



はじめに
こんにちは、MA部MA基盤ブロックでマーケティングオートメーションのシステムを開発している長澤です。この記事ではBigQueryとDatadogを活用した監視を導入した話を紹介します。
はじめに、日々のマーケティングオートメーション(以下、MA)の開発・運用における課題としてシステム信頼性の向上がありました。ZOZOTOWNは年間の購入者数が1,100万人を超えており、MAによりユーザーの皆さまに向けて多様かつ大規模なキャンペーン配信を展開しています。そのため、MAのシステム信頼性の担保が重要課題でした。
その一環としてこれまでに導入されてきた監視が多数ありました。MAの監視を大別すると、一般的に知られるシステム監視とMA特有の監視があります。以下がその一部です。
- 一般的なシステム監視
- OSのCPUやメモリの使用量
- HTTPレスポンスのステータスコード
- SLA
- 死活監視
- MA特有の監視
- 配信件数や配信失敗率(配信システム・配信チャネル・キャンペーン・集計時間などによる組み合わせ多数)
- 重複配信などの異常検知
- 配信からのECサイト・アプリへの流入数
この記事で取り上げるのは後者のMA特有の監視になります。既存のMA特有の監視はいくつかの課題を抱えていました。例えば監視対象のシステムが複数あり、システムによって監視方法が異なり統一されていなかったり、監視ツール自体に課題があったりしました。
これらの課題を解決するため、今回は新たにBigQueryとDatadogを活用した監視の仕組みを構築しました。元々BigQueryは監視のメトリクスのデータソースとして、Datadogは監視ツールとして部署内で活用していたのですが、このふたつを組み合わせた監視の仕組みはまだ存在していませんでした。既存の複数の監視方法の中で、それぞれが別々に活用されている状況でした。この記事では、BigQueryとDatadogを連携するメトリクス送信用アプリケーションによる監視の仕組みをご紹介します。
目次
既存の課題
既存のMA特有の監視の課題としては以下のようなものがありました。
- 配信システムによって監視方法が異なる
- 各監視ツールに課題がある
- 時折通知に失敗する
- メトリクスを蓄積できない
- 監視設定のコード管理ができない
実際に使用していた(試験運用含む)監視ツールは、Redashアラート・Lookerアラート・Digdagで、いずれも本来は監視が主目的のツールではありませんでした。RedashとLookerはBIツールに付随するアラート機能として利用していました。Digdagは定期実行が可能なワークフローエンジンのため、定期的にBigQueryの集計結果が閾値を超えていたら通知するようにして監視代わりにしていました。
時折通知に失敗する
一番の課題として、時折監視の通知に失敗することがありました。RedashはAWS環境でセルフホスティングしていましたが、しばしばワーカーのCeleryのエラーが発生していました。LookerアラートはSaaSでしたが、試験運用中にしばしば通知が失敗してしまい、採用を見送った経緯がありました。
メトリクスを蓄積できない
これは元々が監視ツールではないこともあり、いずれのツールでもできていませんでした。蓄積のためには別途自前の仕組みが必要でした。
監視設定のコード管理ができない
RedashとLookerではアラート設定をコードで実装できないため、コード管理ができませんでした。Redashアラートは管理画面のフォーム以外の管理方法がありません。LookerはAPIでアラートの設定が可能ですが、別途それ用の実装が必要でした。
監視ツールの選定
こうした背景を踏まえて改めて監視ツールを選定し、Datadogを採用しました。採用理由としては、やはり監視ツールであるがゆえに監視のニーズを満たして既存の課題の解決に最適であったためです。加えて、すでに社内や自分の部署内において多数の運用実績があったのも大きな理由です。
Datadogは過去の運用で既知の通り、高いシステム信頼性で安定稼働していました。メトリクスの蓄積は元々機能として備えており、ダッシュボードで過去の推移を簡単に確認できます。また、監視設定はTerraformで記述可能なためコード管理ができます。
監視のアーキテクチャと実装
本題の監視の仕組みを説明します。
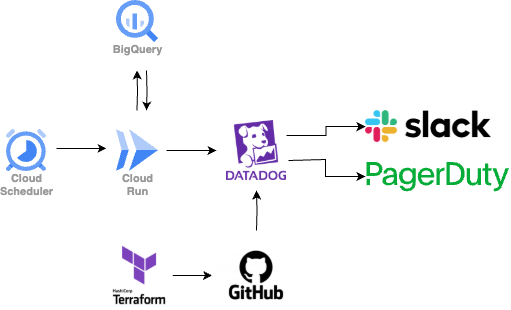
冒頭でも触れた通り、BigQueryのデータを集計し、その集計結果をメトリクスとしてDatadogに送信する監視用アプリケーションを開発しました。言語はGoを採用し、Cloud Runジョブで実行します。Cloud Schedulerでメトリクス送信の実行間隔を設定し、HTTPリクエストをCloud Runジョブに送信します。Datadogの監視はTerraformでコード管理しています。
アプリケーションの設計の要点として、監視対象のシステムや項目が増えてもアプリケーションの修正は不要にしました。新たに監視項目を追加する場合は以下の3つを追加または修正し、GitHub Actionsでそれぞれをデプロイする仕組みになっています。
- Cloud Schedulerを管理するYAMLファイル
- BigQueryのSQLテンプレート
- Terraformの「datadog_monitor」リソースの定義
Cloud Schedulerを管理するYAMLファイルは以下のようなスキーマで記述します。GitHub ActionsでこのYAMLをパースし、Cloud Schedulerジョブを作成・更新します。
- name: zozo-notification-delivery-error-rate-job description: 配信基盤の配信失敗率 pause: false schedule: "*/10 * * * *" template_path: zozo_notification_delivery/error_rate
例えばこの設定は、配信の失敗率を集計するSQLテンプレートを10分おきに定期実行するジョブを作成します。アプリケーションのCloud Runジョブはひとつのみ作成しますが、監視項目ごとに実行するSQLテンプレートは異なります。そのため、Cloud Schedulerのデプロイ時にHTTPリクエストのボディでファイルパスを渡すようにしています。
Cloud Runジョブの実行時に任意の引数を渡したい場合は、以下のように「containerOverrides」で指定するため、この値にファイルパスを渡しています。また、それ以外に任意の引数を渡すことも可能な実装にしています。
gcloud scheduler jobs deploy http ${JOB_NAME} \ --description "${DESCRIPTION}" \ --location asia-northeast1 \ --schedule "$(echo "${SCHEDULE}" | sed -e 's/\"//g')" \ --time-zone "Asia/Tokyo" \ --uri "https://asia-northeast1-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/${PROJECT_ID}/jobs/${CLOUD_RUN_JOB}:run" \ --http-method POST \ --message-body "{\"overrides\":{\"containerOverrides\":[{\"args\":['${MESSAGE_BODY}']}]}}" \ --max-retry-attempts 3 \ --oauth-service-account-email ${SERVICE_ACCOUNT} \ --project ${PROJECT_ID}
アプリケーションの実装においては、SQLの結果をDatadogメトリクスAPIのインタフェースに合わせています。
今回は時系列データをポストできる「Submit metrics」エンドポイントを利用しています。このエンドポイントでは、主にメトリクスの「名前」「タイムスタンプ」「値」「タグ」を送信します。
type MetricSeries struct { Metric string `json:"metric"` Points [][]float64 `json:"points"` Type string `json:"type"` Tags []string `json:"tags"` } func sendToDatadog(metricName string, value float64, tags []string) error { url := fmt.Sprintf("https://api.datadoghq.com/api/v1/series?api_key=%s", datadogAPIKey) metric := DatadogMetric{ Series: []MetricSeries{ { Metric: metricName, Points: [][]float64{ {float64(time.Now().Unix()), value}, }, Type: "gauge", Tags: tags, }, }, } data, err := json.Marshal(metric) if err != nil { return err } resp, err := http.Post(url, "application/json", bytes.NewBuffer(data) // 省略 }
これに合わせて、BigQueryのSQLテンプレートは「メトリクス名」と「集計した値」を出力するようにしています。例えば先ほどの配信失敗率のSQLテンプレートであれば、このような結果を返します。
[{"metric_name": "system1_push", "value": 0.0}, {"metric_name": "system1_mail", "value": 0.01}, {"metric_name": "system1_line", "value": 0.02}]
この結果に加えて、SQLテンプレート名やその他の管理用の情報をタグとしてメトリクスに追加し、Datadogに送信します。このようにしてSQLの詳細に関わらず、集計結果をメトリクスとして送信できるようにしています。
Terraformでは先ほどのメトリクス名と同じ数の監視を定義します。
resource "datadog_monitor" "zozo_notification_delivery_error_rate" { for_each = toset([ "system1_push", "system1_mail", "system1_line", ]) name = "【Notification Delivery】Error rate of ${each.key} over the threshold" type = "metric alert" tags = ["env:${local.env}", "app:zozo_notification_delivery", "template:error_rate"] message = <<-EOT ${local.notification_slack_channel} Error rate of ${each.key}({{value}}%) over the threshold {{threshold}}. template: https://github.com/st-tech/ma-datadog-metrics-sender/blob/main/templates/zozo_notification_delivery/error_rate.tmpl {{#is_alert}} {{#is_exact_match "env" "prd"}} @pagerduty-zozo-ma-alert {{/is_exact_match}} <!subteam^XXXXXXXX|ma-alert-team> {{/is_alert}} {{#is_no_data}} {{#is_exact_match "env" "prd"}} @pagerduty-zozo-ma-alert {{/is_exact_match}} <!subteam^XXXXXXXX|ma-alert-team> {{/is_no_data}} {{#is_no_data_recovery}} {{#is_exact_match "env" "prd"}} @pagerduty-zozo-ma-alert {{/is_exact_match}} {{/is_no_data_recovery}} EOT validate = true query = "max(last_5m):bigquery.query.result.zozo_notification_delivery.error_rate.${each.key}{env:${local.env}} > XXX" notify_no_data = true no_data_timeframe = 25 ## minutes timeout_h = 0 require_full_window = false monitor_thresholds { warning = XXX critical = XXX } }
通知先はSlackとPagerDutyです。監視の閾値を超えた場合だけでなく、一定時間メトリクスの送信がなかった場合も「no_data」の設定によって通知します。「no_data」の設定によって、メトリクス送信アプリケーションに問題があった場合に、それ自体の監視がなくともメトリクス送信の異常を検知できます。
取り組みの結果
現在はこの監視の仕組みを構築し、監視の一部の移行が完了しています。Datadogの安定性とno_dataの設定により、監視の仕組みは安定して運用できています。時折メトリクス送信に失敗しますが、それも検知した上で対応できています。メトリクスの蓄積も既知の通りでしたが、過去の推移を簡単に確認するのに役立っています。監視設定はGitHubで管理しているため、PRレビューをしたり、過去の変更履歴を管理したりできています。Digdagワークフローでは監視項目ごとにアプリケーションコードを実装していましたが、移行後はSQLテンプレートで集計処理が完結するため、コードの実装を減らすことができました。その甲斐もあって移行もコストを抑えてスムーズに行えました。
将来的には複数のツールに点在している監視をこの仕組みに統一することで、拡張性がありつつ運用負荷が低い監視を実現します。
今後の課題
今後の課題としては、残りの監視の移行や不足している監視の追加があります。また、今回の課題とは別問題ですが移行後の監視の見直しを予定しています。見直しの例としては、監視の閾値が低く通知の頻度が多すぎるケースや、監視の集計軸の粒度が大きいために細分化が必要なケースなどです。
まとめ
BigQueryとDatadogを活用したMAの監視について紹介しました。メトリクス送信用のアプリケーションを開発することで、BigQueryをデータソースとしてメトリクスを集計し、Datadogで監視できるようにしました。設計の工夫により、この監視の仕組み自体の運用コストを抑えられるようにしました。監視の一事例として参考になれば幸いです。
MA部ではMAの開発やSREを共に推進してくれる方を募集中です。ご興味のある方は下記リンクの採用募集からぜひご応募ください。