


こんにちは。EC基盤本部 SRE部の渡邉です。去年の今頃はリモートワークによる運動不足を解消するために毎朝ロードバイクで走っていたのですが、3か月目に突入したころ急に飽きてしまいました。継続することの大切さを痛感しています。
さて、以前公開した記事でもSplunkを導入した話について書きました。今回はSplunkをもっと活用していくために、効率的なサーチ方法やダッシュボード作成のTIPSを紹介します。
メトリクスのダッシュボード作成TIPS
あらかじめ、よく使うサーチやメトリクスのダッシュボードを作成しておくと、都度SPL(サーチ処理言語)を書く手間が省けます。しかし、1枚のダッシュボードに漠然とパネルを作ってしまうと、動作が重くなったり視認性が悪くなってしまいがちです。今回はメトリクスのダッシュボードを作る際に行ったちょっとした工夫を紹介します。
Timechartに別要素を追加する
Splunkでは、メトリクスを収集するためにmstatsを使います。
以下の例では平均値と95Percentileでデータを抽出しています。
| mstats avg(_value) p95(_value) prestats=true WHERE metric_name="Processor.%_Processor_Time" AND "index"="em_metrics" AND (host=WEB*) AND `sai_metrics_indexes` span=1m | timechart avg(_value) AS "平均値" p95(_value) AS p95 span=1m BY host | rename "平均値: WEB" AS "CPU(平均値)" | rename "p95: WEB" AS "CPU(p95)" | fields - _span*
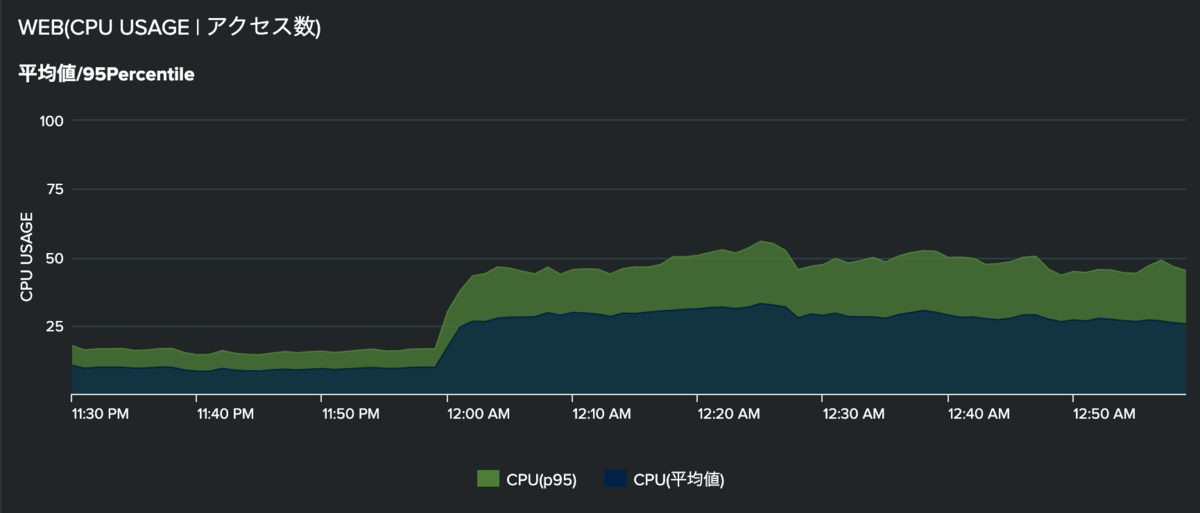
このTimechartにappendcolsを使うことで、他の要素を埋め込むことができます。
| appendcols[ search index=main host=WEB* | timechart span=1m count ]
| mstats avg(_value) p95(_value) prestats=true WHERE metric_name="Processor.%_Processor_Time" AND "index"="em_metrics" AND (host=WEB*) AND `sai_metrics_indexes` span=1m | timechart avg(_value) AS "平均値" p95(_value) AS p95 span=1m BY host | rename "平均値: WEB" AS "CPU(平均値)" | rename "p95: WEB" AS "CPU(p95)" | fields - _span* | appendcols[ search index=main host=WEB* | timechart span=1m sum(count) AS アクセス数]
しかし、SPLを記述しただけではグラフには描画されません。そのため、Format VisualizationからChart Overlayのタブを選択し、追加したいデータをセットしていきます。

この設定を入れることで、アクセス数のデータも一緒に表示可能です。下図のように、アクセス増加に応じてCPU USAGEが上昇している状況を把握できます。他にもエラーカウントを組み合わせても良いでしょう。
個人的な見解ですが、2つ以上のappendcolsはグラフ描画に時間がかかってしまう恐れがあるため、1つまでにしておくのが無難です。

CPU USAGEをインスタンス別で把握する
インスタンスを数百台以上の規模で管理していると、特定のインスタンスだけが高負荷状態に陥っている場合があります。そういった状況を把握するために、CPU USAGEを5段階でレベル分けして表示するダッシュボードを作りました。紹介する例では、95Percentileを取得した結果を表示させています。パネルごとに色の設定が可能なため、現状でどの程度の負荷状況に分布されているのか一目で把握できます。
| mstats p95(_value) prestats=true WHERE metric_name="Processor.%_Processor_Time" AND "index"="em_metrics" AND "host"="WEB*" AND `sai_metrics_indexes` span=1m BY host | bin _time span=1m |stats p95(_value) AS avg_cpu BY host | eval Description=case(avg_cpu<=30,"Clear",avg_cpu<=50,"Attention",avg_cpu<=70,"Warning",avg_cpu<=85,"Problem",avg_cpu<=100,"Critical") | stats count BY Description | eval range=case(Description="Clear", "low", Description="Attention", "guarded", Description="Warning", "elevated", Description="Problem", "high", Description="Critical", "severe")
こちらはVisualizationをSingle Valueに設定し、Trellis Layoutを有効化します。分割の単位はSPLで定義したDescriptionを使います。
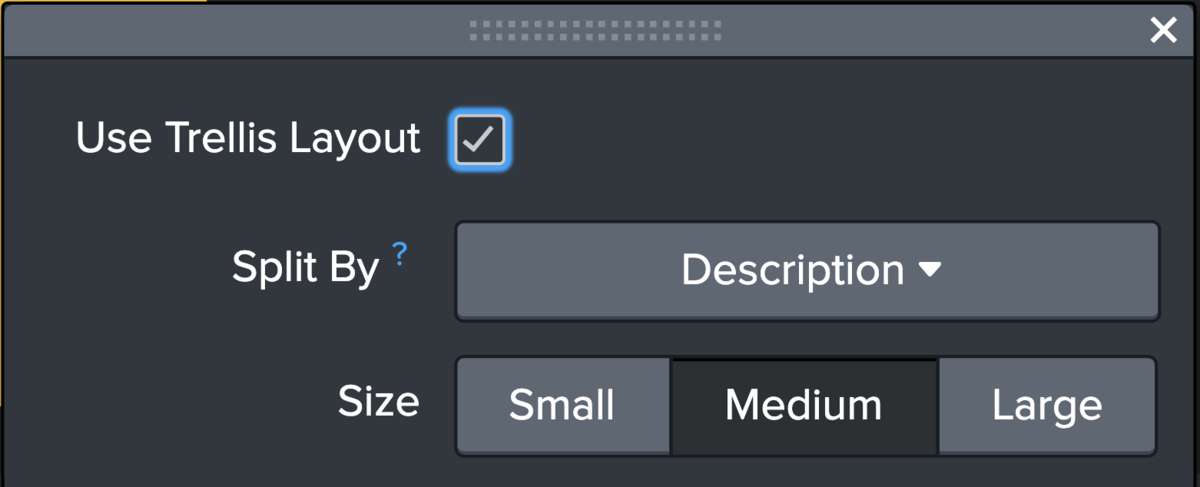
以上で、それぞれのCPU USAGEに対するカウント数を表示するダッシュボードができました。パネルの構成は以下の通りにしました。
- Clear(緑):0〜30%
- Attention(青):30〜50%
- Warning(黄):50〜70%
- Problem(橙):70〜85%
- Critical(赤):85〜100%

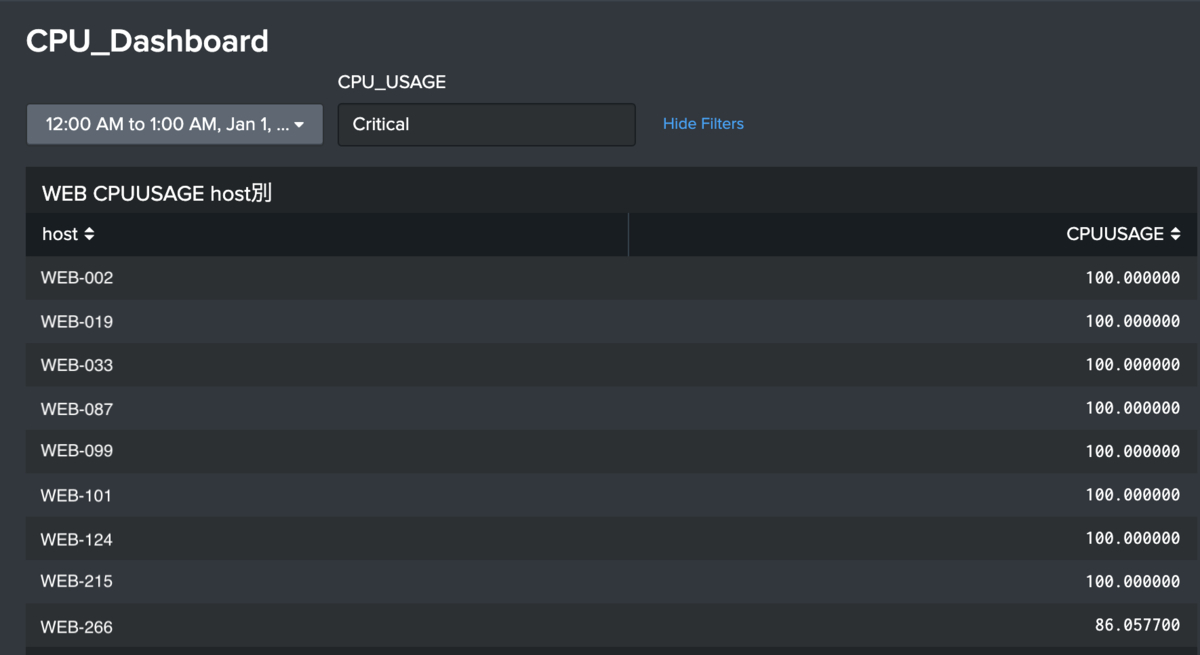
Criticalまで負荷が上昇しているインスタンスが9台存在しているようです。ここではどのインスタンスなのかを特定できるサーチもあると便利だと感じたため、次の連携部分で説明していきます。
ダッシュボードを連携させる
では、次にダッシュボードを連携させていきます。
今回はCPU Levelのパネルをクリックすると詳細のダッシュボードへと遷移し、該当するインスタンスをリスト表示させます。そのために、連携させたいダッシュボードに対してパラメータを設定していきます。調査する時間範囲と選択したCPU Levelをトリガーとするため、パラメータは以下の3つを使用します。これをDrilldown Editorで設定します。
| 項目 | パラメータ名 | トークン名 |
|---|---|---|
| 開始時刻 | form.time_token.earliest | $earliest$ |
| 終了時刻 | form.time_token.latest | $latest$ |
| CPU Level | form.cpulevel | $trellis.value$ |

このトリガーを受け、遷移先のダッシュボードではトリガーを受け取るパラメータを設定が必要です。Add InputからTextとTimeを設置します。
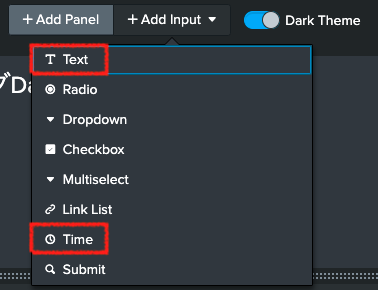
続いて、先程設置したTextフォームを以下のように編集します。Tokenには選択したCPU Levelを渡すため、このように入力します。

そして、サーチ文を以下のように用意します。
| mstats p95(_value) prestats=true WHERE metric_name="Processor.%_Processor_Time" AND "index"="em_metrics" AND "host"="WEB*" AND `sai_metrics_indexes` span=1m BY host | bin _time span=1m | stats p95(_value) AS avg_cpu BY host | eval Description=case(avg_cpu<=30,"Clear",avg_cpu<=50,"Attention",avg_cpu<=70,"Warning",avg_cpu<=85,"Problem",avg_cpu<=100,"Critical") | eval range=case(Description="Clear", "low", Description="Attention", "guarded", Description="Warning", "elevated", Description="Problem", "high", Description="Critical", "severe") | WHERE Description="$cpulevel$" | rename avg_cpu AS "CPUUSAGE" | fields host CPUUSAGE
なお、先程設定したTokenは、サーチ文では以下のように指定します。
| WHERE Description="$cpulevel$"
そして、下図が完成したダッシュボードです。ダッシュボード内から、別のダッシュボードに遷移させることで、さらに詳細を調査するといった使い方が可能です。
サーチに要する時間を短縮させる工夫
Splunkは、取り込んだデータを元に目的のフィールドを抽出するなど、作り込み可能な点が最大の特徴です。しかし、膨大な量のログからデータを抽出する際には、かなりの時間を要する可能性もあります。例えば、過去のレスポンスタイムをTimechartで表示したい場合に、対象の期間が長ければ長いほどサーチにかかる時間も比例して増加します。
Search Modeによる実行時間の差
基本的にはVerbose Modeでサーチを実行するケースが多いでしょう。しかし、Fast Modeに変更するだけで実行時間の改善を見込める場合があります。実際、実行時間にどのくらいの影響を与えるのか確認していきます。
実験に使用したサーチ文は以下の通りです。これを使い、過去24時間分のデータを取得してみます。
index=main sourcetype="ms:iis:auto" host=WEB* | eval response_time_msec=(response_time/1000) | timechart avg(response_time_msec) AS "レスポンス(平均値)" perc95(response_time_msec) AS "レスポンス(p95)" span=1m
まず、Verbose Modeでサーチを実行してみます。開始から7:50経過した段階では、24%しか進行していません。

同様にFast Modeでサーチを実行してみます。すると、半分程度の3:27で完了しました。

このように、取得したいフィールドデータが限定されている場合にはFast Modeを使うことで時間を短縮できます。しかし、複数のパネルが設置されているダッシュボードの場合には、結果が返ってくるまでに時間を要することもありえます。
また、複数人で重いダッシュボードを開いてしまうとサーチヘッドやインデクサーといったSplunkのコンポーネントが悲鳴をあげるでしょう。
Summary Indexを使ってみる
前述の課題を解決するために、Summary Indexを利用することをお勧めします。ライセンスやコストには影響がないため、使用することによるデメリットは基本的にありません。
Summary Indexの設定をしていきます。
Index nameは分かりやすいものにしましょう。そして、Max raw data sizeは0GBにします。次に設定するSearchble timeとArchive Retention Periodは今回の例ではいずれも3年としています。
入力が完了し、保存をすると数分でIndexが作成されます。

次に、新しく作成したIndexにサーチ結果を蓄積させていきます。
まず、実行させるサーチ文を書きます。レスポンスタイムを取得するサーチ文の最後に| collect index=response_data"を追加してください。このサーチ対象時間は今回の例では過去60分としています。
index=main sourcetype="ms:iis:auto" host=WEB* | eval response_time_msec=(response_time/1000) | timechart avg(response_time_msec) AS "レスポンス(平均値)" perc95(response_time_msec) AS "レスポンス(p95)" span=1m | collect index=response_data
作成したサーチ文の実行後、Save AsでReportに保存します。ここでも名前は分かりやすいものにします。

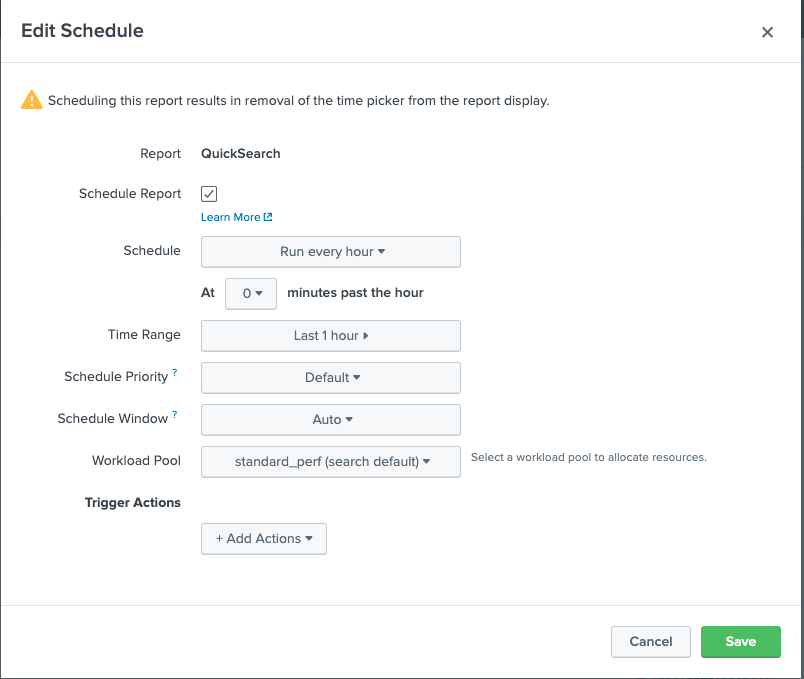
作成したレポートを定期実行させることで、データの蓄積が自動で行われます。定期実行をするために、Edit Scheduleから実行間隔を登録します。

サーチ時間を過去60分としているので、毎時0分になったら実行するように設定します。サーチにかかる時間が数秒から10秒程度であれば、毎分稼働させることも可能です。
スケジュール登録が完了したら、実際にどのようにデータが保存されているか確認してみましょう。
index=response_data
Indexのみを指定してサーチを実行することで、データの格納形式を確認できます。

項目名がそのままフィールド名として格納されているので、これを利用してTimechartにしてみます。
ここでは、過去24時間でTimechartを描画します。
index=response_data | timechart span=1m avg(レスポンス(p95)) AS レスポンス(p95) avg(レスポンス(平均値)) AS レスポンス(平均値)
これを実行すると、過去24時間のサーチが1秒で完了しました。
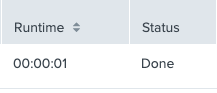
このように、取得する項目があらかじめ決まっていて、値だけが欲しい場合にはSummary Indexを駆使したダッシュボードを活用することで、どれだけパネルが増えても、ストレスなく表示させることができます。現在、ZOZOTOWNのサービス監視で利用しているダッシュボードのパネルの大半でSummary Indexを利用しています。
さいごに
Splunkを導入して1年半が経過し、様々なチームでSplunkの活用が進んでいます。サーチ結果で異常検知したらSlackにアラートを通知をするなど、運用改善にも貢献できています。
また、Splunk Synthethic MonitoringやSplunk Real User Monitoringなどの新製品がリリースされているので、機会があれば試してみたいと思います。
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!