


はじめに
こんにちは、ブランドソリューション開発本部バックエンド部SREブロックの小林(@mirai_kobaaaaaa)です。普段はWEARやFAANSというサービスのSREとして開発、運用に携わっています。
WEARではAmazon Elastic Kubernetes Service(以下、EKSと呼ぶ)を用いて複数システムのインフラ基盤を構築・運用しています。その中の1つとして、ワークフロー処理の実行基盤が存在しています。
本記事では、そのワークフロー実行基盤が抱えていた課題と、それらをどのように解決したのかを紹介します。また、付随して得られたメリットについても紹介いたします。
目次
- はじめに
- 目次
- WEARにおけるワークフロー
- ワークフロー実行基盤の課題
- コスト内訳の調査
- ワークフロー実行基盤の改修方針
- EKS on EC2へのリプレイス
- リプレイス作業
- 切り替え
- 結果
- その他影響
- 終わりに
WEARにおけるワークフロー
まずは、WEARにおけるワークフローとは何か、どのような構成だったのかを紹介します。
ワークフロー処理内容
WEARで運用しているワークフロー実行基盤は、例えば以下のような処理を行っています。
- コーディネート情報の更新
- アイテム情報の更新、紐付け
- ユーザー情報の更新
これらは決まった時間に実行されるスケジュールワークフローとして稼働しています。処理内容によって数分で終わるものから数時間かかるものが存在しており、1日あたり約1500件が実行されています。
ワークフロー実行基盤の構成
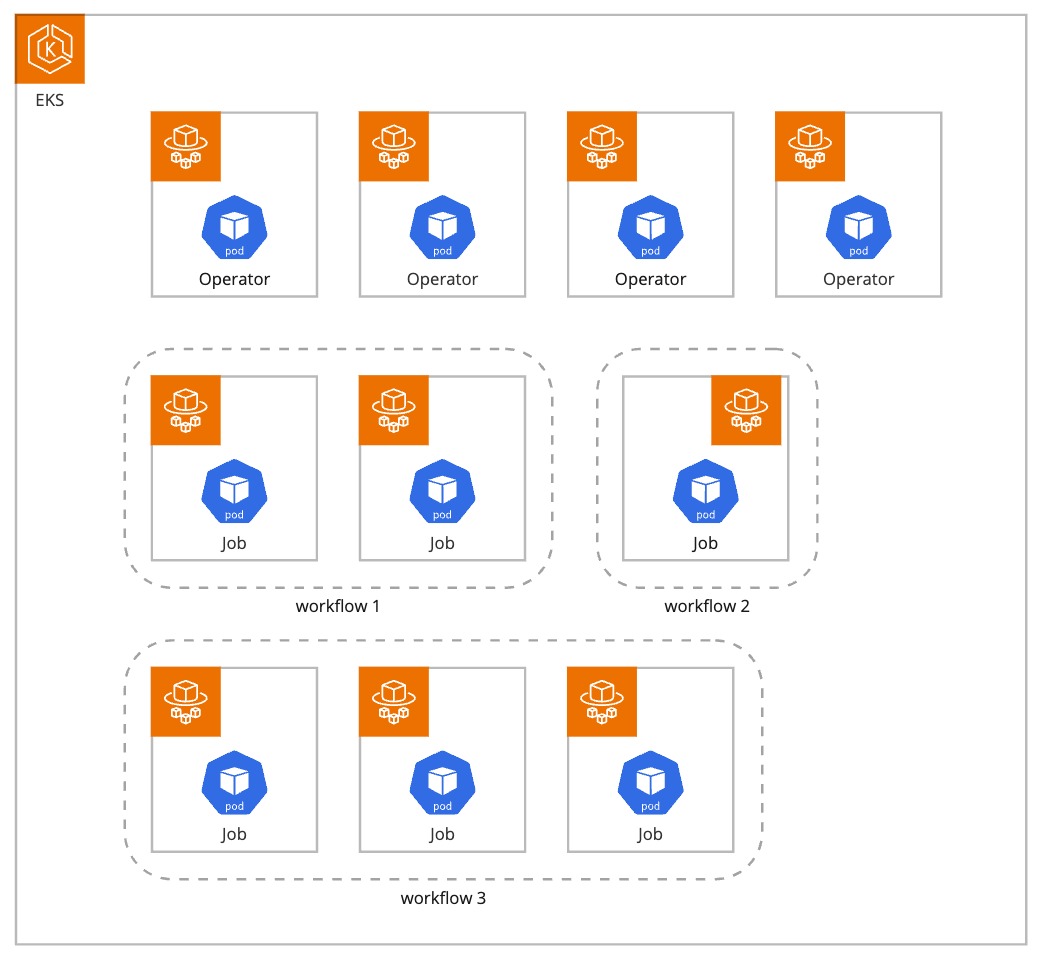
前述の通り、ワークフロー実行基盤はEKSを用いて構築されていました。また、Pod実行基盤としてはAWS Fargate(以下、Fargateと呼ぶ)を採用していました。Fargateで実行されるPodは自動的にワーカーノードがプロビジョニングされるため、運用負荷を減らせると考えたからです。
ワークフロー実行時には子タスクとして1つ以上のJobが起動します。Job実行時には単一のPodがプロビジョニングされます。ワークフローの内容によっては複数のJobが実行されることもあります。
また、このEKSにはワークフローシステム以外に各種Kubernetes Operator(以下、Operatorと呼ぶ)が存在していました。GitOpsで利用するArgo CDやAWSのElastic Load Balancingを管理するためのAWS Load Balancer Controller等です。
ワークフロー実行基盤の課題
ワークフロー実行基盤が抱える最たる課題はコストでした。ワークフロー数や実行回数が増えるにつれ、EKS内でプロビジョニングされるPodも単純増加し、比例してコストも増加していきます。
WEARにおけるコーディネート情報更新数やアイテム処理件数の増加はサービス拡大と同意義です。しかし、サービス拡大とサービスを支える基盤コストが単純比例してしまう構成では、サービス成長を鈍化させる要因の1つとなってしまいます。
これらの理由から、コスト効率性の高い基盤を構築することが急務と考え、ワークフロー実行基盤の改修を決定しました。
コスト内訳の調査
ワークフロー実行基盤において、まずは何がコストセンターになっているかを把握する必要がありました。そのため、AWS Cost Explorerや各種ログ、メトリクスを用いてコスト内訳を調査しました。
その結果、下記要因によりコスト増加を引き起こしていることがわかりました。
- 過剰なPodスペック
- Fargate実行時間の増大
Fargateコストについても触れながら、それぞれの要因について説明していきます。
過剰なPodスペック
Fargateは、割り当てられたスペック、実行時間、Pod数に応じて課金されます。つまり、Podに割り当てられたスペックが大きいほど、コストも増加していくことになります。
CloudWatchやDatadogを確認したところ、Podに割り当てられたスペックと実際に消費されるメトリクスに乖離がありました。これにより不要なコストが発生していました。
この要因については、各Podに対して適切なリソースを割り当て直すことで早々に改善が見込めると考えました。
Fargate実行時間の増大
続いて、Fargate実行時間の増大についてです。
先に述べた通り、Fargateコストは実行時間にも比例します。実行時間はイメージのダウンロードを開始した時間からPodが終了するまでの時間を指します。
Kubernetesログを確認したところ、1Pod起動にあたり25秒程度のイメージダウンロード時間がかかっていました。1日に起動されるPod数は1500以上であるため、1日あたりのイメージダウンロード時間は約10時間にも及びます。
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Pulling 27s kubelet Pulling image "xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/workflow:latest" Normal Pulled 2s kubelet Successfully pulled image "xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/workflow:latest" in 25.246397319s Normal Created 2s kubelet Created container workflow Normal Started 2s kubelet Started container workflow
この問題を解決するため、まずはイメージサイズの削減を検討しました。WEARはモノリシックなアプリケーションとして構成されており、イメージ自体が大きくなりがちでした。そのため、このアプローチが有効であると考えました。
イメージサイズの削減方法としてはzstdによるイメージ圧縮方法の変更を検討しました。zstdはMeta社によって開発された圧縮アルゴリズムであり、使用していたgzip圧縮より圧縮率と解凍速度の向上が見込めたからです。
zstd圧縮テストの結果、イメージサイズを削減できました。しかし、私たちのケースではイメージダウンロード時間へ与える影響は極小規模に留まったため、別のアプローチを検討することにしました。
余談ですが、zstd圧縮アプローチについてはAWS公式よりブログが公開されています。イメージサイズにお困りの方は是非ご覧ください。
最終的に選ばれたのは、EKS on FargateからEKS on EC2へのリプレイスでした。ワーカーノードとしてEC2を使用することで、イメージキャッシュを用いたイメージダウンロード時間の削減が期待できます。
また、ワークフローの性質上、Podは頻繁に入れ替わることが予想されます。そのため、ピーク時の同時実行数をもとにEC2サイズを決定することで、Fargateと比べてより少ないワーカーノードでワークフローを処理でき、ワーカーノードのコスト削減が可能だと考えました。
ワークフロー実行基盤の改修方針
各要因へのアプローチ方法を検討した結果、下記方針で進めることにしました。
- Podに割り当てられたスペックの再調整
- EKS on FargateからEKS on EC2へリプレイス
まずは、1つ目のPodに割り当てられたスペックを再調整しました。
計測された実績値に基づいて各Podに割り当てられたスペックを調整します。テスト等を挟みましたが、作業自体は数日で完了しました。
2つ目のEKS on FargateからEKS on EC2へのリプレイスについては、より詳細に設計しました。
EKS on EC2へのリプレイス
EKS on EC2へリプレイスするにあたり、下記を決定しました。
- ワーカーノードのプロビジョニング方法
- 各Podのノード配置戦略
- ワーカーノードのインスタンスタイプ選定
- ワーカーノードのスケーリングプロダクト選定
ワーカーノードのプロビジョニング方法
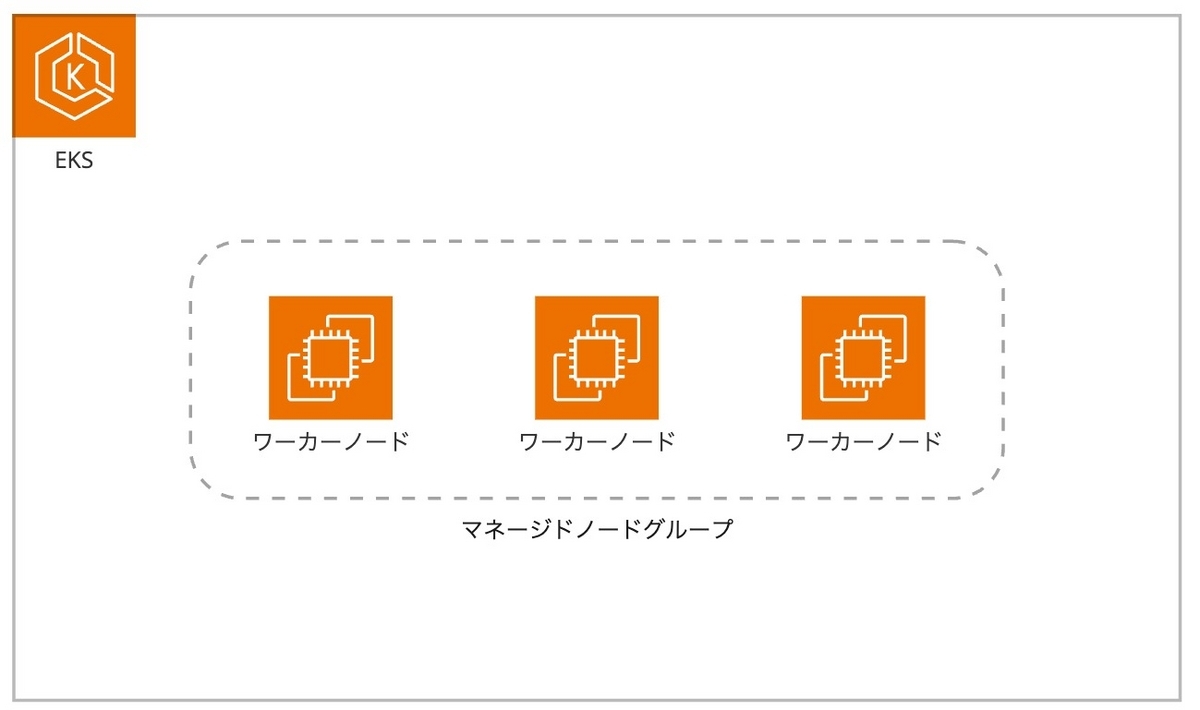
最初にワーカーノードをどのようにプロビジョニングするかを考えました。EKSでEC2をノードとして利用する場合、大きく分けてセルフマネージドノードとマネージドノードの2種類があります。セルフマネージドノードは自身で作成したEC2インスタンスをノードとして利用し、必要に応じてAmazon EC2 Auto Scalingを作成、管理します。一方マネージドノードは、AWSによってEC2インスタンスが自動作成され、それに紐づくAmazon EC2 Auto Scalingもプロビジョニングされます。
今回はセルフマネージドノードを使用するほどのカスタマイズ性が必要ないこと、既に別クラスターで運用経験があったことからマネージドノードを採用しました。また、ワークフローの途中停止リスクを下げたいため、スポットインスタンスではなくオンデマンドインスタンスを使用することにしました。
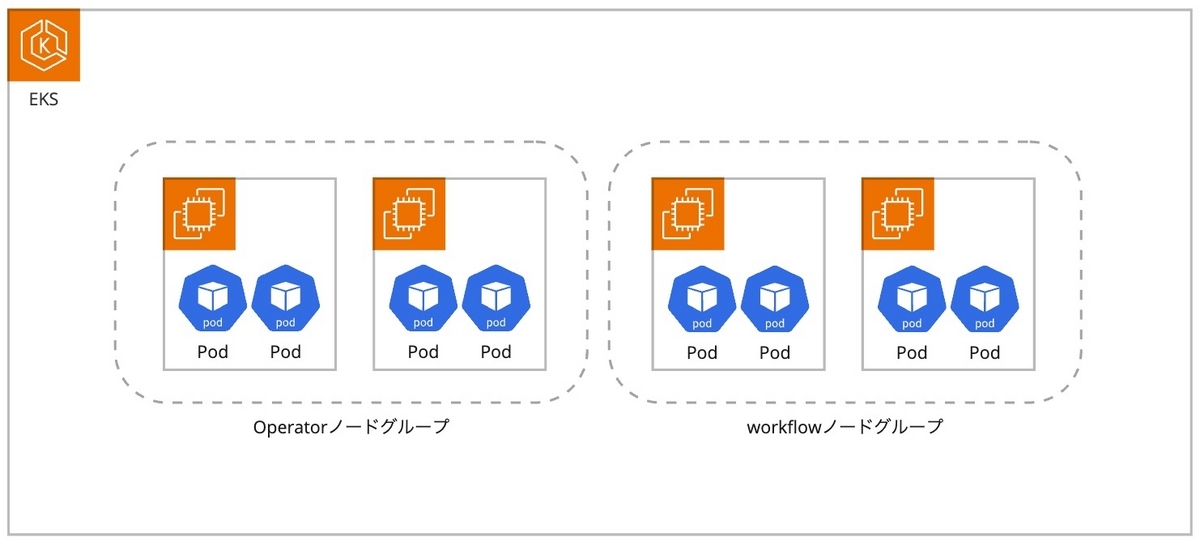
各Podのノード配置戦略
2つ目は、どのPodをどのワーカーノードに配置すべきかという問題です。先に述べた通り、ワークフロー実行基盤のEKSクラスター内にはArgo CD等のOperatorも存在しています。Operatorと同様のワーカーノードにPodを配置することで、ノード数を削減し、コストがより圧縮できます。しかし、Operator系Podによるノードレベルの影響を避けたいと考え、ワークフロー実行PodはOperatorとは別のワーカーノードに配置しました。
ワーカーノードのインスタンスタイプ選定
続いて3つ目に記載したワーカーノードのインスタンスタイプ選定です。調査でも述べましたが、ワークフローの性質上、常に一定のPodが実行されているわけではありません。そのため、ピーク時の同時実行数や負荷傾向をもとにインスタンスタイプを決定しました。
ちなみに、現在は後述するKarpenterの採用によってインスタンスタイプを細かく管理していません。ワークロードの負荷傾向から最適となるようインスタンスファミリーを選択するのみに留まっています。
ワーカーノードのスケーリングプロダクト選定
最後に、ワーカーノードのスケーリングプロダクト選定です。Fargateは1つのPodに対して1つのワーカーノードが自動でプロビジョニングされます。つまり、Horizontal Pod Autoscaler等を用いてPod数を増加させることでワーカーノードを含めた水平スケーリングが可能です。
しかし、EC2をワーカーノードとして使用する場合、Podのスケーリングだけでなくワーカーノードのスケーリング方法も考慮する必要があります。今回はEKSで利用できるスケーリングプロダクトを調査し、比較の上選定しました。
スケーリングプロダクトの概要
EKSでは下記2つのスケーリングプロダクトをサポート1しています。
Cluster AutoscalerはKubernetesが公式で用意しているスケーリングプロダクトです。EKSにおける動作としてはマネージドノードグループ及びAuto Scaling Groupを書き換えることで、EC2インスタンスを追加起動し、起動プロセス完了後にEKSへワーカーノード登録をします。
一方で、KarpenterはOSSとして公開されているスケーリングプロダクトであり、Cluster Autoscalerとは異なる方法でスケーリングを行います。Karpenterは待機中Podのリソースリクエストに応じて必要なワーカーノードのサイズを計算し、必要に応じてワーカーノードを追加、削除します。この時、Auto Scaling Groupは利用しません。ワーカーノード追加時には、待機中Podの情報をもとにした必要な容量の計算、要求を満たすEC2インスタンスの選択と起動、EKSへのワーカーノード登録をします。
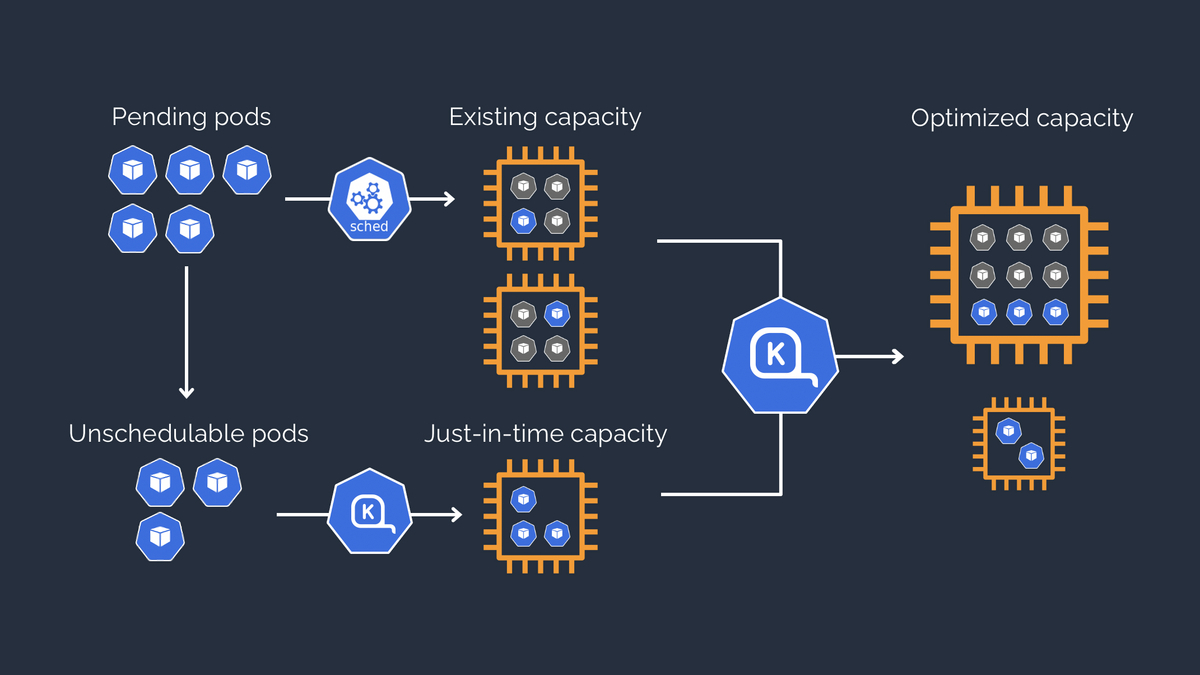 (https://karpenter.sh/より引用)
(https://karpenter.sh/より引用)
選定ポイントと選定結果
選定のポイントとして、スケーリング速度に重点をおきました。ワークフロー実行基盤において、スケーリング速度は非常に重要です。スケーリングに時間がかかってしまえば、ワークフロースケジュール全体、ひいてはサービスへの悪影響が発生してしまいます。
下記はPodがスタートするまでの比較結果2です。イメージキャッシュなしはワーカーノード追加と読み替えてください。Fargateはワーカーノード追加も同時に行うため、イメージキャッシュなしとしています3。
| スケーリングプロダクト | イメージキャッシュなし | イメージキャッシュあり |
|---|---|---|
| Cluster Autoscaler | 70s | 3s |
| Karpenter | 60s | 4s |
| Fargate | 57s | - |
EC2インスタンスをワーカーノードとして登録する工程が発生するため、Fargateが優位だろうと推測していました。しかし、意外にもKarpenterも十分な速度を有していました。また、イメージキャッシュが存在する場合のPod起動速度はやはりEC2が非常に高速です。
検討を重ねた結果、Karpenterを採用しました。決め手となったのは、必要なリソースリクエストに応じて柔軟にEC2インスタンスを選択する機能を有していたからです。これは今回の課題に対して非常に魅力的でした。
リプレイス作業
最終的な構成はこのようになりました。
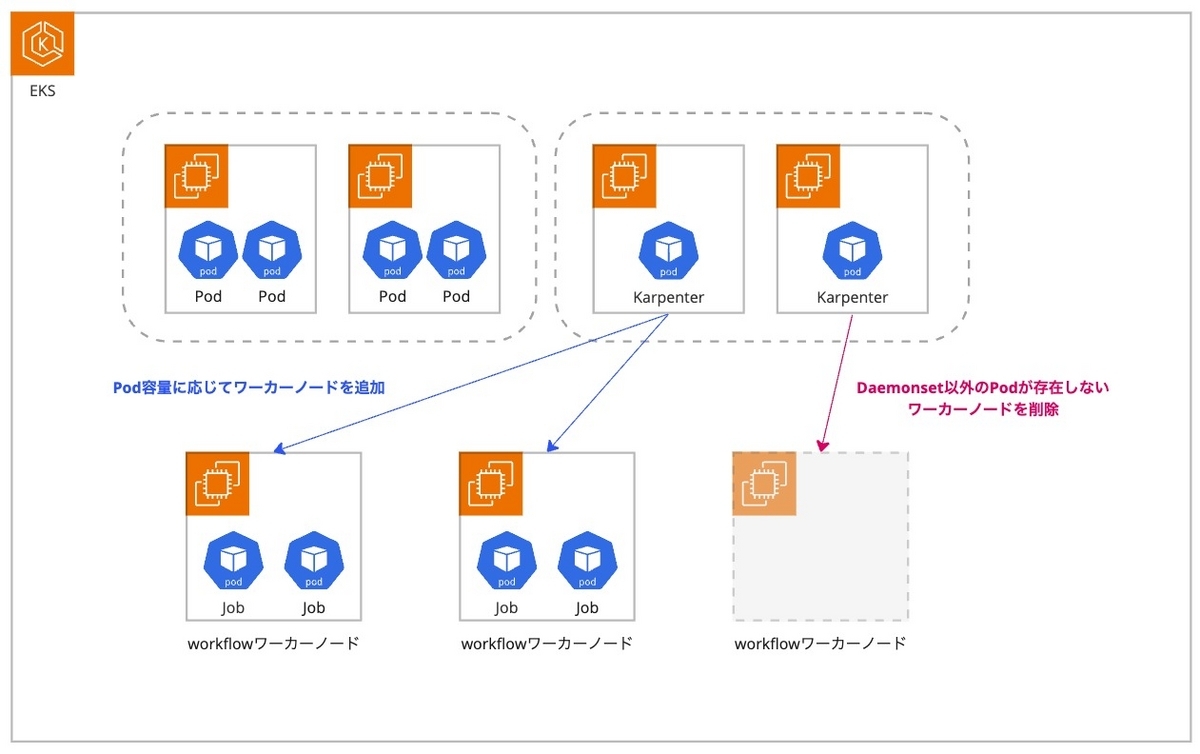
Operator系Podはcommonというマネージドノードグループに配置します。CPU使用率の低いPodがほとんどであり、極稀に負荷が上がるもののバーストクレジットで対応可能と考えT系インスタンスを使用しています。
Karpenterは普段から一定の処理をしており、かつ本構成の心臓部分です。そのため、安定したワークロードを実行できるようにM系インスタンスと独立したマネージドノードグループで構成しています。
実際にワークフローが実行されるワーカーノードの管理はKarpenterに委ねています。スケーリングプロダクト選定でも述べた通り、Karpenterは待機中Podのリソース要求をもとに最適なインスタンスタイプを計算、決定し起動します。
EKSクラスターの作成
既存環境への影響を考慮し、Blue/Greenデプロイメントを利用してクラスターを切り替えることにしました。そのため、新しいクラスターを作成する必要があります。以下はterraform-aws-modules/eks/awsを用いたクラスター設定例です。Submoduleのeks-managed-node-groupを使用し、マネージドノード設定も記述しています。
# main.tf module "workflow_cluster" { source = "terraform-aws-modules/eks/aws" version = "19.6.0" cluster_name = "workflow-cluster" cluster_version = 1.24 vpc_id = var.vpc_id subnet_ids = var.subnet_ids enable_irsa = true # Karpenterがこのタグを見てノードを立ち上げる node_security_group_tags = { "karpenter.sh/discovery" = "workflow-cluster" } # Submoduleのeks-managed-node-groupを利用 eks_managed_node_groups = { # Operatorを設置するマネージドノードグループ common = { name = "common" desired_size = 2 min_size = 2 max_size = 6 instance_types = ["t3.large"] disk_size = 20 capacity_type = "ON_DEMAND" iam_role_additional_policies = { AmazonSSMManagedInstanceCore = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore" } labels = { NodeGroupName = "common" } } # Karpenter本体を設置するマネージドノードグループ karpenter = { name = "karpenter" desired_size = 2 min_size = 2 max_size = 6 instance_types = ["m5.large"] disk_size = 20 capacity_type = "ON_DEMAND" iam_role_additional_policies = { AmazonSSMManagedInstanceCore = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore" } labels = { NodeGroupName = "karpenter" } } } }
Operator系Podの配置
構成図の通り、マネージドノードグループが2種類存在するため、適したPodを適したノードグループに配置する必要があります。そのため、各OperatorのmanifestにNode Affinityを設定し、Podを配置するノードを宣言的に選択します。私たちはArgo CD経由でHelm Chartを使用していたため、helm valuesに設定を追加します。
helm: values: | affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: NodeGroupName operator: In values: - common
この設定により、NodeGroupNameというLabelにcommonという値が設定されたノードにのみPodが配置されます。
Karpenterの設定
続いてKarpenterの設定です。KarpenterがEC2を起動できるようIRSAを作成します。
# main.tf # Karpenter用のIRSAを作成 module "karpenter_irsa" { source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks" version = "5.14.0" role_name = "workflow-cluster-karpenter-controller" attach_karpenter_controller_policy = true karpenter_tag_key = "karpenter.sh/discovery" karpenter_controller_cluster_id = module.workflow_cluster.cluster_name karpenter_controller_node_iam_role_arns = [ module.workflow_cluster.eks_managed_node_groups["karpenter"].iam_role_arn ] oidc_providers = { ex = { provider_arn = module.workflow_cluster.oidc_provider_arn namespace_service_accounts = ["karpenter:karpenter"] } } } # Karpenterが起動するEC2インスタンスにアタッチするインスタンスプロフィール resource "aws_iam_instance_profile" "karpenter" { name = "workflow-cluster-KarpenterNodeInstanceProfile" role = module.workflow_cluster.eks_managed_node_groups["karpenter"].iam_role_name }
Karpenter本体をArgo CDのApplicationとしてデプロイします。
# karpenter.yaml apiVersion: argoproj.io/v1alpha1 kind: Application metadata: name: karpenter namespace: argocd finalizers: - resources-finalizer.argocd.argoproj.io spec: destination: namespace: karpenter server: https://kubernetes.default.svc project: default source: chart: karpenter repoURL: public.ecr.aws/karpenter targetRevision: v0.27.0 helm: releaseName: karpenter parameters: - name: 'settings.aws.clusterName' value: 'workflow-cluster' - name: 'settings.aws.defaultInstanceProfile' value: 'workflow-cluster-KarpenterNodeInstanceProfile' - name: 'settings.aws.clusterEndpoint' value: 'https://xxxxxxxxxxxxxxxxxxxxxx.gr7.eu-west-1.eks.amazonaws.com' - name: 'serviceAccount.annotations.eks\.amazonaws\.com/role-arn' value: workflow-cluster-karpenter-controller values: | affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: karpenter.sh/provisioner-name operator: DoesNotExist - matchExpressions: - key: NodeGroupName operator: In values: - karpenter syncPolicy: syncOptions: - CreateNamespace=true automated: prune: true
KarpenterはProvisionerというCustom Resourceを用いてワーカーノードの管理をします。インスタンス構成やネットワーク設定を指定することで、起動するインスタンスの制御が可能です。
# provisioner.yaml # KarpenterがAWSに立ち上げるEC2インスタンスの設定 apiVersion: karpenter.sh/v1alpha5 kind: Provisioner metadata: name: workflow-provisioner spec: # 起動するワーカーノードにworkflowというlabelを設定 labels: NodeGroupName: workflow requirements: - key: karpenter.k8s.aws/instance-category operator: In values: [m, r] - key: karpenter.sh/capacity-type operator: In values: ["on-demand"] - key: kubernetes.io/os operator: In values: - linux - key: kubernetes.io/arch operator: In values: - amd64 provider: # EC2を起動するサブネットやセキュリティグループ、タグを指定 subnetSelector: karpenter.sh/discovery: workflow-cluster securityGroupSelector: karpenter.sh/discovery: workflow-cluster tags: karpenter.sh/discovery: workflow-cluster # DaemonSet以外のPodが存在しない状態が30秒続くとワーカーノードを削除する ttlSecondsAfterEmpty: 30
最後に、ワークフロー実行PodがKarpenter経由で起動したワーカーノードに配置されるようNode Affinityを設定します。
# workflow.yaml spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: NodeGroupName operator: In values: - workflow
Node Affinityを設定することで、ワークフロー実行PodはworkflowというLabelが設定されたノードにのみ配置されるようになります。また、ワーカーノードのリソースが枯渇している場合はKarpenterが自動でEC2インスタンス起動、EKSへワーカーノードを登録します。
切り替え
先ほど述べた通り、Blue/Greenデプロイメントを用いた切り替えを行いました。
- 旧環境のワークフローを停止
- 新環境のワークフローを開始
- 停止期間中のワークフローを再実行(必要に応じて)
- 各種管理コンソールのドメイン切り替え
事前に疎通確認は取れていたこと、ほとんどのワークフローが後続実行でリカバリーできることから、ユーザーへの影響は発生しませんでした。
結果
これらの改修により、ワークフロー実行基盤のコストを大幅に削減できました。青い部分が旧環境の想定コスト、赤い部分が実際のコストです。
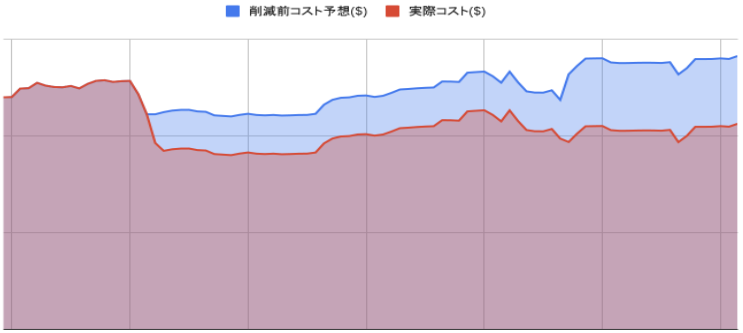
特に効果的だったのは、EC2インスタンスへPodを集約したことでした。これにより、効果的にリソースを使用でき、30%程度のコスト削減を実現できました。
その他影響
今回の改修は主にコスト削減を目的としていましたが、パフォーマンスにも影響がありました。特にイメージキャッシュの効果は大きく、連続して複数Podが実行されるようなワークフローでは、実行時間を20%程度高速化できています。
また、ワークロードに最適なEC2インスタンス4を割り当てることで処理も高速化され、7時間程度かかっていたワークフローを5時間程度まで高速化できました。
これらはWEARのサービス性質上、非常に喜ばしい結果でした。
終わりに
以上のように、WEARのワークフロー実行基盤を改修する取り組みを進めました。
ワークフロー実行基盤の構築当初は、Fargateを使用することで運用負荷を抑制でき、その時間を他の開発に割り当てできました。しかし、「今のWEAR」から見つめ直した時、違うアプローチを取るべきだと判断しました。このように、実装当時は最適であったものが、サービスの成長や環境変化と共に常に変わることを再認識できました。
現在、ワークフロー実行基盤は安定して稼働しています。引き続きサービスをより良いものにできるようコストとパフォーマンスの両軸で改善を進めていきます。
WEARでは、一緒にサービスを作り上げてくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
https://hrmos.co/pages/zozo/jobs/0000021hrmos.co
- 2023年8月16日時点の情報です。今後変更される可能性があります。↩
- 測定結果は環境によって異なります。あくまで参考値としてご覧ください。↩
- 厳密にいえばFargateは純粋なスケーリングプロダクトではありません。今回は比較のために記載しています。↩
- EC2インスタンスはインスタンスタイプによってプロセッサやアーキテクチャが異なります。そのため、ワークロードによっては同一vCPU、Memoryのインスタンスであってもパフォーマンス差異が発生します。参考:https://aws.amazon.com/jp/ec2/instance-types/↩