



こんにちは。技術開発本部SRE部の渡邉です。
リモートワークによる運動不足を解消するために毎朝ロードバイクで走る事を始めたところ、今では印旛沼1のまわりを走るのが生きがいになりました。
そんな私ですが2019年に入社して以降、現在に至るまで、ZOZOTOWNやWEARのインフラを担当しております。
前職からずっとインフラ周りの仕事をしておりますが常に頭を悩ませてきたのは監視の設計と構築というテーマでした。長年稼働しているプロダクトならば、まず抱えている問題のひとつにあがるのではないでしょうか。私たちが日々運用しているZOZOTOWNでも同様に監視システムで課題を持っていました。 本記事ではリプレイスプロジェクトが進むZOZOTOWNのインフラの可視化を向上させる目的でSplunkを導入し、得られたメリットについて紹介したいと思います。
背景
2020年現在、ZOZOTOWNは劇的な変化を遂げており、サービス開始当初から稼働しているオンプレミスとマイクロサービス化が進んでいるパブリッククラウドのハイブリッドな構成になっています。
リプレイスが進むにつれて、必然的に従来の監視システムだけでは成り立たなくなります。
また、移行を推進していく過程における副産物として監視システム自体のサイロ化を生みやすくもなるため、見直しを図る時期に差しかかっていました。
そこで、様々な機器からログを収集することで障害検知までの速度改善が見込め、今後の一元管理も可能となるSplunkの導入を決定しました。
Splunkの基礎知識
私自身、今までにSplunkを使用した経験はありませんでしたが、度々Splunkに関する説明を受けていて、以下の点が私たちにとってメリットがあると感じていました。
- クラウド版を選択することで、インフラの設計を待たずに導入が可能であること
- 様々なAdd-onの提供がSplunkbaseでされており、可視化する際に特別な工夫をしなくても簡単にダッシュボードを作成できること
- 取り込んだログはSplunk側で適切なログフォーマットにあわせた成形をしてくれること
Search Processing Launguage(SPL)について
基本的な情報については様々な記事で紹介されているため詳細は割愛しますが、Splunkを使うためには Search Processing Launguage(SPL) を理解する必要があります。
SPLはBashと似ている部分もあればSQLと似ている部分もあるので、慣れるには実際のログを入れて動かすことが手っ取り早いと思います。そのため、Splunk Free版を使うことで手元のログを所定の形式でインポートして実際に試すことができます。Free版なので様々な制約はあるものの大体の使用感を理解するのは充分です。
なかでも参考にしたのは以下のリファレンスです。 Splunk Fundamentals 1 は無償で受講可能となっているEラーニングですがとても充実しています。
サーチの使い方
index=main sourcetype="ms:iis:auto" host="Server*"
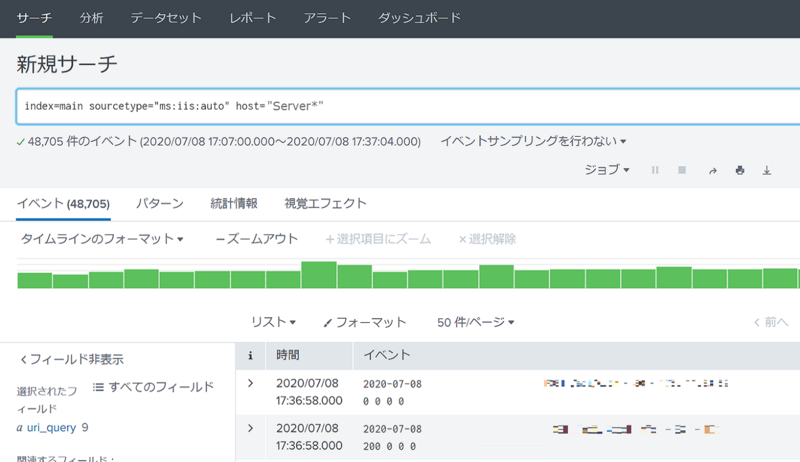
サーチ結果について、デフォルトではイベントが表示されています。この結果をどのように表示させるか以下の4種類から選択可能です。
- イベント
- パターン
- 統計情報
- 視覚エフェクト
グラフィカルに結果を出力できる視覚エフェクトを一番多く使います。チャートやグラフなどあらかじめ複数用意されていますし、サーチ結果に合わせてエフェクトを推奨するパターンもあり、親切に作られています。

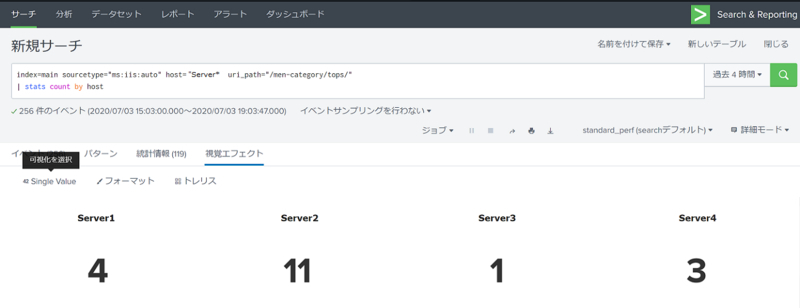
次のサーチ文は特定のUri_Pathのアクセス回数をホストごとにカウントした結果を出力する例です。このサーチ結果を単純に回数を表現するSingle Valueを使って出力してみます。
index=main sourcetype="ms:iis:auto" host="Server*" uri_path="/men-category/tops/" |stats count by host
Single Valueの表示を"トレリスレイアウト"で設定すると、それぞれのホストごとに集計した画面を作ることができました。
監視ダッシュボードを作る
あらかじめ監視画面を作成しておくために、必要なサーチ結果を組み合わせてダッシュボードを用意します。
作成したダッシュボードはこんな感じです。
- エラー発生件数
- レスポンスタイム
- CPU使用率

今回はサーバでHTTP Status 500が発生していた例を使って説明します。
エラーカウントの推移
まず、HTTP Status 500の発生推移を確認します。
特定のサーバに偏っている場合はエラー回数を単純にカウントして降順ソートで出せば完了です。
index=main sourcetype="ms:iis:auto" host"=Server*" AND status=500 | stats count by host | sort - count
しかし、今回は時間軸と傾向を把握したいため、サーバグループごとに分けて抽出しています。
index=main sourcetype="ms:iis:auto" AND (host=ServerA* OR host=ServerB*) AND status=500 | eval servergroup= case(like(host,"%ServerA%"),"ServerGroup1",like(host,"%ServerB%"),"ServerGroup2") | timechart span=1m count as error_count by servergroup
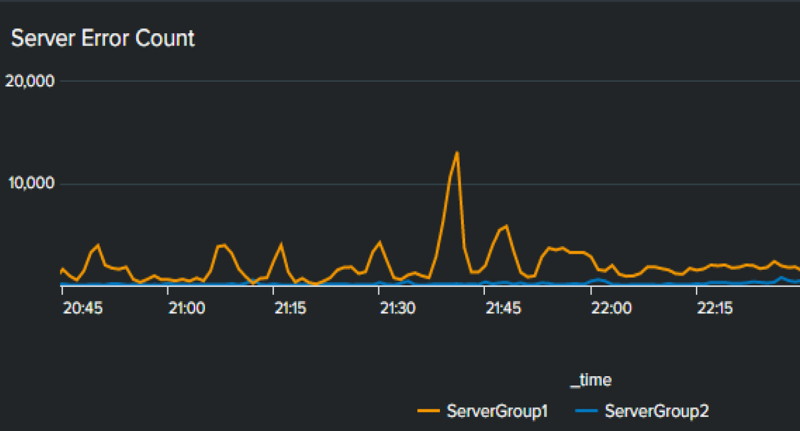
エラー発生状況のグラフを確認するとServerGroup1に偏っている状態がわかります。ServerGroup2側と比較すると、よりその差が明確になっています。
レスポンスタイムの推移
続いてレスポンスタイムの傾向も同様にサーバグループごとに抽出しています。
index=main sourcetype="ms:iis:auto" AND (host=ServerA* OR host=ServerB*) | eval servergroup = case(like(host,"%ServerA%"),"ServerGroup1",like(host,"%ServerB%"),"ServerGroup2") | timechart span=1m avg(time_taken) as responsetime by servergroup

レスポンスタイムの比較でもServerGroup1とServerGroup2に明らかな差が生じていました。
CPU使用率の推移
最後にmstatsというメトリクスサーチでサーバのメトリクスデータからCPU使用率を確認しています。
| mstats avg(_value) prestats=true WHERE metric_name="Processor.%_Processor_Time" AND "index"="em_metrics" AND (host=ServerA* OR host=ServerB*) AND `sai_metrics_indexes` span=1m | eval servergroup = case(like(host,"%ServerA%"),"ServerGroup1",like(host,"%ServerB%"),"ServerGroup2") | timechart avg(_value) AS Avg span=1m by servergroup | fields - _span*
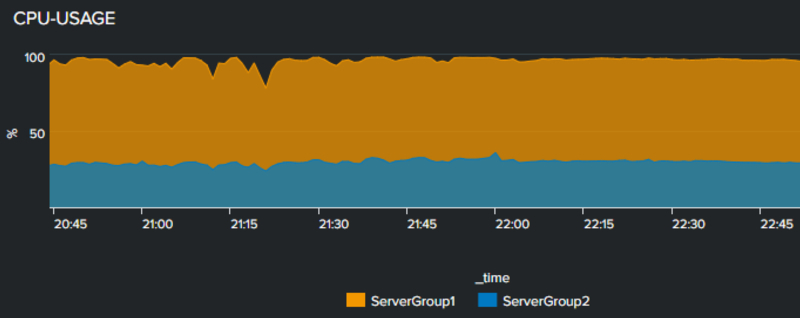
同じ時間帯にも関わらずServerGroup1のCPU使用率が100%で張り付いてしまっている状況でした。エラー発生数とレスポンスの悪化を引き起こしていた原因はCPUの高負荷状態にあったと言えます。
アクセス数の単純増加など、高負荷を引き起こす外的要因が明らかになっていれば、調査に要する時間はもっと短くなるためダッシュボードにアクセス数も組み込んでいくこともできます。
このあたりはログ分析とあわせてメトリクス監視の要素を組み込むこともできる自由度の高さもSplunkの特徴だと思います。
Splunk App for Stream

SplunkにはSplunk App for Streamというネットワークキャプチャも存在しています。
これによってWebサーバから外部APIへ接続する際のレスポンスを取得していく事が可能になるため、サーバ内外のレスポンスの変化を調べることも可能になります。
index=main sourcetype="stream:http" site IN (*api*) host="Server*" | rename "sum(time_taken)" as time_taken | eval response=(time_taken/count/1000) | timechart avg(response) span=1m as avg by site

Streamで取得できるレスポンスタイムの値はマイクロ秒になっているため計算をミリ秒に合わせています。
サーバからAPIへの内部通信のレスポンスを確認できるのはかなり重宝します。
しかしながらIngestされるデータ量が爆増するため事前にSplunkの方と容量の増加について相談をしておいたほうが良いです。
Splunk App for Infrastructure

すでにダッシュボードで使用していたメトリクスサーチという機能で機器のメトリクスデータを扱うことができるAppです。
以下の画面はサーバ単体のメトリクス概要になります。様々な項目を収集できていることがわかります。
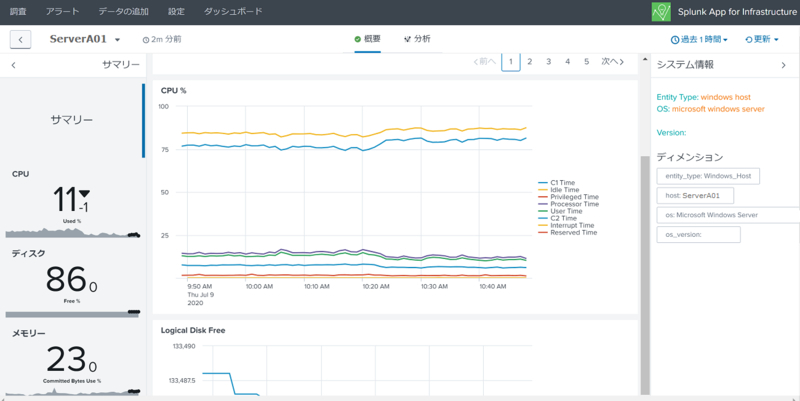
ほかのサーチ文同様に複数のサーバを組み込むことができるのでちょっとした変化に気づきやすくなりますし、比較対象をわかりやすく表示したい場合に重宝します。
| mstats avg(_value) prestats=true WHERE metric_name="Memory.Available_Bytes" AND "index"="em_metrics" AND "host"="ServerA01" OR "host"="ServerA02" OR "host"="ServerA03" AND `sai_metrics_indexes` span=10s | timechart avg(_value) AS Avg span=10s by host[f:id:vasilyjp:20200713120129j:plain] | fields - _span*

ここで使用しているmstatsは、ほかのサーチと比べて結果を高速で返すため、あまりストレスがかからずに調査できる点もメリットです。
Splunk導入の効果とまとめ
Splunkを導入してから、アラート発生時にSplunkで調査するというアクションをチーム全員が自然と取るようになっています。得られたデータをすぐにダッシュボードで共有する流れになったことで、誰が、どういった問題を検知したのかを視覚的に理解しやすくなったといえます。その結果、以前と比較して、アラートに対する動きが格段に速くなったと感じています。
今回は紹介しきれませんでしたが、次の機会があればSplunkの機械学習を使った監視設定や効率よいサーチの作り方について紹介できたらと思います。
ZOZOテクノロジーズでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!