



こんにちは、データ基盤の開発、運用をしていた谷口(case-k)です。最近は配信基盤の開発と運用をしています。
ZOZOではオンプレやクラウドにあるデータをBigQueryへ連携し、分析やシステムで活用しています。BigQueryに連携されたテーブルは共通データ基盤として全社的に利用されています。
共通データ基盤は随分前に作られたこともあり、様々な負債を抱えていました。負債を解消しようにも利用者が約300人以上おり、影響範囲が大きく改善したくても改善できずにいました。
本記事では旧データ基盤の課題や新データ基盤の紹介に加え、どのようにリプレイスを進めたかご紹介します。同じような課題を抱えている方や新しくデータ基盤を作ろうとしている方の参考になると嬉しいです。
データ基盤の紹介
冒頭でご紹介したとおり、ZOZOではオンプレのSQL ServerにあるテーブルをBigQueryに連携して利用しています。
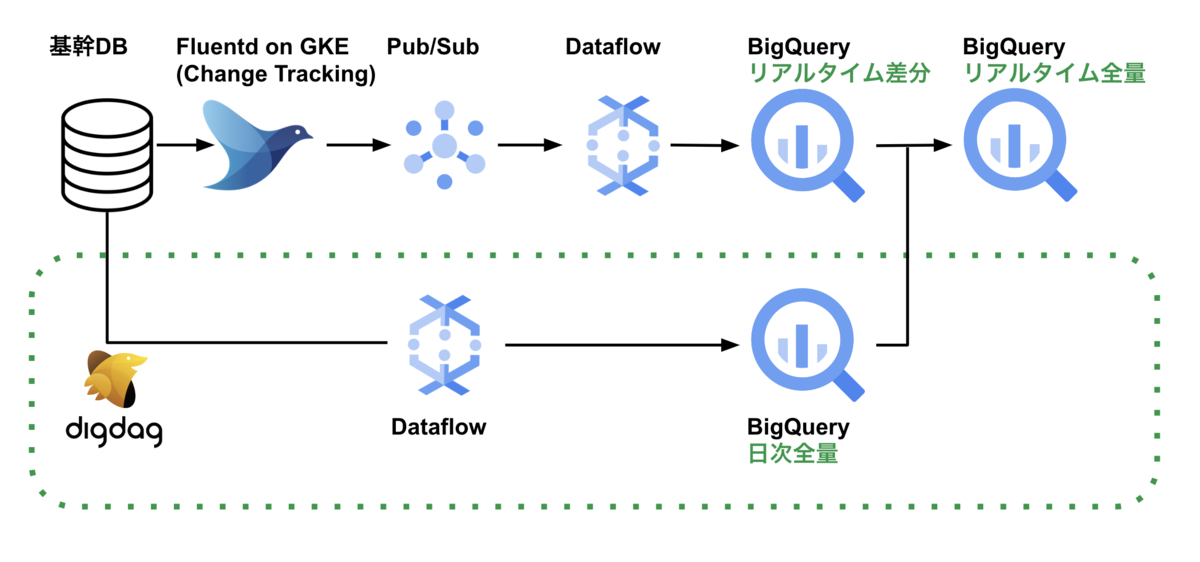
データ基盤は大きく分けて2種類あり、日次でデータ連携してるものとリアルタイムにデータ連携しているものがあります。日次データ基盤ではSQL Serverの全量データを転送しています。リアルタイムデータ基盤ではSQL Serverで変更のあった差分データをBigQueryへ連携しています。

日次の全量データとリアルタイムな差分データを組み合わせることで、リアルタイムにBigQuery上でSQL Serverのテーブルの状態を再現できます。今回はこれらのうち日次データ基盤(以下、旧データ基盤と呼びます)をリプレイスした事例をご紹介します。
リアルタイムタイムデータ基盤については以前書いた以下の記事をご確認ください。オンプレDWHの移行に伴い連携するテーブルが増えたため、現在はGKE上で運用しています。
旧データ基盤の紹介
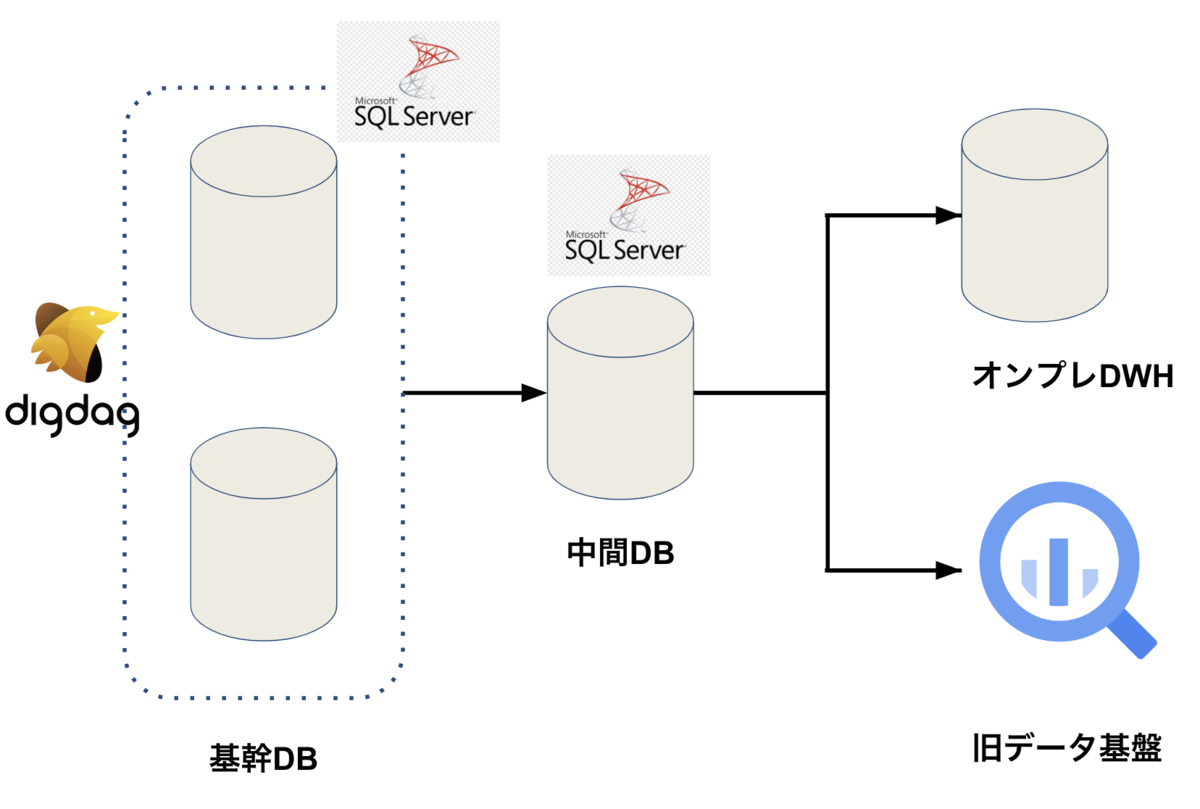
リプレイス対象の旧データ基盤についてご紹介します。旧データ基盤では中間DBをハブとして多段に連携していました。まず、オンプレの基幹DB(SQL Server)で管理されているテーブルを中間DB(SQL Server)に書き込みます。次に、中間DBをハブとしてBigQueryに書き込みます。

実はBigQueryの他にもう1つのオンプレDWHにも中間DBからテーブルを連携していました。このオンプレDWHは配信チーム(MA:マーケティングオートメーション)で管理しているDWHになります。配信系の処理など一部のサービスではオンプレのDWHを活用していました。
テーブルの連携処理はAWS上にあるDigdag(ワークフローエンジン)とEmbulk(ETLツール)を用いていました。
現在はオンプレDWHと旧データ基盤は廃止済みです。オンプレDWHの廃止の詳細は以下の記事をご確認ください。
旧データ基盤の課題
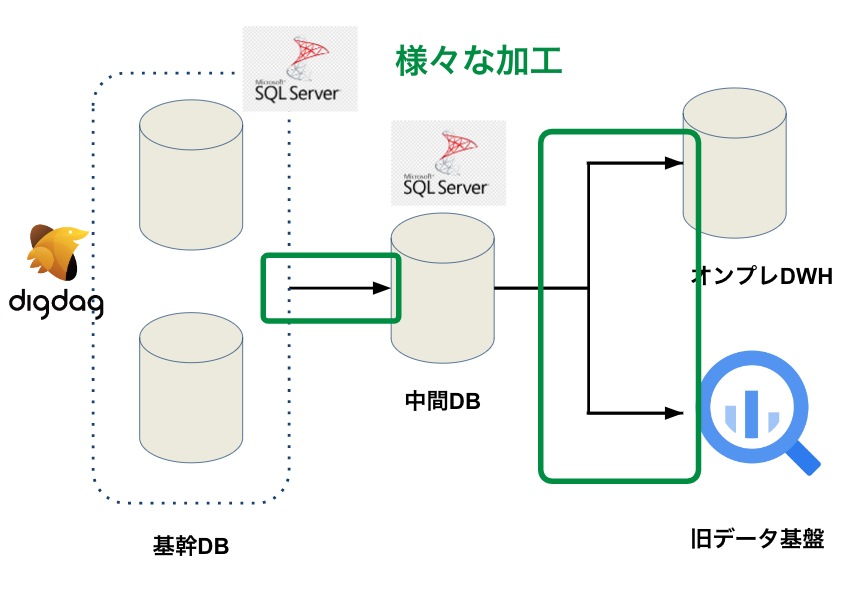
ここからは旧データ基盤の課題をご紹介します。以下の図にあるように旧データ基盤では基幹DBから中間DB、中間DBからDWHに連携するまでに様々な加工処理を施していました。具体的にどのような加工処理を施していたのか、運用上どのような課題があったのかご紹介します。
変更があっても更新されないデータ
旧データ基盤では以下の図にあるようなテーブルの更新タイムスタンプを使った差分連携を採用していました。

タイムスタンプを用いて変更のあった差分データに絞ることで、サイズの大きいテーブルでも低コストで高速に連携できます。しかし、実際に運用してみると、テーブルに変更があっても更新タイムスタンプが適切に更新されないケースがありました。そのため、基幹のテーブルに更新があってもクエリの条件に合致せず、変更のあったデータがBigQueryに反映されませんでした。
また、基幹テーブルのレコードが物理削除された場合削除されたデータを取得できません。それゆえ、基幹DBで削除されたデータがBigQueryから削除されずに残り続けていました。その他にも物理削除されたデータを残す連携など様々な加工処理を施していました。 そのため、BigQueryにあるデータが基幹テーブルのコピーになっておらず、データ不整合が発生していました。
性質の異なるテーブルを同じ命名規則で管理
1つのデータセットで、性質の異なるテーブルを同じ命名規則で管理していました。
例えば日付サフィックスをつけるテーブルがあります。
<テーブル名>_yyyymmdd
この命名のテーブルを見たユーザは、全てのテーブルが同じ性質と考えてしまいます。例えば、最初に日付サフィックスの付いたテーブルが日次の全量スナップショットと認識したら、他のテーブルも同様と考えるでしょう。しかし実際には以下3種類の異なる性質のテーブルになっていました。
- 日次の全量スナップショット
- 日次の差分テーブル
- 日次の物理削除データを含むテーブル
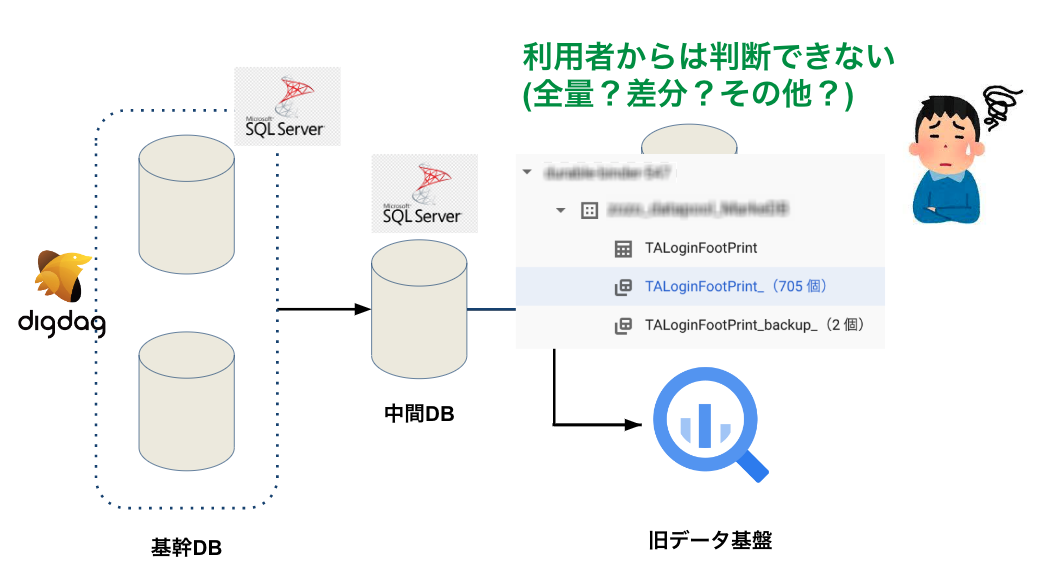
このように、1つのデータセット内で異なる性質のテーブルを同じ命名規則で管理していたため、利用者を混乱させていました。
秘密情報の判断が手動
旧データ基盤では秘密情報の判断を手動でしていました。秘密情報は秘密情報の管理表で管理されています。利用者がテーブルの追加を依頼する際に秘密情報の管理表を確認し、データ基盤の管理者側でも秘密情報がないか確認する運用です。旧データ基盤では秘密情報はBigQueryに入れない運用をとっていたので、秘密情報の場合はマスク処理を施してBigQueryで管理していました。
ただし、利用者の申請ベースの運用だったので、店舗の電話番号など秘密情報ではないのにマスク処理が施されている場合もありました。これまで幸い問題は発生していませんでしたが、人間任せだと誤って秘密情報を漏洩させてしまう懸念がありました。
テーブルの取得元が不適切
基幹DBにはマスタテーブル以外にもレプリされたテーブルがあります。レプリされたテーブルは同じ名前で異なるデータベース内に管理されています。
BigQueryへ連携する際に基幹DBのどのデータベースから連携するか決める必要があります。これまで、テーブルの取得元DBは利用者がテーブルの追加を依頼する際に指定する運用をとっていました。その結果、テーブルの取得元としてマスタDBとレプリDB両方から連携されていました。
冒頭で述べたようにZOZOではリアルタイムデータ基盤も運用しています。リアルタイムデータ基盤では鮮度の高いデータを取得できるようマスタDBから変更のあったデータをBigQueryに連携しています。
リアルタイムデータ基盤ではリアルタイムな差分データと日次の全量データを組み合わせることで、基幹テーブルの最新の状態を作りだしています。旧データ基盤の取得元が不適切だとリアルタイムデータ基盤と旧データ基盤(日次全量)で参照元のDBが異なり、不整合が発生してしまいます。

テーブル追加の依頼者もこうした事情を把握していないため、取得元は不適切になりがちでカオスな状態となっていました。
新データ基盤の紹介
このように様々な辛みがあったので、データ基盤をリプレイスしました。
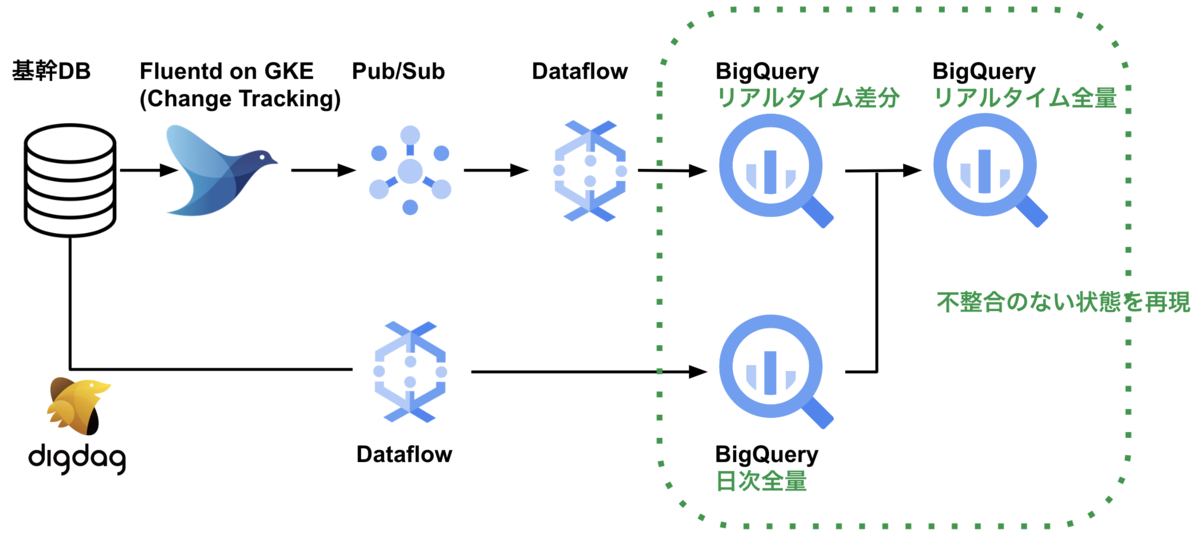
新データ基盤は以下のような構成になっています。緑の点線部分が今回リプレイスした箇所になります。日次の全量データが正しいデータになったので、リアルタイムデータとマージした全量データも正しいデータにできました。ここからは新データ基盤をご紹介します。
データレイクの構築
新データ基盤ではBigQuery上にデータレイクを構築しています。旧データ基盤にあった特定の用途に特化した加工処理は全て廃止し、全量転送しています。無加工のデータレイクを用意し、特定の用途に特化した処理はデータマートで対応するようにしました。

データセットを分けて管理
新データ基盤では取得元DBとテーブルの性質を考慮して、データセットを分けて管理しています。
旧データ基盤では取得元DBや性質の異なるテーブルを全て1つのデータセットで管理していたため、利用者の混乱を招いていました。そこで、新データ基盤ではBigQueryのデータセットを以下のような命名規則にすることで対応しました。
<データベース名>_<性質>
以下の図にあるデータセット名で取得元DBとデータの性質を考慮して、データセットを分けています。例えば取得元DBが「zozob」の日次全量テーブルは「zozob_daily」、リアルタイム全量テーブルは「zozob_realtime」となっています。

秘密情報を適切に管理
新データ基盤では秘密情報の分類マスタに基づいて、秘密情報の判断を自動化しています。方法としては、分類マスタに基づいた適切なポリシータグと秘密情報のマスクカラムの追加によって実現しています。これによって、手動での秘密情報の判断が不要になりました。
新データ基盤ではメルマガ配信等どうしても秘密情報が必要な案件にも対応できるよう、秘密情報をBigQueryにいれています。自動化したことで安全に秘密情報を管理できるようになりました。
詳細は以下の記事にまとめたのでご確認ください。
適切なDBからテーブルを連携する
新データ基盤では取得元DBの判定処理を自動化しています。
基幹DBの管理チームと連携し、判定に必要なマスタ情報を用意しました。判定に必要なマスタ情報を用いることで、適切な取得元DBをクエリを用いて自動で判定できるようにしました。利用者がテーブルを追加する際に取得元DBを指定する運用をやめたことで、誤って意図しない中身のテーブルを用いて分析することを防げるようになりました。
AWSにあったETLをGCPに移行
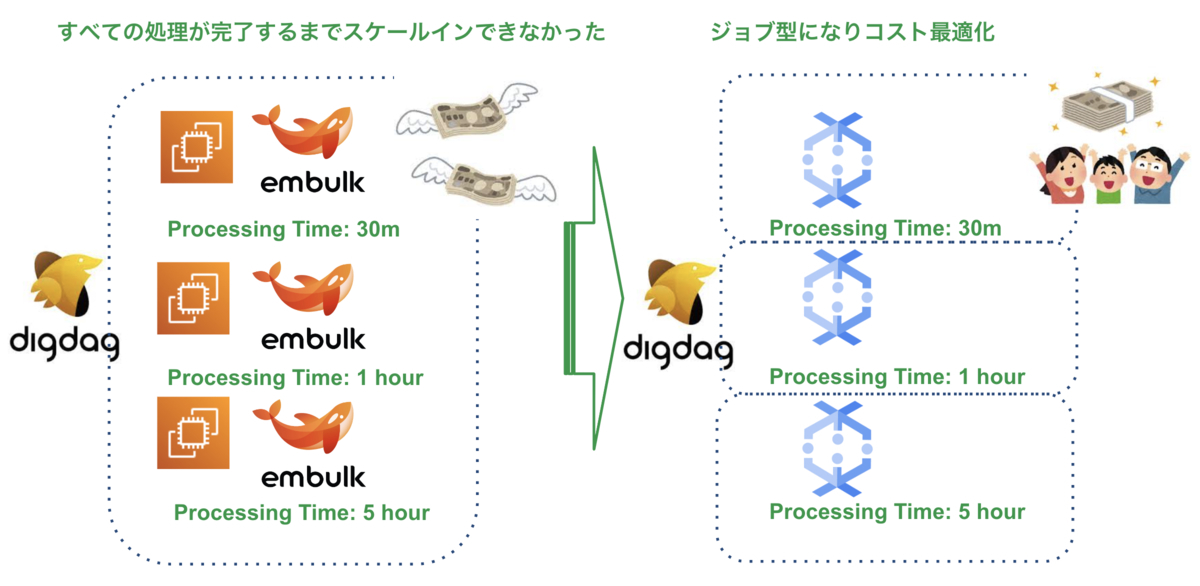
新データ基盤ではAWSにあったETLをGCPに移行しています。当時RedshiftをDWHとして使っていた名残で、AWS上に構築された環境を使いデータ連携を実施していました。今回のリプレイスでAWSにあったETLをGCPに移行しました。ETLツールにはGCPが提供するDataflowを採用しました。Dataflowは負荷に応じてオートスケールしてくれるため、データ連携に必要なコストとパフォーマンスを最適にできます。
旧データ基盤ではバッチ連携前にDigdagのワーカ(EC2)を増やし、Embulkを用いてテーブルを連携していました。この仕組みの問題点として、全てのテーブル連携が完了するまでワーカをスケールインできませんでした。
旧データ基盤は差分連携により、転送するデータ量が少なかったため大きな問題はありませんでしたが、全量転送にしたことで新データ基盤ではコストが飛躍的にあがりました。旧データ基盤と同じ方法で全量転送するようにした場合、Dataflowを使うよりも月間で数百万、年間だと数千万以上のコスト増となってしまいました。
Dataflowを用いることで、ワーカのスケールアウトが不要になり、約85%のコスト削減に繋がりました。コストパフォーマンスの評価は後述しています。
ワークフロー設計
続いてDatafowを前提にしたワークフロー設計についてご紹介します。全体の処理の流れは以下の通りです。
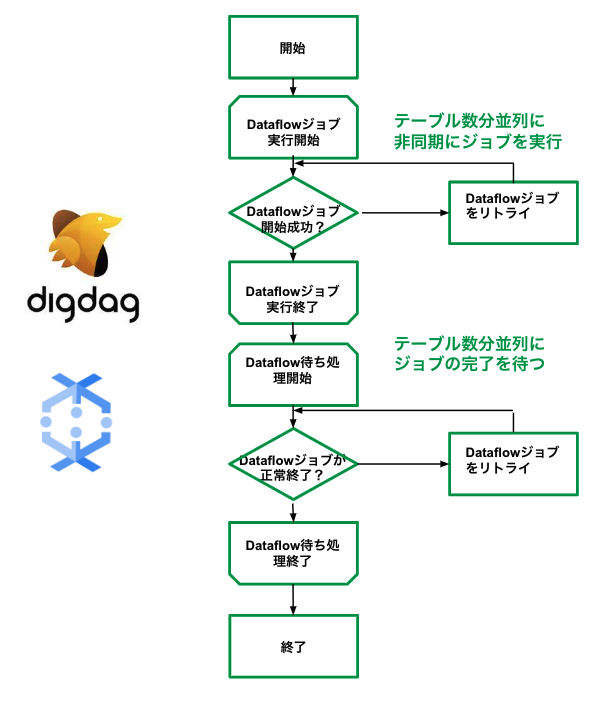
Dataflowを採用したことでパフォーマンス最適化されるようワークフローを改善しました。Dataflowにしたことで、非同期ジョブでのテーブル連携が可能となりました。まず、Digdagで連携対象のテーブル数分並列にDataflowジョブを非同期に実行します。全てのテーブル数分Dataflowジョブを実行した後、後続のタスクでDataflowジョブが失敗していないか以下のように待ち処理を入れています。
def jdbc_to_bigquery_wait(self): project_id_public = workflow_repository.WorkflowRepository().find(key='GCP_PROJECT_ID_PUBLIC') project_id_private = workflow_repository.WorkflowRepository().find(key='GCP_PROJECT_ID_PRIVATE') project_id_private_bucket = workflow_repository.WorkflowRepository().find(key='GCP_BUCKET_NAME') region = workflow_repository.WorkflowRepository().find(key='DATAFLOW_REGION') worker_service_account = workflow_repository.WorkflowRepository().find(key='DATAFLOW_WORKER_SERVICE_ACCOUNT') database = workflow_repository.WorkflowRepository().find(key='DATABASE') table_name = workflow_repository.WorkflowRepository().find(key='IMPORT_TABLE_NAME') local_path = f'job-id-{database}-{table_name}.txt' gcs_path = f'job-id/{database}/{table_name}.txt' job_id = gcp_gcs_repository.GcpGcsRepository(project_id_private,project_id_private_bucket).read_from_gcs(local_path=local_path,gcs_path=gcs_path).replace('"', '') dataflow_job = deploy_dataflow_job.DeployDataflowJob(project_id_public, region, worker_service_account) state, message = dataflow_job.wait_dataflow_job(job_id) if state == False: time.sleep(60) self.jdbc_to_bigquery_wait_until_finish()
ジョブが失敗した場合、テーブル単位で同期的にリトライができるようワークフローを設計しています。以下のように同期的なリトライにすることでジョブが失敗したテーブルのみリトライできるようになります。
def jdbc_to_bigquery_wait_until_finish(self): project_id_public = workflow_repository.WorkflowRepository().find(key='GCP_PROJECT_ID_PUBLIC') region = workflow_repository.WorkflowRepository().find(key='DATAFLOW_REGION') worker_service_account = workflow_repository.WorkflowRepository().find(key='DATAFLOW_WORKER_SERVICE_ACCOUNT') dataflow_job = deploy_dataflow_job.DeployDataflowJob(project_id_public, region, worker_service_account) job_id = self.jdbc_to_bigquery() state, message = dataflow_job.wait_dataflow_job(job_id) if state == False: raise Exception(f'{message}')
コストとパフォーマンスの評価(Embulk vs Dataflow)
Dataflowに移行するにあたり、EmbulkとDataflowでコストや、パフォーマンスを比較評価しました。
Dataflowの方が負荷に応じてオートスケールするため、Embulkより高速に連携できると想定していました。しかし、調査したところEmbulkの方がパフォーマンス面では優れていました。
Dataflowのパイプラインを確認したところ、データの読み込みで時間がかかっていることがわかりました。どうやらJDBCを用いてRDBからデータを取得する際は分散処理ができないようでした。データ取得後の後続処理では分散処理が可能でした。一方Embulkでは、データ読み込みから連携までCPUを複数コア活用できていました。
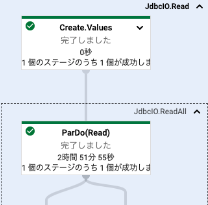
比較ではEmbulkの方がパフォーマンス優位だったものの、Dataflowでもパフォーマンス要件は満たせていたので、コスト最適化できるDataflowを採用しました。
また、Embulkを採用する場合は、テーブルによっては10倍以上のディスク容量が必要になることもわかりました。RDBからとってきたデータをJSONでダンプするため、70GBのテーブルだと700GBまで膨れあがります。ディスク容量が枯渇すると転送処理が失敗します。詳細は以下のissueをご確認ください。
私たちの場合はDataflowでも要件を満たせたのでDataflowを採用しましたが、ETLツールを利用する際は参考にしてみてください。
Dataflowにしたことで、データ連携前にDigdagワーカのスケールアウトも不要になりました。ワーカのスケールアウトは大きな障害ポイントだったので運用負荷も軽減されました。
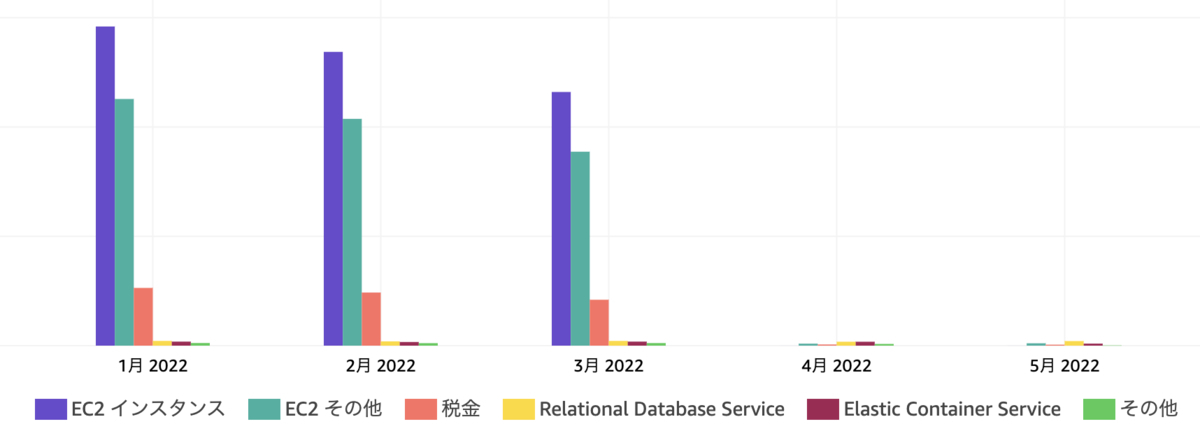
費用対効果は大きく、年間で数千万以上のコスト削減にも繋がりました。以下の図から4月以降大幅にコスト削減されたことが分かります。
Dataflow導入Tips
次にDataflow導入Tipsをご紹介できればと思います。同じようにDataflowの採用を検討してる方の参考になると幸いです。
DataflowのQuotas
私たちの場合連携するテーブルが多かったため、GCP側でDataflowのQuotasを引き上げてもらう必要がありました。DataflowのQuotasと必要な対応をご紹介します。
Dataflow同時実行ジョブ数
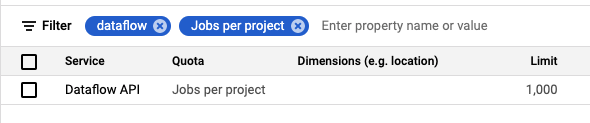
Dataflowの同時実行ジョブ数はデフォルトだとプロジェクトあたり25になっています。連携対象のテーブルは600テーブルほどあったので、今後のことも考え上限を1000に上げてもらいました。サポートケースを起票し用途を伝えれば引き上げてもらえます。引き上げてもらったQuotasはGCPコンソールの「IAM & admin」から「Quotas page」より確認できます。
Compute Engine
DataflowはCompute Engine上で動くため、Compute EngineのQuotasも引き上げる必要があります。ゾーンのN2_CPUSの上限は200だったので2000に引き上げました。この制限は「IAM & admin」から「Quotas page」よりすぐ引き上げられました。
2022-03-06 02:16:04.440 JSTStartup of the worker pool in zone asia-northeast1-b failed to bring up any of the desired 1 workers. QUOTA_EXCEEDED: Instance 'jdbc-to-bigquery-zozoold--03050914-6bui-harness-dvc9' creation failed: Quota 'N2_CPUS' exceeded. Limit: 200.0 in region asia-northeast1.

Dataflowの開発言語
DataflowはJava、Python、Goをサポートしています。私たちはJavaを選びました。Python版を検証をしたところ、クエリの上書きができなかったり、余計な通信が走ったりとまだ本番で利用するには不十分だったからです。
詳しくは以下の記事にまとめました。
Java版はGCPでテンプレートを提供してくれています。しかし、テーブルの上書き(WRITE_TRUNCATE)ができず、タイムスタンプの加工処理が誤っていました。MySQLなど特定のデータソースに特化した加工処理も含まれていたので、カスタムテンプレートを作成しました。
https://github.com/GoogleCloudPlatform/DataflowTemplates/blob/main/src/main/java/com/google/cloud/teleport/templates/JdbcToBigQuery.java#L105github.com github.com
以下のようなDataflowのパイプラインを作り、SQL ServerやMySQLからデータを連携しています。
pipeline
.apply(JdbcIO.<TableRow>read()
.withDataSourceConfiguration(
JdbcIO.DataSourceConfiguration.create(driver_class_name, jdbc_url)
.withUsername(username)
.withPassword(password)
)
.withQuery(query)
.withCoder(TableRowJsonCoder.of())
.withRowMapper(new ResultSetToTableRow(options.getTimezone())))
新しく追加されたカラム等反映できるよう、BigQueryのテーブルを上書きする場合はスキーマ情報が必要です。Digdagでデータ連携する際、対象テーブルのスキーマ情報を取得し、GCSにアップロードしています。GCSにアップロードされたテーブルのスキーマ情報を用いて、書き込み先のテーブルを全量置換しています。
.apply(
"Write to BigQuery",
BigQueryIO.writeTableRows()
.withoutValidation()
.withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)
.withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_TRUNCATE)
.withCustomGcsTempLocation(options.getBigQueryLoadingTemporaryDirectory())
.withSchema(
NestedValueProvider.of(
options.getSchema(),
new SerializableFunction<String, TableSchema>() {
@Override
public TableSchema apply(String jsonPath) {
TableSchema tableSchema = new TableSchema();
List<TableFieldSchema> fields = new ArrayList<>();
SchemaParser schemaParser = new SchemaParser();
try {
JSONArray bqSchemaJsonArray = schemaParser.parseSchema(jsonPath);
for (int i = 0; i < bqSchemaJsonArray.length(); i++) {
JSONObject inputField = bqSchemaJsonArray.getJSONObject(i);
TableFieldSchema field =
new TableFieldSchema()
.setName(inputField.getString(NAME))
.setType(inputField.getString(TYPE));
if (inputField.has(MODE)) {
field.setMode(inputField.getString(MODE));
}
fields.add(field);
}
tableSchema.setFields(fields);
} catch (Exception e) {
throw new RuntimeException(e);
}
return tableSchema;
}
}))
.to(options.getOutputTable()));
pipeline.run();
}
データ基盤のさらなる発展と機能拡充
日次連携データが正しいデータになったことで、依存関係のあったリアルタイムデータ基盤も正しい状態を作り出せるようになりました。データを整備したことで、AI等様々なデータを活用した分野で活用できます。
リアルタイムデータ基盤の差分データと日次の全量データを組み合わせたタイムトラベル機能もその1つです。正しいデータ扱えるようになったことで、特定時刻のテーブルを再現できるようになりました。
詳しくは以下の記事にあるのでご確認ください。
旧データ基盤からのお引っ越し
新データ基盤の構築後はお引っ越しです。利用者に旧データ基盤を参照しているクエリを安全に書き換えてもらう必要があります。
旧データ基盤と新データ基盤で差分があまりないなら大きな問題にはなりません。しかし、数億件以上のレコードの乖離がある場合もあるため、注意が必要です。
安全に移行を進めるため、関係者と協力し、新旧データ基盤の差分や移行先をまとめたテーブル対応表を作りました。新旧テーブル対応表を作成したのち、複数回に分けて利用者に周知しました。
どのように引越し作業を進めたかご紹介できればと思います。
関係者と協力して新旧テーブル対応表を作成
クエリの書き換えをしてもらうために、利用者を特定し、新旧テーブルの差分をまとめた移行対応表を作成します。クエリを1ファイルずつ確認しながら差分を調べるなかなか泥臭いところです。
新旧テーブル対応表の作成するために、様々なチームとの協力が必要でした。各チームと協力し、最終的には以下のような新旧テーブル対応表を作り、利用者に展開しました。各チームとの取り組みについてご紹介します。

配信チーム(オンプレDWH管理)
まずはオンプレDWHを廃止するため、オンプレのDWHを管理する配信チームと協力して移行を進めました。
元々配信チームとデータ基盤は同じチームだったこともあり、ワークフローが混在している状態でした。例えばオンプレDWHにあるデータマートの更新処理を両チームのワークフローから実施していました。
配信チームと持ち物を整理し、利用者とも相談しながら、移行に必要な機能や仕組みを作りました。先行してオンプレDWHの移行を進めたので、このフェーズで新データ基盤に必要な機能は一通り揃いました。

オンプレのDWHの移行の詳細は以下の記事をご確認ください。
データ分析チーム
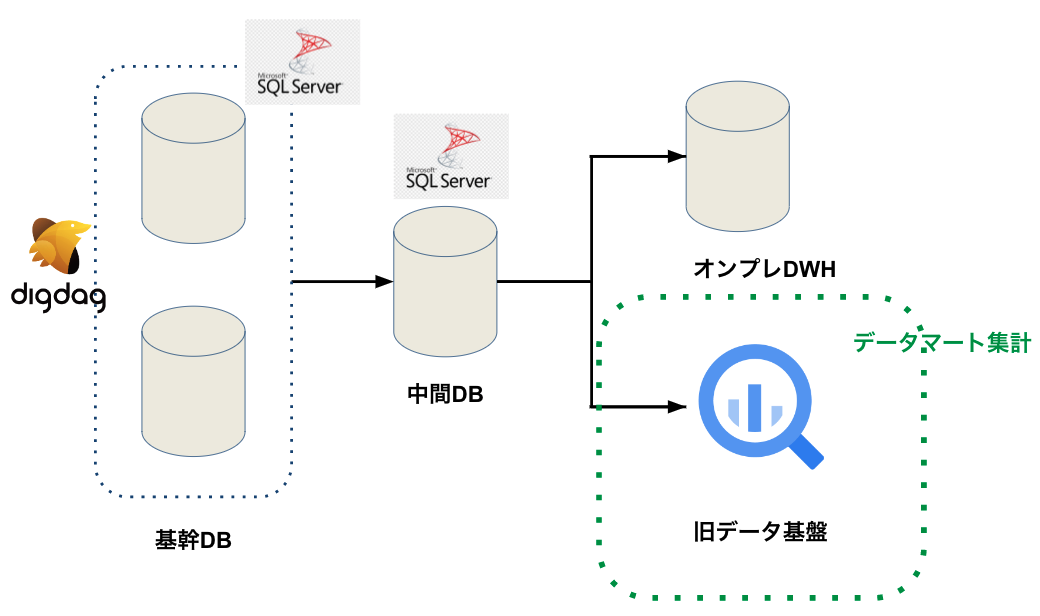
次にデータ分析チームです。データ分析チームでは旧データ基盤のテーブルを使い、データ分析やデータ分析に必要なデータマートを作成していました。
データマートはデータ分析チーム以外に事業部でも作られていました。データマートを構築するために参照してるテーブル先が変わるため、クエリの書き換えが必要になります。ビジネスサイドとも連携が必要なので、移行に伴うビジネスサイド側のディレクションはデータ分析チームに実施してもらいました。
データ分析チームとの定例は新データ基盤への移行完了後も継続して実施しています。これまでデータ分析チームの要望をヒアリングする機会がなかったので良い機会となりました。
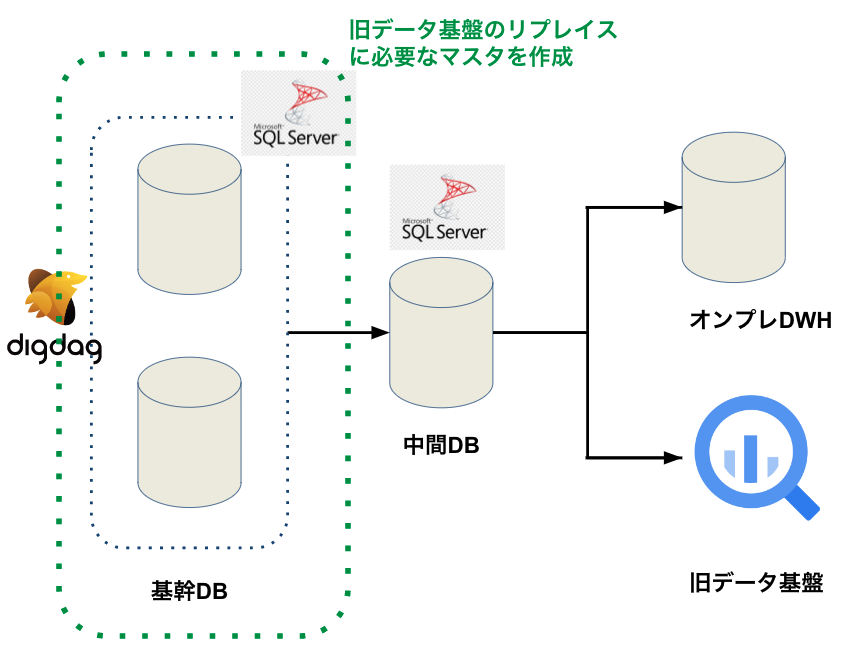
基幹DB管理チーム
新データ基盤の移行にあたり、旧データ基盤の課題を解決するために基幹DB管理チームと協力して、マスタ情報等を整理しました。すでにご紹介したとおり旧データ基盤の負債を解消するためにマスタ情報の整理が必要でした。基幹DB管理チームと連携しマスタ情報を整理し、新データ基盤に必要な仕組みを導入していきました。また、データ欠損や重複を防ぐための仕組みも導入してもらいました。
詳細はテックブログでも公開してるのでご確認ください。
techblog.zozo.com techblog.zozo.com
新データ基盤移行に伴うデータの評価
新データ基盤で移行に必要なテーブルが準備できたあとはデータの評価が必要です。移行に伴いデータ欠損等発生している場合があります。
オンプレのDWH移行では移行前後のデータを評価できる仕組みを入れたことで、移行に伴う欠損を未然に防ぐことができました。配信ログ等並行運用が難しい場合は過去データだけでも評価できるよう仕組みを整えることで、過去データを移行する際に発生してログ欠損を未然に防ぐことができます。
また、データ分析チームにも協力してもらうことで移行に必要なデータが不足していないかを確認しました。様々な加工処理を施した影響で過去データが不足している場合もありました。利用者にクエリを書き換える前に評価することで、事故を未然に防げます。
利用者への全体周知
新データ基盤の評価が完了し、新旧テーブル対応表が作成できたあとは利用者全体への周知です。共通基盤の利用者300人ほどをSlackのチャンネルに招待し、3回に分けて説明会を開きました。
利用者はBigQueryから利用状況を確認し、サービスアカウントの管理者はKintoneやSlackの履歴から特定しました。周知を行い説明会やSlackにて利用者からの疑問に回答していきました。データ分析チームと事前に不明点は調べ、新旧テーブル対応表や資料にもまとめていたので、想定外の問い合わせはありませんでした。新旧データ基盤の差分や移行先等まとめていたのである程度スムーズ進みました。
新データ基盤移行で問題になったこと
ここからは全体周知後、問題になったことをご紹介します。
過去データの扱い
ある程度予想はしていましたが、想像以上に過去データを引き続き使いたいとの要望があがりました。過去データは様々な加工処理が施され、信用できないデータになっています。どうしても必要な場合は別のGCPプロジェクトへコピーして管理してもらおうと思っていました。しかし、利用者からの要望が多かったため、別のGCPプロジェクトにバックアップをとり別環境で引き続き利用できるようにしました。データは信用できなくても、過去データが使えなくなるデメリットよりはましとの判断です。長期的には破棄していければと思います。
参照しているクエリが減らない
新データ基盤への移行を社内で周知しても、移行期限までにクエリの書き換えは思うように進捗しませんでした。止むを得ず、一時的に旧データ基盤のテーブルをビューに置き換え、新旧データ基盤の差分を吸収する対応をしました。
また、チームによっては旧データ基盤を参照しているクエリを止めない判断をする場合もありました。BIツールから実行されているクエリ等不要なクエリの棚卸しに時間がかかるためです。
さらに、GCPのデフォルトサービスアカウントを複数のチームで共用している場合、安全に移行することが困難になります。同じサービスアカウントを使うと、BigQueryの実行ログから移行が完了しているか確認できないためです。
案件ごとに必要最低限の権限をもったサービスアカウントを作らないと安全に移行することは難しいです。前もってデフォルトサービスアカウントの撲滅等を優先し実施した方が良かったです。
期日に余裕があれば参照クエリをなくすことは可能ですが、期日が決まってる場合は完全に参照クエリをなくすことは難しいように思いました。
データマートの管理者が不明
誰が管理者なのか不明確なデータマートがありました。退職等でデータマートの管理者が不在の場合があります。管理者不在のデータマートも他のチームのクエリからは参照されている場合があり、移行にともない混乱がありました。利用する側もそうですが、データマートの管理者がだれなのか品質を担保するために把握できる仕組みが必要に思いました。
まとめ
本記事では古くなった共通データ基盤をリプレイスする事例をご紹介しました。実際にリプレイスしてみると記事では書ききれない泥臭さもありましたが、旧データ基盤の負債も解消できてよかったです。旧データ基盤の負債を解消するために、マスタ情報の整理や運用の見直し、進め方等様々なチームと連携し進めました。関係者のみなさんにも感謝です。
本記事を読んで、もしご興味をもたれた方は、是非採用ページからご応募ください。
最近配信チームに異動したのでこちらも是非!