



こんにちは、MA基盤チームの田島です。私達のチームでは複数のワークフローエンジンを利用し、メールやLINEなどへの配信を含むバッチ処理を行っていました。今回それらのワークフローエンジンをすべてDigdagに統一しました。そして実行環境としてGKEのAutopilot環境を選択したことにより、柔軟にスケールするバッチ処理基盤を実現しましたのでそれについて紹介します。 また、その中で得られた運用Tipsについても合わせて紹介します。
目次
- 目次
- Digdag on GKE Autopilotの構成
- 運用上の工夫と注意点
- 今後の展望
- まとめ
Digdag on GKE Autopilotの構成
今回構築したDigdag on GKE Autopilot環境の最終構成は次のとおりです。

GKE Standard環境における、Digdagの構築はすでに弊社の別チームで行われており、スケーリング部分以外はほぼそれを踏襲する形で構築しました。以下は当時の発表資料です。
参考にした構成から一部拡張した部分について、またAutopilot環境だからこその利点についてなどを含め、改めて構成を紹介します。
Digdagの4つの役割
Digdagは役割ごとに以下の「Worker」「Scheduler」「Web」「API」のDeploymentを作成し、クラスタを構成しています。
Worker
Digdagではワークフローのなかの1つ1つの処理のことをタスクと呼びます。Workerは実際にタスクを実行する役割を担います。DigdagのタスクはPostgreSQL(CloudSQL)に一度キューという形で登録され、Workerは登録されているタスクのうち実行可能なタスクを取得して実行します。
WorkerのDeploymentのマニフェストは次のとおりです。Digdag起動時に disable-scheduler を指定することで、次で紹介するSchedulerの役割を除外しています。Kubernetes関連のオプションに関しては後ほど紹介します。
apiVersion: apps/v1 kind: Deployment metadata: labels: run: digdag-worker name: digdag-worker namespace: digdag spec: progressDeadlineSeconds: 600 revisionHistoryLimit: 10 selector: matchLabels: run: digdag-worker strategy: rollingUpdate: maxSurge: 2 maxUnavailable: 0 type: RollingUpdate template: metadata: labels: run: digdag-worker spec: serviceAccountName: digdag dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 5400 volumes: - name: digdag-config-volume configMap: name: digdag-config containers: - name: digdag-worker image: <YOUR_DIGDAG_IMAGE> imagePullPolicy: Always volumeMounts: - name: digdag-config-volume mountPath: /etc/config command: ["/bin/bash"] args: - "-cx" - | digdag server \ --disable-scheduler \ --log-level <LOG_LEVEL> \ --max-task-threads <MAX_TASK_THREADS> \ --config /etc/config/digdag.properties \ -p environment=<ENVIRONMENT> \ -X database.host=<POSTGRES_IP> \ -X database.password=$POSTGRES_PASSWORD \ -X digdag.secret-encryption-key=$SECRET_ENCRYPTION_KEY \ -X archive.gcs.bucket=<DIGDAG_ARCHIVE_BUCKET> \ -X log-server.gcs.bucket=<DIGDAG_LOG_BUCKET> \ -X agent.command_executor.type=kubernetes \ -X agent.command_executor.kubernetes.config_storage.in.gcs.bucket=<DIGDAG_ARCHIVE_BUCKET> \ -X agent.command_executor.kubernetes.config_storage.out.gcs.bucket=<DIGDAG_ARCHIVE_BUCKET> \ -X agent.command_executor.kubernetes.name=<KUBERNETS_CLUSTER_NAME> \ -X agent.command_executor.kubernetes.<KUBERNETS_CLUSTER_NAME>.master=$KUBERNETS_MASTER \ -X agent.command_executor.kubernetes.<KUBERNETS_CLUSTER_NAME>.certs_ca_data=`cat /var/run/secrets/kubernetes.io/serviceaccount/ca.crt | base64 -w 0` \ -X agent.command_executor.kubernetes.<KUBERNETS_CLUSTER_NAME>.oauth_token=`cat /var/run/secrets/kubernetes.io/serviceaccount/token` \ -X agent.command_executor.kubernetes.<KUBERNETS_CLUSTER_NAME>.namespace=digdag \ -X agent.command_executor.kubernetes.config_storage.in.type=gcs \ -X agent.command_executor.kubernetes.config_storage.out.type=gcs \ -X agent.command_executor.kubernetes.config_storage.out.gcs.direct_upload_expiration=<GCS_DIRECT_UPLOAD_EXPIRATION> \ -X executor.task_ttl=<TASK_TTL> resources: requests: cpu: 1000m memory: 2Gi limits: cpu: 1000m memory: 2Gi
また、configmapは以下のように定義しています。
configMapGenerator: - name: digdag-config namespace: digdag files: - config/digdag.properties
server.bind=0.0.0.0 server.port=8080 database.type=postgresql database.port=5432 database.user=digdag database.database=digdag archive.type=gcs log-server.type=gcs
Scheduler
Digdagでは、ワークフローごとに実行のスケジューリングを行うことができます。これもまた、PostgreSQLにスケジュールが登録されます。そして、Schedulerは実行時間になったワークフローの実行を開始します。
SchedulerのDeploymentのマニフェストは次のとおりです。Digdag起動時に disable-executor-loop を指定することでWorkerの役割を除外しています。
apiVersion: apps/v1 kind: Deployment metadata: labels: run: digdag-scheduler name: digdag-scheduler namespace: digdag spec: progressDeadlineSeconds: 600 revisionHistoryLimit: 10 selector: matchLabels: run: digdag-scheduler strategy: rollingUpdate: maxSurge: 2 maxUnavailable: 0 type: RollingUpdate template: metadata: labels: run: digdag-scheduler spec: serviceAccountName: digdag dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} volumes: - name: digdag-config-volume configMap: name: digdag-config containers: - name: digdag-scheduler image: <YOUR_DIGDAG_IMAGE> imagePullPolicy: Always volumeMounts: - name: digdag-config-volume mountPath: /etc/config command: ["/bin/bash"] args: - "-cx" - | digdag server \ --disable-local-agent \ --disable-executor-loop \ --log-level <LOG_LEVEL> \ --config /etc/config/digdag.properties \ -p environment=<ENVIRONMENT> \ -X database.host=<POSTGRES_IP> \ -X database.password=$POSTGRES_PASSWORD \ -X digdag.secret-encryption-key=$SECRET_ENCRYPTION_KEY \ -X archive.gcs.bucket=<DIGDAG_ARCHIVE_BUCKET> \ -X log-server.gcs.bucket=<DIGDAG_LOG_BUCKET> resources: requests: cpu: 200m memory: 300Mi limits: cpu: 200m memory: 300Mi
Web
DigdagにはDigdag UIと言って、ワークフローをGUIから確認・実行できるものがあります。そのDigdag UIを提供するのがWebになります。また、Digdag UI上からリクエストされるAPIの処理もこのWebが担います。
WebのDeploymentのマニフェストは次のとおりです。Digdag起動時にdisable-scheduler と disable-executor-loop を指定することで、SchedulerとWorkerの役割を除外しています。そして、外部からアクセスできるようポートの設定をしています。
apiVersion: apps/v1 kind: Deployment metadata: labels: run: digdag-web name: digdag-web namespace: digdag spec: progressDeadlineSeconds: 600 revisionHistoryLimit: 10 selector: matchLabels: run: digdag-web strategy: rollingUpdate: maxSurge: 2 maxUnavailable: 0 type: RollingUpdate template: metadata: labels: run: digdag-web spec: serviceAccountName: digdag dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler terminationGracePeriodSeconds: 20 securityContext: {} volumes: - name: digdag-config-volume configMap: name: digdag-config containers: - name: digdag-web image: <YOUR_DIGDAG_IMAGE> imagePullPolicy: Always volumeMounts: - name: digdag-config-volume mountPath: /etc/config command: ["/bin/bash"] args: - "-cx" - | digdag server \ --disable-local-agent \ --disable-scheduler \ --disable-executor-loop \ --log-level <LOG_LEVEL> \ --config /etc/config/digdag.properties \ -p environment=<ENVIRONMENT> \ -X server.http.io-idle-timeout=60 \ -X server.http.no-request-timeout=30 \ -X database.host=<POSTGRES_IP> \ -X database.password=<POSTGRES_PASSWORD> \ -X digdag.secret-encryption-key=<SECRET_ENCRYPTION_KEY> \ -X archive.gcs.bucket=<DIGDAG_ARCHIVE_BUCKET> \ -X log-server.gcs.bucket=<DIGDAG_LOG_BUCKET> ports: - containerPort: 8080 protocol: TCP resources: requests: cpu: 1000m memory: 4Gi limits: cpu: 100m memory: 4Gi readinessProbe: httpGet: path: / port: 8080 initialDelaySeconds: 5 periodSeconds: 5 timeoutSeconds: 4 successThreshold: 1 failureThreshold: 3 livenessProbe: tcpSocket: port: 8080 initialDelaySeconds: 5 periodSeconds: 5 timeoutSeconds: 4 successThreshold: 1 failureThreshold: 3
API
DigdagはDigdagClientを利用したり先程紹介したDigdag UIを利用してコントロールします。クライアントやUIはDigdagサーバへのAPIリクエストをすることでDigdagを操作します。そのAPIを直接利用したいというケースがあったため、API専用のDigdagを今回作成しました。例えば私達のチームではAPIを利用して、特定のワークフローの完了待ちをすると言った処理を別のDigdagや、同一のDigdagから行っています。
最初はWebと同じサーバーを利用していましたが、Webの処理によりPodが落ちるということがたまに発生していました。Webだけであれば画面が使えなくなるだけですから、数秒から数分でPodが復旧すれば問題ありませんでした。しかし、APIの場合では他のアプリケーションから参照されるため、それでは困るケースがあり役割を分離しました。APIのDeploymentはWebのものとほぼ同じ構成となります。
Kubernetes Command Executor
Workerでのタスク実行の問題
タスクの実行はWorkerで処理すると説明しました。私達のチームではメールやLINE・PUSH通知などの配信をしたり、データマートの集計をしたりと様々な種類のバッチ処理がDigdagで実行されます。中には大量のデータを処理するようなものもあれば、単純にHTTPリクエストするだけのものなどワークロードがバラバラです。そのため、Workerは高負荷なタスクに合わせて作成しておく必要があります。それにより、高負荷なタスクが無い場合にはWorkerのPodがオーバースペックになるため、コスト的にかなりのデメリットになります。

Command Executor
この課題を解決するためにKubernetes Command Executorを利用しました。DigdagはCommand ExecutorといってKubernetes等の環境でShellやRuby/Pythonといった処理を実行できる機能があります。
2022年1月にリリースされたDigdag v0.10.4にて、Command Executorのプラグイン化がリリースされました。それにより設定ファイル等でどのCommand Executorを利用するかが選択できるようになりました。Command Executorには現在以下の種類が存在します。
- Docker Command Executor
- ECS Command Executor
- Kubernetes Command Executor
Docker Command ExecutorはWorker内でDockerコンテナを起動しタスクを実行します。また、ECS Command ExecutorはECSでタスクを実行します。そして、Kubernetes Command Executorでは、Kubernetes上にPodを作成しタスクを実行します。
Kubernetes Command Executorの利用
それでは、なぜKubernetes Command ExecutorでWorkerの問題が解決できるのかを紹介します。Kubernetes Command Executorを利用することでWorkerはタスク実行用のPodを作成し、作成したPodの処理完了をポーリングするだけとなります。よって、Worker自体の処理はすごく軽く、負荷は均一となります。それによりPodのサイズは小さくかつ無駄なく利用できるようになります。

GKE Autopilot環境でのKubernetes Command Executorの利用
さらにKubernetes Command Executorを利用するときに、実行するPodのマニフェストを指定できるため、ワークロードに合わせてタスクのPodを作成・実行できます。このときAutopilot環境だと事前にNodePoolを作っておく必要がないため、アプリケーション側ではノードのサイズのことを気にせず必要なキャパシティを指定し処理を実行できます。

Kubernetes Command Executorの使い方
Kubernetes Command Executorを利用するには以下のように設定ファイルを記述することで利用できます。
agent.command_executor.type=kubernetes agent.command_executor.kubernetes.config_storage.in.gcs.bucket=<DIGDAG_ARCHIVE_BUCKET> agent.command_executor.kubernetes.config_storage.out.gcs.bucket=<DIGDAG_ARCHIVE_BUCKET> agent.command_executor.kubernetes.name=<KUBERNETS_CLUSTER_NAME> agent.command_executor.kubernetes.<KUBERNETS_CLUSTER_NAME>.master=$KUBERNETS_MASTER agent.command_executor.kubernetes.<KUBERNETS_CLUSTER_NAME>.certs_ca_data=`cat /var/run/secrets/kubernetes.io/serviceaccount/ca.crt | base64 -w 0` agent.command_executor.kubernetes.<KUBERNETS_CLUSTER_NAME>.oauth_token=`cat /var/run/secrets/kubernetes.io/serviceaccount/token` agent.command_executor.kubernetes.<KUBERNETS_CLUSTER_NAME>.namespace=digdag agent.command_executor.kubernetes.config_storage.in.type=gcs agent.command_executor.kubernetes.config_storage.out.type=gcs agent.command_executor.kubernetes.config_storage.out.gcs.direct_upload_expiration=<GCS_DIRECT_UPLOAD_EXPIRATION>
この状態で以下のようなタスクを定義することで、タスクがPodとして作成され実行されます。
+set_use_rate: _export: docker: image: ${docker_image} kubernetes: Pod: resources: requests: cpu: 100m memory: 0.2Gi limits: cpu: 100m memory: 0.2Gi sh>: echo 'hello'
また、設定ファイルにKubeterntes Command Executorの設定をしなければ、上記のように定義されたタスクはKubernetes Command ExecutorではなくDocker Command Executorが利用されます。そのため、ローカルでの開発ではわざわざKubernetesクラスタの構築をすることなくタスクの実行ができるため効率的に開発を進めることができます。
Workerのオートスケーリング
Kubernetes Command Executorを利用することで、ワークロードに合わせたタスクの実行を実現していることを紹介しました。ただし、Kubernetes Command Executor実行時にPodを作成し、Podの完了を待つという処理に関してはWorkerが担います。Workerはノードごとに max_task_threads で指定した数しか並列でタスクを実行できません。このとき、Workerのノード数を固定にしてしまうと、並列数を上げることができません。そこで、Workerノード自体のスケーリングも必要となってきます。
Custom Metricsを利用したオートスケーリング
Workerのスケーリングに関しては弊社エンジニアの繁谷が考案したスケーリング手法を参考にしました。以下がその構成です。
また、その説明を以下の記事で行っています。
構成を図示したものは次のとおりです。

Digdagでは、PostgreSQL利用しワークフローやタスクを管理しています。その中で現在実行中または実行待ちのタスクキュー数が取得できるため、それを利用することでWorker数を決定できます。そこで、PostgreSQL Exporterを利用しそのキューサイズをPrometheusに溜め込みます。そして、Prometheus Adapterを利用し、KubernetesのCustom Metrics APIに登録します。APIに登録できたら、その値をHPA(Horizontal Pod Autoscaler)で利用しスケーリングを実現します。実際の実装に関しては紹介したリポジトリを参照いただければと思います。
スケーリングの設定
私達のチームでは、紹介した構成からHPAのメトリクスの条件に「averageValue」の項目を追加しています。これを各ノードの max_task_threads の数を設定することで、現状のクラスター全体のスレッド数が足りなくなった分だけスケールアウトできるようになります。そして逆に使われているスレッド数が少なくなった場合にスケールインを行います。

実際のHPAの設定は次のとおりです。
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: digdag-worker namespace: digdag spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: digdag-worker minReplicas: 1 maxReplicas: 10 metrics: - type: Object object: target: kind: Service name: postgres-exporter metricName: queued_tasks targetValue: <MAX_TASK_THREADS> averageValue: <MAX_TASK_THREADS>
スケールイン時の問題
このような設定ではスケールインのタイミングで弊害が生じます。例えば以下のように各Workerで実行中のタスクが一部終了しスケールインしたとします。その時まだ実行中のタスクは処理が中断されてしまいます。
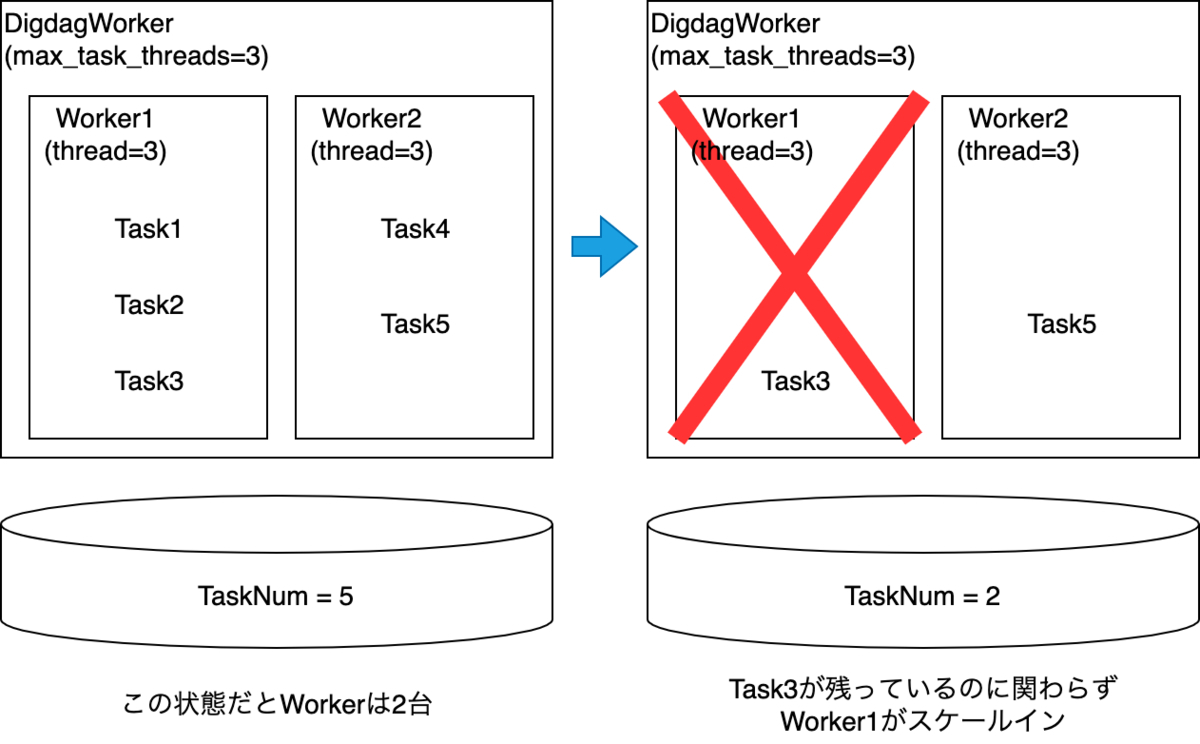
そこでDeploymentに「terminationGracePeriodSeconds」を設定することでタスクの中断を回避しました。このパラメータはpreStopのタイムアウト時間を指定するものです。詳細に関しては以下のドキュメントをご参照ください。
Workerの動きとしてはSIGTERMを受け取ると新たなタスクをキューから取得しない状態になります。また、動いているタスクは完了するまで動き続けます。よって、スケールイン時に動いているタスクが中断しないようにするには「terminationGracePeriodSeconds」をDigdag上で動作しうるすべてのタスクの中で最大の時間以上にします。タスクの中で最大の実行時間が90分以下の場合の設定例は次のとおりです。
terminationGracePeriodSeconds: 5400
そうすることで確実にタスクが終了してからノードがスケールインされます。

PrometheusAdapterの利用の注意点
Prometehus AdapterでCustom Metrics APIにAPIを登録するときに、Kubernetes Masterへの 6443 ポートのアクセス許可が必要となります。ファイアウォール等でアクセスを絞っている場合は注意が必要です。
運用上の工夫と注意点
実際に運用してみると工夫をしないと運用しづらい面や注意点などがあったので、それらについて紹介します。上記で紹介したDigdag APIを独立した構成にしたことも、実際に運用して得られた運用Tipsの1つです。
ノードの立ち上げの待ち時間が発生する
今回GKE Autopilotを利用しているため事前に必要な数だけノードの準備をしておくといったことができません。そのため、タスクのPod作成時に最大で1分ほどのノードの作成待ちが発生します。Webなどの場合HPAの閾値を緩めることで、早めにPodを用意するなどで問題を回避できます。しかし今回の場合タスクの開始時にPodが作成されるためその制御はできません。バッチ処理として利用しているため私達のユースケースにおいてはノードの起動時間は誤差の範囲であって問題とはなっていません。よって、もし数十秒・数秒といった起動時間が許容できない場合はAutopilot環境ではなくStandard環境を選ぶなどをしたほうが良いでしょう。
タスクはすべて冪等にする
各種タスクの実行はKubernetes Command Executorを利用して、毎回Podを作成していると説明しました。運用してみてわかったのですが、Kubenetes Command Executorを利用せずにタスクを実行する場合に比べてPodの起動が失敗するなどタスクの失敗頻度が高くなりました。
そこで、すべてのタスクを冪等にしておくことで安心してリトライ処理を行うことができます。また、Digdagでは、タスクごとにRetryの設定を入れることができるため、すべての処理にリトライ処理を入れることで安定したワークフローの実行ができるようになります。
私達のチームではまだすべてのタスクが冪等になっているというわけではないため、やはりそこのリカバリ処理の運用コストが高くなっています。そのため、現在すべての処理の冪等化と自動リトライの導入を進めています。Digdagに限らず、バッチ処理では冪等化することによって安定性がかなり変わってくるので積極的に取り入れると良いでしょう。
たまにログが出ない
Kubernetes Command Executorでは、処理の最後にDigdag UIなどからログが確認できるよう起動したPodからログを取得しています。しかしタスクのPodが何らかの原因で異常終了した場合、それらのログが取得できずにタスクが終了してしまいDigdag UIからログが確認できません。その場合は、タスクに紐づくPod Nameがタスク実行前に決定されるため、Cloud LoggingでPod Nameを指定してログを確認しています。実際以下のようにDigdag UIからPod Nameを確認できます。
commandStatus: cluster_name: ma-autopilot-stg executor_state: log_offset: 590 io_directory: .digdag/tmp/digdag-py-70356-1834671494158116161 pod_creation_timestamp: 1646198947 pod_name: digdag-pod-70356-0-280485a4-a27a-4e70-bb5c-c557ffc0b7f3
ただしDigdagでログを確認できることがベストであるため、これの回避方法が実装等できないかを検討しています。
終了したPodが消えない
Kubernetes Command Executorでは、Podを作成しその中でタスクを実行すると説明しました。成功したPodはステータスがSuccessになりますが、いつまでたってもPodが消えずに残るということが発生しました。それにより、Podのために用意したIPを使い尽くし新たなPodが作成できないという事態が発生しました。そこで以下のようなスクリプトをCronJobで実行し、終了したPodを定期削除するようにしました。
apiVersion: batch/v1beta1 kind: CronJob metadata: name: pod-cleaner-cronjob spec: schedule: "*/30 * * * *" jobTemplate: spec: template: spec: serviceAccountName: pod-cleaner containers: - name: pod-cleaner image: YOU_SHOULD_OVERWRITE imagePullPolicy: Always command: ["/bin/bash", "-c"] args: - | curl -s https://kubernetes.default.svc/api/v1/namespaces/digdag/pods?fieldSelector=status.phase=Succeeded \ --header "Authorization: Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)" --insecure \ | jq -r --arg target_date `date +%s -d '30 minutes ago'` \ '.items[] | { name: .metadata.name, finishedAt: .status.containerStatuses[0].state.terminated.finishedAt|fromdate} | select(.finishedAt < ($target_date|tonumber)) | .name' \ | xargs -i \ curl -X DELETE -s https://kubernetes.default.svc/api/v1/namespaces/digdag/pods/{} \ --header "Authorization: Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)" --insecure \ | jq .metadata.name restartPolicy: OnFailure
上記スクリプトで削除対象Podを30分より前に絞っています。その理由としては、タスク成功後にDigdag Workerが成功したPodのステータスを確認しログを取得するためです。ステータス確認完了前にPodを消してしまうとタスクが失敗したとDigdagは判断してしまいます。よってそれを防ぐために確実にステータスチェックが終わっているであろう30分より前のPodに条件を絞っています。
ただし、終了した直後にPodがちゃんと消えてくれることがベストなため、以下のようなPRをDigdagに提案をしています。
今後の展望
最初に説明したように、Digdag以外のワークフローエンジンはすべて廃止しました。しかし、Digdag自体は複数のクラスターを運用しています。それらDigdagも今回作成したDigdagに処理をすべて統一させ運用負荷を下げたいと考えています。
また、Digdagはすごく素晴らしいツールでかなり愛用しています。ですがまだ改善の余地が残されているとも考えています。そこで、私達のチームとしても積極的にDigdagの発展に貢献できたらと考えています。
まとめ
今回、DigdagをGKE Autopilot環境に作成することで柔軟にスケールするバッチ処理基盤ができましたのでその紹介をしました。また、実際に運用してみて分かった注意点や運用Tipsについて紹介しました。
上記で挙げたように、まだまだ改善の余地は残っています。また、今回作った基盤上で動かすMAアプリケーションは他にもたくさんあります。興味があれば以下のリンクからご応募ください。