



はじめに
こんにちは、SRE部 検索基盤SREブロックの花房と大澤です。普段はZOZOTOWNの検索関連マイクロサービスのインフラ運用を担当しています。
ZOZOTOWNの検索基盤では、商品検索に関わる大規模なデータを取り扱うためにElasticsearchを利用しています。Elasticsearchを運用していく中で、私たちはパフォーマンスとインフラコスト、運用トイルの問題に直面していました。本記事では、私たちが抱えていた問題と、それを解決したアプローチとしてシャーディング最適化とオートスケーラー開発の取り組みについてご紹介します。
目次
背景・課題
ZOZOTOWNでは、2017年からレガシーシステムのリプレイスを実施しています。レガシーシステムの刷新の中で、検索基盤においてはElasticsearchの導入・運用を開始しました。リプレイスの進展や、おすすめ順検索の利用拡大に伴い、検索基盤へのトラフィックは増大し、Elasticsearchへの負荷も増加していきました。しかし、Elasticsearchのインフラ運用の知見は十分に溜まっておらず、パフォーマンス・インフラコスト・運用トイルの3つの側面で課題が発生しました。
最初に、それら3つの側面の課題について紹介いたします。
パフォーマンスの課題
検索基盤では、ZOZOTOWNの商品情報の更新のために、Elasticsearchへのデータ投入を毎分実行しています。この高頻度のデータ投入と、マイクロサービス側での大量の検索リクエストにより、クラスタ全体のCPU負荷は常に高い状態でした。ノード数を増やしても処理速度の向上は見られず、さらに負荷が増大すると、レスポンスやインデキシングが遅れ、求めるパフォーマンスを維持できなくなります。そのため、負荷増加を招く可能性のある新たな施策には挑戦しにくい状態になっていました。
インフラコストの課題
検索基盤のElasticsearchは、Elastic社が提供するElastic Cloud上で稼働しています。フルマネージドなElastic Cloudではノードの稼働時間にコストが比例します。当然のように思えますが、自前で管理するElastic Cloud on Kubernetes (ECK) 1の場合、利用量でなくライセンスの最大量で契約を結ぶ必要があるため、ノード数を下げてもライセンスの料金の節約には繋がりません。ZOZOTOWNの場合、時間帯や日別のイベントによりトラフィックが大きく変化します。ノード数の変動が大きい弊社では、コストカットができるようECKではなくElastic Cloudを採用しています。
リクエスト量は時間帯によって大きく異なるため、それに応じてリソースを最適化できれば余計なコストを減らせます。以下の図は、時間ごとの検索リクエスト数のグラフです。横軸が時間、縦軸が秒間リクエスト数を示しています。

Elastic Cloudにはディスク利用量トリガーによるオートスケール機能は存在しますが、リクエストやCPU負荷に応じてスケールする仕組みは存在しません。そのため、リクエストが少ない時間帯(深夜、日中など)でも、常にピークタイムのリクエストを処理できるノード数を準備して対応していました。これによりZOZOTOWNのインフラの中でも、特に膨大なインフラコストが発生しており、そのコスト削減が課題になっていました。
運用トイルの課題
ZOZOTOWNは、土日の午後9時頃にかけてリクエスト数が最も多くなる傾向を持っています。ピークである土日のリクエスト数を捌けるノード数を常時抱えておくのはコストが勿体ないため、週末のみスケールアウトする運用にしています。この運用では、土日の売上予算からリソース見積を算出する作業と、Elasticsearchのスケールアウト作業を手動で行っていました。作業はテンプレート化されていますが、運用トイルとなっている状況が問題でした。下記のスクリーンショットは、その作業のGitHub Issueであり、チームメンバー内の輪番により毎週対応していました。

解決策
パフォーマンス課題の解決案としては、シャーディングによる負荷分散を試しました。シャーディングの詳細については後述します。さらに、ノードをCPUコア数の多いマシンへ変更することも検証しました。これによりCPUの余力を作り、シャーディングの効果を一層引き出せると考えたためです。
運用トイルの課題に対しては、ZOZOTOWNの売上予測をベースに必要なリソース量を算出し、Elasticsearchを自動スケールさせるような独自の仕組みを開発しようと考えました。既存のツールでは、私たちの運用に合うオートスケーラーが存在しなかったためです。
パフォーマンス課題と運用トイル課題の解決は、結果的にインフラコストの課題解決にも繋がりました。以降では、3つの課題の解決策となったシャーディング最適化とオートスケーラー開発の詳細についてご紹介します。
シャーディング最適化
Elasticsearchのシャーディング
シャーディングとは、インデックスを分割して複数のノードに保持させることです。分割されたデータをシャードと呼びます。下記にノードとシャード、レプリカの関係を図で示します。ノード数6、シャード数4、レプリカ数2の場合の例です。

CPUリソースに余裕がある場合、複数ノードでの並列処理により、クエリのレイテンシは改善します。各ノードで処理するデータがシャーディングにより分割されたデータ量に絞られるためです。2ただし、並列処理によりクラスタ全体のCPU利用は増加し、各ノードの処理結果をマージするオーバーヘッドも増加するため、スループットの悪化を招いたり、さらにレイテンシ悪化の可能性もあります。
インデックスのシャード数は、インデックス作成時に下記のパラメータを指定することで設定できます。
{ "settings": { "index" : { "number_of_shards": 4 } } }
このパラメータはインデックスごとに個別での設定が必要です。さらに、後からの変更は不可能であり、変更が必要な場合はインデックスを再作成する必要があります。今回の検証では、2シャードと4シャードの設定を試しました。
ノードのインスタンスタイプ変更
シャーディングの効果を引き出すためにはCPUリソースの余裕が必要です。そのため、ノードのインスタンスタイプをCPUコア数の多いマシンへ変更することにしました。
ノードのインスタンスタイプは、Elastic Cloudの管理画面から設定できます。管理画面には「hardware profile」という項目が存在し、そこでは「General purpose」や「CPU optimized」といった選択肢があります。この設定変更により、用途に合わせたリソースのインスタンスタイプの利用が可能です。私たちはAWSをクラスタのクラウドプロバイダとして選択しているため、ノードにはAWSのインスタンスタイプが適用されます。
今回のインスタンスタイプ変更では、「hardware profile」を「General purpose」から「CPU optimized」に変更しました。これにより、以前適用されていたm5dインスタンスから、c6gdインスタンスへの変更が行われます。私たちはTerraformコードにより適用しました。下記に、弊社で利用しているTerraformコードの例を示します。
resource "ec_deployment" "zozo_tech_blog" { region = "ap-northeast-1" version = "7.17.0" deployment_template_id = "aws-cpu-optimized-arm-v6" # この部分を変更 name = "ZOZO TECH BLOG" elasticsearch { autoscale = "false" topology { id = "hot_content" size = "60g" zone_count = "3" size_resource = "memory" } topology { id = "master" size = "8g" zone_count = "3" size_resource = "memory" } } }
m5dとc6gdのCPUの比較は下記の通りです。
| m5d | c6gd | |
|---|---|---|
| vCPUコア数 | 16 | 32 |
| プロセッサ | Intel製 | ArmベースのAWS Graviton2 |
実は、以前にもインスタンスタイプ変更によるパフォーマンス向上を検証したことがあります。その際もm5dからc6gdへの切り替えを検証しました。検証の結果、99パーセンタイルのレイテンシが100msほど悪化したため、この変更は本番環境にリリースできませんでした。当時はインデックスが1シャード構成であり、CPUコア数が多くても効果的な並列活用ができず、CPU1コアのパフォーマンスがレイテンシに直接影響したためと考えました。
最終的に、インスタンスタイプ変更によるCPUの2倍確保で書き込みと読み込みが相互影響しにくい状態にした上で、さらに余ったCPUを効率良く利用できるようにシャーディングを行う狙いになりました。
負荷試験によるパフォーマンス検証
負荷試験では、本番環境と同じ構成のステージング環境を利用します。今回はElasticsearchの検証を実施するため、ステージング環境に対して下記を設定しました。
- ステージング環境のアプリケーションを検証対象のElasticsearchクラスタに接続
- アプリケーション側のキャッシュを無効化し、Elasticsearchに負荷がかかるように設定
- アプリケーションのリソースだけでなく、Elasticsearchへのインデキシングも本番環境と同様に動作する状態に変更
負荷試験におけるアプリケーションへのリクエスト数はElasticsearchのノード数に応じて変化させ、下記の条件の組み合わせで試験を実施しました。3負荷試験の実行では、弊社で開発しているOSSであるGatling Operatorを活用しています。Gatling Operatorについてはこちらの記事をご参照ください。
| 条件 | 内容 |
|---|---|
| インスタンスタイプ | c6gd |
| インデックスのシャード数 | 2, 4 |
| Elasticsearchのノード数 | 3 ~ 年間最大トラフィック想定の台数 |
| リクエスト数(req/sec) | 50 ~ 年間最大トラフィック |
今回の負荷試験では、主にアプリケーション側の99パーセンタイルのレイテンシと、Elasticsearchのスループット、インデキシングバッチの処理時間の3つに焦点を当てています。また、4シャードの結果が2シャードよりも良好であったため、これまでの構成と4シャードの新構成で比較しました。下記は年間最大トラフィックでの比較結果です。
| 項目 | 1シャード x m5dインスタンス | 4シャード x c6gdインスタンス |
|---|---|---|
| 99パーセンタイルレイテンシ | 670ms | 370ms |
| 1ノードあたりのスループット | 40 query/sec | 40 query/sec |
| インデキシングバッチ処理時間 | 120分 | 60分 |
比較結果から、新構成はスループットを維持したまま、2つの項目では優れていることが確認できました。それぞれの項目について、考察を下記にまとめます。
- 99パーセンタイルレイテンシ
- シャーディングにより4つのノードに処理が分散されたことで、レスポンスを結合するオーバーヘッドを含めても、処理時間を短縮できた結果だと考えています。
- 1ノードあたりのスループット
- シャード数が4に増えた分、各シャードへのクエリ回数は4倍に増加するためスループットは減少しそうですが、今回はスループットを維持できています。これはインスタンスタイプ変更によるCPUコア数の増加の効果だと考えています。
- インデキシングバッチ処理時間
- 新構成では旧構成と比較してCPUが2倍になったため、書き込みと読み込みが別々のCPUで処理されることが多くなり、書き込みでCPUを占有できるようになった結果、処理時間が短縮したと考えています。反対に、旧構成ではCPUの数が少なく、1つのCPUで書き込みと読み込みの両方を担うことが多かったため、処理に時間がかかっていたと考えています。また、シャードが分かれたことにより、インデキシングを並列で実行できるようなった効果も大きいと考えています。
コスト見積
リリースの判断を下すためには、インフラコストの見積が必要です。最終的なコストの詳細は記載できませんが、各要素について説明します。
1ノードのインスタンスサイズについては、メモリ容量で決定しています。Elastic Cloudのインスタンスは、基本的に他のユーザとリソースを共有する環境です。私たちのElasticsearchノードと、他のユーザのノードが同じインスタンス上に配置される可能性があります。その場合、リソースを取り合う形になってしまうため、安定した性能が発揮できないこともあります。しかし、一定以上のメモリサイズを指定することで、占有リソースのインスタンスが利用可能です。そのため、私たちはメモリサイズが60GBのインスタンスを「Hot data and Content tier」として使用しています。このサイズのノードについて、今回比較したインスタンスタイプの料金は2023年9月時点でそれぞれ以下の通りです。
| m5d | c6gd | |
|---|---|---|
| 1時間あたりのコスト | $3.648 | $4.452 |
コスト見積では、過去のリクエスト数データと負荷試験の結果を元に必要なノード数を計算し、Elastic Cloudの料金情報に基づいてコストを算出しました。1時間あたりのコストの計算方法は下記の通りです。
( 検索APIのリクエストによって発生するElasticsearchへのクエリ量[query/sec] / ノード1台のスループット[query/sec] ) x ( ノード1台の1時間あたりのコスト[$] x ドル円為替[¥/$] ) x バッファ
下記2パターンについて、以前の構成と比較した際のコスト削減率を記載しています。
| コスト算出パターン | 以前の構成と比較した際のコスト削減率 |
|---|---|
| 最もリクエスト数が多い日のコスト | -20% |
| 年間コスト | -35% |
新構成では1台あたりのインスタンスコストが上がってしまうため、全体のコストも上がるように思います。しかし、レイテンシに関してはガードレール指標を定めており、レイテンシの改善分をガードレール指標まで落とすことでスループットを増やせました。その結果、ノード数を削減してコスト削減が実現できました。
安全なリリース方法
負荷試験結果から新構成のパフォーマンス、コストに問題がないことは分かりました。しかし、本番環境にリリースしてユーザトラフィックに晒した時、想定外のエラーやパフォーマンス悪化といったリスクが発生しないとは言い切れません。そのため、カナリアリリースによる安全なリリースを実施します。カナリアリリースは手動ではなく、以前の記事でご紹介した、Flaggerを用いたプログレッシブデリバリーにより実行しました。Flaggerはプログレッシブデリバリーを実現するKubernetes Operatorであり、検索基盤のマイクロサービスには導入済みです。
旧構成から新構成に切り替える方法は2つ考えられました。
- 同じクラスタ内でインデックスを作成し、エイリアスを切り替える案
- 旧クラスタと同じデータを持つ新クラスタを作成し、アプリケーション側から接続するElasticsearchのエンドポイントを切り替える案
シャーディングのみ適用すると切り替え期間は2つのインデックスへの書き込みが必要になり、CPUリソース不足になる可能性があります。また、インスタンス変更のみ適用するとレイテンシ悪化の可能性があります。そのため、今回は両方を同時に適用できる2つ目の方法を選択しました。
エンドポイントの切り替えは、Kubernetes上の検索APIのdeploymentリソースに記載している環境変数の更新により行います。また、新クラスタへの接続情報を格納するsecretの作成と、それを参照するよう変更も行いました。これらの更新により、Flaggerが新クラスタへ接続する検索APIのカナリアバージョンを作成し、カナリアリリースを自動で進めてくれます。エラーの多発やレイテンシの悪化が発生した場合は、Flaggerにより自動的に元のクラスタを向いているバージョンに切り戻されるため、安全なリリースが実現できました。下記はプログレッシブデリバリーがKubernetes上でどのように実施されるかを表した図です。

リリースまでの手順は以下の通りです。まず検証環境で本手順通りにリリースの予行演習をし、問題がないことを確認しました。その後、本番環境で本手順通りにリリースしました。
- 新クラスタの構築
- 新旧2つのクラスタへのインデキシングを開始
- プログレッシブデリバリーでのクラスタ切り替え
- 旧クラスタへのインデキシングの停止
導入効果
シャーディング最適化による導入効果を改めて下記にまとめます。
- 分散処理による、検索リクエストのレイテンシおよびインデキシング処理時間の改善
- スループット向上によるコストカット
本番環境のレイテンシには変動があるため、1か月ほど様子を見た上で改善されたと判断しました。改善幅は負荷試験時ほどではありませんでしたが、99パーセンタイルレイテンシは平均で約150ms改善されました。本番環境と負荷試験との主な違いは、サイト内セールの影響や、それに伴う検索リクエスト種類の割合です。これらの要因や、コスト削減のためにレイテンシを落としてスループットを上げたことにより、負荷試験時とは異なる結果になったと考えています。インデキシングバッチについては、約4.5時間かかっていた処理が半分以下の約1.7時間で完了するようになりました。さらに、トイル削減にも繋がっており、セールイベント時に行っていたインデキシングバッチのチューニングが不要になりました。
シャーディング最適化によって、パフォーマンスとインフラコストの課題について解決できました。以前はCPUに余裕がなく断念せざるを得なかったパーソナライズに関する施策にも挑戦できるようになりました。
オートスケーラー開発
前述の通りインフラコスト・運用トイルを改善するためのアプローチとして、日中夜間・平日休日に適したリクエスト量を見積もり、かつ適切なノード数へ自動変更する手法を模索しました。この章ではSREチーム独自の仕組みとしてオートスケーラーを開発するに至った経緯と、その概要についてご紹介します。
オートスケール方針の検討
SREチームではElastic Cloud上でElasticsearchクラスタを運用しています。可能であれば公式に提供されている機能を利用したいところです。しかしながら、現在のところElastic Cloudよりスケジュール設定やCPU使用量、リクエスト量に応じたノード数変更の仕組みは提供されていません。そのため、実現方法としては下記の2つを検討しました。
- 既存のOSSを利用する
- 独自の仕組みとして開発する
既存のOSSを利用する方法として、elastic-cloud-autoscalerを検討しました。このOSSは、Elastic CloudのAPIを通してスケジュールやクラスタ負荷に応じたノード数へ変更できます。導入にあたって検証を進めたところ、SREチームでの運用に不適ないくつかの課題が確認できました。
以前の記事にて紹介のとおり、SREチームではTerraformによるコード管理にてElasticsearchクラスタを運用しています。これによりクラスタの状態とリリースブランチのコードの状態を常に一致させるという安定した運用基盤を構築しています。
OSSのオートスケーラーによる運用では、Terraformのコードとクラスタの状態との間に差分が生じてしまうことが最大の問題点でした。OSSのオートスケーラーはコードの状態を考慮せずにノードのスケーリングを実施します。この振る舞いによりコード差分が生じ、緊急時にTerraformでクラスタの構成を変更しようとすると、予期せぬ問題やエラー発生の可能性があります。また、本OSSで提供されているスケジュール設定についても、私たちの運用には合っていないことが分かりました。ZOZOTOWNでは、日によってセールなどの各種要因によりElasticsearchへ流入するリクエスト量が異なります。そのため、適切なノード数も日によって異なり、シンプルなスケジュール設定は合わなかったのです。
さらに、Elastic Cloudからは将来的にサーバーレスアーキテクチャが提供される予定もあり、オートスケーラーは一時的な運用となる可能性もあります。これらの点を加味し、SREチームの運用に適した、独自の仕組みを持つオートスケーラーを導入する方針が固まりました。以下がSREチームで検討した独自オートスケーラーの要件です。
- クラスタの状態はTerraformのコードで管理する (Single Source of Truth)
- クーポンやイベント、広告により日々異なる売り上げ予想から、日々適切なノード数を自動で見積り、自動でスケールを行う
- 既存の仕組みを利用し、最小限の実装でオートスケールを実現する
- Elasticsearch以外に、Kubernetesのpod数変更や検索ドメイン以外でも利用できるような汎用的な作りにする
オートスケーラーの設計と開発
SREチームの現在のクラスタ運用は、GitHub Actions (GHA) のCI/CDにより実施しています。リリースブランチへのPRマージをトリガーにGHAが起動し、terraform applyを実行することでクラスタの状態とコードの状態を一致させています。この運用方法をベースに、最小限の実装でオートスケーリングを実現するため、GHAで新しいワークフローを構築しました。以下がワークフローの概要になります。左が今回新しく構築したオートスケール全体を担うワークフロー、右がPRマージ時にCI/CDで動作する既存のワークフローです。
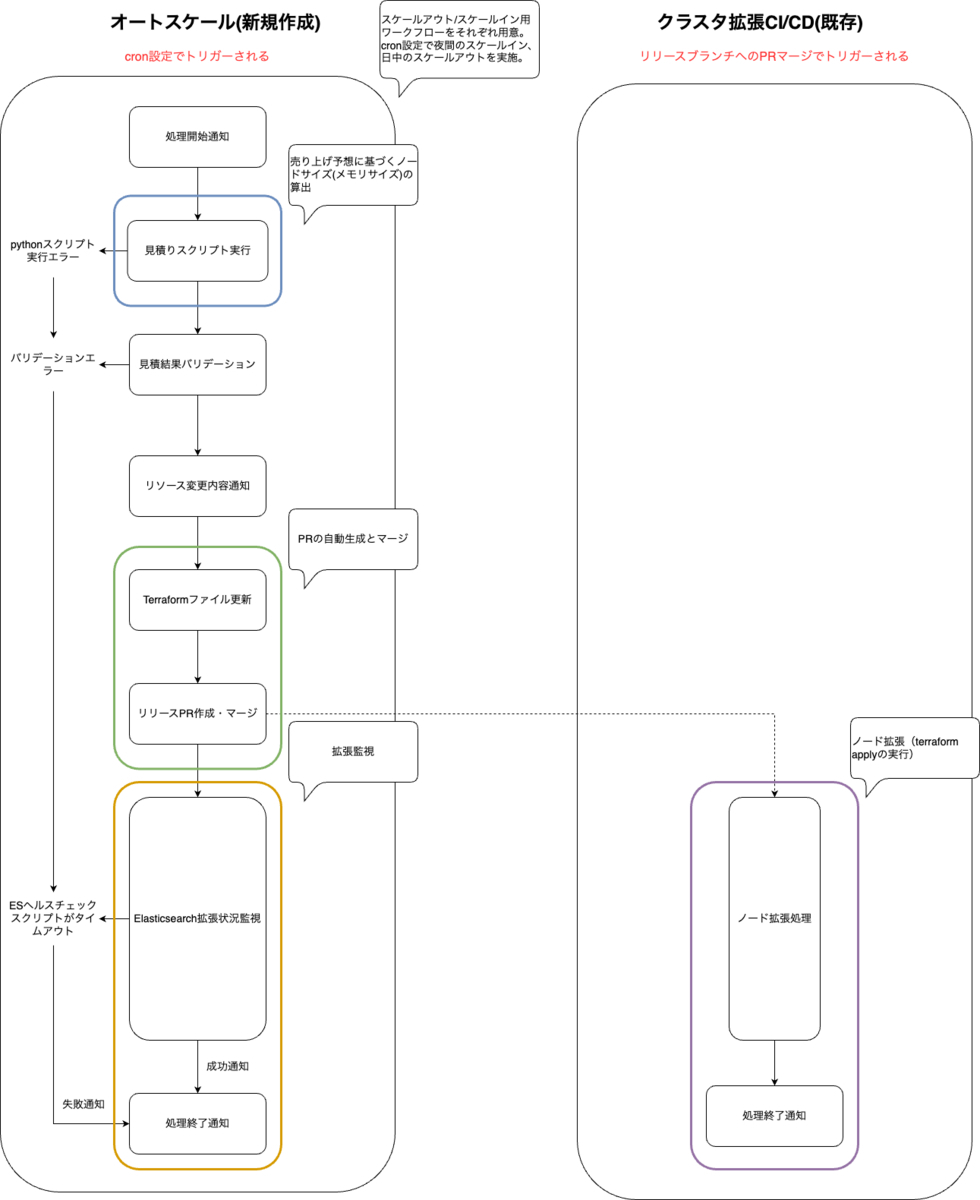
大きく以下の要素で構成されています。
- 夜間のスケールインと日中の段階的なスケールアウト
- 売上予算に基づく必要ノード数(メモリサイズ)の算出
- PRの自動生成とマージ
- ノード拡張(terraform applyの実行)
- 拡張監視
各要素のポイントを以降で説明します。
夜間のスケールインと日中のスケールアウト
時間帯で異なるトラフィック傾向に合わせて、以下のようにGHAのcronを設定しています。
- 9時 : 昼休みの時間帯のトラフィック増に備えてピーク時リソースの8割に増加
- 16時 : ゴールデンタイムのトラフィック増に備えてピーク時リソースの10割に増加
- 25時 : トラフィックのピークを過ぎたためピーク時リソースの6割に減少
売り上げ予想に基づくノードサイズ(メモリサイズ)の算出
Pythonスクリプトにて毎日の売上予算を基に、オートスケール実施日のリクエスト量を予測し最適なノード数を算出しています。以下は算出プロセスの詳細です。
(1). 過去のデータの取得
過去N日分の売上予算と最大リクエスト量を取得します。SREチームではElasticsearchの各種メトリクス情報をDatadogに送信しているため、DatadogのAPIを利用して過去N日分の最大リクエストを取得します。
(2). 最大リクエスト量の予測
取得したN日分の過去のデータをもとに、重回帰分析を実施し当日の売上予算から最大リクエスト量を予測します。
def calculate_trend(self, y_values, x_values, target): x = np.array(x_values) # x軸:過去の売上予算 y = np.array(y_values) # y軸:過去のリクエスト量 # 傾きと切片を計算 slope, intercept, _, _, _ = linregress(x, y) # 売上予算に対するリクエスト量を計算 trend_value = intercept + slope * target # target:当日の売上予算 return trend_value
(3). 必要ノード数(メモリサイズ)の算出
terraformによるノード数の変更はメモリサイズ単位で行います。そのため、予測された最大リクエスト量をもとに、必要となるノード数を計算し必要メモリサイズへ変換します。
PRの自動生成とマージ
クラスタを構成するterraformファイルには以下のようにタグ# {autoscaling}を設定しています。shellコマンドでこのタグが設定された行を検出し、算出したメモリサイズへファイルを更新します。
# タグを設定したterraformファイル
topology {
id = "hot_content"
size = "900g" # {autoscaling}
zone_count = "3"
size_resource = "memory"
}
# sedコマンドによるタグ検出とファイル更新例
esfile=terraform/elastic_cloud/es-cluster.tf
sed -i '/# {autoscaling}/s/size = "[0-9]*g"/size = "${{ env.ESTIMATE_SIZE }}g"/' ${esfile}
ファイル更新後はリリースブランチへPRを作成し自動でマージしています。
ノード拡張(terraform applyの実行)
リリースブランチへのPRマージを機に既存のCI/CDプロセスがトリガされ、クラスタの状態が最新のコードに一致するように更新されます。
拡張監視
監視方法として、Elasticsearchのヘルスチェックエンドポイントを叩き、クラスターステータス、Unassigned Shards数を監視します。なお、スケールインの失敗はサービスに最悪の影響を及ぼさないため許容できます。しかしながら、スケールアウトの失敗はピークタイム時のサービスに重大な影響を及ぼすため、万一の失敗時は即時対応が必要となります。そのため、スケールアウト時に一定時間経ってもクラスターステータスが正常にならない場合や、ワークフロー実行中にエラーが発生した場合にはPagerDutyでオンコールする仕組みを導入しています。
導入効果
オートスケーラーの導入により以下の効果が得られました。
- インフラコスト削減:適切なリソース管理により、オートスケール導入前と比較し月額コストが20%改善しました。
- 運用トイル削減:輪番担当の際の負荷見積りやノード数調整、監視にかかる時間が無くなり、作業負荷が軽減されました。
これらの効果により、サービスの運用管理がスムーズになり、より価値のある開発や改善に時間とリソースを割くことが可能になりました。また、今回は記載を省略しましたが、Elasticsearchのノード数スケールと同様の方法で、検索APIのpod(minReplicas設定)についてもオートスケールの対象にしています。
おわりに
本記事では、Elasticsearchを運用していく中で私たちが直面した問題と、その問題をシャーディング最適化とオートスケーラー開発によって解決する過程をご紹介しました。
今回の取り組みによって、Elasticsearchのパフォーマンス、インフラコスト、運用トイルの改善を進めることができました。Elasticsearchの運用で同様の課題を抱えている方がいれば、ぜひ参考にしてみてください。
今後は、シャーディングのさらなる最適化とオートスケーラーのブラッシュアップ、その他にもワークロードに合わせたクラスタの分割などの施策を進め、改善を継続していきたいと考えています。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。ご興味のある方は、以下のリンクからぜひご応募ください!
- https://github.com/elastic/cloud-on-k8s↩
-
シャーディングにより、デフォルトでは単語頻度の計算がシャードごとになります。全てのシャードから収集した情報で、グローバルな単語頻度を計算させるには、
search_typeとしてdfs_query_then_fetchを指定する必要があります。https://www.elastic.co/guide/en/elasticsearch/reference/current/search-search.html#search-type↩ - クラスタの拡張縮退を繰り返す際はマスターノードのリソースを増やしておくことを推奨します。シャード再配置に失敗し、クラスタが利用不可になる可能性があるためです。↩