



こんにちは、データ基盤の開発・運用をしている谷口(case-k)です。
本記事では、BigQueryで秘密情報を守るためのリソースである、ポリシータグをご紹介します。ポリシータグの概要から採用理由、仕様を考慮したデータ連携の仕組みや運用における注意点まで幅広くお伝えします。
ポリシータグとは
ポリシータグは、BigQueryでカラム単位のアクセス制御が可能なリソースです。BigQueryに保存されている秘密情報を、機密性高く管理するために利用します。
これまで、BigQueryではテーブルやデータセット単位でのアクセス制御はできましたが、カラム単位でのアクセス制御はできませんでした。1つのテーブルに複数の秘密情報が管理されている場合には、テーブル単位のアクセス制御だと、必要以上の秘密情報を参照できてしまいます。
例えば会員情報を扱う場合、1つのテーブルに名前や性別、年齢など様々な秘密情報が管理されます。それらは下図のように機密性も様々です。それらの秘密情報を掛け合わせることで個人の特定に繋がってしまいます。カラム単位のアクセス制御を導入することにより、個人を匿名化し、個人情報の漏洩リスクを防ぐことに役立ちます。
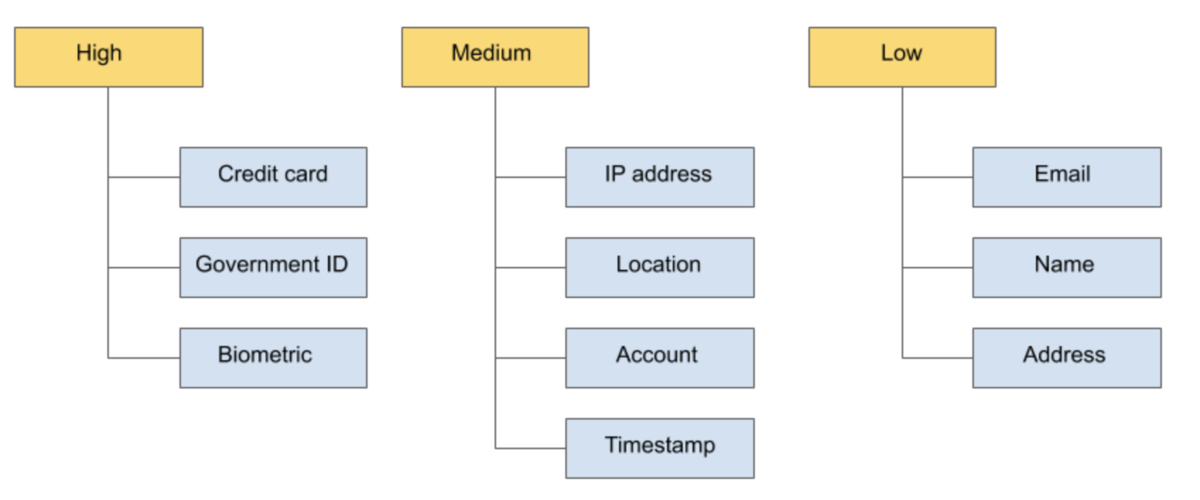
引用:BigQuery でポリシータグを使用する際のベスト プラクティス | Google Cloud
BigQueryのスキーマ情報からどのスキーマが秘密情報で、どのようなポリシータグが付与されているか、下図のように把握できます。

A column can have only one policy tag. A table can have at most 1,000 unique policy tags.
引用:制限事項 - BigQuery の列レベルのセキュリティの概要 | Google Cloud
そして、ポリシータグはTerraformでも管理できます。ここではその流れを紹介します。
まず、親となる分類「taxonomy」リソースを作ります。
resource "google_data_catalog_taxonomy" "taxonomy" { project = var.project_private provider = google-beta region = "us" display_name = "policytag-taxonomy-${var.env}" description = "A collection of policy tags" activated_policy_types = ["FINE_GRAINED_ACCESS_CONTROL"] }
次に、子のリソースとなる「ポリシータグ」を作ります。名前や年齢など、秘密情報の分類に基づいたポリシータグを作ります。
resource "google_data_catalog_policy_tag" "child_policy_name" { provider = google-beta taxonomy = google_data_catalog_taxonomy.taxonomy.id display_name = "name" description = "name" parent_policy_tag = google_data_catalog_policy_tag.parent_policy_secret.id }
作成したポリシータグは、GCPコンソール上で確認できます。例えば、親子関係でリソースを作った場合、下図のような表示になります。弊社では、親リソースとして「secret」を用意し、子リソースとして分類ごとのポリシータグを作成しています。

そして、コードとして取り扱うので、Git上で「誰にどの権限を付与しているのか」を管理できます。
resource "google_data_catalog_policy_tag_iam_binding" "child_policy_name_viewer" { provider = google-beta policy_tag = google_data_catalog_policy_tag.child_policy_name.name role = "roles/DataCatalog.categoryFineGrainedReader" members = var.zozo_datapool_private_policy_tag_name_viewer }
なお、ポリシータグを付与したカラムは、権限がないと参照できなくなります。参照するには「Fine-Grained Reader role」権限が必要です。権限がない状態で参照しようとすると、以下のエラーが発生します。これは、オーナー権限を持っている管理者であっても同様です。
Access Denied: Policy tag projects/<project_id>/locations/<locations>/taxonomies/<taxonomies-id>/policyTags/<policyTags-id>: User does not have permission to access policy tag "<policytag-taxonomy-name> : tell" attached to table(s) <project>.<dataset>.<table>
引用:きめ細かい読み取りのロール - BigQuery の列レベルのセキュリティによるアクセス制限 | Google Cloud
前述の通り、ポリシータグはカラム単位のアクセス制御により個人情報を匿名化します。最初は「データベース × テーブル」でポリシータグを作ろうと考えましたが、分類あたりのポリシータグの上限が100と決まっているため、それは実現できませんでした。「テーブル × カラム」で秘密情報を保護する思想にはなっていないようです。
Maximum number of policy tags per taxonomy 100
引用:割り当てと上限 | Data Catalog のドキュメント | Google Cloud
ポリシータグを採用した理由
BigQueryにおける秘密情報への参照を制限する方法は、ポリシータグ以外にも、承認済みビューなどの承認済みリソースを使う方法も考えられます。
承認済みビューを使うと、元テーブルへの参照権限がなくても承認済みビューからは参照できるようになります。秘密情報のカラムを除いた承認済みビューを用意することで、秘密情報ではないレコードのみを参照できます。
なぜ承認済みビューではなく、ポリシータグを採用したのか、その判断理由を順に説明します。
匿名化による機密性の高さ
ポリシータグは、秘密情報の分類に基づき、カラムごとに閲覧者を制限できます。前述の通り、年齢だけでは個人の特定に至る可能性は低いですが、複数の秘密情報を掛け合わせることで個人の特定に繋がるため、カラムごとの制限は効果的です。
一方、承認済みビューは、テーブルやデータセットごとのアクセス制御です。そのため、テーブルに複数の秘密情報が管理されている場合、必要でないカラムの秘密情報まで参照できてしまうことになります。それを回避するために、カラムレベルでアクセス制御できるよう、特定のカラムのみ参照する承認済みビューを作る方法も考えられます。しかし、大量の承認済みビューを管理する必要がでてきます。我々は少人数のチームなため、その運用面で現実的ではありませんでした。
また、前述の通りポリシータグを付与するとオーナー権限を持っていたとしても参照できません。参照するには「Fine-Grained Reader role」権限が必要です。オーナーが誤って秘密情報を参照してしまうことも防げます。なお、オーナー自身で権限付与は可能ですが、監査ログにはその証跡が残るため検知可能です。
しかし、テーブル単位のアクセス制御の場合は、オーナー権限があれば参照が可能です。誤って参照してしまうことも考えられます。
以上の違いにより、ポリシータグの方が、より安全に秘密情報を管理できると判断しました。
機密性と利便性の両立
ポリシータグの良い点は、機密性を担保しつつも、利用者が使いやすい点も挙げられます。ポリシータグを付与したテーブルでも、参照権限があれば下図のようにプレビューでクエリ実行前にレコードを確認できます。参照できないのは、ポリシータグでアクセス制御されているカラムのみです。
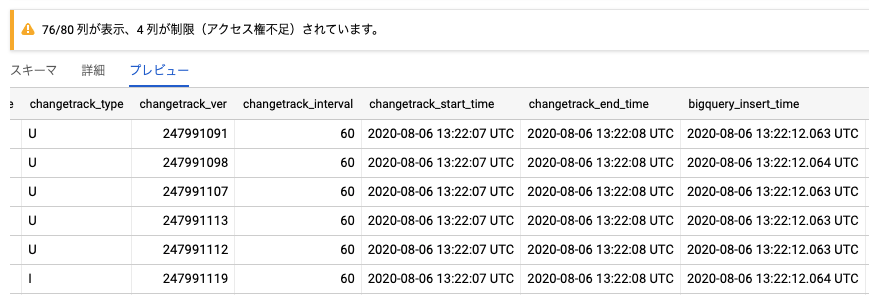
下図のようにBigQueryテーブルのスキーマを見れば、どのカラムが参照できないのか、どの分類のポリシータグが付与されているかを確認できます。
なお、権限がないカラムは、以下のように対象カラムを除外すれば参照できます。
SELECT * EXCEPT(policy-tag-column) FROM TABLE
一方、承認済みビューの場合テーブルへのアクセス権限はありません。そのため、プレビューを使ったレコードの確認もできなくなってしまいます。プレビューする必要がある際には、以下のようなクエリを実行し、全カラムの値を確認する必要があります。また、ポリシータグのように、どのカラムが秘密情報としてアクセス制御されているかは分かりません。
SELECT * FROM Table LIMIT 100
このように承認済みビューでも機密性は担保できますが、利用者の立場だと使いにくい環境です。また、データを確認するために全件取得する必要がある点は、費用面でも懸念がありました。BigQueryの定額料金プランで運用しているプロジェクトもあれば、オンデマンドで運用しているプロジェクトもあるからです。オンデマンドの場合、従量課金なため、全件取得に伴う費用は無視できません。
以上の違いにより、ポリシータグの方が機密性を担保しつつ、利用者が分析しやすい環境を提供できると判断しました。
データ基盤を保守運用しやすい
ポリシータグを利用することで、下記の理由により保守運用がしやすくなります。
秘密情報をテーブルに新規追加しやすい
秘密情報が存在していなかったテーブルに、新しく秘密情報を追加する場合があります。ポリシータグであれば、新しく追加された秘密情報カラムに付与するのみで対応完了です。
一方、承認済みビューの場合、閲覧先を切り替えるために、テーブルへの閲覧権限を剥奪する必要があります。そのため、対象テーブルを参照しているクエリの利用状況を確認し、関係者と調整した上でクエリの書き換えや承認済みビューへの差し替え対応が必要です。もちろん、最初から全テーブルの閲覧を制限し、承認済みビューのみ参照している状況であれば新規追加の運用も容易です。しかし、前述の通り、プレビューや秘密情報の有無を利用者が確認できないため、使いやすさの点は課題です。
秘密情報の権限管理がしやすい
ポリシータグを使うことで、秘密情報の権限管理がしやすくなります。ポリシータグは、同じリージョンであれば他のプロジェクトにも共有できます。ポシリータグリソースの共有には「roles/datacatalog.viewer」権限が必要です。ポリシータグをBigQueryのスキーマに付与するにはbigquery.tables.setCategory権限が必要となるため、「roles/bigquery.dataOwner」も必要になります。共有先のGCPプロジェクトのガイドライン化することで、BigQueryにある全ての秘密情報に共通のポリシータグを付与できます。
resource "google_project_iam_binding" "private_bigquery_datacatalog_viewer" { project = var.project_private role = "roles/datacatalog.viewer" members = var.zozo_datapool_private_datacatalogviewer }
Taxonomies are regional resources, like BigQuery datasets and tables. When you create a taxonomy, you specify the region, or location, for the taxonomy.
引用:ポリシータグ - BigQuery の列レベルのセキュリティの概要 | Google Cloud
また、Terraformを使ってコード管理できるのも良い点です。ポリシータグごとに「roles/DataCatalog.categoryFineGrainedReader」を付与することで「誰がどの秘密情報を参照できるのか」を一元管理できます。秘密情報を必要とする分析が発生した場合には、付与した権限は分析完了後にリバートすれば良いので剥奪もしやすいです。
resource "google_data_catalog_policy_tag_iam_binding" "child_policy_name_viewer" { provider = google-beta policy_tag = google_data_catalog_policy_tag.child_policy_name.name role = "roles/DataCatalog.categoryFineGrainedReader" members = var.zozo_datapool_private_policy_tag_name_viewer }
一方、承認済みビューの場合、テーブル単位のアクセス制御になるため、オーナー権限であれば参照が可能な状況です。「誰が秘密情報を見れるのか」を把握するのは困難です。
ポリシータグを活用したデータ連携の仕組み
本章では、ポリシータグを活用したデータ連携の仕組みを紹介します。
利用者が参照するデータ連携後のテーブル
ポリシータグを活用したデータ連携を行い、最終的に利用者は下図のようなテーブルを参照します。BigQueryのスキーマを見ると、秘密情報であるメールアドレスにポリシータグが付与されていることが分かります。また、分析用にメールアドレスをマスキングしたカラムも確認できます。このように、カラムのアクセス制御の状況が一覧で確認できます。
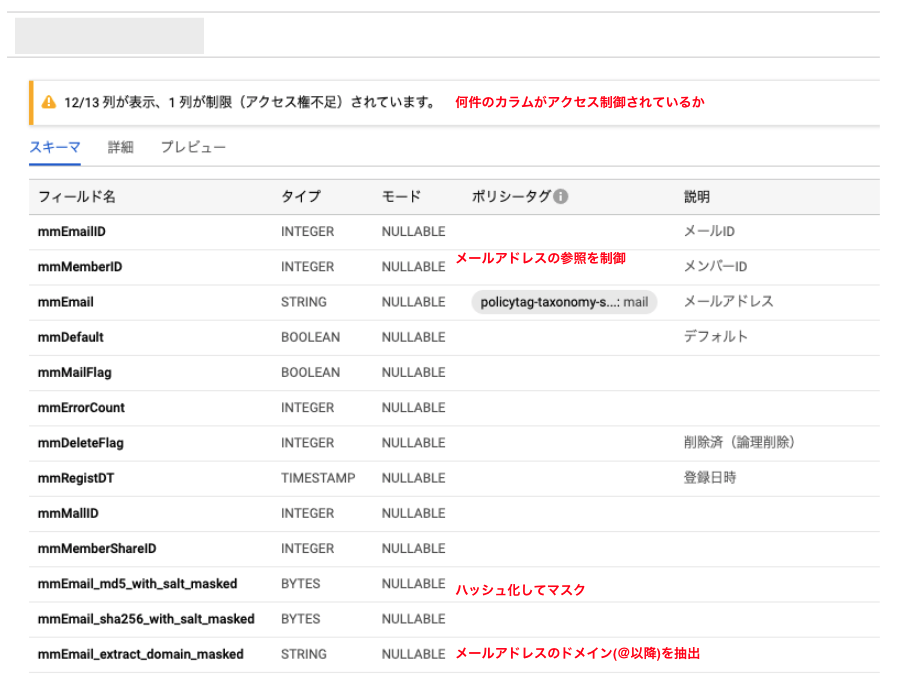
なお、ポリシータグやマスキングしたカラムは、下図のような秘密情報の分類マスタに基づいて付与されます。 秘密情報の分類マスタでは、秘密情報カラムの分類情報「classification」を管理しています。この秘密情報カラムに付与されている分類に基づき、ポリシータグとマスキングしたカラムを追加しています。
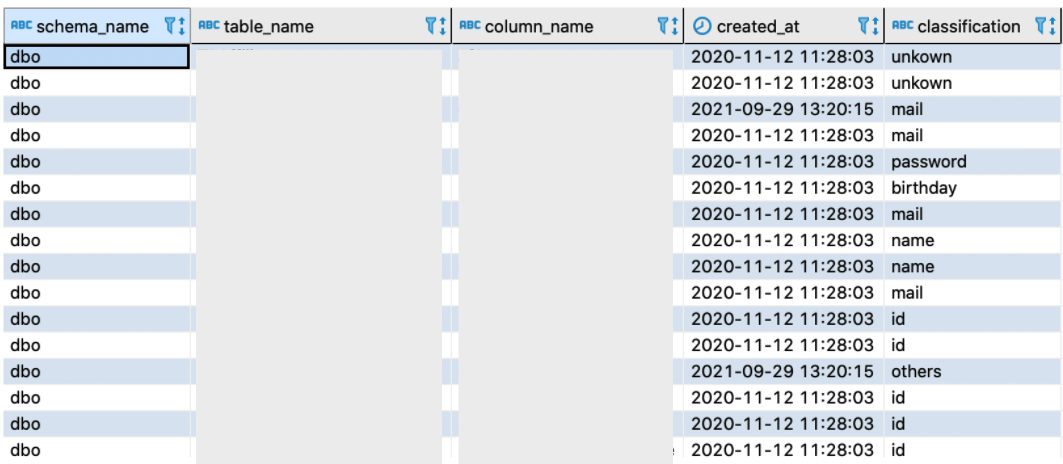
また、マスキングしたカラムは次の命名規則で管理しています。
<カラム名>_<マスキングアルゴリズム>_masked
「mmEmail_sha256_with_salt_masked」は、ソルトを付与したメールアドレスにSHA-256でハッシュ化したカラムです。そして、「mmEmail_extract_domain_masked」は、メールアドレスから@以降のドメインのみを抽出したカラムです。
特別な事情により、どうしても秘密情報が必要な場合を除いては、このマスキングしたカラムを参照します。メルマガ配信など、秘密情報が必須の場合は、対象のポリシータグに権限を付与します。
なお、ポリシータグの権限がないカラムは、前述の通り、以下のように対象のカラムを除外すれば参照できます。
SELECT * EXCEPT(policy-tag-column) FROM TABLE
2つのデータ連携基盤
ポリシータグを活用したデータ連携は、日次で全量転送している日次データ連携基盤と、リアルタイムで差分連携しているリアルタイムデータ連携基盤の2つを運用しています。それぞれ、ポリシータグを付与するタイミングや、マスク処理したカラムを追加する方法が異なります。順に、その違いを紹介します。
日次データ連携基盤
ポリシータグを用いた日次データ連携基盤を紹介します。日次データ連携基盤では、オンプレのSQL ServerにあるテーブルをBigQueryへ全量転送しています。
全体のインフラ構成は以下の通りです。
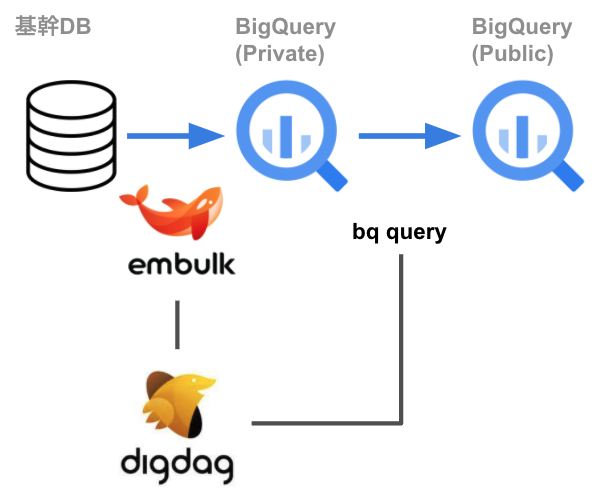
処理の流れを順に説明します。
基幹DBからBigQuery(Private)へのロード
まず、基幹DBに存在するテーブルを、利用者が参照できない非公開のGCPプロジェクトへロードします。これは、Embulkを利用するための工夫です。当初は、SQL ServerのETLツールであるBCPとbqコマンドを用いて、BigQueryへロードしようと考えていました。なぜならば、BCPによるパフォーマンスの改善が見込まれたことと、bqコマンドを使うことでロードのタイミングでポリシータグを付与できると考えたためです。
しかし、SQL Serverのバージョンによる制約やBCPの仕様の問題もあり、この手法によるロードは困難でした。そのため、諸々の煩雑な処理を吸収してくれるEmbulkをETLツールとして採用しました。ところが、Embulkだとポリシータグを付与できない事情があるため、まずは利用者が参照できない非公開環境へロードするようにしています。

Other ways to set a policy tag on a column You can also set policy tags when you: Use bq mk to create a table. Pass in a schema to use for creation of the table. Use bq load to load data to a table. Pass in a schema to use when you load the table. For general schema information, see Specifying a schema.
引用:列にポリシータグを設定するその他の方法 - BigQuery の列レベルのセキュリティによるアクセス制限 | Google Cloud
BigQuery公開環境への書き込み
非公開環境にロードしたテーブルを、利用者が参照できる公開環境に転送します。そして、公開環境へ書き込む際には、ポリシータグを付与します。
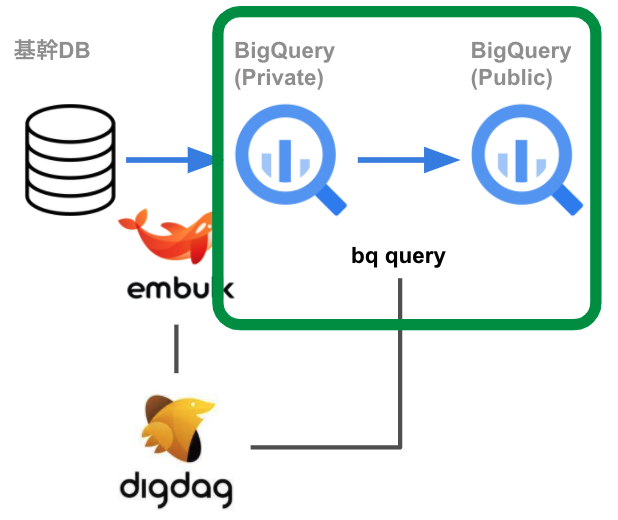
しかし、秘密情報へポリシータグに付与するためには、そのカラムが「どの分類に該当するのか」を判定する必要があります。
その際に、前述の秘密情報の分類マスタを利用します。秘密情報カラムの分類情報「classification」に基づき、ポリシータグとハッシュカラムを追加します。
なお、公開環境への書き込みは「上書きジョブ」で行います。上書きジョブでポリシータグを付与するには、以下のように、スキーマにポリシータグのリソースIDを含める必要があります。
{ "name": "birthday", "type": "TIMESTAMP", "mode": "NULLABLE", "description": null, "policyTags": { "names": [ "projects/<project-id>/locations/us/taxonomies/<taxonomies-id>/policyTags/<policyTags-id>" ] } },
そして、分類に基づいて、分析用にマスキングしたカラムも作ります。弊社の場合、全ての秘密情報にSHA-256でハッシュ化したカラムを追加しています。その他にも、分類に基づいて共通のマスキング処理を施したカラムを追加しています。
例えば、分類が「birthday」の場合は、誕生月で情報を丸めています。分類が「mail」の場合は、メールアドレスからドメインのみ抽出したカラムを追加しています。
[ { "name": "birthday_sha256_with_salt_masked", "type": "BYTES", "mode": "NULLABLE" }, { "name": "birthday_truncate_to_month_masked", "type": "TIMESTAMP", "mode": "NULLABLE" } ]
次に、上書きジョブで利用するクエリを生成します。ポリシータグを付与する秘密情報に加え、分析に必要なマスキング処理を施したカラムを追加するために、以下のようなクエリを生成します。カラムの追加は、非公開環境から公開環境へ書き込む際にBigQueryで実施しています。
SELECT birthday, SHA256(CONCAT("<salt>",CAST(birthday AS STRING))) AS birthday_sha256_with_salt_masked, TIMESTAMP_TRUNC(birthday, MONTH) AS birthday_truncate_to_month_masked FROM <private-gcp-project>.<dataset>.<table>
そして、秘密情報の分類マスタを元に、生成したクエリとスキーマを用いて bq query で公開環境へ上書きします。
日次データ基盤では、上書きジョブで全量更新しているため、後述するリアルタイムデータ基盤のように事前にテーブルを用意する必要はありません。なお、非公開環境から公開環境へ書き込む際に、ポリシータグを付与しています。
#!/bin/bash echo ${BQ_SCHEMA} > schema.json echo ${GCP_CREDENTIAL} > gcp_credential.json gcloud auth activate-service-account --key-file=gcp_credential.json gcloud config set project ${GCP_PROJECT_ID_PUBLIC} bq query --destination_table ${PUBLIC_DATASET}.${PUBLIC_TABLE} \ --use_legacy_sql=false \ --destination_schema=schema.json \ --replace=true --max_rows=0 \ "${QUERY}"
テーブルに対してポリシータグを付与するためには「roles/bigquery.dataOwner」権限が必要です。しかし、非公開環境にあるデータにはポリシータグが付与されていないため、参照時に「Fine-Grained Reader role」は必要ありません。一方、ポリシータグを付与した公開環境のデータを参照するには「Fine-Grained Reader role」が必要です。
なお、我々の場合は、公開環境への書き込み後に日次でスナップショットを取得しているテーブルがあります。コピージョブでスナップショットを取得するため、「Fine-Grained Reader role」権限をサービスアカウントに付与しています。
resource "google_project_iam_binding" "bigquery_data_owner" { role = "roles/bigquery.dataOwner" members = var.zozo_datapool_dataowner }
以上のように、ポリシータグを活用した日次データ基盤では、非公開環境にロードしてから上書きジョブで公開環境へ書き込んでいる点がポイントです。
リアルタイムデータ連携基盤
次に、ポリシータグを用いたリアルタイムデータ基盤を紹介します。リアルタイムデータ基盤では、オンプレ環境のSQL Serverで変更のあったレコードをBigQueryへ書き込んでいます。以前の記事で紹介しているので、併せてご覧ください。その記事の執筆時に比べ、現在ではGKEへの移行と、Kinesisからの参照が追加されています。
全体のインフラ構成は以下の通りです。
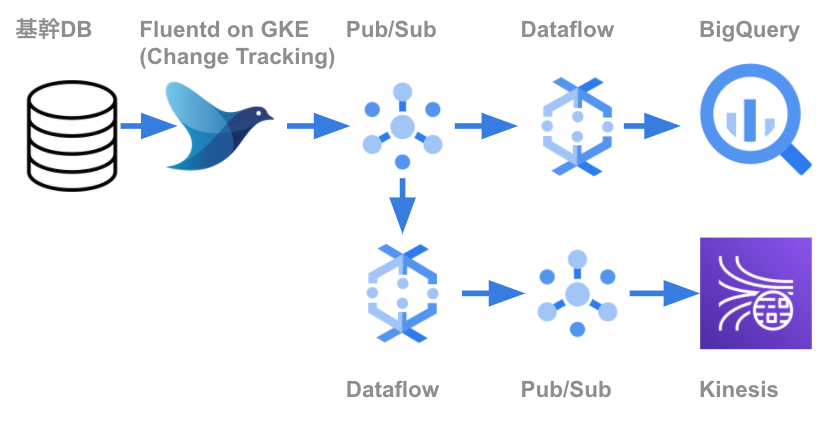
BigQueryロード前にマスクしたカラムを追加
リアルタイムデータ連携基盤は、日次データ連携基盤とは異なり、BigQueryへロードする前にマスキングしたカラムを追加しています。リアルタイムデータ基盤の場合、Cloud Pub/SubやKinesisからも参照されるためです。Fluentdを利用し、元のデータは残したまま、秘密情報をマスキングしたカラムを追加しています。
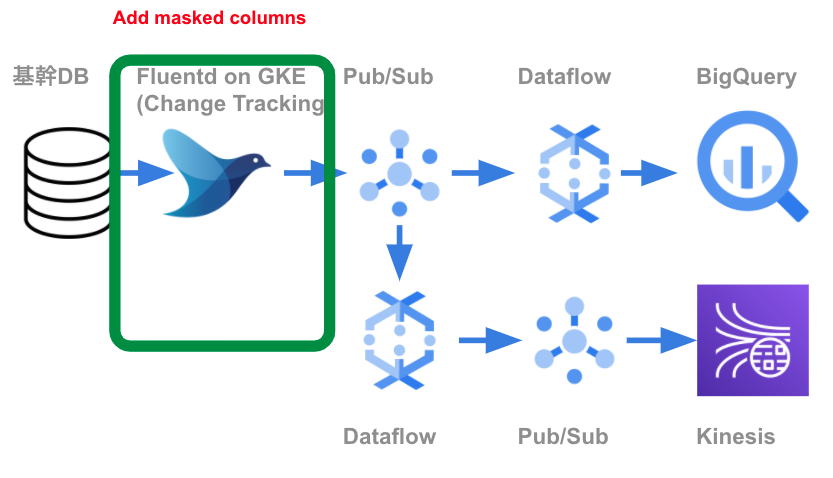
Flunetdの設定ファイルは、秘密情報の分類マスタに基づいて生成します。その際のマスキングカラムの追加は、Flunetdのfilterプラグインを使っています。SQL Serverから取得した差分データに、元データを残したままにし、マスク処理したカラムを追加しています。
<filter <database_name>.<table_name>>
<record>
<column_name>_sha256_with_salt_masked ${require "/usr/src/app/templates/db2bigquery/masked_util.rb";case record['<column_name>'] when nil then record['<column_name>'] else MaskedUtil.to_sha256_with_salt_masked(record['<column_name>']) end }
</record>
</filter>
なお、BigQueryのハッシュ関数とRubyのハッシュ関数は、同じアルゴリズムでも仕様が異なります。そのため、それぞれの仕様を確認の上、実装内容を揃える必要があります。
例えば、SHA-256の場合、BigQueryだとBase64でエンコードされた結果が返ってきますが、Rubyだと16進数の文字列が返ってきます。リアルタイデータ基盤では、BigQueryのハッシュ関数の結果をと一致するようにしています。
-- Note that the result of MD5 is of type BYTES, displayed as a base64-encoded string.
引用:標準 SQL のハッシュ関数 | BigQuery | Google Cloud
data のダイジェストを SHA256 で計算し、16進文字列で返します。
引用:class OpenSSL::Digest::SHA256 (Ruby 3.0.0 リファレンスマニュアル)
また、FluentdからCloud Pub/Subへのメッセージ転送は、outputプラグインを利用しています。Cloud Pub/Subへ送信する際に「attribute_key_values」を使い、秘密情報のカラムを渡しています。そして、渡された秘密情報カラムは、後述するDataflowで秘密情報をDROPするために使われます。
<match database_name>.<table_name>> @type gcloud_pubsub ・・・・ attribute_key_values {"database": "<database_name>", "table": "<table_name>", secret_columns: "column_a,column_b"} ・・・・ </match>
次に、先程触れたDataflowで秘密情報をDROPする処理を紹介します。
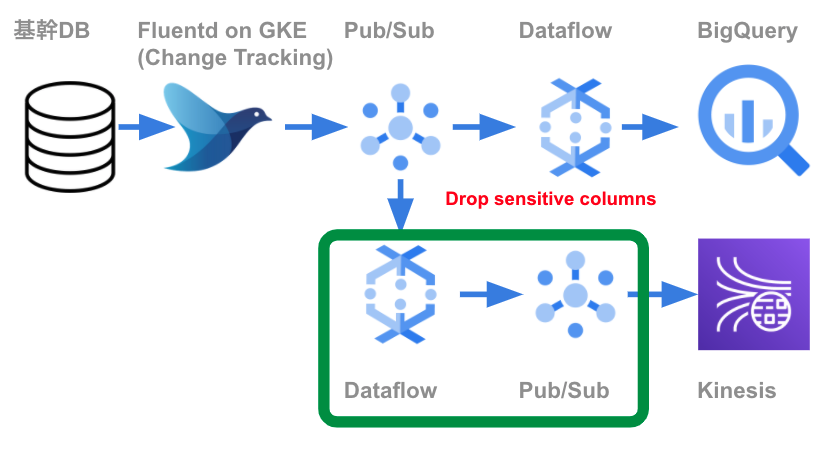
秘密情報をDROPする目的は、Cloud Pub/SubやKinesisから参照する際に、秘密情報を参照できないようにするためです。
そのため、Cloud Pub/SubやKinesisから参照することも考慮し、秘密情報を保持しているCloud Pub/Subと、保持していないCloud Pub/Subの2種類を用意します。秘密情報を保持しているCloud Pub/Subは、BigQueryへの書き込み処理、もしくはCloud Pub/SubやKinesisから秘密情報を参照する必要がある場合に利用します。
以下のようにして「attribute_key_values」から渡された秘密情報を使い、秘密情報をDROPします。
@ProcessElement public void processElement(ProcessContext context) { PubsubMessage message = context.element(); if (message.getAttribute(masked_attribute_key)!= null) { String [] masked_target_columns = message.getAttribute(masked_attribute_key).split(","); if(masked_target_columns.length != 0) { JSONObject jsonObject = new JSONObject(new String(message.getPayload(), StandardCharsets.UTF_8)); for(String s : masked_target_columns) { jsonObject.put(s, masked_event_key_value); } byte[] masked_message_byte = jsonObject.toString().getBytes(StandardCharsets.UTF_8); Map<String, String> attribute = message.getAttributeMap(); message = new PubsubMessage(masked_message_byte, attribute, null); } } context.output(message); }
BigQueryへのストリーミングインサート
秘密情報を残したPub/Subトピックから、BigQueryへ書き込みます。
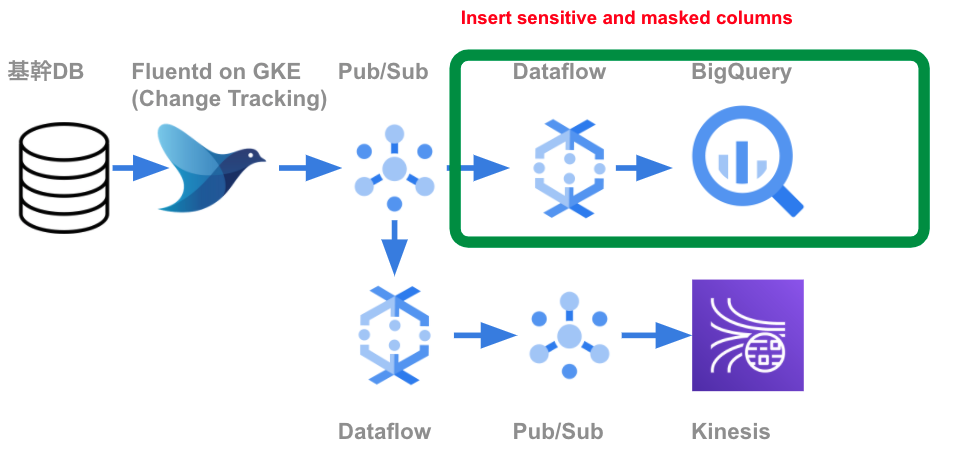
日次データ連携の上書きジョブとは異なり、リアルタイムデータ基盤の書き込みは、既存テーブルへのレコード追加をしています。あらかじめ、Terraformを用いてBigQueryのテーブルを作成します。スキーマには、ポリシータグのリソースIDを付与します。そして、tfファイルは秘密情報の分類マスタに基づいて自動生成しています。
resource "google_bigquery_table" "<dataset_table>" {
dataset_id = "<dataset>"
table_id = "<table>"
time_partitioning {
type = "DAY"
field = "bigquery_insert_time"
}
schema = <<EOF
[
{
"name": "orTel",
"type": "STRING",
"mode": "NULLABLE",
"policyTags": {
"names": [
"${var.policy_tag_tell}"
]
}
},
{
"name": "orTel_sha256_with_salt_masked",
"type": "BYTES",
"mode": "NULLABLE"
}
]
EOF
}
前述の通り、ポリシータグはプロジェクト間で共有できます。現状でも、リアルタイムデータ基盤と日次データ基盤のGCPプロジェクトは分離されていますが、共通のポリシータグを利用しています。具体的には、リアルタイムデータ基盤で、日次データ連携基盤の全量データとリアルタイムデータ基盤の差分データをUNIONしたビューを管理しています。ビューを参照することで、SQL Serverにあるテーブルの最新状態を取得できます。このように共通のポリシータグを利用することで、秘密情報の権限管理がしやすくなります。
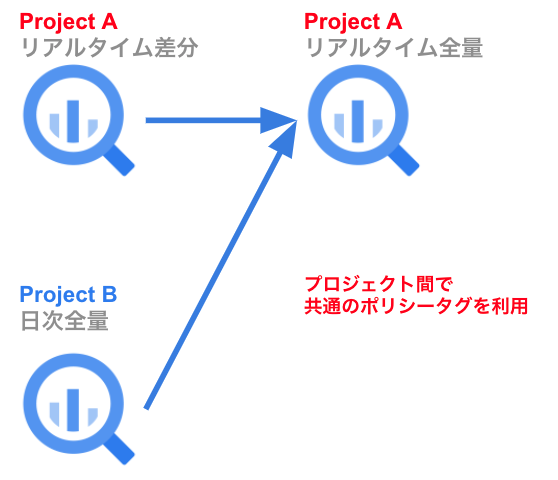
このように、リアルタイムデータ基盤では、BigQueryへロード前にマスキングカラムを追加しています。追加したカラムをCloud Pub/SubやKinesis、BigQueryで参照できるようにしています。リアルタイムデータ基盤の場合、事前にTerraformで秘密情報にポリシータグを付与したテーブルを作り、差分データを既存のテーブルに追加しています。GCPプロジェクトは異なりますが、日次データ基盤、リアルタイムデータ基盤で共通のポリシータグを利用することで権限管理のしやすい環境を構築できます。
ポリシータグ運用の注意点
本章では、ポリシータグ運用における注意点を紹介します。前述のデータ連携は、ここで紹介する注意点を考慮した設計になっています。
カラムの削除・変更時に「ALTER TABLE」が使えない
ポリシータグを付与しているテーブルのカラムの変更や削除は、やや煩雑です。ポリシータグを付与しているテーブルは「ALTER TABLE」でカラムを削除できない制約があります。
カラムの削除や変更をする際には、以下のように「ALTER TABLE」を使うことが一般的です。ポリシータグを付与していないテーブルであれば、以下のクエリでカラムの削除ができます。
ALTER TABLE <project>.<dataset>.<table> DROP COLUMN IF EXISTS <column>
引用:ALTER TABLE DROP COLUMN statement
一方、ポリシータグを付与しているテーブルは、ポリシータグを付与していないカラムでも、以下のようなエラーが発生して削除できません。
Alpha category references are no longer a supported type, please use policy tags instead: ''
なお、スキーマ変更はポリシータグを付与していても利用できます。しかし、「ALTER TABLE」でスキーマ変更ができるのは限定的です。詳細はドキュメントをご確認ください。
ALTER TABLE <project>.<dataset>.<table> ALTER COLUMN IF EXISTS <column_name> SET DATA TYPE <data_type>
引用:ALTER COLUMN SET DATA TYPE ステートメント - 標準 SQL のデータ定義言語(DDL)ステートメント | BigQuery | Google Cloud
そのため、スキーマの変更や削除をする場合には、基本的にはクエリを使った上書きにする必要があります。単純な上書きジョブであれば、さほど手間はかかりません。日次連携のような上書きジョブで書き込む際には、スキーマも更新されます。リアルタイムデータ基盤の場合、既存のテーブルにレコードを常時追加しています。そのため、BigQueryへの書き込みを止め、以下のようなクエリでテーブルのスキーマを変更すれば対応可能です。
SELECT CAST(column AS STRING) column FROM table
しかし、ポリシータグを付与している場合、単純な上書きジョブでは参照したテーブルのポリシータグを引き継げません。ポリシータグのリソースIDを含んだスキーマを指定しないと、参照元のテーブルでポリシータグが付与されていても引き継げない仕様です。カラムの削除や変更をする場合、スキーマを生成し、生成したスキーマを使い、上書きジョブを実行する必要があります。
なお、手動運用だと運用コストが大きくなるため、自動化することをお勧めします。そして、スキーマを指定しないとポリシータグが外れ、秘密情報が閲覧可能な状況になってしまうので注意が必要です。
テーブルにマスキングしたカラムが必要
ポリシータグを利用する場合、テーブルにマスキングしたカラムを追加する必要があります。一見すると、ポリシータグとあまり関係なさそうですが、ポリシータグの仕様を考慮すると必要になります。
我々の場合、基本的には秘密情報の参照権限は付与していません。秘密情報をマスキングしたカラムを参照してもらうことで、ほとんどの場合に要件を満たせるためです。誕生月を丸めたり、メールアドレスからドメインのみ抽出したり、身長・体重の異常値を丸めたりしています。

承認済みビューを使う場合、このようなマスキングしたカラムはビュー内に作れるので、わざわざBigQueryにカラムを追加する必要はありません。
一方、ポリシータグの場合は、テーブルに対してマスク処理したカラムを追加する必要があります。承認済みビューであれば、元テーブルへのアクセス権限がなくても参照できますが、元テーブルにポリシータグを付与している場合、ポリシータグの権限がなければ承認済みビューを使っても秘密情報は参照できません。これらの関係は、下図のようにまとめられます。
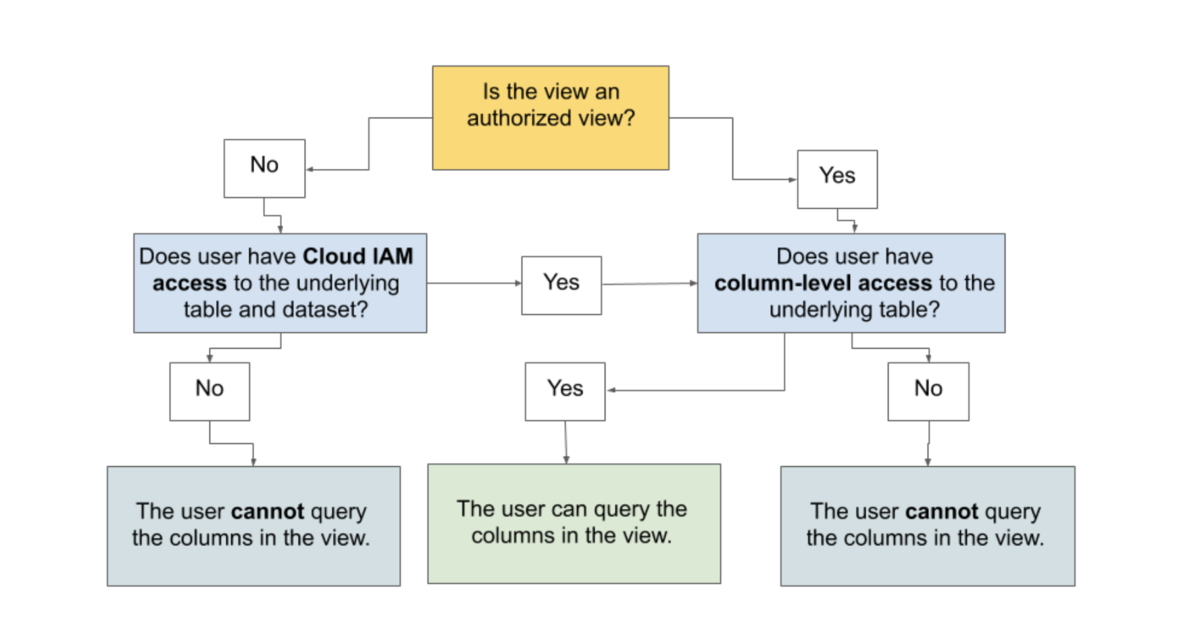
引用:ビューのクエリ - BigQuery の列レベルのセキュリティの概要 | Google Cloud
ポリシータグを使う場合、分析に使うマスキングしたカラムは、元のテーブルに追加する必要があります。我々の場合、リアルタイムデータ基盤でPub/SubやKinesisからマスクしたカラムを参照する必要がありました。また、マスク処理したカラムをBigQuery以外からも参照しているため、どちらにしろテーブルに対して付与する必要がありました。このように、テーブルにマスキングしたカラムを追加する前提で連携方法を考える必要があります。ポリシータグの参照権限を持たない利用者が、承認済みビューでマスキングしているカラムを参照できないので注意が必要です。
秘密情報の管理を分類マスタで行う
前述の通り、ポリシータグは以下のような秘密情報の分類マスタに基づいて付与しています。
この分類マスタが正しくなければ、適切なポリシータグを付与できません。
過去に、秘密情報の分類マスタにあるカラムが、オンプレ環境のSQL Server内のカラムと表記ずれを起こしていたことがありました。表記がずれていたため、秘密情報の判定時にマッチせず、「秘密情報なのにポリシータグが付与されない」状況が発生していました。このような状況が再発しないよう、秘密情報の分類マスタに表記揺れがないか、カラム名が一致してるかを検知できる仕組みを導入しました。
また、「正しい分類」が秘密情報の分類マスタでされていることも重要です。誤った分類が付与されていると、その間違った分類に基づいたポリシータグが付与されてしまいます。その結果、分類に基づいて追加されるマスク処理したカラムも間違った状態になってしまいます。
ポリシータグを運用する上で、秘密情報の分類マスタの管理は非常に重要です。間違っていると秘密情報なのにポリシータグが付与されていない状態になるため、本記事で紹介してきた施策の努力も無駄になってしまいます。
まとめ
本記事では、ポリシータグの活用事例や運用における注意点を紹介しました。実際に運用してみると、秘密情報の権限管理や分類マスタに基づいたマスクカラムの追加など、かなり柔軟に対応できるようになりました。同じように、BigQueryの秘密情報の管理方法を検討されている方の参考になれば幸いです。
本記事を読んで、もしご興味をもたれた方は、是非採用ページからご応募ください。