



はじめに
こんにちは、データシステム部MLOpsブロックの岡本です。
MLOpsブロックではWEAR by ZOZO(以下WEAR)やZOZOTOWNのレコメンドシステムを開発・運用しています。
WEARのコーディネート詳細画面には、表示しているコーディネートに関連性が高いコーディネートを表示する関連枠があります。今回、WEARのコーディネート詳細画面の関連枠におけるコーディネートの表示ロジックを、ルールベースからMLを使ったロジックに置き換えました。新たに開発したMLを使ったロジックを、以下では関連コーデレコメンド機能と呼んでいます。説明のため、以下では関連コーデレコメンド機能を本機能と記載します。
本機能の開発ではベクトル検索技術を利用しています。ベクトル検索の実装には、Google Cloudが提供するマネージドなベクトル検索サービスであるVertex AI Vector Searchを利用しました。
Vertex AI Vector Searchでベクトル検索機能を実装する際に、Google Cloudの公式ドキュメントの説明だけでは理解しにくかった点などいくつか苦労がありました。また本番環境のシステムの一部として運用し、遭遇した課題やその解決策についても学びがありました。
本記事では、WEARの関連コーデレコメンドプロジェクトのベクトル検索の開発にVertex AI Vector Searchを導入し、実装・本番運用で得られた知見を説明します。Vertex AI Vector Searchを使ってベクトル検索機能を実装する際の参考になれば幸いです。
記事の内容は2025年7月時点での情報であることにご留意ください。
目次
- はじめに
- 目次
- プロジェクト説明とVertex AI Vector Searchの導入背景
- Vertex AI Vector SearchとScaNNアルゴリズムの概要
- Index構築の実装とパラメータ値の決定
- Indexのデプロイ戦略とEmbeddingの更新・削除方法
- ベクトル検索クエリ実行とフィルタリングの実装
- Vertex AI Vector Searchの本番運用と課題の改善
- まとめ
プロジェクト説明とVertex AI Vector Searchの導入背景
関連コーデレコメンドプロジェクトの概要
WEARの関連コーデレコメンドプロジェクトでは、コーディネート詳細画面の関連枠に表示するコーディネートの選出ロジックをルールベースからMLに置き換えることを目的としました。
下図の左側の画像は、WEARのコーディネート詳細画面の関連枠のUIで、右側の画像がコーディネート詳細のトップです。関連枠はコーディネート詳細画面の下部に表示され、ユーザーが閲覧しているコーディネートに関連する他のコーディネートをコンテンツとして一覧表示します。

ルールベースのロジックでは、コーディネートに紐づくメタデータを使って関連枠に表示するコーディネートを選出していました。ルールベースによる関連枠の表示には次の課題がありました。
- 視覚的な類似性を考慮できていない
- ログインユーザーの嗜好に基づいた関連性を考慮できていない
本プロジェクトでは既存のルールベースによるコーディネート選出での上記2つの課題を解決するため、MLを使った手法でコーディネートを選出しました。よりユーザーが興味を持つコーディネートを提案することを目指し、関連枠でのインプレッション数、クリック数といったKPIの改善を図りました。
レコメンドロジックの概要
グラフニューラルネットワークモデルによるEmbeddingの抽出
本機能ではユーザー・コーディネートのベクトル表現であるEmbeddingを抽出し、ベクトル検索に利用することでユーザーごとにパーソナライズされた類似コーディネートを選出しました。
Embeddingの抽出にはグラフニューラルネットワーク(以下GNN)を用いています。GNNは深層学習の手法であり、ネットワーク構造を持つデータに対して効率的に特徴を学習・表現します。ネットワークは各要素を表すNodeとNode間を結ぶEdgeから構成されます。本機能ではWEARにおけるユーザーとコーディネートの関係をネットワークとして表現し、GNNモデルでコーディネートとユーザーの関係性を学習しました。WEARにおけるユーザーとコーディネートの関係は次のネットワーク構造で表現しました。
- Node
- ユーザー
- コーディネート
- Edge
- ユーザー行動
- クリック
- いいね
- etc...
- ユーザー行動
WEARのデータを用いて学習したGNNモデルを使うことで、ネットワークの持つ構造的な特徴を反映したEmbeddingを抽出できます。またGNNモデルとは別のモデルでユーザー・コーディネートの内部特性を表す特徴量を抽出しており、GNNモデルで抽出したEmbeddingと集約することで最終的なEmbeddingを作成しています。こうしてユーザー・コーディネートについて構造的かつ属性を反映したEmbeddingを得ています。
このように得られたコーディネートのEmbeddingを用いて、ベクトル検索のIndexを構築しています。構築したIndexを対象にベクトル検索クエリを実行することでコーディネート群を取得できます。ユーザーのEmbeddingはリランキングに利用しており、リランキングについては後節(2段階のベクトル検索)で説明します。
2段階のベクトル検索
本機能ではユーザーごとにパーソナライズされた類似コーディネート群を取得するため、2段階でベクトル検索しています。
- 類似コーディネート群の取得
- ユーザー嗜好に基づくパーソナライズ(リランキング)
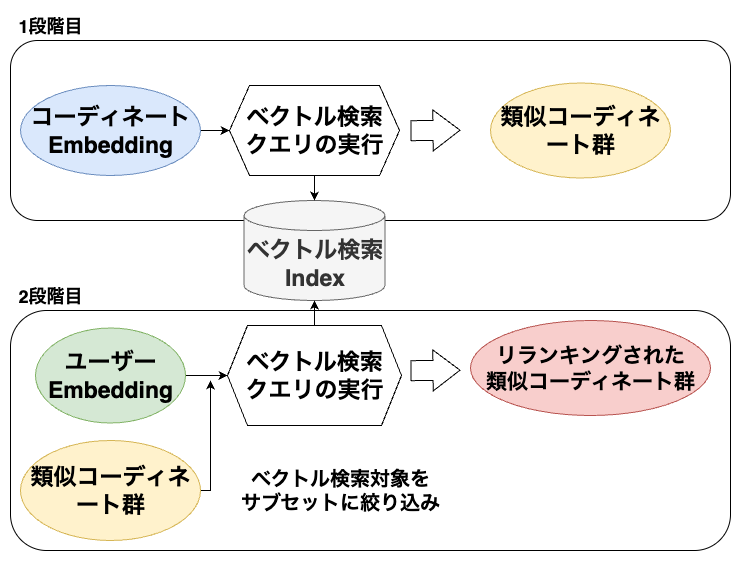
1段階目のベクトル検索クエリ実行では、コーディネートEmbeddingを入力として視覚的に類似したコーディネート群を取得します。
続いて2段階目のベクトル検索クエリ実行では、ユーザーEmbeddingを入力として1段階目で取得した類似コーディネート群をリランキングします。
リランキングにより類似コーディネート群はユーザーの嗜好に基づいて並び替えられます。これにより関連枠に表示する最終的なコーディネートを決定します。
Vertex AI Vector Searchの導入背景
過去プロジェクトにおけるベクトル検索機能の実装
MLOpsブロックでは関連コーデレコメンドプロジェクト以前にも、ベクトル検索を利用した他のレコメンドシステムを構築・運用していました。一方で過去のシステム実装時にはベクトル検索のマネージドサービスが充実しておらず、自前でベクトル検索機能を実装・運用していました。
過去に自前でベクトル検索機能を実装し、運用を続けているシステムの1つとして、ZOZOTOWNの類似アイテム検索機能があります。
類似アイテム検索機能はZOZOTOWNの商品詳細画面から利用できる機能で、ユーザーが閲覧している商品に類似した商品を検索します。類似アイテム検索では、商品画像から抽出した特徴量によりベクトル検索Indexを構築しています。構築したIndexに対してベクトル検索クエリを実行し、類似商品を取得しています。
類似アイテム検索のベクトル検索システムは主に次の機能を含んでおり、これらの実装・運用にかかる工数面での課題がありました。
- バッチ処理
- Indexの構築
- Indexの更新(新規商品の追加・削除)
- ベクトル検索API
- Indexを用いてベクトル検索クエリを実行
- Indexのリリース管理
- バッチで作成したベクトル検索Indexの更新をベクトル検索APIに反映
特にIndexのリリース管理はシステム的にバッチ処理とベクトル検索APIに跨る部分であり、実装だけでなく運用面の複雑さを増す要因となり課題感がありました。バッチとベクトル検索API間の連携について以下で説明します。
前提としてMLOpsブロックではAPIの動作インフラとしてGoogle Kubernetes Engine(以下GKE)を利用しています。類似アイテム検索のベクトル検索APIもGKE上にPodとしてデプロイされています。
ベクトル検索APIのコンテナはベクトル検索Indexをメモリに持ち、クエリ実行時はIndexを参照してベクトル検索します。API起動時にIndexをメモリへ読み込み、保持しています。そのためIndexの更新をベクトル検索APIへ反映するにはPodの再起動が必要です。
Index更新時は同期的にベクトル検索APIへIndex更新を反映するため、Index更新とベクトル検索APIのPodの再起動を両方バッチ処理で実行していました。
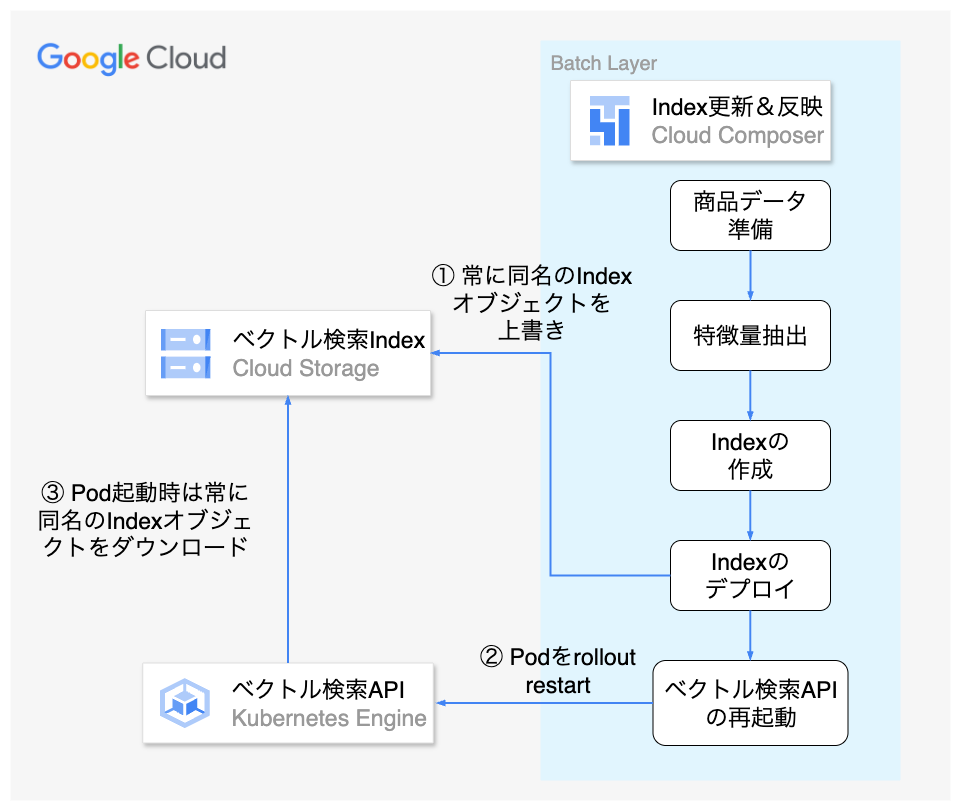
上記の構成では運用面で具体的に次の課題がありました。
- ベクトル検索APIの回復性が悪い
- Indexのデータ量が大きく、ベクトル検索APIのPod起動に時間がかかる
- Podの入れ替わり頻度が高いことによる障害リスクの増加
- 入れ替わり時にはエラー発生のリスクが高い
- 入れ替わり時の障害リスクを防ぐためには、リクエストのドレインやProbeなど特に慎重に考慮する必要があり、実装難易度が高い
- バッチとAPI間の依存によるシステムの複雑性の高さ
- ベクトル検索APIへのIndex更新の反映タイミングを開発者側で制御できない
- バッチ処理を実装する上で、ベクトル検索APIの実装や構成を考慮する必要がある
このように自前でベクトル検索機能を実装・運用する場合は工数・システムの複雑性の面でいくつかの課題がありました。
Vertex AI Vector Searchの導入モチベーション
本システムの開発でVertex AI Vector Searchの導入に至ったモチベーションは次になります。
- マネージドサービスである
- ベクトル検索機能の実装・運用・保守の工数を抑えられる
- 一度IndexをデプロイすればIndexのEmbedding更新はVertex AI Vector Search側で自動反映する
- 高速なクエリ実行が可能
- ScaNNアルゴリズムを利用して高速な近似最近傍探索が可能
- 将来需要に備えた知見獲得
- 今後社内でベクトル検索を利用したレコメンドシステムの開発が増えると予想されるため、マネージドサービスでのベクトル検索機能の開発・運用事例を獲得する
マネージドサービスであるVertex AI Vector Searchを利用することで、ベクトル検索機能を自前で実装・運用する場合の工数やシステムの複雑性の課題を解決できると考えました。また今後社内でベクトル検索を利用したレコメンドシステムの開発が増えることも予想されており、Vertex AI Vector Searchを利用した開発・本番運用の知見を獲得したい狙いもありました。WEARはZOZOTOWNと比較するとトラフィック負荷は小さいため、Vertex AI Vector Searchを本番環境で利用し、知見を得るには適したプロジェクトであると判断しました。
Vertex AI Vector Searchでは、ベクトル検索のアルゴリズムにScaNNアルゴリズムを利用しており近似最近傍探索を高速に実行できます。前述した類似アイテム検索のベクトル検索機能ではAnnoyアルゴリズムを利用していました。後発の手法であるScaNNアルゴリズムの性能を試す良い機会であると考えました。
ベクトル検索機能を持つマネージドサービスの比較
Vertex AI Vector Searchを導入する前に、Google Cloudのその他のベクトル検索サービスと比較しました。
Google Cloudでは複数のマネージドデータベースサービスでベクトル検索機能も提供しています。このうちAlloyDB for PostgreSQL(以下AlloyDB)でもScaNNアルゴリズムを利用しています。マネージドサービスである点やScaNNアルゴリズムを利用している点で、AlloyDBのベクトル検索機能はVertex AI Vector Searchと類似しています。一方で本番システム以外のユースケースでは、サービス構築や他サービスとの連携の容易性もサービス選定の上で重要な要素と考えました。
MLOpsブロックが関わるプロジェクトの機能開発では、本番システム開発初期の段階で実験・PoCを行います。この段階では主にMLエンジニアやデータサイエンティストがMLモデルの精度や出力の評価・改善をします。本システムの最終的な出力は、GNNモデルで抽出したEmbeddingではなくベクトル検索クエリ実行の結果です。そのため実験・PoCの段階でもGNNモデルで抽出したユーザー・コーディネートのEmbeddingを元にベクトル検索Indexを構築し、クエリを実行して結果を比較・確認可能にします。
本番システムの開発ではサービス選定時にシステムの堅牢性や安定性を重視します。一方で開発初期の実験・PoC段階での開発では構築容易性と柔軟性を重視しています。実験・PoC段階での利用も考慮に入れると、Vertex AI Vector SearchにはAlloyDBと比較して次の優位性を感じました。
- 環境構築が容易
- データベースの構築が不要
- Google Cloud Storage(以下GCS)のデータを元にIndexを作成可能
- Indexの切り替えが容易
- Vertex AI Pipelinesと合わせて利用しやすい
AlloyDBでベクトル検索機能を利用するには、PostgreSQLのデータベースの構築が必要です。これに対してVertex AI Vector SearchではGCSのデータを元にIndexを作成できるため、データベースの構築が不要でソースデータも用意しやすく環境構築が容易です。またVertex AI Vector Searchではアクセス先となるIndex EndpointとIndexが分離されており、Indexを切り替えてベクトル検索結果を比較可能です。
さらにVertex AI Vector Searchは社内のML系のサービスのパイプライン開発で多く利用しているVertex AI Pipelinesとも合わせて利用しやすいです。Vertex AI PipelinesはKubeflow Pipelinesのフレームワークを使用してサーバレスでMLワークフローをオーケストレーションできるサービスです。Kubeflow PipelinesはKubernetes上で機械学習ワークフローを管理するためのオープンソースツールです。
Vertex AI Pipelinesではパイプラインの成果物であるArtifactをGCSに保存します。Vertex AI Vector SearchではGCSのオブジェクトを元にIndexを作成します。そのためVertex AI Pipelinesでパイプラインの成果物として保存したGCSのデータを直接参照してIndexを作成・更新できます。パイプラインでのIndexの作成・更新については後節(Indexの作成・更新フロー)で説明します。
これらの観点からベクトル検索機能のマネージドサービスとしてVertex AI Vector Searchを選定しました。
Vertex AI Vector SearchとScaNNアルゴリズムの概要
Vertex AI Vector Searchの概要
Vertex AI Vector Searchは、Google Cloudが提供するマネージドなベクトル検索サービスです。以前はVertex AI Matching Engineという名称で提供されていました。
Vertex AI Vector Searchは主に次のコンポーネントで構成されています。
- Vector Search Index
- Vector Search Index Endpoint(以下Index Endpoint)
Vector Search Indexは、ベクトル検索のIndexを表現するコンポーネントで、GCSに保存されたデータを元に構築されます。Index Endpointは、構築したIndexのデプロイ先であり、クエリを受け付けるエンドポイントです。
各コンポーネントの関係性は次の図で表せます。
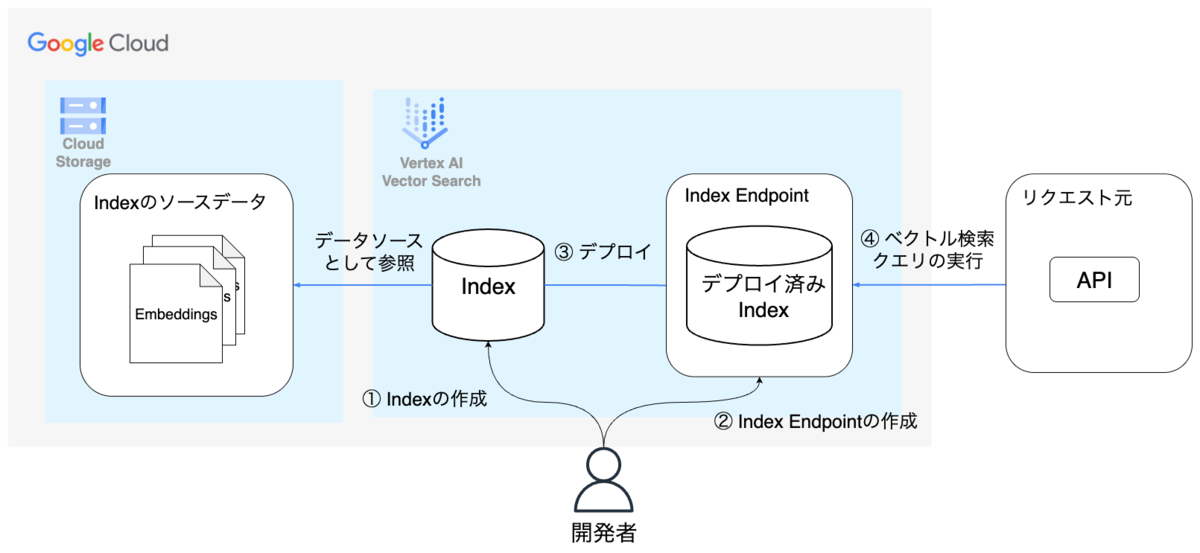
開発者は事前にIndex EndpointとIndexを作成します。Indexを指定したIndex Endpointにデプロイすることでベクトル検索クエリを実行できます。Vertex AI Vector Searchの各コンポーネントをこのように構成することでベクトル検索機能を実装できます。
ScaNNアルゴリズムの概要
Vertex AI Vector Searchを利用する上で、ScaNNアルゴリズムの特徴の理解は有用です。
ScaNNアルゴリズムは次の特徴を持つ近似最近傍探索の手法です。
- データを事前にパーティショニングし、検索時には全データを対象とせずに近いパーティションのみを検索することで計算コストを削減する
- ベクトル量子化手法の一種であるProduct Quantization(PQ)により高次元ベクトルを圧縮するためメモリ効率が良い
ScaNNアルゴリズムでは次の3段階の処理でベクトル検索をします。
- パーティショニング:データを事前にパーティショニングし、クエリ実行時に上位のパーティションを選択して、2段階目のスコアリングに進む
- スコアリング:検索対象のパーティション内の全データポイントまでの距離を近似計算し、スコアリングする
- 再スコアリング:2段階目のスコアリングの結果から上位k'個のデータポイントを選択する。正確な距離を再計算した上で上位k個のデータポイントを選択することで再スコアリングする(k'はkより大きな値を取る)
1・2段階目の処理では計算コストを削減し、3段階目の再スコアリングで精度を向上させます。これにより速度と精度のトレードオフを両立しており、大規模なデータセットに対しても高速な近似最近傍探索を実現しています。
Vertex AI Vector Searchで提供されているTreeAH IndexはScaNNアルゴリズムを使用するベクトルIndexの1つです。
TreeAHでは1段階目の処理でデータをツリー構造にパーティショニングします。パーティショニングを行わない場合は全データを対象に近似計算するブルートフォース検索となります。
TreeAHの2段階目の処理では、PQの中でも特に4-bit PQを利用して高次元ベクトルを圧縮(量子化)します。4-bit PQを利用することでSIMDレジスタに収まるサイズのベクトルを扱うことができます。
SIMDとはSingle Instruction, Multiple Dataの略で1つの命令で複数のデータを並列化し、同時に処理する形態を指します。4-bit PQではCPUのSIMD命令を利用することで高速な近似最近傍探索が可能になっています。TreeAHのAHはAsymmetric Hashingの略です。クエリベクトルは量子化されない生ベクトルである一方、候補データのベクトルは事前に量子化されていることがAsymmetric Hashingの所以です。
ScaNNアルゴリズムのドキュメントでは経験則としてデータ数に応じて次の構成が推奨されています。
| データ規模 | 推奨手法 |
|---|---|
| 20,000 件未満 | ブルートフォースを使う |
| 100,000 件未満 | Asymmetric Hashing(AH)でスコアリングし、その後再スコアリングする |
| 100,000 件以上 | パーティショニングを行い、AH でスコアリングし、その後再スコアリングする |
ScaNNアルゴリズムやTreeAHの理解にあたっては次の資料を参考にさせていただきました。
- Accelerating Large-Scale Inference with Anisotropic Vector Quantization
- ScaNN Algorithms and Configuration
また近似最近傍探索のアルゴリズムや4-bit PQについては次の資料を参考にさせていただきました。
アルゴリズムの詳細については上記の資料をご参照ください。
Index構築の実装とパラメータ値の決定
Indexの作成・更新フロー
関連コーデレコメンドのシステムでは、Embeddingの抽出からIndexの作成・更新・デプロイまでの一連の処理をパイプラインで実行しています。パイプラインのインフラにはVertex AI Pipelinesを利用しています。
本システムのパイプラインは日次実行しており、デプロイ済みのIndexを更新しています。Index更新時は新規コーディネートのEmbeddingの追加や、既存のコーディネートのEmbeddingを最新のユーザーの行動を反映したEmbeddingへ更新します。さらに削除済みのコーディネートのEmbeddingを削除することでIndexを最新化します。
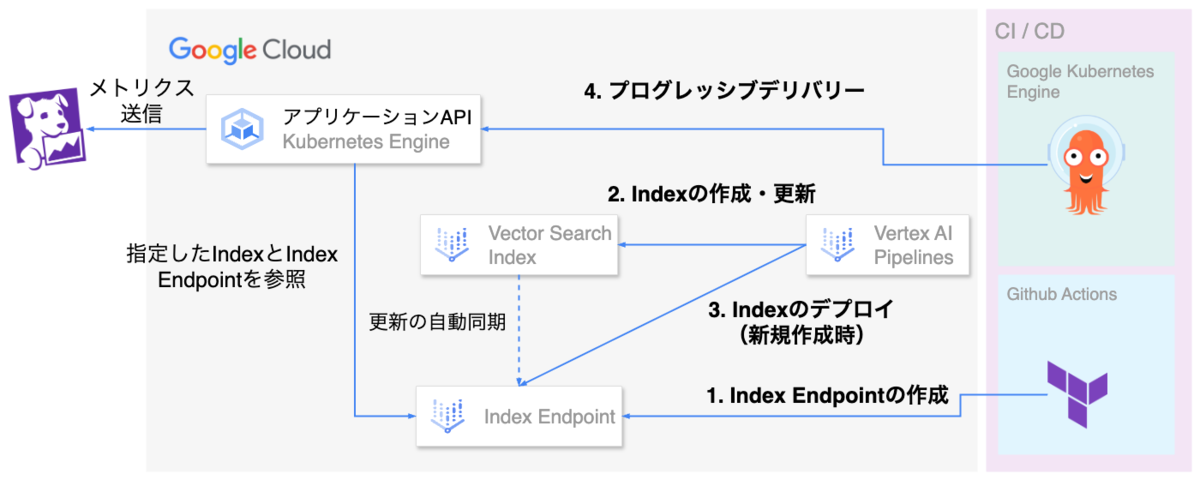
下図は本システムでVector Search Indexを作成・更新・デプロイするパイプラインの処理のフローを示しています。説明の関係でVertex AI Vector Searchに直接関係しない処理は省略しています。
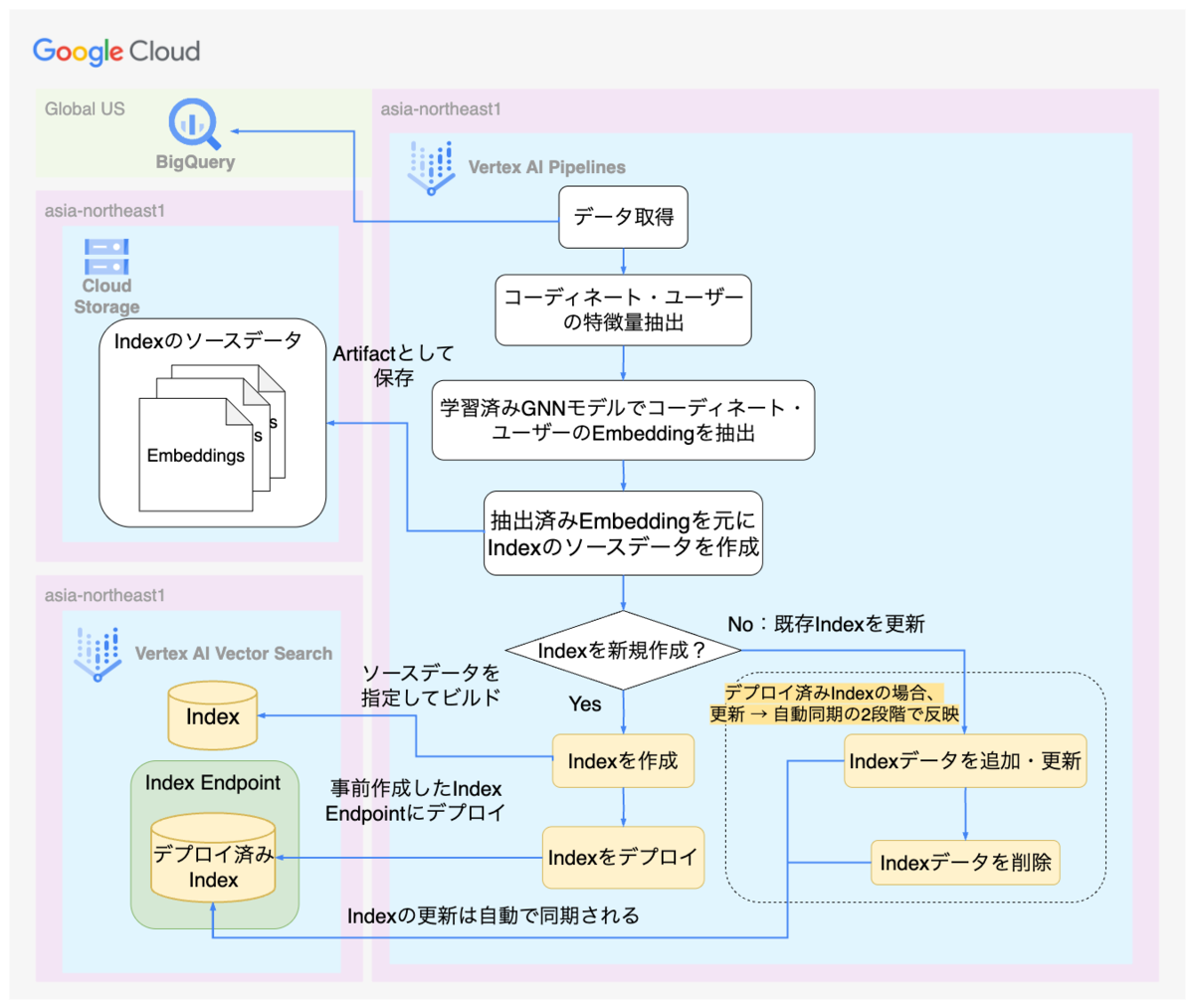
Vertex AI Pipelinesで実行される各タスク間のデータの受け渡しにはArtifactを利用しています。ArtifactはKubeflowでデータを保存するための仕組みです。Vertex AI PipelinesにおいてArtifactはGCSのオブジェクトとして保存されます。
パイプラインのタスクで抽出したコーディネートのEmbeddingはIndexのソースデータ形式に合わせて成形し、ArtifactとしてGCSに保存します。Vertex AI Vector SearchではGCSのデータを元にIndexを作成・更新します。パイプラインのタスクで保存したArtifactをそのままIndexのデータソースとして参照し、Vertex AI Vector SearchのIndexを作成・更新しています。
システムの構成にあたってはGKEクラスタとVertex AI Vector Search、Vertex AI Pipelinesで利用するリージョンを揃えることに注意しました。
ZOZOではDWHとしてBigQueryを利用しており、パイプラインで扱う多くのデータはUSマルチリージョンに保存されています。そのため通常は、Vertex AI Pipelinesの実行リージョンはBigQueryのクエリ費用を抑えるためにUS系のリージョンを利用することが多いです。
一方で本システムではVertex AI Vector Searchの呼び出し元となるAPIはasia-northeast1リージョンのGKEクラスタで動作しています。以下では呼び出し元となるAPIをアプリケーションAPIと記載します。ベクトル検索クエリ実行時のレイテンシを抑えるためIndex EndpointはアプリケーションAPIと同じasia-northeast1リージョンに作成しています。またVertex AI Vector SearchではIndexデプロイ時の制約として、デプロイ先のIndex EndpointとIndexのリージョンを一致させる必要があります。この制約によりIndexのリージョンはIndex Endpointに合わせてasia-northeast1リージョンに作成しました。
Indexのリージョン制約としては、ソースデータに指定するGCSのバケットとIndexのリージョンを一致させる必要もあります。本システムではVertex AI PipelinesのArtifactをIndexのソースデータとして直接参照しています。そのためArtifactを保存するGCSのバケットもasia-northeast1リージョンに作成しました。
またVertex AI Pipelinesでは、Artifactの保存先のGCSバケットのリージョンとパイプラインを実行するリージョンを一致させる必要があります。そのためパイプラインの実行もasia-northeast1リージョンで行うようにしました。
リージョン制約は見落としがちであるため、システム設計時に確認しておくことをおすすめします。
Index構築の実装
Index作成の実装
パイプラインでのVertex AI Vector Search Index、Index Endpointに関わるタスク実装にはVertex AI SDK for Pythonを利用しました。
Index作成の実装は次の通りです。MatchingEngineIndexクラスのcreate_tree_ah_indexメソッドを呼ぶことでIndexを作成できます。create_tree_ah_indexメソッドの引数のうちdimensions以下の引数はIndex構成パラメータです。Index構成パラメータについては後節(Index構成パラメータの決定)で別途説明します。
from google.cloud.aiplatform.matching_engine import MatchingEngineIndex created_index = MatchingEngineIndex.create_tree_ah_index( project=project_id, location=location, display_name=index_display_name, index_update_method="BATCH_UPDATE", contents_delta_uri=gcs_uri, ####### 以下はIndex構成パラメータ ######## dimensions=dimensions, approximate_neighbors_count=approximate_neighbors_count, shard_size=shard_size, leaf_node_embedding_count=leaf_node_embedding_count, distance_measure_type=distance_measure_type, feature_norm_type=feature_norm_type, ) with open(output_index_name, "w") as f: f.write(created_index.name)
引数のcontents_delta_uriにはIndex作成のソースデータとして参照するGCSのURI(gs://で始まるもの)を指定します。ソースデータとして参照するフォルダは次の構成に従う必要があります。フォルダ名やファイル名は任意ですがファイルの拡張子は.csv、.json、.avroのいずれかである必要があります。
batch_root/ feature_file_1.json feature_file_2.json
各ファイルはEmbeddingデータを含み、データの形式は決まっています。密Embedding、スパースEmbedding、ハイブリッドEmbeddingのどれを使用するかによって、ファイル内のデータ形式が決まっているため注意が必要です。詳細は公式ドキュメントの入力データ処理を参照してください。本システムでは密Embeddingを使用しており、各ファイルは次の例の形式で保存しています。例に記載のid、embeddingの値はご自身の環境に合わせて置き換えてください。
{"id": "1", "embedding": [0.1,0.05,0.3]} {"id": "2", "embedding": [0.2,0.01,0.02]}
Index内の各Embeddingごとのレコードを以下ではデータポイントと呼びます。データポイントのidはIndex内で一意になるため重複しないように注意してください。本システムではコーディネートが一意のidを持っているためコーディネートのidをそのままデータポイントのidとして利用しました。
create_tree_ah_indexメソッドの戻り値はMatchingEngineIndexクラスのインスタンスでありIndexのメタデータを含みます。インスタンスのnameプロパティを参照することで完全修飾されたIndexのidを取得できます。Indexのidはデプロイ時に必要であるため、created_index.nameの値を最後にタスクの出力パラメータとして書き込んでいます。
Index Endpointの作成とIndexのデプロイ
作成したIndexをデプロイする前にデプロイ先となるIndex Endpointの作成が必要です。
Index Endpointはパイプラインとは別でTerraformにより作成しました。TerraformはIaCツールの1つでインフラの構成を宣言的に記述でき、ソースコードとして管理できます。MLOpsブロックでは原則としてGoogle Cloudのインフラ構成をTerraformで定義し、管理しています。
次に示すのはIndex Endpointを作成するTerraform実装です。Terraform Providerの設定は省略していますが、google Providerを利用して作成可能です。
resource "google_vertex_ai_index_endpoint" "user_to_snap_index_endpoint" { display_name = "user_to_snap_index_endpoint" region = "asia-northeast1" network = "projects/1234/global/networks/dummy-vpc-network" public_endpoint_enabled = false }
Vertex AI Vector Searchへのリクエストはセキュリティ、レイテンシの観点から内部通信のみに制限しています。Index Endpointの作成時にVPCネットワークを指定することで、サービスプロデューサー側のネットワークとユーザーが作成するVPCネットワーク間でVPC Peeringを構成できます。VPC Peeringを構成することで2つのVPCネットワークを接続でき、各ネットワーク内のリソースが相互に内部通信できます。Vertex AI Vector SearchのVPC Peering構成の詳細については公式ドキュメントのVPC ネットワーク ピアリング接続を設定するを合わせてご参照ください。
またVertex AI Vector SearchではGoogle Cloudのネットワーキング機能の1つであるPrivate Service Connectもサポートしています。Private Service Connectを利用する場合は公式ドキュメントのPrivate Service Connect でベクトル検索を設定するをご参照ください。
次に示すのはパイプラインでIndexをデプロイする実装例です。Terraformで事前作成したIndex Endpointのidを指定してMatchingEngineIndexEndpointクラスのインスタンスを作成します。作成したインスタンスのdeploy_indexメソッドを呼ぶことでIndexをデプロイできます。
import time from google.cloud.aiplatform.matching_engine import MatchingEngineIndex, MatchingEngineIndexEndpoint index_endpoint_name = ( "projects/<YOUR_PROJECT_NAME>/locations/asia-northeast1/indexEndpoints/<YOUR_INDEX_ENDPOINT_ID>" ) index_name = "<YOUR_INDEX_ID>" machine_type = "e2-standard-16" min_replica_count = 2 max_replica_count = 5 index_endpoint = MatchingEngineIndexEndpoint( index_endpoint_name=str(index_endpoint_name), ) index = MatchingEngineIndex( index_name=str(index_name), ) current_timestamp_sec = int(time.time()) deployed_index_id = f"{index.display_name}_{index.name}_{current_timestamp_sec}" deployed_index_endpoint = index_endpoint.deploy_index( index=index, deployed_index_id=deployed_index_id, display_name=index_endpoint_display_name, deploy_request_timeout=timeout, ####以下ではマシンタイプやレプリカ数を指定##### machine_type=machine_type, min_replica_count=min_replica_count, max_replica_count=max_replica_count, ) with open(output_index_endpoint_name, "w") as f: f.write(str(deployed_index_endpoint.name))
Indexのデプロイ後はIndexのidとは別にデプロイ済みIndexのidが付与されます。デプロイ済みIndexはGoogle Cloudのコンソール上で確認できます。次の画像に含まれるIDの値がデプロイ済みIndexのidです。
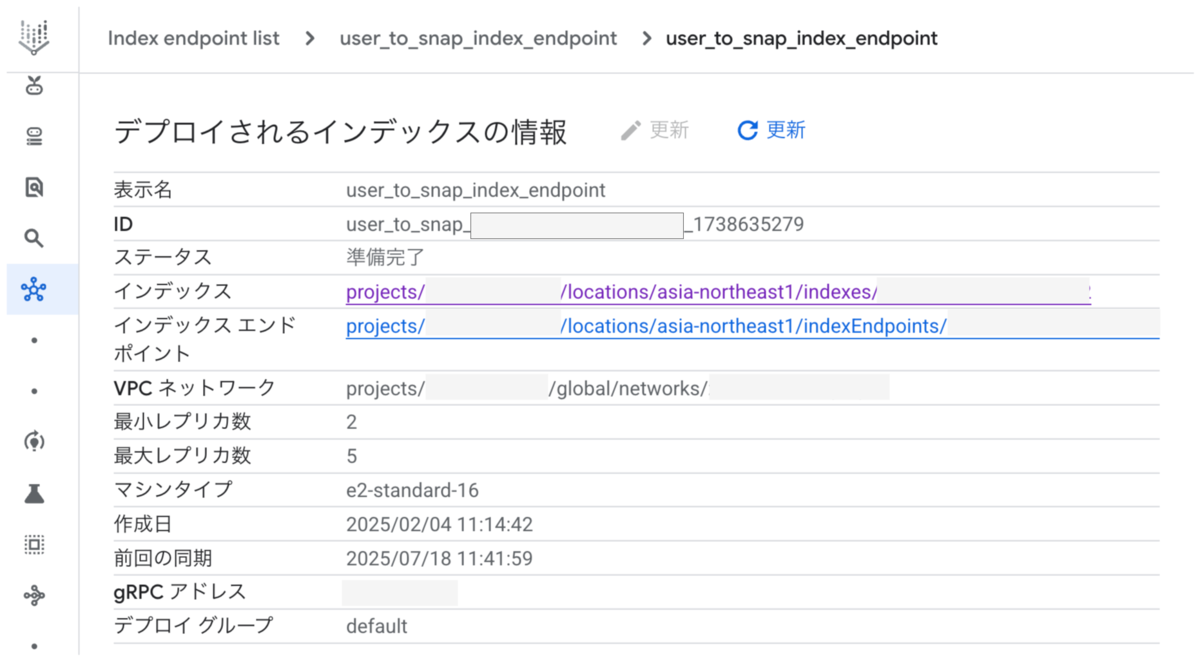
本システムでは、デプロイ対象のIndexのidと作成時のタイムスタンプを組み合わせてデプロイ済みIndexのidを生成しています。タイムスタンプを含めるのは、同じIndexを再度デプロイした場合にデプロイ済みIndexのidが重複しないようにする意図です。
Indexのデプロイ時にはマシンタイプやノードの最小・最大レプリカ数を指定できます。利用可能なマシンタイプは後述するIndex構成パラメータの1つであるシャードサイズごとに限定されます。マシンタイプはIndexのデプロイ後に変更できないため、シャードサイズを見積もった上でマシンタイプの選定が必要です。Indexサイズの見積もりとシャードサイズの決定については後節(Indexサイズの見積もりとシャードサイズの決定)で説明します。
またマシンタイプには、それぞれパフォーマンスと費用のトレードオフがあります。これらを考慮した上で、システムの要件に合わせてマシンタイプを選定することをおすすめします。マシンタイプごとのパフォーマンスについては公式ドキュメントのパフォーマンスに影響するデプロイ設定をご参照ください。
レプリカ数はIndexのシャードごとのノード台数を指定するパラメータです。つまりシャード数xレプリカ数がノード台数の合計になります。レプリカ数は最小・最大レプリカ数の範囲でオートスケーリングします。また最小レプリカ数を2未満に設定する場合はVertex AIサービスレベル契約の対象外となるため注意してください。
Indexをデプロイするとアクセス先となるgRPCアドレスが割り当てられます。ベクトル検索クエリ実行時はこのgRPCアドレスを指定してリクエストを送信します。リクエスト先となるアドレスの範囲はdeploy_indexメソッドのreserved_ip_ranges引数で指定可能です。指定がない場合はVPC内でVPC Peering用に割り当てているアドレス範囲から割り当てられます。ノードのレプリカ数を変更した場合もリクエスト先のgRPCアドレスは不変です。
Indexのデプロイに関する詳細は公式ドキュメントのVPC ネットワークにインデックス エンドポイントをデプロイして管理するを参照してください。またdeploy_indexメソッドの詳細についてはPython SDKのドキュメントをご参照ください。
Index構成パラメータの決定
Indexの作成時にはIndex構成パラメータを指定します。パラメータの多くはIndex作成時に確定しますが、クエリ実行時に設定値を上書きすることで動的に調整できるものもあります。ここでは、Index作成時に指定するパラメータとクエリ実行時に動的に調整しているパラメータについて、本システムを構成した際の値の決め方を説明します。
ベクトル検索で利用するアルゴリズムはTreeAHとBruteForceの2種類から選択できます。前節(ScaNNアルゴリズムの概要)で述べたScaNNアルゴリズムのドキュメントの経験則では100,000件以上のデータ規模ではTreeAHの利用が推奨されていました。本システムのIndexに含まれるEmbedding総数は約1,400万件であるため、TreeAHを利用することにしました。本記事での内容は特に断りがない限りはTreeAHアルゴリズムの利用を前提としていることをご留意ください。
Index構成パラメータについては公式ドキュメントのインデックス構成パラメータも本節の内容と合わせてご参照ください。
クエリ実行時に上書きしているパラメータ
本システムではクエリ実行時、次のIndex構成パラメータを上書きすることで動的に調整しています。
| フィールド | 説明 |
|---|---|
approximateNeighborsCount |
再スコアリング実行前の近似探索によってデフォルトで探索される近傍数 |
fractionLeafNodesToSearch |
クエリが検索されるリーフノードのデフォルトの割合 |
これらの値の大小は再現率とレイテンシ間のトレードオフになります。値を大きくするほど検索範囲が広がるため再現率は向上する一方でレイテンシは増加します。
またIndexの構成パラメータではありませんが、ベクトル検索クエリ実行時にはクエリで返す結果の数であるsetNeighborCountも指定できます。この値が大きくなるほどレイテンシは悪化します。
前節(2段階のベクトル検索)の説明の通り、本システムは1段階目のベクトル検索で取得した類似コーディネート群を2段階目のベクトル検索でリランキングし最終的な結果を返します。ここで最終的に返すべき件数の上限を60件とする要件は決まっていたため、この値を元にその他のパラメータ値を決定しました。
まず1段階目のベクトル検索におけるパラメータ値の決定について説明します。1段階目は「粗く速く、多めに拾う」を意識して決定しました。
2段階目に1段階目で取得した結果をリランキングすることを鑑みると1段階目ではなるべく多くの結果を返したいと考えました。そのため2段階目で返す60件よりも十分大きい値を1段階目で返す結果数の上限とし、setNeighborCountの値を決定しました。
公式ドキュメント(パフォーマンスに影響するクエリ時間の設定)ではsetNeighborCountの値が小さい場合、approximateNeighborsCountの値を10倍にすることが推奨されています。approximateNeighborsCountの値はこの推奨に従って決定しました。
本システムのビジネス要件ではそれほど高い再現率は要求されていませんでした。そのため類似コーディネート群の取得においては、再現率よりもレイテンシを優先してfractionLeafNodesToSearchは比較的小さい値であるデフォルト値をそのまま採用しました。
上記を踏まえて1段階目のクエリ実行時に上書きしたパラメータと値は次の通りです。参考までに本システムのベクトル検索IndexのEmbedding総数は約1,400万件です。
| フィールド | 値 |
|---|---|
approximateNeighborsCount |
10,000 |
fractionLeafNodesToSearch |
0.05 |
setNeighborCount |
1,000 |
続いて2段階目のベクトル検索におけるパラメータ値の決定について説明します。2段階目は「精度の重視」を意識して決定しました。
2段階目のベクトル検索では1段階目のベクトル検索結果に絞り込んでベクトル検索するため検索対象は1,000件に絞られています。approximateNeighborsCountやfractionLeafNodesToSearchの値を大きくするとレイテンシの増加が懸念されます。一方でここでは検索対象数が絞られているためここでのレイテンシ悪化の懸念は少ないと考えました。そのため2段階目では再現率を重視してapproximateNeighborsCount、fractionLeafNodesToSearchともに十分大きな値を指定しました。具体的に指定した値は次の通りです。
| フィールド | 値 |
|---|---|
approximateNeighborsCount |
1,000 |
fractionLeafNodesToSearch |
0.99 |
setNeighborCount |
60 |
このように決めた値でベクトル検索クエリを実行し、レイテンシの観点で目標を満たせることを確認しました。またベクトル検索結果について定性的に満足できる結果が得られることも確認しました。開発スケジュールが厳しかったこともあり、厳密な比較調整などのチューニングは行わず上記の値で運用を開始しました。
クエリ実行時に指定可能なパラメータとパフォーマンス影響については、公式ドキュメントのパフォーマンスに影響するクエリ時間の設定で説明されているため合わせてご参照ください。
Index構成時に指定しているパラメータ
Indexの構成パラメータのうち、前節(クエリ実行時に上書きしているパラメータ)で説明したパラメータ以外はIndex作成後の変更はできません。これらの値を変更する場合はIndexの再作成が必要です。
次のパラメータはIndex作成時に確定するパラメータです。これらのパラメータについて本システムでの値の決め方を説明します。
| フィールド | 説明 |
|---|---|
dimensions |
入力ベクトルの次元数 |
ShardSize |
各シャードのサイズ |
leafNodeEmbeddingCount |
各リーフノードに対するEmbeddingの数 |
distanceMeasureType |
最近傍探索で使用される距離尺度 |
featureNormType |
各ベクトルに対して実行される正規化のタイプ |
dimensionsは入力ベクトルの次元数を指定するパラメータです。Embeddingの次元数を元に値を決定します。本システムではGNNモデルで抽出したEmbeddingの次元数は256次元であるため256を指定しました。
ShardSizeは次の3種類から選択できます。
| 種類 | 説明 |
|---|---|
SHARD_SIZE_SMALL |
シャードあたり 2 GiB |
SHARD_SIZE_MEDIUM |
シャードあたり 20 GiB |
SHARD_SIZE_LARGE |
シャードあたり 50 GiB |
ShardSizeは各ノード上のデータ量を制御するパラメータです。本システムではSHARD_SIZE_MEDIUMを選択しました。本システムでのシャードサイズの決定方法については後節(Indexサイズの見積もりとシャードサイズの決定)で別途詳細に説明します。
leafNodeEmbeddingCountは各リーフノードのEmbeddingの数を指定するパラメータです。前節(ScaNNアルゴリズムの概要)で説明したパーティショニング数に関わります。値の大小は再現率とレイテンシ間のトレードオフになります。値を大きくするほど検索対象が減りレイテンシは短くなる一方で再現率は低下します。公式ドキュメント(パフォーマンスに影響する構成パラメータ)では、ほとんどのユースケースで値が15,000を超えない限りレイテンシは短くなると説明されています。本システムではレイテンシを優先して15,000を指定しました。
leafNodeEmbeddingCountについては、パラメータ値を決定する前にダミーで100としていたところクエリ実行に数秒かかる問題がありました。15,000に変更したところクエリ実行の時間は数10ミリ秒に改善しました。Index内のEmbedding数が多い場合は注意してleafNodeEmbeddingCountの値を決定することをおすすめします。
distanceMeasureTypeとfeatureNormTypeは公式ドキュメント(インデックス構成パラメータ)での推奨値に従いDOT_PRODUCT_DISTANCE + UNIT_L2_NORMを指定しました。以上をまとめると本システムでのIndex構成時に指定しているパラメータ値は次の通りです。
| フィールド | 値 |
|---|---|
dimensions |
256 |
ShardSize |
SHARD_SIZE_MEDIUM |
leafNodeEmbeddingCount |
15,000 |
distanceMeasureType |
DOT_PRODUCT_DISTANCE |
featureNormType |
UNIT_L2_NORM |
Indexサイズの見積もりとシャードサイズの決定
Index構成パラメータのうち、ShardSizeは各ノード上のデータ量を制御するパラメータであり、指定したShardSizeごとにサポートされるデータサイズが決まっています。シャード数は指定したShardSizeとIndexのサイズに応じて自動で決定されます。ShardSizeはIndex作成後に変更できないため、事前に値の見積もりが必要です。またVertex AI Vector Searchの合計ノード台数はシャード数xレプリカ数で決まるため、ShardSizeの見積もりは費用にも大きく影響します。
最適なShardSizeを選択するために、作成するIndexサイズの確認が必要です。一方で作成したIndexのサイズを直接的に確認する方法はないため概算します。
Indexのサイズは次式で概算しました。ここで式に含まれるRestrictsはEmbeddingデータに属性情報を付与するためのフィールドであり、ベクトル検索時のフィルタリングに利用できます。本システムでは2段階目のベクトル検索クエリ実行時、検索対象を1段階目のベクトル検索結果へ絞り込むためにフィルタリングを利用しています。Restrictsについては後節(フィルタリングの実装)で詳しく説明します。
Indexサイズ(Bytes) = Embedding数 × [(次元数 × 1次元あたりのサイズ) + Restrictsのサイズ]
ScaNNアルゴリズムではEmbeddingを圧縮しますが、ShardSizeの見積もりにあたっては圧縮後のサイズではなく、圧縮前のサイズを元に計算する必要があることに注意してください。
本システムではEmbedding数は約1,400万件、次元数は256次元、1次元あたりのサイズは4 Bytes(float32)です。Embeddingデータのサイズは14,000,000 × (256 × 4)で計算でき、約13.35 GiBとなります。RestrictsのサイズをIndexのサイズに対して約15%と見積もるとIndexの全体サイズは約15.35 GiBと概算できました。概算のためRestrictsのサイズは大きめに見積もりました。
Indexの全体サイズが15.35 GiBである場合、SHARD_SIZE_SMALLとSHARD_SIZE_MEDIUMの2種類のシャードサイズでは必要なシャード数は次のように見積もりできます。
| 種類 | サポートされるサイズ | シャード数の見積もり |
|---|---|---|
SHARD_SIZE_SMALL |
シャードあたり 2 GiB | 8~9 |
SHARD_SIZE_MEDIUM |
シャードあたり 20 GiB | 1 |
上記のEmbedding数でシャードサイズにSHARD_SIZE_SMALLを選択すると実際のシャード数は8となりました。前述の通りIndexのサイズを直接確認する方法はないため、実際に構成するまではシャード数の見積もりの妥当性を厳密に確認できません。一方で見積もりと実際の値の誤差が2 GiB程度で一致したことから、概算値の妥当性はある程度担保されていると判断できます。そのため実際にIndexを作成し、シャードサイズを変更して確認せずともシャードサイズを決定できます。
シャードサイズとシャード数の大小は再現率とレイテンシ間のトレードオフになります。シャードサイズが小さいほどシャード数は増え再現率を向上しますがレイテンシを悪化させます。シャードサイズが大きいほどシャード数は減りレイテンシを改善しますが再現率を低下させます。本システムではレイテンシを優先してSHARD_SIZE_MEDIUMを選択しました。
Indexのデプロイに使用できるマシンタイプはShardSizeによって異なります。例えばe2-standard-2マシンタイプはSHARD_SIZE_SMALLのシャードサイズでのみ利用可能です。SHARD_SIZE_MEDIUMを選択した場合に利用できる最も安価なマシンタイプはe2-standard-16になります。
| マシンタイプ | SHARD_SIZE_SMALL |
SHARD_SIZE_MEDIUM |
SHARD_SIZE_LARGE |
|---|---|---|---|
n1-standard-16 |
◯ | ◯ | × |
n1-standard-32 |
◯ | ◯ | ◯ |
e2-standard-2 |
◯ | × | × |
e2-standard-16 |
◯ | ◯ | × |
e2-highmem-16 |
◯ | ◯ | ◯ |
n2d-standard-32 |
◯ | ◯ | ◯ |
本システムのIndexサイズを元に、SHARD_SIZE_SMALLを選択した場合とSHARD_SIZE_MEDIUMを選択した場合の費用を比較すると次の通りです。計算に当たってはそれぞれのShardSizeごとに使用できる最も安価なマシンタイプで比較しています。リージョンはasia-northeast1を想定しており、マシンタイプの費用は公式ドキュメントの2025年7月時点の価格を元に計算しています。レプリカ数は本システムでの最小レプリカ数である2を想定しています。
| 種類 | シャード数 | マシンタイプ | 1ノード時間あたりの費用(USD) | ノード台数(シャード数 × レプリカ数) | 月額費用(USD) |
|---|---|---|---|---|---|
SHARD_SIZE_SMALL |
8 | e2-standard-2 |
0.12 | 16 | 1382.4 |
SHARD_SIZE_MEDIUM |
1 | e2-standard-16 |
0.963 | 2 | 1386.72 |
計算例では、SHARD_SIZE_SMALLを選択して小さなマシンを利用するのとSHARD_SIZE_MEDIUMを選択し、より大きなマシンを利用するのでは費用に大きな差はないことがわかります。SHARD_SIZE_SMALLの場合、リリース後の早い段階でEmbedding数が増えてシャード数が9になる可能性もあります。シャード数9だとSHARD_SIZE_SMALLの場合はSHARD_SIZE_MEDIUMと比較して若干費用が高くなります。このように費用観点でもSHARD_SIZE_MEDIUMを選択することが妥当であると判断しました。
ShardSizeの選択時は今後のEmbedding数の増加も考慮に入れるなど、システム要件に応じて値を選定することをおすすめします。
シャードサイズについては公式ドキュメントのインデックスの管理も合わせてご参照ください。
Indexのデプロイ戦略とEmbeddingの更新・削除方法
本番システムの運用観点においてIndexのデプロイ・リリース管理をどのように行うか、Indexの更新・削除時はどのようなフローで行うのか、ダウンタイムはあるのかは重要なポイントとして考慮しています。関連コーデレコメンドでもVertex AI Vector Searchを利用してシステムを構成する際にこれらのポイントには注意しました。
本節では関連コーデレコメンドのシステムにおけるIndexのデプロイ戦略の紹介と、Indexの更新・削除の実装時の注意点について説明します。
Indexのデプロイ戦略
本システムにおけるIndexのリリースフローをご説明します。
前節(Index Endpointの作成とIndexのデプロイ)での説明の通り本システムでは、Indexのデプロイ先となるIndex EndpointをTerraformで作成しています。Index Endpointの作成後は、Vertex AI Pipelinesを利用してIndexをデプロイします。
IndexのデプロイはTerraformのgoogle_vertex_ai_index_endpoint_deployed_indexリソースでも可能です。一方で本システムでは新規にIndexを作成する場合、Indexの作成とデプロイの作業を分けない方が開発者の手間が少ないと考えました。そのためIndexの作成とデプロイはどちらもVertex AI Pipelinesで行う構成にしました。
ただ実際運用してみると、Indexのデプロイに関してはVertex AI Pipelinesで行ってもTerraformで行っても運用上大きな違いはないと感じています。大切なのはIndexのデプロイ時には先のシャードサイズとマシンタイプ、シャード数とレプリカ数など、Indexの構成パラメータとインフラの設定が密接に関わるものがある点について理解することだと思います。例えばIndexを作成するチームとデプロイを担当するインフラチームが分かれている場合は、Index作成とデプロイについてお互いの棲み分けや連携についての認識合わせが重要と感じました。
本システムにおけるIndexのリリースフローは次図で表せます。
Vertex AI Vector Searchでのベクトル検索クエリはMLOpsブロックで開発・運用するアプリケーションAPIから実行しています。アプリケーションAPIはGKE上で動作しており、コンテナの環境変数でクエリ実行先のIndex Endpoint、Indexを指定しています。
MLOpsブロックでは、GKE上で動作するAPIのデプロイをKubernetes向けのGitOpsデリバリーツールであるArgo CDで行っています。また高度なデプロイ戦略の実現のため、KubernetesのカナリアリリースやブルーグリーンデプロイメントをサポートするツールであるArgo Rolloutsを利用しています。
Argo Rolloutsではこれらのデプロイ戦略に加えてAPIのSLO分析を組み合わせた段階的なリリース・自動ロールバックの仕組みを提供しています。このようなデプロイ手法をプログレッシブデリバリーと呼びます。アプリケーションAPIのデプロイはArgo CDで管理されており、Argo Rolloutsを利用してプログレッシブデリバリーを実現しています。
アプリケーションAPIのメトリクスはDatadogで収集しています。Argo RolloutsのSLO分析にはDatadogのメトリクスを利用しています。エラーレートやレイテンシのSLOを設定し、これらのSLOを満たさない場合は自動でロールバックするよう設定しています。
MLOpsブロックで利用するArgo CDの詳細は、TECH BLOGの「MLOpsマルチテナントクラスタへのArgo CDの導入と運用」をご参照ください。
本システムの構成では新規にIndexをデプロイした場合、アプリケーションAPIの環境変数でクエリ実行先のIndexを変更します。この作業を挟むことで、Index新規デプロイ時の安全性はアプリケーションAPIのプログレッシブデリバリーにより担保しています。
また新規にIndexをデプロイした後で参照されなくなったデプロイ済みIndexは不要な費用を防ぐため、デプロイを解除します。図では省略していますがこの作業は手動で行っています。
Indexの更新・削除
Indexの更新方法
本システムではVertex AI PipelinesのタスクでIndexを更新します。本番環境では最新のIndexではなく過去に作成したIndexを更新したいケースはないと考え、更新対象は作成日が最も新しいIndexとしました。
from google.api_core.client_options import ClientOptions from google.cloud.aiplatform_v1 import IndexServiceClient, ListIndexesRequest from google.cloud.aiplatform_v1.services.index_service import pagers from google.cloud.aiplatform_v1.types import Index from google.cloud.aiplatform.matching_engine import MatchingEngineIndex location = "asia-northeast1" project_id = "<YOUR_PROJECT_ID>" target_index_display_name = "<YOUR_TARGET_INDEX_DISPLAY_NAME>" option = ClientOptions(api_endpoint=f"{location}-aiplatform.googleapis.com") client = IndexServiceClient(client_options=option) parent = f"projects/{project_id}/locations/{location}" filter = f'display_name="{target_index_display_name}"' request = ListIndexesRequest(parent=parent, filter=filter) page_result: pagers.ListIndexesPager = client.list_indexes(request=request) latest_index: Index = sorted(page_result, key=lambda i: i.create_time, reverse=True)[0] index_name = latest_index.name index = MatchingEngineIndex(index_name=index_name) gcs_uri = str(contents_delta_jsonl_dir).replace("/gcs/", "gs://") index.update_embeddings( contents_delta_uri=gcs_uri, is_complete_overwrite=is_complete_overwrite, )
本システムではIndex更新方法としてバッチ更新を利用しています。バッチ更新の場合はMatchingEngineIndex.update_embeddingsメソッドを利用してIndexを更新します。更新時に指定するソースデータはIndex作成時のソースデータと同じ形式で用意し、contents_delta_uri引数で指定します。is_complete_overwrite引数は更新時にIndex全体を上書きするかどうかを指定するものです。本システムではIndex全体を更新分で置き換えたい訳ではなく、部分的にIndexを更新するため常にFalseを指定しています。
ソースデータに含まれるデータポイントのidが既にIndexに存在する場合は新しいEmbeddingデータで上書きされます。ソースデータに含まれるデータポイントのidがIndexに存在しない場合は新規に追加されます。
Indexの更新後はIndexが自動で再構築(圧縮)され、再構築中は増分Indexが作成されます。増分Indexが存在する間は、更新後にコンソールから確認できるIndexの密ベクトル数が実際にIndexに含まれるid数より多くなることがあります。また増分Indexが存在する間はベクトル検索クエリ実行時に増分Indexが優先的に参照されるため、この間も新規更新したEmbeddingを使ってベクトル検索します。
デプロイ済みのIndexを更新する場合はIndexの更新後に同期が必要です。基本的にバックグラウンドで自動同期されますが、更新から同期の完了までは若干のラグがあることに注意が必要です。コンソールから確認できるデプロイ済みIndexの前回の同期の値はEmbeddingの更新に関わらず定期的に更新されます。ドキュメント等に明記はなかったため手元で確認した値にはなりますが、この値は5分間隔で更新されていました。そのため経験的にはIndex更新の完了後5分以内に同期が完了します。
デプロイ済みIndexを更新する場合、更新や再構築、同期の間にダウンタイムはありません。
Indexの更新に関する詳細は公式ドキュメントのアクティブ インデックスの更新と再構築をご参照ください。
Indexの削除方法
Index内のEmbeddingデータを削除する場合は、Indexのバッチ更新と同じくMatchingEngineIndex.update_embeddingsメソッドを呼び出します。データ更新と異なる点はcontents_delta_uri引数でソースデータに指定するフォルダの構成です。指定先のフォルダ内にdeleteという名前でサブディレクトリを作成し、削除対象のデータポイントのidを指定したテキストファイルを配置します。
batch_root/
delete/
delete_file.txt
テキストファイルには次の例のように各行に1つのidを指定します。
1 2
Indexの更新と削除は一度のMatchingEngineIndex.update_embeddingsメソッドの呼び出しで同時に行えないことに注意してください。指定したフォルダ内にEmbedding更新用のファイルとdeleteサブディレクトリ内に削除用のファイルの両方が存在する場合、Indexデータの削除が行われないという事態がありました。Indexの更新と削除を別々の処理として実装することで解消できたため、本システムでは処理を分けています。
ベクトル検索クエリ実行とフィルタリングの実装
クエリ実行の実装
Python Vertex AI SDKとcurlコマンドでのベクトル検索クエリ実行の方法は公式ドキュメント(パブリック インデックスをクエリして最近傍を取得する)に記載されています。公式ドキュメントだけでなくGoogle CloudのVertex AI Vector Searchのコンソールでもgrpc_cliとPythonでの実装例が用意されています。コンソールのPython実装例はVertex AI Pythonクライアントライブラリを利用した実装になっています。
Vertex AI SDKはクライアントライブラリよりも高い抽象化レベルで動作します。より高い柔軟性や制御等のチューニングが必要な場合はVertex AI Pythonクライアントライブラリの利用も検討できます。
本システムのアプリケーションAPIはWEARのバックエンドAPIからのリクエストを受けて、Vertex AI Vector SearchやDBへアクセスする役割を担います。これらのVertex AI Vector SearchやDBへのリクエストはI/Oバウンドな処理であり、I/O待ちの間に他の処理を非同期に実行することでAPIのパフォーマンスを向上できます。
アプリケーションAPIの実装にはPythonのWebフレームワークであるFast APIを利用しており、エンドポイントの定義であるPath Operationに渡す関数はasync defとして定義しています。Fast APIではこの関数をasync defで定義することでイベントループを利用した非同期処理が可能になります。一方で関数をdefで定義するとスレッドプールを利用した並列処理を行います。イベントループを使った方法はスレッドプールを使った方法よりも高い並行性を持ちます。
Path Operationに渡す関数をasync defで定義する際の注意点として、関数内に同期処理があるとイベントループがブロックされてしまいパフォーマンスの低下につながります。そのためasync defで関数を定義し効率的に並行処理するには、関数内の重たい同期処理やI/O待ちのある処理を全て非同期処理にします。
Vertex AI Vector Searchでのベクトル検索クエリ実行について、Python Vertex AI SDKで用意されているクライアントは非同期処理に対応していません。ベクトル検索クエリを非同期に実行するため、本システムではVertex AI Pythonクライアントライブラリで非同期処理に対応したクライアントを指定して実装しました。
上述したコンソールのPython実装例を非同期処理に対応させると次のようになります。注意点として、grpc.insecure_channelやgrpc.aio.insecure_channelは通信を暗号化しません。そのため実際の実装ではgrpc.aio.secure_channelを利用して通信を暗号化することを推奨します。
import grpc from google.cloud.aiplatform_v1beta1 import MatchServiceAsyncClient from google.cloud.aiplatform_v1beta1.services.match_service.transports.grpc_asyncio import ( MatchServiceGrpcAsyncIOTransport, ) index_endpoint_ip_port = "<YOUR_gRPC_ADDRESS>:10000" channel = grpc.aio.insecure_channel(target=index_endpoint_ip_port) transport = MatchServiceGrpcAsyncIOTransport(channel=channel) client = MatchServiceAsyncClient(transport=transport)
ベクトル検索クエリ実行の実装例は次です。
from collections.abc import MutableSequence from google.cloud.aiplatform.matching_engine import MatchingEngineIndexEndpoint from google.cloud.aiplatform_v1.types import ( FindNeighborsRequest, FindNeighborsResponse, IndexDatapoint, ) feature_vector: list[float] = [0.1, 0.2, 0.3, ...] # クエリに使用するベクトル(※ 実際の値に置き換えてください) neighbor_count: int = 1000 # 取得する近傍の数 approximate_neighbor_count: int = 10000 # 近似探索で取得する近傍の数 fraction_leaf_nodes_to_search: float = 0.05 # 検索するリーフノードの割合 index_endpoint_name = ( "projects/<YOUR_PROJECT_NAME>/locations/asia-northeast1/indexEndpoints/<YOUR_INDEX_ENDPOINT_ID>" ) deployed_index_id = "<YOUR_DEPLOYED_INDEX_ID>" # デプロイ済みIndexのid datapoint = IndexDatapoint( feature_vector=feature_vector, ) vector_search_endpoint = MatchingEngineIndexEndpoint( index_endpoint_name=index_endpoint_name, ) query = FindNeighborsRequest.Query( datapoint=datapoint, neighbor_count=neighbor_count, approximate_neighbor_count=approximate_neighbor_count, fraction_leaf_nodes_to_search_override=fraction_leaf_nodes_to_search, ) find_neighbors_req = FindNeighborsRequest( index_endpoint=index_endpoint_name, deployed_index_id=deployed_index_id, queries=[query], return_full_datapoint=False, ) res: FindNeighborsResponse = await client.find_neighbors( request=find_neighbors_req, ) neighbors: MutableSequence[FindNeighborsResponse.NearestNeighbors] = ( res.nearest_neighbors )
先の方法で初期化したクライアントのfind_neighborsメソッドを呼び出すことでベクトル検索リクエストを実行できます。ここでfind_neighborsメソッドは非同期メソッドであり、awaitを付けて呼び出すことでベクトル検索リクエストを非同期に実行できます。
find_neighborsメソッドの引数のrequest引数にFindNeighborsRequestクラスのオブジェクトを渡すことで、ベクトル検索先やクエリ実行のパラメータを指定できます。また記載は省いていますが、timeout引数やretry引数を指定することでタイムアウトやリトライの設定も可能です。
クエリ実行対象のIndex Endpointとデプロイ済みIndexはFindNeighborsRequestクラスの初期化時に指定します。index_endpoint引数でIndex Endpointのリソース名を、deployed_index_id引数でデプロイ済みIndexのidを指定します。queries引数にFindNeighborsRequest.Queryクラスのオブジェクトを要素として持つ配列を渡してベクトル検索クエリの内容を指定します。queries引数の値は配列であり、要素が複数ある場合はクエリを同時に指定できます。本システムでは特にハイブリッド検索は利用していないためクエリは1つ指定しています。またreturn_full_datapoint引数でベクトル検索結果のデータポイントが持つ全ての情報を返すかどうかを指定できます。return_full_datapoint引数の値をTrueにした場合、データポイントのidだけでなく、Embeddingやrestrictsフィールドの値も返します。本システムではデータポイントのidのみがあれば十分であり、レスポンスサイズを小さくするためにFalseを指定しています。
FindNeighborsRequest.Queryクラスの初期化時、datapoint引数にIndexDatapointクラスのオブジェクトを渡すことでベクトル検索の対象を指定します。クエリ実行時の入力にはEmbeddingだけでなく、Indexに含まれるデータポイントのidも指定できます。本システムではデータポイントのidとしてコーディネートのidを利用しています。アプリケーションAPIはWEARのバックエンドAPIからコーディネートのidを受け取り、そのままIndexDatapointのdatapoint_idフィールドに指定してクエリ実行しています。またIndexDatapointクラスにはrestrictsフィールドも指定可能です。こちらは後節(フィルタリングの実装)で詳しく説明します。
上記の例ではクエリ実行時の入力にEmbeddingを使用する実装例ですが、データポイントのidを指定する場合は次のようにIndexDatapointオブジェクトを作成できます。
datapoint_id="1234"
datapoint = IndexDatapoint(
datapoint_id=datapoint_id
)
前節(クエリ実行時に上書きしているパラメータ)での説明の通り、approximateNeighborsCount・fractionLeafNodesToSearch・setNeighborCountの値はクエリ実行時に上書きし、Index作成時の指定値を変更しています。これらの値はFindNeighborsRequest.Queryクラスの初期化時に指定します。
フィルタリングの実装
Vertex AI Vector SearchではIndexのデータポイントへ属性情報を付与するrestrictsフィールドを利用して、ベクトル検索クエリの対象をIndexのサブセットに制限できます。
前節(2段階のベクトル検索)で説明した通り、本システムでは2段階にベクトル検索をします。restrictsフィールドを利用することで、2段階目のベクトル検索クエリ実行時に、検索対象を1段階目のベクトル検索で取得したサブセットに制限しています。
restrictsフィールドを指定する場合、名前空間(namespaceフィールド)の指定が必要です。またオプションとしてトークン(allow・denyフィールドの値)を指定できます。トークンの値は文字列の配列になります。クエリ実行時にallow_listやdeny_listを指定することで、トークンの値に応じて検索対象を制限できます。
前節(Index作成の実装)で紹介したIndexソースデータのファイルの値にrestrictsフィールドを指定すると、次の例のデータ形式になります。
{"id": "1", "embedding": [0.1,0.05,0.3], "restricts": [{"namespace": "snap_id", "allow": ["1"]}]} {"id": "2", "embedding": [0.2,0.01,0.02], "restricts": [{"namespace": "snap_id", "allow": ["2"]}]}
前節(クエリ実行の実装)に記載の通り、本システムではIndexのデータポイントのidとしてコーディネートのidを利用しています。フィルタリングには取得したデータポイントのidを指定するため、上記のようにrestrictsフィールドのトークンの値にもコーディネートのidを利用しています。またallow・denyフィールドはオプションであるため、指定しない場合は空の配列になります。本システムではallowフィールドのみを指定しています。
次に示すのはrestrictsフィールドを指定したベクトル検索クエリ実行におけるIndexDatapointクラスのオブジェクトの初期化の例です。本システムの2段階目のベクトル検索クエリ実行ではIndexDatapoint.Restrictionクラスの引数にallow_listを指定し、クエリ実行の対象をサブセットに制限しています。つまりfind_neighborsメソッド呼び出しの戻り値はallow_listに指定した値を持つデータポイントのみになります。
from google.cloud.aiplatform_v1.types import IndexDatapoint namespace = "snap_id" # 名前空間の指定 allow_list = ["1"] # 許可対象とする値の配列 datapoint = IndexDatapoint( feature_vector=feature_vector, restricts=[ IndexDatapoint.Restriction( namespace=namespace, allow_list=allow_list, ) ], )
また本システムでは1段階目のベクトル検索クエリ実行時にもrestrictsフィールドを活用しています。Vertex AI Vector Searchではデータポイントのidを指定してベクトル検索クエリを実行した場合、ベクトル検索結果には自身のデータポイントも含まれます。本システムでは1段階目のベクトル検索クエリ実行時にデータポイントのidを指定して近傍を取得しています。そのためデフォルトでは指定したデータポイントのidもfind_neighborsメソッド呼び出しの戻り値に含まれます。本システムでは入力となるコーディネートの類似コーディネートを取得したいため、find_neighborsメソッド呼び出しの戻り値に入力となるコーディネートのidを含めたくありません。入力したデータポイントのidを検索結果から除外するため、IndexDatapoint.Restrictionクラスの引数へdeny_listを指定しています。
from google.cloud.aiplatform_v1beta1.types import IndexDatapoint namespace = "snap_id" # 名前空間の指定 deny_list = ["1"] # 除外対象とする値の配列 datapoint = IndexDatapoint( datapoint_id=datapoint_id, restricts=[ IndexDatapoint.Restriction( namespace=namespace, deny_list=deny_list ) ], )
Restrictsの利用時に注意が必要なのは、Index作成時に指定するallow・denyフィールドとクエリ実行時に指定するallow_list・deny_listはそれぞれの組み合わせでフィルタリングされる点です。フィルタ条件と一致について次の例で説明します。この例は公式ドキュメント(ベクトル一致をフィルタする)での説明を元にしています。
例えばcolor名前空間について、次のallow・denyフィールドを持つデータポイントがIndexに存在するとします。
A: {"id": "A", "embedding": [...]} B: {"id": "B", "embedding": [...], "restricts": [{"namespace": "color", "allow": ["red"], "deny": []}]} C: {"id": "C", "embedding": [...], "restricts": [{"namespace": "color", "allow": ["blue"], "deny": []}]} D: {"id": "D", "embedding": [...], "restricts": [{"namespace": "color", "allow": ["orange"], "deny": []}]} E: {"id": "E", "embedding": [...], "restricts": [{"namespace": "color", "allow": ["red", "blue"], "deny": []}]} F: {"id": "F", "embedding": [...], "restricts": [{"namespace": "color", "allow": ["red"], "deny": ["blue"]}]} G: {"id": "G", "embedding": [...], "restricts": [{"namespace": "color", "allow": ["red", "blue"], "deny": ["blue"]}]} # 実務上必要性が薄いケース H: {"id": "H", "embedding": [...], "restricts": [{"namespace": "color", "allow": [], "deny": ["blue"]}]}
上記をソースデータに持つIndexに対してクエリ実行時に指定するallow_list・deny_listのパターンとして次の例を考えます。
(1) {} # restrictsの指定なし (2) {"namespace": "color", "allow_list": ["red"], "deny_list": []} (3) {"namespace": "color", "allow_list": ["blue"], "deny_list": []} (4) {"namespace": "color", "allow_list": ["orange"], "deny_list": []} (5) {"namespace": "color", "allow_list": ["red", "blue"], "deny_list": []} (6) {"namespace": "color", "allow_list": ["red"], "deny_list": ["blue"]} (7) {"namespace": "color", "allow_list": ["red", "blue"], "deny_list": ["blue"]} # 実務上必要性が薄いケース (8) {"namespace": "color", "allow_list": [], "deny_list": ["blue"]}
この時、データポイントのallow・denyフィールドとクエリ実行時に指定するallow_list・deny_listの組み合わせによるフィルタリング結果は次になります。◯は条件が一致しデータポイントを取得できる組み合わせです。空欄は条件が一致せずデータポイントを取得できない組み合わせを表しています。
| A | B | C | D | E | F | G | H | |
|---|---|---|---|---|---|---|---|---|
| (1) | ◯ | ◯ | ◯ | ◯ | ◯ | ◯ | ◯ | ◯ |
| (2) | ◯ | ◯ | ◯ | ◯ | ||||
| (3) | ◯ | ◯ | ||||||
| (4) | ◯ | |||||||
| (5) | ◯ | ◯ | ◯ | |||||
| (6) | ◯ | ◯ | ||||||
| (7) | ◯ | |||||||
| (8) | ◯ | ◯ | ◯ | ◯ | ◯ |
本システムではデータポイントの作成時、allowフィールドに1つのトークンの値を持たせているため、上記の例ではデータポイントB~Dのパターンに該当するデータポイントがIndexに存在します。
1段階目のクエリ実行では入力となるコーディネートのidを除外するようにdeny_listを指定しており、これは上記の例ではクエリの(8)に該当します。(8)とB~Dで一致を見ると(8)とC以外の組み合わせで一致することがわかります。また2段階目のクエリ実行では1段階目のベクトル検索で取得した複数のデータポイントのidをallow_listに指定しており、上記の例ではクエリの(5)に該当します。(5)とB~Dで一致を見ると(5)とB、(5)とCの組み合わせで一致することがわかります。
このようにデータポイントのrestrictsフィールドのallow・denyフィールドとクエリ実行時に指定するallow_list・deny_listの組み合わせで複雑な条件でのフィルタリングが可能です。一方で本システムのような簡単なクエリであればデータポイントに持たせるのはallowフィールドのみで十分です。ユースケースによって指定するフィールドを使い分けつつ、上記のような表でフィルタリング対象が意図したものになるか確認することをおすすめします。
Vertex AI Vector Searchの本番運用と課題の改善
モニタリング運用
Vertex AI Vector Searchではメトリクスダッシュボードがデフォルトで提供されており、ダッシュボードでは次のメトリクスを確認できます。
- ノード数
- シャード数
- 秒間クエリ数
- レイテンシ(50・95・99%tile)
- CPU使用率
- メモリ使用率
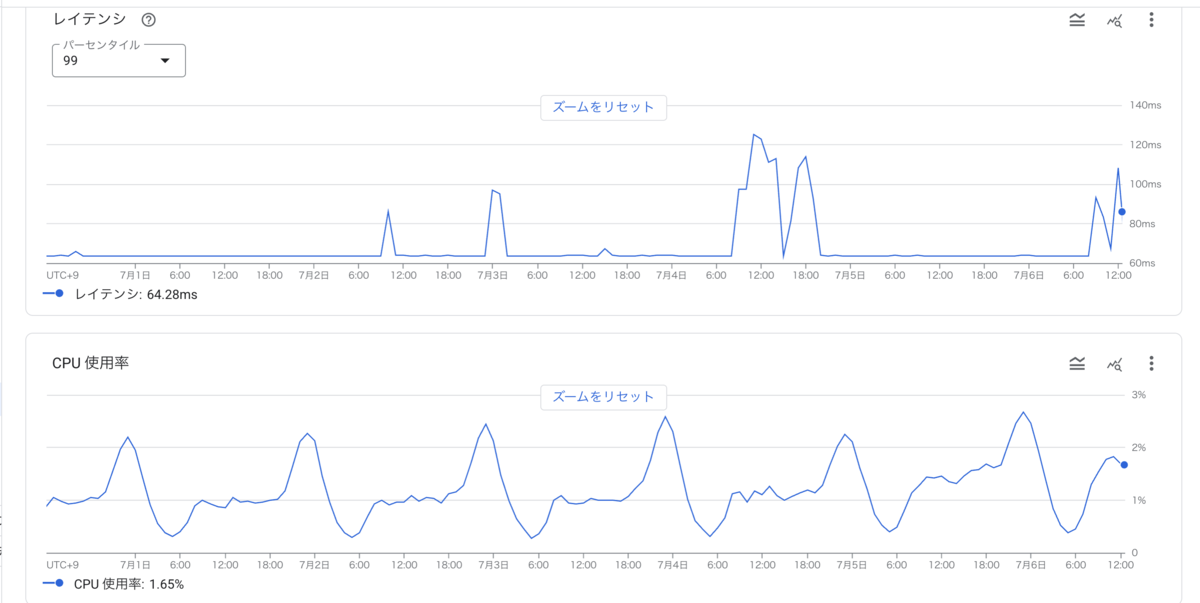
次に示すのは実際のダッシュボードの画面です。
本システムでは現状、Vertex AI Vector Searchのメトリクスを対象としたアラートの設定は行なっていません。アプリケーションAPIやLoad Balancer、Datadogのメトリクスはモニタリング・アラートを設定しています。Vertex AI Vector Searchのメトリクスダッシュボードはこれらのモニタリングで異常があった場合の調査手段として参照しています。
現状上記のモニタリング運用で特に困った点はありません。今後の運用でVertex AI Vector Search単体でのメトリクス悪化を検知したいケースなど出た場合は、Vertex AI Vector Searchのみの監視やアラートの設定を検討します。
運用して感じたメリット
関連コーデレコメンドでVertex AI Vector Searchを約4か月間、本番運用して感じた利用メリットを紹介します。
運用・保守の容易さ
前節(Vertex AI Vector Searchの導入モチベーション)でVertex AI Vector Searchの採用理由としてマネージドサービスであることを挙げていました。マネージドサービスであるためリリース後に必要な運用・保守作業は特になく、ユーザー側ではベクトル検索Indexの作成や更新、クエリ実行の実装に集中できています。
また過去プロジェクトにおけるベクトル検索機能の実装で述べたようなバッチとAPI間の依存もありません。前節(Indexのデプロイ戦略)で述べたようにIndexのデプロイ戦略もシンプルな構成に実装できています。過去プロジェクトにおけるベクトル検索機能と比較するとシステム自体をシンプルにできた点も運用負荷の軽減につながりました。
安定したパフォーマンス
本システムをリリース後、Vertex AI Vector Search起因での問題はほとんど発生しておらず、安定したパフォーマンスを発揮しています。
本システムの平均リクエスト数は約15req/secでピーク時は約30req/secです。Vertex AI Vector Searchのベクトル検索リクエストのレイテンシは99%tileで約60〜120msであり、特にピーク時の大きなレイテンシ悪化も見られません。
Vertex AI Vector Searchはマネージドサービスであるため、ベクトル検索APIと同じGKEクラスタ内に自前でAPIを構築する場合と比較するとネットワーク的な距離は離れています。クエリ実行のレイテンシへネットワーク起因でのレイテンシ等が上乗せされることで、ベクトル検索リクエスト時のレイテンシを増加する可能性を懸念していましたが、結果として本プロジェクトの要件に対しては十分なパフォーマンスでした。
またマネージドサービスへのリクエスト時、timeoutエラーの発生が度々他システムで見られており、Vertex AI Vector Searchについても懸念していました。しかし本システムでのVertex AI Vector Searchへのリクエストではtimeoutエラーは1日1件発生するかどうかの頻度となっており安定しています。
関連コーデレコメンドプロジェクトの出面での負荷は比較的に規模が小さく、より高負荷な本番環境でのVertex AI Vector Searchの利用実績はまだMLOpsブロックでは作れていません。しかし負荷試験時には新規導入したVertex AI Vector Searchの負荷限界を把握するため、本番の想定トラフィックを大きく超える~200req/secまで検証しました。検証した範囲ではVertex AI Vector Searchのレイテンシに大きな変化は見られませんでした。こういった実績からも、今後より大規模なシステムでベクトル検索機能を構築する際にも十分選択肢になり得ると考えています。
運用して見つかった課題と改善
Vertex AI Vector Searchを利用した本システムを本番運用する中で次の課題が見つかりました。
- Index更新にかかる時間が長い
- Index更新数が多いとデータ更新にかかる費用が増加する
それぞれの課題と本システムで実施した改善内容を紹介します。
Indexの更新時間が長い
本システムでは日次でIndexの更新を行なっています。また前節(Indexの削除方法)で述べた通り追加・更新と削除はタスクを分けて直列に実行しています。Indexの更新にかかる時間は追加・更新、削除を合わせると約2〜3時間となっており、パイプラインの全体の実行時間に対して約半分の割合を占めていました。
それぞれのタスクにかかる時間と更新数は次の通りです。参考までにIndex全体のデータ数は約1,400万件です。
- 追加・更新:1〜2時間
- 更新数:約3,500,000件
- 削除:約30〜40分
- 更新数:約30〜60件
本システムではインフラ構築にかかる費用やシステムの複雑性を抑えるため、APIでのリアルタイムなEmbedding抽出は行なっていません。そのためバッチ処理で事前にEmbedding抽出されたユーザー・コーディネートのみを関連コーデレコメンドプロジェクトでのMLを使ったレコメンドの対象としています。この構成では新規ユーザー・コーディネートのEmbeddingをより早く抽出し、レコメンド対象とするにはバッチの実行頻度を上げる必要があります。またバッチの実行頻度を上げると、より直近の行動を反映したEmbeddingを使ってベクトル検索をできるためレコメンドのリアルタイム性も向上します。
本システムで高いリアルタイム性は要求されていませんが、今後バッチの実行頻度を増やしてリアルタイム性を向上させる場合、Indexの更新にかかる時間がボトルネックになることを懸念しました。
Indexのデータ更新費用の増加
Vertex AI Vector Searchの費用は主に次の2つの要素で構成されています。
- インスタンスの費用
- Index構築の費用
データ更新によるIndex構築の費用はIndexの更新時に処理されたデータの量に応じて課金されます。Vertex AI Vector Searchのバッチ更新では2025年7月現在、すべてのリージョンに一律で処理されたデータ量に対して$3.00/GiBが課金されます。費用については公式ドキュメントで最新の情報を参照してください。
本システムでのIndex更新数は1日あたり3,500,000件であり、Vertex AI Vector SearchのIndex更新に伴うIndex構築の費用は1日あたり約$46となっていました。asia-northeast1リージョンでe2-standard-16インスタンスをノード数2で利用した場合の1日あたりの費用は約$46となります。そのためIndex更新の費用はインスタンスの費用と同程度となっており、データ更新に伴う費用がベクトル検索機能の費用の半分近くを占めています。これは当初想定していたよりも大きな費用であり、問題になりました。
Indexのデータ更新費用の算出については混乱する部分があったため後節(Indexのデータ更新費用の見積もり)で別途説明します。
Embedding更新対象のデータ数を削減
本システムでは前節の運用課題に対してIndexの更新対象となるデータ数を減らすことで対応しました。更新対象となるデータ数を減らすことで次の改善が得られました。
- Indexのデータ更新費用の大幅な削減
- Index更新時間の短縮
前節(グラフニューラルネットワークモデルによるEmbeddingの抽出)で述べた通り、本システムではGNNモデルを利用してEmbeddingを抽出しています。次に該当するユーザー・コーディネートをEmbedding抽出対象とし、Indexへ追加・更新していました。このうちデータ更新数の増加に大きく関係していたのは3のデータでした。
- 新規追加されたNode
- 自身に紐づくユーザー行動の変化があったNode
- 上記の更新対象に隣接するNode
2に該当するユーザー・コーディネートをアクティブなユーザー・コーディネートと表現します。3を更新対象とすることでアクティブなユーザー・コーディネートに紐づく非アクティブなユーザー・コーディネートも更新対象となります。特にアクティブなユーザー・コーディネートは隣接するNodeも多いため、結果として更新数の爆発的な増加へ繋がっていました。
3に該当するユーザー・コーディネートのEmbedding更新についてはレコメンドの精度にはそれほど大きく影響しないと考えました。更新対象のデータ数を減らすため3に該当するユーザー・コーディネートはEmbeddingの更新対象へ含めないよう変更しました。補足として非アクティブなユーザー・コーディネートについても、新規にユーザー行動があった場合には上記の2に該当するため、隣接Nodeとの関係性を考慮してEmbeddingを更新しています。変更の適用後もビジネスKPIに悪化は見られず、レコメンドの精度に大きく影響することなく更新数を低減できました。
削減前後のEmbedding更新数は次の通りです。
- コーディネート
- 削減前:約3,500,000件
- 削減後:約150,000件
- ユーザー
- 削減前:約2,000,000件
- 削減後:約10,000件
日によって更新数は変動しますが、更新対象のデータ数を大きく減らすことができました。コーディネートについては削減前に比べて約23分の1、ユーザーについては約200分の1のデータ更新数となりました。
抽出したユーザーのEmbeddingはGoogle CloudのサーバレスNoSQLドキュメントデータベースであるCloud Firestoreに保存していました。更新対象のユーザーEmbeddingの件数も想定より多かったためCloud Firestoreの書き込み費用も課題となっていました。更新対象のデータ数を削減したことにより、Vertex AI Vector Search、Cloud Firestoreのデータ更新費用は対応以前と比較して8割以上削減できています。
またIndex更新対象のデータ数が大きく減ったことで、Indexの更新にかかる時間も大きく短縮されました。データ更新時に約1〜2時間かかっていたIndexの更新時間は約40分に短縮できました。データ処理対象の件数が減ったことでパイプライン内のIndexの更新以外のタスクの実行時間も短縮され、パイプライン全体の実行時間は約半分に短縮されました。
一方でIndexへのEmbeddingの追加・更新時の更新時間は更新データ削減対応後、Embeddingの削除時の更新時間と同程度まで短縮できました。約30〜60件しか更新対象のデータ数がない削除時と同程度まで短縮できたことを鑑みて、さらに更新対象のデータ数を減らすことによる更新時間の短縮は効果が薄いと考えています。
バッチ更新時間の更なる短縮のためにはIndexのストリーミング更新の利用可能性があります。公式ドキュメントにはストリーミング更新を利用することで数秒以内にIndexを更新できると説明があります。
一方で既存のIndexではバッチ更新を利用しているため、ストリーミング更新を利用するにはIndexの再作成が必要となります。またストリーミング更新では更新リクエストの制限や割り当ての上限があるため、大規模なデータ更新には向かないという懸念があります。このような理由からストリーミング更新の利用は現時点では慎重に検討しています。
Indexのデータ更新費用の見積もり
Vertex AI Vector Searchを本番運用する中で、自分が見積もりしていたIndexのデータ更新時の費用とCloud Billingのコンソールで確認できる費用に乖離がありました。
前述の通りIndex構築の費用は2025年7月現在、公式ドキュメントで次のように説明されています。
ベクトル検索では、すべてのリージョンにおいて、処理されたデータ 1 GiB あたり $3.00 が課金されます。
当初自分は処理されたデータを更新対象のデータと解釈していました。つまりIndex更新のデータソースとして指定したファイルに含まれるEmbeddingデータを課金対象と勘違いしていました。
Embedding更新対象のデータ数を削減する前のIndexの更新数は1日あたり約3,500,000件です。前節(Indexサイズの見積もりとシャードサイズの決定)の式で更新分のデータ量を計算すると1日あたり約3.8GiBです。更新分のデータ量に対して課金された場合、1日あたり$11.4が費用となるはずです。しかし前節(Indexのデータ更新費用の増加)で述べた通り、Cloud Billingで確認した費用は1日あたり約$46であり、更新分のデータ量での見積もり額よりも明らかに大きな金額です。
処理されたデータを更新対象のデータだけでなく、既存のIndexに含まれるデータも含めたデータ全体を指すと考える場合、実際の費用と近い金額を算出できることに気がつきました。削減対応前では、データ更新数とIndexのデータ総数を合わせて約1,400万件でした。データ量は約15.35GiBであり、費用を算出すると約$46となるためCloud Billingで確認した費用に一致します。
しかしIndexデータ全体を課金対象と考えると、更新対象のデータ数を減らすことでIndexの更新に伴うIndex構築の費用を大きく削減できたことの説明がつきません。そこでIndexの圧縮による再構築で処理されたデータ量が費用に関係していると推測しました。バッチアップデートでのIndexの圧縮については公式ドキュメントで次の説明があります。
増分データセット サイズが基本データセット サイズの 20% を超えるときに行われます。
削減前のIndexのデータ総数は約1,380万件であり、更新対象のデータ数は約350万件でした。350万件は1,380万件の約25%に相当します。更新対象のデータ数が20%を超えたことで、更新の度にIndexは圧縮により再構築され、データ全体を処理することで課金対象となったと考えました。削減後の更新対象のデータ数は約150,000件であり、1,380万件の約1%に相当します。更新対象のデータ数が20%を下回ったためIndexの圧縮による再構築はされず、処理されるデータ量が大きく減ったことで費用が減少したと推測しました。
次図は更新分のデータ量がIndexのデータ量の20%以上の場合に課金対象となるデータのイメージです。

次図は更新分のデータ量がIndexのデータ量の20%以下の場合に課金対象となるデータのイメージです。こちらは内部挙動を推測して作成したイメージであるため実際の挙動とは異なる可能性があります。

Cloud Billingで確認できた削減対応の前後でのIndex構築の費用の変化は次の通りです。
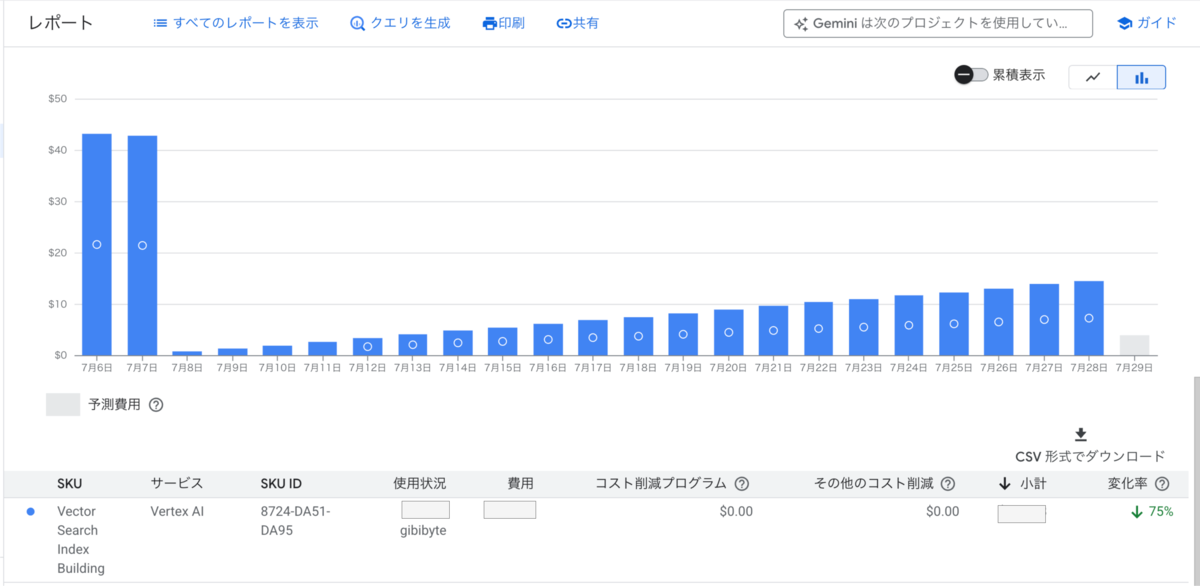
更新対象データを削減した7月7日以降に費用が大きく減っており、更新対象データ削減の効果が出ていることがわかります。しかし費用が大きく減った7月8日以降は費用が線形に増加しています。更新対象のデータ量はほぼ一定の値であるため、線形に増加するのは不自然だと感じました。また公式ドキュメントに記載の内容からこのような費用増加の説明は読み取れませんでした。そこでVertex AI Vector Searchの内部挙動を推測して、更新対象のデータ数が20%を下回る場合の費用見積もりの方法を考えました。
本節の以下の内容は、公式ドキュメントに記載のない内容を推測で補い、仮説立てした説明です。公式ドキュメントに記載の内容・実際の費用・データ量以外は推測であり、確実でないためご注意ください。
データ更新にかかるIndex構築費用の算出は本システムの運用の中で苦労した点であり、同様の課題を抱える方の参考になればと思い、記載しています。
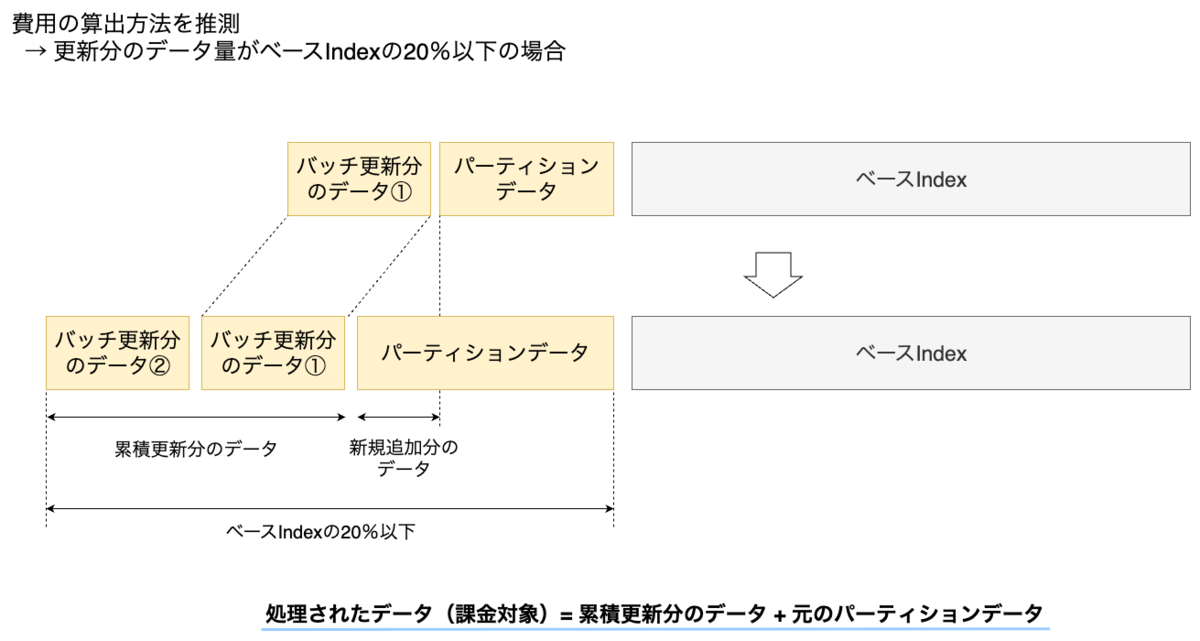
更新対象データを削減した後で費用が大きく減ったこと、その後で線形増加したことを踏まえて、Indexは内部でパーティショニングされており更新時にパーティションデータを処理している可能性を推測しました。一般的に大量のデータを扱うシステムでは、一部のデータ更新でデータ全体を再構築せず、パーティションデータのみを更新することでパフォーマンスを向上させます。公式ドキュメント内での記載はないため、あくまでも推測ですが、Vertex AI Vector SearchでもIndexをパーティショニングしている可能性はあります。パーティションがIndex全体の20%を超えるまではパーティションデータを更新し、パーティションがIndex全体の20%を超える場合はIndex全体が圧縮されると推測しました。またパーティションデータの更新時は累積更新分とパーティション分のデータ量に対して課金されると推測する場合、削減後の費用の線形増加も説明できます。
次図は更新分のデータ量がIndexのデータ量の20%以下かつパーティションデータを更新する場合に課金対象となるデータのイメージです。こちらも内部挙動を推測して作成したイメージであるため実際の挙動とは異なる可能性があります。
以上の推測に基づいて、更新対象のデータ数がIndex全体の20%以下である場合のIndexのデータ更新費用は次の式で計算できると考えました。本システムのIndex構築費用の算出に次式を利用しています。
データサイズ(Bytes) = (パーティションの累積更新Embedding数(重複あり) + 更新前のパーティションのEmbedding数(重複なし)) × [(次元数 × 1次元あたりのサイズ) + Restrictsのサイズ]
公式ドキュメントに記載の費用とCloud Billingで確認できる費用以外の要素は推測であるため、上式での正確な費用の算出はできていません。実際のところ、過去のデータを用いて上式で計算した費用とCloud Billingで確認できる費用には10%前後のズレが出ています。しかし全体としての傾向は捉えられており、単に更新分のデータ量やIndex全体のデータ量を処理されたデータとして見積もるよりも、実際の費用と近い値を計算できています。
費用の形態や課金の仕組みはサービス内部の仕様に依存するため、費用の傾向が変わる可能性はあります。そのため今後もVertex AI Vector SearchのIndex構築の費用は継続的に確認し、見積もりから大きくずれることがあれば見積もり方法の見直しを考えています。
まとめ
本記事ではWEAR関連コーデレコメンドプロジェクトへのVertex AI Vector Search導入と実践について紹介しました。実プロジェクトでの実装・運用経験を通じて得られた知見が、これからVertex AI Vector Searchの導入を検討している方の参考になれば幸いです。
今後はVertex AI Vector Searchの利用実績を増やし、より大規模なシステムでの利用経験を積んでいきたいと考えています。また、Vertex AI Vector Searchの新機能や改善点についても引き続き注目していきます。
ZOZOでは、一緒にサービスを作り上げてくれる方を募集中です。MLOpsブロックでも絶賛採用を行っているため、ご興味ある方は以下のリンクからぜひご応募ください。