



はじめに
こんにちは。家系らーめん好きが高じて鶏油を自分で取得するようになり、金色に輝く液体を見るだけでパブロフの犬的に涎が止まらない、SRE部の横田です。普段はSREとしてZOZOTOWNのリプレイスや運用に携わっています。
先日、弊社の高橋が執筆したZOZOTOWNカート機能リプレイスに関する記事が公開されました。
本記事では、上記記事で紹介したリプレイスのキーポイントとなる、キューイングシステムに焦点を当てます。キューイングシステムをDeep Diveし、サービス選定からプロダクションレディにするまでの取り組みを紹介します。
目次
キューイングシステムの概要と選定
本章では、今回のテーマとなる「キューイングシステム」の概念を、ZOZOTOWNのカート投入システムを例に解説します。
ZOZOTOWNのカート機能は、カート投入や決済など、さらに細かい様々な機能から構成されています。そして、ZOZOTOWNにとって、最も重要な機能の1つと言えます。しかし、関連システムも多いため、一度にすべてをリプレイスするのではなく、段階的にいくつかのPhaseに分けたリプレイスを現在進めています。カート機能のリプレイス Phase1では、カート投入処理でWebサーバーとカート情報を扱うデータベース(以下、カートDB)間にキューイングシステムを挟みました。これにより非同期処理となり、イベント時のアクセス集中に伴うカートDBの負荷上昇を抑えることを可能にしました。
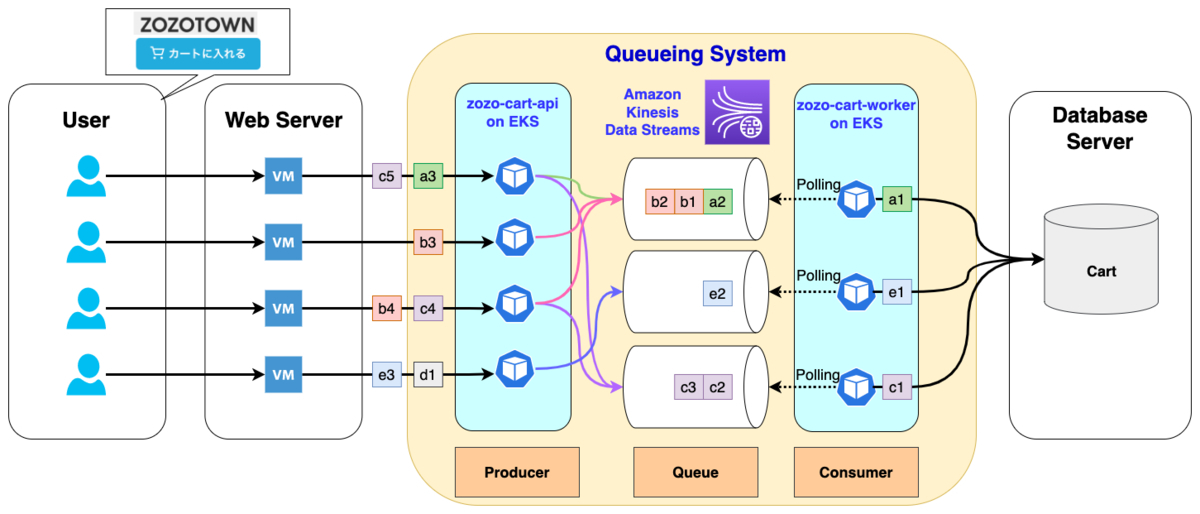
上図で用いられている用語を簡単に説明します。
- Queue
- キュー(Queue)とは、「待機、待ち行列」を意味する
- 本システムでは、カート投入処理をキューで一時的に預かることで、後段のシステム負荷軽減を実現させている
- First In First Out(以下、FIFO)、つまり順序性を保証したい場合は、要件に合うキューを選択する必要があるため、本システムではAmazon Kinesis Data Streams(以下、KDS)を採用している
- KDSでは、キューの役割を持つリソースをシャードと呼び、シャードに投入するデータをレコードと呼ぶ
Producer
- キューにデータを投入する役割を持つ
- 本システムでは、上図のzozo-cart-apiがProducerの役割を果たす
- 前段のWebサーバーからリクエストを受け、KDSにレコードを投入するまでがzozo-cart-apiの役割である
Consumer
- キューからデータを取り出し、後続の処理を行う役割を持つ
- 本システムでは、上図のzozo-cart-workerがConsumerの役割を果たす
- KDSから読み込んだレコードを後段のシステムに繋げる役割を持つ
Polling
- Consumerがキューの状態変化を検知するために、一定間隔でリクエストを送る処理をポーリングと呼ぶ
- 本システムでは、Consumerであるzozo-cart-workerがKDSにポーリングを行うことで、未処理のレコードに対するアクションを行う
このように、本システムではカート投入要求に対する非同期処理システムを、KDSを活用して実現しています。次に、なぜキューイングシステムとしてKDSを採用したのかを説明します。
検討したサービス
AWSが提供するキューイングシステムから、以下の選択肢を検討しました。
- Amazon Simple Queue Service(以下、SQS)
- KDS
それぞれの特徴は以下の通りです。
SQS
SQSはメッセージキューサービスであり、以下の特徴があります。
- 1リージョン内で複数AZの冗長構成なため、可用性が高い
- キューサービスのため、Consumerはメッセージの取り出しと削除が役割となる
- 標準キューとFIFOキューが存在し、タイプにより性能や動作が異なる
- デッドレターキューを利用することで、処理に失敗したメッセージに対するアクションが可能である
なお、標準キューとFIFOキューには、以下の違いがあります。
| 特徴 | 標準キュー | FIFOキュー |
|---|---|---|
| 順序性 | ベストエフォートのため、厳密な順序性の保証はされない | 順序性が保証される |
| 重複 | 重複の可能性がある | 重複メッセージがないように設計されている |
| APIコール制限 | 無制限 | APIメソッド毎に300リクエスト/secのAPIコールをサポート |
KDS
KDSは、ストリーミングデータサービスで、ログやイベントデータの収集、リアルタイム分析などで活用可能なサービスです。以下のような特徴があります。
- 複数AZ間でデータ同期されるため、可用性が高い
- ストリームサービスのため、Consumerは「レコードを削除する」という考えが無く、どこまで処理したかを記録する役割を持つ
- レコードは指定した期間の経過後に破棄される(最短24時間)
- FIFOをシャード単位で担保可能である
- 処理性能はシャード単位で考える
- データ取り込みは、1シャードあたり1000レコード/secまたは1MB/sec
- Kinesis Client Library(以下、KCL)が提供されている
なお、より詳しくSQSとKDSを知りたい方は、公式ドキュメントをご参照ください。
KDSの選定理由
本システムでは、KDSを採用しました。その選定理由を説明します。
理由1:カート投入処理数への懸念がない
前提条件として「カート投入機能は同一商品に限り順序性を担保したい」という要件がありました。つまり、FIFOキューを利用する必要があります。
ここで懸念として挙がったのは、SQSのFIFOキューにおけるAPIコール数制限です。APIメソッド毎に最大300リクエスト/secのAPIコールがサポートされていますが、この数値はZOZOTOWNのカート投入数に対してボトルネックになる可能性が考えられました。一方、KDSのデータ投入のクォータはシャードあたり1000レコード/secとなっており、高いイベント処理能力を有しています。1つのストリームでシャード数を増加させることで、同時に処理可能なレコード数を引き上げられます。この点がKDSの魅力の1つでした。
理由2:Consumerの回復性が高い
SQSとKDS、共に高可用性を有したマネージドサービスであるため、利用者側はあまり深く意識しなくとも回復性や信頼性が備わっています。しかし、ProducerやConsumerに関しては、利用者自身で別のサービスを利用するなどの対策が回復性や信頼性を向上させるために必要です。
可用性や回復性の担保において、ProducerはAPIがその役割を担うため、複数台のAPIを水平スケールさせるといった既存システムのナレッジで容易に実現が可能でした。しかし、Consumerは順序保証のために1つのキューに対して1つのConsumerである必要があり、水平スケールの実現が困難でした。そこで、障害発生時にConsumerが可能な限り早く処理を再開させるためには「Failover動作が好ましい」と考えました。これは、KCLを利用することで比較的容易に実現できることも分かりました。
KCLアプリを利用したFailoverの実現
本システムではKCLを活用しています。その特徴を簡単に説明します。
KDSからレコードを取得して処理をするConsumerアプリケーションを開発する場合、その方法の1つとしてKCLを利用する方法が挙げられます。KCLは、KDSとレコードに対する後続処理の仲介役を担う存在です。KCLアプリケーションでは、Consumerをワーカーと呼び、主に以下の機能を提供します。
- KDSへの接続
- シャードとワーカーのバインディング
- レコードをどこまで処理したか管理するためのチェックポイント記録
- ワーカー数やシャード数変更に伴うリバランス処理
KCLアプリケーションは、ワーカーとシャード間のバインディングを定義します。また、定義されたデータをLeaseと呼び、Lease Table(DynamoDB)を利用してワーカーにより処理されるシャードの追跡や、ワーカー数増減・シャード増減の追従を可能にします。Lease Tableでは、各Itemに対して下図の内容が定義されます。

そして、チェックポイントを利用したレコードの追跡により、ワーカーで障害が発生した際に、他のワーカーが処理を引き継ぎ、未処理のレコードから処理を再開することが可能になります。
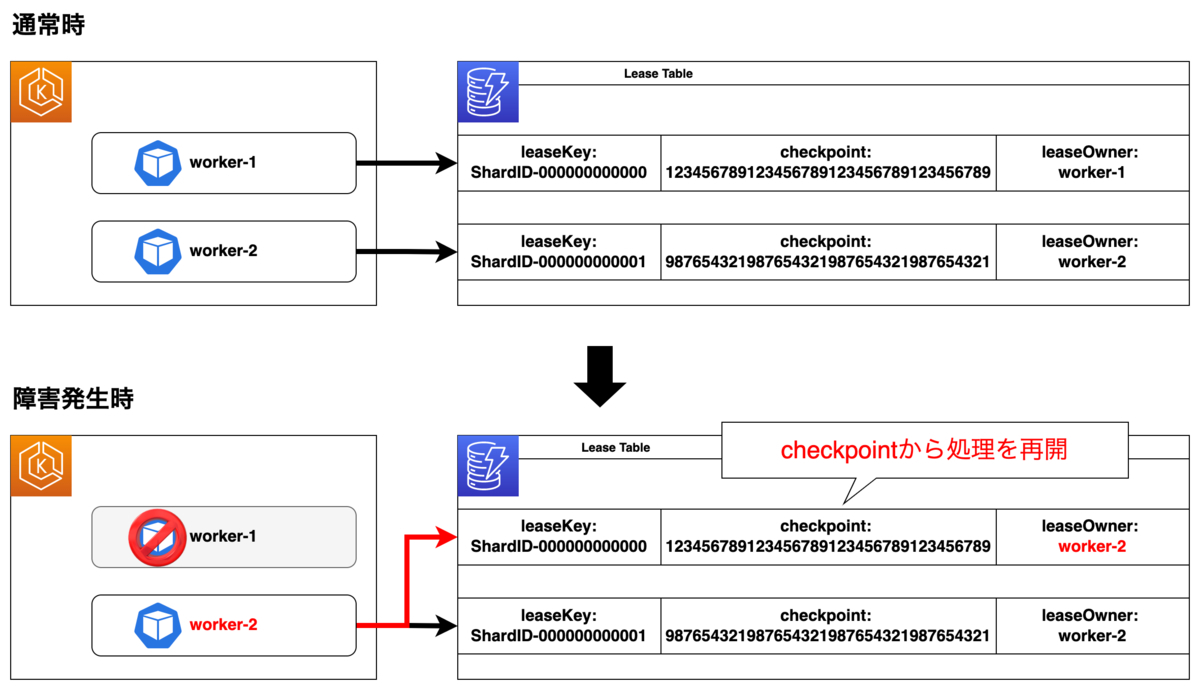
前述のように、下記2点が採用を決めた大きな理由です。
- KDSが高いイベント処理能力を有していること
- KCLを利用することで、ワーカーのFailoverなど回復性向上が比較的容易に実現可能であること
プロダクションレディに向けた取り組み
前述の通り、キューイングシステムとしてKDSを採用することが決まりました。本章では、本システムをプロダクションレディにするため取り組んだことを紹介します。
シャード数拡張戦略
KDSでキューイングシステムを構築する上で、シャード数は並列処理数を左右する非常に重要な要素です。現在稼働しているシャード数は、過去数年のカート投入リクエストログによる分析結果と、実際にそのシャード数でカートDBの負荷低減に繋がるかという検証を繰り返しながら決定した値です。
一方、今後の成長などを考慮するとシャード数の増加、場合によっては減少させることも十分考えられます。その際に備え、拡張・縮退にどの程度の時間を要するのかを把握しておくことが重要です。そこで、シャード拡張・縮退に要する時間の検証を行いました。
検証1:シャード数変更に要する時間の検証
シャード拡張・縮退に要する時間の検証を行った結果が下記表です。
| 変更前シャード数 | 変更後シャード数 | シャード数差分 | 拡張に要した時間 |
|---|---|---|---|
| 2 | 4 | +2 | 41s |
| 4 | 8 | +4 | 40s |
| 8 | 16 | +8 | 41s |
| 16 | 32 | +16 | 1m13s |
| 32 | 64 | +32 | 1m13s |
| 64 | 100 | +36 | 11m29s |
| 100 | 200 | +100 | 2m44s |
| 200 | 300 | +100 | 15m35s |
| 300 | 400 | +100 | 29m38s |
| 400 | 500 | +100 | 44m13s |
| 500 | 600 | +100 | 59m8s |
| 500 | 501 | +1 | 1h11m20s |
現在はKDSをCloudFormationで構成管理しているため、拡張に要した時間はCloudFormationのステータスから計測しています。試行回数2回の平均値を記載しています。上記の結果にはシャード数の増加のみ掲載していますが、減少の検証でも概ね同様の結果が得られました。増減数が少ない時は高速で拡張・縮退が完了しますが、64→100への変更時点から、かなり時間が安定しなくなっています。500→501への変更では、1シャード増が完了するまでに1時間を要しています。しかし、100→200への変更では、処理が早く完了しているように見えます。
本検証の結果を分析していったところ、この結果はKDSのリシャーディング動作が大きく関わっていることが分かりました。公式ドキュメントによると、リシャーディングにはシャードの分割(Split)と結合(Merge)というオペレーションが存在します。また、FAQによれば、これらのオペレーションは1シャードずつ行われることが分かります。

Q: How often can I and how long does it take to change the throughput of my Kinesis stream? A: resharding operation such as shard split or shard merge takes a few seconds. You can only perform one resharding operation at a time. Therefore, for a Kinesis stream with only one shard, it takes a few seconds to double the throughput by splitting one shard. For a stream with 1000 shards, it takes 30K seconds (8.3 hours) to double the throughput by splitting 1000 shards. We recommend increasing the throughput of your stream ahead of the time when extra throughput is needed
引用:Amazon Kinesis Data Streams FAQs | Amazon Web Services
この説明から、シャード数が増えれば増える程、総処理時間も増加することが分かります。また、先程の検証結果で100→200への変更の変化時だけ極端に処理時間が早かったのは、シャードの分割だけで処理が完了していたためだと言えます。CloudFormationを使って、拡張前の2倍ではないシャード数の変更オペレーションを行った場合、全シャードを分割した後に目的の値まで結合処理が繰り返し行われるため、極端に時間がかかっています。
検証2:シャード数変更を2倍または2分の1に限定した場合に要する時間の検証
シャードの分割・結合の発生頻度を下げるために、拡張時は2倍、縮退時は2分の1でシャード数を変更する検証を行いました。その結果が下記表です。
| 変更前シャード数 | 変更後シャード数 | シャード数差分 | 拡張に要した時間 |
|---|---|---|---|
| 64 | 128 | +64 | 1m43s |
| 128 | 256 | +128 | 3m16s |
| 256 | 512 | +256 | 6m20s |
| 512 | 256 | -256 | 6m22s |
| 256 | 128 | -128 | 3m16s |
| 128 | 64 | -64 | 2m13s |
検証結果を比較すると分かるように、拡張・縮退に要する時間が大きく短縮されました。
AWS CLIなどを利用し、API経由で任意のシャードのみをSplitする方法も考えられます。しかし、各シャードで管理するキーレンジのバランスを意識する必要が出てくるデメリットや、可能な限りリソースをCloudFormationで構成管理したいという思いから、現在は拡張の必要がある際にはシャード数を倍にする運用方法を選択しています。
また、KDSを東京リージョンで利用する場合は、デフォルトで200シャード(バージニア北部など一部のリージョンでは500シャード)というクォータが存在します。200シャード以上の拡張が必要になる場合は、あらかじめクォータ引き上げの申請をしておくことが重要です。また、シャード数の拡張・縮退は1度のオペレーションで2倍以上へのスケールアップ、または半分以下にスケールダウンすることができない点も注意が必要です。
ワーカーのLiveness Probe
ワーカーであるzozo-cart-workerは、アプリケーション回復性や伸縮性のために、Amazon Elastic Kubernetes Service(以下、EKS)上で稼働させています。Failoverの仕組みが利用可能とはいえ、問題が発生したPodをKubernetesのライフサイクルの仕組みであるLiveness Probeを使って稼働可能な状態へ戻したい、という狙いがありました。
これまでにも、私たちの管理するEKS上の様々なマイクロサービスで、同様の取り組みを行っています。しかし、HTTPリクエストに対する処理を行うAPIと異なり、ワーカーのような処理を行うアプリケーションに対するLiveness Probeをどう実現するかが新たな課題として出てきました。
今回採用した方法は「ワーカー内に特定の条件でファイル(Example:/tmp/health)を作成・更新させ、最終更新からのタイムスタンプをLiveness Probeの条件にする」というものでした。ファイルの作成・更新タイミングには、以下のものがあります。
- KCLの初期化完了
- レコードのフェッチ
- レコードの処理開始時
なお、レコードが空であったり、Putされたレコードがない場合にもフェッチ処理が行われるため、作成したファイルのタイムスタンプが更新されるようになっています。
Manifestのサンプルは下記の通りです。
apiVersion: apps/v1 kind: Deployment metadata: labels: run: zozo-cart-worker name: zozo-cart-worker spec: template: spec: containers: - name: zozo-cart-worker image: <YOUR_IMAGE_URL> livenessProbe: exec: command: - sh - -c - find /tmp/ -name "health" -mmin -`echo $KINESIS_IDLE_TIME_BETWEEN_READS_MILLIS | awk '{print $1/60000*5}'` | grep /tmp/health initialDelaySeconds: 180 periodSeconds: 5 env: - name: KINESIS_IDLE_TIME_BETWEEN_READS_MILLIS value: 1000
KDSへのPolling間隔は、環境変数KINESIS_IDLE_TIME_BETWEEN_READS_MILLISで指定します。この変数は、KCLで指定可能なidleTimeBetweenReadsInMillisプロパティの値を指定しています。ファイルの更新が、Polling間隔のN倍(上記サンプルでは1000msの5倍)以上行われない場合、Liveness Probeに失敗したと判断させるように実装しています。これにより、回復性の向上を実現しています。
Lease Tableのキャパシティモード
KCLアプリケーションでは、Lease Tableを利用してレコードの処理状況を管理します。なお、KCLアプリケーションは、対象のDynamoDBのテーブルが存在しない場合、自動的にLease Tableを作成します。DynamoDBには、利用者側でRead/Write共に上限を設けるプロビジョニングモードと、トラフィック状況に応じて動的に拡張・縮退を行うオンデマンドモードという2種類のキャパシティモードが存在します。
KCLアプリケーションの起動時に自動生成されるLease Tableは、プロビジョニングモードで読み書き共に上限10で作成されます。シャード数やワーカーの増加に応じてLease Tableへの読み書き頻度が上がります。そのため、今回は事前に作成したオンデマンドモードのDynamoDBをLease Tableとして利用することにしました。以下がCloudFormationのサンプルです。
AWSTemplateFormatVersion: '2010-09-09' Description: 'DynamoDB KCL Lease Table Resources' Resources: DynamoDBLeaseTable: Type: 'AWS::DynamoDB::Table' Properties: TableName: leasetable AttributeDefinitions: - AttributeName: leaseKey AttributeType: S KeySchema: - AttributeName: leaseKey KeyType: HASH BillingMode: PAY_PER_REQUEST
Lease TableとなるDynamoDBのパーティションキーはleasekey(String)を指定し、BillingModeでPAY_PER_REQUESTを指定することでオンデマンドモードのLease Tableを作成します。その後、KCLアプリケーション側で作成したLease Table名を利用するように指定し、起動します。以上により、「利用状況に応じてLease Tableのキャパシティを意識する」という手間を1つカットできました。
KCLアプリケーションの監視
安定した継続運用を行う上で、監視項目は非常に重要です。Producerにあたるzozo-cart-apiは、これまで運用してきた他のマイクロサービスのAPIのナレッジが利用でき、DatadogのAPMを利用したTracingやメトリクス監視がすぐに実現できました。また、KDSでは拡張メトリクスを有効化することで、シャード単位の監視を実現しています。ワーカーの監視に関しては、KCLが発行するAmazon CloudWatchのCustomMetricsを活用しています。
このメトリクスは、KCLアプリケーションのチューニングに非常に役立ちます。過去に、負荷試験を進める中で大幅にシャード数を増加させるシーンがありました。その際には、シャード数を増やした直後にアプリケーションの動作が不安定になり、時間経過と共に改善していく事象がありました。しかし、ワーカーであるzozo-cart-workerのCPUやメモリの負荷状況は目立って悪化している部分もなく、ボトルネックがどこか分からない状態でした。そこで、KCLアプリケーションから発行されるCustomMetricsであるNeededLeasesやCurrentLeases、LeasesToTakeを確認したところ、極端にスパイクしていることに気がつきました。

- NeededLeases
- 現在のワーカーがシャード処理の負荷を分散するのに必要なシャードリースの数
- CurrentLeases
- すべてのリースの更新後にワーカーによって所有されているシャードリースの数
- TakenLeases
- ワーカーが取得に成功したリースの数
上記のメトリクスから、シャード数増加直後に複数台存在するワーカー間で管理しているシャード数にかなり偏りが発生しており、動作が不安定になっていたことが推察されます。上記の結果を受け、KCLアプリケーションのmaxLeasesForWorkerやmaxLeasesToStealAtOneTimeといったパラメーターを見直すきっかけになりました。
- maxLeasesForWorker
- 単一のワーカーが受け入れるリースの最大数
- maxLeasesToStealAtOneTime
- スティールを試みるリースの最大数
チューニング可能なその他のパラメーターは、デベロッパーガイドから確認可能です。KCLアプリケーションを運用する上で、CustomMetricsは様々な気づきを与えてくれます。ただし、シャード数やConsumerの数を増やすことでCloudWatchへのPutMetircDataの頻度が増加する点に注意が必要です。場合によっては、スロットリング(デフォルトは150TPS)が発生する恐れもあるため、上限の緩和申請を行うか、メトリクスのPUT頻度を下げるといった対応が必要になります。
さらに、ワーカーとAPIの処理をDatadog APMを使って紐付け、一貫したトランザクションを確認できる仕組みも導入しています。この取り組みは、以前の記事で紹介しているので、併せてご覧ください。
キューイングシステムの導入効果
本章では、キューイングシステムの導入効果を紹介します。
下図は、リプレイス前後でカート投入が大量に発生した際の、Webサーバーのメトリクスの一例です。以下の3項目をピックアップし比較しています。
- カート投入のリクエスト数
- カート投入に要する処理時間(Latency)
- リクエストスパイク時のエラー発生率

リプレイス前は、リクエスト数が急激にスパイクすることで、Latencyが上昇しています。その結果、ユーザーにエラーを返してしまっていることがグラフから読み解けます。
一方、リプレイス後はキューイングシステムによりカートDBへの流量をコントロールが可能になりました。その結果、リクエスト数のスパイク時のLatencyやエラー発生率を大幅に改善できています。
今後の展望
本記事では深く触れていませんが、カート投入処理が集中すると予測される商品は過熱商品用のストリームにレコードをPutする仕組みを導入しています。その際に、過熱商品であるかどうかの判定はDynamoDBの過熱商品用テーブルを参照する仕組みですが、この登録作業は手動で実施しています。トイルを可能な限り減らしていくために、過熱商品の検知と自動登録の仕組みを導入していく予定です。
今後もリリースしたシステムの運用改善を行いながら、カート機能のリプレイスはPhase2、3と段階的に進めていきます。
最後に
ZOZOでは、本記事で紹介したカート投入機能など、様々な機能のリプレイスやマイクロサービス化を進めていく仲間を募集しています。興味のある方は、以下のリンクから是非ご応募ください。
https://hrmos.co/pages/zozo/jobs/0000010hrmos.co
また、カジュアル面談も随時実施中です。是非ご応募ください。