



こんにちは。ECプラットフォーム基盤SREブロックの高塚と巣立(@tmrekk_)です。
ZOZOTOWNはクラウド化・マイクロサービス化を進める中で、監視SaaSのDatadogを採用しました。この数年で多くの知見が蓄積され、今では様々なシーンでDatadogを活用しています。この記事ではそのノウハウを惜しみなく公開します。
※本記事は、先日開催されたDatadog Japan Meetup 2022 Summerにて発表した内容を書き起こして再構成したものです。
当日の発表資料
目次
はじめに

(高塚)こんばんは。これからZOZOTOWNにおけるDatadogの活用と、それを支える全社管理者の取り組みについて発表させていただきます。

わたくし、株式会社ZOZOでSREをしている高塚大暉と申します。よろしくお願いいたします。

(巣立)同じくSREの巣立健太郎です。Datadogの全社管理者も務めています。よろしくお願いします。

(高塚)ZOZOTOWNは日本最大級のファッションECサイトです。洋服はもちろん、シューズやコスメも取り扱っておりますので、ぜひ使ってみてください。

そのZOZOTOWNは2004年にサービスを開始しました。
ここで皆様にクイズです。2004年のできごとは4つのうちどれでしょうか?

(巣立)答えは...全部です! 皆様ご正解です。おめでとうございます!

話を本題に戻すと、2004年にオープンしたZOZOTOWNは、長らくオンプレでモノリスなアプリケーションとして動いてきました。ただ、サービスが成長にするにつれて、スケーリングや開発効率など、様々な点で厳しくなってきました。
そこで2020年から本格的にクラウド化・マイクロサービス化によるリプレイスを推し進めており、今もその道半ばです。
(目次に戻る)
マイクロサービス基盤に必要な監視の要件
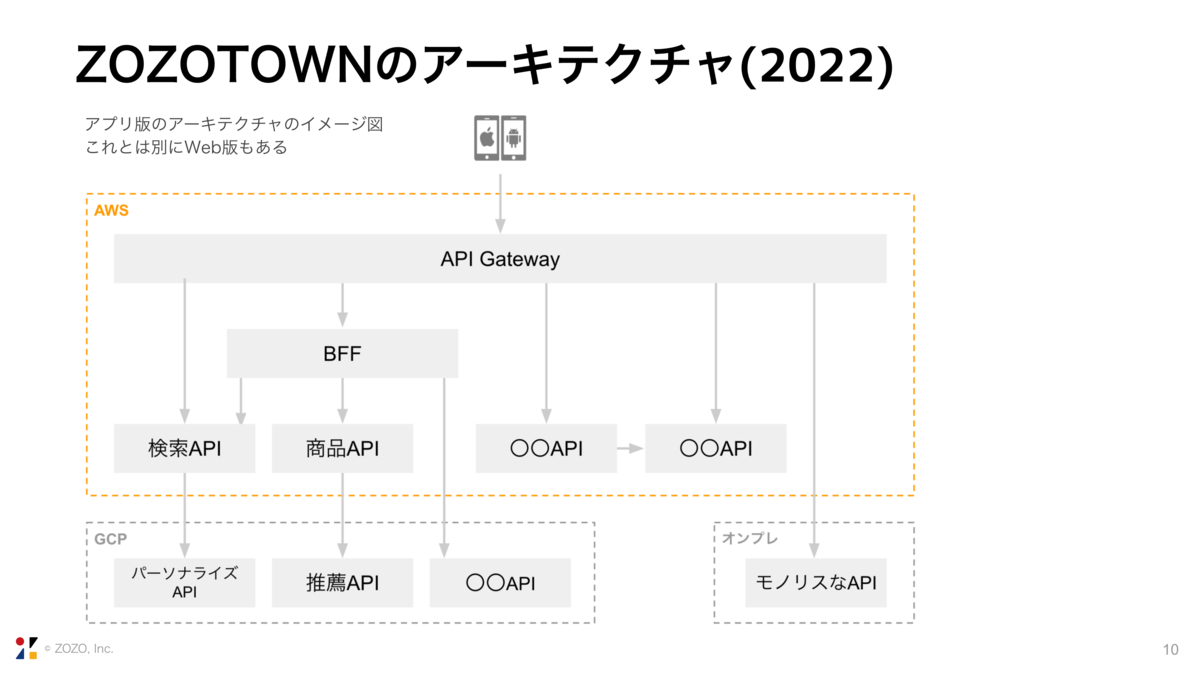
現在のアーキテクチャがこちらです。AWS, GCP, オンプレのハイブリッド構成で、API Gatewayが各マイクロサービスにルーティングを行います。
まだマイクロサービス化できていないAPIは、API Gatewayを経由してオンプレを叩きます。マイクロサービス化ができたPathは、API Gatewayで新しいAPIにルーティングを切り替えます。
また、BFF(Backend for Frontend)で複数のAPIのレスポンスをまとめて返すこともあります。APIが他のAPIを叩くこともあります。
そして、各APIで使用技術は大きく異なります。

ここまでをまとめると、マイクロサービスアーキテクチャにおいてサイト全体の信頼性を上げるには、各マイクロサービスを個別に監視するのではなく、統合的に監視することが必須です。
そのためには、我々は色々な言語やフレームワークを使っていますので、幅広い技術に対応していて、ひと通りの機能が揃った監視SaaSが必要というわけです。

そこでDatadogです。Datadogは、その条件にマッチしていました。

本発表は2部に分かれています。
第1部はZOZOTOWNにおけるDatadogの活用についてです。我々がぶつかった監視の課題と、それをDatadogでどう解決したか、そしてDatadogの便利なポイントについて話します。
第2部はそれを支える全社管理者の取り組みです。弊社ではSREだけでなく色々な職種のエンジニアがDatadogを使っていますので、それを支える工夫をいくつか紹介します。
(目次に戻る)
第1部 ZOZOTOWNにおけるDatadogの活用

(高塚)第1部では、監視の課題を6つ紹介します。
1. どこで障害が起こっているのか分からない → APM
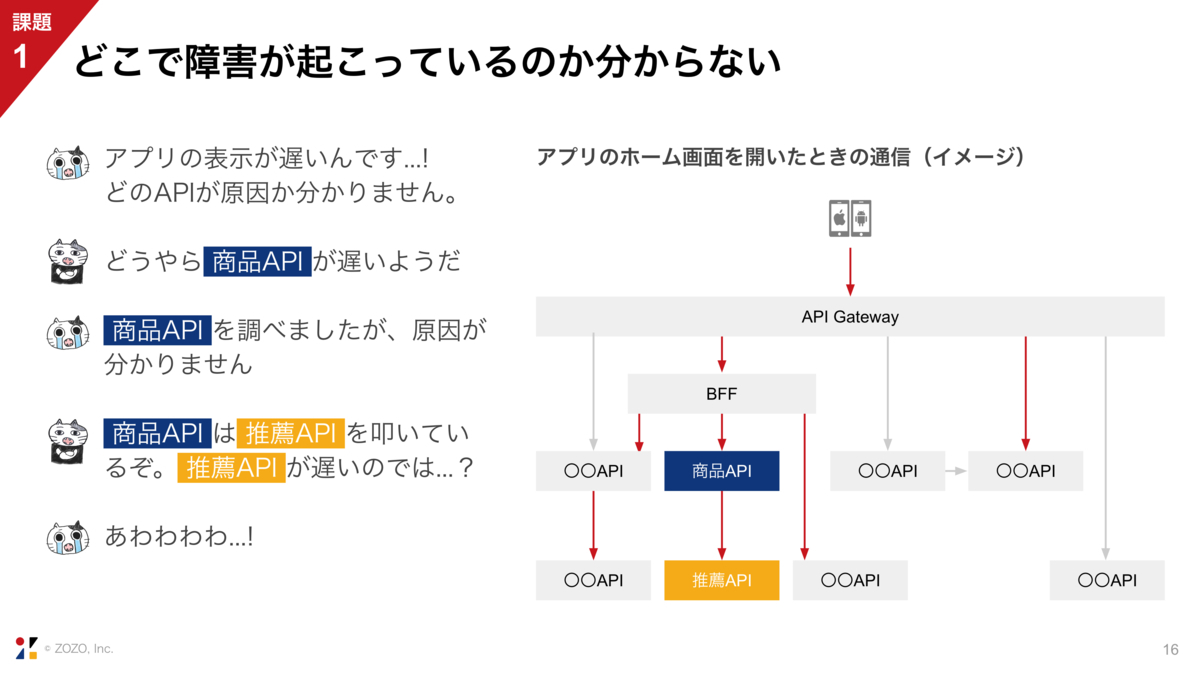
1つ目の課題は、どこで障害が起こっているか分からないということです。
例えばZOZOTOWNアプリのホーム画面を開いたとき、図の赤い矢印のような通信が発生します。ホーム画面の表示がいつもより遅いというとき、いろいろなマイクロサービスが原因として考えられるわけです。
仮に、どうやら商品APIのレイテンシが上昇しているぞと分かっても、実は商品API自体は問題なくて、商品APIが呼び出す推薦APIが遅くなっていたということがあり得るわけですね。
API間の通信が複雑になればなるほど、障害箇所の特定が難しくなります。

そこで活用したいのがAPMです。APMは色々なことができますが、今日は特に分散トレーシングについて話します。
導入方法は簡単で、スライドにGo言語での例を入れていますが、パッケージを入れた上でアプリケーションコードに数行追加するだけです。もちろん色々な言語に対応しています。
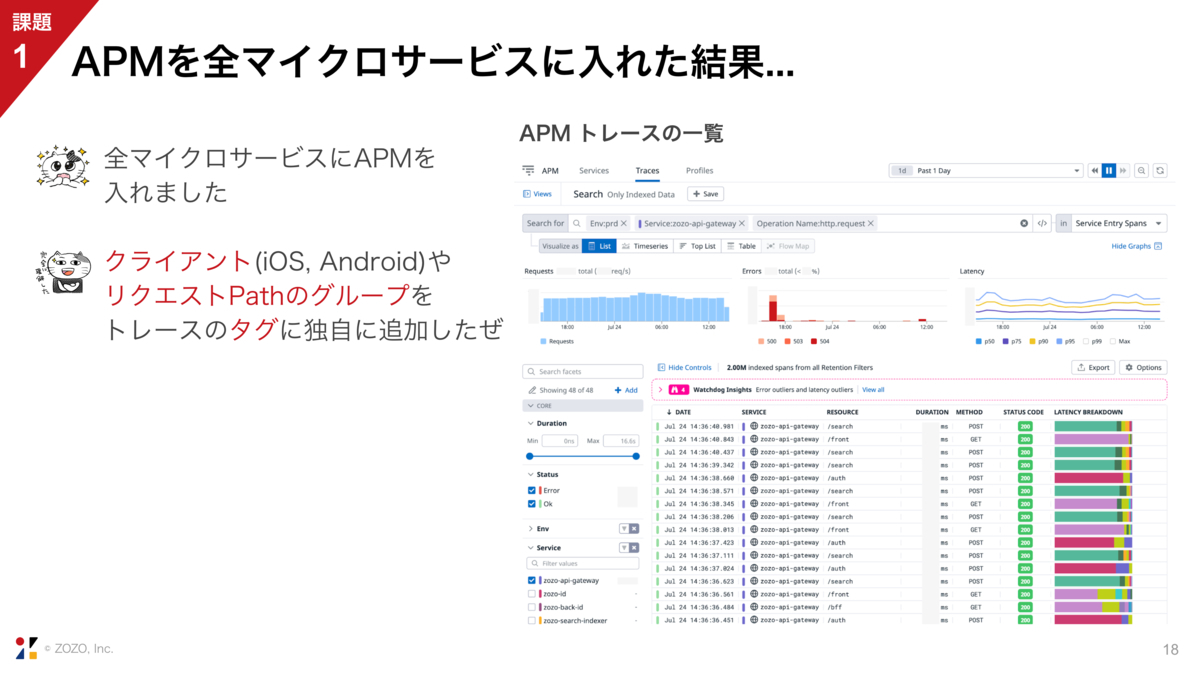
我々は全マイクロサービスにAPMを入れました。さらに、全てのリクエストの入口であるAPI Gatewayで、クライアントとリクエストPathをトレースのタグに追加しました。独自のタグを追加するのも1行のコードで可能です。
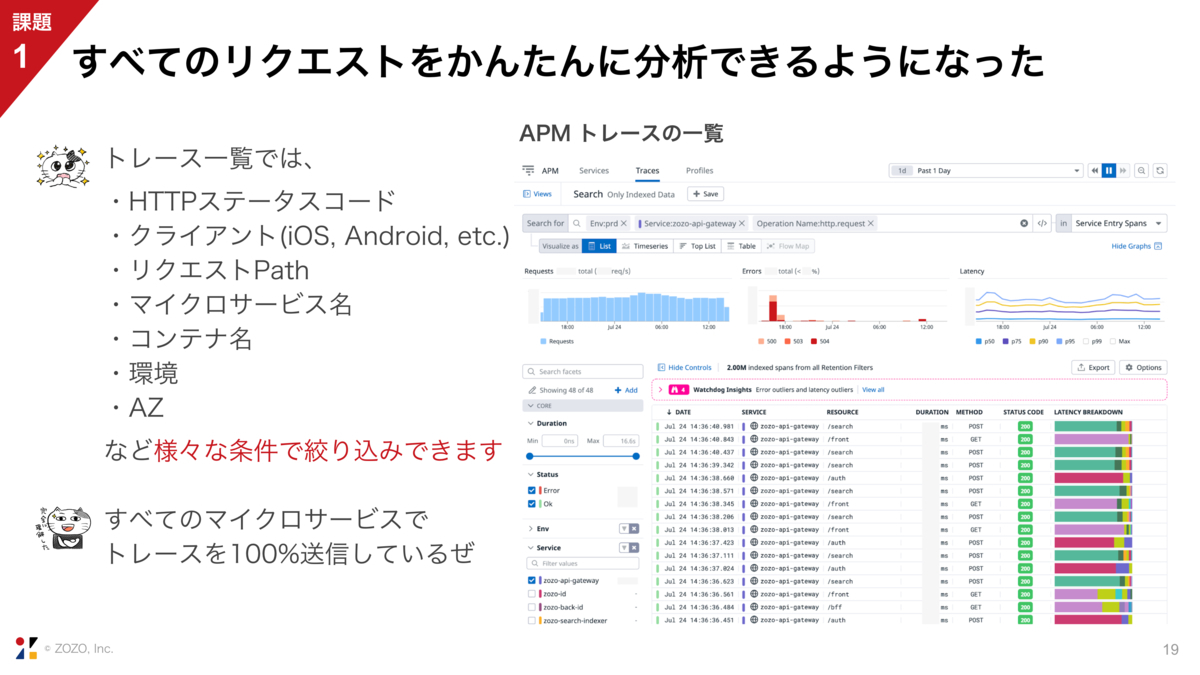
そうした結果、ご覧のようなトレース一覧が見られるようになります。この画面ではスライド左側に書いたような条件で絞り込み表示できます。
例えばステータスコードを500番台に絞って、「あれ、このリクエストPathだけエラーが出ているな」とか「iOSだけエラーが起きているな」とか「AWSのAZ-1cだけ障害が起きているな」というような使い方をしています。
これがとても便利なので、我々のチームは全てのマイクロサービスで、かつ本番環境だけでなく事前環境や開発環境も100%トレースを送信しています。
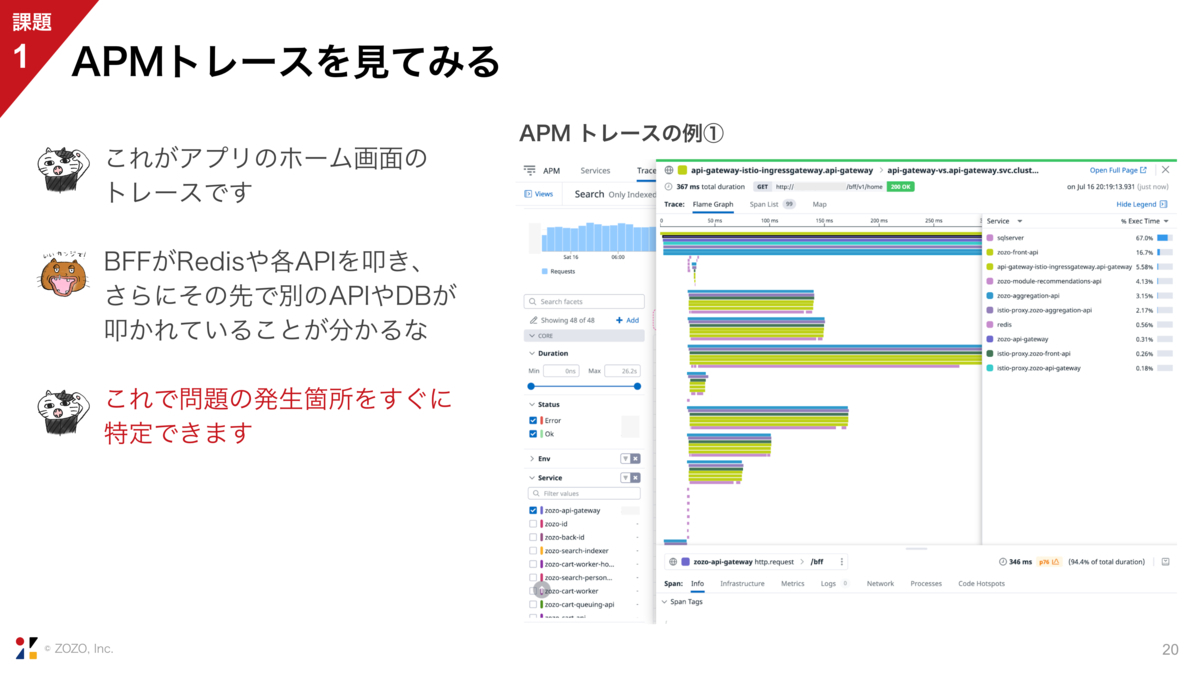
一覧画面の次は、1つ1つのトレースを見ていきましょう。これがアプリのホーム画面を開いたときの実際のトレースです。
上に見える青色のラインがBFFのスパンです。BFFは色々なAPIを叩いて結果を集約し、ホーム画面の描画に必要なJSONを返すという処理をします。
真ん中の緑色のラインが、叩かれている各APIのスパンです。各緑色のスパンの下に紫色のスパンもあるのですが、これがデータベースへの接続のスパンです。
今こうやってぱっと見ても、ちょうど真ん中らへんのスパンだけ長い、つまり時間がかかっていることが分かりますよね。「ホーム画面の表示が遅い」という問題に対して、かなりスピーディーに原因を特定することができました。
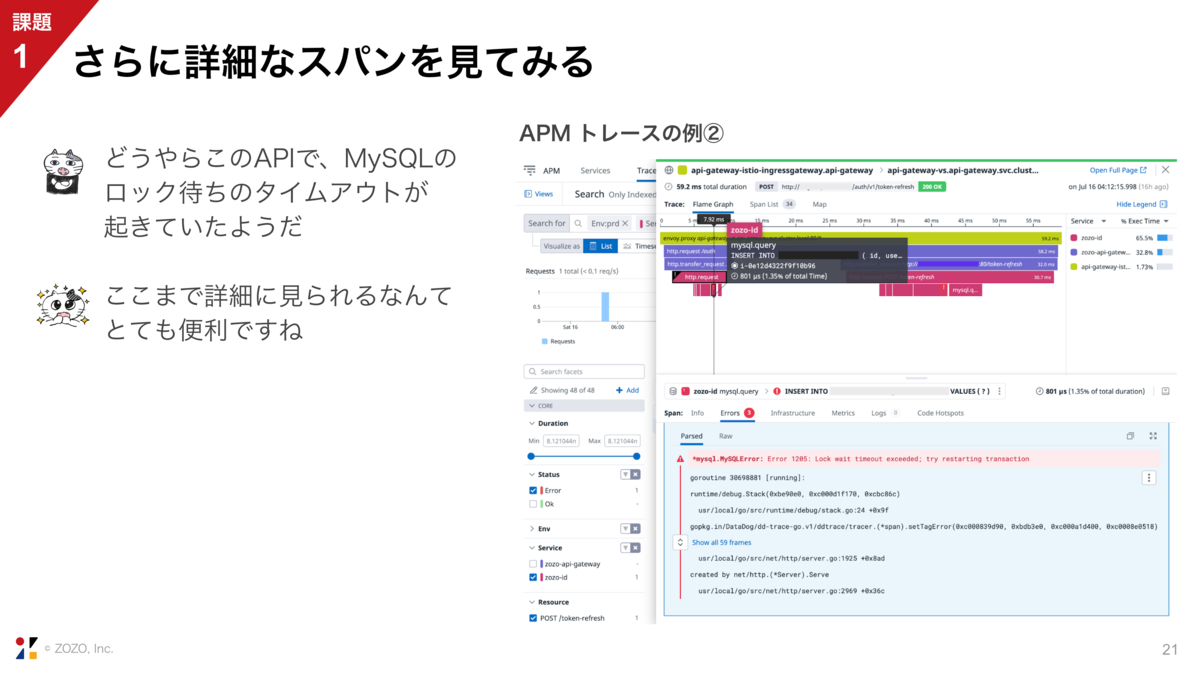
今度は別のトレースで、細かいスパンの中まで見てみます。
アプリケーションが実行したMySQLのクエリ1つ1つが、トレースの1番下の行、赤色のスパンで表示されています。画面の下半分には、ロック待ちでタイムアウトしたというエラーが表示されています。非常に細かいレベルまで見られるので便利です。
(目次に戻る)
2. アラートやダッシュボードや外形監視が欲しい → Monitors, Dashboards, Synthetics

(巣立)課題2では、Datadogの基本機能であるMonitorやDashboard、Syntheticsについて、便利なポイントをお話します。
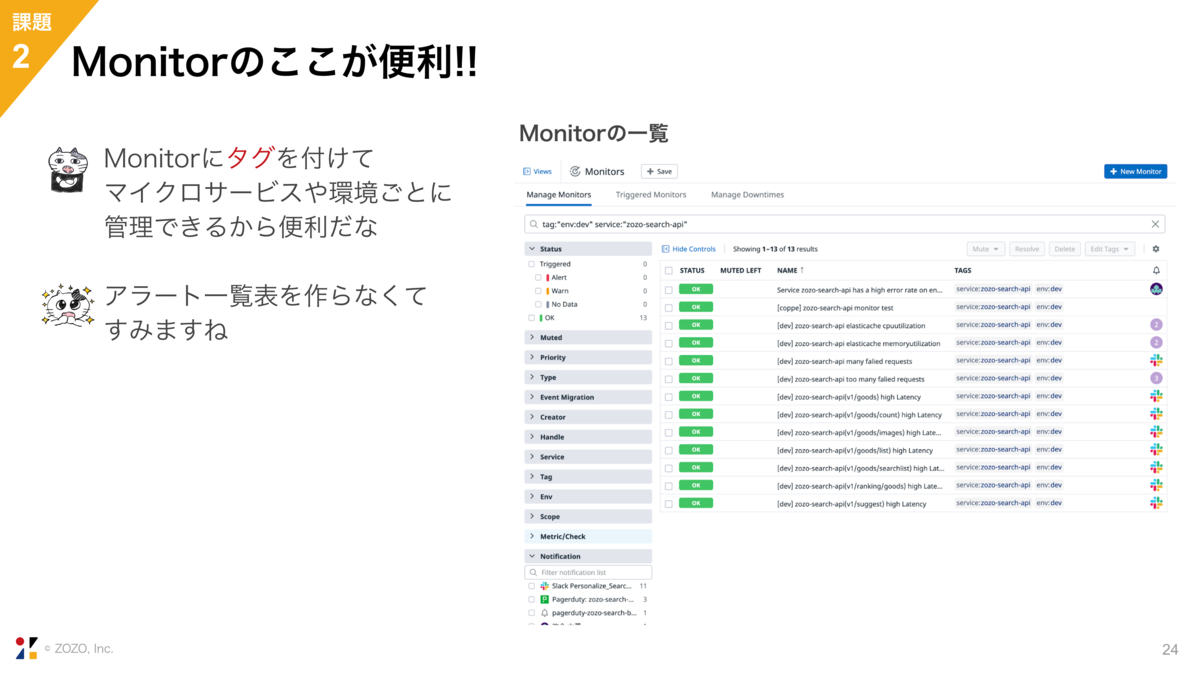
まず、Monitorです。Monitorはタグをつけることが可能で、マイクロサービスや環境ごとに管理することができます。
スライドの画像では、serviceタグにzozo-search-apiを、envタグにdevを指定してMonitor一覧を表示しています。このようにタグを使ってフィルターできるので、Monitorの一覧表を別に用意する必要がありません。
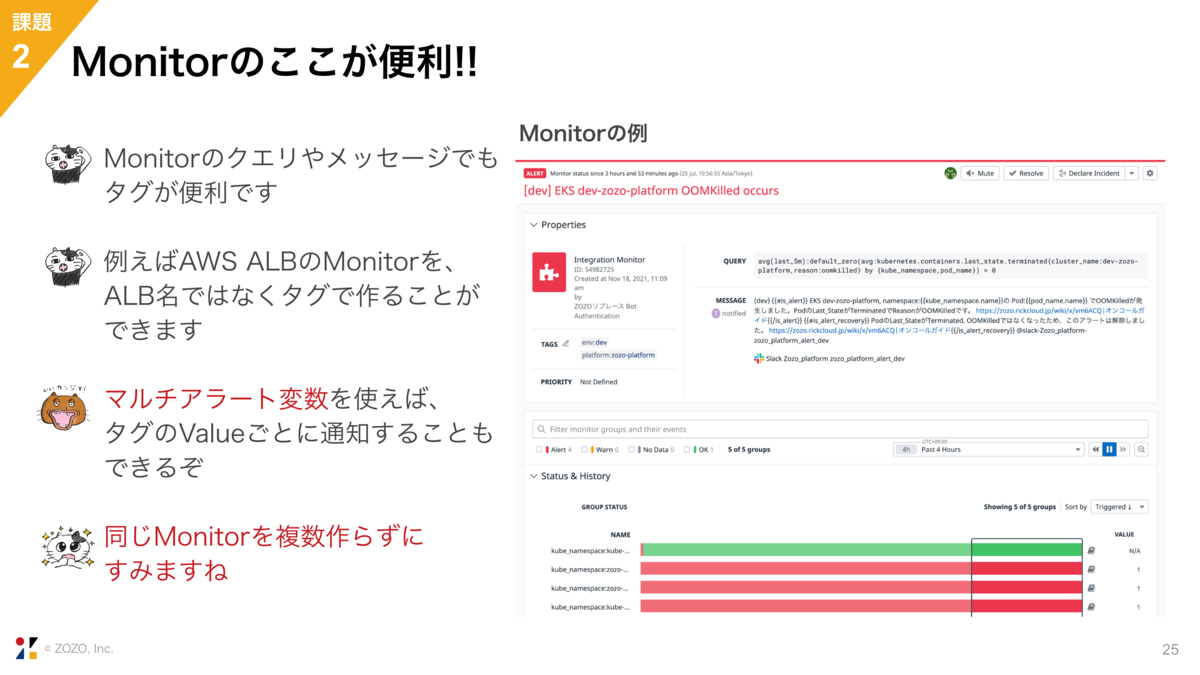
また、Monitorで使用するクエリやメッセージにもタグを使用することができます。例えばAWS ALBのMonitorを作成する時には、ALB名ではなくタグを使用してMonitorの設定が可能です。
マルチアラート変数を使えば、タグの値ごとに通知することもできます。スライドの画像ではマルチアラート変数にKubernetesのNamespaceを指定しています。Namespaceの数だけmonitorを作らずとも、全てのNamespaceに対して一括でMonitorを作成できます。
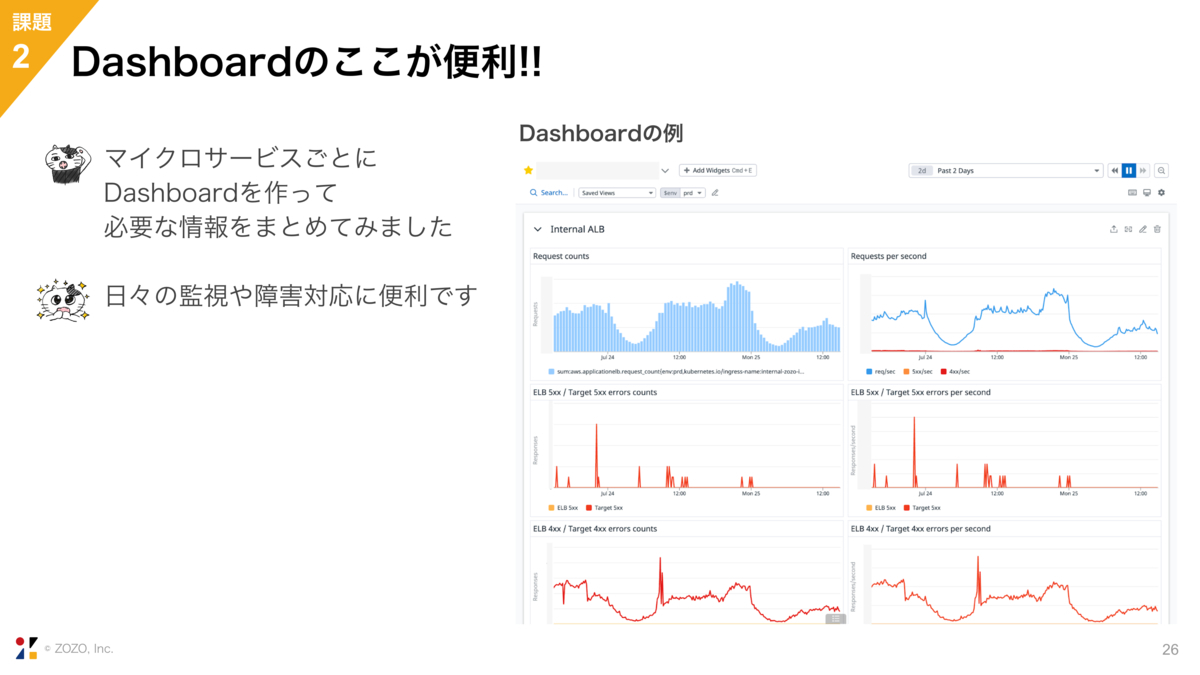
続いてDashboardです。弊チームではマイクロサービスごとにDashboardを作成しています。リリースや負荷試験などの日々の監視や障害対応にとても活躍しています。
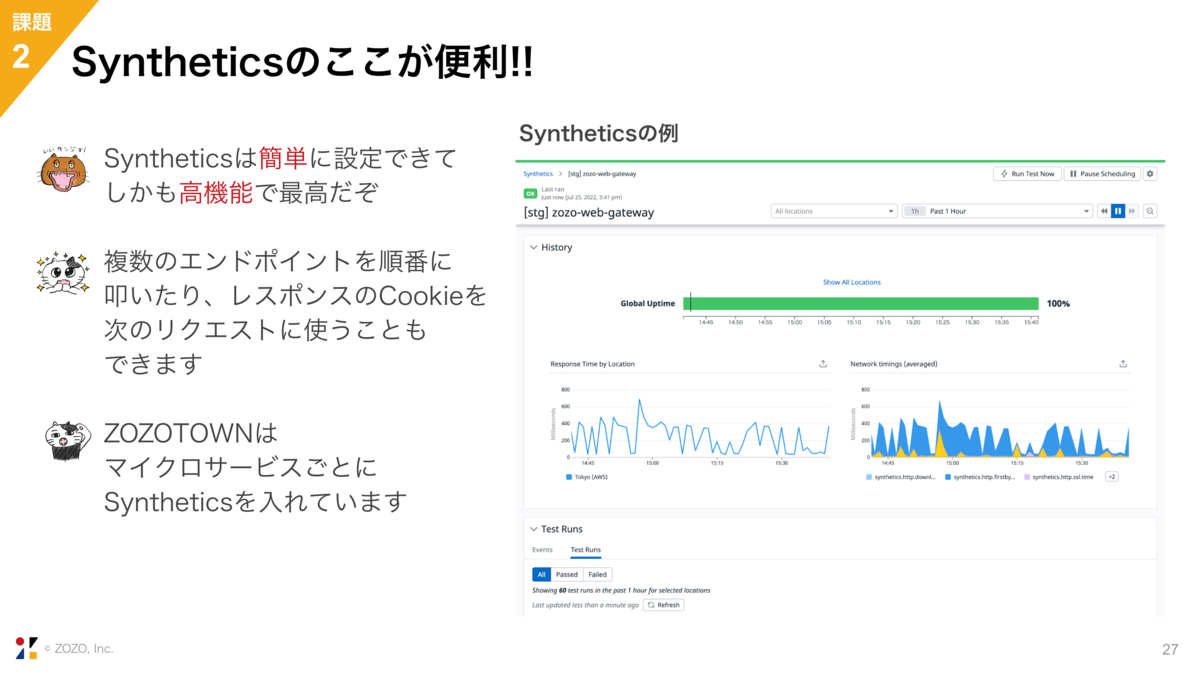
今度はSyntheticsについてです。DatadogのSyntheticsは簡単に設定でき、他のサービスに比べても高機能な印象です。
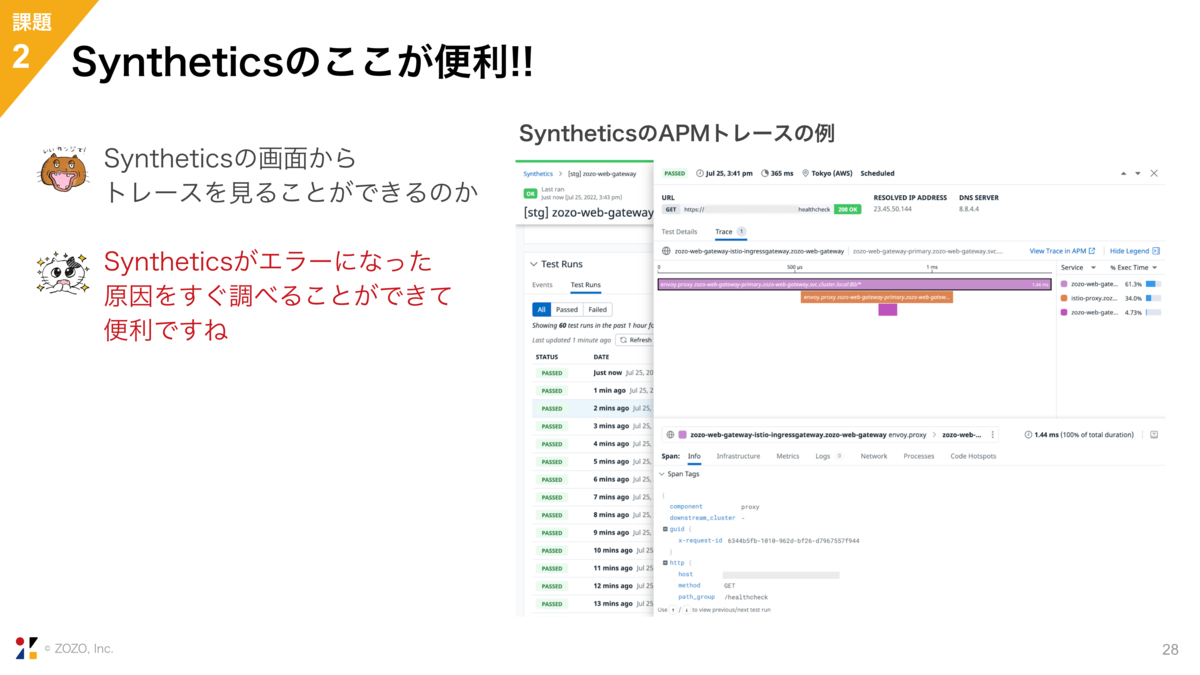
そして、これが一番お気に入りなのですが、Syntheticsの画面からAPMトレースを見ることができるので、Syntheticsがエラーになった原因をすぐに調べることができます。
(目次に戻る)
3. AWSのメトリクスがDatadogに届くのが遅い → Metric Streams

(高塚)課題3は、AWSのメトリクスがDatadogに届くのが遅い件です。
AWSのメトリクスがDatadogに届くまで10分程度遅れることがあります。右側にALBのグラフがありますが、各グラフの右端だけ線が欠けています。
何が問題かと言うと、Datadog Monitorが10分遅れると、障害に気づくのも10分遅れてしまうという点です。
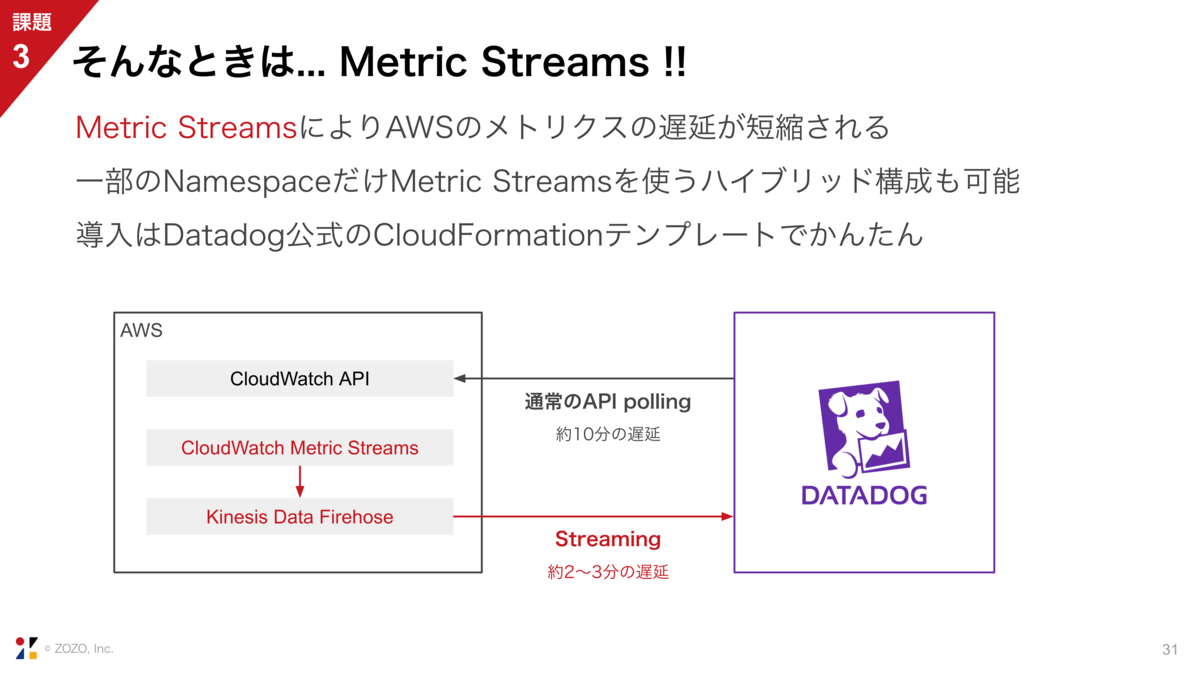
そこで、Metric Streamsです。これはAWSの場合に限った話になりますが、CloudWatch Metric StreamsとKinesis Data Firehoseを使ってDatadogにメトリクスをストリーミングすることで、先ほどの遅延を2〜3分程度に抑えることができます。

これを活用することで、我々はMonitorやDashboardの遅延をほぼ考慮することなく利用できています。
(目次に戻る)
4. 障害調査や負荷試験などでメトリクスを記録するのが大変 → Notebook
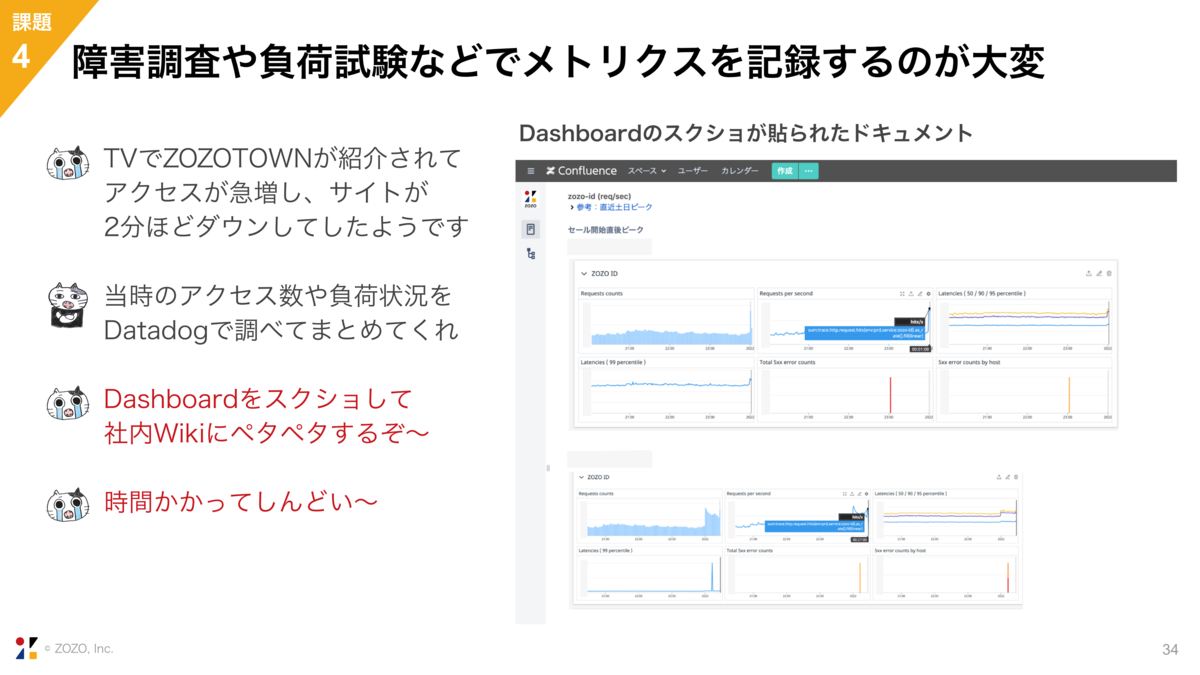
4つ目の課題は、障害調査や負荷試験などでメトリクスを記録するのが大変、という点です。
リクエスト数や負荷状況などのメトリクスを記録したいというときに、我々はこれまでDatadogのDashboardをスクショして、社内Wikiにペーストしていました。時間のかかる面倒くさい作業でした。

それを改善できるのが、Notebookです。NotebookはDatadog上にドキュメントを作成、共有できる機能です。

これが実際に作ったNotebookです。画面はDashboardに似ていて、例えば右上にタイムフレームがあります。スクショとは違って、この時刻を変更すればグラフが動的に変わります。デフォルトを障害発生時刻にする、みたいなこともできます。
コメント機能や同時編集機能もあります。

テンプレート変数を使って、左上のプルダウンメニューから環境やマイクロサービスを切り替えて表示できるようにしたり、Notebookをテンプレートとして保存したりすることもできます。これまでのスクショの苦労がなくなりました。
(目次に戻る)
5. サイトの健全性を数値化したい → SLO
課題5は、サイトの健全性を数値化したいということです。これまで色々な監視の話をしましたが、結局サイト全体の健全性はどうなんだ、数値化できないのか、という話です。

そんなときにSLOが使えます。SLOとは、スライドに記載したようなサービスレベル目標のことですが、Datadogを使うと簡単にSLOを算出して可視化できます。

これが試しにやってみたサンプルです。障害を防ぐという仕事は「やって当たり前」と思われることも多く、エンジニアでさえ成果が見えにくい部分です。それをSLOで可視化したり、目標を設定したりすることで、モチベーションが湧きやすくなります。
(目次に戻る)
6. CI/CDが遅い原因がわからない → CI Visibility
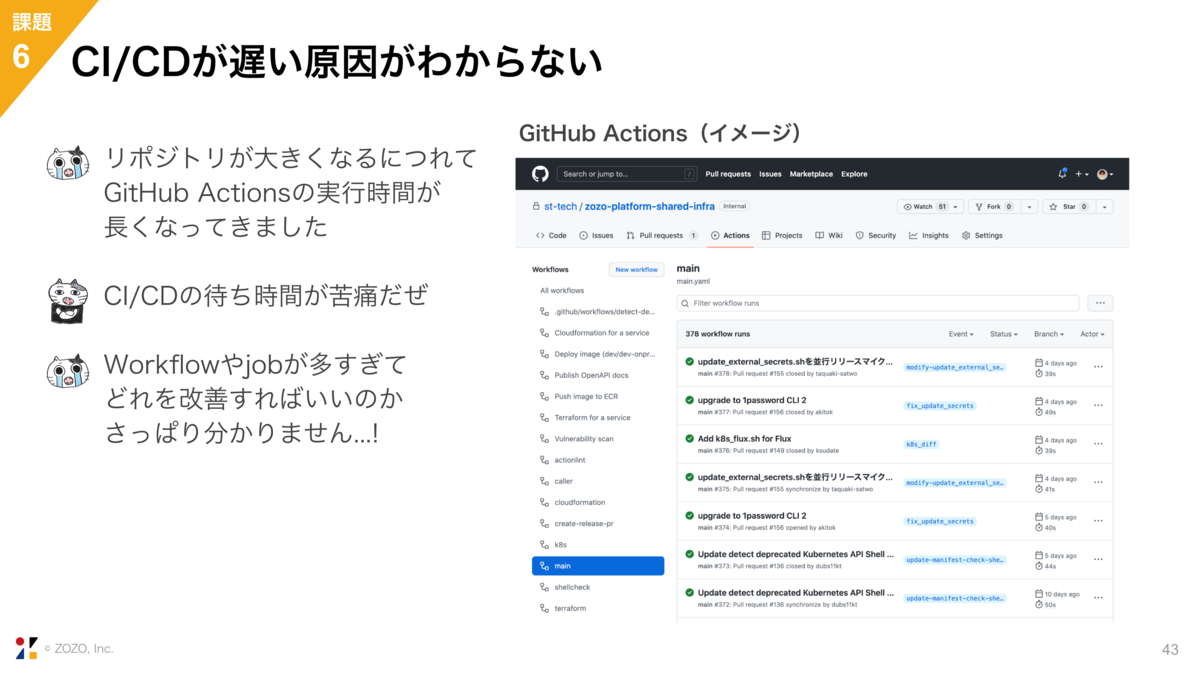
6つ目の課題は、CI/CDが遅い原因が分からないということです。
我々はCI/CDにGitHub Actionsを使っています。リポジトリが大きくなるにつれて、WorkflowやJobにかかる時間が伸びたり、Workflowの数自体が増えたりして、CI/CDの待ち時間、デプロイ待ちのような時間が生まれてしまいました。
ただ、WorkflowやJobが多く、どれを改善すれば良いのか分からないという問題がありました。

そこでCI Visibilityです。CI Visibilityは多くのCIサービスに対応しています。
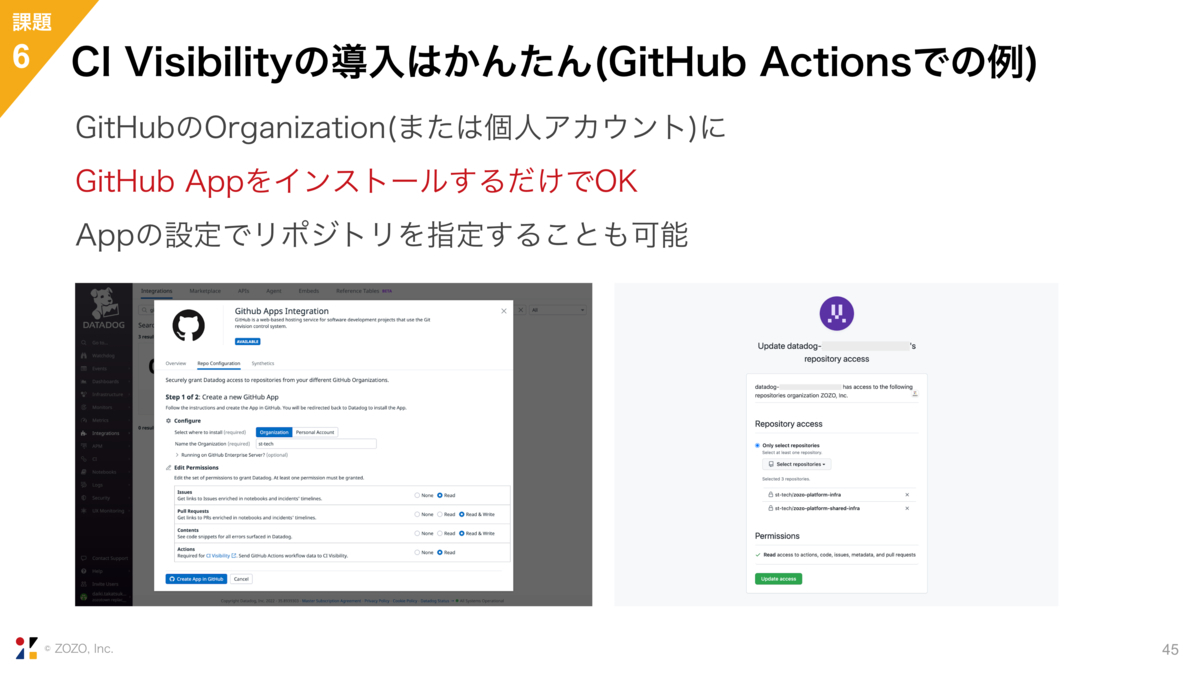
導入も非常に簡単で、例えばGitHub Actionsの場合は、DatadogのIntegrationsの画面からGitHub Appをインストールだけで完了します。リポジトリを指定することも可能です。
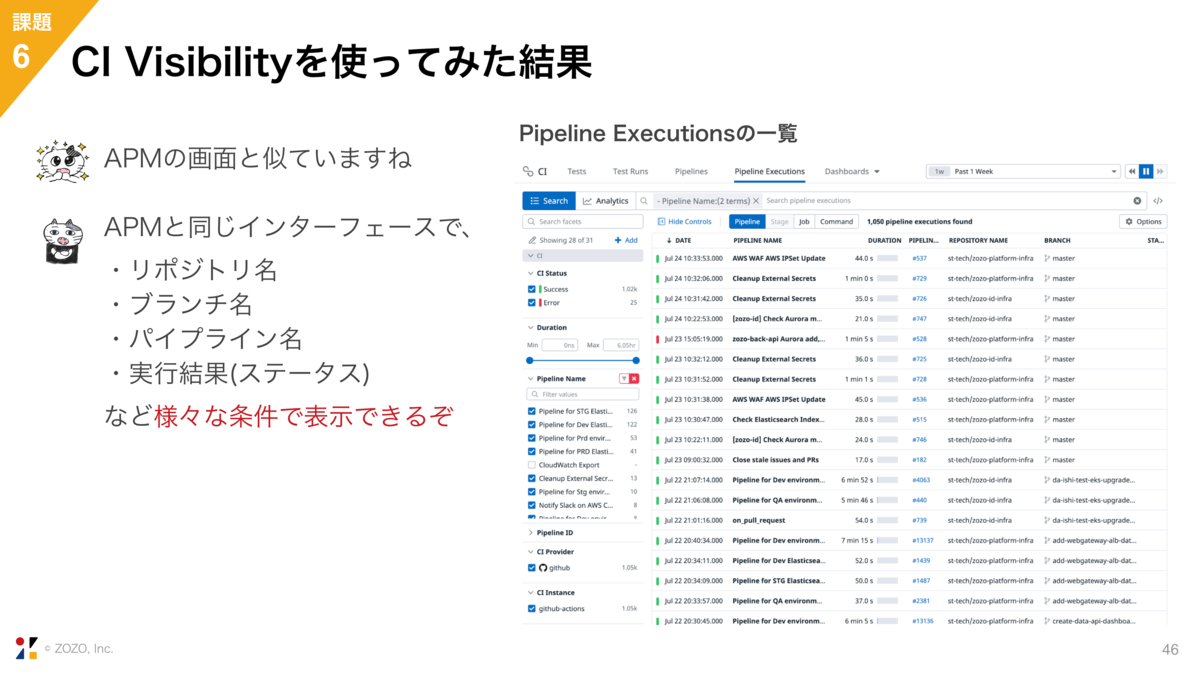
導入すると表示されるようになるのがこの画面で、これはCIの実行結果一覧です。APMと同じように、リポジトリ名やブランチ名でフィルター表示できます。
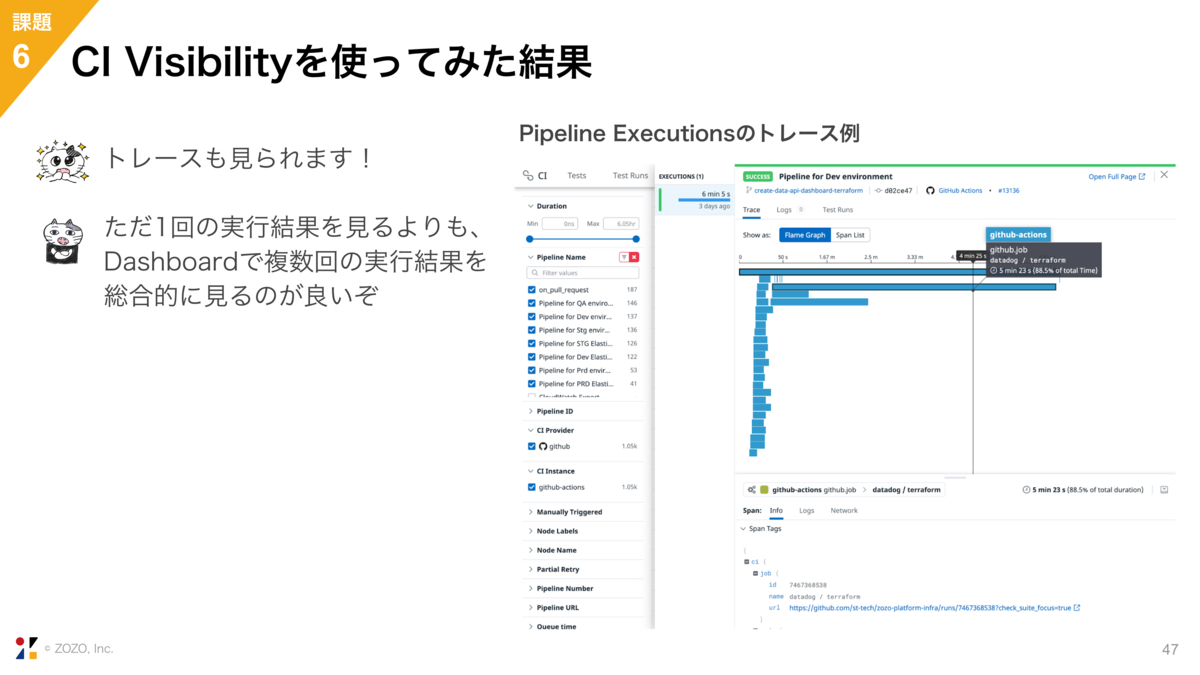
そして、1つの実行結果をクリックすると、なんとトレースが見られます。例えばこのトレースでは、最初に同じJobが複数環境に対して並列に実行されて、そのあといくつか時間のかかるJobが実行されています。
ただ、1回の実行結果を見るよりも、複数回の実行結果を横断的に分析したほうが良いと思いまして...
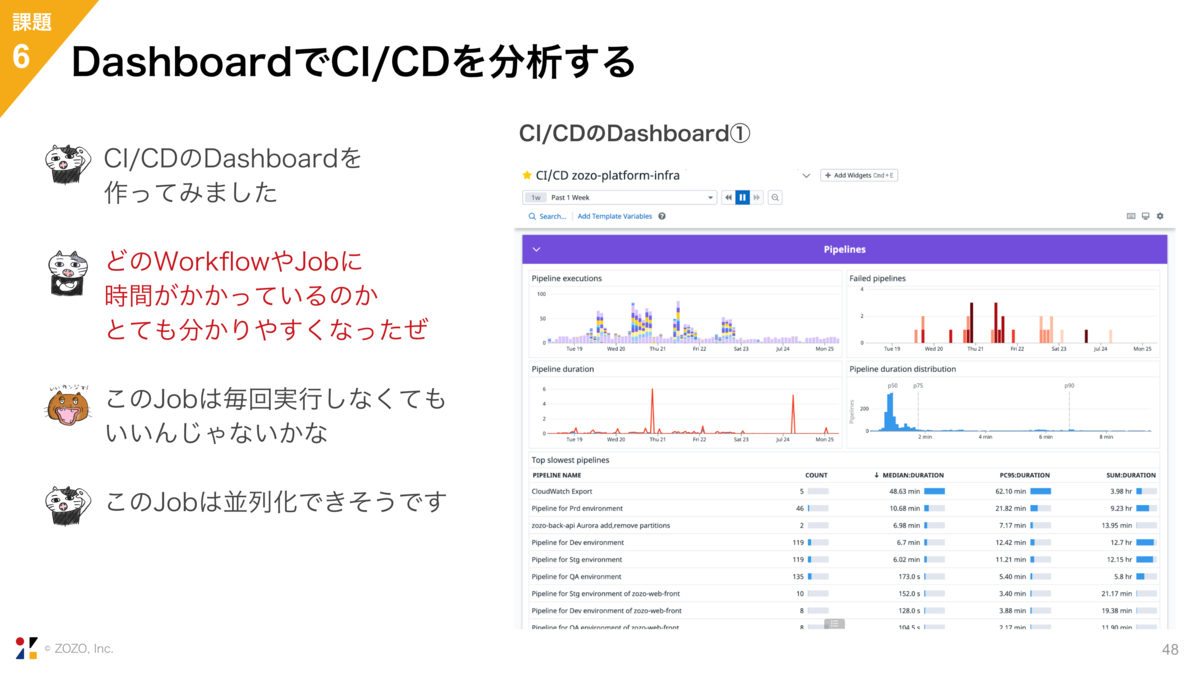
CIのDashboardを作ってみました。色々ありますが、例えば下半分の表は、もっとも時間のかかったWorkflowのランキングです。画面外にはJob単位の表もあります。
これを見ることで、どのWorkflowやJobに時間がかかっているのか、どれくらいの頻度で実行されているのかを分析できるようになりました。
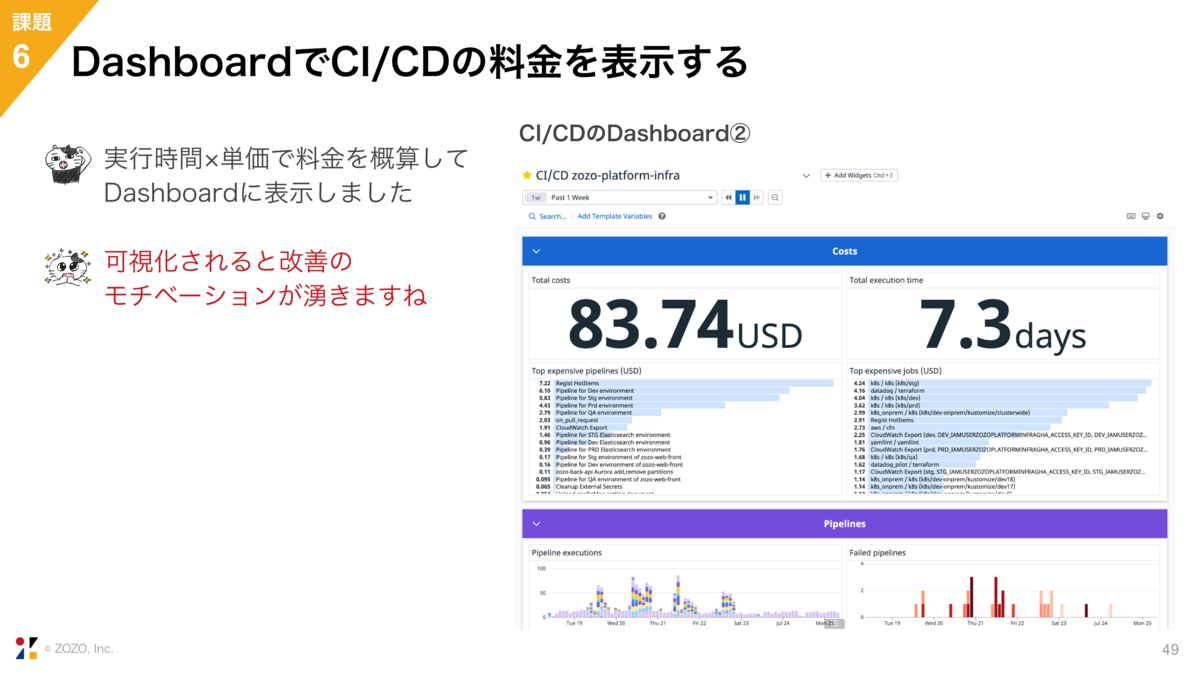
もう1つ我々がやっている工夫として、実行時間×単価でCIのおよその料金を表示するようにしました。このJobにいくらお金がかかっている、ということを可視化しています。
先ほどと同じ話になりますが、可視化することで改善のモチベーションが湧くことを実感しています。

以上が第1部です。ご覧のサービスの活用法をご紹介しました。1つでも皆さまにとってお役に立つ情報が含まれていたら幸いです。
(目次に戻る)
第2部 全社管理者の取り組み

(巣立)第2部では、ZOZOにおける全社管理者の役割を最初に説明します。その後、具体的な取り組みを3つ紹介します。

弊社では、Datadogやその他のクラウドサービスをたくさんのチームが利用しています。
今回のテーマである全社管理者とは、それらのクラウドサービスのアカウント管理やセキュリティインシデントの監視など、サービス利用者が開発に集中できるようにするための様々な取り組みを行うメンバーです。複数チームのSREから構成されており、Datadogの管理者は現在3名います。
(目次に戻る)
1. Azure ADによるDatadogユーザーの管理
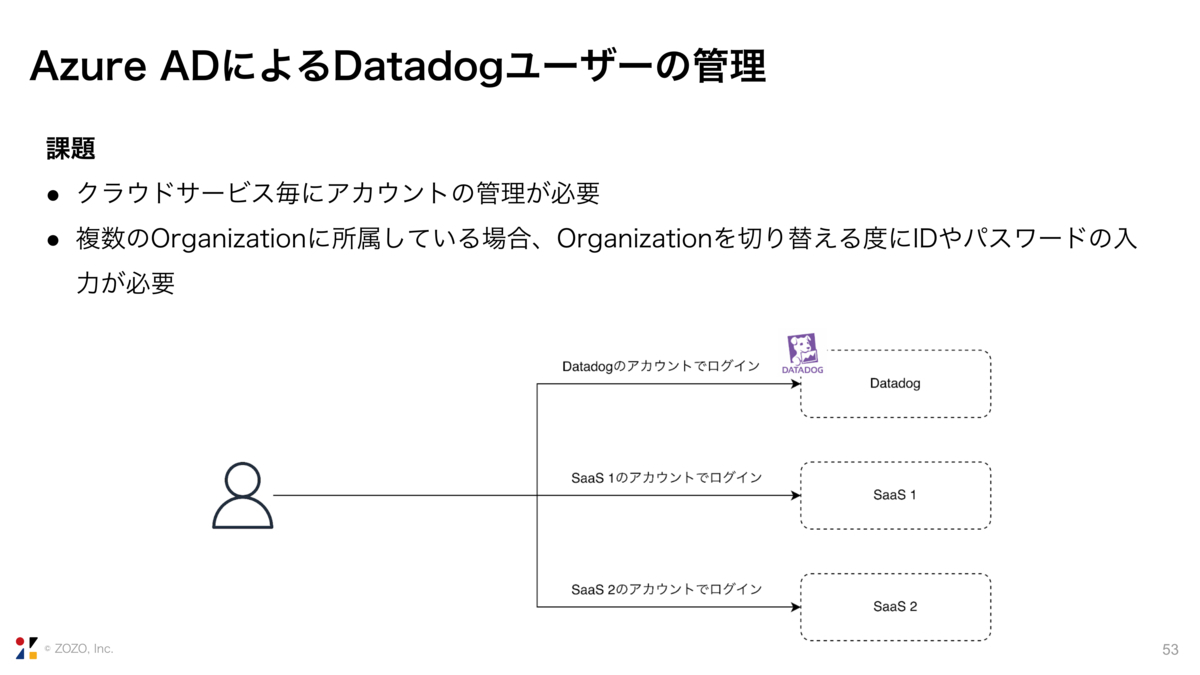
ここから、その全社管理者の取り組みについて紹介します。1つ目はAzure ADによるDatadogユーザの管理についてです。
通常であれば、クラウドサービスごとにアカウントの管理が必要になります。また、Datadogに関して言えば、複数のOrganizationに所属しているメンバーは、Organizationを切り替えるたびにIDやパスワードの入力が必要になります。
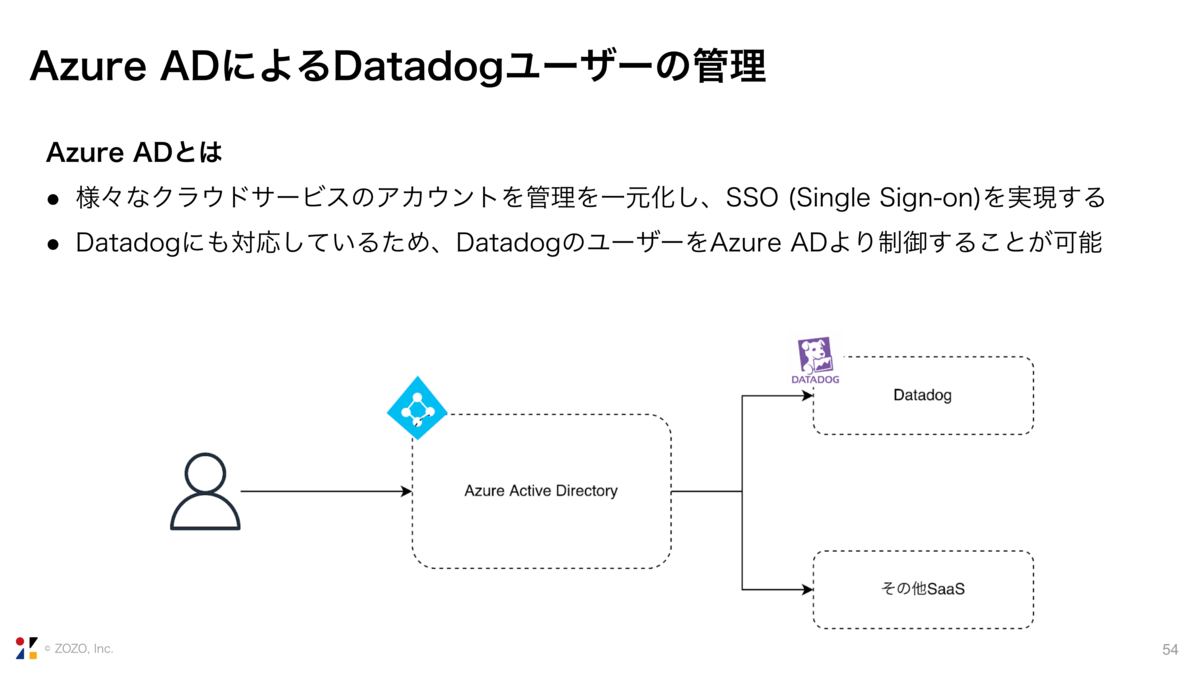
そこでAzure ADです。Azure ADでは、様々なクラウドサービスのアカウント管理を一元化し、SSO (Single Sign-on) を実現することができます。Azure ADはDatadogにも対応しています。
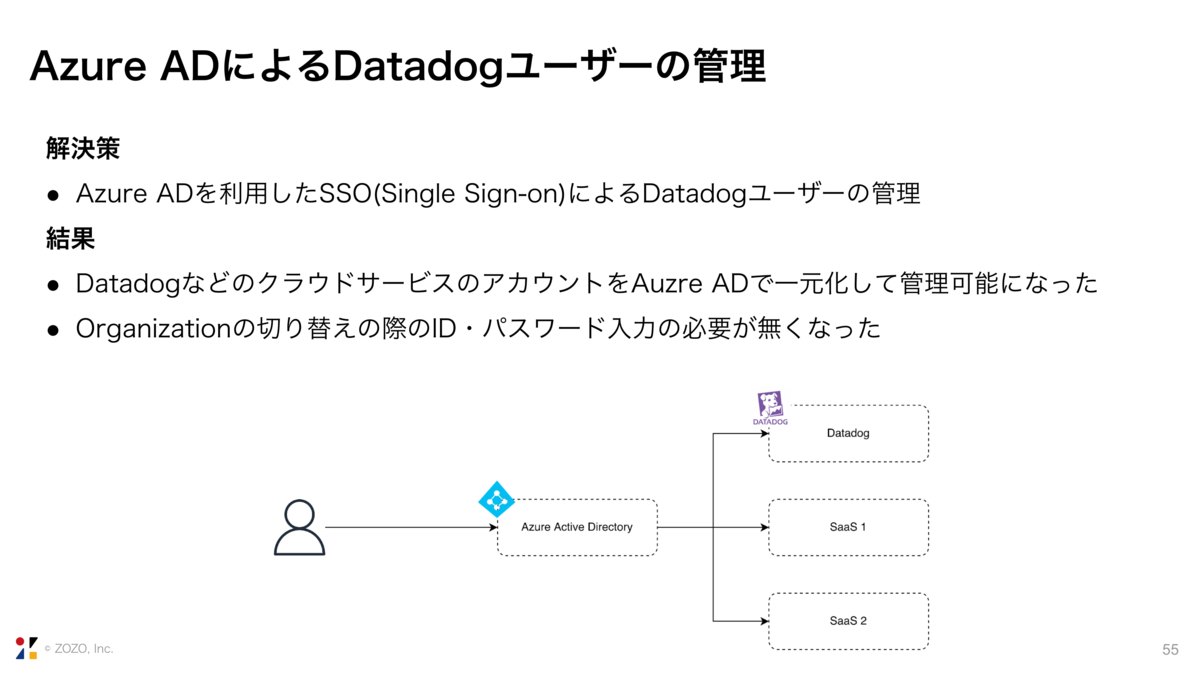
Azure ADを使ってDatadogのアカウントを管理するようにし、SSOを実現しました。これによりOrganizationの切り替えの際にID・パスワードの入力が不要になり、利用者も管理者もアカウント管理の負担が減りました。
(目次に戻る)
2. Multiple-Organization Accountsを使った一括請求
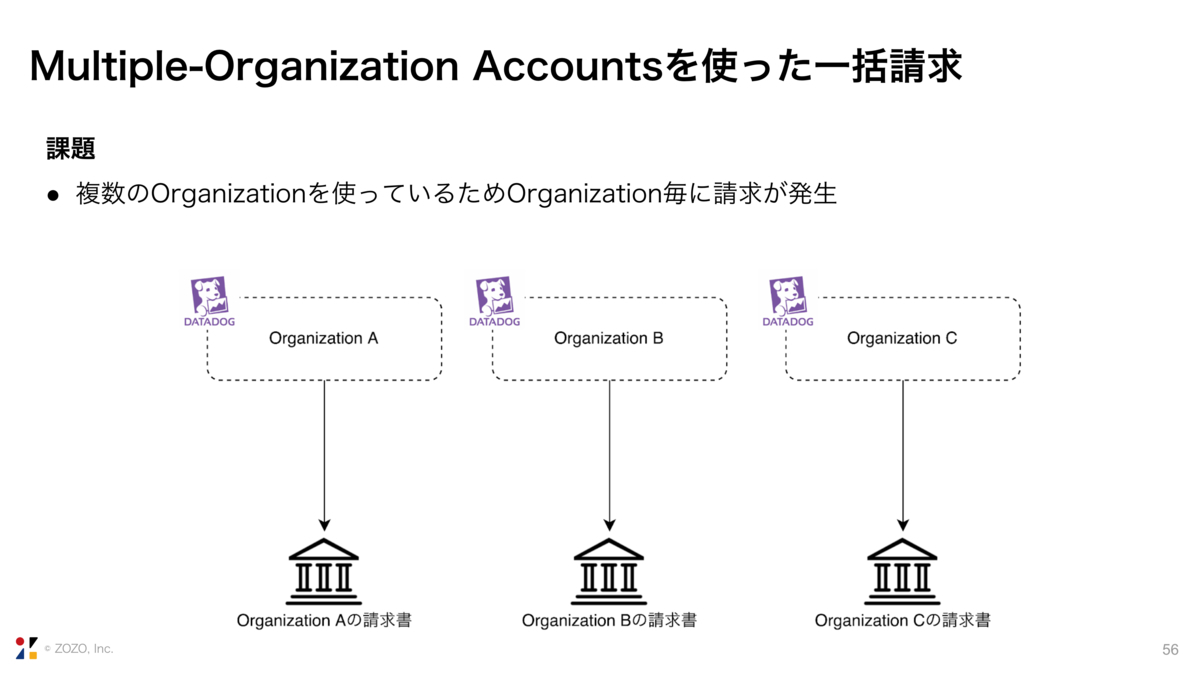
続いて、Multiple-Organizationを使ったDatadogの一括請求についてです。
弊社では、Datadogで複数のOrganizationを利用しています。そのため、Organization毎に請求が発生し、Organizationの数だけ請求書を処理する必要がありました。

そこでMulti-Organizationです。
下の画像のようにOrganizationごとの利用量、例えばInfra hostsがこのくらい、などを親Organizationから確認することが可能になります。そして、全てのOrganizationの請求を親Organizationに一元化できます。
この機能はDatadogサポートへ連絡することで使えるようになります。
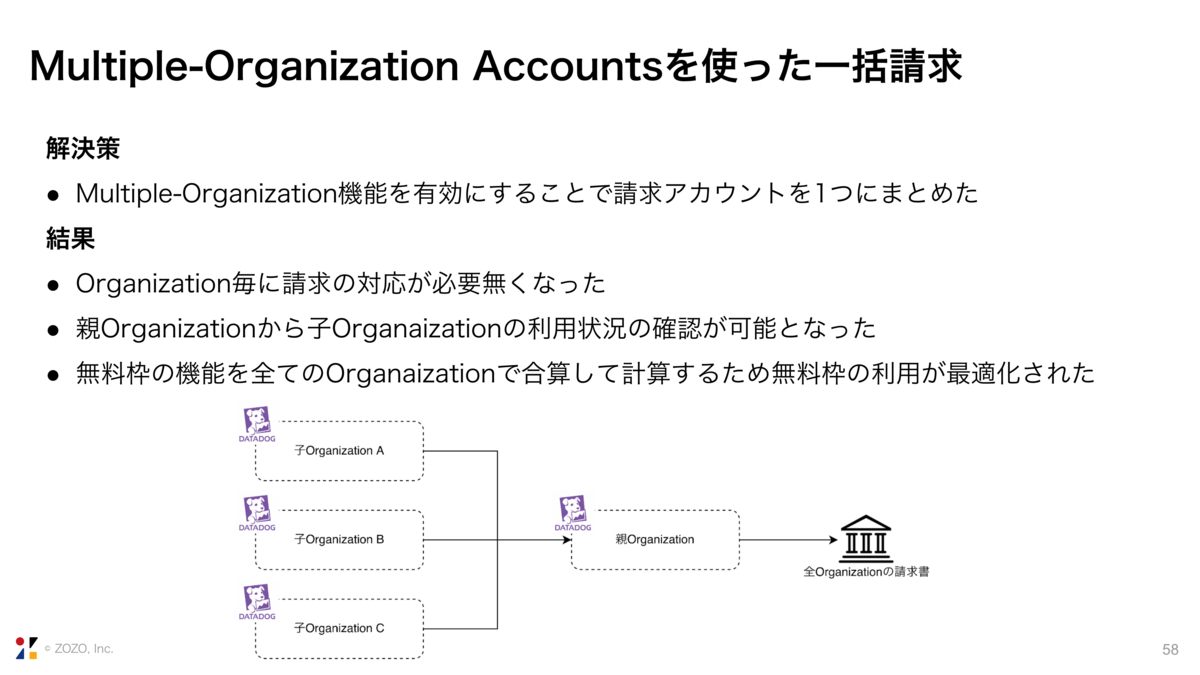
Multi-Organizationを利用したことによって、Organizationごとに請求書を処理する必要がなくなりました。また、親Organizationから子Organizationの利用状況の確認が可能となりました。
そして、無料枠を全てのOrganizationで合算して計算するようになったため、無料枠の利用が最適化されました。
(目次に戻る)
3. カスタムロールを使ったUsageの確認
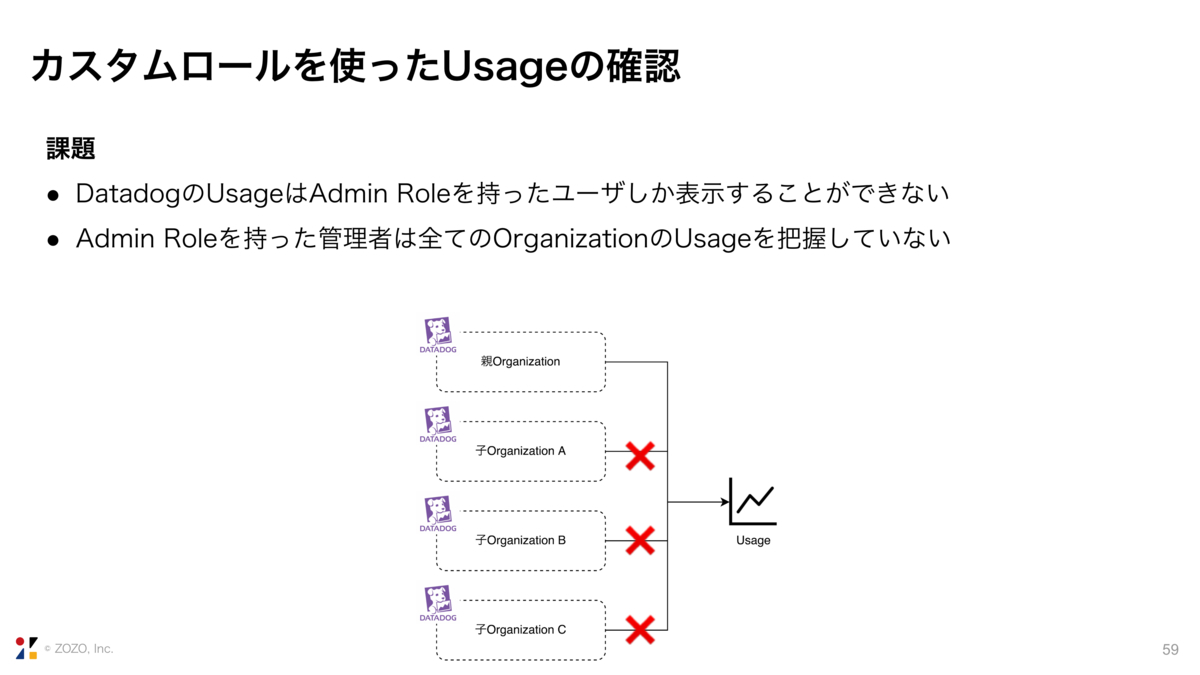
3つ目に、カスタムロールを使ったUsageの確認です。
DatadogのUsage、先ほど見せたInfra hostsがこのくらいなどを確認できる画面ですね。このUsageは、Admin Roleを持ったユーザしか表示することができません。
しかし、Admin Roleを持ったユーザ、つまりはDatadogの管理者は、全てのOrganizationでどのくらい利用しているのかを把握することが難しいので、このOrganizationでのこの機能の利用料は適切かどうかを判断することができません。

そこでカスタムロールを使用することにしました。
カスタムロールを説明する前に簡単にDatadogのデフォルトのロールについて説明します。1つずつの説明は省きますが、デフォルトのロールで請求情報、UsageにアクセスできるのはAdmin Roleだけです。
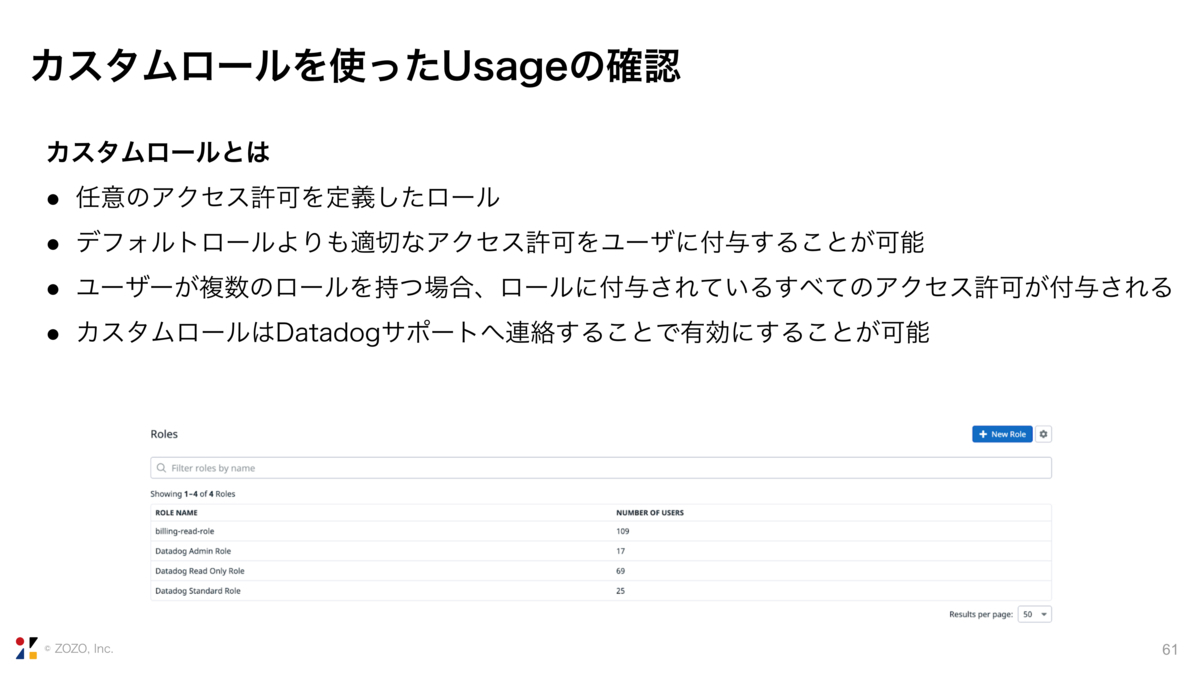
では、本題のカスタムロールについてです。
カスタムロールでは任意のアクセス許可を定義することができます。そのため、デフォルトのロールよりも適切なアクセス許可をユーザに付与することができます。また、ユーザが複数のロールを持つ場合、例えばデフォルトのロールとカスタムロールの2つを持つ場合は、両方のロールに付与されている全てのアクセス許可が付与されます。
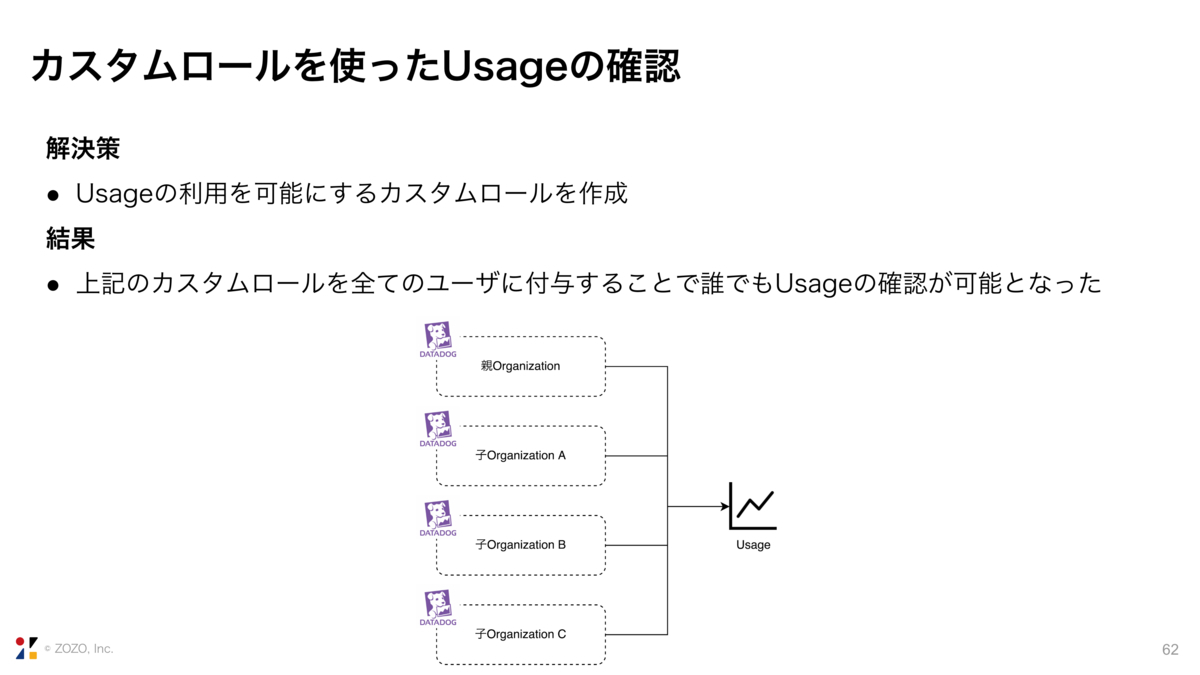
このカスタムロールに請求情報へのアクセス権を付与し、全てのユーザにこのロールを渡すことで、誰でも自身の所属するOrganizationのUsageの確認が可能となりました。また、管理者は各Organizationの利用料が適切かどうかをOrganizationの利用者に任せることが可能となりました。
以上が、Datadog全社管理者の取り組みについての紹介でした。

まとめです。本発表では、ZOZOTOWNにおけるDatadogの活用と、それを支える全社管理者の取り組みについてご紹介しました。
(目次に戻る)
おわりに

冒頭でご紹介した通り、本内容はDatadog Japan Meetup 2022 Summerで発表させていただきました。
ご来場いただいた皆様、ここまでお読みいただいた皆様、誠にありがとうございました。
私たちのチームでは、Datadog・AWS・Kubernetes・Istioなどをフル活用し、ZOZOTOWNのマイクロサービス基盤を一緒に作る仲間を募集しています。ぜひ下記リンクからご応募ください!