + event.EventName(),
"message_id": event.MessageId(),
"key": event.RealtimeMessageKey(),
"action": event.Action(),
},
OrderingKey: event.OrderId(),
})
属性情報の役割は以下の通りです。
| 属性 | 説明 |
|---|---|
| event | 各イベントを識別するために利用 |
| message_id | メッセージのユニーク値を識別するために利用 |
| key | SQL Serverのプライマリーキー |
| action | 変更のあったイベントタイプ「upsert」と「delete」 |
これらの属性情報に基づき、後述する配信系サービスへデータ連携を担うAPIで処理されています。
データ連携API(Analyzer)
Cloud Pub/SubへパブリッシュされたデータはAnalyzerへデータ連携されます。Analyzerへのデータ連携APIにはCloud Dataflowを用いています。Cloud Pub/Subへパブリッシュ時に属性情報として渡した「event」を用いて、イベント名に基づきAnalyzerへのエンドポイントに対してリクエストします。AnalyzerはAWS環境にあるため、GCPからAWS環境へリクエストするために、ZOZO内の共通基盤であるShard VPCを用いています。

ShardVPCについては以下の記事をご確認ください。
当時Cloud RunやCloud Functionsを採用しなかったのは従量課金によるコストを抑えたかったためです。Cloud RunやCloud Functionsの比較的新しい料金体系である「Always on CPU」だと、リクエスト課金が発生しません。大量のデータを扱うログ収集基盤などではスケーリングが速く、コスト面の費用対効果も高いです。
ただし、今回はShard VPCを利用するためCloud RunやCloud Functionsを使う場合はサーバレスVPCを利用する必要があります。サーバレスVPCは従量課金となってしまうため、運用実績もあり、費用帯効果の高いCloud Dataflowを採用しました。
しかし、実際にCloud Runも運用してみてパフォーマンス面や最小ワーカー数の制御等、Cloud Dataflowよりも優れている点が多いように感じました。要件次第ではありますが、今後新規でストリーミング系のデータ連携をする場合は積極的にCloud Runを使いたいと思いました。
Appendix:データ連携API(Push/LINE配信基盤)
前述の「なぜリプレイスをしたのか」でご紹介したとおり、新TrackerはAnalyzer以外の各マイクロサービスへもリアルタイムにデータ連携できます。Appendixとして配信基盤へのデータ連携についても簡単にご紹介します。
リアルタイムマーケティングシステム全体のリプレイスに伴い、Analyzerの各チャンネルへの配信機能を配信基盤として切り出し、モジュール化しています。配信基盤は全社の共通基盤としてZOZO内部の他のシステムからも配信処理が実施できるように作られています。配信基盤の機能として、配信基盤へのリクエストに含まれているメンバーIDを用いて、通知設定の確認やPushやLINE配信に必要なトークンへの変換をしています。配信基盤で必要なデータを新Trackerを用いて連携しています。

配信基盤用のデータ連携APIにはCloud Runを採用しています。Cloud Runを採用したのは、Cloud Dataflowよりもスケーリングが速く、パフォーマンス面で優れていたためです。また、「Always on CPU」を使えば今後データ量が増えてもリクエスト課金による懸念はなくなります。配信基盤用のデータ連携APIはAWSと疎通することもないため、サーバレスVPCの費用を気にする必要もありません。
配信基盤のストレージにはGCPのサーバレスでNoSQLデータベースであるCloud FirestoreをDatastoreモードで採用してます。配信基盤に必要なデータをデータ連携APIを用いて、Cloud Firestoreにキャッシュしています。属性情報の「action」に基づいてデータの更新と削除をしています。配信基盤でもAnalyzer同様に十分なパフォーマンスがでるよう、Cloud FirestoreのKEYにメンバーIDを用いています。MA部以外のシステムからも配信できるようメンバーIDを用いて配信に必要なパーミッションなどの情報を取得するためです。Cloud FirestoreにキャッシュされたデータもAnalyzer同様、必要に応じ削除しています。例えばLINEの連携を解除した際にキャッシュされたデータを消す必要があります。
ただし、AnalyzerのようにメンバーIDなどの変更前のデータは必要ありません。以下のように属性情報の「key」で渡されたSQL Serverのプライマリーキーを用いて、対象のデータを抽出して削除をしています。
func (mdsrepository *EventCacheRepository) Delete(ctx context.Context, cacheLog entity.TableCatchLog) error { // delete datastore key from sql server primary key _, err := mdsrepository.client.RunInTransaction(ctx, func(tx *gcpdatastore.Transaction) error { query := gcpdatastore.NewQuery(mdsrepository.entityKind).Transaction(tx).FilterField(cacheLog.ToPrimaryKeyName(), "=", cacheLog.ToPrimaryKey()) it := mdsrepository.client.Run(ctx, query) catchIterator := CatchIterator{ CatchName: cacheLog.ToCatchName(), Iterator: it, } for { catch, err := catchIterator.NextEvent() if err == iterator.Done { break } if err != nil { return err } key := gcpdatastore.NameKey(mdsrepository.entityKind, catch.ToKey(), nil) if err := tx.Delete(key); err != nil { return err } } return nil }) if err != nil { mdsrepository.logger.Error("Transaction Faile To Delete Entity") return err } return nil }
配信基盤のストレージの選定時にKEYではなく、クエリで十分なパフォーマンスが出るかも必要な要件でした。SQL Serverのプライマリーキーを用いてキャッシュの操作をするためです。結果整合性によりパフォーマンスで優れているCloud Firestoreは負荷検証の結果1億件を超えるデータでも高速に処理できることが確認できました。
なお、バッチの洗い替えなど大量にデータを削除するには不向きなので注意が必要です。夜間であれば問題ありませんが、配信中などに実施するとクエリのレイテンシが悪化します。ドキュメントでも負荷検証等で十分なパフォーマンスがでるか検証することを勧めています。
配信基盤用のデータ連携クエリは、Analyzerとは異なり変更データ取得の際にBigQueryのリソースを多く消費することもありません。Analyzerのインメモリなデータストアで実現できるのかパフォーマンスの確認は必要となりますが、今後Analyzerにも同様の改修を入れたいと考えています。
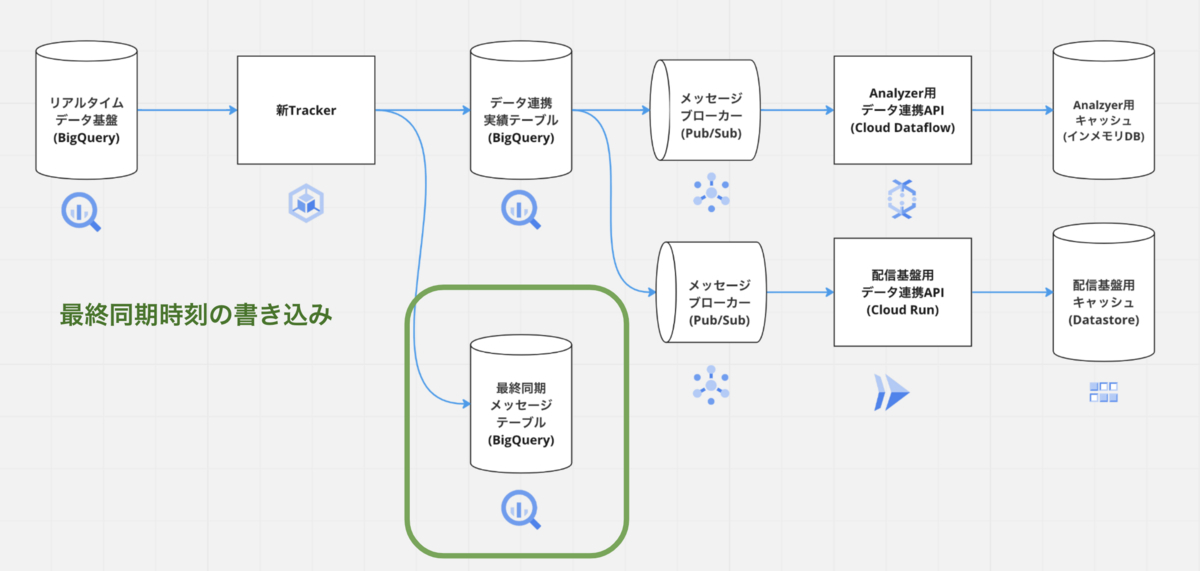
最終同期メッセージを書き込む
メッセージブローカーへのパブリッシュが全て成功した場合は最後にパブリッシュした、メッセージのメッセージIDとデータの取得開始時刻をBigQueryへ同期的に書き込みます。最終同期時刻を変更データ取得用に作られたテーブル関数へ渡し、変更のあったデータを取得しています。また、このメッセージIDを用いて、実績テーブルからデータ連携するデータを絞っています。冒頭で説明したSQL Serverの変更追跡バージョンと同じ役割を果たしています。障害発生時のリカバリもこの最終同期メッセージの時刻を巻き戻すことで、最終同期した時刻以降のデータを再連携可能です。
初回の全量データ連携
新Trackerで取得できるデータは変更データのみです。初回時のデータ連携やリカバリ時には全量データの連携が必要になります。以降「ローダーバッチ」と呼びます。ローダバッチではDigdagを用いて、BigQueryのクエリ実行結果をCloud Storageへdumpし、並列にCloud Pub/Subへパブリッシュしています。Cloud Pub/Subへパブリッシュされたデータは前述した各サービスごとに作られたデータ連携APIを用いてキャッシュされます。ストリーミング処理である新Trackerの差分連携、バッチ処理であるDigdagを用いた全量連携で使うデータ連携APIの共通化が可能です。バッチ処理とストリーミング処理の両方で同じロジックのメンテナンスをする必要がないため、運用負荷を軽減できます。また、新Trackerを用いて新しくデータ連携する場合の導入工数も削減できます。

なお、Cloud Pub/Subへのパブリッシュで十分なパフォーマンスがでない場合は、Cloud Pub/Subクライアントのバッチメッセージングの設定値を調整する必要があります。今回はmax_messagesをデフォルトの100から1000に変更し、max_latencyをデフォルトの10msから1sに変更しました。これにより、約1.7億件のデータをCloud Pub/Subへパブリッシュするのに10時間かかっても終わらなかったのが、約90分ほどで完了するようになりました。
設定値の詳しい説明は、以下の公式のドキュメントをご確認ください。
Digdagについては以下の記事をご確認ください。
移行前後の評価
リプレイスにあたり以下の観点でデータの評価をしました。Analyzerに連携しているテーブルは約22テーブルほどあり、マスタテーブル等のJOIN等複雑な加工処理を実施しています。移行時の評価方法についてご紹介します。
データの整合性を評価
データの整合性を担保するため、旧Trackerと新Trackerのログを比較できるようにしました。旧TrackerのログはWindows Server内から取得し、新Trackerの方はCloud Loggingにログを書き出しました。両方の結果をハッシュ値で比較して、データの値が一致しているか調べました。言語仕様等でずれがあった場合は問題ないか確認していきました。評価の過程で旧Tracker側の問題、新Tracker側の問題両方見つかりました。修正が必要なテーブルはクエリを修正し、対応しました。
データの欠損を評価
次にデータの欠損を調べました。データ欠損の観点では旧Trackerで変更のあったプライマリーキーが新Trackerに含まれているか調べました。遅延を考慮し、ウィンドウ幅を1時間程度に調整して調べました。プライマリーキーの有無で調べたのは、データ連携の性質上、短い期間に複数回の更新が走った場合はプライマリーキーに紐づくデータが新旧で一致しなくなるからです。プライマリーキーであれば、旧Trackerにあるキーは新Trackerにないといけないため、データの欠損を調べることができます。データの欠損がないか確認し、問題がないことを確認しました。
データの遅延時間を評価
旧Trackerをベンチマークにデータの遅延時間を調べました。旧Trackerの遅延の調査は旧Trackerとリアルタイムデータ基盤のログをBigQuery上で突合して調べました。
新旧Trackerのデータ遅延だけではなく、リアルタイムデータ基盤側のデータ遅延も調べました。調べたところ旧Trackerでは最大で20分程度の遅延が発生していることが確認できました。一方で、新TrackerではBigQueryのコンピューティングリソースであるスロットを十分確保すると、遅くても数十秒ほどでクエリの完了が確認できました。しかし、数十テーブルの連携で十分なスロットを確保する場合は600スロットほど必要なことがわかりました。調査したところ主に変更前のデータ取得で多くのスロットを消費していることが分かりました。
運用ではコストを抑えるため100スロットに固定しています。100スロット固定だとパフォーマンスは遅くなりますが、旧Trackerのパフォーマンスは超えることができました。後述しますが、Analyzer側に修正を加えることで100スロット以内に、必要なパフォーマンスをだせる予定です。
監視設計
新Trackerの監視設計について紹介します。リアルタイムに差分データを取得しているアプリケーションを「プロデューサ」、メッセージブローカーのデータを処理するデータ連携APIを「コンシューマ」と呼びます。
プロデューサの監視
プロデューサの監視ではCloud Monitoringを活用して、データの遅延と正常に稼働しているか監視しています。変更前後のデータを取得する一連の処理が完了した際に、Cloud Loggingを用いて監視で用いるイベント情報を書き出しています。一定時間たってもイベントが書き込まれない場合はアラートを飛ばすようにしています。
コンシューマの監視
コンシューマの監視にはCloud Pub/Sub内のACKされていないデータを監視しています。コンシューマで障害が発生し、処理が完了しなかった場合はExponential Backoffでリトライするように作られています。リトライしても成功しない場合はCloud Pub/Sub内でACKされていないデータが増え続けます。Cloud Pub/Sub内のメトリクスである「oldest_unacked_message_age」を監視して、コンシューマの障害を検知できるようにしています。
リプレイスによる改善点
リプレイスしたことによる改善点をご紹介します。
リアルタイムマーケティングシステム全体のリプレイスに必要な基盤を構築
リアルタイムマーケティングシステム全体のリプレイスを進めていく上で、必要な基盤を構築できました。各マイクロサービスで必要なデータをリアルタイムに連携が可能となりました。また、初回の全量データ連携の仕組みも共通化できました。新規でサービスを追加する場合は、新しくクエリやトピック等追加することで容易にリアルタイムデータ連携が可能です。
運用負荷の軽減
旧Trackerからリプレイスできたことで、運用負荷の高かったWindows Serverから脱却できました。Windows Serverにデプロイされたクラスタの運用やSQL Server起因の障害がなくなりました。リプレイスに伴いデプロイも自動化でき安心して実施できるようになりました。また、半年間大きな障害なく運用もできています。
今後の課題
最後に今後の課題について紹介します。リプレイスは完了しましたが、まだいくつか改善の余地があります。
パフォーマンスの改善
今回Analyzerに手を加えない形で修正しました。しかし、変更前データを実績テーブルから取得することで多くのBigQueryのコンピューティングリソース(スロット)を消費しています。Analyzerはプライマリーキーではないものをキーにしてるキャッシュが多いためです。十分なスロットが確保できれば、遅くても数十秒以内でクエリは完了します。配信基盤のようにAnalyzerも変更前のデータをSQL Serverのプライマリーキーから取得するよう改修することで、コストやパフォーマンス面で改善が見込まれます。今後この基盤を用いてさらにデータ連携するサービスが増えていく予定なので、対応していきたいです。
初回全量データ連携処理の完全移行
前述した初回全量データ連携する仕組み(ローダバッチ)ですが、Analyzerの全量データ連携ではまだ利用できていません。ローダーバッチの仕組みを利用できているのは配信基盤(Push/LINE)用のデータ連携のみです。Analyzerでも全量データをロードするための仕組みがあり、インメモリ上のキャッシュが吹き飛んだ時などに用いています。
しかし、SQL Serverから全量データを取得するには時間もかかり、ロードには8〜9時間程度かかります。今回紹介したローダーバッチへ移行できると、BigQueryからデータを取得できるので、パフォーマンス面での改善が期待できます。DigdagにAnalyzer用のクエリを追加すればいいため、Analyzerやデータ連携APIには手を加えずにリプレイスできます。より短い時間でリカバリできれば、Analyzerを運用していく上で一番大きな不安も解消されるので、今後対応していきたいです。
まとめ
本記事ではリアルタイムマーケティングシステム全体のリプレイスに向け、配信用リアルタイムデータ連携基盤をリプレイスした事例をご紹介しました。
リプレイスに伴い、運用負荷の高いWindows Serverから脱却できました。今回のリプレイスで変更データの取得元をSQL Serverから全社共通の基盤であるリアルタイムデータ基盤に変更しました。データソースの変更に伴い、「データの重複」「データの順序」「変更前データの取得方法」を考慮した設計が必要でした。さらに、Analyzerの制約も考慮し、切り戻しや評価できるよう安全にリプレイスを進める必要がありました。
構築した新Trackerで連携できるデータは差分データのみなので、初回の全量データを連携するための仕組みが必要でした。運用負荷や導入工数を考慮し、ストリーミング処理とバッチ処理で同じデータ連携用のAPIを用いています。
今回のリプレイスに伴い、旧Trackerの抱えていた課題を解決できましたが、まだ課題は残っているので今後対応していきたいです。
最後に
この記事を読んで、もしご興味をもたれた方は是非採用ページからお申し込みください。