



はじめに
こんにちは。ブランドソリューション開発本部バックエンド部SREの山岡(@ymktmk)です。普段はファッションコーディネートアプリ「WEAR」のSREとしてクラウドの運用やリプレイスをおこなっています。
昨年から、私たちのチームでは分散した技術スタックをKubernetesへ統一するリプレイスプロジェクトを開始し、先月ついにKubernetesへの移行が完了しました。
また、Kubernetesへの段階的な移行と並行して、Kubernetesの柔軟性を活かした運用改善や開発者体験の向上に取り組んできました。その一環として、k6-operatorを活用した負荷試験基盤を作成しました。
本記事ではWEARにKubernetesネイティブな負荷試験基盤を導入した背景とその効果についてご紹介します。Kubernetes環境における負荷試験基盤の導入を検討している方の参考になれば幸いです。
目次
導入の背景
私たちのチームでは、これまで負荷試験に関して、各々が異なる負荷試験ツールを使用しており、統一されていませんでした。そのため、チームにおける負荷試験のノウハウの蓄積が難しく、特に新規メンバーは負荷試験の実施が容易ではありませんでした。テストシナリオも手探りで書く必要があり、開発効率が悪くなっていました。
このような課題を解決し、負荷試験の容易な実施とノウハウの蓄積を可能にするため、負荷試験基盤を導入しました。
負荷試験基盤の設計
要件
負荷試験基盤を構築するにあたって、3つの要件を定めました。
導入の背景で述べた通り、私たちのチームでは各々が異なる負荷試験ツールを使用しており、チーム内でのノウハウが蓄積されていませんでした。そのため、負荷試験ツールの統一が必要でした。
負荷試験ツールの統一にあたり、負荷試験を実施する開発者が簡素で馴染みのある言語でテストシナリオを記述できることはテストシナリオの作成・共有が容易になり、開発効率の向上が期待できます。
単一のマシン上で行う負荷試験では、そのマシンの性能の限界に達するまでの負荷しかかけることができません。分散負荷試験は、想定される大きな負荷を再現し、アプリケーションの振る舞いを再現できます。
負荷試験結果をレポートとして残すことで、チームメンバーとの負荷試験結果の共有を容易にし、レビュー時においてメンバーが理解しやすくなります。また、過去の負荷試験結果と比較できるため、パフォーマンスの劣化・向上とその要因を調査しやすくなります。
これらの要件を満たすことで、チームの課題を解決できると考えました。そして、適切な負荷試験ツールの選定とインフラ設計をしました。
負荷試験ツールの選定
選定対象の負荷試験ツールの概要と比較
はじめに述べた通り、私たちのチームは全ての基盤をKubernetesに移行することを決定しました。こうした背景から、Kubernetesの特徴である柔軟性を活かして負荷試験基盤を作成しようと考えていました。
そのため、Kubernetes上で実現可能な負荷試験ツールを調査しました。その結果、以下のツールが選定対象として挙げられました。
それぞれのツールの特徴を見ていきます。
GatlingはテストシナリオをScala(Gatling 3.7からはJavaやKotlinもサポート)のDSLで記述します。社内でも利用実績が豊富であり、GatlingをベースとしたKubernetes Operatorであるgatling-operatorを開発しています。
LocustはテストシナリオをPythonで記述します。Google Cloud Platformでは、「Google Kubernetes Engineを使用した負荷分散テスト」というテーマでKubernetes環境におけるlocustを使用した分散の負荷試験を紹介しています。
k6はテストシナリオをJavaScriptで記述します。k6にはKubernetes Operatorであるk6-operatorが公式から提供されています。
これら3つのツールを要件に基づいて比較した結果が以下です。
| 言語の馴染み深さ | 分散負荷試験 | レポート出力 | |
|---|---|---|---|
| Gatling | × | ○ | ○ |
| Locust | ○ | ○ | ○ |
| k6 | ○ | ○ | ○ |
k6の選定理由
Gatlingは社内で多くの利用実績がありましたが、テストシナリオをScalaで記述する必要があり、普段Rubyで開発しているWEARのエンジニアには馴染みがありませんでした。そのため、選択肢から外れました。
選定候補として残ったのがLocustとk6の2つでした。どちらも最低限の要件を満たしていましたが、最終的にk6を選択しました。k6を選んだ理由は、私たちのチームでは保守・運用性を重視し、Kubernetes Operatorであるk6-operatorが公式から提供されているk6を選択しました。さらに、チーム内で既にk6の利用実績があったことも選定の決め手となりました。
負荷試験基盤のアーキテクチャ
要件を考慮した上で、負荷試験基盤のアーキテクチャは以下のようになりました。
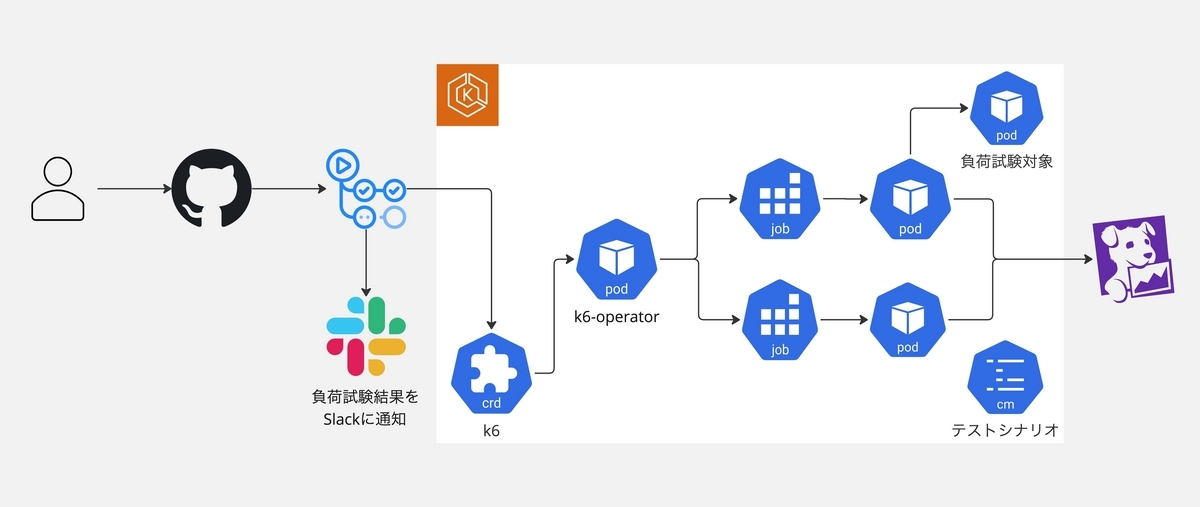
負荷試験の開始から終了までは以下の流れになります。
- GitHub Actionsワークフローを介してk6 Custom Resourceをクラスターに適用
- k6-operatorがk6 Custom ResourceをWatchし、Podを起動して負荷試験を開始
- Slackに負荷試験結果レポートのDatadogダッシュボードを送信
GitHub Actionsワークフローを介した負荷試験の実行
負荷試験の実行には、k6-operatorが実行されているクラスターにk6 Custom Resourceを適用する必要があります。ただし、k6 Custom Resourceをローカルから手動適用するのは手間がかかります。そのため、GitHub Actionsのワークフローを実行し、k6 Custom Resourceを適用するようにしました。GitHub Actionsを利用することで負荷試験を容易に実施でき、利便性が高いと考えました。
負荷試験結果レポートのDatadogダッシュボードの活用
負荷試験結果レポートはk6がDatadogのインテグレーションに対応していることから、Datadogダッシュボードを利用することにしました。また、私たちのチームでは以前からアプリケーションやDBのモニタリングにDatadogを利用していたため、Datadogダッシュボードを使って負荷試験結果レポートを確認できることは好都合でした。
次に実際に負荷試験を実施する際のフローとその仕組みを説明します。
負荷試験の実施フローとその仕組み
テストシナリオの作成
負荷試験基盤の実施者は、テストシナリオを記述します。以下はテストシナリオの簡単な例です。
1人の仮想ユーザーが100秒間、1秒につき1回 https://test.k6.io に対してGETリクエストを送信し、レスポンスのHTTPステータスコードが200であることを確認する負荷試験です。
import http from 'k6/http'; import check from 'k6'; export const options = { vus: 1, duration: '100s', rps: 1, }; export default function () { const response = http.get('https://test.k6.io'); check(response, { "status is 200": (r) => r.status === 200 }); }
テストシナリオのクラスターへの自動適用
k6-operatorを使用して負荷試験を実施するには、テストシナリオを記述するだけでは不十分です。実際に負荷試験を行うには、k6-operatorが実行されているクラスターに以下のようなk6 Custom Resourceを適用する必要があります。
apiVersion: k6.io/v1alpha1 kind: K6 metadata: name: k6 namespace: k6-operator-system spec: parallelism: 1 arguments: --out statsd script: configMap: name: scenario file: test01.js runner: env: - name: K6_STATSD_ENABLE_TAGS value: "true" - name: K6_STATSD_ADDR value: "datadog-agent.datadog.svc.cluster.local:8125"
k6 Custom ResourceはConfigMapと、それに格納しているテストシナリオのJavaScriptファイルを指定する必要があります。したがって、記述したテストシナリオを元に負荷試験を行うためには、その都度テストシナリオのJavaScriptファイルからConfigMapを作成しなければなりません。
そこで、kustomizeのconfigMapGeneratorを使用してテストシナリオのJavaScriptファイルからConfigMapを動的に生成するようにしました。
apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization configMapGenerator: - name: scenario namespace: k6-operator-system files: - scenario/test01.js - scenario/test02.js - scenario/test03.js - scenario/test04.js generatorOptions: annotations: argocd.argoproj.io/compare-options: IgnoreExtraneous
私たちのチームでは、Argo CDを使ってKubernetesマニフェストのデプロイを実現しています。そのため、テストシナリオを負荷試験の専用のGitHubリポジトリへPushするだけで、テストシナリオのJavaScriptファイルからConfigMapを動的に生成し、クラスターに適用されます。
負荷試験の実行
GitHub Actionsの workflow_dispatch トリガーを使ってWeb UIからワークフローを実行し、k6 Custom Resourceを適用します。引数を設定する画面にて、テストシナリオであるJavaScriptファイルをプルダウンから選択することで、容易に負荷試験を実施できます。また、負荷試験の実行時に、vus、duration、rps、parallelismなどのパラメータを容易にオーバーライドできるよう実装しています。
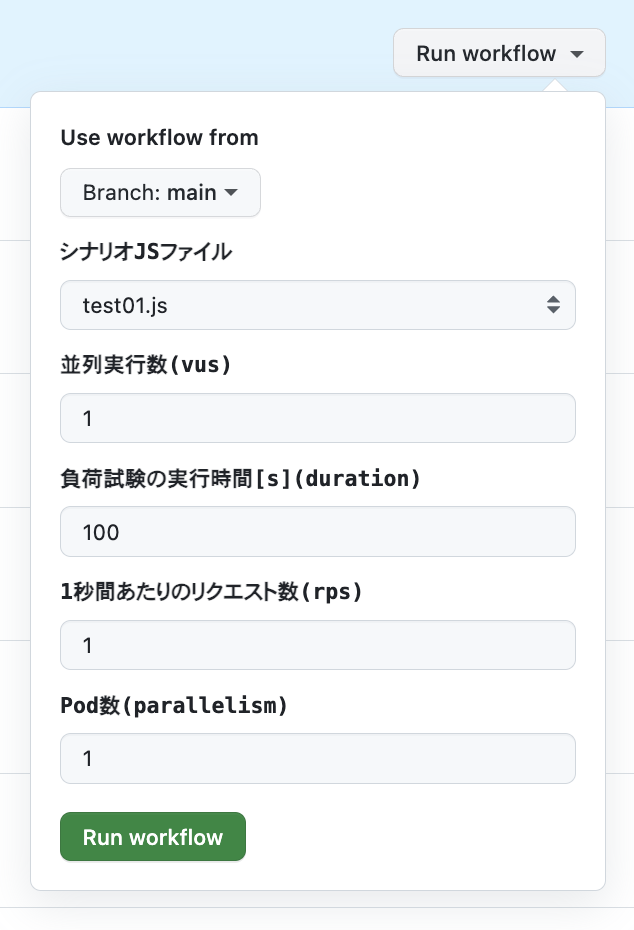
ワークフローを実行すると、k6 Custom Resourceがクラスターに適用され、k6-operatorがPodを起動し、負荷試験を行います。この際の負荷試験のメトリクスは、Datadog Agentを介してDatadogに送信されます。
負荷試験の結果
負荷試験が終了すると、負荷試験用のSlackチャンネルに負荷試験結果レポートである、DatadogダッシュボードのURLが送信されます。
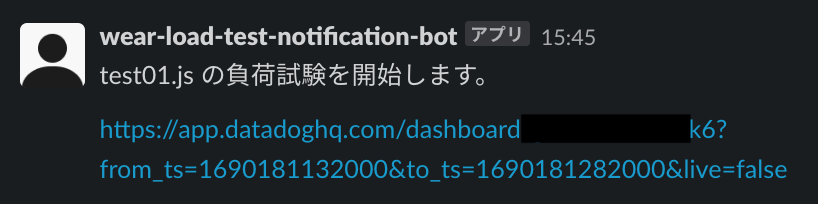
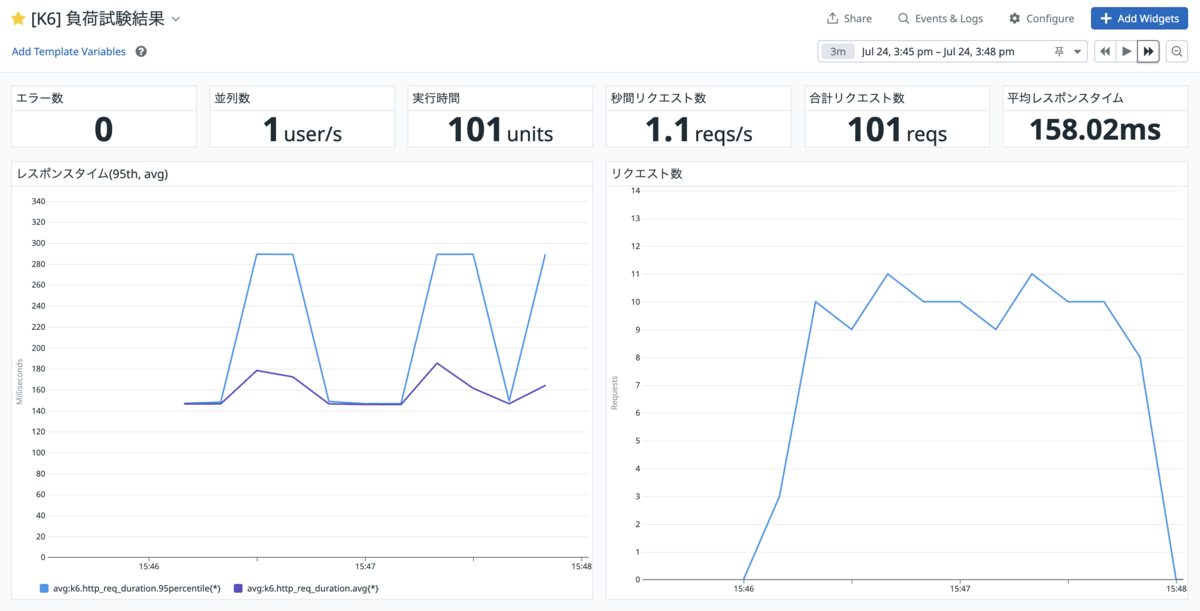
URLをブラウザで開くと、Datadogダッシュボード上で負荷試験結果レポートが閲覧できます。
導入後の効果
今回作成した負荷試験基盤の導入により、今年入社した新卒エンジニアなどの新規メンバーでも手軽に負荷試験を実施でき、負荷試験を実施するハードルを下げることができました。
また、負荷試験ツールの統一により、チーム内での負荷試験のノウハウが蓄積され、開発者の開発効率が向上しました。
さらに、今回の取り組みにより、専用のGitHubリポジトリを使用して負荷試験を管理できるようになったことが非常に良かったです。テストシナリオの作成から負荷試験の実行、結果の確認まで、チームレビューが行き届くようになりました。これにより、以前に個人で行っていた時と比べて、負荷試験の妥当性が向上し、心理的な負担も軽減しました。
まとめ
今回は、WEARにおけるKubernetesネイティブな負荷試験基盤の導入とその効果についてご紹介しました。この負荷試験基盤の導入により、負荷試験が手軽に実施できるようになり、負荷試験へのハードルが下がりました。
また、これを機に従来の負荷試験についても見直すことができました。今後も負荷試験基盤の利用者がより使いやすくなるよう継続的に改善していきます。
さらに、今後は負荷試験基盤だけではなく、Kubernetesの柔軟性を活かして運用改善や開発者体験の向上に取り組んでいきます。
おわりに
WEARでは一緒にサービスを改善してくれる仲間を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!